1. Introduction
The World Health Organization (WHO) reported in 2023 that globally about 1.3 million people die each year from road traffic accidents (2.3% of all deaths), resulting in a loss of 3–5% of global GDP (about USD 1.8 trillion/year) [
1]. This underscores the vital necessity to reinforce the capabilities of pre-hospital medical emergency services and to improve the capacity of monitoring and early prediction of the emergency system. A significant proportion of pre-hospital medical emergency calls are from traffic accidents, which highlights the necessity for the development of a predictive model. However, researchers have conducted little research in this field.
The data pertaining to pre-hospital traffic accident emergency calls exhibits patterns and trends over time. The collated data comprise a series of data points arranged in chronological order, which reflects the state of a system or process at different points in time. Consequently, this paper treats the aforementioned data as time series data for the purposes of analyzing and predicting the number of future callers. Time series analysis methods leverage the relationship between the current and past values of the series, as well as stochastic factors, to construct prediction models with a certain degree of accuracy [
2]. These include autoregressive (AR), moving average (MA), autoregressive moving (ARMA), and autoregressive integrated moving average (ARIMA) models. Among these models, the ARIMA model [
3] excels at extracting deterministic information from non-stationary time series, and achieves this efficiently by using the characteristics of the difference method. This has important applications in the study and forecasting of fluctuating time series. Thirugiri et al. [
4] developed an ARIMA-based mobility prediction model to predict the future mobility speed of nodes in a mobile autonomous network (MANET). Dey et al. [
5] developed and compared a variety of linear and nonlinear regression models, as well as the ARIMA model, with the objective of predicting gasoline demand in India. Zhao et al. [
6] used an ARIMA model to predict the number of COVID-19 confirmed cases using a dataset from 1 November 2021 to 17 February 2022. However, the ARIMA model can only capture linear relationships in a time series and fails to model complex nonlinear patterns, making it difficult to capture dependencies between distant time steps.
The inherently temporal nature of time series data is a key property that deep learning models can capture, which is particularly significant when handling sequence data. For example, the Hetero-ConvLSTM model, which uses heterogeneous spatiotemporal data, and the traffic accident prediction method, which employs the LSTM-GBRT model, are adept at handling complex data [
7,
8], but the model fusion architecture is complex, requires multimodal data alignment, and incurs high data preprocessing costs in real-world applications. These models not only enhance the precision of prediction, but also offer novel insights into traffic management. Furthermore, deep-learning-based frameworks for traffic accident severity prediction have demonstrated their potential in accident consequence assessment [
9], but are not dynamically adaptable enough to real-time data to handle sudden road condition changes. A deep learning approach was employed to construct models for time series research utilizing Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs) [
10], Long Short-Term Memory (LSTM) [
11], Gated Recurrent Unit (GRU) [
12], and Transformer [
13]. Lai et al. [
14] synthesized the proposed LSTNet (Long and Short-term Time series Network) model by combining the network structure of CNN with RNN, LSTM, and GRU, thereby achieving superior results in the exchange-rate dataset, but lacked the self-attention module to integrate the entire time series to improve the overall feature relevance of the model to the data. Wu et al. [
15] employed the Transformer to construct the Autoformer model and conducted model validation on six datasets (ETT, Electricity, Exchange, Traffic, Weather, and ILI) spanning diverse domains. The best results were achieved on all datasets, but the model parametric quantities and inference times were large, and the computational resource requirements were too high to be deployed on lightweight devices. However, the Transformer model, due to its attention mechanism, exhibits an increase in inference time with an increase in the number of parameters in a time series. Li et al. [
16] proposed a novel adaptive traffic signal control method based on periodic signal timing and traffic flow prediction, which combines a mixture of Kalman filtering and LSTM to achieve traffic flow prediction. Cai et al. [
17] proposed the MHA-Net multiscale higher-order attention mechanism network, which demonstrated a more lightweight performance than the Transformer model, but with lower accuracy in model prediction. This was achieved by reducing the model parameters and inference time. However, there is a paucity of research in the traffic accident emergency prediction field.
Regarding traffic flow prediction, Che et al. [
18] proposed a novel traffic flow prediction method based on the fusion of static and dynamic maps, and verified the performance of the proposed method. Wang et al. [
19] proposed a hybrid framework combining Long Short-Term Memory Neural Networks (LSTM NNs) and Bayesian Neural Networks (BNNs) for real-time traffic flow prediction and uncertainty quantification based on sequential data. Dong [
20] proposed a new integrated entropy cloud model, which includes two algorithms: fused cloud model inference based on DS evidence theory and cloud model inference and prediction based on compensatory mechanism, which are designed to solve the problem of short-term traffic flow prediction by utilizing a cloud model of the historical traffic data to guide the short-term prediction in the future. Wang et al. [
21] introduced an innovative traffic flow prediction method, ASTRformer, which emphasizes the integration of spatial and temporal information from historical data through an adaptive spatiotemporal relationship learning mechanism that integrates feature embedding with adaptive spatial and temporal embedding. Chen et al. [
22] proposed a traffic flow prediction model based on sequence to sequence time graph convolutional network, designing an innovative Seq2seq architecture based on time graph convolutional network to capture the spatiotemporal features of traffic flow. However, the above study lacks a comparison with traditional time series prediction models (e.g., ARIMA, Autoformer). To address this gap, we conduct statistical characterization and autocorrelation analysis of the measured data, aiming to identify temporal change patterns and forecast future values based on historical observations. In this study, we use the pre-hospital traffic accident emergency calls data of Chengdu City to train three models. The models considered are ARIMA, LSTNFCL (Long-Short-Term Network with Conv2Former, CBAM (Convolutional Block Attention Module), and LSTM) and Autoformer. The optimal model is selected based on the criteria of mean absolute error (MAE) and root mean square error (RMSE). The initial step is to select a historical time series data set of a specified length, which will serve as the modeling dataset. Subsequently, the modeling dataset is evaluated in terms of its smoothness and stochasticity, and an appropriate model is selected for modeling purposes. The main contribution of the model is to improve the LSTNet model and propose a novel LSTNFCL timing prediction framework. First, in the feature extraction stage, the Conv2Former module is introduced to combine the convolutional operation with the self-attention mechanism, which enhances the model’s ability to jointly model local features and global timing dependencies; meanwhile, the CBAM attention mechanism is integrated in the feature fusion session to dynamically adjust the key feature weights through the channel-space dual visual attention. Secondly, at the temporal modeling level, a hybrid loop cell architecture of GRU, LSTM, and RNN is constructed to comprehensively capture the multiscale patterns of temporal data by taking advantage of the complementary nature of different gating mechanisms. In addition, by optimizing the feature interaction paths and adjusting the residual connection structure, the efficient fusion of multilevel features is achieved, which further strengthens the nonlinear representation ability of the model. Then, the loss function MSE is optimized using stochastic gradient descent, which in turn optimizes the model parameters and results in an optimized model. Finally, the model is utilized to predict future pre-hospital traffic accident emergency calls.
1.1. Symmetry in Traffic Patterns
Pre-hospital traffic accident emergency calls in Chengdu exhibit both temporal symmetry and asymmetry. Cyclic symmetry is manifested by mirrored demand patterns during daily peak hours (e.g., 8:00–9:00 vs. 17:00–18:00) and weekly cycles, with weekday peaks forming a self-similar temporal structure. Conversely, holiday diversions and irregular events lead to asymmetry. The LSTNFCL model proposed in this paper decomposes the temporal signal into symmetric and asymmetric components via Conv2Former-CBAM. The GRU layer maintains daily symmetry via reset gates, the LSTM forgetting gates isolate holiday-induced asymmetries, and parallel RNN branching strengthens the stability of short-term patterns. Adaptive residual concatenation dynamically reweights the symmetric/asymmetric features of each layer, and LSTNFCL suppresses overfitting to historical symmetries by suppressing overfitting when dealing with holiday data. Autoformer captures temporal symmetry through its global self-attention mechanism and positional encoding, and recognizes periodic patterns by calculating pairwise correlations across all timestamps. However, its static attention matrix tends to overfit historical symmetries while lacking an explicit mechanism to isolate asymmetric events. In contrast, the LSTNFCL proposed in this study explicitly splits the symmetric/asymmetric components through a hybrid operation of Conv2Former and adaptively reweights them using CBAM to achieve multiscale temporal filtering, which has been validated on data with Chengdu traffic.
1.2. Organization of the Paper
The remainder of this paper is organized as follows.
Section 2 describes the methodology for analyzing and predicting pre-hospital traffic accident medical emergency calls in Chengdu, including data processing and modeling.
Section 3 validates model performance on historical data, highlighting the lightweight LSTNFCL model’s competitive accuracy with computational efficiency.
Section 4 provides an in-depth analysis of the differences between the different models and their applicability scenarios. The last section summarizes the research results of the whole paper, reiterates the importance and practical application value of the research, and proposes possible future research directions.
2. Methods
2.1. Data Preparation
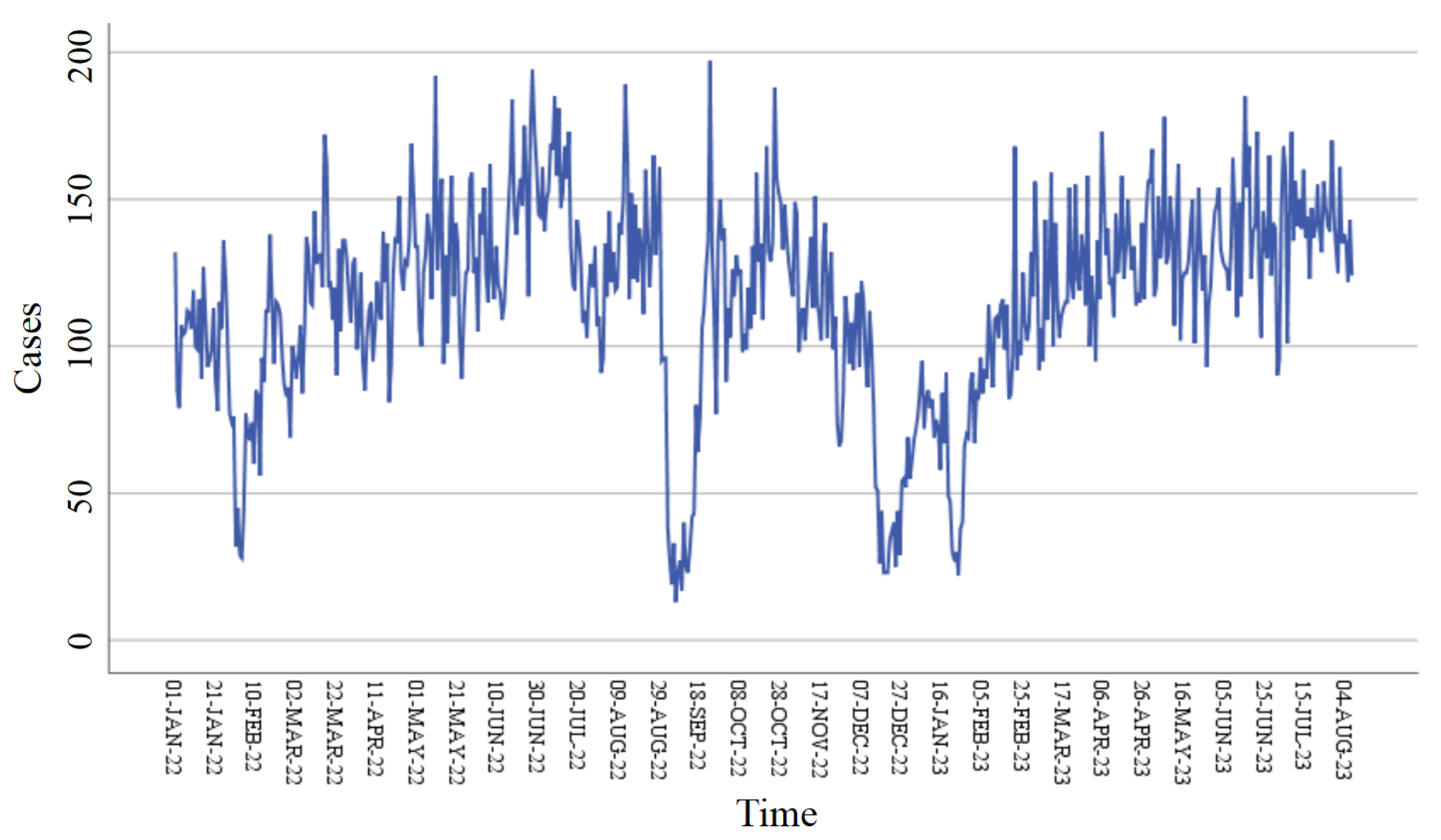
We used pre-hospital medical emergency calls in Chengdu from 1 January 2022 to 31 December 2023, provided by the Chengdu Medical Emergency Center. All data are updated daily. In this study, 730 observations were divided into a training set and a validation set, of which 80% was the training set and the rest (20%) was the test set. The dataset from 1 January 2022 to 6 August 2023 was considered as the training set, and the data from 7 August 2023 to 31 December 2023 was considered as the validation set.
For non-stationary time series, normalization preserves statistical symmetry through linear transformation, while second-order differencing converts asymmetric trends into symmetric and stationary sequences by eliminating trend components. This symmetry transformation is a critical prerequisite for ARIMA modeling.
2.2. ARIMA Model
The ARIMA model is a commonly used non-smooth time series forecasting model, which consists of an autoregressive (AR) model and a sliding average (MA) model. The ARIMA model is generally denoted as ARIMA(p,d,q) (p,d,q are the orders of the AR model, the signal difference and the MA model, respectively), which is an extension of ARMA(p,q). The ARIMA model can only be used for smooth time series, while for the non-smooth time series
, ARIMA transforms
into a smooth time series
by d-order signal differencing, and then fits the smooth time series
with the ARMA(p,q) model, which is the ARMA(p,q) model:
where
and
are autoregressive coefficients and sliding average coefficients, respectively;
is a white noise sequence obeying a normal distribution with mean 0. The modeling process of ARIMA is as follows:
The ADF and KPSS unit root methods are used to test the smoothness of the time series data, respectively.
If the smoothness test is not passed, the time series is converted to a smooth time series by performing a d-order difference.
The models are ranked using the Bayesian information criterion (BIC).
The time series are fitted using a fixed-order model, and the model parameters are estimated using great likelihood estimation.
The autocorrelation of the residuals of the model fit is tested. The closer the residuals are to the white noise distribution, the more fully the useful information in the time series is extracted.
After passing the residual test, the specified ARIMA model can be used for time series forecasting. If the residual test is not passed, the model will be re-ordered.
For the ARIMA model, its symmetry arises from the stationarity requirement enforced through differencing, which assumes invariance in statistical properties under time translation. This symmetry enables ARIMA to model linear temporal patterns but restricts its ability to adapt to non-stationary dynamics. In contrast, the LSTNFCL architecture inherently breaks such symmetry via its gating mechanisms, allowing adaptive learning of time-varying patterns in non-stationary regimes.
2.3. LSTNFCL Model
Recurrent Neural Networks (RNNs) [
23] are a class of neural network structures specialized in processing sequence data, and are characterized by the possibility of introducing recurrent connections to process the temporal information of sequence data. The specific inference process is as follows, and its structure is shown in
Figure 1.
In the above calculation, y is the information output, a is the information input, W is the weight information, and g is the activation function. It is possible to make the information after a certain time propagation also retain the information of the previous period of time, to have the effect of a short time attention mechanism.
However, the traditional RNN structure suffers from the problems of gradient vanishing and gradient explosion, which leads to difficulties in processing long sequence data and capturing long-term dependencies. In order to solve this problem, the Long Short-Term Memory Network (LSTM) [
24] is proposed. The LSTM introduces three key gating structures: input gate, forgetting gate, and output gate, through which the flow of information can be better controlled and long-term dependencies can be captured efficiently, which mitigates the problem of gradient vanishing and gradient exploding and enables LSTM to perform better in dealing with sequential tasks that require long-term memory.
Similar to LSTM, the gated recurrent unit GRU is another structure proposed to solve the gradient problem of the RNN. The GRU [
25] is more simplified compared to LSTM, containing only two gating structures, the update gate and the reset gate, which reduces the number of parameters, while maintaining a better performance performance to a certain extent. Therefore, in some scenarios with high requirements on model size and computational efficiency, the GRU model is usually used to solve the gradient problem of RNN. The specific reasoning of LSTM and the GRU is as follows, and its model structure diagram is shown in
Figure 2 and Equation (
3).
where
f and
i are forgetting gate and input gate functions, respectively;
h is the past information output;
synthesizes the past input information;
O is the final output;
, tanh, and
u are the activation functions; and
W is the weight information. The GRU, which is similar to this one, includes only the update gate
and the reset gate
:
where
W,
b are the weights and biases of each parameter, respectively. The importance of
c,
x is learned, and weight information is obtained by
and
, respectively.
As illustrated in
Figure 3, the LSTNet method [
26] integrates multiple deep learning network structures. It employs a one-dimensional convolutional network to extract data features, followed by an RNN network for temporal feature extraction. Additionally, a GRU structure is embedded within the RNN-skip architecture to capture long-term time series patterns and periodic dependencies. Global attention is implemented via an attention mechanism, while the autoregressive (AR) process is simulated using a linear multilayer perceptron (MLP) through a HighWay module, ensuring the desired output dimensionality.
This paper introduces the LST-Skip model, which combines the LSTM framework with other deep learning architectures and an attention mechanism. This model adopts a structurally symmetric design, enhancing computational efficiency in time series prediction. The symmetry balances the model’s computational load, reduces parameter counts and inference times, and improves generalization capabilities. By capturing bidirectional dependencies in time series data, it ensures balanced forward and backward information flows, mitigating the risk of local optima. Furthermore, the model emphasizes key time points, improving prediction accuracy and leveraging LST-Skip to incorporate prior knowledge of periodicity into the sequence.
Experimental results demonstrate that this model performs exceptionally well in time series forecasting. To address the asymmetry inherent in the original LSTNet model, we propose the LSTNFCL model—a structurally symmetric architecture that offers superior performance and stability compared to LSTNet. The structure of the LSTNFCL model is depicted in
Figure 4.
By optimizing the LSTNet model, we propose the LSTNFCL model, which is a complex neural network architecture designed for time series analysis and forecasting. The model integrates a convolutional layer for feature extraction, an attentional mechanism to enhance feature representation, and a recursive layer to capture temporal dependencies. By combining these components, the LSTNFCL model is able to efficiently integrate information from different branches and, thus, excel in tasks that require spatiotemporal understanding of data. In addition, the model introduces an autoregressive layer to further capture the dynamics in the time series, and finally achieves accurate prediction results through the linear and additive layers.
The LSTNFCL model proposed in this paper decomposes the temporal signal into symmetric and asymmetric components via Conv2Former-CBAM. The GRU layer maintains daily symmetry via reset gates, the LSTM forgetting gates isolate holiday-induced asymmetries, and parallel RNN branching strengthens the stability of short-term patterns. Adaptive residual concatenation dynamically reweights the symmetric/asymmetric features of each layer, and LSTNFCL suppresses overfitting to historical symmetries by suppressing overfitting when dealing with holiday data.
2.4. Autoformer Model
Since Transformer was proposed in 2017, starting as a solution to problems in natural language, the self-attention mechanism makes it possible to consider all positions in the input sequence at the same time. Therefore, it better captures global dependencies and is suitable for modeling entire time series. In addition, the Transformer model can be computed in parallel, thus allowing faster training and inference when dealing with time series of longer lengths. However, for longer time series, the computational cost of the Transformer model becomes very high due to the fact that the autoattention mechanism needs to take into account the information of all the positions, which can lead to an increase in computational complexity with the increase in the length of the sequence.
As shown in
Figure 5, the Autoformer, proposed by Zeng et al. [
27], breaks through the traditional method of sequence decomposition as preprocessing and proposes the decomposition architecture, which is able to decompose more predictable components from complex time patterns.
Based on the theory of stochastic process, the autocorrelation mechanism is proposed to replace the attention mechanism of point-wise connection, to realize series-wise connection and O(nlogn) complexity, and to break the bottleneck of information utilization. The model uses encoder and decoder patterns. The encoder part gradually eliminates the trend term to obtain the time series detection and mainly calculates the period term
S, where
X is a hidden variable. (Remember SeriesDecomp is
, AutoCorrelation is
, and FeedForward is
):
The decoder periodic term is
Autoformer captures temporal symmetry through its global self-attention mechanism and positional encoding, and recognizes periodic patterns by calculating pairwise correlations across all timestamps. However, its static attention matrix tends to overfit historical symmetries while lacking an explicit mechanism to isolate asymmetric events.
2.5. Evaluation of the Prediction Performance
In this article, we use mean absolute error (MAE) and root mean square error (RMSE) to assess the predictive performance of the model; the smaller the value of MAE and RMSE, the better the predictive ability of the model. These equations and other metrics, including BIC (Bayesian information criterion), RSE (relative squared error), RAE (relative absolute error), CORR (correlation coefficient), MAPE (mean absolute percentage error), MSE (mean squared error), and MSPE (mean squared percentage error), are shown below.
where
denotes the predicted value for the
i-th observation,
denotes the (true) value for the
i-th observation,
n denotes the number of samples,
denotes the average of the observations,
denotes the average of the predicted values,
k denotes the number of model parameters, and
denotes the value of the likelihood function.
4. Conclusions
In this study, we collected regular symmetric pre-hospital medical emergency call data from 1 January 2022 to 31 December 2023 in Chengdu City. In this study, we constructed and compared three models: ARIMA (Autoregressive Integrated Moving Average Model), LSTNFCL (Long-Short-Term Network with Conv2Former, CBAM (Convolutional Block Attention Module), and LSTM), and Autoformer. Firstly, the ARIMA(1,2,3) model was selected through statistical methods and BIC (Bayesian information criterion) evaluation. Secondly, by improving the LSTNet (Long and Short-term Time series Network) model, the LSTNFCL model was proposed, which enhances the joint modeling of local features and global temporal dependencies through its self-attention module. At the temporal modeling level, it utilizes complementary gating mechanisms to comprehensively capture multiscale patterns in time series data, while optimized residual linking achieves efficient fusion of multilevel features, and the model has small parameter sizes and computational complexity, making it particularly effective in real-time prediction. Finally, the Autoformer model was used to predict the data results with high accuracy without considering the time cost. The experimental results show that LSTNFCL maintained a very competitive performance and is particularly suitable for real-time prediction scenarios.
According to the minimum MAE (mean absolute error) and RMSE (root mean square error) criteria, Autoformer’s prediction accuracy is better than that of ARIMA and LSTNFCL; however, due to its larger number of parameters and computational requirements, its inference time is longer, which shows its limitation in real-time applications; it is more suitable for deployment on high-performance hardware. In contrast, LSTNFCL, with an MAE of 1.681, an RMSE of 3.301, and a small inference time, achieved competitive performance while maintaining a low computational overhead, making its prediction results valuable for pre-hospital medical emergency systems. Finally, we used the LSTNFCL model to predict the pre-hospital medical emergency call data in each district of Chengdu, providing actionable insights for optimizing the pre-hospital medical emergency response system.
Existing Autoformer models rely on strong a priori assumptions about periodic patterns, which can fail significantly in the face of chaotic or asymmetric events in reality. For example, unexpected events tend to disrupt the periodic structure of time series data, leading to degraded prediction performance. In contrast, the LSTNFCL model proposed in this paper reduces the reliance on strict periodicity by incorporating multiscale modules and attention mechanisms, and is able to dynamically capture local mutations and global trends in non-smooth time series, thus exhibiting stronger robustness in complex scenarios.
Our analysis shows that temporally symmetric patterns of emergency calls, especially recurring daily peaks, enable proactive ambulance pre-positioning, whereas asymmetric surges (e.g., during holidays) require dynamic reallocation.The LSTNFCL model efficiently balances these requirements by maintaining the dual ability to respond cyclically and to adapt to anomalies, offering practical advantages for optimizing planned deployment of emergency medical systems, and its real-time resource allocation provides practical advantages. This work emphasizes the trade-off between computational efficiency and prediction accuracy in time series forecasting, and the LSTNFCL model represents a balanced solution for resource-constrained real-time applications. The experimental data used in this paper only cover a two-year short-term time series sample from a specific region in Chengdu City, which does not adequately capture cross-geographic heterogeneity; second, the model’s ability to predict extreme low-frequency events (e.g., natural disasters) still needs to be verified, as its training data do not contain such extreme cases, and need to be optimized further by combining with an online learning mechanism. Future work could explore the deep integration of spatiotemporal symmetry (e.g., mirrored event distributions) with dynamic timing models, or develop asymmetry-driven multimodal architectures to enhance anomaly detection and adaptation to chaotic scenarios.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}