1. Introduction
The stress–strength model is a widely utilized framework in system reliability analysis, applicable across various fields such as engineering, geology, oceanography, economics, and materials [
1,
2,
3,
4,
5]. Its fundamental principle involves comparing the stress imposed on a system or material with its inherent strength. In the context of the stress–strength model, reliability is defined as the probability that the strength of the system or material exceeds the applied stress under given conditions. The classic stress–strength model was first introduced by Birnbaum [
6]. Since its inception, numerous researchers have extended and refined the model to better suit the needs of different fields and application scenarios [
7,
8,
9]. By employing the stress–strength model, engineers and designers can gain a deeper understanding of how systems or materials perform under external loads, leading to more rational design and optimization. Additionally, this model aids in predicting and preventing potential failure modes, thereby enhancing the safety and reliability of products.
In reliability engineering, the Lomax distribution has a wide range of applications due to its excellent mathematical and physical properties. The Lomax distribution, also known as the Pareto Type-II distribution, was initially proposed by Lomax for the analysis of failure data in economics [
10]. This distribution is particularly suited for datasets that exhibit right-skewed or heavy-tailed characteristics. Over time, with the advancement of scientific research, the Lomax distribution has found applications in various other domains, including reliability engineering [
11], transportation engineering [
12], telegraph [
13], aerospace [
14], and computer science [
15].
In reliability analysis, the mathematical properties of the Lomax distribution are well-suited to reliability scenarios. Most failures are concentrated in the early stage, but there is a small amount of long-tailed data. Therefore, reliability data, such as equipment lifetime and failure time, are usually right-skewed. The right-skewed characteristic of the Lomax distribution can better fit the long-tail phenomenon in actual data. Compared with other distributions commonly used in reliability, the exponential distribution is unable to model aging or early failures, while the Lomax distribution can model aging by adjusting the shape parameter. In addition, the Weibull distribution has insufficient prediction for extreme events, and extreme events need to be modeled using heavy-tailed distributions. The tail of the Lomax distribution decays more slowly than that of the Weibull distribution, so it can better capture extreme risks. The log-normal distribution has a fast tail decay, which may lead to an underestimation of extreme events. In contrast, the Lomax distribution provides a more conservative estimate of reliability. In engineering practice, the physical meanings of the parameters of the Lomax distribution are well-defined, making it suitable for the modeling of complex systems. Moreover, its ability to account for extreme events endows it with greater value in some crucial fields such as aerospace and nuclear power safety.
A significant amount of research has been conducted on the Lomax distribution. Fitrilia A et al. [
16] utilized the E-Bayesian method to estimate the parameters of the Lomax distribution under Type-II right-censored data. Hassan et al. [
17] derived the Bayesian estimates of entropy for the Lomax distribution, along with their corresponding confidence intervals, based on linear exponential, squared error, and precautionary loss functions. Dong G et al. [
18] estimated the Shannon entropy of the Lomax distribution using noninformative priors. Additionally, the Lomax distribution has gradually been applied to stress–strength reliability models. AlEssa L.A. et al. [
19] assumed that the system components follow the Lomax distribution and studied the problem of estimating the distribution parameters of a triple modular redundancy system under step-stress partially accelerated life tests. They employed various estimation methods to analyze the reliability of the system and mean residual lifetime. Hassan M.A. [
20] performed statistical inference on reliability for two mutually independent stress and strength variables, assuming a common scale parameter, and derived various point and interval estimates for reliability. Hamad A.M. et al. [
21] investigated the stress–strength reliability estimation for the Restricted Exponentiated Lomax distribution under two scenarios when the stress is Y: one scenario involves a single strength
, and the other involves dual strengths
and
. In these research findings on stress–strength models of the Lomax distribution, [
19] discusses the stress–strength model for k-out-of-n systems, while [
20,
21] both consider the entire system as a whole. Therefore, from the analysis of existing research, it is discovered that the issue of reliability assessment for stress–strength models of the Lomax distribution in multi-component complex systems with diverse component types has been barely addressed. As a probability distribution, the Lomax distribution has a long-tail characteristic and can effectively describe extreme events, which is particularly important in reliability engineering. However, its application in complex systems has not been fully explored, limiting its potential in stress–strength reliability assessment. Therefore, researching the application of the Lomax distribution in complex systems can enrich the methodology of reliability assessment.
System signature is an effective tool for assessing system reliability, initially introduced by Samaniego F.J. in 1985, and its influence grew substantially with the release of his book “
System Signatures and Their Applications in Engineering Reliability” [
22]. However, the signature theory requires that the components of the system be independent and identically distributed. To address this, Coolen et al. [
23] introduced the concept of survival signature for systems with multiple types of components. This significantly reduces the need for prior information about the system in reliability studies, making it more applicable to practical scenarios. The survival signature theory has significant advantages in the reliability assessment of complex systems. Compared with the methods based on probability statistics [
24], it reduces the dependence on the component life distribution and focuses more on the essence of the system structure. In contrast to machine learning methods [
25], it has stronger interpretability and lower data requirements. When compared with system dynamics methods [
26], it is simpler and more efficient in calculations and directly links the system structure with reliability. In comparison with multi-attribute decision-making methods [
27], it focuses on the core assessment of reliability and provides clear system reliability indicators. These features make it more practical and efficient in the reliability analysis of complex systems. Bai X et al. [
28] conducted statistical inference on the stress–strength reliability of a system with bounded strength, using the survival signature theory for a three-parameter exponentiated Weibull distribution with unequal scale and shape parameters. Bai X et al. [
29] proposed a new stress–strength model for multi-state systems composed of multiple types of multi-state components. In the case where all types of components are exposed to the same set of dependent stresses, they used an improved generalized survival signature to perform statistical inference on stress–strength reliability. Jana N et al. [
30], under progressive Type-II censoring, investigated the reliability of a stress-strength system with multiple types of components using the signature approach for a two-parameter inverse Weibull distribution, deriving various point estimators and confidence intervals. Liu Y et al. [
31] studied the stress–strength reliability of multi-state systems based on generalized survival signatures and derived the expressions for stress–strength reliability in both discrete and continuous cases. However, in practical problems, the strength of some components and systems can change over time, and the stress acting on components or systems is a cumulative process. Yet, an analysis of many current research findings from [
28] to [
31] reveals that they are all static stress–strength reliability models. Research on dynamic stress–strength reliability models for systems with multiple types of components has not been seen. However, in engineering practice, the stress and strength of many components will degrade over time due to factors such as material fatigue and environmental corrosion. Static models cannot capture such dynamic changes, which may lead to inaccurate reliability assessment results and affect the safety and reliability of the system. Therefore, extending the stress–strength model to a dynamic one can more realistically reflect the actual operating conditions of components and improve the accuracy and practicality of the assessment.
In conclusion, this paper has two main research objectives. One is to discuss the estimation of the model parameters and the stress–strength reliability of complex multi-component systems where both the stress and strength variables follow the Lomax distribution. The other is to introduce the time variable into the static stress–strength model and complete the expansion of the model from static to dynamic.
Consequently, in response to the first research objective, the content of the study is that when the stress and strength variables corresponding to different types of components in the system all follow the Lomax distribution, where the Lomax distribution parameters vary across different types of components, the stress–strength model of such complex systems is derived utilizing the survival signature theory. Then, based on different parameter estimation methods, the parameter estimation results for each type of component and the estimates of stress–strength reliability are provided, and the accuracies of these estimation methods are compared. In addition, the sensitivity of the model to each parameter and sample size under different parameter estimation methods needs to be analyzed and compared.
The second research content of this paper is to solve the problem of dynamic stress-strength estimation for the system. By leveraging the relevant theories of stochastic processes, the time variable is introduced into the stress–strength model derived from the first research question, and an estimation algorithm for the model is presented. Subsequently, the accuracy of the algorithm is determined by comparing it with the static model, and the sensitivity of the model to hyperparameters is analyzed.
2. Model Description
Assume that the system has
types of components, where
.
represents the number of components of type
, where
and
. Let the state vector of the system be defined as
, where
.
represents the state of the
th component of type
, where
indicates that the
th component of type
has failed, and
indicates that the
th component is functioning.
represents the number of components of type
that are in the working state, where
.
is the structure function of the system, with
indicating that the system is operational and
otherwise. The survival signature of the system,
, is defined as the probability that the system is functioning, given that, for each type
,
out of
components are functional. It can be formulated as follows:
where
represents the set of all state vectors for the whole system at which
for
[
27]. In Equation (1),
calculates the total number of all possible combinations when there are
working components among the components of types
respectively. In the classical probability model, it corresponds to the total number of samples.
calculates the number of combinations that enable the system to be in a normal operating state. In the classical probability model, it corresponds to the number of samples of the event “the system is in an operating state”. Therefore, Equation (1) represents the probability of the event “the system is in an operating state”.
Within the system, the strength variables of the various components are mutually independent, the stress variables experienced by each component are independently distributed, and the stress and strength variables are also independent of each other. All the strength variables of the components and the stress variables they experience follow the Lomax distribution. If random variable
follows the Lomax distribution [
32], its probability density function (pdf) can be expressed as follows:
the cumulative distribution function (CDF) can be depicted as follows:
where
is the shape parameter and
is the scale parameter, denoted as
.
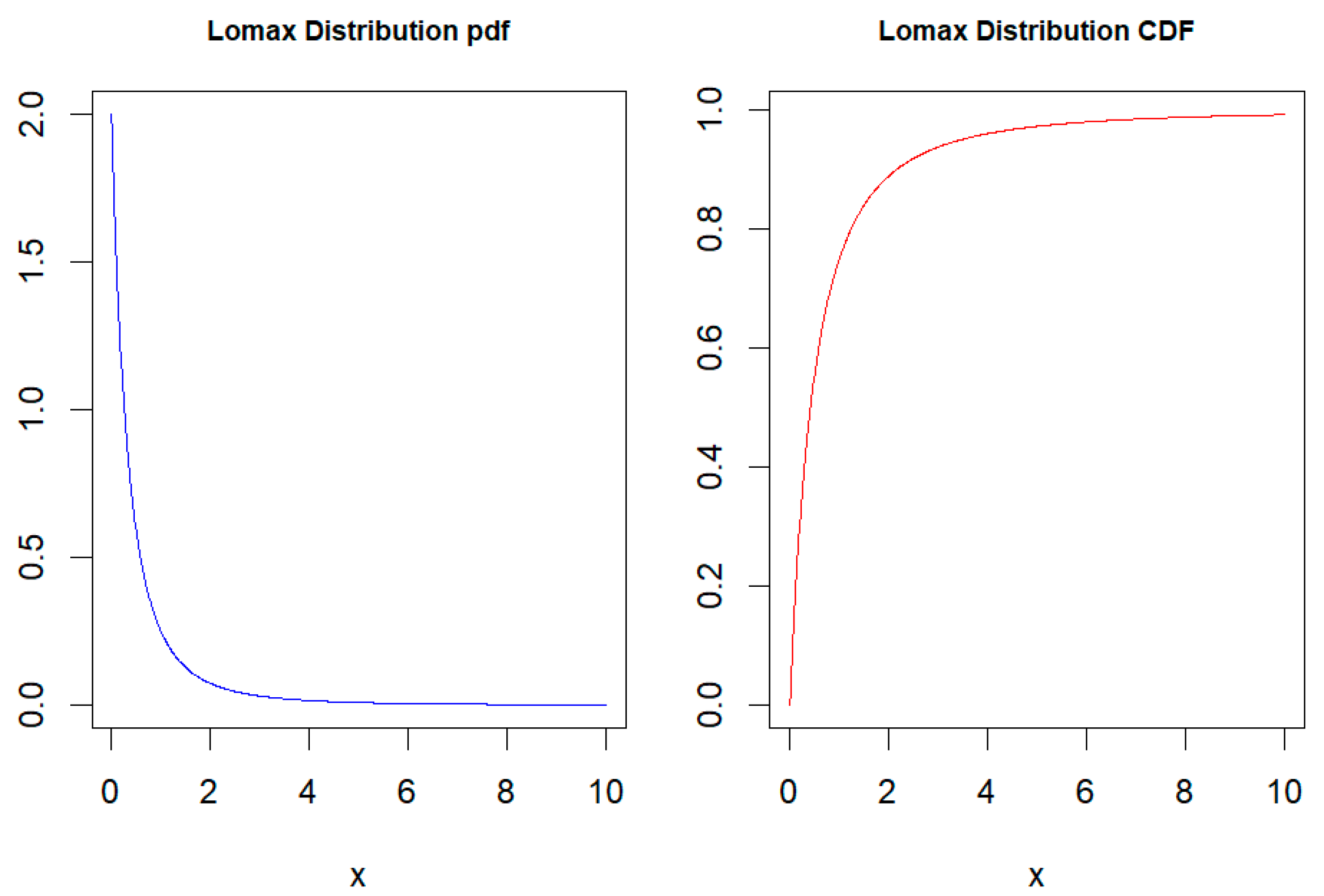
Figure 1 shows the pdf and CDF of
. From the figure, it can be seen that the Lomax distribution exhibits right-skewness and heavy-tailed characteristics.
Let the random variables
and
represent the strength and the stress endured by the components of type
. From the assumption of the independence between stress variables and strength variables, it can be known that
and
are independent of each other. Given that the strength variable
, where the pdf denoted as
and the CDF is denoted as
. Similarly, the stress variable
, with its pdf and CDF denoted as
and
, respectively. Here,
is the common scale parameter,
and
are the shape parameters corresponding to the strength and stress variables, respectively, and all these parameters are unknown.
represents the number of components of type
that satisfy the condition
, where
. Therefore, the stress–strength reliability of the system can be defined as follows:
where
[
33].
From the distribution types of
and
, we can infer that
let
,
is derived as follows:
substituting (5) into (4), the stress–strength reliability is expressed as follows:
6. Numerical Experiment and Results Analysis
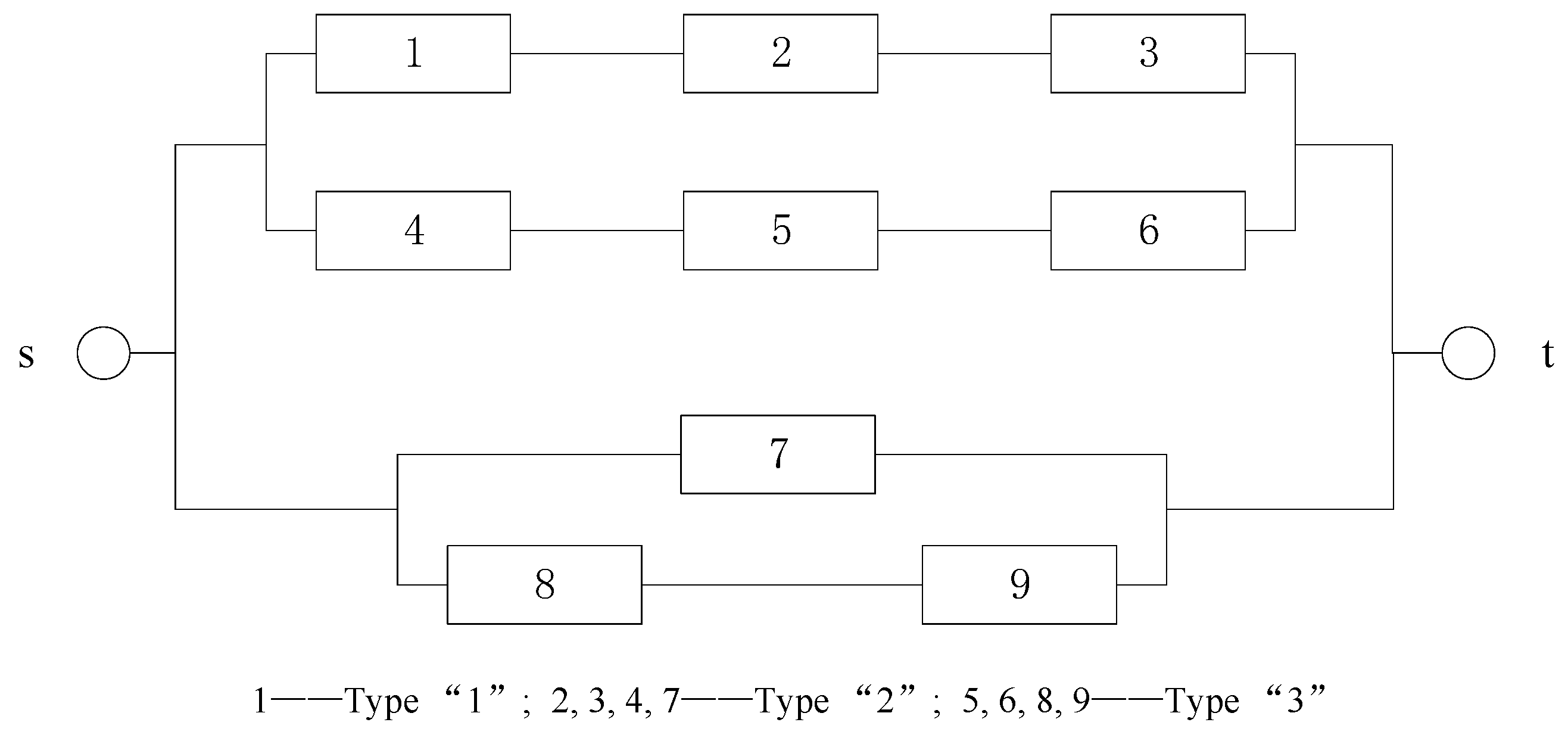
In this section, this study examines the performance of different estimation methods through simulation. It then takes into account a system with nine components, as shown in
Figure 2. The system components are grouped into three types, with component “1” being the first type, the second type including components “2, 3, 4, 7”, and the third type including components “5, 6, 8, 9”.
Table A1,
Table A2,
Table A3,
Table A4,
Table A5,
Table A6,
Table A7 and
Table A8 are all long tables and are presented in the
Appendix A.
The calculation of the system survival signature is implemented using the ReliabilityTheory package in R language.
Table A1 represents the survival signature of the system in
Figure 2. For example, when the first type of component fails (i.e., “1” fails), one out of the second type of components (“2, 3, 4, 7”) are operational, and three out of the third type of components (“5, 6, 8, 9”) are operational, the survival signature of the system
.
6.1. Parameters Estimation
Let and be independent random numbers from . Given the values of parameters and , the inverse transform method can be used to generate and random numbers that follow the Lomax distribution (where ). It is the case that various estimates were calculated under small, medium, and large sample sizes, and the control variable method was used to determine how these estimates change with variations in the parameters and , or with changes in sample size. The above steps were carried out 100 times to obtain the mean and average relative error of various point estimates.
Therefore, three groups of control experiments were set up to analyze the effects of parameter variations on model estimation. Within each group, four subgroup control experiments were conducted to examine how different values of stress and strength data impact the reliability estimation. Since the stress–strength reliability estimation Formula (6) was independent of , it was fixed while and were allowed to vary in order to investigate their impact on the stress–strength reliability. In the first set of experiments, the parameters for three different types of components were set as follows: , and In the second set of experiments, the parameters were adjusted to: and . The shape parameters of the stress variables and the common scale parameters (for were kept constant to study the effects of increasing the shape parameters of the strength variables on the estimation results and errors across different sample sizes. Similarly, in the third set of experiments, the parameters were set as follows: and . Compared to the first set of experiments, this set up effectively keeps the shape parameters of the strength variables and the common scale parameters constant, allowing for the study of how increasing the shape parameters of the stress variables influences the estimation results and errors across various sample sizes.
6.1.1. Maximum Likelihood Estimation and Bootstrap-p Confidence Interval
Table A2 provides the results of the maximum likelihood estimation. The first two sets of experimental data indicate that, when
and
were held constant, an increase in the parameter
results in a decrease in system reliability. Similarly, the results from the first and third sets of experiments demonstrate that, when
and
were kept constant, an increase in the parameter
leads to an increase in the system reliability. The change in sample size has a slight impact on the estimation of reliability, and its effect is not very significant. This is reflected in all three sets of experiments in
Table A2. For instance, when the sample sizes
increases from
to
, doubling the sample size, the stress–strength reliability of the experiments changes only slightly from
to
. However, this slight variation does not exclude the influence of random simulation errors on the experimental results. Overall, the increase in sample size shows a minor and insignificant effect on system reliability. Furthermore, compared to the first and second sets of experiments, it was evident that when the shape parameters
of the strength variables increase, the estimated reliability of stress–strength decreases. Evidently, this conclusion can also be analyzed and derived from the monotonicity of the function in Equation (6). Similarly, when compared to the first and third sets of experiments, an increase in the shape parameters
of the stress variables leads to an increase in the estimated reliability. However, this conclusion cannot be analyzed or derived based on the monotonicity of the function in Equation (6). The shape parameters of the strength variables and the stress variables play opposite roles in the estimation of reliability, which allows us to more accurately predict and adjust the reliability performance of systems.
The average relative errors of the maximum likelihood estimation are presented in
Table A3, calculated using formula
, where
and
, while
represents the estimate values of
and
. Analyzing the data presented in
Table A3, it is evident that, with exceptions for certain data points that are impacted by random simulations, the average relative error for most parameters tends to decrease as the sample size increases. Moreover, by ignoring the individual effects of random simulations, it is clear that with a fixed sample size, increasing the shape parameters of either the strength variables or the stress variables lead to a reduction in the relative error of reliability estimates. Notably, increasing the shape parameters of the stress variables significantly reduces the relative error, often bringing it to a very low level.
Subsequently, the 95% Bootstrap confidence intervals were calculated based on the maximum likelihood estimates of each parameter.
Table A4 shows the average confidence intervals obtained by running Algorithm 2 for 1000 iterations, and based on these, the average length of the confidence intervals and the average coverage rate were calculated. The experimental results indicate that the Bootstrap method achieves a high coverage rate, all exceeding 85%.
6.1.2. Maximum Spacing Estimation in Point Estimation
Table A5,
Table A6 and
Table A7 present the results of the maximum spacing estimation for all parameters and the stress strength reliability
. During the calculation process, the L-BFGS-B algorithm was employed to solve the nonlinear system of Equation (15). The objective function was set as the sum of the squares of the partial derivatives, and the goal was to minimize this function to find the roots of the system of equations. In the optimization process, the lower bounds for the parameters
,
, and
were all set to 0.01, and the upper bounds were set to 5. Through iterative loops, the MSPE for all parameters and
were obtained and shown in
Table A5, the mean relative error in
Table A6, and the iterative error of the system of equations in
Table A7.
From
Table A5, it can be seen that, apart from the uncertainties brought by individual random simulations, the estimation results of most parameters achieve closer to the true values as the sample size increases. The same conclusion can also be drawn from
Table A6, which shows that the relative estimation error of parameters decreases as the sample size increases. Furthermore, from the three sets of experiments in
Table A5 and
Table A6, we can observe that when the sample size
increases from
to
or
, whether it is an increase in the sample size of the stress variables or an increase in the sample size of the strength variables, both contribute to reducing the estimation error of the parameters. Furthermore, the stress strength reliability decreases as the shape parameter
of the strength variable increases, and increases as the shape parameter
of the stress variable increases. This conclusion is consistent with the maximum likelihood estimation, and it can also be reached by conducting a monotonicity analysis on Equation (6). Comparing
Table A6 with
Table A3, it is found that, overall, the average relative error of the maximum likelihood estimation is smaller than that of MSPE.
Table A7 presents the verification results obtained by substituting the MSPE values of the parameters from
Table A5 into equation set (15). All calculation results are below 0.2, with 96% of them being less than 0.09 and nearly 70% below 0.009. This suggests that the computational outcomes are highly accurate.
6.1.3. Bayesian Estimation and 95% HPD Confidence Interval
Table A8 presents the results of Bayesian estimation, which includes the estimated values of the stress–strength reliability
, the bias and average relative error of the Bayesian estimates, and the last two columns provide the lower and upper bounds of the 95% HPD confidence interval.
In Bayesian estimation, parameters
and
of the gamma prior were set to 1, where
. The algorithm was iterated 100 times, and the average values were calculated to obtain the Bayesian average estimate of
, along with its bias and average relative error. The experimental results show that the bias in the first and third sets of experiments is relatively small, all below 0.05, while the bias in the second set of experiments is larger, ranging from 0.1 to 0.13. Therefore, it can be concluded that, when holding other parameters constant, the accuracy of Bayesian estimation decreases as the shape parameters
of the strength variables increase. The bias of Bayesian estimation is relatively sensitive to changes in parameters. By comparing these three groups of experiments, it can be found that when
increases, the bias significantly increases, indicating that the estimated values are larger. When
increases, the bias significantly decreases and is entirely negative, indicating that the estimated values are smaller. In addition, the results in
Table A8 indicate that, as the sample size increases, the accuracy of Bayesian estimation gradually improves, with average relative error decreasing, and the Highest Posterior Density interval also becoming narrower. Different parameter settings have an impact on the estimation results, but the general trend is that the larger the sample size, the more reliable the estimation results become.
In conclusion, regarding estimation accuracy, the results indicate that
. This suggests that the maximum likelihood estimation yields the highest precision, followed by the maximum spacing estimation, and lastly, the Bayesian estimation. This result is due to the combined effects of several factors, including differences in sample size, the choice of prior information, computational complexity, and system structure. In complex systems with diverse system types, when the same prior distribution is applied to different types of components, it will affect the estimation accuracy of the model. However, as the sample size increases, the influence of the prior distribution on the estimation results will become smaller and smaller. It can also be seen from
Table A8 that as the sample size increases, the average relative error gradually decreases. Furthermore, Bayesian estimation involves complex calculations, such as MCMC methods, which can converge too slowly with large sample sizes. In contrast, maximum likelihood estimation and maximum spacing estimation do not rely on prior information and perform more stably with larger sample sizes.
6.2. Dynamic Stress–Strength Reliability Estimation
Subsequently, the maximum likelihood estimation results of each parameter were utilized to verify the dynamic stress–strength reliability model proposed in
Section 5. For the parameters in models (23) and (25), the MLE results from the first set of experiments in
Table A2 were employed to verify the dynamic model which was presented in
Section 5, where
,
, and
2.0053).
Under the action of cyclic stresses, the unit degradation amounts of the strength variables for different types of components are taken as
. The first set of parameters estimated from
Table A2 was used for simulation experiments. Then, the first set of parameters was substituted into Equation (23), and Algorithm 4 was applied to estimate the generalized integral in Equation (24).
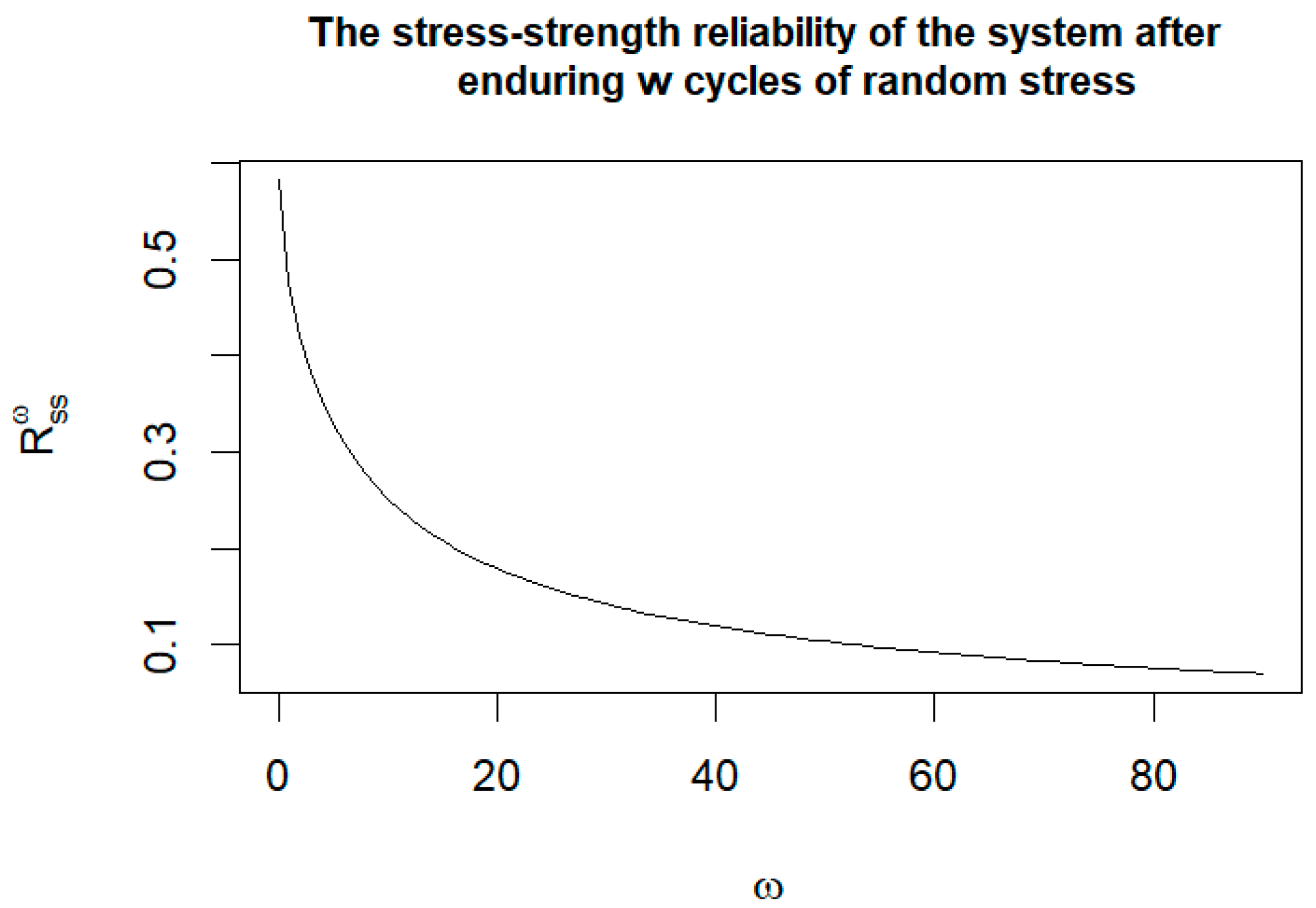
Figure 3 illustrates the reliability varying with cyclic stress, demonstrating that the stress–strength reliability of the system decreases gradually as the number of cycles increases. According to the definition of reliability, when the stress increases, the system reliability will gradually decrease. The experimental results in
Figure 3 are consistent with the definition, which indicates that Algorithm 4 is feasible and accurate in the approximate estimation of the stress–strength reliability.
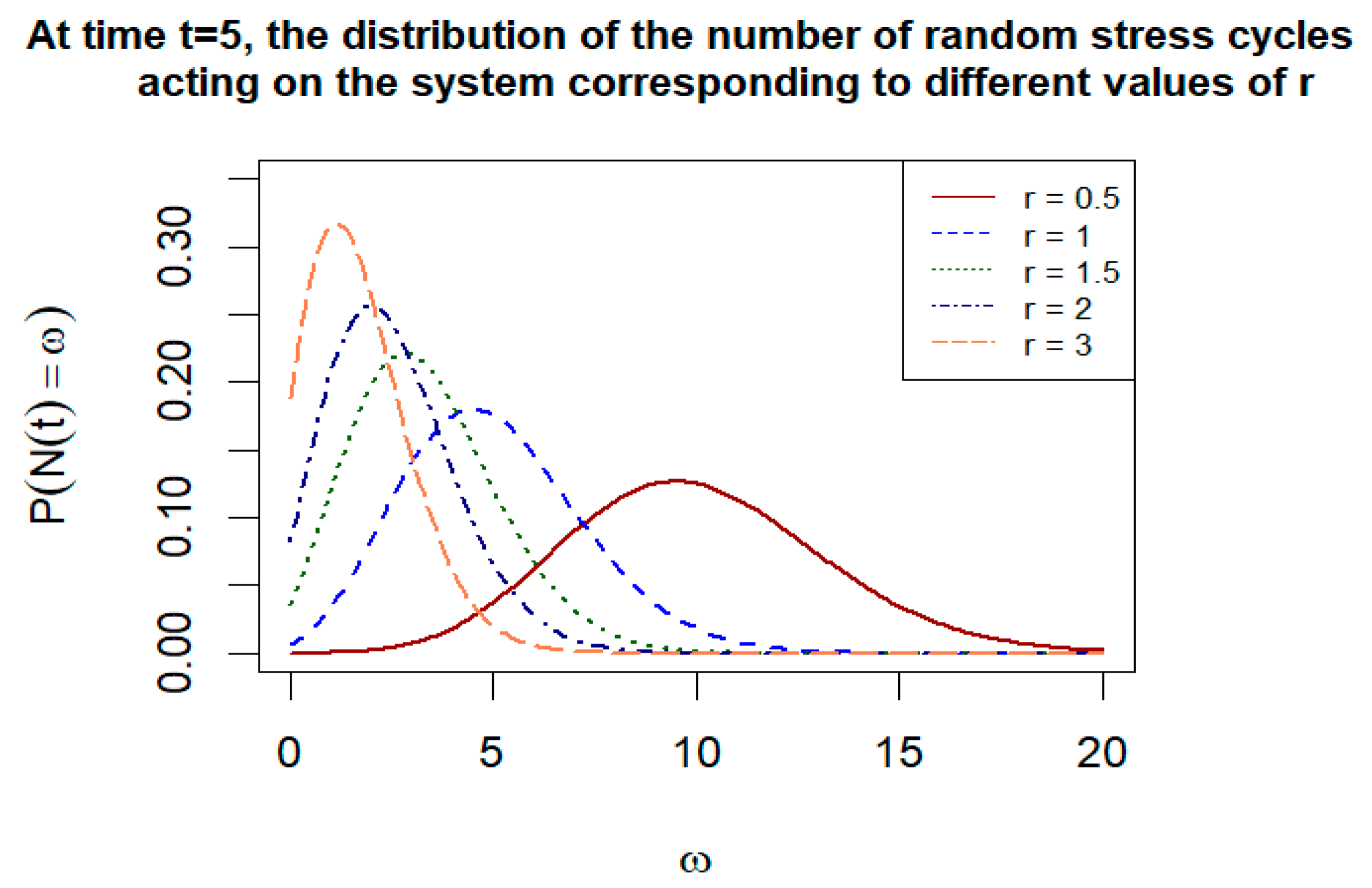
The number of cyclic stresses follows a Poisson distribution with parameter
. Let
, and
take the values
and
. The probability distribution of the number of cycles
within the time interval
is shown in
Figure 4. From the results, we can see that as
increases, the probability distribution gradually changes from a symmetric distribution to a right-skewed distribution. The same conclusion can be obtained by analyzing the meaning of Equation (22). When
is fixed and
increases, the probability of
stress cycles occurring within the time period
will also decrease accordingly.
is equivalent to reducing the length of the time interval. The larger
is, the smaller the time interval
will be. Obviously, there will not be too many cyclic stresses within a smaller time period.
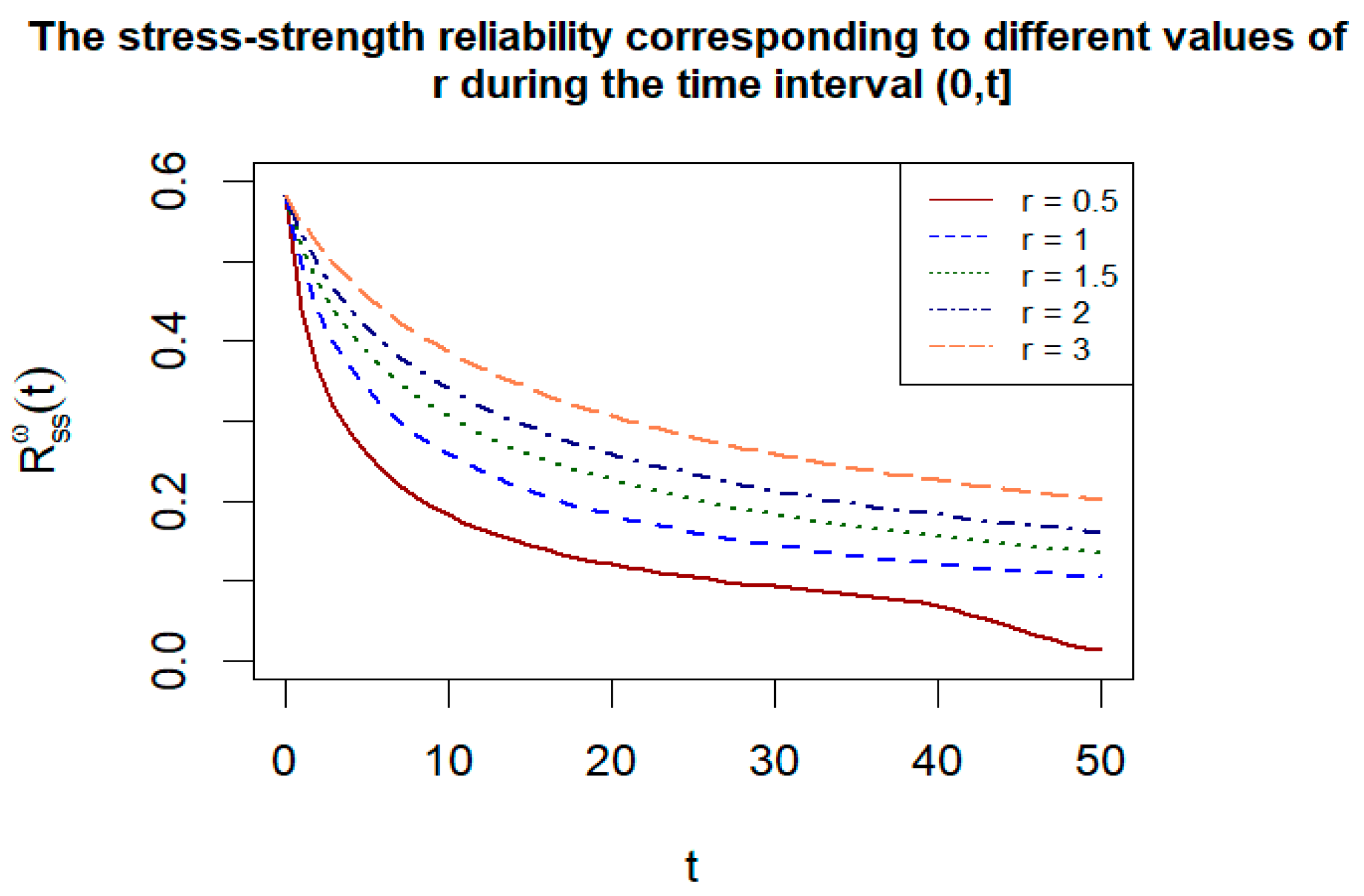
Figure 5 shows the dynamic stress–strength reliability of the system over the time interval
. For different values of
, specifically
and
, the reliability values were approximately calculated using Algorithm 4. From the figure, it can be observed that the larger the value of
, the more slowly the system reliability decays over time. The conclusions of
Figure 4 and
Figure 5 are consistent. The larger the value of
, the shorter the transformed time interval
is. Therefore, the probability of
stress cycles occurring is also smaller. In the stress–strength reliability model, at the same moment, when the strength is fixed, the smaller the stress, the higher the reliability. In addition, when
, the result of the dynamic reliability model (25) becomes that of the static model. The estimated value approximately obtained according to Algorithm 4 is 0.5823. Compared with the estimated result of 0.6287 in
Table A2, the error is 0.0464. The error is relatively small, indicating that the result is fairly accurate.
Through the above simulation experiments, the problem of system reliability estimation under periodic stress was solved. From
Figure 3 and
Figure 5, it can be seen that whether the number of stress cycles increases or the time interval increases, the system reliability gradually decreases, which is also the principle of the reliability model.
6.3. Sensitivity Analysis
6.3.1. Sensitivity Analysis of Stress–Strength Reliability to the Parameters of the Lomax Distribution
Next, from a quantitative analysis perspective, the extent to which the stress–strength reliability estimates are affected when parameters
and
undergo sequential changes under the three parameter estimation methods will be systematically examined. Through this process, the underlying patterns regarding how the variations in these parameters impact the reliability estimation results are aimed to be uncovered. The parameters were set as follows:
, and
. The model in Equation (6) is independent of the parameter
, so the sensitivity of
is unnecessary. In each group of experiments, all other parameters were held constant. The fluctuations in the system stress–strength reliability were analyzed successively as parameters
,
, and
were adjusted individually.
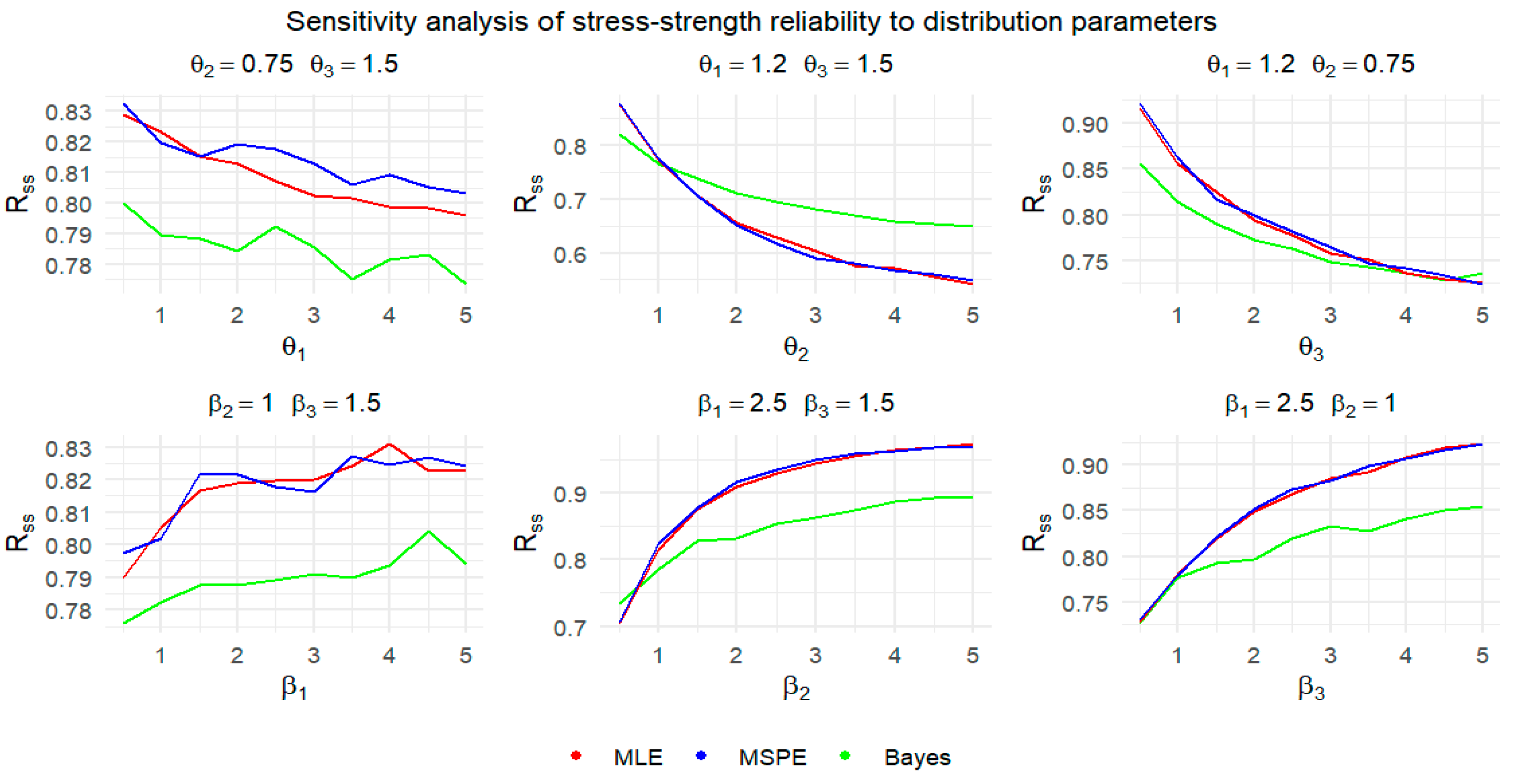
Figure 6 depicts the shifts in reliability when the aforementioned six parameters are tweaked successively under three different estimation methods.
From the commonalities of the above six sub-figures in
Figure 6, the larger the shape parameter
of the strength variable, the lower the reliability. The larger the shape parameter
of the stress variable, the higher the reliability. Numerically, the changes in parameters
and
have the least impact on the estimated reliability value. When
,
and
(or
,
, and
) change from 0.5 to 5, the ranges of change in reliability are approximately 0.027–0.041, 0.159–0.334, and 0.127–0.197, respectively. The existence of redundant design in the system may lead to a smaller impact of changes in parameters
and
on reliability. Obviously, when Type 1 only contains component “1”, the normal operation of this component does not have a significant impact on the system reliability. However, whether the components in Type 2 and Type 3 are faulty and the number of faulty components will significantly affect the reliability estimation. This also results in the stress–strength reliability being relatively significantly affected by the changes in these parameters such as
,
,
, and
. From the perspective of parameter estimation methods,
Figure 6 shows that the results of MLE and MSPE are very close, while the results of the Bayesian estimation differ significantly from those of the above two estimation methods under certain circumstances. As these parameters increase, the results of the Bayesian estimation begin to diverge from those of the other two methods. Overall, the trend indicates that the variation range of the Bayesian estimation is relatively smoother compared to the other two methods. This is because the MLE is highly sensitive to the distribution assumptions of the data, while the MSPE is very sensitive to extreme values in the data. The results of these two parameter estimation methods can fluctuate significantly due to changes in the data distribution. The introduction of prior information can smooth out the changes in parameter estimation. Therefore, Bayesian estimation may exhibit lower sensitivity when parameters change.
6.3.2. Sensitivity Analysis of Stress–Strength Reliability to Sample Size
In addition, in
Section 6.1, the estimation errors of the model were analyzed by setting the sample sizes of the stress and strength variables of each type of component as (10, 10, 40, 40, 40, 40), (10, 15, 40, 60, 40, 60), (15, 10, 60, 40, 60, 40), and (20, 20, 80, 80, 80, 80), respectively. The preliminary analysis results show that MLE and MSPE are not very sensitive to the changes in sample size, though there is also a certain degree of reduction. In contrast, the estimation error of Bayesian estimation decreases significantly as the sample size increases. However, the values of these sample sizes are not comprehensive enough. Next, the sample size will be considered as an uncertain factor, and the impacts of its different values on the estimation results of the stress–strength reliability model will be analyzed in detail. The parameters of Lomax distribution were set as follows:
, and
.
In the following, the changes in the average relative error of the stress–strength reliability model will be analyzed when the sample sizes of stress and strength variables change from (5, 5, 20, 20, 20, 20) to (30, 30, 120, 120, 120, 120), respectively. In the system shown in
Figure 2, the number of components of types “2” and “3” is four times that of type “1”. Therefore, during the process of sample size analysis, the sample sizes of types “2” and “3” are also set to be four times that of type “1”.
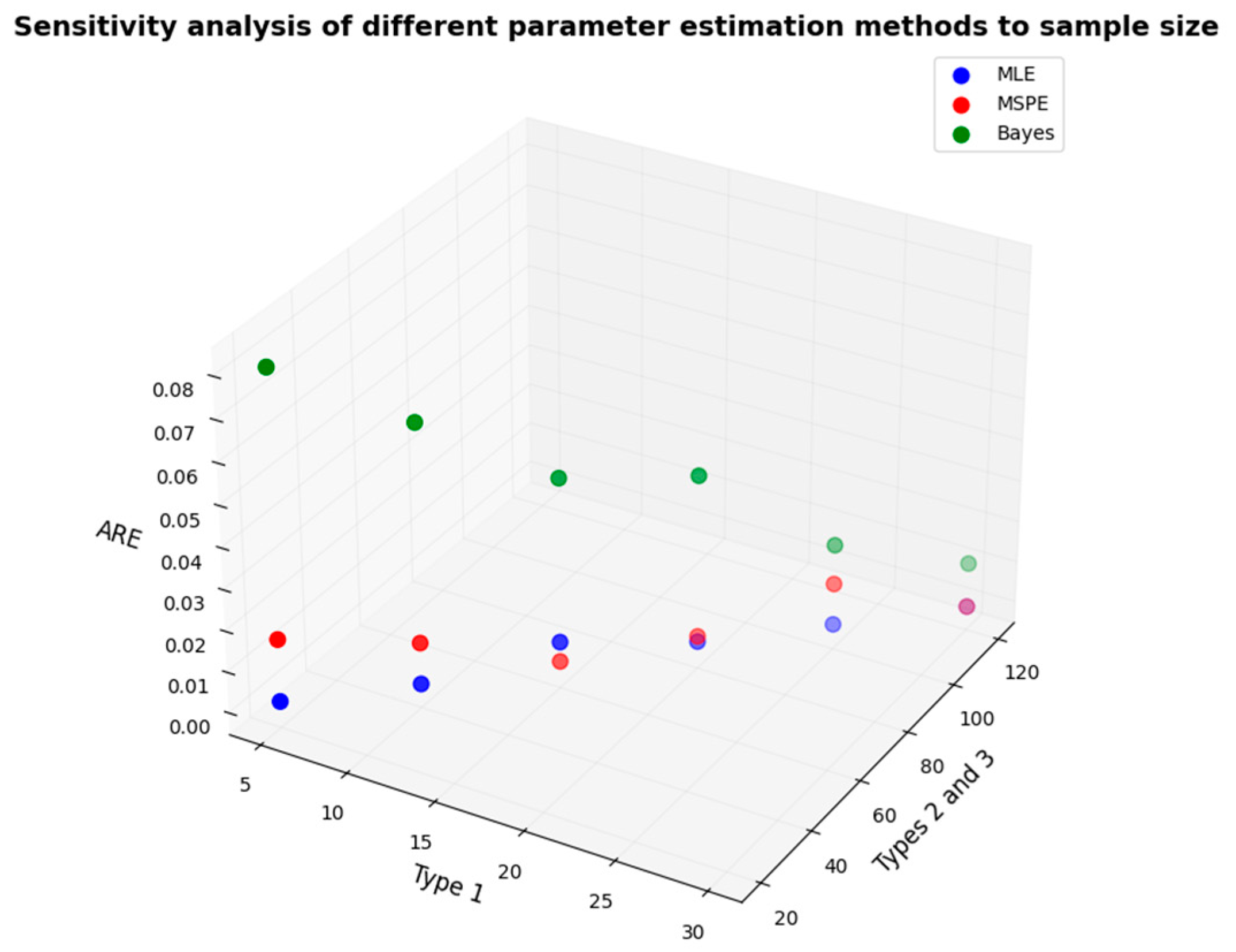
Figure 7 shows the results of the sensitivity analysis of the estimation errors of the stress–strength model to the sample size under three estimation methods. It can be seen from
Figure 7 that as the sample size increases, the average relative errors of these three estimation methods all decrease. Among them, the error of MLE is the smallest, followed by that of MSPE. The accuracy of these two estimation methods has already shown excellent performance in the case of small sample sizes. However, the Bayesian estimation is affected by the prior distribution when the sample size is small, and its error is larger compared with the first two estimation methods. But as the sample size increases, the error gradually decreases, and it shows good estimation accuracy in the case of large sample sizes.
6.3.3. Sensitivity Analysis of the Dynamic Stress–Strength Model to the Hyperparameters of Variable Degradation
In the following, the impact of changes in the individual degradation amounts and of the strength variables of different types of components on the stress–strength reliability under cyclic stress will be analyzed.
In each experimental group, the system undergoes five cycles of stress application. Then, through the method of controlled variables, the variations in stress–strength reliability with respect to
and
were analyzed. The parameter estimation results of the MLE are used, and the results corresponding to the fourth sample size in the first set of experiments in
Table A2 are selected for analysis. The parameters were set as follows:
, (
, and
. The findings are illustrated in
Figure 8.
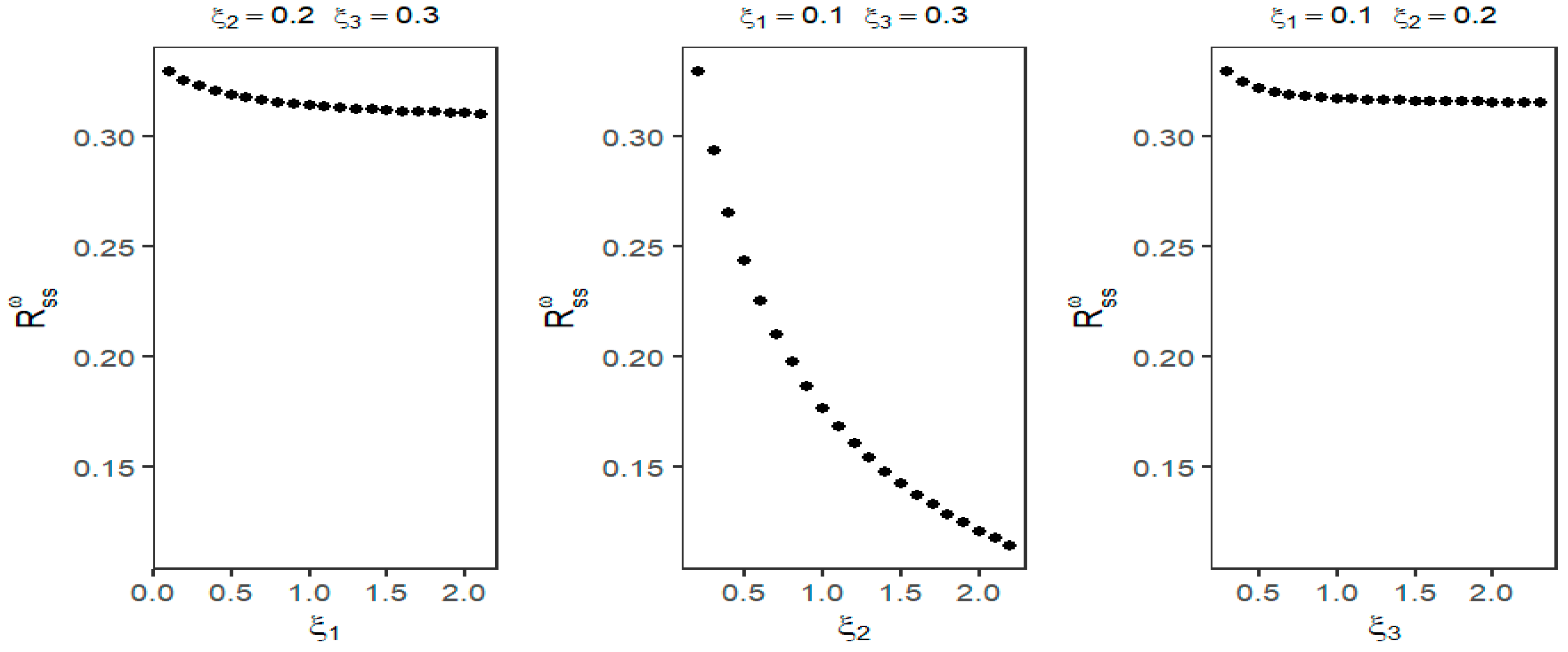
From
Figure 8, it can be seen that as
, and
increase, the reliability gradually decreases. Apparently, this conclusion is easy to explain. Obviously, when the unit degradation amounts of the strength variables increase, the probability that the strength exceeds the stress under the same stress decreases, leading to a lower system reliability. The change of
has the most significant impact on the reliability. The impacts of the changes of
and
on the reliability are less significant than those of
. The reason for this result is still related to the system structure in
Figure 2.
is the unit degradation amount of the strength variable corresponding to component type “2”. From the perspective of the importance of different types of components, components of type “2” have the most significant impact on the change in the system reliability.
7. Conclusions
This paper mainly solves two core problems. One is that for systems where both stress and strength variables follow the Lomax distribution, it extends the traditional stress–strength reliability model, which is usually applied to single-component types or systems with relatively simple structures, to complex multi-component systems, so as to enrich the research on reliability theory. The other is to introduce the time variable into the traditional static stress–strength model and expand it into a dynamic stress–strength model that is more suitable for practical needs.
Regarding the first question, let the strength and stress variables of each type of component follow the Lomax distribution. Assuming that the scale parameters of the strength and stress variables are identical, the stress–strength reliability model is derived based on survival signature theory. Next, various point estimates were formulated, including the MLE, the MSPE, and the Bayesian estimate, for the parameters and the reliability model. Additionally, the 95% Bootstrap-p confidence interval for the MLE and the HPD confidence interval for the Bayesian estimate using the MCMC algorithm were provided. Finally, a numerical experiment on a system consisting of nine components across three different types was performed and the average relative error of various estimation methods was calculated. Finally, the sensitivities of the three estimation methods to parameter changes and sample size, as well as the sensitivity of the dynamic stress–strength model to the unit degradation amount of strength variables, were discussed, respectively. Moreover, the reasons behind these results were analyzed from the perspectives of system structure and estimation methods. The results show that MLE has the highest estimation accuracy, followed by MSPE. Moreover, these two estimation methods can achieve relatively high estimation accuracy even with a small sample size. For example, when the sample sizes are set as (5, 5, 20, 20, 20, 20), the average relative error of MLE is only 0.1%, that of MSPE is 1.62%, while the error of Bayesian estimation is 8.05%. The accuracy of Bayesian estimation is lower than that of the previous two methods. On the one hand, when the sample size is small, Bayesian estimation is easily affected by the prior distribution. On the other hand, Bayesian estimation requires calculating the posterior distribution, and in many practical problems, the form of the posterior distribution can be very complex. For instance, it is quite difficult to calculate Equation (17) in this paper accurately. Usually, numerical methods are needed to obtain approximate solutions. For example, Algorithm 1 uses the Markov Chain Monte Carlo method for solving. These methods will introduce calculation errors, and the convergence and stability of the calculation process will also affect the estimation accuracy. In contrast, MLE usually only needs to find the maximum value of the likelihood function, and MSPE determines the classification boundary by optimizing a convex function. Its calculation process is relatively simple and straightforward, and is less affected by calculation errors. As the sample size increases, the average relative error of Bayesian estimation gradually decreases. When the sample size is (30, 30, 120, 120, 120, 120), the average relative error of the model drops to 1.12%. Therefore, in a large-sample environment, for the stress–strength model, Bayesian estimation is still a good estimation method.
Regarding the second question, the Poisson process is used to describe the degradation process of the stress variables over time. The change process of the strength variables over time is achieved by introducing hyperparameters , where , which are used to describe the unit degradation amount of the strength variables under the action of periodic stress, thus also associating them with the time variable. By applying different periodic random stresses to various types of components, the dynamic stress–strength reliability model of the system that changes over time is derived, and an approximate calculation algorithm for this model is provided through Algorithm 4. In addition, the feasibility and accuracy of the dynamic stress–strength reliability model are verified through this system, thus solving Problem 2. Substitute a set of results from the MLE into the dynamic stress–strength reliability model. By comparing it with the static model at the moment of , the estimated error is 0.0464, which is relatively small. Therefore, the model has a relatively high accuracy rate. In the sensitivity analysis, affected by the system structure, the parameters corresponding to different types of components have different impacts on the stress–strength reliability. Influenced by the system redundancy design and the importance of each type of component in the system, changes in each parameter among the stress variable, strength variable, and the unit degradation amount of the strength variable of type “1” components have the least impact on the reliability. Changes in these parameters of type “2” and “3” components have the greatest impact on the reliability. The estimation results of the three estimation methods, MLE and MSPE, are similar. Bayesian estimation is not as sensitive to parameter changes as the first two estimation methods.
In future research, the following aspects can be considered. First, regarding the assumptions for model simplification, this paper assumes that stress variables and strength variables are independent of each other. In real life, there may be certain dependence relationships among many stress factors such as temperature, pressure, and friction, or strength factors like high-temperature resistance, pressure resistance, and wear resistance. Therefore, relevant theories such as the copula function can be used to analyze the correlations between these variables. Second, models corresponding to various types of censored data can be considered, such as Type-I censoring, Type-II censoring, progressive Type-I censoring, or progressive Type-II censoring. Stress–strength models can be established from the perspective of complex data types. In addition, in this paper, the model was simplified by assuming that the stress and strength variables within the same type of component have the same scale parameter. Therefore, the estimation of reliability models can be studied when the scale parameters of stress and strength variables are different. Apart from the above aspects, the application of the dynamic stress–strength model proposed in
Section 5 in the field of system maintenance can be explored. Moreover, a dynamic reliability model in which both stress and strength vary periodically can be considered, or the nonlinear effects of strength degradation can be taken into account.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}