Abstract
This article introduces a new continuous lifetime distribution within the Gamma
family, called the induced Xgamma distribution, and explores its various statistical properties.
The proposed distribution’s estimation and prediction are investigated using Bayesian
and non-Bayesian approaches under progressively Type-II censored data. The maximum
likelihood and maximum product spacing methods are applied for the non-Bayesian approach,
and some of their performances are evaluated. In the Bayesian framework, the
numerical approximation technique utilizing the Metropolis–Hastings algorithm within
the Markov chain Monte Carlo is employed under different loss functions, including the
squared error loss, general entropy, and LINEX loss. Interval estimation methods, such as
asymptotic confidence intervals, log-normal asymptotic confidence intervals, and highest
posterior density intervals, are also developed. A comprehensive numerical study using
Monte Carlo simulations is conducted to evaluate the performance of the proposed point
and interval estimation methods through progressive Type-II censored data. Furthermore,
the applicability and effectiveness of the proposed distribution are demonstrated through
three real-world datasets from the fields of medicine and engineering.
1. Introduction
The development of new probability distributions plays a crucial role in statistical modeling, particularly in reliability engineering, survival analysis, and actuarial science. In many real-world applications, existing distributions fail to adequately capture the complexity of observed data, leading to the need for more flexible and robust models (see [1,2,3,4,5,6,7,8,9,10,11,12]). One such challenge arises in studying lifetime data, where traditional distributions may not fully accommodate various hazard-rate behaviors. This motivates the derivation of new probability models that better describe real-world phenomena.
For the PCT-II approach, ref. [2] created an algorithm to simulate general PCT-II samples from uniform or other continuous distributions. Some procedures for the estimation of parameters from different lifetime distributions based on PCT-II were developed by many authors, which include [1,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29]. Recently, ref. [28] looked at the A and D optimal censoring plans in the PCT-II scheme order statistics. Ref. [26] suggested a new test statistic based on spacings to see if the samples from the general PCT-II scheme are from an exponential distribution. Ref. [30] estimated a Burr distribution’s unknown parameters, reliability, and hazard functions under the PCT-II sample.
Ref. [31] showed that when a controlled stepwise sample of the second type was available, parametric (classical and Bayes) point estimation procedures could be used to determine reliability characteristics, such as the reliability function and the mean time to failure for the Xgamma distribution, based on all observations.
To demonstrate the PCT-II scheme analyzing methods, the examiner gives different but identical units to the life test. There are n units to be tested at the beginning of the experiment, and the test ends when the mth unit fails. Once one unit fails, the time is recorded and units are randomly selected from the remaining survival units . Again, when the second unit fails, the time will be recorded, and units are then randomly withdrawn from the remaining survival units. This experiment stops at the mth failure, which is determined in advance, at time , and . The likelihood function based on a PCT-II sample is given by (see, [1]):
where C is defined as and and represent the cumulative distribution function (Cdf) and probability density function (Pdf), respectively. For the representation of the PCT-II scheme, Figure 1 illustrates the PCT-II scheme.
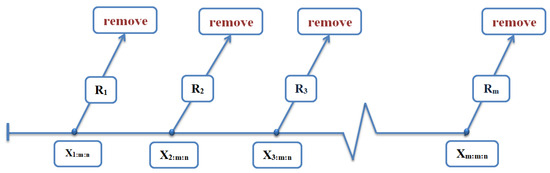
Figure 1.
Visualization of PCT-II scheme.
This article introduces a new probability distribution using the concept of an induced distribution. Let X be a continuous random variable with Pdf , Cdf , and expectation . We define an induced Pdf as:
It is well known that:
Thus, the induced Pdf can be rewritten as:
The assumed is the Xgamma distribution which was proposed by [16] with Pdf and Cdf, respectively, given by:
and
Many of the statistical characteristics of this distribution are easily studied, and it exhibits a strong relationship with its parent distribution, i.e., the Xgamma distribution. The Xgamma distribution is chosen for its flexibility in modeling lifetime data, combining gamma and exponential properties, and adapting well to progressive Type-II censoring (PCT-II), and it exhibits similar properties to the Lindley distribution. Using the approach described in Equation (2), where is the mean of the random variable , we derive the Pdf of the new distribution, which we term the induced Xgamma distribution (iXgamma). Hence, the Pdf of the iXgamma distribution is obtained by substituting from Equation (4) into Equation (2). It is expressed as:
The Cdf of the iXgamma distribution can be derived by integrating Equation (5) concerning x. It is given by:
Proof.
We know,
□
The newly proposed iXgamma distribution can also be expressed as a form of the following mixture:
where
and
Proof.
□
The Pdf and Cdf plots for the iXgamma distribution with different values of are shown in Figure 2. These plots exhibit characteristics similar to those of the exponential distribution.
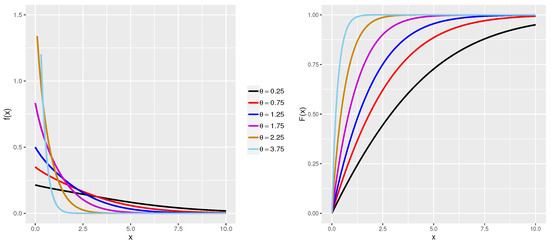
Figure 2.
The graph of Pdf and Cdf of iXgamma for different values of .
The novelty of our research is defined in three key aspects. First, we derived a new distribution based on the concept of induced distributions, as given in Equation (2), utilizing , leading to the proposed iXgamma distribution. Second, our proposed distribution is not merely an extension of the Xgamma distribution but rather a hybrid approach that integrates two fundamental distributions in mathematical statistics and reliability analysis—the Gamma and exponential distributions.
The limitations and challenges of this work are primarily related to the complexity of parameter estimation, computational intensity, limited sample sizes, model power, prediction, and inference difficulties. Advanced statistical methods and thorough evaluation of the data details and the censoring scheme are frequently needed to address these problems. Due to their costly numerical evaluations and complicated outcomes, new extended-gamma (iXgamma) lifetime models receive little attention from researchers. To our knowledge, no attempt has been made to estimate the iXgamma parameters based on the PCT-II scheme since the iXgamma distribution was presented in the literature, except for the work of [32], who used a complete sample to study Bayesian inferences based on non-informative priors.
The rest of the article is organized as follows: Section 2 introduces properties of the proposed iXgamma distribution. We discussed the maximum likelihood estimation and maximum product spacing estimation in Section 3. In Section 4, we present the Bayesian inferences and in Section 5, the confidence intervals estimations are presented. Simulation investigations and discussion are highlighted in Section 6. Three real datasets are analyzed in Section 7. In Section 8, point prediction is addressed using the maximum likelihood predictor and the Bayesian predictor. Finally, various observations are made in Section 9.
2. Properties of the Proposed iXgamma Distribution
In this section, various statistical and mathematical properties of the proposed distribution are explored, including reliability analysis, the distribution of order statistics, and the reliability of the stress strength and moments.
2.1. Reliability and Hazard Rate Function
The reliability and hazard rate function for the iXgamma distribution are given, respectively, by:
It should be noted that The plot of the reliability and hazard rate functions of the iXgamma for different are given in Figure 3.
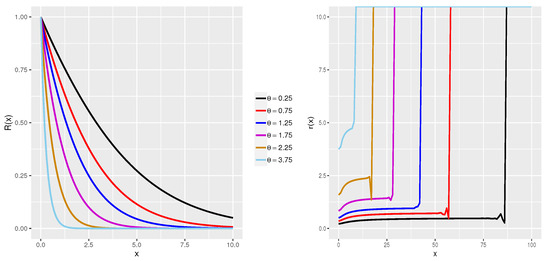
Figure 3.
The reliability and hazard rate functions plot of iXgamma for different values of .
The mean residual life (MRL) function of iXgamma is given by
and . Note that
2.2. Quantile Function
The quantile function is defined as the inverse of the Cdf, . It satisfies the relationship:
where u follows a standard uniform distribution. For the iXgamma distribution, the percentiles cannot be expressed in a closed-form analytical solution due to the complexity of its Cdf. Thus, numerical methods are typically used to compute the quantile function.
2.3. Moments
The rth order moment for the iXgamma distribution is given by
Proof.
We know,
□
In particular,
Using the recursive relation of raw and central moments, we can derive the skewness (), kurtosis (), and coefficient of variation () as follows:
In Table 1, the values of the mean, variance, coefficient of skewness, coefficient of kurtosis, and coefficient of variation for different values of are presented. We draw the following conclusions:

Table 1.
Table of central tendency and coefficient of skewness, kurtosis, and variation of iXgamma for different .
- The mean and variance decrease as increases.
- increases as increases,
- and > 3, . So, the iXgamma distribution is positively skewed and leptokurtic.
The inverse raw moment is used to find the harmonic mean and the expression for the inverse raw moment is given by
Putting , we obtain the harmonic mean as
Also, the expression for the moment-generating function is given by
2.4. Entropy Measures
Some alternatives to moments are entropy measures, such as the Rnyi and Shannon entropies, which are illustrated below:
- Rnyi Entropy:If , the Rnyi entropy is defined as:Proof.□
- Shannon Entropy:If , the Shannon entropy is defined as:Proof.□
2.5. Distribution of Order Statistics
Let be a random sample from iXgamma and be the corresponding order statistics; then, the Pdf and Cdf of the rth-order statistics, say, , are given by,
Putting and and , we obtain the Pdf of and , respectively, as
2.6. Stress-Strength Reliability (SSR)
SSR provides the probability of success for a system; a system succeeds whenever its inbuilt strength, Y exceeds the applied stress, X. Let X∼ iXgamma () and Y∼ iXgamma (); then, the expression for SSR is given by
Figure 4 shows the stress strength reliability of the iXgamma for different values of and .
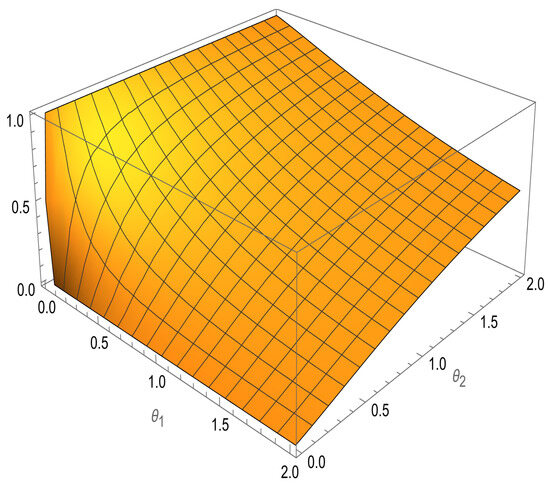
Figure 4.
The SSR of iXgamma for different values of and .
3. Non-Bayesian Estimation
In this section, we will discuss the non-Bayesian methods for estimating the unknown parameter of the iXgamma distribution in the presence of PCT-II censoring, specifically, MLE and MPS.
3.1. Maximum Likelihood Estimation
Here, we estimate the parameter of the iXgamma distribution under PCT-II samples using the MLE. Let where is the PCT-II sample of size m from a sample of n with the scheme , drawn from the iXgamma distribution with parameter . Substituting the Cdf and Pdf from Equations (5) and (6), respectively, into Equation (1), the log-likelihood function of can be given as follows:
The log-likelihood function , without the constant term, can be written as follows:
Calculating the first partial derivatives of ℓ with respect to , and equating each to zero, we obtain the likelihood equations as follows:
Since Equation (9) does not provide any closed-form solutions, we use the Newton–Raphson iteration method by using the optim() command of the R programming software to obtain the estimates. Refs. [4,14,18] describe the algorithm as follows:
- Initially, set and use as the starting point of iteration.
- Calculate , where is the value of the unknown parameter at iteration number k and find the observed Fisher information matrix .
- Then, continue the iteration with as follows:where ; the Fisher information matrix can also be obtained from the second-order partial derivatives of the log-likelihood function.
- Increment and return to Step 2.
- Continue the iterative steps until is smaller than a threshold value. The final estimates of are the MLE of the parameters, denoted as .
Moreover, using the invariance property of the MLEs, we obtain the MLEs of and by replacing with , as follows:
Existence and Uniqueness of MLEs
To check the existence and uniqueness of under the PCT-II sample data, we begin by taking the second partial derivatives of the log-likelihood function ℓ with respect to as follows:
From Equation (10), one can observe that
which is a clear indication that the log-likelihood function ℓ is strictly concave. So, we can say that the MLE exists and is unique.
3.2. Maximum Product Spacing
The maximum product spacing (MPS) method, which approximates the Kullback–Leibler information measure, serves as a reliable alternative to the MLE method. Consider the PCT-II sample of size m, obtained using the PCT-II scheme from the iXgamma population with parameter , denoted as , where i ranges from 1 to m. The MPS for the iXgamma distribution can be formulated as follows:
and can be obtained as
Upon deriving the first derivative of the function with respect to , we obtain:
Setting Equation (13) equal to zero and solving for , the MPS is obtained. Equation (13) does not provide a closed-form analytical solution when equated to zero. Consequently, numerical methods are employed to find the solutions.
4. Bayesian Estimation
In this section, we derive the Bayesian estimation (BE) of the parameter for the iXgamma distribution under PCT-II samples, assuming a Gamma prior distribution. The Gamma prior is specified as follows:
Thus, the posterior distribution is given by:
where is the likelihood function given in Equation (7) based on the PCT-II samples (x̠). The integral in the denominator ensures that the posterior distribution is normalized. Thus, the posterior distribution can be written
A commonly used symmetrical loss function is the square error loss (SEL), which assigns equal losses to overestimation and underestimation. If is estimated by an estimator , then the SEL function is defined as
Therefore, the BE of any function of , say under the SEL function, can be obtained as
Ref. [28] considered a LINEX (linear-exponential) loss function for a parameter is given by
This loss function is suitable for situations where overestimation is more costly than underestimation. Ref. [29] discussed BE and prediction using the LINEX loss. Hence, under the LINEX loss function, the BE of a function is
The BE of a function of , concerning the general entropy loss (GEL) function, is given by
All the above estimators in Equations (15)–(17) are the form of the ratio of two integrals for which simplified closed forms are not available. The Tierney–Kadan method is a numeric integration technique in such cases, and the Markov Chain Monte Carlo (MCMC) method finds the BEs.
4.1. MCMC Method
The MCMC methodology is one of the most effective numerical approaches in Bayesian inference. Moreover, calculating the normalization constant is unnecessary when summarizing the posterior distribution using MCMC methods. MCMC techniques have been extensively utilized in Bayesian statistical inference [32,33,34,35,36]. An algorithm, the Metropolis–Hastings (MH) algorithm, can be utilized as a sampler for the MCMC approach. A critical aspect of this method involves selecting an appropriate proposal distribution that satisfies two key criteria: (1) it should be easy to simulate, and (2) it should closely approximate the posterior distribution of interest. Once such a proposal distribution is identified, the acceptance/rejection rule is employed to generate random samples from the target posterior distribution. This enables efficient approximation of the Bayesian posterior summaries.
After obtaining a set of M samples from the posterior distribution, discarding a portion of the initial samples (known as the burn-in samples), and retaining the remaining samples for further analysis is common practice. Specifically, the BEs of the parameter , using the SEL and LINEX, GEL functions, are provided as follows:
where represents the number of burn-in samples.
MCMC Convergence
The Gelman–Rubin statistics are available to assess the convergence of the samples produced by the posterior distribution using MCMC. The goal of this approach is to confirm that MCMC samples have reached the target distribution that was planned for them. In this work, we use several Markov chains to evaluate convergence using the Gelman–Rubin statistic, which is sometimes referred to as the potential scale reduction factor (PSRF). The following formula is used to determine the PSRF:
where is the average within-chain variance, and the term in the numerator combines the between-chain variance with the within-chain variance to estimate the marginal posterior variance of the parameter. The number of iterations of each chain is shown here by M.
It is likely that the chains have converged if the PSRF value is near 1. The Gelman–Rubin statistic is extremely valuable as it uses several chains to provide an independent measure of convergence, eliminating the potential of erroneous integration that usually exists when using only a single chain. For more information, see [37].
4.2. Tierney–Kadane Method
Here, in this method, the ratios of the integrals from Equations (15)–(17) are represented in two forms shown below:
The equation takes the form of
where and maximize and , respectively, and and are the negatives of the inverse Hessian of and at and , respectively. Here, Equation (25) is used to obtain the Bayes estimators for the parameter , which is an approximation form. Now, differentiating Equation (24) with respect to , we obtain,
Now, the BE of can be computed as follows:
4.2.1. Under SEL Function
Again differentiating with respect to , we obtain
Therefore,
Putting the value in Equation (25), we obtain the Bayes estimator using the TK method under the SEL function.
4.2.2. Under the LINEX Function
Again differentiating with respect to , we obtain
Therefore,
Putting the value in Equation (25), we obtain the Bayes estimator using the TK method under the LINEX function.
4.2.3. Under the GEL Function
5. Confidence Interval Estimation
The confidence interval (CI) estimation for the parameter is derived from data obtained from the iXgamma distribution under the PCT-II scheme. In this section, the asymptotic confidence intervals and the highest posterior density intervals for the MLEs and BEs are presented.
5.1. Approximate Confidence Interval
Approximate confidence interval (ACI) estimation for the parameter using large-sample approximations. Two methods are presented: normal approximation (NA), which assumes follows a normal distribution, and log-transformed normal approximation (NL), which applies a logarithmic transformation for better coverage. The NA method provides direct ACI estimates, while the NL method ensures a more reliable range, especially for small samples or highly skewed distributions
5.2. Highest Posterior Density
According to the technique of [34], one can establish the highest posterior density (HPD) intervals for the unknown parameter of the iXgamma distribution under the PCT-II scheme using the samples obtained by the suggested MH algorithm in the preceding paragraph. Considering to be the th quantile of , that is,
where and is the posterior function of . It should be noted that for a given , an accurate estimator based on simulation of might well be computed as
Here, is the indicator function. The proper estimate is then determined as
where and are the ordered values of . Now, for , may be estimated by
Let determine a HPD credible interval for as
for ; here, indicates the largest integer that ≤a. It is necessary to choose from one of many s with the narrowest width.
6. Simulation Study and Discussion
In this section, Monte Carlo simulation studies are conducted to evaluate the performance of various estimation methods, including MLE, MPS, and BE, within the framework of the PCT-II scheme for the iXgamma distribution. We produce 1000 data points from the iXgamma distribution with parameters and 3. The choice of parameter values for the iXgamma distribution covered different shapes and behaviors of the distribution, allowing for an analysis of its behavior under these values. The PCT-II scheme can be assumed according to a given value of n and m and a different pattern for removing items , where , as shown in Table 2.
Table 2.
Proposed schemes for PCT-II.
This implies that the scheme corresponds to a Type-II censoring scheme as a particular case, with the number of failure items given by . Moreover, complete sampling is treated as a special case of the PCT-II scheme when for .
6.1. Monte Carlo Simulation Process
- Generate random samples for the iXgamma distribution with parameter using the assumed schemes of PCT-II in Table 2 employing the algorithm proposed by [2].
- Estimate the parameter using non-Bayesian methods (Non-BE), specifically MLE and MPS. From the MLE, the variance of the parameter can also be derived. When calculating MLEs, the initial estimate values are assumed to coincide with the true parameter values.
- Estimate the parameter using Bayesian methods (BE) as follows:
- (a)
- Assume the informative prior case, where the hyper-parameters are proposed and fixed at and . These values are plugged into the posterior density.
- (b)
- Consider three loss functions: SEL, LINEX (with ), and GEL (with ). We have experimented with different values to achieve the best possible results through these functions, ultimately arriving at the current values.
- (c)
- Estimate the parameter using the BE methods adopted in the research, initially through the TK method and MCMC.
- (d)
- For the MCMC method, using the MH algorithm:
- The initial values for the MH algorithm are set to the MLE estimates with their variances.
- Proposal samples for are generated from a normal distribution: , where is the MLE of , and is the observed Fisher information matrix of .
- A total of 10,000 posterior samples are generated, with the first 2000 samples discarded as burn-in to enhance the convergence of the MCMC estimation.
- The final estimate of is obtained by computing the average based on the chosen loss functions.
- The acceptance rate in our MCMC implementation was approximately 65%.
- Estimate the CIs for the parameter , which are the NA, NL, and HPD intervals.
- Perform steps 1 to 4 iteratively for a total of 1000 repetitions, storing all resulting estimates. Subsequently, compute the average (AV) and root mean square error (RMSE) for the point estimate. Additionally, determine the mean values of the lower and upper bounds of the CIs, calculate the average interval length (AIL), and evaluate the coverage probability (CP) as a percentage (%).
- In addition to the specific PCT-II patterns in Table 2, a general case of complete sampling has been added to estimates where and did not involve the exclusion of units from the experiment.
6.2. Comments on Results
In Table 3, Table 4 and Table 5,we obtained point estimates for the parameter at values 0.5, 1.5, and 2.5, respectively, for all estimation methods. Meanwhile, in Table 6, Table 7 and Table 8, we obtained interval estimates for the same parameter values in the same sequence. In general, from the results, we observe that as m increases, there is an improvement in the estimates converging closer to the assumed parameter value. Additionally, we observe a decrease in RMSE and, finally, a decrease in AILs for all estimation methods. Furthermore, CP is also observed to be constrained within specific bounds greater than 94%. There are also specific observations regarding the patterns of PCT-II and estimation methods, which can be summarized as follows:
Table 3.
The estimated values of AV and RMSE under various PCT-II schemes at .
Table 4.
The estimated values of AV and RMSE under various PCT-II schemes at .
Table 5.
The estimated values of AV and RMSE under various PCT-II schemes at .
Table 6.
The CIs, AILs, and CP (in %) across various PCT-II schemes at .
Table 7.
The CIs, AILs, and CP (in %) across various PCT-II schemes at .
Table 8.
The CIs, AILs, and CP (in %) across various PCT-II schemes at .
- With respect to the Non-BE methods, it is observed that the MLE method outperforms the method of percentile score MPS in scenarios involving PCT-II schemes, , , and , whereas the opposite is observed in schemes, and .
- In the BE methods, specifically, the TK method, we observe that the LINEX loss function performs best among the three loss functions when the parameter is less than 1, whereas SEL appears to perform better when is greater than 1.
- As for the MCMC method, there is variability in the performance of the loss functions and different PCT-II schemes, and we could not determine a clear preference for monitoring patterns or loss functions. However, it can be said that in most cases, the SEL tends to have the highest preference, followed by the GEL.
- Regarding interval estimation, we observe that the highest efficiency is with the HPD method, followed by NA, and finally, NL intervals for . For , the NA interval has the smallest AILs.
For checking of the convergence of the MCMC, assuming and the PCT-II pattern is , we may create three separate chains using a number of iterations of 10,000 samples to confirm the convergence of the MCMC for the two-parameter . We were able to use Equation (21) to estimate the PSRF. According to the results, all PSRF estimations are near to one, demonstrating that the chains have converged to the target distribution and implying that the MCMC method’s sampling is stable and trustworthy for more research.
7. Data Analysis
In this section, we aim to explore the applicability of the statistical distribution discussed in this research to various applications, including medicine, industry, and life testing. Therefore, we have applied it to three different applications: leukemia-free survival times, electrical appliances, and time between failures. Initially, we investigate the compatibility of these applications with the proposed iXgamma distribution using their data, illustrating this with graphical representations whenever possible. Then, we implement PCT-II for several proposed schemes.
7.1. Application 1: Leukemia-Free Survival Times
A total of fifty-one patients underwent an autologous bone marrow transplant [38]. The table below, Table 9, presents the leukemia-free survival durations (in months) for these patients.
Table 9.
The leukemia free-survival times (in months) dataset.
To evaluate the appropriateness of the iXgamma distribution for the given dataset, we compute the MLEs for the parameter and assess various goodness of fit (GOF) measures. These include the negative log-likelihood criterion (NLC), Akaike information criterion (AIC), Bayesian information criterion (BIC), and the Kolmogorov–Smirnov (K-S) test statistic, along with its corresponding P-value. These measures are then compared against those for other distributions, such as the Gamma, Xgamma, Inverse Weibull (Inv. Weibull), and exponential distributions. The estimated parameters, along with their standard errors (St.Er) and GOF statistics, are summarized in Table 10, where lower criterion values and higher P-values indicate a better fit. The findings suggest that the iXgamma distribution is a suitable model for the data. Furthermore, graphical representations, including the empirical Cdf and histogram with the fitted Cdf and Pdf curves for each distribution, are shown in Figure 5, which visually demonstrates that the iXgamma distribution provides a superior fit to the dataset when compared to the other distributions.
Table 10.
GOF for survival times (in months).
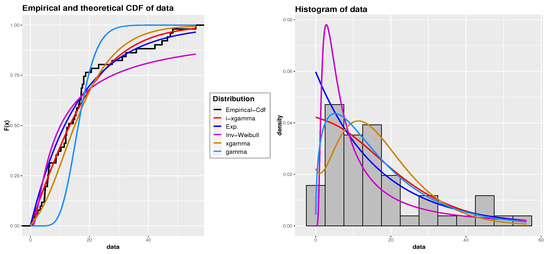
Figure 5.
The fitted Pdf and Cdf for dataset 1: Leukemia-free survival times.
7.2. Application 2: Electrical Appliances
The second dataset pertains to the number of cycles to failure for 60 electrical appliances in a life test experiment (see [39]), as shown in Table 11.
Table 11.
Failure time of 60 electrical appliances dataset.
To verify the compatibility of the data with the iXgamma distribution, we compare it with the Burr-III, log-normal, Lindley, and generalized exponential (Gen-Exp) distributions, following the same methodology as in the first application. The estimated parameters along with the GOF statistics are displayed in Table 12. Additionally, Figure 6 provides the empirical Cdf and histogram, along with the fitted Cdf and Pdf lines for the compared distributions. The results show that the iXgamma distribution provides a better fit compared to the other distributions for this particular dataset.
Table 12.
GOF for electrical appliances dataset.
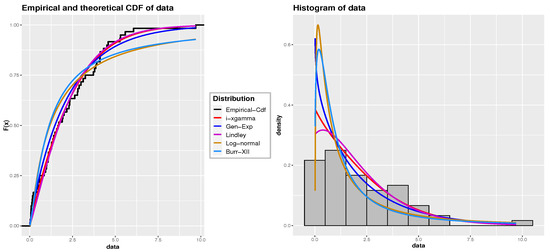
Figure 6.
The fitted Pdf and Cdf for dataset 2: Electrical appliances.
7.3. Application 3: Time Between Failures
The data, sourced from [40], pertain to the time between failures for 30 repairable items, and are detailed in Table 13.
Table 13.
Sorted time intervals between failures for a set of 30 repairable items.
Following a methodology similar to the first and second applications, we assess the compatibility of the iXgamma distribution both numerically and graphically with this dataset. We compare its fit with the Gamma, Rayleigh, exponential, and Xgamma distributions. The estimated parameters and GOF statistics can be found in Table 14. Figure 7 displays the empirical Cdf and histogram with the fitted Cdf and Pdf lines for the various distributions. The results suggest that the iXgamma distribution offers a better fit than the other distributions for this particular dataset.
Table 14.
GOF for repairable items.
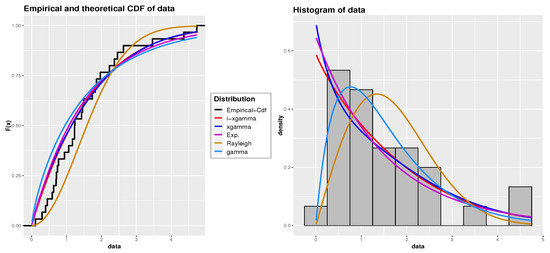
Figure 7.
The fitted Pdf and Cdf for dataset 3: Time between failures dataset.
Finally, for the three given datasets, a summary of the MLE and the different Asy-CIs, including both the NA and NL methods, for the parameter is presented in Table 15.
Table 15.
Summary of estimation for given three datasets.
After confirming the compatibility of the previous three applications with the iXgamma distribution, our goal is to implement the PCT-II methodology using various removal schemes and estimate the distribution parameter using assumed estimation methods. Specifically, for Non-BE methods, we employ MLE and MPS. For BE methods, we apply various loss functions, such as SEL, LINEX at , and GEL at under TK, along with MCMC using the MH algorithm. Both point estimates and interval estimates have been calculated, with the results shown in Table 16 and Table 17, respectively. It is noteworthy that the entire dataset has been used, and these estimates are provided for comparison with those obtained under the PCT-II schemes.
Table 16.
Point estimates for Non-BE and BE methods for the three datasets under various PCT-II schemes.
Table 17.
Interval estimates for the three datasets under various PCT-II schemes.
Figure 8, Figure 9 and Figure 10 illustrate the convergence of the MCMC estimates using the MH algorithm for the three datasets under the initial PCT-II scheme. These figures present trace plots, histograms, and cumulative means of the estimated parameter , based on non-informative priors. These visual representations highlight the distribution of the posterior samples obtained when using informative priors for both parameters.
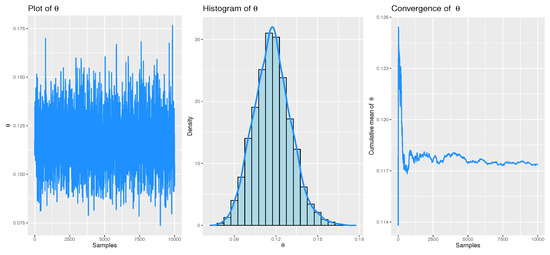
Figure 8.
Convergence of MCMC for real dataset 1: Leukemia free-survival times.
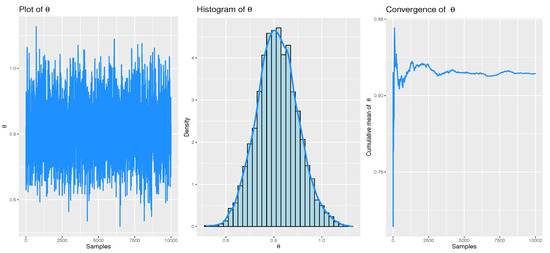
Figure 9.
Convergence of MCMC for real dataset 2: Electrical appliances.
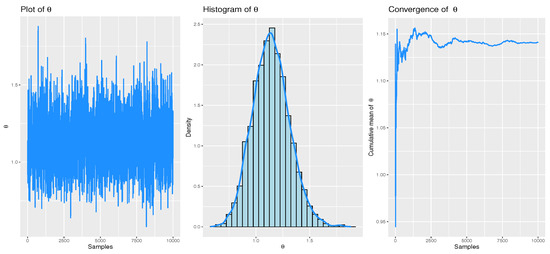
Figure 10.
Convergence of MCMC for real dataset 3: Time between failures.
8. Prediction
This section addresses the issue of point prediction. Recall that under the PCT-II scheme, a number of live units are randomly removed from the experiment at the time of the failure, denoted as . Let represent the lifespans of these units, where , and . It is then important to note that the conditional density of , given the PCT-II sample x and R, provided in references [11,41], can be written as:
where,
and
Now, the aim is to predict the value of by several prediction methods after entering all the values.
8.1. Maximum Likelihood Predictor
Here, we have to estimate and predict the value of ; the predictive likelihood can be written as
By applying the predictive log-likelihood function, , and computing the partial derivatives concerning both and , we derive the following expression:
where , and . Solving the above equations, we obtain the predictive maximum likelihood estimates (PMLE) of and .
8.2. Best Unbiased Predictor
Here, can be predicted using the concept of the best unbiased predictor (BUP), i.e., by . It can also be concluded that if , and if be any other unbiased predictor, then .The BUP is given by
Putting the values of , and in the above equation, we obtain the BUP of .
8.3. Bayesian Predictor
In this subsection, we focus on the Bayesian predictor (BP) to forecast the observations using the prior along with the SEL function. The predictive posterior density, under the posterior and prior , is expressed as:
Additionally, the kth observation from the censored units can be predicted under the SEL function as follows:
The above expression represents the expectation of under the SEL function.
To obtain the desired predictive estimate, we first generate samples from the corresponding predictive posterior density using the MH algorithm. Subsequently, the predictive estimate can be obtained as follows:
where M is the number of MCMC iterations and is the burn in samples.
Application to Real Datasets
In this section, we apply the prediction methods discussed earlier to the datasets introduced in Section 7, utilizing the PCT-II methodology. The first four censored observations are predicted using the proposed methods: PMLE, BUP, and BP. The predictive values for all observations are provided in Table 18. Additionally, the true observations for the considered datasets are also included in Table 18. It can be seen that the predictive estimates obtained using BP are closer to the true observations compared to those generated by the other methods.
Table 18.
Estimates from different predictive methods: PMLE, BUP, and BP for .
9. Concluding Remarks
In this research, a new life distribution, named the iXgamma distribution, has been proposed and studied based on induced distributions. The PCT-II scheme is implemented for the proposed distribution. Several mathematical properties of the iXgamma distribution, including its reliability properties, moments, order statistics, and stress-strength reliability, have been derived. Various Non-BE methods, such as MLE and MPS, have been explored. Additionally, Bayesian procedures have been examined using numerical techniques (MCMC with the MH algorithm) and approximation methods, such as the Tierney–Kadane method based on the loss functions SEL, LINEX, and GEL. Interval estimation is also studied for MLE and BE, using Asy-CI and HPD intervals, respectively. The effectiveness of the proposed distribution is demonstrated through the analysis of three actual lifetime datasets. Our proposed distribution is shown to be superior to the Gamma, Rayleigh, exponential, and Xgamma distributions. Furthermore, Monte Carlo simulation studies were conducted to assess the performance of both non-Bayesian and BEs using the PCT-II scheme for the iXgamma distribution. Among the point estimation methods, MLE performed well in non-BE, while the Terry–Kande method excelled in BE. The HPD interval estimation method proved to be the most efficient among different interval estimation techniques. After our study, several predictor functions for the iXgamma distribution under the PCT-II scheme were derived, including the maximum likelihood predictor, best-unbiased predictor, and Bayesian predictor. Future work can explore extending the study to acceptance sampling plans, investigating informative and non-informative priors in BE, and studying causes of failure.
Author Contributions
A.R.E.-S.: Writing—review, Software, Formal analysis, Conceptualization. M.K.R.: Writing—original draft, Methodology. A.H.T.: Writing—review & editing, Writing—original draft, Conceptualization, Software, Methodology, Conceptualization. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported and funded by the Deanship of Scientific Research at Imam Mohammad Ibn Saud Islamic University (IMSIU) (grant number IMSIU-DDRSP2503).
Data Availability Statement
Data are contained within the article.
Acknowledgments
This work was supported and funded by the Deanship of Scientific Research at Imam Mohammad Ibn Saud Islamic University (IMSIU).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Balakrishnan, N.; Aggarwala, R. Progressive Censoring: Theory, Methods, and Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2000. [Google Scholar]
- Balakrishnan, N.; Sandhu, R. A simple simulational algorithm for generating progressive Type-II censored samples. Am. Stat. 1995, 49, 229–230. [Google Scholar] [CrossRef]
- Maiti, K.; Kayal, S. Estimating Reliability Characteristics of the Log-Logistic Distribution Under Progressive Censoring with Two Applications. Ann. Data Sci. 2023, 10, 89–128. [Google Scholar] [CrossRef]
- Eryilmaz, S.; Bayramoglu, I. Spacings, exceedances, and concomitants in progressive type II censoring scheme. J. Stat. Inference 2006, 136, 527–536. [Google Scholar]
- Maiti, K.; Kayal, S. Estimation of parameters and reliability characteristics for a generalized Rayleigh distribution under progressive type-II censored sample. Commun. Stat.-Simul. Comput. 2021, 50, 3669–3698. [Google Scholar] [CrossRef]
- Tolba, A.; Almetwally, E.; Ramadan, D. Bayesian Estimation of A One-Parameter Akshaya Distribution with Progressively Type-II Censored Data. J. Stat. Appl. Probab. 2022, 11, 565–579. [Google Scholar]
- Balakrishnan, N. Progressive censoring methodology: An appraisal. Test 2007, 16, 211–259. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Cramer, E. The Art of Progressive Censoring, Applications to Reliability and Quality; Springer: New York, NY, USA, 2014. [Google Scholar]
- Saha, M.; Yadav, A. Estimation of the reliability characteristics by using classical and Bayesian methods of estimation for Xgamma distribution. Life Cycle Reliab. Saf. Eng. 2021, 10, 303–317. [Google Scholar] [CrossRef]
- Abushal, T. Parametric inference of Akash distribution for Type-II censoring with analyzing of relief times of patients. Aims Math. 2021, 6, 10789–10801. [Google Scholar] [CrossRef]
- Aggarwala, R.; Balakrishnan, N. Recurrence relations for single and product moments of progressive Type-II right censored order statistics from exponential and truncated exponential distributions. Ann. Inst. Stat. Math. 1996, 48, 757–771. [Google Scholar] [CrossRef]
- Aggarwala, R.; Balakrishnan, N. Some properties of progressively censored order statistics from arbitrary and uniform distributions with applications to inference and simulation. J. Stat. Plan. Inference 1998, 70, 35–49. [Google Scholar] [CrossRef]
- Sarhan, A.; Al-Ruzaizaa, A. Statistical inference in connection with the Weibull model using type-II progressively censored data with random scheme. Pak. J. Stat. 2010, 426, 267–279. [Google Scholar]
- Sarhan, A.; Abuammoh, A. Statistical inference using progressively type-II censored data with random scheme. Int. Math. Forum 2008, 3, 1713–1725. [Google Scholar]
- Cheng, R.; Amin, N. Estimating parameters in continuous univariate distributions with a shifted origin. J. R. Stat. Soc. Ser. B Methodol. 1983, 45, 394–403. [Google Scholar] [CrossRef]
- Sen, S.; Maiti, S.; Chandra, N. The Xgamma distribution: Statistical properties and application. J. Mod. Appl. Stat. Methods 2016, 15, 38. [Google Scholar] [CrossRef]
- Montanari, G.; Mazzanti, G.; Cacciari, M.; Fothergill, J. Optimum estimators for the Weibull distribution from censored test data. Progressively censored tests. IEEE Trans. Dielectr. Electr. Insul. 1998, 5, 157–164. [Google Scholar] [CrossRef]
- Ahmed, E. Estimation and prediction for the generalized inverted exponential distribution based on progressively first-failure-censored data with the application. J. Appl. Stat. 2017, 44, 1576–1608. [Google Scholar] [CrossRef]
- Ali Mousa, M.; Jaheen, Z. Statistical Inference for the Burr Model Based on Progressively Censored Data. Comput. Math. Appl. 2002, 43, 1441–1449. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Kannan, N. Point and interval estimation for parameters of the logistic distribution based on progressively Type-II censored samples. Adv. Reliab. 2001, 20, 431–456. [Google Scholar]
- Balakrishnan, N.; Sandhu, R. Best linear unbiased and maximum likelihood estimation for exponential distributions under general progressive Type-II censored samples. Indian J. Stat. Ser. B 1996, 58, 1–9. [Google Scholar]
- Alsadat, N.; Ramadan, D.; Almetwally, E.; Tolba, A. Estimation of some lifetime parameter of the unit half logistic-geometry distribution under progressively type-II censored data. J. Radiat. Res. Appl. Sci. 2023, 16, 100674. [Google Scholar] [CrossRef]
- Klein, J.; Moeschberger, M. Survival Analysis: Techniques for Censored and Truncated Data; Springer Science and Business Media: Berlin/Heidelberg, Germany, 1997. [Google Scholar]
- Ghitany, M.; Al-Awadhi, S. Maximum likelihood estimation of Burr XII distribution parameters under random censoring. J. Appl. Stat. 2002, 29, 955–965. [Google Scholar] [CrossRef]
- Lawless, J. Statistical Methods and Methods for Lifetime Data; John Wiley and Sons: New York, NY, USA, 1982. [Google Scholar]
- Panahi, H.; Asadi, S. On adaptive progressive hybrid censored Burr type III distribution: Application to the nanodroplet dispersion data. Qual. Technol. Quant. Manag. 2021, 18, 179–201. [Google Scholar] [CrossRef]
- Qin, X.; Yu, J.; Gui, W. Goodness-of-fit test for exponentiality based on spacings for general progressive Type-II censored data. J. Appl. Stat. 2020, 49, 599–620. [Google Scholar] [CrossRef]
- Salemi, U.; Rezaei, S.; Nadarajah, S. A-optimal and D-optimal censoring plans in progressively Type-II right censored order statistics. Stat. Pap. 2019, 60, 1349–1367. [Google Scholar] [CrossRef]
- Tse, S.; Yang, C.; Yuen, H. Statistical analysis of Weibull distributed lifetime data under type II progressive censoring with binomial removals. J. Appl. Stat. Taylor Fr. J. 2020, 27, 1033–1043. [Google Scholar] [CrossRef]
- Ali Mousa, M.; Jaheen, Z. Bayesian prediction for progressively censored data from the Burr model. Stat. Pap. 2002, 43, 587–593. [Google Scholar] [CrossRef]
- Ali Mousa, M.; Al-Sagheer, S. Bayesian Prediction for Progressively Type-II Censored Data from the Rayleigh Model. Commun. Stat. Theory Methods 2005, 34, 2353–2361. [Google Scholar] [CrossRef]
- Alotaibi, R.; Dey, S.; Elshahhat, A. Analysis of Progressively Type-II Inverted Generalized Gamma Censored Data and Its Engineering Application. CMES-Comput. Model. Eng. Sci. 2024, 141, 459–489. [Google Scholar] [CrossRef]
- Tolba, A. Bayesian and Non-Bayesian Estimation Methods for Simulating the Parameter of the Akshaya Distribution. Comput. J. Math. Stat. Sci. 2022, 1, 13–25. [Google Scholar] [CrossRef]
- Chen, M.; Shao, Q. Monte Carlo estimation of Bayesian credible and HPD intervals. J. Comput. Graph. Stat. 1999, 8, 69–92. [Google Scholar] [CrossRef]
- Meeker, W.; Escobar, L.; Pascual, F. Statistical Methods for Reliability Data; John Wiley & Sons: Hoboken, NJ, USA, 2022. [Google Scholar]
- Ramos, P.; Mota, A.; Ferreira, P.; Ramos, E.; Tomazella, V.; Louzada, F. Bayesian analysis of the inverse generalized Gamma distribution using objective priors. J. Stat. Comput. Simul. 2021, 91, 786–816. [Google Scholar] [CrossRef]
- Gelman, A.; Rubin, D. Inference from iterative simulation using multiple sequences. Stat. Sci. 1992, 7, 457–472. [Google Scholar] [CrossRef]
- Murthy, D.; Xie, M.; Jiang, R. Weibull Models; John Wiley & Sons: Hoboken, NJ, USA, 2004. [Google Scholar]
- Efron, B. The bootstrap and other resampling plans. In CBMS-NSF Regional Conference Series in Applied Mathematics; SIAM: Philadelphia, PA, USA, 1982. [Google Scholar]
- Gupta, R.; Kirmani, S. The role of weighted distributions in stochastic modeling. Commun. Stat. Theory Methods 1990, 19, 3147–3162. [Google Scholar] [CrossRef]
- Ahmed, E. Estimation of some lifetime parameters of generalized Gompertz distribution under progressively type-II censored data. Appl. Math. Model. 2015, 39, 5567–5578. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).