1. Introduction
Rolling bearings work similarly to the train’s “ankle joints” and are crucial parts for the dependable operation of high-speed trains. They primarily serve to support loads, transmit alternating forces, and facilitate motion conversion [
1]. Given the extensive operational hours and complex environmental conditions faced by high-speed trains in China, these bearings are frequently subjected to harsh environments characterized by elevated temperatures, severe shocks, and significant fluctuations in temperature and humidity. Consequently, monitoring their condition and implementing intelligent fault diagnosis for high-speed train bearings have become imperative for ensuring the safety and stability of train operations [
2].
Numerous academic fields, including computer science, mechanics, mathematics, and signal processing, are involved in the study of rolling bearing defect identification. Scholars have been focusing more on machine learning and deep learning methods in recent years. These strategies use pattern recognition techniques and large data analysis to provide automated rolling bearing fault diagnosis [
3]. Vibration signals from rolling bearings exhibit high sensitivity to early-stage faults and can effectively reflect changes in the condition of the bearing over time. Furthermore, advancements in vibration signal acquisition technologies have established them as one of the most widely utilized data sources for diagnosing faults in rolling bearings [
4].
Time-domain analysis methods are capable of extracting comprehensive and complete information, enabling accurate analysis of the temporal characteristics of signals. These methods are particularly effective for analyzing non-periodic signals and demonstrate strong performance in fault diagnosis [
5]. In order to diagnose faults, Zong et al. [
6] used the Gini index in conjunction with three dimensionless time-domain features: average margin factor, average kurtosis factor, and average pulse factor. This information is fed into an Extreme Learning Machine (ELM) classifier to detect different defect kinds. Wang et al. [
7] employed Singular Value Decomposition (SVD) to reconstruct the original signal, from which they extracted time-domain features along with power spectral entropy features that were successfully utilized in a classifier for fault classification purposes. Liang et al. [
8] introduced one-dimensional time-domain signals into a one-dimensional extended convolutional network with residual connections to facilitate bearing fault diagnosis across various noise environments and loading conditions.
Single-feature defect diagnosis techniques are severely hampered by the non-stationarity of vibration signals from mechanical equipment. One interesting method for problem diagnostics has been identified as signal-to-image conversion [
9]. Zhou et al. [
10] presented a rolling bearing defect diagnosis technique that combines Vision Transformers (ViT), Convolutional Neural Networks (CNN), and Gramian Angular Field. The model’s fault diagnosis accuracies were 99.79% and 99.63%, respectively, following validation on two datasets. Hu et al. [
11] applied the continuous wavelet transform to convert the bearing vibration signals into time-frequency images and then integrated these signals with the motor current data before feeding them into a network model. In various noise environments, the fault diagnosis accuracy reached 98%. These studies suggest that image-based signal transformation methods have great potential for application in rolling bearing fault diagnosis.
In bearing fault diagnosis, multi-channel data [
12] can provide richer and more comprehensive fault information, effectively reducing the interference of random factors present in single-channel data. Sun et al. [
13] embedded the representation patterns of rotating machinery faults from multi-modal information into an attention mechanism, focusing on extracting representative fault features with physical significance, thereby generating a universal representation of multi-modal information. Xu et al. [
14] fused horizontal and vertical vibration signals using Principal Component Analysis (PCA), then employed Continuous Wavelet Transform to generate time-frequency feature maps, which were subsequently input into a residual neural network for feature extraction and classification. Using a model-data integrated digital twin system, Shi et al. [
15] were the first to combine simulation signals with observed signals from rolling bearings displaying different fault modes. They then transformed 1D vibration signals into 2D images that contained time-frequency information using a Markov transition matrix-based image encoding technique. Using real bearing data, the created model’s effectiveness was evaluated. In order to create a multi-channel input network model that could simultaneously learn from these three image types, Gao et al. [
16] used signal processing techniques to convert one-dimensional vibration signals into three different kinds of two-dimensional time-frequency images. The results show that the multi-channel technique achieved a 100% accuracy rate in fault diagnosis tasks compared to single-channel diagnostic models.
ResNet excelled in the field of deep learning, effectively extracting local and global features of vibration signals, and alleviating the problem of disappearing gradients through residual connections, making the training of deep networks more stable. Traditional machine learning methods, such as SVM and random forest, rely on artificial feature extraction and it is difficult to effectively capture complex time series dependencies. BiLSTM can capture the time series characteristics of the signal, taking into account both forward and backward information, thereby improving the ability to model time-dependent patterns. Combining spatial features extracted by ResNet with temporal features captured by BiLSTM can enhance the robustness and generalization ability of the model. With the advent of the big data era, the equipment monitoring data is growing exponentially, and the efficiency of single-mode signal processing methods is facing a challenge. At the same time, the computational burden of deep learning models has increased. Therefore, an enhanced ResNet-BiLSTM three-channel feature fusion method for bearing defect identification is proposed in this paper. The aim of this technique is to reduce the computational burden of deep models when processing multi-modal data while improving the effectiveness and accuracy of problem identification.
This paper’s remaining sections are arranged as follows. The fundamental ideas of the Continuous Wavelet Transform, Bidirectional Long Short-Term Memory Networks, Residual Neural Networks, Markov Transition Field, and Cross-Attention Mechanisms are presented in
Section 2. The enhanced ResNet-BiLSTM three-channel feature fusion method’s construction is shown in
Section 3. Two sets of bearing experimental data are used in
Section 4 to examine the performance of the suggested approach. The conclusion and prospects are finally presented in
Section 5.
2. Basic Theory
2.1. Continuous Wavelet Transform
The Continuous Wavelet Transform is a signal processing technique used for multi-scale analysis of signals, capturing their characteristics at different frequencies and time scales [
17]. The basic principle is as follows:
The CWT decomposes and reconstructs the signal using a wavelet function. In order to efficiently capture the local aspects of the signal, a wavelet function is a localized function that can have localized properties in both the time and frequency domains. In order to acquire wavelet coefficients at several scales, the CWT convolves the signal with wavelet functions at distinct frequencies and scales. This allows for multi-scale analysis of the signal in both the frequency and temporal domains. The formula for CWT is given by Equation (1):
Here, the mother wavelet is scaled and translated to produce A:
In the equation, a is the scale factor, which corresponds to the scaling related to frequency, and b is the translation factor, represents the wavelet basis function.
The Morlet wavelet is chosen as the wavelet basis function in this investigation because its waveform resembles the impact characteristics brought on by rolling bearing problems [
18].
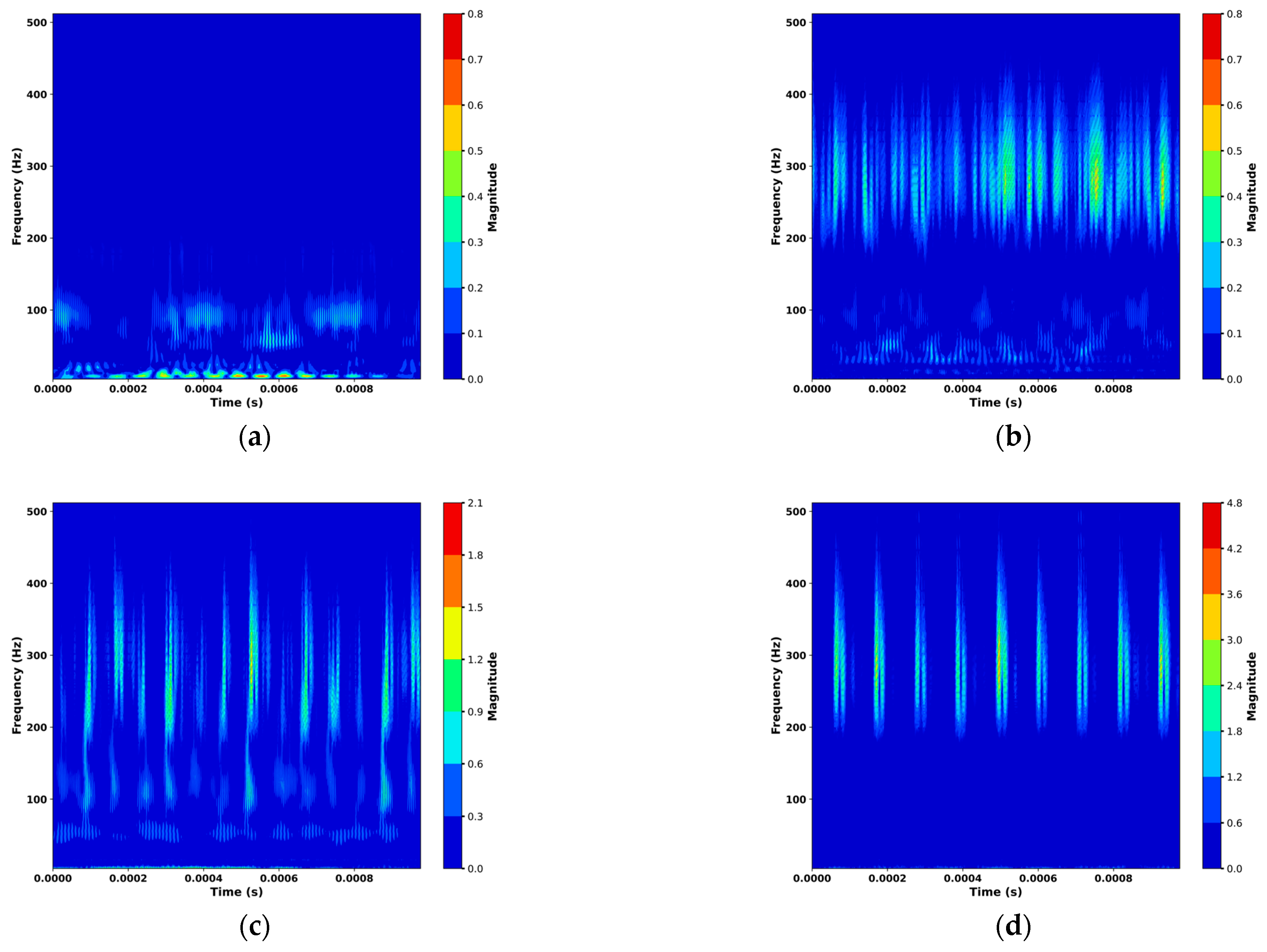
Figure 1a–d shows the CWT images of rolling bearings under four health states.
2.2. Markov Transition Field
The Markov Transition Field incorporates both temporal and spatial factors into the traditional Markov model, constructing a Markov transition matrix while preserving the temporal correlation of the original signal by transforming a one-dimensional time-domain signal into a two-dimensional image [
19].
The original time-series signal X = {x
1, x
2 …, x
n} is divided into Q quantile regions based on the signal amplitude at different time instants. Each data point has distinct characteristics, and they are mapped to different quantile regions
(
i ∈ [1, Q]). hen, along the time axis, a Markov chain is used to calculate the transitions between quantile points, thereby constructing the Markov transition matrix D, as shown in Equation (3).
In the equation,
represents the probability of data points in the quantile region
transitioning to the quantile region
. The dynamic probabilistic transitions within the time series data are not taken into account by the Markov state transition matrix, which solely computes the transition probabilities between successive time steps. Equation (4) illustrates how the Markov-Kernel Filter overcomes this constraint by producing a dynamic probability transition matrix M across time scales.
Using the Markov probability transition matrix D, which is displayed in Equations (2) and (3), the MTF calculation steps entail calculating the transition probabilities between
and
. For instance,
stands for the transition probability from
to
, or the likelihood of moving from the quantile unit, which contains
, to the quantile unit, which contains
. By consulting matrix D, the corresponding transition probability
is identified as the second element in the first row of the matrix, which is then used to construct the dynamic probability transition matrix MTF with dimension n × n.
Figure 2a–d shows the MTF images of rolling bearings under four health states.
2.3. Residual Networks
Due to their remarkable feature extraction capabilities, residual networks—a common deep learning architecture—are employed extensively in a variety of domains, including image recognition and natural language processing [
20]. This study employs two types of residual modules: the Bottleneck Block and the Identity Block. Additionally, the ScConv module is introduced in both blocks to replace the traditional 3 × 3 convolution layer, effectively reducing spatial and channel redundancies within the network.
2.3.1. Residual Block
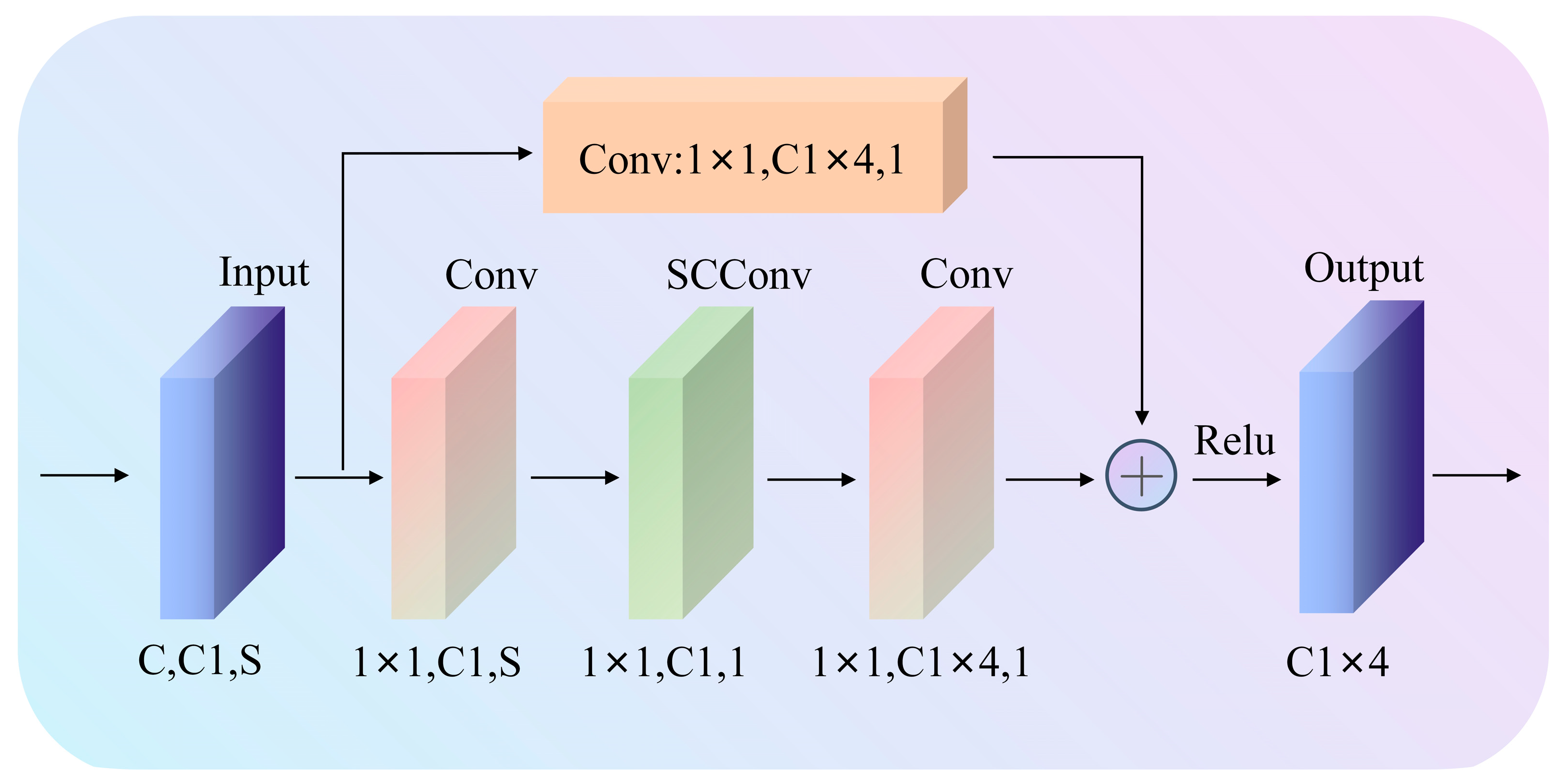
Figure 3 shows the Bottleneck Block’s convolutional structure. In order to lower the number of channels and, consequently, the number of parameters and computational complexity, this structure first employs a 1 × 1 convolution layer. After that, a ScConv module is used to extract features. Lastly, an up-scaling operation is performed using a second 1 × 1 convolution layer to restore the number of channels. This design’s benefit is that it can efficiently extract features while drastically cutting down on computation and parameters. It also helps with gradient backpropagation, which is particularly useful in networks with deeper structures. In the graphic, S stands for the convolution stride, C for the input channel number, and C1 for the output channel number.
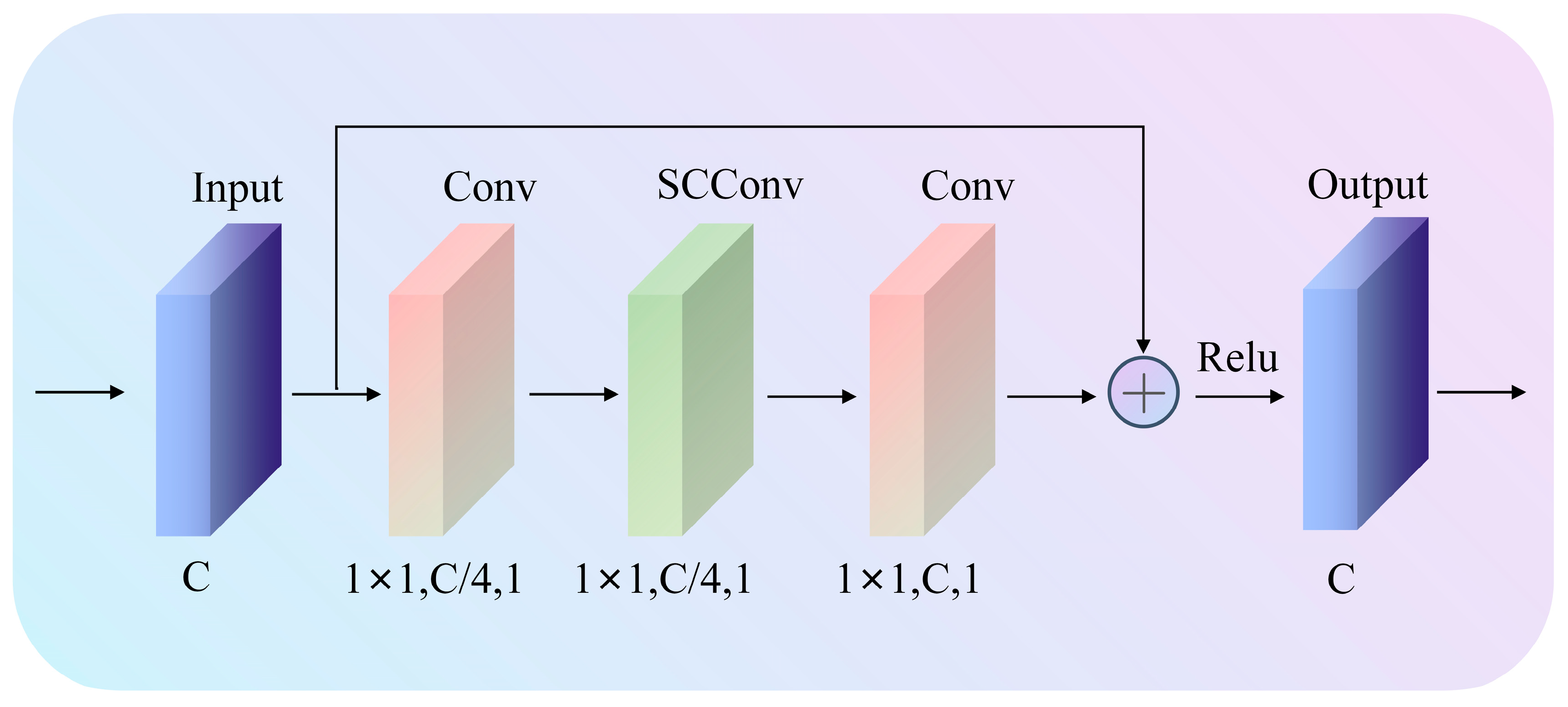
The Identity Block, shown in
Figure 4, has a structure similar to the Bottleneck Block but with the same input and output dimensions, allowing them to be used in a sequential manner. The main purposes of this module are to deepen the network, solve the vanishing gradient issue, and successfully maintain the information’s integrity.
2.3.2. ScConv Module
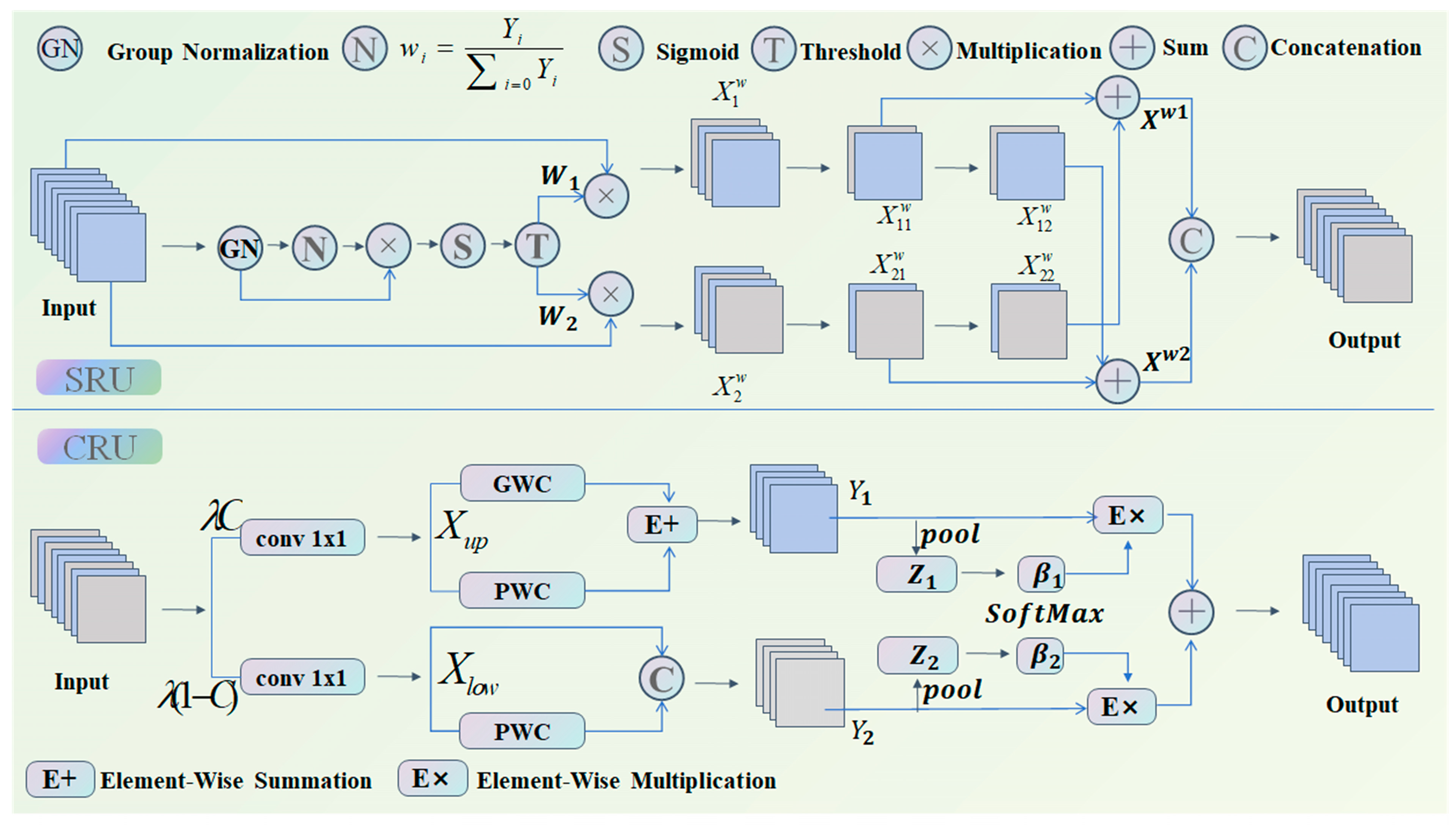
The ScConv module reduces both spatial and channel redundancy in convolutional neural networks by integrating the Spatial Reconstruction Unit (SRU) with the Channel Reconstruction Unit (CRU) [
21]. Whereas the CRU maximizes channel features, the SRU maximizes spatial features. Lastly, the optimized features are transmitted to the subsequent convolutional block after being added to the initial residual connection. In
Figure 5, the model structure is displayed.
The Spatial Reconstruction Unit (SRU) optimizes spatial features by separating and reconstructing the input feature X. Group normalization is applied as shown in Equation (5).
Equation (6) is used to produce the normalized weights, which indicate the relative relevance of various feature maps. A threshold is then utilized to apply gating after these weights are used to map the weighted features to the range (0, 1) using a Sigmoid function. By setting the threshold weight to 1 or 0.5, either full or partial information weights can be obtained with the specific calculation formula provided in Equation (7).
In the equation, and represents the mean and standard deviation, and β are trainable variable and is a small constant used to ensure stability.
The reconstruction operation involves adding features with more information to those with less information, generating a more informative feature while saving space.
Equations (8) through (11) demonstrate how cross-reconstruction is used to merge two weighted features with disparate information to create
and
, which are combined to produce the feature map with spatial refinement.
The Channel Reconstruction Unit (CRU) takes the spatially optimized features as input and generates channel-optimized features. CRU reduces channel redundancy through segmentation, transformation, and fusion operations while retaining the expressive power of the features.
The input spatially refined feature is split into two sections by the segmentation procedure, each with a channel size of λC and (1 − λ)C. Both feature sets are then compressed using convolutional kernels, producing and .
The input is initially processed using pointwise convolution (PWC) and groupwise convolution (GWC) operations, which are carried out independently for each group. The output
is then obtained by adding the results. In order to generate the output
, the input is further utilized as supplemental data and subjected to a pointwise convolution (PWC) [
22].
The fusion operation utilizes a simplified SKNet method for the adaptive merging of
and
[
23]. In particular, the pooled features
and
are obtained by first combining global geographical information and channel statistics using global average pooling. Then, a softmax function is applied to
and
to obtain the feature weight vector
and
. Lastly, as indicated by Equation (12), the output
Y is calculated using the feature weight vectors.
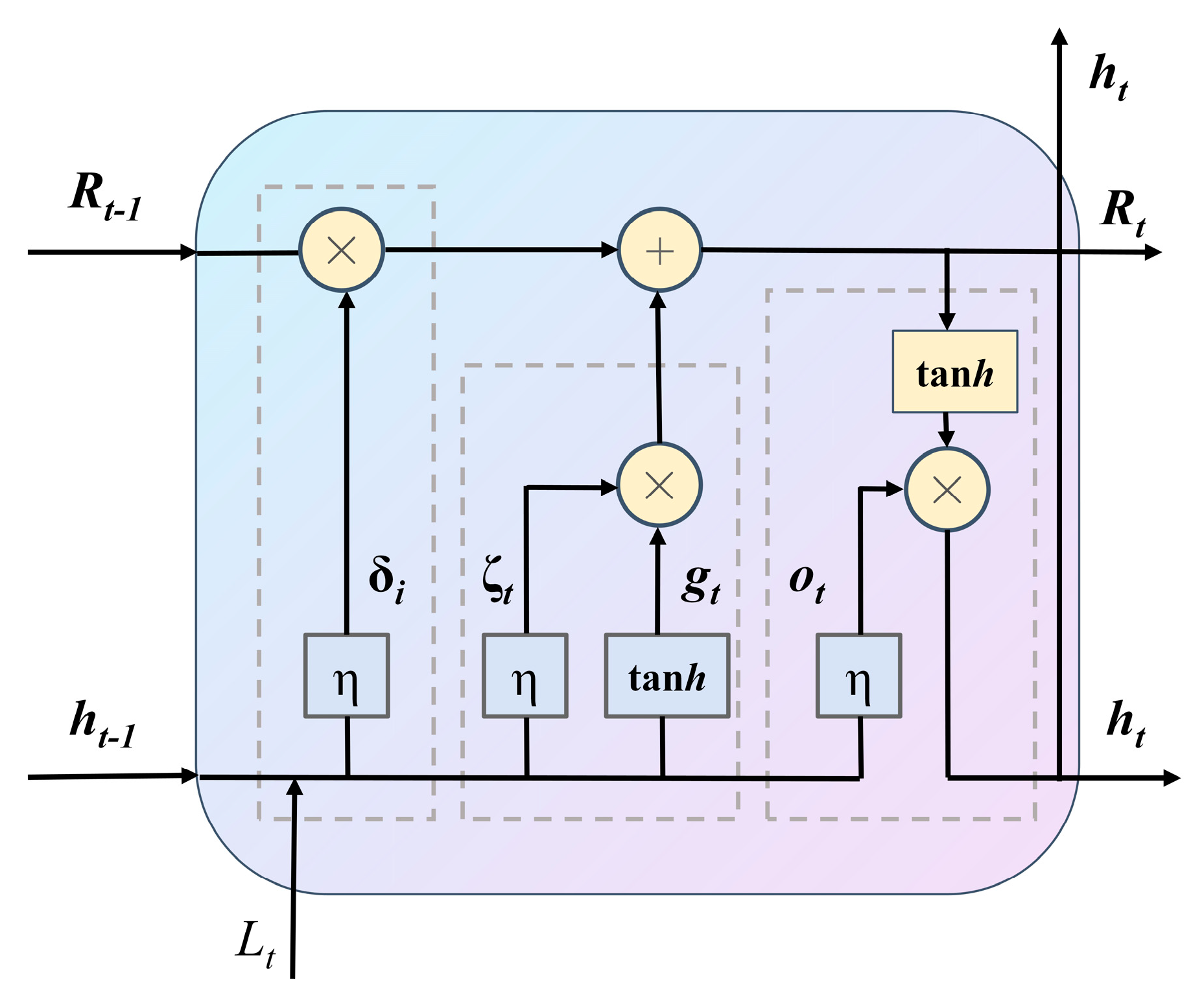
2.4. Bidirectional Long-And Short-Term Memory Networks
LSTM [
24] effectively retains long-term dependent information by introducing memory units and gate mechanisms (forgetting gates, input gates, and output gates), mitigates the phenomenon of gradient vanishing, and provides a better fit for nonlinear prediction. The structure is shown in
Figure 6. BILSTM processes the input sequences in 2 directions, forward and reverse, by means of 2 independent LSTM layers, respectively.
The Oblivion Gate is responsible for controlling the transfer of information and is mainly responsible for extracting some valid information from the external input:
where
represents the forgetting gate’s input, η the activation function,
the forgetting gate’s input weight,
the output state value at the previous instant,
Lt the input amount, and
Rs the forgetting gate’s deviation.
Whether or not fresh data is added to memory is determined by the input part of the gate:
where:
is the input to the input gate;
is the input gate weight;
is the input gate deviation;
is the candidate unit state;
is the memory unit weight; and
is the memory unit deviation.
Where the candidate unit state is denoted by , the memory unit weight by , the input gate weight by , the input gate deviation by , the input gate input by , and the memory unit weight by .
The output gate is responsible for deciding the output.
where:
is the input to the input gate; E
t is the output gate weight; R
t is the output gate deviation;
and
re the forward and backward connection weights;
and
are the forward and backward output state values; and
is the output gate deviation.
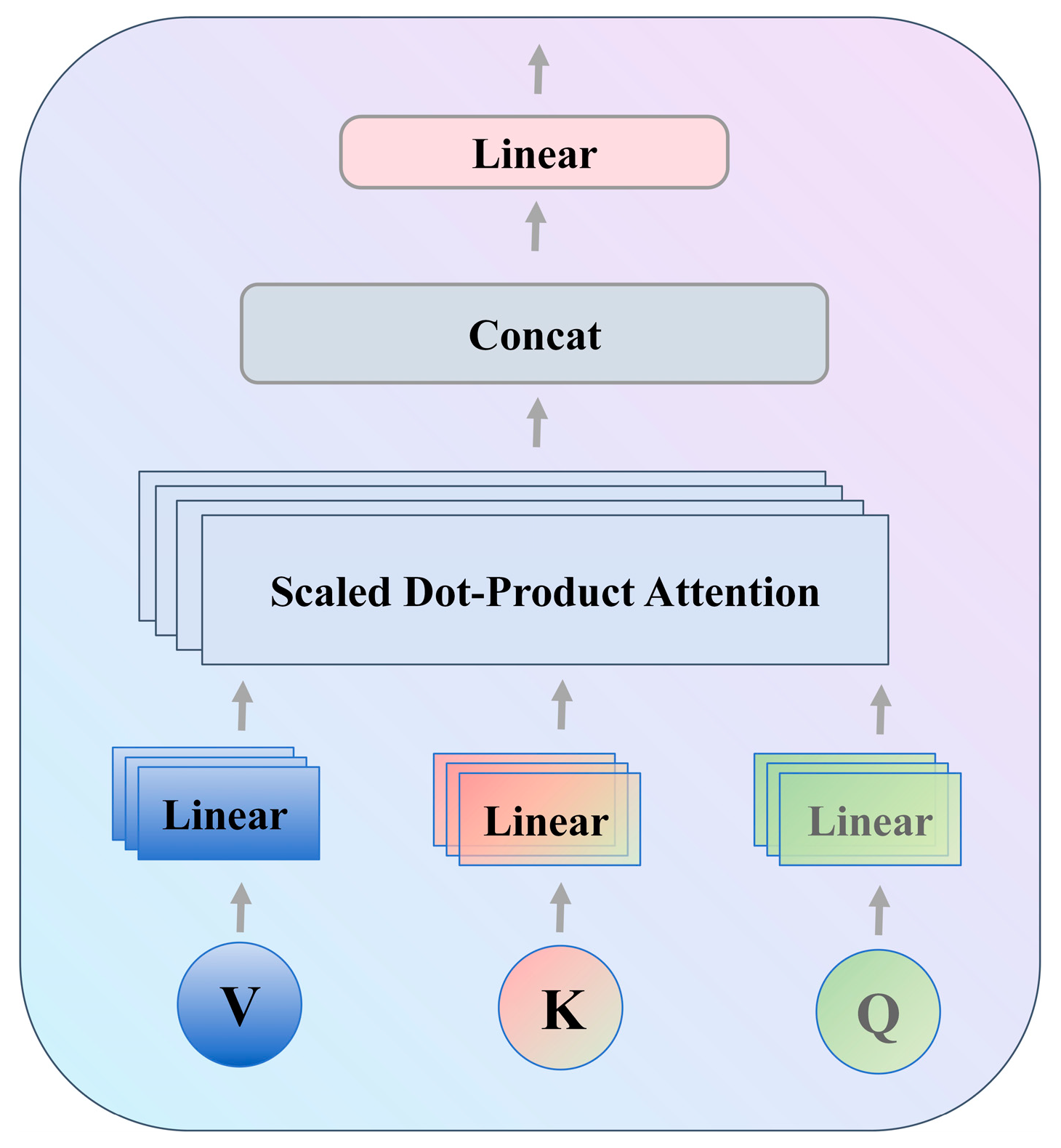
2.5. Cross-Attention Mechanism
The cross-attention mechanism’s computation method is comparable to that of the self-attention mechanism and is based on the calculation of Query, Key, and Value: A self-attention mechanism’s queries, keys, and values originate from a single input sequence, whereas a cross-attention mechanism’s queries originate from one input sequence and its keys and values from another, the structure is shown in the
Figure 7 [
25].
The computational steps are as follows:
First, the input query, key and value are transformed using a linear layer.
The query Q is dot-producted with the key K to determine the correlation score between the two inputs. Using the linear layer, the correlation score between the two inputs is determined. Here is the formula.
where,
is the dot product of the query and the keys, which represents the similarity of the two sequences at different positions, and
is the dimension of the keys, which is used as a scaling factor to avoid too large values.
Calculate the attention weights: convert these similarities into probability distributions by means of the softmax function, which represents the attention weights of the query for each key.
Weighted summation: these attention weights are applied to the values V to end up with the output vector. This is equivalent to extracting the attention information from the sequence of values and feeding it into the next network layer.
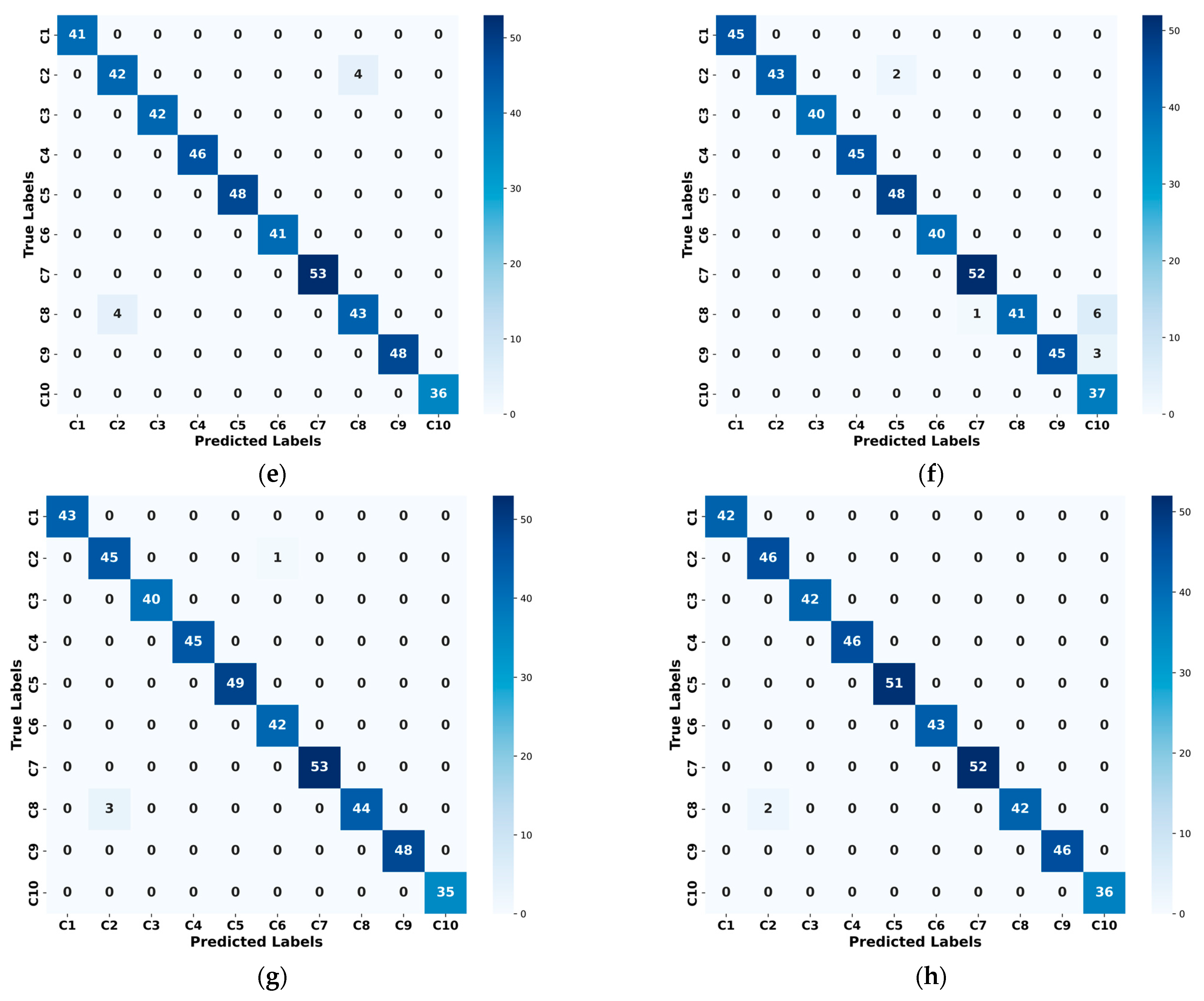
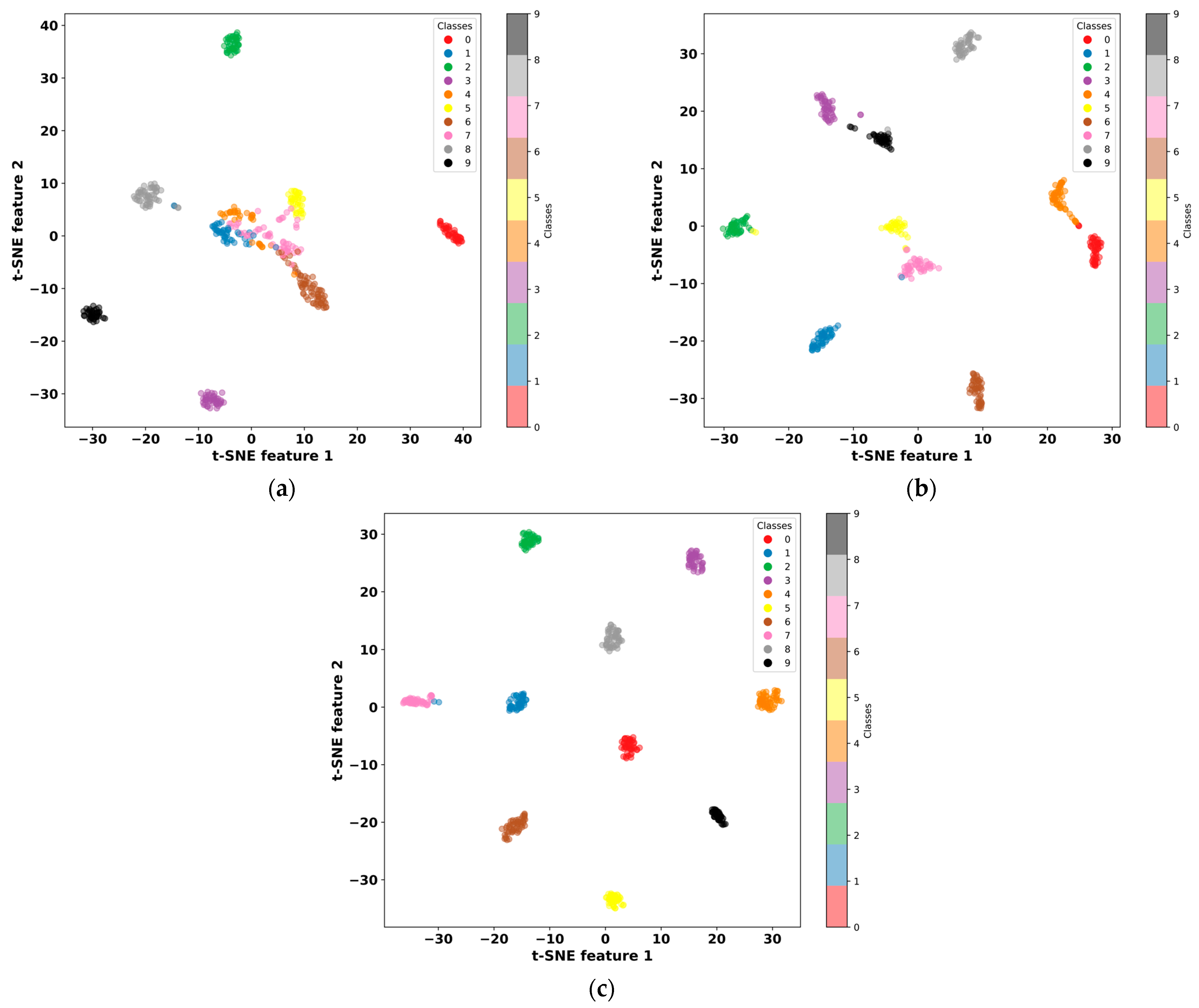
3. Three-Channel Feature Fusion Model Based on Improved Resnet-BiLSTM
In order to solve the problem of bearing defect diagnostics under different load scenarios, this study proposes a unique three-channel feature fusion technique based on the integration of bidirectional long and short-term memory networks and an improved residual neural network. First, the Markov variation field and continuous wavelet transform are used to convert the one-dimensional data into picture form. The 2D-ResNet-BiLSTM structure is then used to extract features from the two types of images independently, which are then supplied into the cross-attention mechanism by weighted fusion. Simultaneously, the fully connected layer classifies the one-dimensional signals that have been retrieved from the 1D-ResNet-BiLSTM structure and paired with the 2D features to feed into the cross-attention mechanism.
Figure 8 depicts the general model structure of the suggested approach.
The one-dimensional data has an initial shape of 32 × 1024, which is extended to a dimension of 32 × 1 × 1024 by the unsqueeze (1) operation in PyTorch and input into the 1D-Resnet-BiLSTM structure after continuous wavelet and Markov variation field processing, the data is converted into a two-dimensional image with a shape of 32 × 224 × 224 × 3 and input into the 2D-Resnet-BiLSTM structure. Each Resnet module contains a Bottleneck Block and an Identity Block, arranged in the order shown in
Figure 8; the specific output of each feature extraction module is shown in
Table 1.
The features processed by continuous wavelet transform and Markov variation field are weighted and fused and input into the cross-attention mechanism, which is calculated as shown in Equation (19):
where
ϑ1 =
ϑ2 = 0.5, C is the feature extracted by the continuous wavelet image transform channel, and M is the feature extracted by the Markov transform field image transform channel.






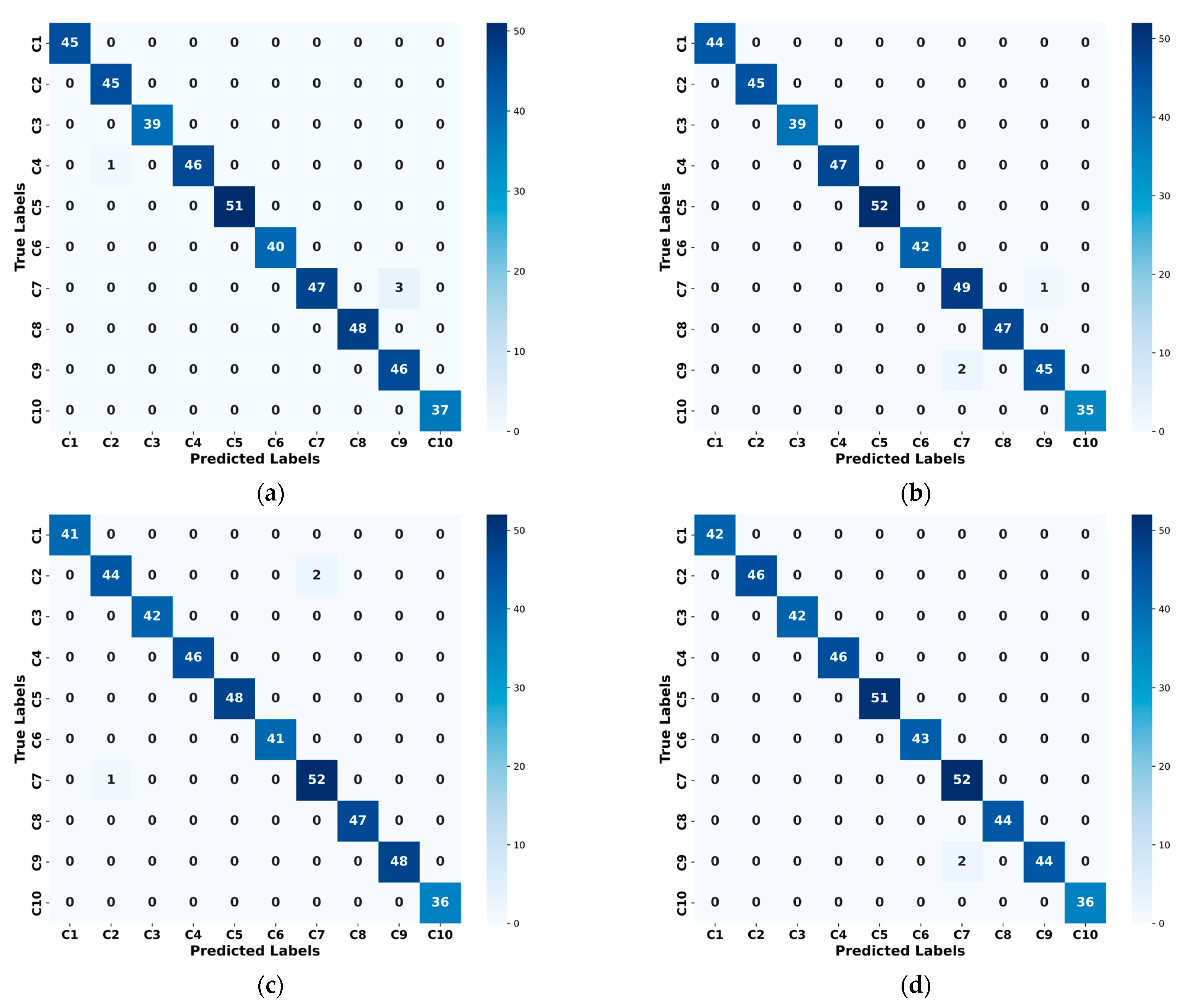



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}