1. Introduction
The field of system identification focuses on the development and analysis of estimation methodologies for system models using experimental data, i.e., estimating the set of system models that best fit measurements [
1,
2,
3,
4]. The formulation of system identification algorithms is generally based on a stochastic problem, where measurement errors are treated as stochastic processes that can affect the accuracy of the estimates of the system model parameters. The measurement error behavior, modeled as Gaussian or other symmetric distributions [
1,
5], is a classical assumption for the development of estimation algorithms. However, real-world dynamic systems can be affected by uncertainty sources with asymmetric distribution behavior, and the estimation algorithms perform poorly under symmetric distribution assumptions [
6]. In this context, it is crucial to address the asymmetries in error models, especially for multiple-input multiple-output (MIMO) systems that require more flexible representation of the uncertainty behavior.
Many system identification algorithms in the literature have been developed under the Maximum Likelihood (ML) principle, motivated by its valuable statistical properties [
1,
3]. This approach has been used in various fields of application under symmetric and asymmetric distribution assumptions, ranging from modeling simple single-input single-output (SISO) systems, such as dynamic systems with a Finite Impulse Response (FIR) structure [
7], systems with quantized data [
8], non-linear systems [
9,
10], astronomy [
11,
12], estimation [
13], medicine [
14], and communications [
15], among others. Similarly, ML estimation approaches in the time domain [
1,
2] and the frequency domain [
16] have been considered for MIMO systems, with applications in robust control [
17,
18], power electronics [
19,
20], and biomedical engineering [
21], to mention a few.
In particular, ML estimators are asymptotically unbiased—that is, the estimated values approach the
true values when the number of measurements is large. Nevertheless, if the set of measurements is small, the estimates deviate from the
true values as a result of the measurement noise variance [
1,
2]. However, there are scenarios in which a large number of measurements are available and the estimated models change between estimations because there exist sources of uncertainty that the system model does not incorporate [
22,
23]. In [
24], the authors proved that Bayesian methods yield more accurate estimates than classical ML estimation when a kind of exponential distribution assumption is considered to handle censoring data. In [
25], the analysis of various approaches to estimate the parameters of a class of exponential distribution was addressed. The authors considered censored samples with mechanical and medical data, obtaining better performance using a Bayesian approach with asymmetry assumptions than using the ML method.
To illustrate the behavior of biased ML estimates, we consider the discrete-time system models shown in
Figure 1 as two-input and two-output (
) MIMO linear dynamic systems, where
is the output signal,
denotes the input deterministic signal,
is the measurement noise signal, and
corresponds to the backward shift operator (
). The main goal is to obtain an ML estimate of the vector of parameters,
, that parameterizes the MIMO system model
. The estimates are computed from the measurement set
for both the system model shown in
Figure 1a, referred to as
Model I, and in
Figure 1b, called
Model II, where
N is the data length. Without loss of generality, we assume that all transfer functions in
Figure 1 are second-order FIR–MIMO systems. For
Model I, an additive measurement noise
is considered. Similarly, for
Model II, we add the term
, parameterized by a stochastic vector of parameters
, which models structural and parametric uncertainties in the MIMO system.
We perform 50 numerical simulations to obtain different data sets
. Then, for each data set, the MIMO system model,
, is estimated for both
Model I and
Model II using the Prediction Error Method (PEM) for MIMO systems [
2]. The principal gains for each estimated MIMO system model are computed. The principal gains are important characteristics used to assess the robustness of the system model to plant variations, its sensitivity to disturbances, and for designing robust multivariable control strategies to ensure stability and performance margins [
19,
26,
27]. In
Figure 2 and
Figure 3, the blue and red shaded regions represent the area in which the magnitudes of the largest,
, and smallest,
, principal gains, respectively, of 50 estimations lie. The solid lines (blue and red colors) represent the principal gains of the
true MIMO system model
. In
Figure 2a, we observe small estimation biases when the number of measurements used for the ML estimations is large (
). These biases increase as the number of measurements decreases (
), as shown in
Figure 2b. In contrast, in
Figure 3, given the incorporation of parametric uncertainties with the term
, the estimated MIMO system model yields biased principal gains for both large and small data lengths (see
Figure 3a and
Figure 3b, respectively). Based on this, it is desirable to develop system identification methodologies to provide estimated models capable of quantifying the error-model that provides parametric and/or structural uncertainties.
One alternative is to consider the uncertainty model as part of the estimation algorithm, combining a
nominal model with an
error-model. This idea can be adopted for designing robust control systems based on the
norm [
28,
29] or variable–structure controllers [
30]. This approach to model error modeling has been addressed using a deterministic framework, in which the error model is bounded by a set of possible solutions [
31]. However, this methodology has been developed for SISO system models and also does not guarantee that the set of solutions adequately describes the uncertainty in the corresponding dynamic system. In [
23], the uncertainty modeling is based on residual dynamics calculated from an available nominal SISO system model using PEM.
On the other hand, the Stochastic Embedding (SE) approach has been used to describe uncertainty in dynamic systems by assuming that the system model is a realization that belongs to a probability space and that the parameters that define the error-model are characterized by a probability density function (PDF). In this context, the error-model can be quantified utilizing an ML estimation that treats the error-model parameters as hidden (latent) variables and then solving the associated optimization problem via the Expectation-Maximization (EM) [
32] algorithm under Gaussian assumptions for the error-model distribution [
33]. In [
34], a Bayesian approach is adopted to jointly characterize the nominal system model and the error-model as realizations of random variables under certain
prior distributions; then, the posterior distributions of the system model parameters are estimated. However, this approach does not provide a separate derivation of a nominal system model and an error-model.
In [
35], a more flexible scenario is proposed in which the error-model distribution can be represented as a Gaussian Mixture Model (GMM). Then, an iterative EM-based algorithm is developed to solve the estimation problem for both the parameters of the nominal system model and the Gaussian mixture parameters that define the error-model distribution. GMMs have traditionally been used in filtering [
36,
37], communications [
38], tracking [
39], and probabilistic modeling [
40], among others. The flexibility of GMMs lies in the fact that they can approximate non-Gaussian PDFs according to the Wiener approximation theorem, which establishes that any PDF with compact support can be approximated as a linear combination of Gaussian distributions [
41]. This idea has been utilized to develop estimation algorithms under non-Gaussian assumptions for dynamic systems (see, e.g., [
6]). However, this approach has been considered only for a SISO dynamic system with a multiplicative error-model structure.
In this paper, we extend the SE approach adopted in [
35] to a class of MIMO linear dynamic systems considering an additive or a multiplicative structure for modeling the error-model term under non-Gaussian assumptions. We develop an ML estimation algorithm with the SE framework to estimate separately the MIMO nominal system model and the non-Gaussian multivariate error-model distribution as a GMM. Combining the SE approach with a linear combination of Gaussian distributions produces flexible scenarios in which the non-Gaussian distribution that describes the uncertainty is not a GMM but can be approximated by one. The main contributions of the paper are the following:
- (a)
A Maximum Likelihood methodology using the SE approach is developed to model parametric and structural uncertainties in a class of MIMO linear dynamic systems. The resulting estimated model combines a nominal MIMO model with an additive or multiplicative multivariate error-model distribution represented as a GMM.
- (b)
An iterative EM-based algorithm is proposed to solve the optimization problem associated with the ML estimation, obtaining the estimator for the MIMO nominal system model parameters and closed-form expressions for the estimators of the multivariate GMM parameters that characterize the error-model PDF.
The paper is organized as follows:
Section 2 outlines the problem of interest, which considers modeling the error-model for MIMO linear dynamic systems using the SE approach. In
Section 3, the estimation problem using the ML principle within GMMs is addressed. In
Section 4, an iterative EM-based algorithm is developed to address the associated ML estimation problem. Numerical simulations, considering scenarios with additive and multiplicative uncertainty models, are shown in
Section 5. Finally, in
Section 6, we present our conclusions.
3. Maximum Likelihood Estimation for Multivariable Model Error Modeling Using GMMs
Typically, the analysis of uncertainty in MIMO systems has been addressed within a deterministic context, assuming that this uncertainty is bounded [
46,
47]. In contrast, in the SE framework, a stochastic approach is adopted. Specifically, in this approach, we assume the existence of a PDF parameterized by a vector of parameters,
, that describes the stochastic behavior of the vector of parameters of the error-model,
[
22,
35]. In order to obtain the ML estimator for the nominal system model and the error-model PDF in (
1), we consider that the observed data,
, and the data from the input signal,
, are sets of measurements from each independent experiment
r. Then, the MIMO dynamic system in (1) can be described as follows:
Additive error-model (
2):
with
Multiplicative error-model (
3):
with
where
, ⊗ represents the Kronecker product,
corresponds to the input signal
filtered by the nominal model
,
,
, and
. The term
represents the output response of the nominal model
in (
1). The terms
and
are the output response of the additive error-model or multiplicative error-model, respectively, and
. Notice that the term
implies the structure of the nominal model
in (
4) within the data of the input signal
. The terms
and
correspond to the error-model structure,
in (
9), which can refer to an additive error-model in (
2) or a multiplicative error-model,
in (
3), respectively.
The vector of parameters to be estimated is defined as
, where
in (
11) denotes the nominal model parameters,
in (
14) gives the GMM parameters that define the error-model PDF in (
13), and
is the covariance matrix of the zero-mean multivariable Gaussian noise signal in (
1). Thus, the ML is obtained as follows:
Lemma 1. Consider the vector of parameters to be estimated using (
11)
and (
14)
. Under the standing assumptions, the ML estimator for the MIMO system in (
1)
is given bywhere and are computed as follows: - (a)
If an additive error-model (
2)
is considered, then from (
15)
, we have the following: - (b)
If a multiplicative error-model (
3)
is considered, then from (
18)
, we have the following:
Proof. Consider the set of output measurements
, and the input signal data set
for each experiment
from the MIMO system model in (
1). Then, the MIMO system model in (
1) can be expressed as follows:
where
corresponds to
in (
16) if an additive error-model approach is considered, or
corresponds to
in (
19) if a multiplicative error-model approach is adopted. Then, the likelihood function,
, for the system model in (
28) is
where
is the vector of parameters to be estimated. From the random variable transformation theorem in [
48] and utilizing the GMM in (
13), the likelihood function is obtained by marginalizing with respect to the latent variable,
, as follows:
where
where
I is the identity matrix with appropriate dimensions, and
,
. Then, the log-likelihood function is given by the following:
Let us consider the random variables
x and
y with Gaussian probability density functions
and
, where
C is a constant with appropriate dimensions. Then, using the well-known Woodbury matrix identity [
49], the following identities are satisfied:
where
Using (
36) in (
34), and then solving (
33) using (
35), we obtain the following:
where
The term
corresponds to
in (
16) if an additive error-model approach is considered, or
corresponds to
in (
19) if a multiplicative error-model approach is used. This complete the proof. □
Remark 2. Notice that the estimation of the systems in (
15)
and (
18)
can be handled by using a Bayesian perspective, where both vector of parameters, , are modeled as multivariate random variables with specifics prior distributions. Under this Bayesian approach and for particular system model structures, it is possible to estimate an unified system model of both the nominal model and the error-model [33]. In our proposed SE framework, the structure and complexity of both the nominal system model and the uncertainty model are defined by the user, which provides more flexibility to obtain suitable models. The result in Lemma 1 presents the likelihood function using the simultaneous information from
M experiments to obtain an estimate of the vector of parameters
. This contrasts with the classical ML formulation, where data from a single experiment are used to estimate the model parameters of interest. On the other hand, the term
in (
24) and (
25) represents a regressor matrix constructed from the
r-th experiment data set of the multivariable input
. The term
in (
26) and (
27) is a regressor matrix built from filtering the
r-th multivariable input signal
through the nominal system model
.
Solving the optimization problem in (
22) involves inverting large-dimensional matrices, which can be challenging with gradient-based optimization methods (e.g., quasi-Newton or trust-region). Moreover, the likelihood function utilizes the logarithm of a summation that depends on the number of GMM components, and it becomes difficult to solve when the number of GMM components is large. In this context, formulating an iterative algorithm based on the EM algorithm can be advantageous, since it typically provides closed-form expressions for the estimators of the parameters that define the GMM [
50].
4. An Iterative Algorithm for Model Error Modeling in Multivariable Systems
The Expectation-Maximization algorithm is an iterative optimization methodology used to develop identification algorithms for both linear and nonlinear dynamic systems in the time domain [
51] and in the frequency domain [
52]. In such algorithms, a sequence of parameter estimates
,
, is computed for the parameter vector
, ensuring convergence to a local maximum of the likelihood function associated with the dynamic system of interest [
32]. Specifically, the formulation of the EM algorithm with GMMs adopts a data augmentation approach, in which a discrete hidden random variable models an indicator that determines which GMM component an observation comes from [
50,
53].
In the SE context, formulating an EM-based algorithm can consider the parameter vector
, which defines the error model as the hidden variable [
35]. To solve the estimation problem in (
22), an EM algorithm with GMMs is developed starting from the definition of the likelihood function using the observed data,
, and the hidden variable,
. In other words, we define the likelihood function in (
23) using the complete data set,
. Hence, the EM-based algorithm is given by
where
and
represent the expected value and the PDF of the random variable
a given the random variable
b, respectively.
is the current estimate of the vector of parameters
, and
is the joint PDF of the observations from the
M experiments,
, and the vector of parameters of the error-model from the experiments,
.
is the auxiliary function of the EM-based algorithm. Note that (
45) and (
46) correspond to the
E-step and
M-step of the EM algorithm, respectively [
32,
53]. In general terms, the EM algorithm can be summarized as follows:
- (i)
Choose an initial value for .
- (ii)
For
, compute the
E-step using the auxiliary function
in (
45).
- (iii)
Compute the
M-step to obtain
by solving the optimization problem in (
46).
- (iv)
Go to step (ii) until convergence or until the number of EM algorithm iterations is reached.
Based on the description above, and inspired in the procedure in [
54], the
E-step of the EM-based algorithm can be computed as follows:
Lemma 2. Consider the vector of parameters to be estimated using (
11)
and (
14)
. For the system of interest in (
1)
, the E-step is given bywhere , and are computed as follows: - (a)
If an additive error-model (
15)
is considered, then from (
45)
, we havewhere is the trace operator andcomputing and utilizing (
24)
and (
25)
, respectively, using the current estimations and . - (b)
If a multiplicative error-model (
18)
is considered, then from (
45)
, we havewherecomputing and utilizing (
26)
and (
27)
, respectively, utilizing the current estimations and .
Proof. Consider the log-likelihood function
in (
33) as follows:
where
with
given in (
34). The term
can be expressed as follows [
54]:
where
Using Jensen’s inequality, it can be shown that the term
is a decreasing function for any value of
[
54]. From (
34)–(
36), the term
can be expressed as follows:
where
Let us consider the following identity for a random variable
z:
where
and
. Using (
65) to compute
in (
60), we obtain the following:
where
and
are computed utilizing (
39)–(
41) as follows:
Using (
66) in (
60), and solving the integral utilizing (
36), we obtain the following:
where
is given in (
66) and
where
is given in (
62). Finally,
corresponds to
in (
16) if an additive error-model approach is used, or
corresponds to
in (
19) if a multiplicative error-model approach is considered. Then, substituting (
70) in (
57), we obtain directly the auxiliary function
in (
47). This completes the proof. □
From Lemma 2, the term
in (
48) represents the posterior probability that the observations from the
r-th experiment,
, comes from the
l-th GMM component defining the PDF of the error-model [
55,
56]. On the other hand, to compute the
M-step of the EM-based algorithm, we need to solve (
46). Since it is not possible to obtain a closed-form solution for all the estimators of the parameters of interest, we define a solution based on the coordinate descent algorithm and on the concept of Generalized EM as follows (see, e.g., [
57,
58]):
- (1)
Fix the vector of parameters
at the current estimate
in (
47) and solve (
46) with respect to the GMM parameters
in (
14) and the noise variance
to obtain the estimates
and
.
- (2)
Fix the estimated values
and
in (
47) and solve (
46) with respect to
to obtain the estimate
.
From Lemma 2, the M-step of the proposed EM-based algorithm can be computed as follows:
Theorem 1. Consider the MIMO system given in (
1)
and the vector of parameters to be estimated . Under the standing assumptions, the solution of the optimization problem stated in (
46)
utilizing the auxiliary function (
47)
is given by the following:Then, the M-step in the proposed EM-based algorithm can be carried out as follows: - (a)
If an additive error-model (
15)
is considered, the estimators (
72)–(
76)
are computed using in (
50)
, in (
51)
, and as follows: - (b)
If a multiplicative error-model (
18)
is considered, the estimators (
72)–(
76)
are computed using in (
54)
, in (
55)
, and as
Proof. Using (
70) and (
71), the auxiliary function
in (
47) can be expressed as follows:
Taking the derivative of (
79) with respect to
and equating to zero yields
Then, we obtain the following:
From (
81), if we consider an additive error-model, then
is equal to
in (
50) and we directly obtain (
73). If we consider a multiplicative error-model, then
corresponds to
in (
54).
Next, taking the derivative of (
79) with respect to
and equating to zero yields
Then, we obtain
as follows:
From (
83), if we consider an additive error-model, then
is equal to
in (
50),
is
in (
51), and we directly obtain (
74). If we consider a multiplicative error-model, then
is equal to
in (
54) and
is
in (
55).
Then, taking the derivative of (
79) with respect to
and equating to zero yields
Notice that
. Then, we obtain
If we consider an additive error-model, then
is equal to
in (
50),
is
in (
51), and we directly obtain (
75). If we consider a multiplicative error-model, then
is equal to
in (
54) and
is
in (
55).
For the parameter
, we use a Lagrange multiplier in order to deal with the constraint on
. Then, from (
79), we define the Lagrangian
as follows:
Taking the partial derivatives of (
87) with respect to
and
and equating to zero, we obtain
Then, taking summation over
in (
88) and utilizing (
89), we have
Substituting (
90) in (
88) yields:
Notice that
. Then, we obtain directly (
72).
Finally, from (
86), substituting
by
, we can obtain (
77) and (
78) for an additive error-model and a multiplicative error-model, respectively. □
The results of Theorem 1 show the closed-form expressions for both the error-model distribution parameters as a GMM and the noise variance are obtained. In addition, the estimation problem of the nominal model parameters in (
76) can be solved utilizing traditional gradient-based optimization methods (see, e.g., [
6,
59]). Finally, the proposed iterative algorithms for an additive error-model and an multiplicative error-model with GMMs are summarized in Algorithm 1 and Algorithm 2, respectively.
| Algorithm 1 Iterative algorithm with GMMs for additive error-model |
Inputs , , M, K, , , and , for . Outputs , and for . - 1:
- 2:
procedure
E-step - 3:
Compute and from ( 24) and ( 25) for , and . - 4:
Compute from ( 48) for , and . - 5:
Compute and from ( 50) and ( 51) for , and . - 6:
end procedure - 7:
procedure
M-step - 8:
Estimate , from ( 72)–( 75). - 9:
Compute from ( 77) using and . - 10:
Estimate by solving ( 76). - 11:
end procedure - 12:
if stopping criterion is not satisfied then - 13:
, return to 2 - 14:
else - 15:
, , - 16:
end if - 17:
End
|
| Algorithm 2 Iterative algorithm with GMMs for multiplicative error-model |
Inputs , , M, K, , , and , for . Outputs , and for . - 1:
- 2:
procedure
E-step - 3:
Compute and from ( 26) and ( 27) for , and . - 4:
Compute from ( 48) for , and . - 5:
Compute and from ( 54) and ( 55) for , and . - 6:
end procedure - 7:
procedure
M-step - 8:
Estimate , from ( 72)–( 75). - 9:
Compute from ( 78) using and . - 10:
Estimate by solving ( 76). - 11:
end procedure - 12:
if stopping criterion is not satisfied then - 13:
, return to 2 - 14:
else - 15:
, , - 16:
end if - 17:
End
|
5. Numerical Simulations
In this section, we consider three simple examples to show the benefits and performance of our proposed iterative algorithm for model error modeling with an SE approach in MIMO systems described in (
1). Using numerical simulations is a common way to verify the performance of new estimation algorithms, as it allows the exploration of different scenarios that cannot be safely tested in experimental design [
60,
61].
All the numerical examples consider a two-input, two-output (
) MIMO system. The first example adopts the SE approach with an additive error-model in (
2). The nominal system model,
in (
4), corresponds to an FIR system model, i.e.,
for
and
. The error-model in (
9) corresponds to a second-order FIR system model with a two-component GMM for the error-model distribution. Similarly, for the second example, FIR system models for both nominal model in (
4) and the multiplicative error-model in (
3) are considered. The error-model distribution corresponds to a two-component overlapped Gaussian mixture distribution. In both examples, it is assumed that there is no modeling uncertainty at low frequency. Furthermore, a traditional MIMO system estimation is performed using an FIR structure for each
using a non-linear least squares (NLSs) search method for the prediction error minimization, implemented via the Matlab
tfest() function. This estimation aims to validate the error-model dynamic behavior using a data set different from the one used to estimate the MIMO system model parameters with the SE approach.
On the other hand, in the third numerical example, we focus on analyzing the flexibility of the proposed iterative algorithm for the MIMO system in (
1). In this case, the model
in (
1) is defined by the model structure in (
5) with
,
, for
and
. Here,
denote the nominal values, and
models a parametric uncertainty with a non-Gaussian distribution that does not correspond to a GMM.
For all the examples, the simulation setup is as follows:
- (1)
The data length is .
- (2)
The number of independent experiments is .
- (3)
The number of Monte Carlo (MC) simulations is .
- (4)
The stopping criterion is given by
or when 1000 iterations of the EM-based algorithm have been reached, where ‖·‖ denotes the vector norm operator.
The initial values for the proposed EM-based algorithm are obtained as follows:
- (I)
For the nominal MIMO model structure
,
M estimates,
and
, are obtained from the set of independent experimental data. For this purpose, the
bj() function from Matlab’s System Identification toolbox is used, considering a Box–Jenkins model structure [
1,
2]. Then, the initial values
and
correspond to the average of all the corresponding estimates.
- (II)
For the linear regression structure of the MIMO error-model,
,
M estimates
are obtained using the
bj() function with the corresponding FIR system model. Then, for the set of estimates
, the following procedure based on the
k-means algorithm is used [
50]:
- (II.1)
The mixing weight, , is chosen equal to .
- (II.2)
The covariance matrix is chosen to be diagonal and identical to the sample variance of the estimates .
- (II.3)
The mean, , is chosen to be evenly spaced between the maximum and minimum estimated values of each component of the estimates .
The initialization methodologies for iterative EM algorithms with GMMs have been extensively studied in the literature (see e.g., [
62,
63,
64]), where it has been shown that a careful initialization of the Gaussian mixture parameters yields accurate estimates and also improves the rate of convergences. These methods typically assume that a GMM describes a probabilistic model of the observed data and require a previous short run of an EM algorithm to obtain the initial values of the GMM parameters. However, the problem addressed with the SE approach is different, since we assume that the multivariate GMM describes the PDF of a hidden variable that defines the dynamic behavior of the error-model. Our experience shows that the procedure previously described yields accurate estimates of the system model parameters without requiring additional runs of the EM algorithm.
5.1. Example 1: Multivariable FIR System Model with Additive Error-Model
Consider the MIMO system in (
1) with an additive error-model (
2) as follows:
where
,
, and the
true values (but unknown) are
,
,
,
,
,
,
, and
. The deterministic input signal is
,
, and the noise signal is
,
. We also consider that
—i.e., we focus on uncertainties in the MIMO system at high frequencies with
. Then, the error-model distribution as a GMM with
is given by
and
The vector of parameters to be estimated is
, with
,
, and
.
Figure 4 shows the results of the parameter estimates for the nominal MIMO model
. The large red cross indicates the
true value of the parameter vector
. The black circles represent the estimated nominal model values for all Monte Carlo simulations.
Table 1 presents the mean values of the estimated nominal model parameters and the noise variance across all MC realizations. We observe a small bias in the estimates compared to the
true values. This effect can be mitigated by utilizing a larger number of measurements,
N, in each independent experiment. The standard deviation of the estimates is similar in each case, with a value close to
.
Figure 5 shows the estimated multivariate GMM for the distributions of the error-model parameters
.
Figure 5a,b show the estimated GMM for
and
, respectively. The Gaussian mixture distributions are drawn utilizing the mean values of the estimated GMM parameters for all MC simulations. We observe the bimodal behavior of the error-model distributions described in (
94).
On the other hand, to describe the dynamic behavior using the SE approach, we consider computing the frequency response of the principal gains of the estimated MIMO system model. The principal gains provide a metric to evaluate the estimated MIMO system model performance in terms of how, and to what extent, different linear combinations of the input signals are amplified in the outputs signals, as well as the degree of channel coupling [
17,
51]. Here, we compute the principal gains of
M realizations of the MIMO system model given by
with
, where
is the estimated MIMO nominal system model from the estimated values in
Table 1, and
is obtained from
M independent realizations of
utilizing the GMM in (
13) with the mean values of the estimated parameters,
, from all MC simulations. In addition, we consider estimating the MIMO system
using the NLS [
1] algorithm with a second-order FIR multivariable system model. In order to validate the error-model behavior, we consider the data from 25 independent experiments, and we obtain an estimate of a second-order FIR multivariable model for each independent experiment.
Figure 6 shows the magnitude of the principal gains corresponding to the estimated MIMO system model using the SE approach. In
Figure 6a, the solid blue line represents the largest principal gain,
, of the estimated nominal MIMO system model. The blue-shaded region corresponds to the area that described the error-model behavior with respect to the largest principal gain. Similarly, in
Figure 6b, the red solid line is the smallest principal gain,
, of the estimated MIMO system model. The red-shaded area corresponds to the estimated uncertainty region in which the smallest principal gains of the estimated
true MIMO system lie. In both cases, the dotted black lines represent the principal gains computed from the estimated MIMO system models using the NLS algorithm. We observe that the estimated principal gains lie in the shaded regions (blue and red regions) that described the error-model behavior with the SE approach.
5.2. Example 2: Multivariable FIR System Model with Multiplicative Error-Model
In this example, we consider the MIMO system in (
1) with a multiplicative error-model (
3) as follows:
where
and
, and the
true values of the nominal model are
,
,
,
,
,
,
, and
. The input signal corresponds to
,
, and the noise signal is
,
. We consider that
—i.e., we focus on uncertainties in the MIMO system at high frequencies with
. Then, the error-model distribution as an overlapped GMM with
is given by
and
As in the previous example, the vector of parameters to be estimated is
, with
,
, and
.
Figure 7 presents the nominal MIMO system model parameter estimates. The large red cross corresponds to the
true value of the parameters for the nominal system model. The black circles represent the parameter estimates of the nominal MIMO system model for all MC realizations.
Table 2 summarizes the mean values of the estimated nominal system model parameters and the noise variance. In contrast to the previous example, we observe that the multiplicative error-model approach improves the estimation accuracy, as the dynamic behavior of the nominal model weights the model uncertainty. In this case, the standard deviation of the estimates remains similar, around
.
In
Figure 8, the estimated GMM distribution for the error-model parameters
is shown.
Figure 8a,b show the estimated GMM for
, and
, respectively. The GMM distributions are computed utilizing the mean values of the estimated GMM parameters for all MC simulations. We observe the overlapped behavior of the multivariate error-model distribution described in (
98).
For this example, we compute the principal gains of the
M realizations of the MIMO system model
with
, where
is the estimated MIMO nominal system model where
is given by the estimated values in
Table 2, and
is obtained from
M independent realizations of
utilizing the GMM in (
13) with the mean values of the estimated parameters,
, from all MC realizations. We also estimate the system
using the NLS [
1] algorithm with a second-order FIR multivariable system model. We consider the data from 25 independent experiments and we obtain an estimate of a second-order FIR multivariable model for each independent experiment in order to validate the uncertainty dynamic behavior.
Figure 9a,b show the magnitude of both the largest and smallest principal gains corresponding to the estimated MIMO system model. The solid blue and red lines represent the largest and smallest principal gains computed from the estimated nominal MIMO system model, i.e.,
and
, respectively. The shaded regions (blue and red) correspond to the error-model region in which the principal gains of the
true system lie. We observe that all principal gains from the estimated MIMO system using the NLS algorithm (black dotted lines) lie in the error-model area, that is, the estimations lie in the uncertainty region described with the SE approach.
5.3. Example 3: A General MIMO System with Non-Gaussian Mixture Error-Model Distribution
In this example, we consider the MIMO system model in (
1) with uncertainties in the parameters of the system model as follows:
where
,
,
,
, and
,
. The parameters
and
are given by
where
,
,
,
,
,
,
,
, and
is uniformly distributed as
.
In the SE framework, we consider a multiplicative error-model and a nominal MIMO system model as follows:
where
,
, and
. The distribution of the parameters
of the error-model in (
103) is considered a GMM with
—that is,
. The vector of parameters to be estimated is
. In this case, the advantage of the proposed algorithm lies in the fact that a non-Gaussian PDF can be accurately approximated by a linear combination of Gaussian distributions [
65]. Gaussian mixture approximations enhance the accuracy of the estimates when Gaussian assumptions are relaxed (see, e.g., [
6,
35]).
In order to validate proposed SE approach for the MIMO system in (
100), we compute the principal gains of
M independent realizations of the vector of parameters
in (
99) with
. The vector of parameters
corresponds to the average of the estimated parameters of the nominal MIMO system model for all MC simulations. The vector of parameters
is computed from a GMM as in (
13) using the average of the estimated Gaussian mixture parameters from the MC simulations. In addition, we estimate the MIMO system model
with the system model structure in (
102) using the NLS algorithm. In particular, we use the measurements of 25 independent experiments and we estimate
for each experiment, that is, for
.
Figure 10a,b show the frequency response of the largest and the smallest principal gains, respectively, for the estimated MIMO system model with the SE approach. The solid blue and red lines represent the largest and smallest principal gain of the estimated nominal MIMO system model,
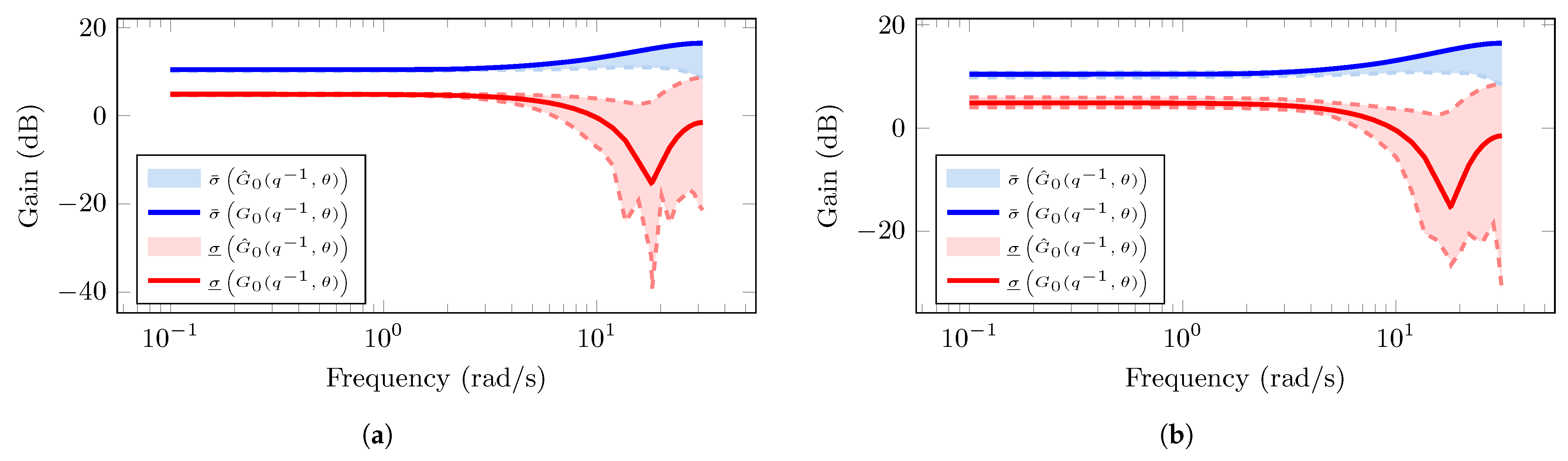
. The two shaded areas are the uncertainty regions in which the principal gains computed from the
M realizations of
in (
99) lie. The dotted black lines represent the principal gains of the estimated MIMO system models using the NLS algorithm. We observe that the principal gains from the estimated MIMO system
lie in the uncertainty regions despite the fact that the SE system model in (
99) does not correspond to the system model structure in (
102).
Remark 3. In the numerical simulations, we consider that the MIMO system model structure (both nominal model and error-model), and the number of components, K, of the GMM are known. However, we can use an information criterion, e.g., Akaike’s information criterion [66], in order to obtain a candidate reduced complexity model that explains the dynamic behavior with good accuracy from a set of system models in which the true system model does not lie; see, e.g., [67]. 







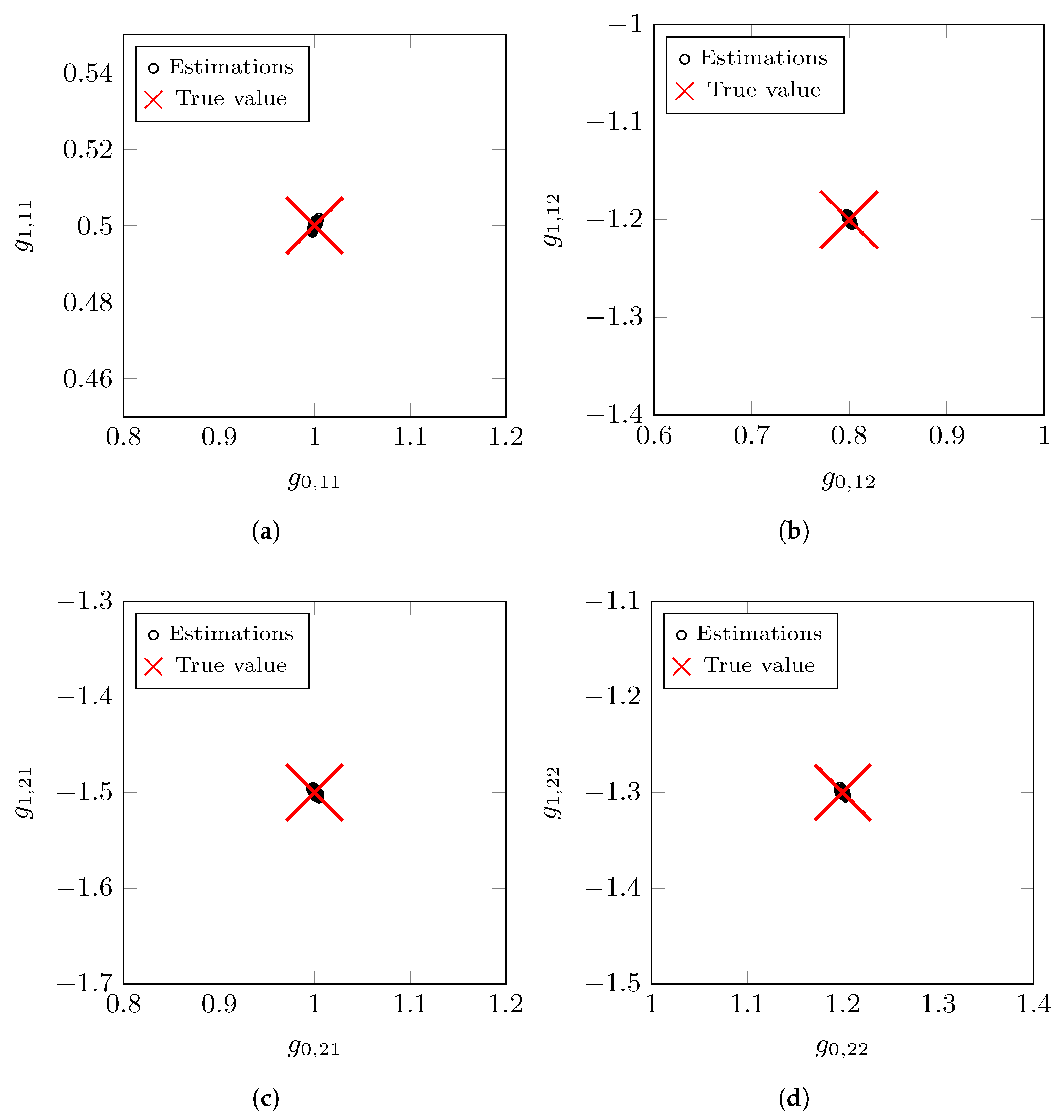




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}