2.1. The Relationship Between the Overall Lifetime Performance Index and Individual Lifetime Performance Index
products with
d parts produced in
d production lines, the lifetime of the
ith part of products denoted by
is assumed to follow the Gompertz lifetime distribution with the shape parameter
and the scale parameter
This distribution is proposed by Gompertz [
28] and the probability density function (p.d.f.), cumulative distribution function (c.d.f.), and the hazard function (h.f.) are given by
and
where
is the scale parameter,
i = 1, …,
d.
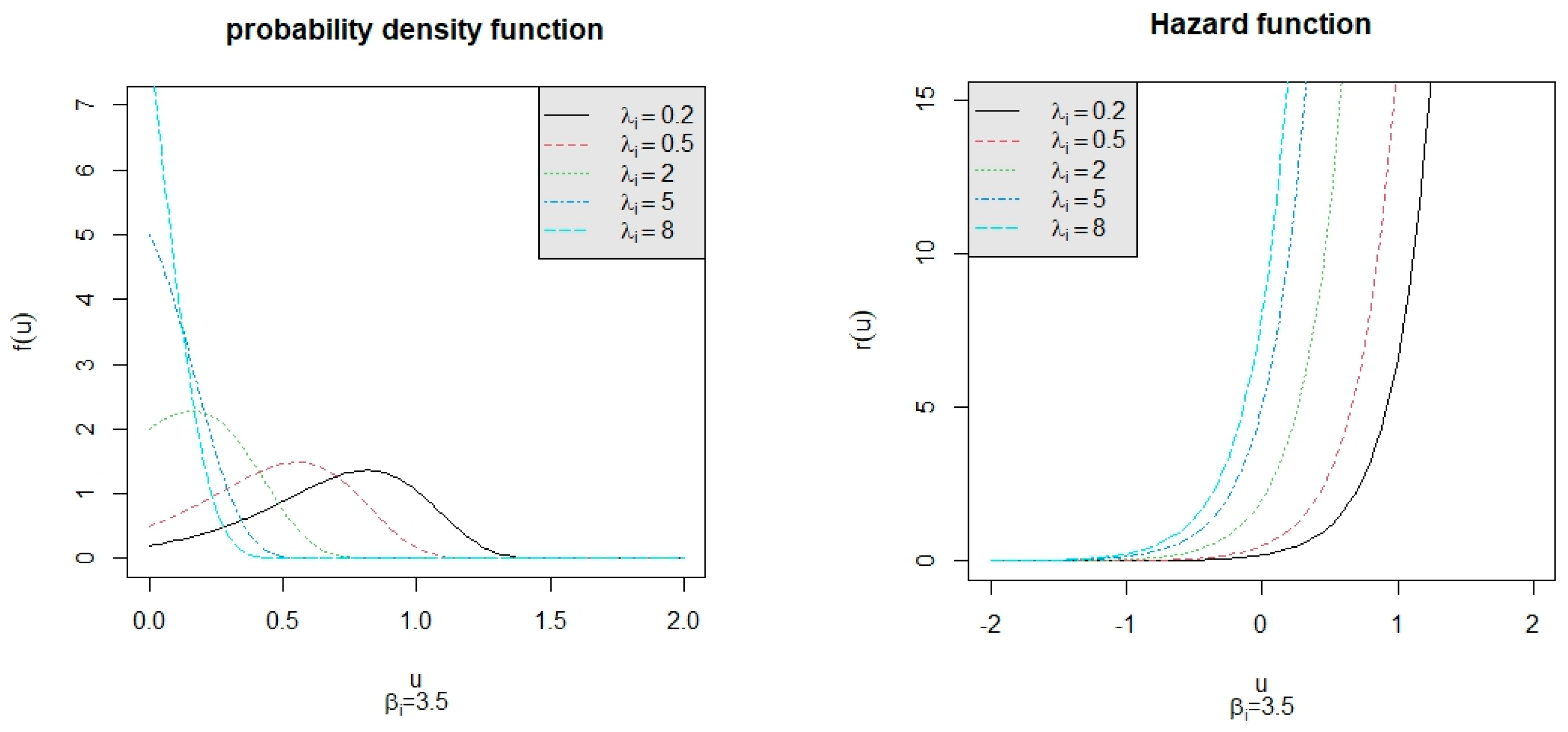
To explore the properties of Gompertz distribution, the p.d.f. and h.f. for
= 0.2, 0.5, 2, 5, 8 under
= 2.5 are depicted in
Figure 1. The p.d.f. and h.f. for
= 0.2, 0.5, 2, 5, 8 under
= 3.5 are depicted in
Figure 2. From the left panels of
Figure 1 and
Figure 2, we observe that the shape of the p.d.f. changes when
changes and the parameter
only affects the degree of data dispersion. Additionally, the right panels of
Figure 1 and
Figure 2 show that the hazard rate increases exponentially as
u increases. These properties make the Gompertz distribution well-suited for modeling aging-related processes where the likelihood of failure increases exponentially with time. Let us compare this model with the Weibull distribution. The Weibull distribution is versatile, supporting various hazard shapes, including increasing, decreasing, and constant rates. While the Weibull model is more versatile and widely used in reliability engineering, the Gompertz model offers unique advantages in scenarios where the failure rate aligns with biological or exponential growth patterns. Its simplicity and focus on exponential hazard rate growth make it a strong choice for aging-related life tests. Because the Gompertz distribution is an asymmetric probability distribution, this research pertains to the subject of asymmetric probability distributions and their applications in diverse fields. For the estimation for different censoring schemes for this distribution, refer to Srivastava [
29].
Let
; then, we have the new random variable
following an exponential distribution with rate parameter
and the p.d.f. of
is given by
The cumulative distribution function (c.d.f.) and the hazard function (h.f.) of
are defined as follows:
To evaluate the larger-the-better lifetime performance, the lifetime performance index introduced by Montgomery [
1] as follows is used in this study. Suppose that
is the specified lower specification limit for
; then,
is the lower specification limit for
. We found that
as the mean and the standard deviation of
. Based on this information, the lifetime performance index for the production of the
ith part, as stated by Montgomery [
1], is defined as
From the above equation, it is observed that this index increases as the hazard rate decreases.
A product on the
ith production line for producing
ith part is considered to be conforming if the related lifetime surpasses
so that the proportion of conforming products for the
ith part is obtained as
Suppose that the productions of
d parts of products in
d production lines are independent. We can find the overall process yield
as
The overall lifetime performance index
CT defined in the work by Wu and Chiang [
24] is employed in this study and it satisfies the following equation:
The index
is designed to have a strictly increasing relationship with the overall process yield
. According to Equations (9) and (10), we yield the relationship between the overall lifetime performance index
and the individual lifetime performance index
as follows:
To present a new overall lifetime performance index when we have d parts of products produced in d dependent production lines, the Bonferroni inequality stated in Lemma 1 is needed.
Lemma 1. Let be d events; then,
Using Lemma 1, we can find the lower bound of the overall process yield as follows:
Set the lower bound of the overall process yield to be
. Let the overall lifetime performance index
satisfy
Observe that
is an increasing function of
Prl. Solving Equation (12), we have the relationship between the overall lifetime performance index and individual lifetime performance index for each production line as follows:
A reasonable assumption in this context is that the capabilities of the production lines are equally important for quality engineers across all product parts. This rational configuration of equal individual lifetime performance indices is defined as follows: .
For the independence case, substituting this configuration into Equation (11), we obtain the relationship between
and
as
Suppose that the analyst desires the overall yield to exceed 0.9277; then, is found to be greater than 0.925 from Equation (10). From Equation (14), the corresponding values of are found to be 0.9625, 0.9750, 0.9812, 0.9850, 0.9875, 0.9893, 0.9906, 0.9917, 0.9925 for d = 2, 3, 4, 5, 6, 7, 8, 9, 10. Observe that the inequality > holds, when d > 1; that is, the equality holds, when d = 1.
For dependence case,
, we obtain the relationship between
and
as
Suppose that the analyst desires the lower bound of the overall process yield Prl to be 0.9277, the value of is found to be 0.925 from Equation (12). The corresponding values of are found to be 0.9632, 0.9756, 0.9818, 0.9854, 0.9879, 0.9896, 0.9909, 0.9919, 0.9927 for d = 2, 3, 4, 5, 6, 7, 8, 9, 10 from Equation (15). Observe that the values of for the dependent case are slightly higher than those for the independent case under the same value of and .
2.2. The Maximum Likelihood Estimators and Their Asymptotic Distributions for the Lifetime Performance Indices
The progressive type I interval-censoring is depicted as follows: For the ith production line for producing the ith part, let n products undergo a life test with m inspection intervals with the predetermined inspection time points (t1, …, tm), where tm is the termination time of this experiment. Once the number of failure units Xij is observed at the time point of tj, Rij products are randomly removed under the removal probability pj, j = 1, …, m. The number of failure units Xij follows a binomial distribution denoted by bin(, qij), where and denotes the cdf for the lifetime variable of the ith part. The number of removal units Rij follows a binomial distribution denoted by bin(, pj), where pj is the pre-assigned removal probability, j = 1, …, m. Once the experiment is completed, the progressive type I interval-censored sample is collected under the censoring scheme of for the ith production line.
Based on the progressive type I interval-censored sample
for the lifetimes of the
ith part of products at the time points
under the progressive censoring scheme of
, we make inferences on the overall lifetime performance index and each individual lifetime performance index. The likelihood function of the censored sample
is
where
We obtain the log-likelihood function as
where
.
By taking the derivative to Equation (17) with respect to the parameter
and equating it to zero, we yield the log-likelihood equation as
The solution of the above derivative of the log-likelihood equation is the maximum likelihood estimator for the parameter
, denoted by
. To show that this solution is indeed attaining the maximum, we take the second derivative of the log-likelihood function as follows:
Since it is negative, the solution for the log-likelihood equation as
should be the maximum likelihood estimator. The other approach to find the maximum likelihood estimator is using the Expectation–Maximization (EM) algorithm for incomplete data. Each iteration of the EM algorithm consists of two steps including the E-step (expectation-step) and the M-step (maximization step). Let
be the failure times in the
jth time interval
and
be the failure times of removing units in time interval
. The log-likelihood function for the complete sample is
Taking derivative with respect to parameter
and equating to zero, we have the log-likelihood equation
To solve the above equation, we have the maximum likelihood estimator of
given by
The expected failure times of
and
are given by
The iterative process for obtaining the maximum likelihood estimator of
with the EM algorithm is in Algorithm 1.
| Algorithm 1: The iterative process for EM algorithm |
- Step 1:
Set the initial value of to be , k = 0. - Step 2:
For the E-step: Calculate the expected failure times of and . Replace and by and in the log-likelihood function given in Equation (20) to have a new log-likelihood function. - Step 3:
For the M-step: The log-likelihood equation is . Solve this equation to have the next value of given by . - Step 4:
Set k = k + 1 and repeat steps 2–4 until converges. Then, is the approximate maximum likelihood estimator of .
|
Referring to Casella and Berger [
29], we can state that the asymptotic distribution of the maximum likelihood estimator
is the normal distribution with the variance given by
where the Fisher’s information number is defined as
.
For the progressive type I interval-censoring, we assume that the number of failures
is following a binomial distribution denoted by
where
Additionally, we assume that the number of progressive censorings at the
jth observation time point is coming from a binomial distribution denoted by
where
is the removal probability for the number of removals
at the
jth inspection time point
.
Based on the conditional probabilities given in Equations (24) and (25), we yield the expected values for
as
Using Equations (22) and (23), we yield Fisher’s information number as
The asymptotic normal distribution of
is denoted as
Applying the property of invariance for the maximum likelihood estimator, we can find the maximum likelihood estimator for the lifetime performance index
as
For this purpose, the Delta method is applied, which is a statistical approach used to approximate the distribution of a function of an estimator, especially when the estimator has a known asymptotic distribution, commonly a normal distribution. Applying the Delta method in Casella and Berger [
29], we yield
where
Referring to the overall lifetime performance index
, we can find the maximum likelihood estimator for
as
Due to
d independent production lines, the asymptotic variance of
is
and its estimator is
. Additionally, we obtain the asymptotic distribution for
as
where
For the dependent case, we can find the maximum likelihood estimator for
as
We can also obtain the asymptotic distribution for
as





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}