
Deep Double Towers Click Through Rate Prediction Model with Multi-Head Bilinear Fusion


Abstract
1. Introduction
- The SENET mechanism is introduced to dynamically learn important features, and enhance the performance of predictive models by improving the quality of feature interactions.
- Drawing inspiration from the concept of bilinear pooling in image classification, a parallel deep double tower structure is proposed to learn differentiated feature interactions.
- Features from different subspaces are aggregated by introducing a multi-head bilinear fusion layer for more fine-grained feature fusion.
- The experimental results of four publicly available datasets effectively validate that the proposed DDT model surpasses existing CTR prediction models in terms of effectiveness.
2. Related Work
2.1. Conventional CTR Prediction Models
2.2. Deep CTR Prediction Models
3. The Proposed Model
3.1. Input Layer
3.1.1. Primitive Feature Embedding
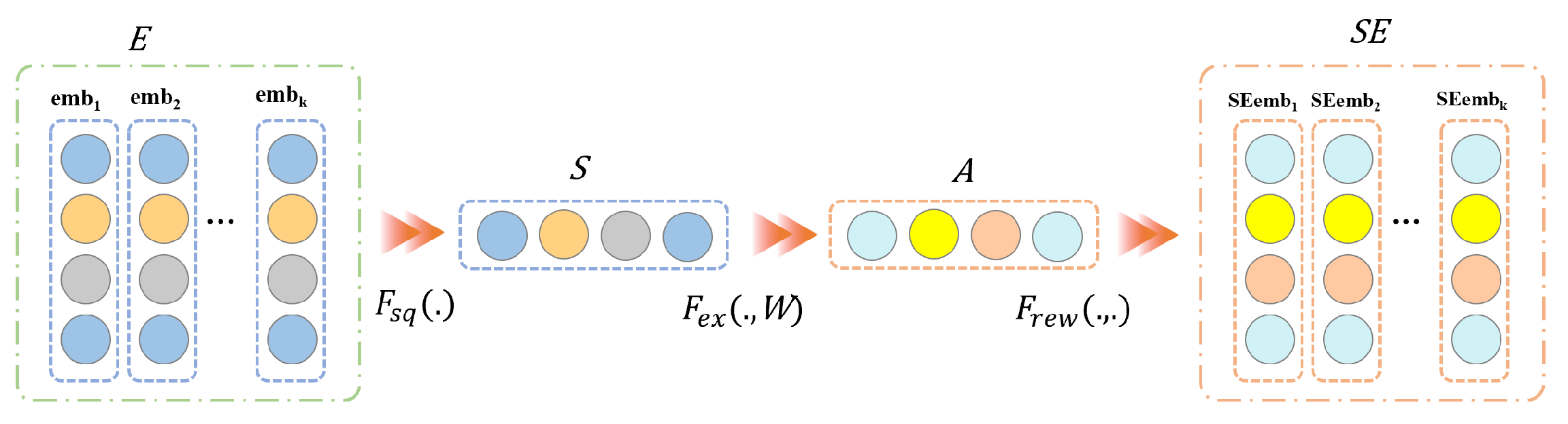
3.1.2. Significant Feature Embedding
3.2. Deep Layer
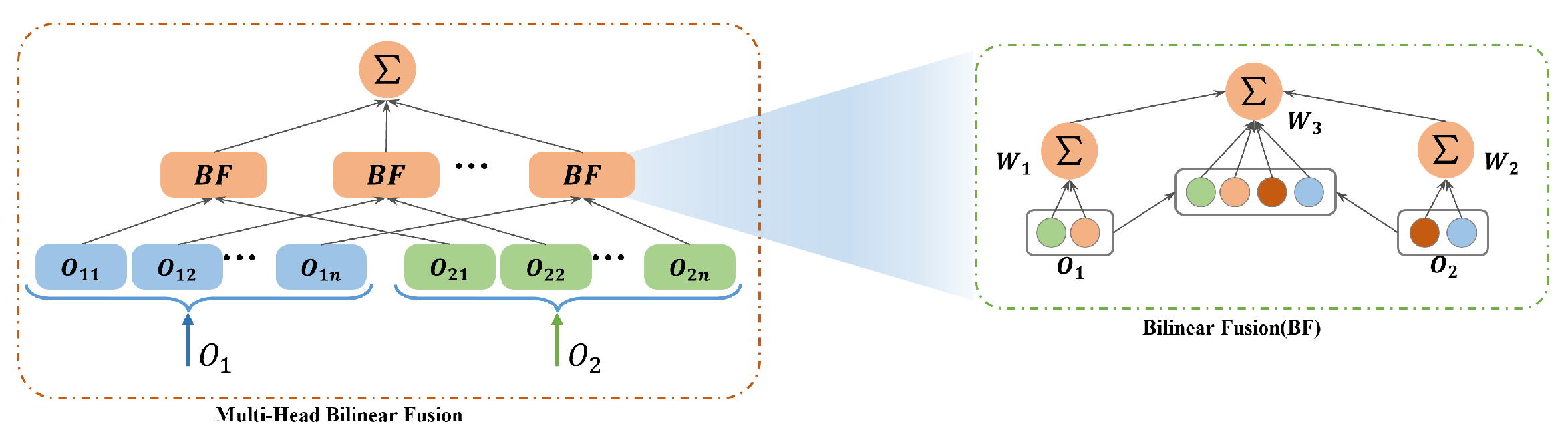
3.3. Fusion Layer
3.4. Output Layer
4. Experiments
4.1. Experimental Settings
4.1.1. Datasets
4.1.2. Evaluation Metrics
4.1.3. Baseline Models
4.1.4. Implementation Details
4.2. Comprehensive Performance
4.3. Parametric Analysis
4.3.1. Impact of the Number of Network Layers
4.3.2. Impact of Dimensionality Reduction Ratio
4.3.3. Impact of Number of Heads
4.4. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, J.; Ma, C.; Zhong, C.; Zhao, P.; Mu, X. Multi-scale and multi-channel neural network for click-through rate prediction. Neurocomputing 2022, 480, 0925–2312. [Google Scholar] [CrossRef]
- Lyu, Z.; Dong, Y.; Huo, C.; Ren, W. Deep match to rank model for personalized click-through rate prediction. AAAI Tech. Track AI Web 2020, 34, 156–163. [Google Scholar] [CrossRef]
- Yang, Y.; Zhai, P. Click-through rate prediction in online advertising: A literature review. Inf. Process. Manag. 2022, 59, 102853. [Google Scholar] [CrossRef]
- Guan, F.; Qian, C.; He, F. A knowledge distillation-based deep interaction compressed network for CTR prediction. Knowl. -Based Syst. 2023, 275, 110704. [Google Scholar] [CrossRef]
- Yang, X.; Liu, Q.; Su, R. Click-through rate prediction using transfer learning with fifine-tuned parameters. Inform. Sci. 2022, 612, 188–200. [Google Scholar] [CrossRef]
- Lauriola, I.; Lavelli, A.; Aiolli, F. An introduction to deep learning in natural language processing: Models, tech-niques, and tools. Neurocomputing 2022, 470, 443–456. [Google Scholar] [CrossRef]
- Yang, L.; Zheng, W.; Xiao, Y. Exploring Different Interaction Among Features For CTR Prediction. Soft Comput. 2022, 26, 6233–6243. [Google Scholar] [CrossRef]
- Luo, Y.; Peng, W.W.; Fan, Y.; Xu, X.; Wu, X. Explicit sparse self-attentive network for CTR prediction. Procedia Comput. Sci. 2021, 183, 690–695. [Google Scholar] [CrossRef]
- Jiang, D.; Xu, R.; Xu, X.; Xie, Y. Multi-view feature transfer for click-through rate prediction. Inform. Sci. 2021, 546, 961–976. [Google Scholar] [CrossRef]
- Jun, X.; Zhao, X.; Xu, X.; Han, X.; Ren, J.; Li, X. DRIN: Deep Recurrent Interaction Network for click-through rate prediction. Inf. Sci. 2022, 604, 210–225. [Google Scholar] [CrossRef]
- Guo, H.; Tang, R.; Ye, Y.; Li, Z.; He, X. DeepFM: A factorization-machine based neural network for CTR prediction. Int. Jt. Conf. Artif. Intell. 2017, 521, 1725–1731. [Google Scholar]
- Wang, R.; Fu, B.; Fu, G.; Wang, M. Deep & Cross Network for Ad Click Predictions. Assoc. Comput. Mach. 2017, 604, 12. [Google Scholar]
- Xiao, J.; Ye, H.; He, X.; Zhang, H.; Wu, F.; Chua, T.-S. Attentional Factorization Machines: Learning the Weight of Feature Interactions via Attention Networks. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 3119–3125. [Google Scholar]
- Tao, Z.; Wang, X.; He, X.; Huang, X.; Chua, T. HoAFM: A High-order Attentive Factorization Machine for CTR Pre-diction. Inf. Process. Manag. 2020, 57, 102076. [Google Scholar] [CrossRef]
- Rendle, S. Factorization Machines. In Proceedings of the IEEE International Conference on Data Mining, Sydney, Australia, 13–17 December 2010; pp. 995–1000. [Google Scholar]
- Sidahmed, H.; Prokofyeva, E.; Blaschko, M.B. Discovering predictors of mental health service utilization with k-support regularized logistic regression. Inf. Sci. 2016, 329, 937–949. [Google Scholar] [CrossRef]
- Shan, Y.; Hoens, T.R.; Jiao, J.; Wang, H.; Yu, D.; Mao, J.C. Deep Crossing: Web-Scale Modeling without Manually Crafted Combinatorial Features. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 255–262. [Google Scholar]
- Zou, D.; Wang, Z.; Zhang, L.; Zou, J.; Li, Q.; Chen, Y.; Sheng, W. Deep Field Relation Neural Network for click-through rate prediction. Inf. Sci. 2021, 577, 128–139. [Google Scholar] [CrossRef]
- Huang, T.; Zhang, Z.; Zhang, J. FiBiNET: Combining Feature Importance and Bilinear Feature Interaction for Click-through Rate Prediction. In Proceedings of the Thirteenth ACM Conference on Recommender Systems, Copenhagen, Denmark, 16–20 September 2019; pp. 169–177. [Google Scholar]
- Chen, Y.; Wang, Y.; Ren, P.; Wang, M.; Maarten. Bayesian feature interaction selection for factorization machines. Artif. Intell. 2022, 302, 103589. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, Z.; Du, B. Deep Dynamic Interest Learning With Session Local and Global Consistency for Click-Through Rate Predictions. IEEE Trans. Ind. Inform. 2022, 18, 3306–3315. [Google Scholar] [CrossRef]
- Mao, K.; Zhu, J.; Su, L.; Cai, G.; Li, Y.; Dong, Z. FinalMLP: An Enhanced Two-Stream MLP Model for CTR Prediction. AAAI 2023, 37, 4552–4560. [Google Scholar] [CrossRef]
- Song, K.; Huang, Q.; Zhang, F.-E.; Lu, J. Coarse-to-fine: A dual-view attention network for click-through rate predic-tion. Knowl.-Based Syst. 2021, 216, 106767. [Google Scholar] [CrossRef]
- Juan, Y.; Zhuang, Y.; Chin, W.S.; Lin, C. Field-aware factorization machines for CTR prediction. In Proceedings of the Tenth ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 43–50. [Google Scholar]
- Zheng, J.; Chen, S.; Du, Y.; Song, P. A multiview graph collaborative filtering by incorporating homogeneous and heterogeneous signals. Inf. Process. Manag. 2021, 59, 103072. [Google Scholar] [CrossRef]
- Liu, M.; Cai, S.; Lai, Z.; Qiu, L.; Hu, Z.; Ding, Y. A joint learning model for click-through prediction in display advertising. Neurocomputing 2021, 445, 206–219. [Google Scholar] [CrossRef]
- Liu, B.; Zhu, C.; Li, G.; Zhang, W.; Lai, J.; Tang, R.; He, X.; Li, Z.; Yu, Y. AutoFIS: Automatic Feature Interaction Selection in Factorization Models for Click-Through Rate Prediction. In Proceedings of the 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual Event, 6–10 July 2020; pp. 2636–2645. [Google Scholar]
- Cheng, H.T.; Koc, L.; Harmsen, J.; Shaked, T.; Chandra, T.; Aradhye, H.; Shah, H. Wide & Deep Learning for Recommender Systems. In Proceedings of the DLRS 2016: Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016; pp. 7–10. [Google Scholar]
- Liu, B.; Xue, N.; Guo, H.; Tang, R.; Zafeiriou, S.; He, X.; Li, Z. AutoGroup: Automatic Feature Grouping for modeling Explicit High-Order Feature Interactions in CTR Prediction. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 25–30 July 2020; pp. 199–208. [Google Scholar]
- He, X.; Chua, T.-S. Neural Factorization Machines for Sparse Predictive Analytics. In Proceedings of the SIGIR’17, Tokyo, Japan, 7–11 August 2017; pp. 355–364. [Google Scholar]
- Jing, C.; Qiu, L.; Sun, C.; Yang, Q. ICE-DEN: A click-through rate prediction method based on interest contribution extraction of dynamic attention intensity. Knowl.-Based Syst. 2022, 250, 109135. [Google Scholar] [CrossRef]
- Bian, W.; Wu, K.; Ren, L.; Pi, Q.; Zhang, Y.; Xiao, C.; Sheng, X.R.; Zhu, Y.N.; Chan, Z.; Mou, N.; et al. CAN: Feature Co-Action Network for Click-Through Rate Prediction. In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, Virtual Event, 21–25 February 2022; pp. 57–65. [Google Scholar]
- Li, X.; Sun, L.; Ling, M.; Peng, Y. A survey of graph neural network based recommendation in social networks. Neurocomputing 2023, 549, 126441. [Google Scholar] [CrossRef]
- Huang, J.; Han, Z.; Xu, H.; Liu, H. Adapted transformer network for news recommendation. Neurocomputing 2022, 469, 119–129. [Google Scholar] [CrossRef]
- Wang, Z.; She, Q.; Zhang, J. MaskNet: Introducing Feature-Wise Multiplication to CTR Ranking Models by In-stance-Guided Mask. arXiv 2021, arXiv:2102.07619. [Google Scholar]
- Wang, F.; Gu, H.; Li, D.; Lu, T.; Zhang, P.; Gu, N. Towards deeper, lighter and interpretable cross network for ctr prediction. In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, Birmingham, UK, 21–25 October 2023. [Google Scholar]
- Tian, Z.; Bai, T.; Zhao, W.X.; Wen, J.R.; Cao, Z. EulerNet: Adaptive Feature Interaction Learning via Euler’s Formula for CTR Prediction. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, Taiwan, China, 23–27 July 2023. [Google Scholar]
- Cheng, W.; Shen, Y.; Huang, L. Adaptive factorization network: Learning adaptive-order feature interactions. Proc. AAAI Conf. Artif. Intell. 2020, 34, 3609–3616. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Instances | Fields | Features |
|---|---|---|---|
| Criteo | 45,840,422 | 39 | 2,083,736 |
| Avazu | 40,428,365 | 22 | 1,534,240 |
| Frappe | 288,609 | 10 | 5328 |
| Movielens | 2,006,859 | 3 | 90,445 |
| Model | Criteo | Avazu | Frappe | Movielens | ||||
|---|---|---|---|---|---|---|---|---|
| AUC | LogLoss | AUC | LogLoss | AUC | LogLoss | AUC | LogLoss | |
| LR | 0.7832 | 0.4656 | 0.7510 | 0.3735 | 0.9532 | 0.2841 | 0.9315 | 0.3458 |
| FM | 0.8018 | 0.4493 | 0.7587 | 0.3702 | 0.9644 | 0.2215 | 0.9414 | 0.2818 |
| AFM | 0.8005 | 0.4505 | 0.7540 | 0.3720 | 0.9652 | 0.2243 | 0.9475 | 0.2761 |
| NFM | 0.8042 | 0.4470 | 0.7596 | 0.3703 | 0.9730 | 0.2142 | 0.9465 | 0.2848 |
| DeepFM | 0.8114 | 0.4404 | 0.7605 | 0.3696 | 0.9729 | 0.2076 | 0.9485 | 0.2946 |
| FiBiNET | 0.8118 | 0.4401 | 0.7599 | 0.3699 | 0.9732 | 0.2101 | 0.9515 | 0.2358 |
| MaskNet | 0.8119 | 0.4408 | 0.7600 | 0.3696 | 0.9728 | 0.2177 | 0.9664 | 0.2199 |
| GDCN | 0.8124 | 0.4391 | 0.7613 | 0.3675 | 0.9737 | 0.2202 | 0.9682 | 0.2107 |
| EulerNet | 0.8136 | 0.4372 | 0.7624 | 0.3681 | 0.9739 | 0.1991 | 0.9678 | 0.2138 |
| DDT (ours) | 0.8143 | 0.4376 | 0.7635 | 0.3674 | 0.9765 | 0.1984 | 0.9683 | 0.2104 |
| Heads (k) | Criteo | Avazu | Frappe | Movielens | ||||
|---|---|---|---|---|---|---|---|---|
| AUC | LogLoss | AUC | LogLoss | AUC | LogLoss | AUC | LogLoss | |
| 1 | 0.8138 | 0.4382 | 0.7630 | 0.3675 | 0.9765 | 0.1984 | 0.9683 | 0.2104 |
| 5 | 0.8142 | 0.4378 | 0.7618 | 0.3680 | 0.9752 | 0.1987 | 0.9678 | 0.2137 |
| 10 | 0.8140 | 0.4380 | 0.7599 | 0.3715 | 0.9749 | 0.1997 | 0.9674 | 0.2135 |
| 20 | 0.8143 | 0.4376 | 0.7601 | 0.3684 | 0.9731 | 0.2004 | 0.9669 | 0.2144 |
| 40 | 0.8140 | 0.4379 | 0.7624 | 0.3693 | 0.9735 | 0.2001 | 0.9667 | 0.2146 |
| 50 | 0.8141 | 0.4378 | 0.7609 | 0.3690 | 0.9737 | 0.2000 | 0.9664 | 0.2157 |
| Model | Configuration | Criteo | Avazu | |||||
|---|---|---|---|---|---|---|---|---|
| Input Layer | Deep Layer | Fusion Layer | AUC | LogLoss | AUC | LogLoss | ||
| SENet | MLP1 | MLP2 | Fusion | |||||
| Model 1 | ✗ | ✓ | ✓ | ✓ | 0.8139 | 0.4380 | 0.7604 | 0.3804 |
| Model 2 | ✓ | ✗ | ✓ | ✓ | 0.8141 | 0.4378 | 0.7606 | 0.3693 |
| Model 3 | ✓ | ✓ | ✗ | ✓ | 0.8132 | 0.4387 | 0.7555 | 0.3713 |
| Model 4 | ✓ | ✓ | ✓ | ✗ | 0.8138 | 0.4382 | 0.7596 | 0.3704 |
| DDT (our) | ✓ | ✓ | ✓ | ✓ | 0.8143 | 0.4376 | 0.7635 | 0.3674 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Cheng, X.; Wei, W.; Meng, Y. Deep Double Towers Click Through Rate Prediction Model with Multi-Head Bilinear Fusion. Symmetry 2025, 17, 159. https://doi.org/10.3390/sym17020159
Zhang Y, Cheng X, Wei W, Meng Y. Deep Double Towers Click Through Rate Prediction Model with Multi-Head Bilinear Fusion. Symmetry. 2025; 17(2):159. https://doi.org/10.3390/sym17020159
Chicago/Turabian StyleZhang, Yuan, Xiaobao Cheng, Wei Wei, and Yangyang Meng. 2025. "Deep Double Towers Click Through Rate Prediction Model with Multi-Head Bilinear Fusion" Symmetry 17, no. 2: 159. https://doi.org/10.3390/sym17020159
APA StyleZhang, Y., Cheng, X., Wei, W., & Meng, Y. (2025). Deep Double Towers Click Through Rate Prediction Model with Multi-Head Bilinear Fusion. Symmetry, 17(2), 159. https://doi.org/10.3390/sym17020159