
Deep Multi-View Clustering Optimized by Long Short-Term Memory Network

Abstract
1. Introduction
- We introduce DMVC-LSTM, a novel framework that utilizes LSTM to integrate multi-view data and capture nonlinear interdependencies between views.
- We provide three feature fusion mechanisms for multi-view data, concatenation, averaging, and attention-based fusion, with concatenation being the primary approach due to its simplicity and effectiveness in capturing consistency across views.
- Through extensive experiments, we show that DMVC-LSTM outperforms existing multi-view clustering methods, particularly on complex and high-dimensional datasets, offering better robustness and generalization.
2. Related Work
2.1. Deep Autoencoder
2.2. Long Short-Term Memory Network
- Forget Gate
- 2.
- Input Gate
- 3.
- Cell State Update
- 4.
- Output Gate
- 5.
- Gradient Computation and Backpropagation
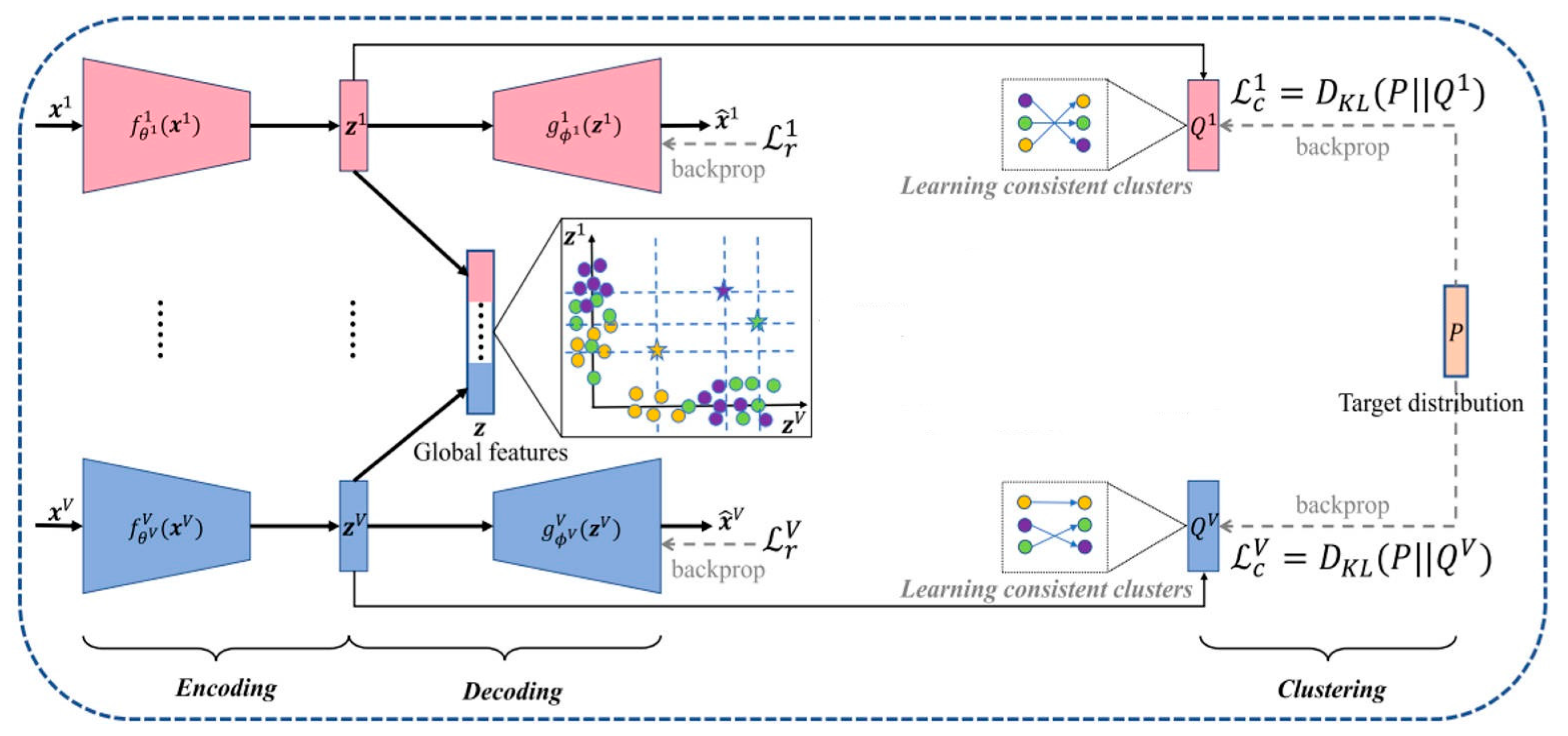
3. Proposed Approach
3.1. Preliminaries
3.1.1. Notations and Definitions
3.1.2. Data Preprocessing
3.1.3. KL Divergence
3.2. Model Overview
- Multi-View Feature Extraction
- 2.
- Feature Fusion and Shared Representation
- 3.
- LSTM Autoencoder
- 4.
- Dynamic Clustering Optimization
3.3. Model Details
- LSTM-Based Clustering Model
- Input Layer: Takes in multi-dimensional feature data, where each data point is represented as a sequence of feature vectors, preserving sequential dependencies.
- LSTM Hidden Layer: The LSTM layer captures temporal dependencies between features. It outputs a condensed feature representation used for clustering. The number of units in the LSTM layer is chosen based on the complexity of the data.
- Output Layer: A fully connected layer using softmax activation assigns data points to one of the n clusters. The model is trained with KL divergence as the loss function, minimizing the difference between the predicted cluster probabilities and the target distribution.
- Optimization: The model is optimized using the Adam optimizer to adapt the learning rate during training, and accuracy is tracked to monitor performance.
- 2.
- Pretraining with Autoencoder
- Input Layer: The same multi-dimensional data as in the clustering model are input to the autoencoder.
- LSTM Layer: Similarly to the clustering model, the autoencoder uses an LSTM layer. In this case, the LSTM outputs a sequence of feature representations, preserving temporal dependencies.
- Time-Distributed Reconstruction Layer: The LSTM output is passed through a time-distributed fully connected layer, which reconstructs the original input data at each time step.
- Loss Function: During pretraining, the model uses mean squared error (MSE) to minimize the reconstruction error.
- Training and Weight Transfer: After pretraining, the LSTM layer weights from the autoencoder are transferred to the clustering model, enabling it to start with well-learned features for better clustering.
- 3.
- Fine-Tuning for Clustering
3.4. Objective Function
3.5. Optimization
| Algorithm 1: The Optimization of DMVC-LSTM |
| Input: Shared feature representation , hidden layer dimension . Step 1: Initialize the regularization coefficient and the weight matrix for the -th view. Step 2: Optimize the reconstruction loss via Equations (17)–(21). Step 3: Update the learning rate via Equation (22). Step 4: Initialize the cluster centers , calculate the probability distribution of samples to centers, and dynamically optimize the target distribution and clustering parameters until the model converges. Output: Clustering result . |
3.6. Computational Complexity Analysis
- Feature Extraction: The feature extraction network involves two hidden layers with ReLU activation and a softmax classification layer. The complexity of the ReLU activation function is , where is the feature dimension, and the complexity of the softmax layer is , where is the number of categories. With samples, the total complexity is .
- Feature Fusion: For multi-view feature fusion, the complexity is determined by the fusion method. If concatenation or averaging is used, the complexity is , where represents the feature dimension of each view. The same complexity applies when using an attention mechanism, as it weights and sums features from multiple views.
- LSTM Forward and Backward Propagation: For each time step, the complexity of LSTM is , where is the feature dimension of the view. For sequence data of length , the forward and backward propagation complexity for a single view is . With views, the total complexity becomes .
- Clustering: Initializing each cluster has a complexity of , where k is the number of clusters and d is the feature dimension. Calculating distances between samples and cluster centers has a complexity of , and updating cluster centers also requires .
- Optimizing: The Adam algorithm has a complexity of for each update, as it updates the weight matrix for each view. Regularization also has a complexity of , as it involves traversing all view-specific weight matrices. The clustering loss function involves computing Euclidean distances, which requires complexity.
4. Experiments
4.1. Datasets
- 100 Leaves [24] includes 1600 leaf images from 100 leaf categories, with 16 images per category. It provides three views, each with a feature dimension of 64, corresponding to texture, shape, and edge features of the leaves.
- BBC [25] consists of 4659 news articles from the BBC News corpus, covering multiple news topics. It provides four views, each with a feature dimension of 685, extracted using different text feature extraction methods, including bag of words and TF-IDF.
- 20 Newsgroups [26] contains 2000 articles from 20 newsgroups and exhibits high-dimensional sparse characteristics. It provides three views, each with a feature dimension of 500, based on term frequency features, TF-IDF features, and topic modeling features.
- HW2sources [27] consists of 2000 handwritten letter samples and provides two views. The first view has a feature dimension of 784, extracted based on pixel information. The second view has a feature dimension of 256, capturing the structural edge information of handwriting.
- movies617 [28] comprises 617 movies with features describing movie plots, actors, and metadata. It has two views: the first view has a feature dimension of 1878 based on textual features extracted from plot descriptions, and the second view has a feature dimension of 1398 based on structured metadata features.
- Wikipedia Articles [29] contains 693 Wikipedia articles covering multiple thematic domains. It provides two views: the first view has a feature dimension of 128, extracted using the bag-of-words model, and the second view has a feature dimension of 10, generated using topic modeling.
4.2. Algorithms for Comparison
4.3. Evaluation Metrics
- Accuracy (ACC) measures the proportion of correctly clustered samples compared to the total number of samples. It provides a straightforward assessment of how well the clustering algorithm performs in assigning samples to the correct clusters.
- Normalized Mutual Information (NMI) measures the amount of shared information between the predicted cluster assignments and the true labels, normalized to account for differences in dataset size. A higher NMI indicates better clustering performance, with values ranging from 0 (no mutual information) to 1 (perfect alignment).
- Adjusted Rand Index (ARI) compares the similarity between the predicted cluster assignments and the true labels, adjusting for the possibility of random clustering. Its value ranges from −1 (completely dissimilar) to 1 (perfectly identical), with 0 indicating random clustering assignments.
- Purity (PUR) evaluates how well each cluster corresponds to a single true class by calculating the fraction of correctly assigned samples in each cluster. Higher purity indicates better clustering results where each cluster predominantly contains samples from a single class.
4.4. Main Parameter Settings
- LSTM Hidden Layer Dimension: The number of hidden units in the LSTM layer is set to 256, enabling the model to capture complex temporal relationships and inter-feature dependencies in multi-view data.
- Maximum Iterations: The maximum number of iterations is set to 5000, providing sufficient time for the model to converge.
- Tolerance: The convergence tolerance is set to 0.001, meaning training stops when the change in the target distribution is smaller than this threshold.
4.5. Comparative Results Analysis
4.5.1. Overall Performance of Different Algorithms
4.5.2. Cross-Dataset Performance Trends
- On low-dimensional datasets with minimal redundancy, such as 100 Leaves and BBC, DMVC-LSTM quickly uncovers clustering structures with ACC scores of 74.07% and 76.33%. Other methods like SwMC and MSC_IAS show competitive performance, but struggle with complex feature relationships.
- On high-dimensional and heterogeneous datasets like 20 Newsgroups and movies617, DMVC-LSTM consistently achieves high NMI and ARI scores, demonstrating its robustness to complex relationships. In contrast, SwMPC and MVGL struggle on these datasets.
- On datasets with intricate inter-view interactions, such as Wikipedia Articles, DMVC-LSTM achieves an ACC of 79.14%, outperforming all other methods.
4.5.3. Performance Summary
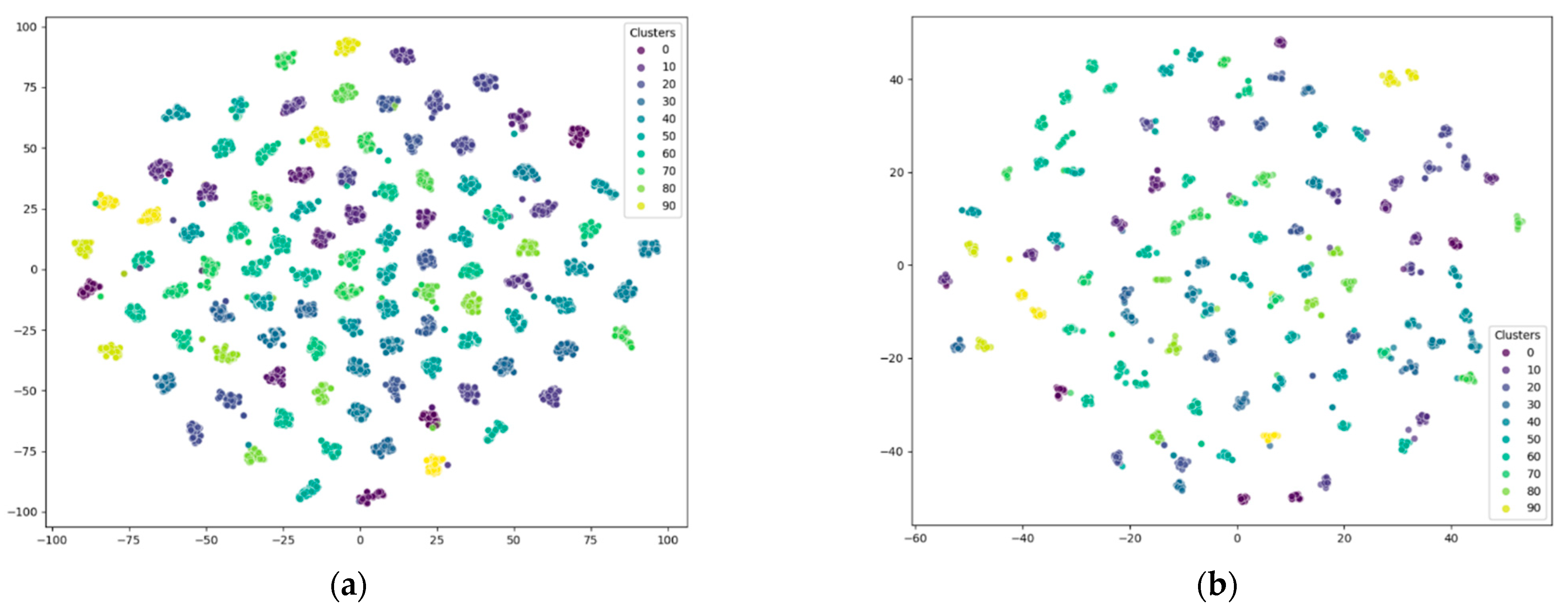
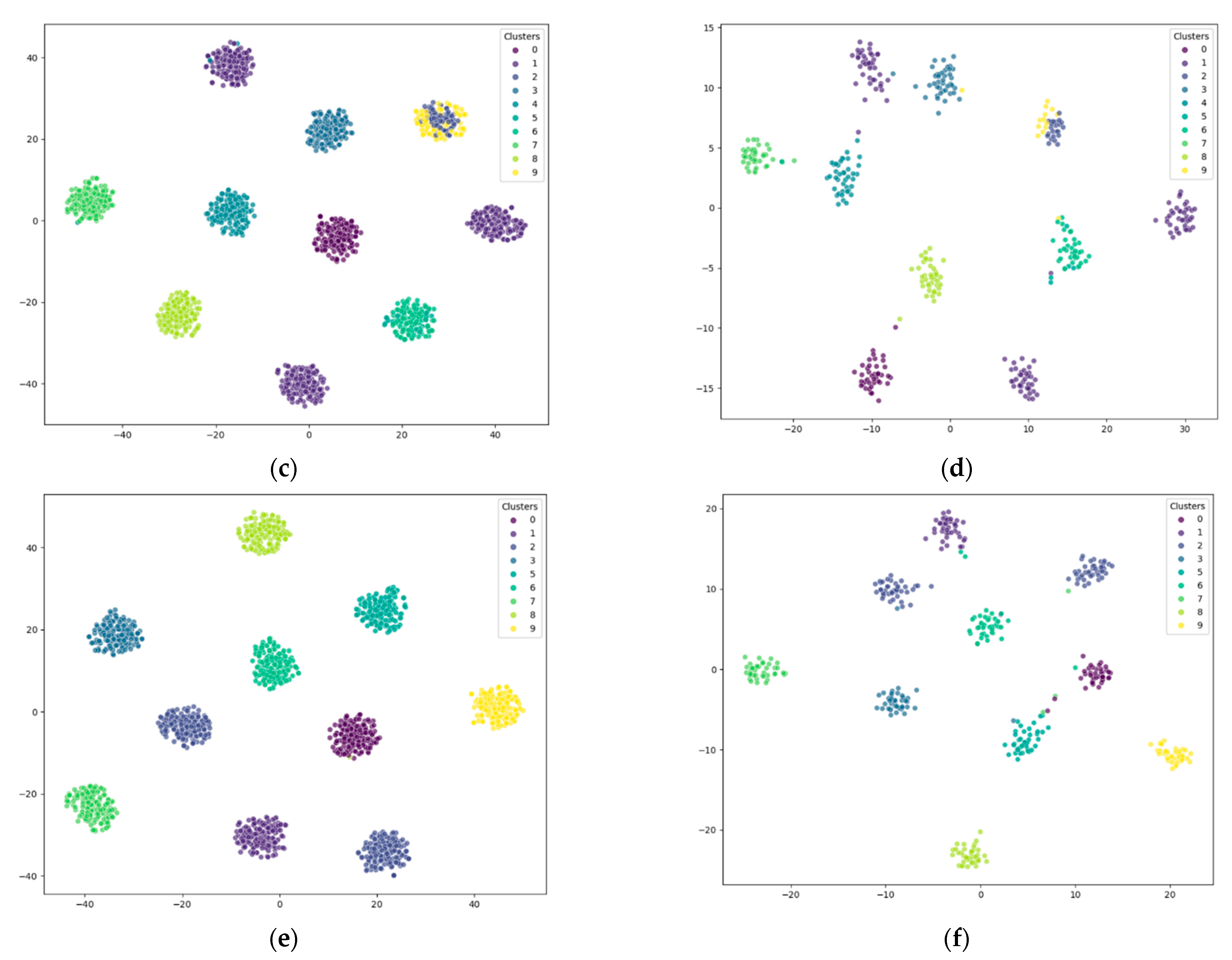
4.6. Visualization of Clustering
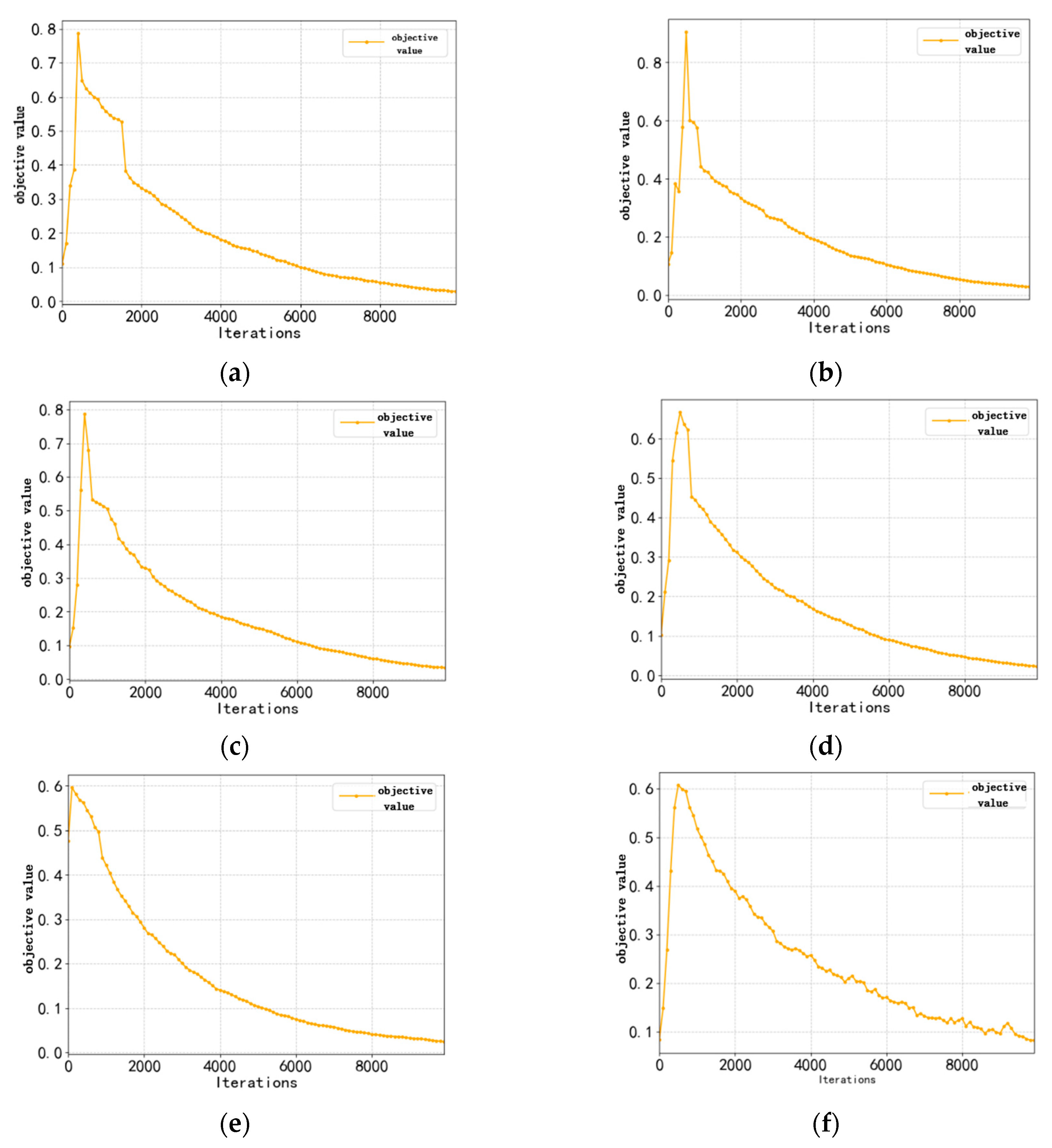
4.7. Convergence Analysis
4.8. Parameter Sensitivity Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chao, G.; Sun, S.; Bi, J. A survey on multi-view clustering. arXiv 2017, arXiv:1712.06246. [Google Scholar]
- Nie, F.; Li, J.; Li, X. Self-weighted multiview clustering with multiple graphs. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI-17), Melbourne, Australia, 19–25 August 2017; pp. 2564–2570. [Google Scholar]
- Xu, Y.M.; Wang, C.D.; Lai, J.H. Weighted multi-view clustering with feature selection. Pattern Recognit. 2016, 53, 25–35. [Google Scholar] [CrossRef]
- Xu, C.; Tao, D.; Xu, C. A survey on multi-view learning. arXiv 2013, arXiv:1304.5634. [Google Scholar]
- Likas, A.; Vlassis, N.; Verbeek, J.J. The global k-means clustering algorithm. Pattern Recognit. 2003, 36, 451–461. [Google Scholar] [CrossRef]
- Ng, A.; Jordan, M.; Weiss, Y. On spectral clustering: Analysis and an algorithm. Adv. Neural Inf. Process. Syst. 2001, 14. [Google Scholar]
- Bickel, S.; Scheffer, T. Multi-view clustering. In Proceedings of the Fourth IEEE International Conference on Data Mining (ICDM’04), Brighton, UK, 1–4 November 2004; Volume 4, pp. 19–26. [Google Scholar]
- Fu, L.; Lin, P.; Vasilakos, A.V.; Wang, S. An overview of recent multi-view clustering. Neurocomputing 2020, 402, 148–161. [Google Scholar] [CrossRef]
- Yang, Y.; Wang, H. Multi-view clustering: A survey. Big Data Min. Anal. 2018, 1, 83–107. [Google Scholar] [CrossRef]
- Gönen, M.; Margolin, A.A. Localized data fusion for kernel k-means clustering with application to cancer biology. Adv. Neural Inf. Process. Syst. 2014, 27. [Google Scholar]
- Du, L.; Zhou, P.; Shi, L.; Fan, M. Robust multiple kernel k-means using l21-norm. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Zheng, Q.; Zhu, J.; Ma, Y.; Li, Z.; Tian, Z. Multi-view subspace clustering networks with local and global graph information. Neurocomputing 2021, 449, 15–23. [Google Scholar] [CrossRef]
- Du, G.; Zhou, L.; Yang, Y.; Lü, K.; Wang, L. Deep multiple auto-encoder-based multi-view clustering. Data Sci. Eng. 2021, 6, 323–338. [Google Scholar] [CrossRef]
- Xu, J.; Ren, Y.; Tang, H.; Pu, X.; Zhu, X.; Zeng, M.; He, L. Multi-VAE: Learning disentangled view-common and view-peculiar visual representations for multi-view clustering. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 9234–9243. [Google Scholar]
- Hochreiter, S. Long Short-term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Lange, S.; Riedmiller, M. Deep auto-encoder neural networks in reinforcement learning. In Proceedings of the 2010 International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 1–8. [Google Scholar]
- Huang, P.; Huang, Y.; Wang, W.; Wang, L. Deep embedding network for clustering. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 1532–1537. [Google Scholar]
- Opochinsky, Y.; Chazan, S.E.; Gannot, S.; Goldberger, J. K-autoencoders deep clustering. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 4037–4041. [Google Scholar]
- Dong, S.; Xu, H.; Zhu, X.; Guo, X.; Liu, X.; Wang, X. Multi-view deep clustering based on autoencoder. J. Phys. Conf. Ser. 2020, 1684, 012059. [Google Scholar] [CrossRef]
- Ghasedi Dizaji, K.; Herandi, A.; Deng, C.; Cai, W.; Huang, H. Deep clustering via joint convolutional autoencoder embedding and relative entropy minimization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5736–5745. [Google Scholar]
- Lim, K.L.; Jiang, X.; Yi, C. Deep clustering with variational autoencoder. IEEE Signal Process. Lett. 2020, 27, 231–235. [Google Scholar] [CrossRef]
- Medsker, L.R.; Jain, L. Recurrent neural networks. Des. Appl. 2001, 5, 2. [Google Scholar]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Beghin, T.; Cope, J.S.; Remagnino, P.; Barman, S. Shape and texture based plant leaf classification. In Advanced Concepts for Intelligent Vision Systems, Proceedings of the 12th International Conference, ACIVS 2010, Sydney, Australia, 13–16 December 2010; Proceedings, Part II 12; Springer: Berlin/Heidelberg, Germany, 2010; pp. 345–353. [Google Scholar]
- Greene, D.; Cunningham, P. Practical solutions to the problem of diagonal dominance in kernel document clustering. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 377–384. [Google Scholar]
- Lang, K. Newsweeder: Learning to filter netnews. In Proceedings of the Machine Learning Proceedings 1995, Tahoe City, CA, CA, 9–12 July 1995; Morgan Kaufmann: Burlington, MA, USA, 1995; pp. 331–339. [Google Scholar]
- Wang, H.; Yang, Y.; Liu, B.; Fujita, H. A study of graph-based system for multi-view clustering. Knowl. Based Syst. 2019, 163, 1009–1019. [Google Scholar] [CrossRef]
- Available online: https://lig-membres.imag.fr/grimal/data.html (accessed on 4 December 2024).
- Available online: http://www.svcl.ucsd.edu/projects/crossmodal/ (accessed on 4 December 2024).
- Zhan, K.; Zhang, C.; Guan, J.; Wang, J. Graph learning for multiview clustering. IEEE Trans. Cybern. 2017, 48, 2887–2895. [Google Scholar] [CrossRef]
- Wang, R.; Nie, F.; Wang, Z.; Hu, H.; Li, X. Parameter-free weighted multi-view projected clustering with structured graph learning. IEEE Trans. Knowl. Data Eng. 2019, 32, 2014–2025. [Google Scholar] [CrossRef]
- Wang, X.; Lei, Z.; Guo, X.; Zhang, C.; Shi, H.; Li, S.Z. Multi-view subspace clustering with intactness-aware similarity. Pattern Recognit. 2019, 88, 50–63. [Google Scholar] [CrossRef]
- Kang, Z.; Shi, G.; Huang, S.; Chen, W.; Pu, X.; Zhou, J.T.; Xu, Z. Multi-graph fusion for multi-view spectral clustering. Knowl. -Based Syst. 2020, 189, 105102. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Definition |
|---|---|
| -th view | |
| Number of data samples | |
| Number of views | |
| -th view | |
| -th view | |
| Shared feature representation | |
| Reconstructed shared feature representation | |
| -th iteration | |
| -th view | |
| -th view | |
| -th view | |
| -th iteration | |
| -th iteration | |
| -th iteration | |
| Learning rate | |
| Decay factor | |
| Training step | |
| -th iteration | |
| Exponential decay rates for the moment estimates | |
| True probability distribution | |
| Predicted probability distribution |
| Dataset | |||
|---|---|---|---|
| 100 Leaves | 1600 | 3 | 64 |
| BBC | 4659 | 4 | 685 |
| 20 Newsgroups | 2000 | 3 | 500 |
| HW2sources | 2000 | 2 | 784, 256 |
| movies617 | 617 | 2 | 1878, 1398 |
| Wikipedia Articles | 693 | 2 | 128, 10 |
| Dataset | Method | ACC | NMI | ARI | PUR |
|---|---|---|---|---|---|
| SC_best | 51.91 | 33.04 | 51.76 | 87.82 | |
| MVGL | 44.90 | 42.72 | 84.56 | 66.68 | |
| SwMC | 63.23 | 92.29 | 71.50 | 98.19 | |
| 100 Leaves | SwMPC | 61.66 | 76.79 | 48.51 | 69.99 |
| MSC_IAS | 73.87 | 90.16 | 84.85 | 69.80 | |
| GFSC | 50.91 | 77.75 | 52.54 | 90.35 | |
| Ours | 74.07 | 92.53 | 84.35 | 98.39 | |
| SC_best | 70.40 | 90.41 | 67.56 | 80.42 | |
| MVGL | 63.02 | 86.18 | 77.94 | 78.87 | |
| SwMC | 65.28 | 90.20 | 78.90 | 90.54 | |
| BBC | SwMPC | 61.48 | 88.43 | 60.29 | 96.73 |
| MSC_IAS | 75.31 | 87.51 | 80.37 | 91.20 | |
| GFSC | 70.52 | 87.23 | 69.13 | 87.23 | |
| Ours | 76.33 | 90.54 | 94.42 | 95.99 | |
| SC_best | 57.37 | 69.69 | 56.51 | 73.62 | |
| MVGL | 42.82 | 42.16 | 64.72 | 67.55 | |
| SwMC | 62.15 | 84.66 | 73.46 | 92.71 | |
| 20 Newsgroups | SwMPC | 64.75 | 70.09 | 57.71 | 76.28 |
| MSC_IAS | 59.00 | 94.22 | 72.61 | 77.96 | |
| GFSC | 75.16 | 96.00 | 67.14 | 68.55 | |
| Ours | 75.38 | 96.29 | 84.49 | 92.96 | |
| SC_best | 64.73 | 97.82 | 53.54 | 59.00 | |
| MVGL | 58.02 | 57.70 | 52.01 | 60.34 | |
| SwMC | 69.60 | 98.69 | 80.46 | 92.74 | |
| HW2sources | SwMPC | 49.95 | 84.40 | 48.07 | 77.59 |
| MSC_IAS | 63.07 | 79.73 | 67.53 | 81.18 | |
| GFSC | 58.04 | 85.23 | 56.46 | 92.82 | |
| Ours | 69.86 | 98.94 | 80.68 | 93.11 | |
| SC_best | 66.22 | 97.03 | 73.76 | 75.24 | |
| MVGL | 66.29 | 63.41 | 60.57 | 79.75 | |
| SwMC | 46.97 | 98.10 | 65.97 | 84.55 | |
| movies617 | SwMPC | 49.97 | 84.11 | 68.48 | 87.25 |
| MSC_IAS | 76.60 | 89.26 | 69.57 | 96.04 | |
| GFSC | 74.22 | 95.83 | 71.14 | 67.51 | |
| Ours | 76.83 | 97.86 | 73.97 | 96.34 | |
| SC_best | 61.91 | 88.58 | 73.55 | 84.99 | |
| MVGL | 51.59 | 60.72 | 59.83 | 75.43 | |
| SwMC | 54.84 | 66.94 | 67.12 | 79.25 | |
| Wikipedia Articles | SwMPC | 60.75 | 74.15 | 77.74 | 87.91 |
| MSC_IAS | 77.72 | 81.45 | 76.01 | 92.56 | |
| GFSC | 71.45 | 96.47 | 72.43 | 64.89 | |
| Ours | 79.14 | 98.53 | 80.79 | 95.54 |
| Hidden Layer Dimension | ACC | NMI |
|---|---|---|
| 32 | 62.13 | 86.42 |
| 64 | 68.07 | 89.27 |
| 128 | 72.49 | 91.04 |
| 256 | 74.07 | 92.53 |
| 512 | 71.43 | 90.98 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zou, H.; Zhou, S. Deep Multi-View Clustering Optimized by Long Short-Term Memory Network. Symmetry 2025, 17, 161. https://doi.org/10.3390/sym17020161
Zou H, Zhou S. Deep Multi-View Clustering Optimized by Long Short-Term Memory Network. Symmetry. 2025; 17(2):161. https://doi.org/10.3390/sym17020161
Chicago/Turabian StyleZou, Hangtao, and Shibing Zhou. 2025. "Deep Multi-View Clustering Optimized by Long Short-Term Memory Network" Symmetry 17, no. 2: 161. https://doi.org/10.3390/sym17020161
APA StyleZou, H., & Zhou, S. (2025). Deep Multi-View Clustering Optimized by Long Short-Term Memory Network. Symmetry, 17(2), 161. https://doi.org/10.3390/sym17020161