
k-Nearest Neighbors Estimator for Functional Asymmetry Shortfall Regression


Abstract
1. Introduction
2. KNN Estimator of Expectile Shortfall Regression
3. Pointwise Convergence
- (P1)
- where .
- (P2)
- There exists an invertible non-negative function , a bounded and positive function , and a function such that
- (i)
- tends to zero as goes to zero and, , as , for certain
- (ii)
- For all ,
- (P3)
- , ,
- (P4)
- For all ,
- (P5)
- The kernel function is supported on such that
- (P6)
- The number of the neighborhood k such thatComments on the hypotheses.
- C1.
- and
- C2.
- C3.
- andThen, we have
4. UCNN Convergence
- U1
- The function’s classis a pointwise measurable class, such that:where the maximum is an overall probability on the space with with G being the envelope function of the set . is the number of open balls with a radius , which is necessary to cover the class of functions . The balls are constructed using the -metric.
- U2
- The kernel is supported within and has a continuous first derivative, such that:where is the indicator function of set A.
- U3
- The sequences and verify:Then, the following theorem gives the UINN consistency of .
5. Empirical Analysis
5.1. Smoothing Parameter Selection: Cross-Validation
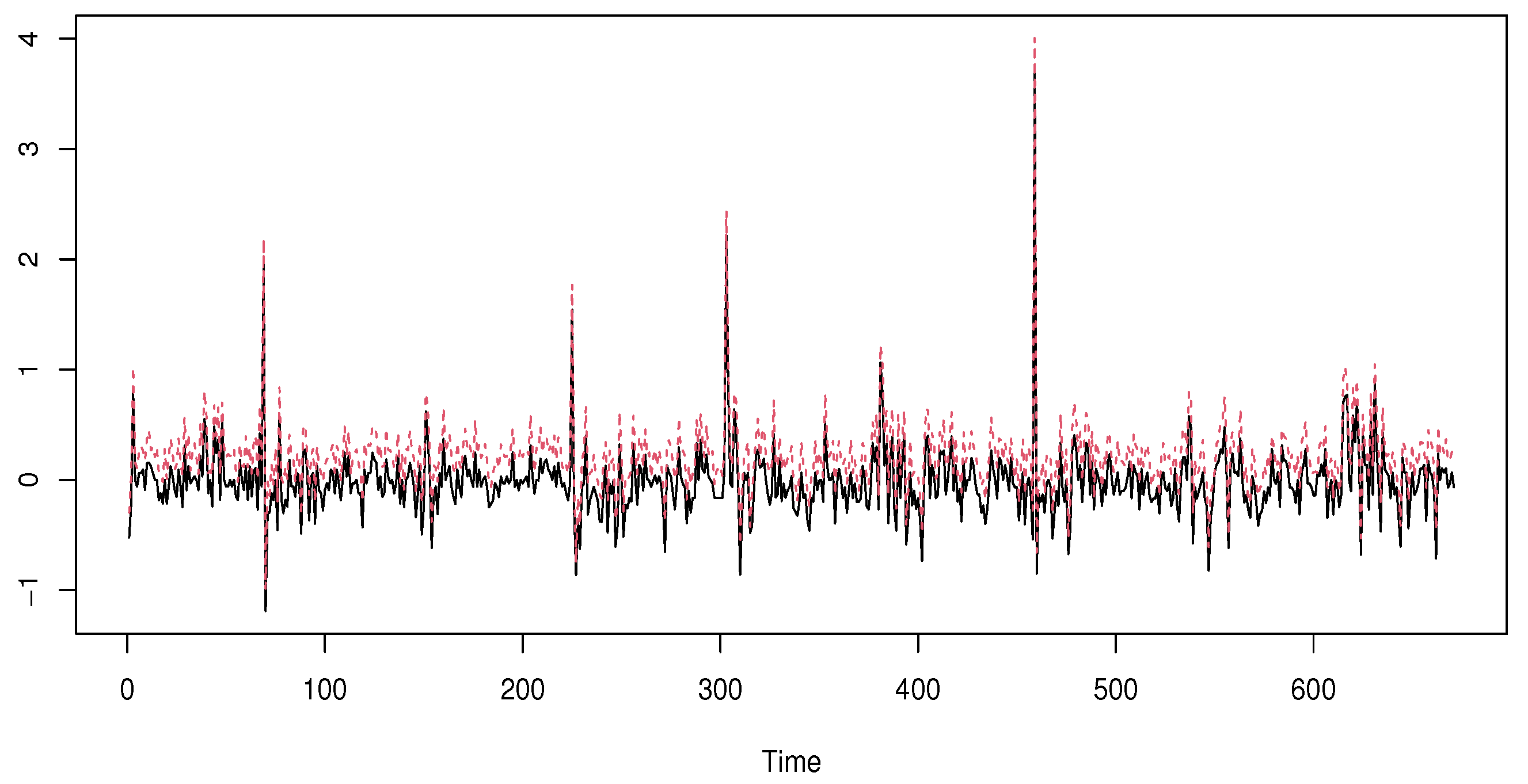
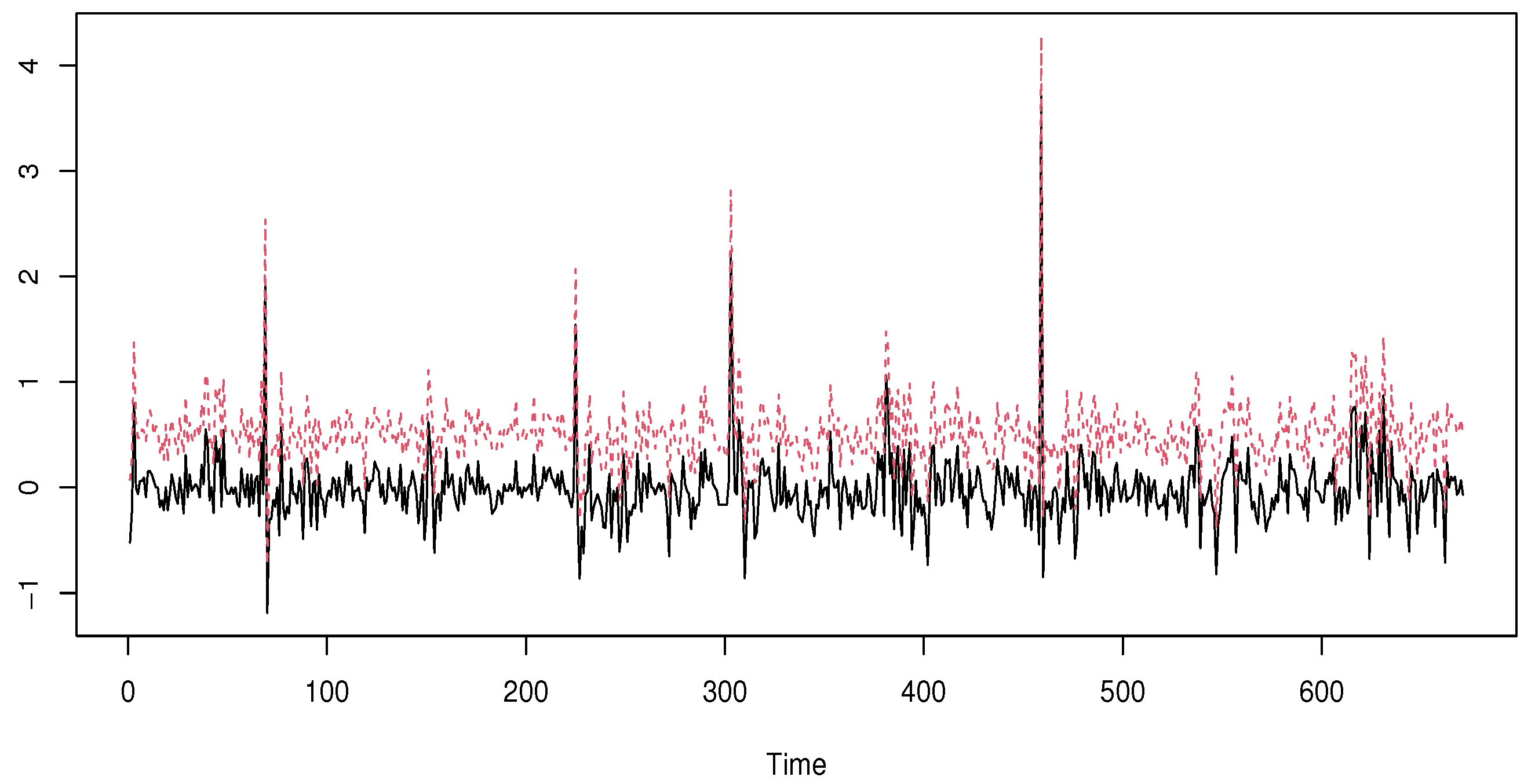
5.2. Simulated Data
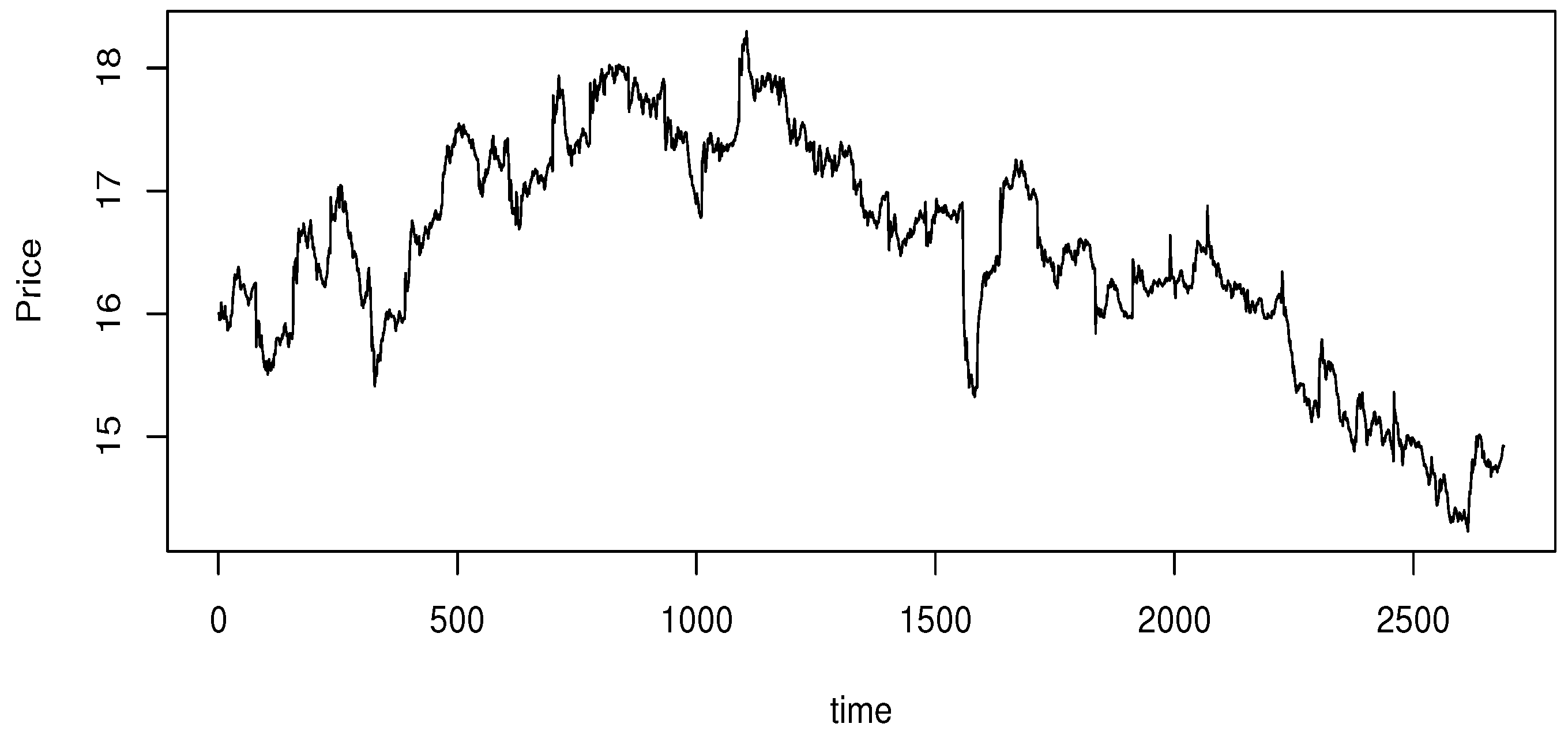
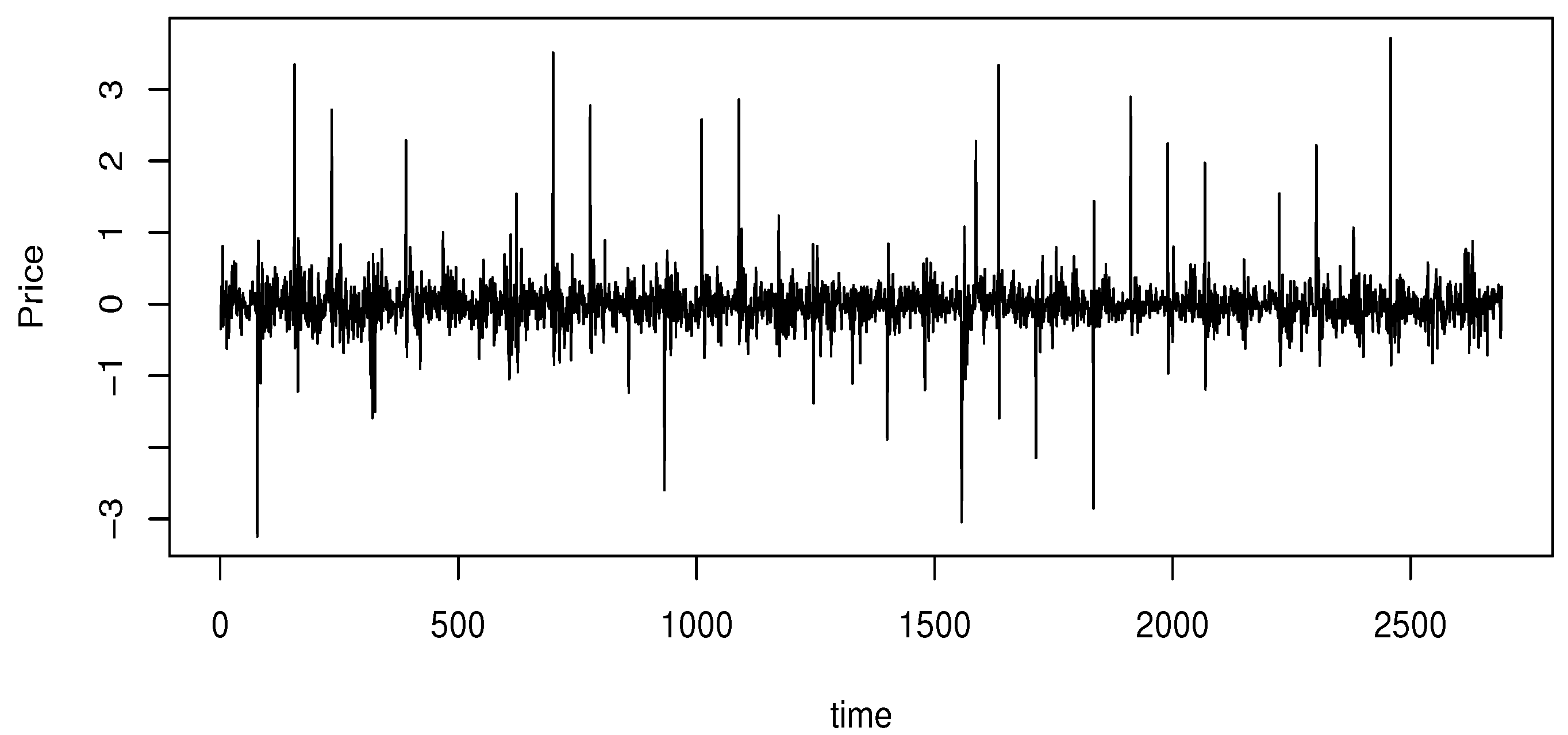
5.3. Real Data Application
6. Conclusions and Prospects
7. The Demonstration of the Intermediate Results
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Artzner, P.; Delbaen, F.; Eber, J.M.; Heath, D. Coherent measures of risk. Math. Financ. 1999, 9, 203–228. [Google Scholar] [CrossRef]
- Righi, M.B.; Ceretta, P.S. A comparison of expected shortfall estimation models. J. Econ. Bus. 2015, 78, 14–47. [Google Scholar] [CrossRef]
- Moutanabbir, K.; Bouaddi, M. A new non-parametric estimation of the expected shortfall for dependent financial losses. J. Stat. Plan. Inference 2024, 232, 106151. [Google Scholar] [CrossRef]
- Lazar, E.; Pan, J.; Wang, S. On the estimation of Value-at-Risk and Expected Shortfall at extreme levels. J. Commod. Mark. 2024, 3, 100391. [Google Scholar] [CrossRef]
- Scaillet, O. Nonparametric estimation and sensitivity analysis of expected shortfall. Math. Financ. Int. J. Math. Stat. Financ. Econ. 2004, 14, 115–129. [Google Scholar] [CrossRef]
- Cai, Z.; Wang, X. Nonparametric estimation of conditional VaR and expected shortfall. J. Econom. 2008, 147, 120–130. [Google Scholar] [CrossRef]
- Wu, Y.; Yu, W.; Balakrishnan, N.; Wang, X. Nonparametric estimation of expected shortfall via Bahadur-type representation and Berry–Esséen bounds. J. Stat. Comput. Simul. 2022, 92, 544–566. [Google Scholar] [CrossRef]
- Ferraty, F.; Quintela-Del-Río, A. Conditional VAR and expected shortfall: A new functional approach. Econom. Rev. 2016, 35, 263–292. [Google Scholar] [CrossRef]
- Ait-Hennani, L.; Kaid, Z.; Laksaci, A.; Rachdi, M. Nonparametric estimation of the expected shortfall regression for quasi-associated functional data. Mathematics 2022, 10, 4508. [Google Scholar] [CrossRef]
- Newey, W.K.; Powell, J.L. Asymmetric least squares estimation and testing. Econom. J. Econom. Soc. 1987, 55, 819–847. [Google Scholar] [CrossRef]
- Waltrup, L.S.; Sobotka, F.; Kneib, T.; Kauermann, G. Expectile and quantile regression—David and Goliath? Stat. Model. 2015, 15, 433–456. [Google Scholar] [CrossRef]
- Bellini, F.; Di Bernardino, E. Risk management with expectiles. Eur. J. Financ. 2017, 23, 487–506. [Google Scholar] [CrossRef]
- Farooq, M.; Steinwart, I. Learning rates for kernel-based expectile regression. Mach. Learn. 2019, 108, 203–227. [Google Scholar] [CrossRef]
- Bellini, F.; Negri, I.; Pyatkova, M. Backtesting VaR and expectiles with realized scores. Stat. Methods Appl. 2019, 28, 119–142. [Google Scholar] [CrossRef]
- Chakroborty, S.; Iyer, R.; Trindade, A.A. On the use of the M-quantiles for outlier detection in multivariate data. arXiv 2024, arXiv:2401.01628. [Google Scholar]
- Gu, Y.; Zou, H. High-dimensional generalizations of asymmetric least squares regression and their applications. Ann. Stat. 2016, 44, 2661–2694. [Google Scholar] [CrossRef]
- Zhao, J.; Chen, Y.; Zhang, Y. Expectile regression for analyzing heteroscedasticity in high dimension. Stat. Probab. Lett. 2018, 137, 304–311. [Google Scholar] [CrossRef]
- Kneib, T. Beyond mean regression. Stat. Model. 2013, 13, 275–303. [Google Scholar] [CrossRef]
- Mohammedi, M.; Bouzebda, S.; Laksaci, A. The consistency and asymptotic normality of the kernel type expectile regression estimator for functional data. J. Multivar. Anal. 2021, 181, 104673. [Google Scholar] [CrossRef]
- Girard, S.; Stupfler, G.; Usseglio-Carleve, A. Functional estimation of extreme conditional expectiles. Econom. Stat. 2022, 21, 131–158. [Google Scholar] [CrossRef]
- Almanjahie, I.M.; Bouzebda, S.; Kaid, Z.; Laksaci, A. The local linear functional kNN estimator of the conditional expectile: Uniform consistency in number of neighbors. Metrika 2024, 1–29. [Google Scholar] [CrossRef]
- Aneiros, G.; Cao, R.; Fraiman, R.; Genest, C.; Vieu, P. Recent advances in functional data analysis and high-dimensional statistics. H. Multivar. Anal. 2019, 170, 3–9. [Google Scholar] [CrossRef]
- Goia, A.; Vieu, P. An introduction to recent advances in high/infinite dimensional statistics. J. Multivar. Anal. 2016, 170, 1–6. [Google Scholar] [CrossRef]
- Yu, D.; Pietrosanu, M.; Mizera, I.; Jiang, B.; Kong, L.; Tu, W. Functional Linear Partial Quantile Regression with Guaranteed Convergence for Neuroimaging Data Analysis. Stat. Biosci. 2024, 1–17. [Google Scholar] [CrossRef]
- Di Bernardino, E.; Laloe, T.; Pakzad, C. Estimation of extreme multivariate expectiles with functional covariates. J. Multivar. Anal. 2024, 202, 105292. [Google Scholar] [CrossRef]
- Collomb, G.; Härdle, W.; Hassani, S. A note on prediction via conditional mode estimation. J. Statist. Plann. Inference 1987, 15, 227–236. [Google Scholar] [CrossRef]
- Burba, F.; Ferraty, F.; Vieu, P. k-nearest neighbor method in functional nonparametric regression. J. Nonparametr. Statist. 2009, 21, 453–469. [Google Scholar] [CrossRef]
- Kudraszow, N.; Vieu, P. Uniform consistency of kNN regressors for functional variables. Statist. Probab. Lett. 2013, 83, 1863–1870. [Google Scholar] [CrossRef]
- Bouzebda, S.; Nezzal, A. Uniform consistency and uniform in number of neighbors consistency for nonparametric regression estimates and conditional U-statistics involving functional data. Jpn. J. Stat. Data Sci. 2022, 5, 431–533. [Google Scholar] [CrossRef]
- Bouzebda, S.; Mohammedi, M.; Laksaci, A. The k-nearest neighbors method in single index regression model for functional quasi-associated time series data. Rev. Mat. Complut. 2022, 36, 361–391. [Google Scholar] [CrossRef]
- Ferraty, F.; Vieu, P. Nonparametric Functional Data Analysis; Springer Series in Statistics; Springer: New York, NY, USA, 2006. [Google Scholar]
- Bayer, S.; Dimitriadis, T. Regression-Based Expected Shortfall Backtesting. J. Financ. Econom. 2022, 20, 437–471. [Google Scholar] [CrossRef]
- Kara-Zaïtri, L.; Laksaci, A.; Rachdi, M.; Vieu, P. Data-driven kNN estimation for various problems involving functional data. J. Multivariate Anal. 2017, 153, 176–188. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Example | Cases | p = 0.9 | p = 0.5 | p = 0.1 | p = 0.05 | p = 0.01 |
|---|---|---|---|---|---|---|
| Case: Normal distribution | 0.06 | 0.04 | 0.03 | 0.098 | 0.096 | |
| 0.091 | 0.092 | 0.098 | 0.094 | 0.07 | ||
| 0.12 | 0.13 | 0.17 | 0.14 | 0.19 | ||
| 0.18 | 0.17 | 0.15 | 0.11 | 0.10 | ||
| 0.23 | 0.39 | 0.22 | 0.27 | 0.37 | ||
| 0.32 | 0.37 | 0.35 | 0.33 | 0.39 | ||
| Case: Log-normal distribution | 0.02 | 0.01 | 0.007 | 0.0042 | 0.006 | |
| 0.089 | 0.091 | 0.098 | 0.090 | 0.06 | ||
| 0.091 | 0.097 | 0.065 | 0.078 | 0.081 | ||
| 0.11 | 0.10 | 0.098 | 0.087 | 0.086 | ||
| 0.15 | 0.19 | 0.16 | 0.12 | 0.19 | ||
| 0.13 | 0.17 | 0.18 | 0.15 | 0.15 |
| Example | Cases | p = 0.9 | p = 0.5 | p = 0.1 | p = 0.05 | p = 0.01 |
|---|---|---|---|---|---|---|
| Case: Normal distribution | 0.11 | 0.12 | 0.13 | 0.14 | 0.099 | |
| 0.091 | 0.094 | 0.099 | 0.089 | 0.107 | ||
| 0.18 | 0.20 | 0.27 | 0.32 | 0.39 | ||
| 0.46 | 0.49 | 0.32 | 0.38 | 0.29 | ||
| 0.23 | 0.22 | 0.24 | 0.27 | 0.24 | ||
| 0.42 | 0.39 | 0.41 | 0.40 | 0.36 | ||
| Case: Log-normal distribution | 0.096 | 0.082 | 0.088 | 0.065 | 0.074 | |
| 0.088 | 0.089 | 0.095 | 0.091 | 0.06 | ||
| 0.12 | 0.13 | 0.17 | 0.14 | 0.19 | ||
| 0.093 | 0.089 | 0.092 | 0.087 | 0.088 | ||
| 0.22 | 0.34 | 0.17 | 0.22 | 0.34 | ||
| 0.13 | 0.24 | 0.27 | 0.19 | 0.16 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alamari, M.B.; Almulhim, F.A.; Kaid, Z.; Laksaci, A. k-Nearest Neighbors Estimator for Functional Asymmetry Shortfall Regression. Symmetry 2024, 16, 928. https://doi.org/10.3390/sym16070928
Alamari MB, Almulhim FA, Kaid Z, Laksaci A. k-Nearest Neighbors Estimator for Functional Asymmetry Shortfall Regression. Symmetry. 2024; 16(7):928. https://doi.org/10.3390/sym16070928
Chicago/Turabian StyleAlamari, Mohammed B., Fatimah A. Almulhim, Zoulikha Kaid, and Ali Laksaci. 2024. "k-Nearest Neighbors Estimator for Functional Asymmetry Shortfall Regression" Symmetry 16, no. 7: 928. https://doi.org/10.3390/sym16070928
APA StyleAlamari, M. B., Almulhim, F. A., Kaid, Z., & Laksaci, A. (2024). k-Nearest Neighbors Estimator for Functional Asymmetry Shortfall Regression. Symmetry, 16(7), 928. https://doi.org/10.3390/sym16070928