
A Novel Self-Adaptive Deformable Convolution-Based U-Net for Low-Light Image Denoising

Abstract
1. Introduction
- (1)
- A novel low-light image denoising model termed SD-UNet is proposed to specially address the challenge of low-light image denoising caused by the weak noise distribution modeling ability of existing deep models. The proposed method can extract more reliable noise distribution representations and achieve low-light image denoising effectively.
- (2)
- A self-adaptive learning block combined with deformable convolution is leveraged to overcome the limitation of a fixed convolution kernel size. The deformable convolution has a flexible receptive field, and the self-adaptive learning block can enable the network to automatically select a learning branch with an appropriate scale, which will effectively improve the noise feature extraction ability of the proposed SD-UNet.
- (3)
- A novel structural loss function is proposed to facilitate the parameter optimization process. The proposed loss function can evaluate the difference between a denoised image and the ground-truth clean image more precisely, thus guiding the model parameter optimization process and improving the model’s ability to extract noise distribution more effectively.
2. Related Work
2.1. Physics-Based Methods
2.2. Learning-Based Methods
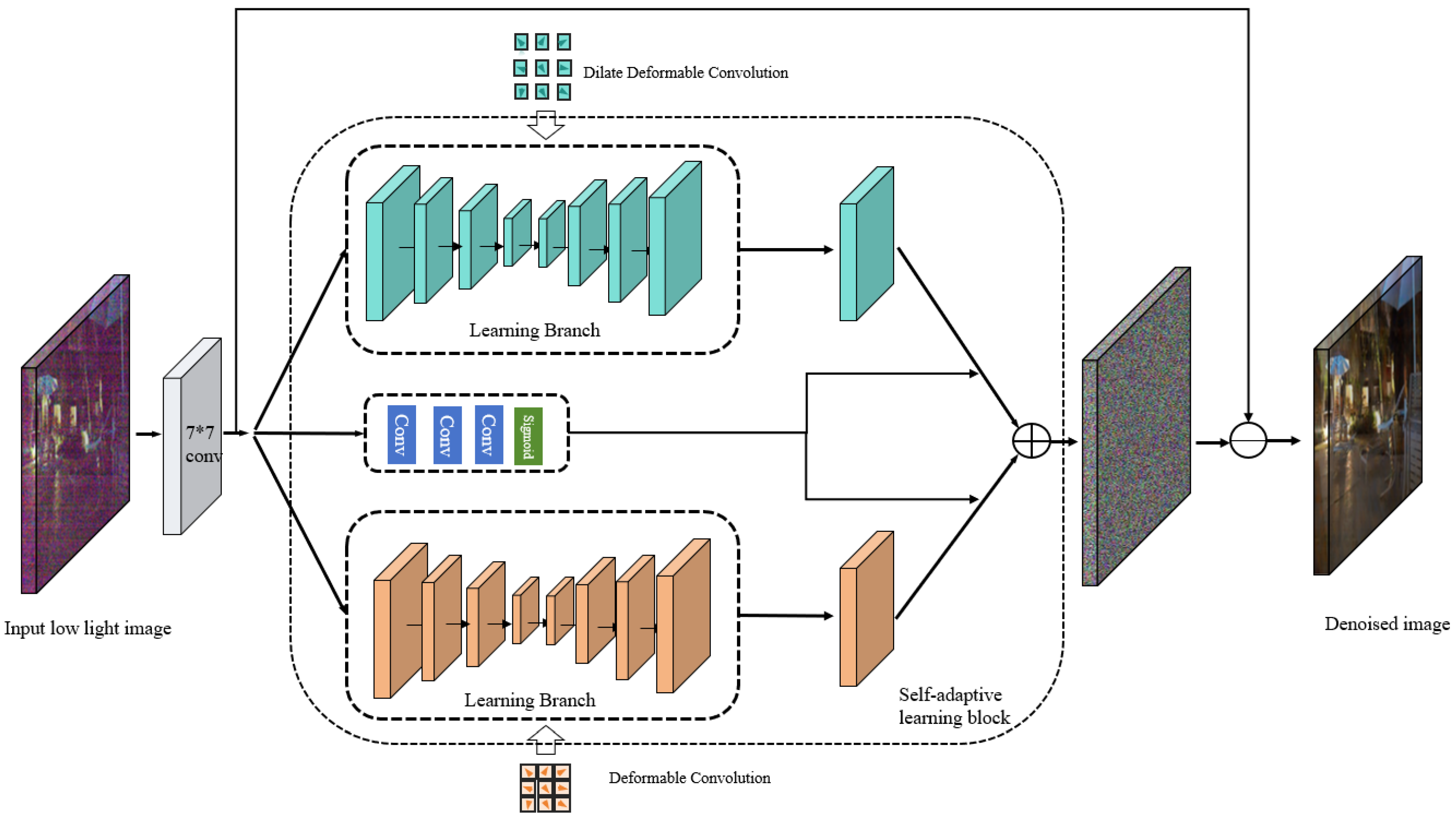
3. SD-UNet
3.1. The Overall Structure of SD-UNet
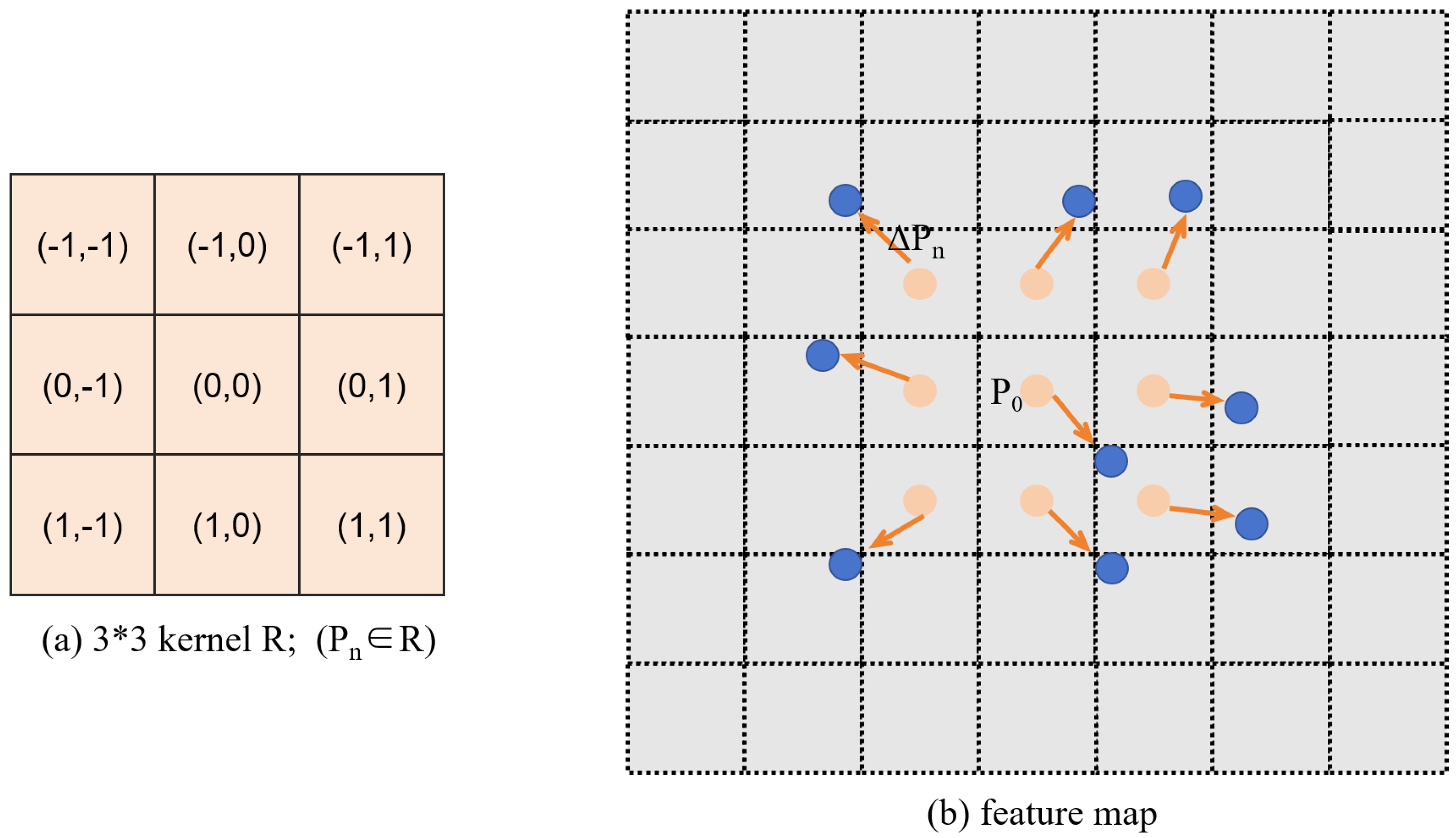
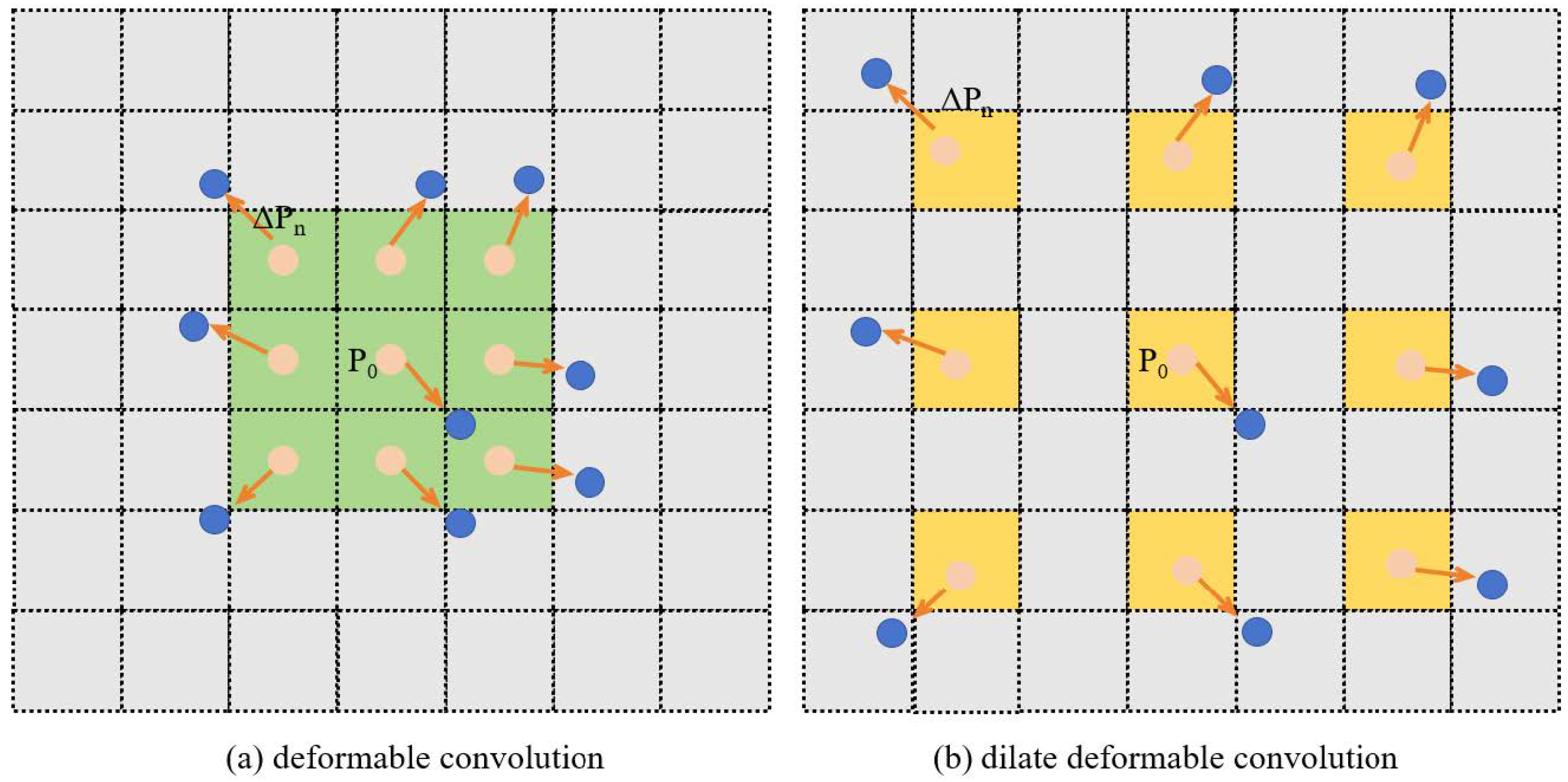
3.2. Deformable Convolution
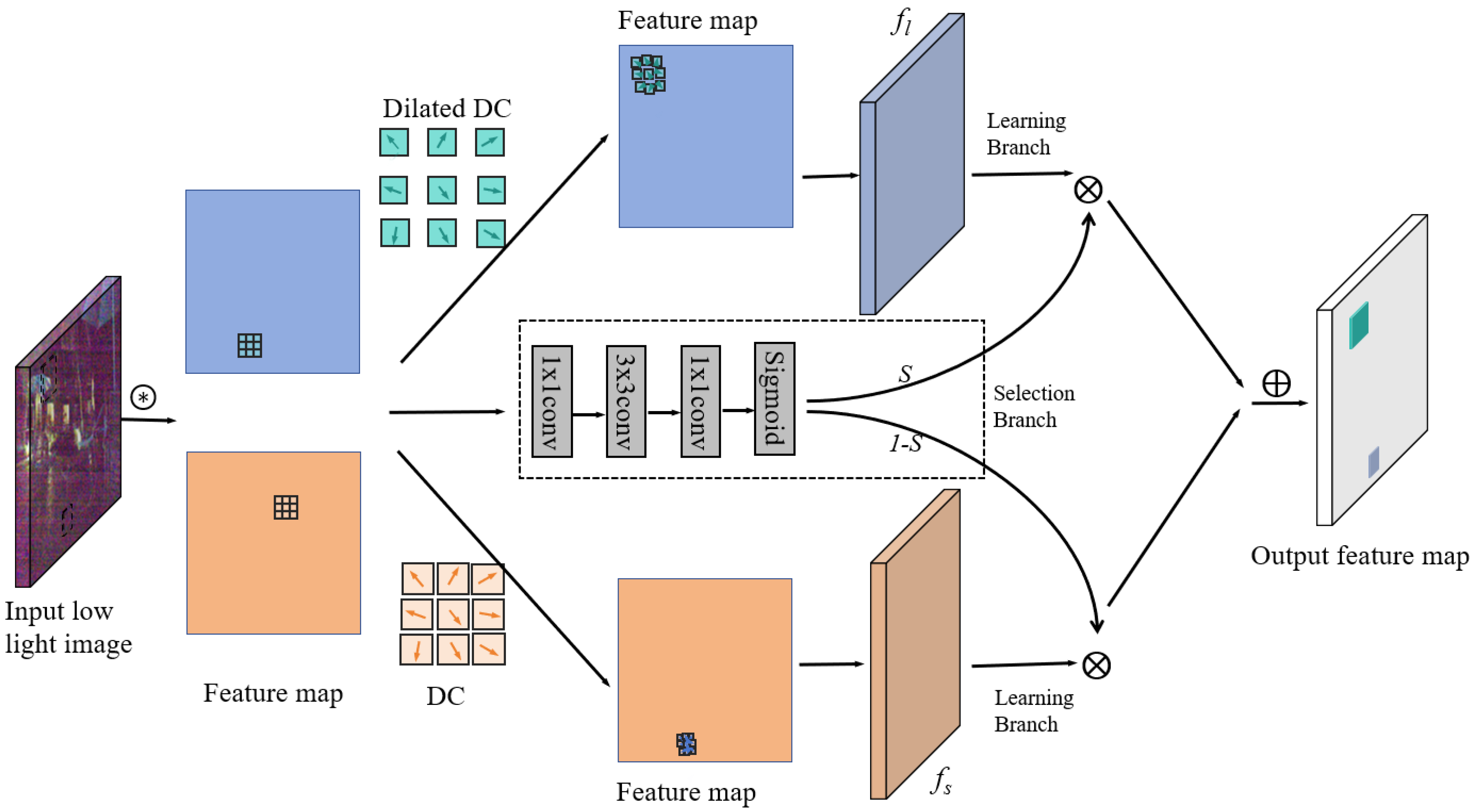
3.3. Self-Adaptive Learning Block
3.4. Structural Loss Function
4. Experiments
4.1. Experiment Details
4.2. Comparison with SOTA Methods
4.3. Ablation Study
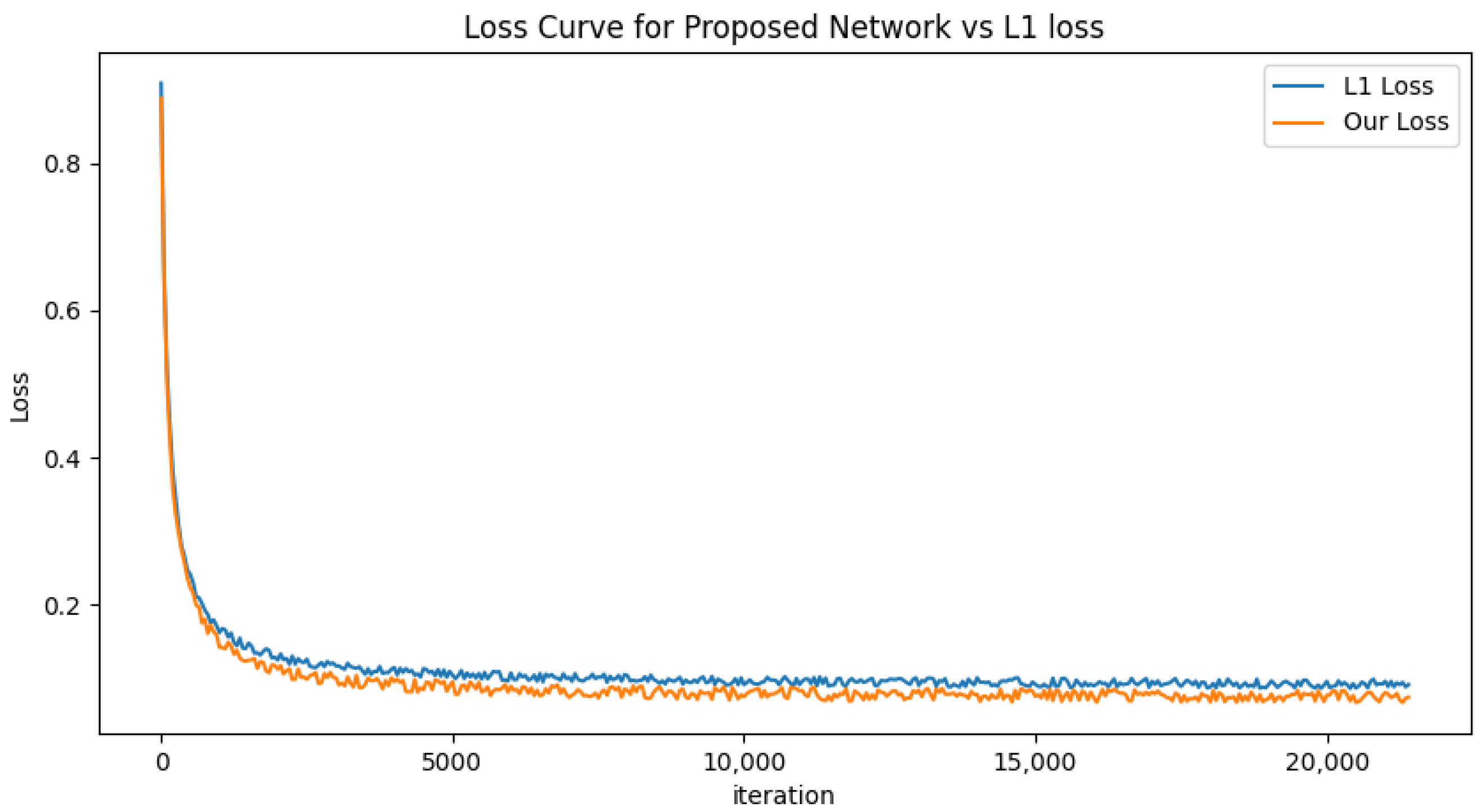
4.4. The Effectiveness of the Proposed Loss Function
4.5. Further Experimental Results on the ELD Dataset
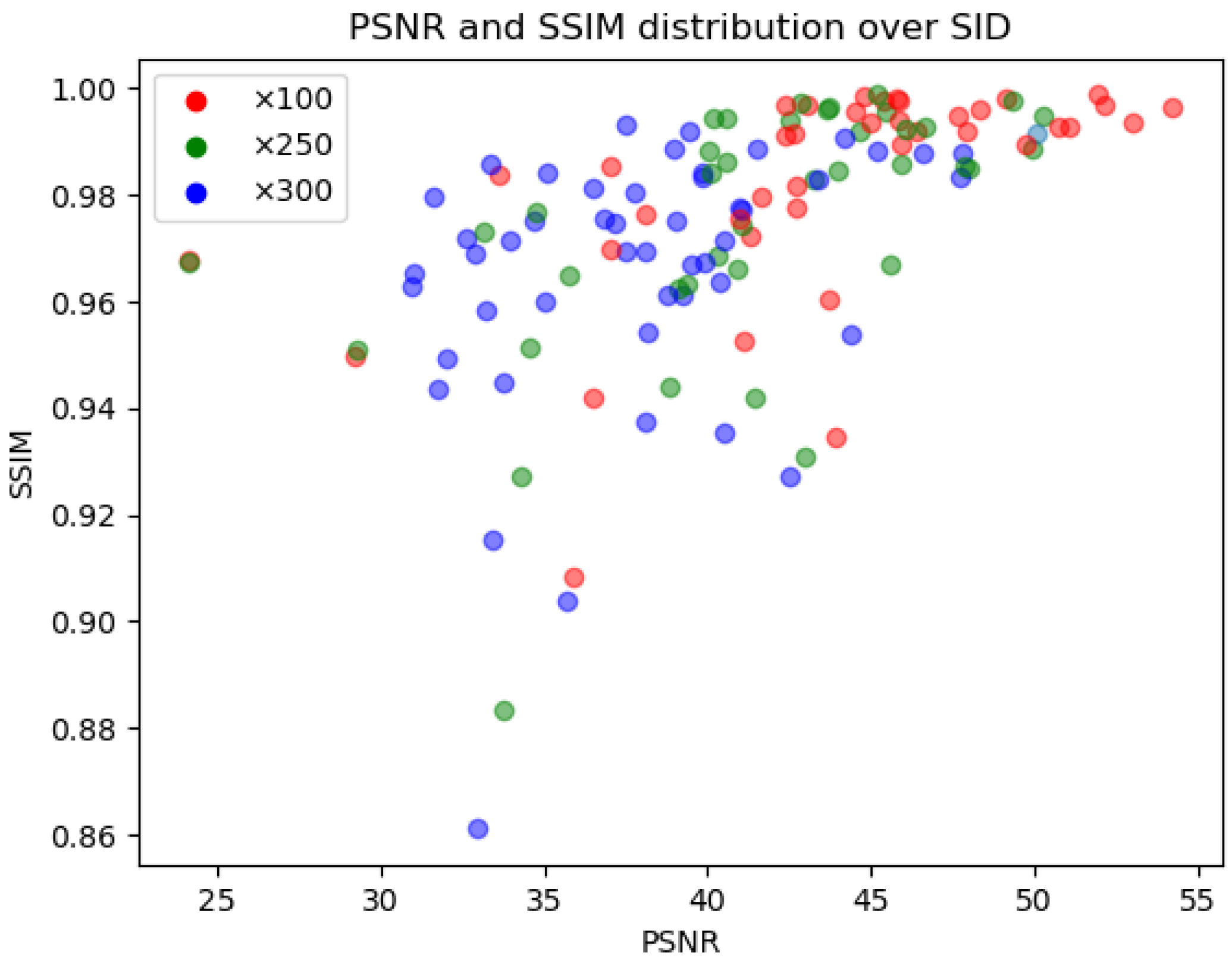
4.6. Visual Results Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hasinoff, S.W.; Sharlet, D.; Geiss, R.; Adams, A.; Barron, J.T.; Kainz, F.; Chen, J.; Levoy, M. Burst photography for high dynamic range and low-light imaging on mobile cameras. ACM Trans. Graph. (ToG) 2016, 35, 1–12. [Google Scholar] [CrossRef]
- Liba, O.; Murthy, K.; Tsai, Y.T.; Brooks, T.; Xue, T.; Karnad, N.; He, Q.; Barron, J.T.; Sharlet, D.; Geiss, R.; et al. Handheld mobile photography in very low light. ACM Trans. Graph. 2019, 38, 164. [Google Scholar] [CrossRef]
- Guerrieri, F.; Tisa, S.; Zappa, F. Fast single-photon imager acquires 1024 pixels at 100 kframe/s. In Proceedings of the Sensors, Cameras, and Systems for Industrial/Scientific Applications X, San Jose, CA, USA, 20–22 January 2009; Volume 7249, pp. 213–223. [Google Scholar]
- Morris, P.A.; Aspden, R.S.; Bell, J.E.; Boyd, R.W.; Padgett, M.J. Imaging with a small number of photons. Nat. Commun. 2015, 6, 5913. [Google Scholar] [CrossRef] [PubMed]
- Xu, J.; Zhang, L.; Zhang, D.; Feng, X. Multi-channel weighted nuclear norm minimization for real color image denoising. In Proceedings of the IEEE international Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1096–1104. [Google Scholar]
- Xu, J.; Zhang, L.; Zhang, D. A trilateral weighted sparse coding scheme for real-world image denoising. In Proceedings of the European conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 20–36. [Google Scholar]
- Guo, S.; Yan, Z.; Zhang, K.; Zuo, W.; Zhang, L. Toward convolutional blind denoising of real photographs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1712–1722. [Google Scholar]
- Brooks, T.; Mildenhall, B.; Xue, T.; Chen, J.; Sharlet, D.; Barron, J.T. Unprocessing images for learned raw denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11036–11045. [Google Scholar]
- Foi, A.; Trimeche, M.; Katkovnik, V.; Egiazarian, K. Practical Poissonian–Gaussian noise modeling and fitting for single-image raw-data. IEEE Trans. Image Process. 2008, 17, 1737–1754. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Zhang, Y.; Li, W.; Sun, W.; Tao, R.; Du, Q. Single-source domain expansion network for cross-scene hyperspectral image classification. IEEE Trans. Image Process. 2023, 32, 1498–1512. [Google Scholar] [CrossRef] [PubMed]
- Bhatti, U.A.; Huang, M.; Neira-Molina, H.; Marjan, S.; Baryalai, M.; Tang, H.; Wu, G.; Bazai, S.U. MFFCG–Multi feature fusion for hyperspectral image classification using graph attention network. Expert Syst. Appl. 2023, 229, 120496. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Chen, S.; Sun, P.; Song, Y.; Luo, P. Diffusiondet: Diffusion model for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 19830–19843. [Google Scholar]
- Wang, Z.; Li, Y.; Chen, X.; Lim, S.N.; Torralba, A.; Zhao, H.; Wang, S. Detecting everything in the open world: Towards universal object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Paris, France, 1–6 October 2023; pp. 11433–11443. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Jain, J.; Li, J.; Chiu, M.T.; Hassani, A.; Orlov, N.; Shi, H. Oneformer: One transformer to rule universal image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 2989–2998. [Google Scholar]
- Wu, J.; Fu, R.; Fang, H.; Zhang, Y.; Yang, Y.; Xiong, H.; Liu, H.; Xu, Y. Medsegdiff: Medical image segmentation with diffusion probabilistic model. In Proceedings of the Medical Imaging with Deep Learning, PMLR, Paris, France, 3–5 July 2024; pp. 1623–1639. [Google Scholar]
- Jang, G.; Lee, W.; Son, S.; Lee, K.M. C2n: Practical generative noise modeling for real-world denoising. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 2350–2359. [Google Scholar]
- Maleky, A.; Kousha, S.; Brown, M.S.; Brubaker, M.A. Noise2noiseflow: Realistic camera noise modeling without clean images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17632–17641. [Google Scholar]
- Zhang, Y.; Qin, H.; Wang, X.; Li, H. Rethinking noise synthesis and modeling in raw denoising. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 4593–4601. [Google Scholar]
- Chen, C.; Chen, Q.; Do, M.N.; Koltun, V. Seeing motion in the dark. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3185–3194. [Google Scholar]
- Monakhova, K.; Richter, S.R.; Waller, L.; Koltun, V. Dancing under the stars: Video denoising in starlight. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16241–16251. [Google Scholar]
- Moseley, B.; Bickel, V.; López-Francos, I.G.; Rana, L. Extreme low-light environment-driven image denoising over permanently shadowed lunar regions with a physical noise model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6317–6327. [Google Scholar]
- Wang, J.; Yu, Y.; Wu, S.; Lei, C.; Xu, K. Rethinking noise modeling in extreme low-light environments. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Wei, K.; Fu, Y.; Zheng, Y.; Yang, J. Physics-based noise modeling for extreme low-light photography. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 8520–8537. [Google Scholar] [CrossRef] [PubMed]
- Cao, Y.; Liu, M.; Liu, S.; Wang, X.; Lei, L.; Zuo, W. Physics-guided iso-dependent sensor noise modeling for extreme low-light photography. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 5744–5753. [Google Scholar]
- Chang, K.C.; Wang, R.; Lin, H.J.; Liu, Y.L.; Chen, C.P.; Chang, Y.L.; Chen, H.T. Learning camera-aware noise models. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 343–358. [Google Scholar]
- Abdelhamed, A.; Lin, S.; Brown, M.S. A high-quality denoising dataset for smartphone cameras. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1692–1700. [Google Scholar]
- Feng, H.; Wang, L.; Wang, Y.; Huang, H. Learnability enhancement for low-light raw denoising: Where paired real data meets noise modeling. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 1436–1444. [Google Scholar]
- Chen, C.; Chen, Q.; Xu, J.; Koltun, V. Learning to see in the dark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3291–3300. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Janesick, J.; Klaasen, K.; Elliott, T. CCD charge collection efficiency and the photon transfer technique. In Proceedings of the Solid-State Imaging Arrays, San Diego, CA, USA, 22–23 August 1985; Volume 570, pp. 7–19. [Google Scholar]
- Joiner, B.L.; Rosenblatt, J.R. Some properties of the range in samples from Tukey’s symmetric lambda distributions. J. Am. Stat. Assoc. 1971, 66, 394–399. [Google Scholar] [CrossRef]
- Gow, R.D.; Renshaw, D.; Findlater, K.; Grant, L.; McLeod, S.J.; Hart, J.; Nicol, R.L. A comprehensive tool for modeling CMOS image-sensor-noise performance. IEEE Trans. Electron Devices 2007, 54, 1321–1329. [Google Scholar] [CrossRef]
- Abdelhamed, A.; Brubaker, M.A.; Brown, M.S. Noise flow: Noise modeling with conditional normalizing flows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3165–3173. [Google Scholar]
- Wang, J.; Li, P.; Deng, J.; Du, Y.; Zhuang, J.; Liang, P.; Liu, P. CA-GAN: Class-condition attention GAN for underwater image enhancement. IEEE Access 2020, 8, 130719–130728. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Anoosheh, A.; Sattler, T.; Timofte, R.; Pollefeys, M.; Van Gool, L. Night-to-day image translation for retrieval-based localization. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 5958–5964. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Lakmal, H.; Dissanayake, M. Illuminating the Roads: Night-to-Day Image Translation for Improved Visibility at Night. In Proceedings of the International Conference on Asia Pacific Advanced Network, Colombo, Sri Lanka, 24–25 August 2023; pp. 13–26. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H.; Shao, L. Learning enriched features for fast image restoration and enhancement. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1934–1948. [Google Scholar] [CrossRef] [PubMed]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configuration Item | Value |
|---|---|
| Central processing unit | Intel(R) Xeon(R) CPU E5-2650 v3 |
| Graphics processor unit | NVIDIA Tesla T4 16 GB |
| Operating system | Ubuntu 18.04.2 LTS (64-bit) |
| Memory | 128 GB |
| Hard Disk | 2 TB |
| Method | ×100 | ×250 | ×300 | |||
|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | |
| P-G [9] | 39.03 | 0.926 | 35.57 | 0.861 | 32.26 | 0.781 |
| Noiseflow [41] | 41.08 | 0.923 | 36.90 | 0.836 | 32.38 | 0.753 |
| Paired Data [36] | 42.03 | 0.953 | 39.57 | 0.937 | 36.57 | 0.922 |
| ELD [31] | 41.95 | 0.953 | 39.44 | 0.931 | 36.36 | 0.911 |
| MiRNet [47] | 41.27 | 0.949 | 38.74 | 0.927 | 36.08 | 0.897 |
| SFRN [26] | 42.31 | 0.955 | 39.60 | 0.938 | 36.85 | 0.923 |
| PMN [35] | 43.16 | 0.960 | 40.92 | 0.947 | 37.64 | 0.934 |
| SD-UNet | 42.79 | 0.958 | 40.04 | 0.941 | 36.98 | 0.926 |
| DC | SALB | ×100 | ×250 | ×300 | ||
|---|---|---|---|---|---|---|
| ✓ | PSNR | 42.33 | 39.72 | 36.75 | ||
| SSIM | 0.955 | 0.938 | 0.922 | |||
| ✓ | PSNR | 42.18 | 39.65 | 36.60 | ||
| SSIM | 0.956 | 0.941 | 0.924 | |||
| ✓ | ✓ | PSNR | 42.51 | 39.91 | 36.90 | |
| SSIM | 0.956 | 0.939 | 0.923 | |||
| ✓ | ✓ | PSNR | 42.38 | 39.88 | 36.83 | |
| SSIM | 0.957 | 0.941 | 0.926 | |||
| ✓ | ✓ | ✓ | PSNR | 42.79 | 40.04 | 36.98 |
| SSIM | 0.958 | 0.941 | 0.926 |
| Method | ×100 | ×250 | ×300 | |||
|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | |
| Loss | 42.79 | 0.958 | 40.04 | 0.941 | 36.98 | 0.926 |
| L1 Loss | 42.53 | 0.931 | 40.03 | 0.925 | 36.71 | 0.912 |
| L1+ Loss | 42.77 | 0.959 | 0.942 | 0.959 | 36.96 | 0.927 |
| Method | Sony A7S2 | Nikon D850 | ||||||
|---|---|---|---|---|---|---|---|---|
| ×100 | ×200 | ×100 | ×200 | |||||
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | |
| P-G [9] | 41.72 | 0.925 | 39.27 | 0.870 | 41.68 | 0.907 | 39.99 | 0.887 |
| Noiseflow [41] | 41.05 | 0.924 | 39.23 | 0.889 | 41.55 | 0.881 | 38.95 | 0.820 |
| Paired Data [36] | 44.43 | 0.964 | 41.95 | 0.927 | 43.01 | 0.950 | 41.10 | 0.926 |
| ELD [31] | 45.40 | 0.971 | 43.41 | 0.954 | 42.85 | 0.949 | 41.08 | 0.928 |
| MiRNet [47] | 44.83 | 0.967 | 42.17 | 0.932 | 42.34 | 0.938 | 40.47 | 0.919 |
| SFRN [26] | 45.74 | 0.976 | 43.84 | 0.955 | 43.04 | 0.949 | 41.28 | 0.930 |
| PMN [35] | 46.50 | 0.985 | 44.51 | 0.973 | 43.28 | 0.960 | 41.32 | 0.941 |
| SD-UNet | 45.83 | 0.979 | 43.67 | 0.948 | 43.18 | 0.952 | 41.27 | 0.931 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Cao, J.; Guo, H.; Li, C. A Novel Self-Adaptive Deformable Convolution-Based U-Net for Low-Light Image Denoising. Symmetry 2024, 16, 646. https://doi.org/10.3390/sym16060646
Wang H, Cao J, Guo H, Li C. A Novel Self-Adaptive Deformable Convolution-Based U-Net for Low-Light Image Denoising. Symmetry. 2024; 16(6):646. https://doi.org/10.3390/sym16060646
Chicago/Turabian StyleWang, Hua, Jianzhong Cao, Huinan Guo, and Cheng Li. 2024. "A Novel Self-Adaptive Deformable Convolution-Based U-Net for Low-Light Image Denoising" Symmetry 16, no. 6: 646. https://doi.org/10.3390/sym16060646
APA StyleWang, H., Cao, J., Guo, H., & Li, C. (2024). A Novel Self-Adaptive Deformable Convolution-Based U-Net for Low-Light Image Denoising. Symmetry, 16(6), 646. https://doi.org/10.3390/sym16060646