1. Introduction
Initially, Treyer [
1] introduced the inverse Rayleigh distribution as a model for analyzing reliability and survival data. The model later underwent further examination by Voda [
2], who observed that the lifetime distributions of various experimental units could be closely approximated with the inverse Rayleigh distribution. Additionally, Voda explored its properties and provided a maximum likelihood (ML) estimator for the scale parameter.
Gharraph [
3] conducted an in-depth analysis of the inverse Rayleigh distribution, deriving five key measures of location: the mean, harmonic mean, geometric mean, mode, and median. Furthermore, Gharraph explored various estimation methods to determine the unknown parameter of this distribution. A numerical comparison of these estimation techniques was conducted, focusing on their bias and root-mean-squared error (RMSE), providing valuable insights into their performance and applicability.
Mukherjee and Maiti [
4] developed a percentile estimator for the scale parameter
of one-parameter inverse Rayleigh distribution and investigated its asymptotic efficiency. Howlader et al. [
5] established Bayesian prediction bounds for both Rayleigh and inverse Rayleigh lifetime models. Additionally, they demonstrated that the inverse Rayleigh (IR) model can serve as a viable alternative to the log-normal distribution for analyzing the survival time of specific diseases. Soliman et al. [
6] addressed both Bayesian and non-Bayesian issues related to parameter estimation in the IR distribution.
Almarashi et al. [
7] propose a two-parameter extension of the inverse Rayleigh distribution, employing the half-logistic transformation to address limitations in modeling moderately right-skewed or near-symmetrical lifetime data. Their theoretical contributions encompass mathematical properties and empirical evidence, demonstrating the model’s effectiveness in handling diverse right-skewed datasets.
Chiodo and Noia [
8] present the inverse Rayleigh probability distribution as a robust model for estimating extreme wind speeds, crucial in wind power production and mechanical safety assessment. Their study not only validates the model’s capability in interpreting real wind speed data, but also introduces a novel Bayesian approach for estimating a dynamic “risk index”. Through extensive numerical simulations, they highlight the method’s precision and robustness, emphasizing its practical relevance for system engineers.
Furthermore, Chiodo et al. [
9] introduce the compound inverse Rayleigh distribution as a model tailored for extreme wind speeds, essential in wind power generation and turbine safety evaluation. They provide a practical framework for real-world data analysis, accompanied by a novel Bayesian estimation approach, supported by extensive numerical simulations and robustness assessments.
In a different context, Bakoban and Al-Shehri [
10] introduce the beta generalized inverse Rayleigh distribution, a four-parameter lifetime model, and conduct a comprehensive investigation into its properties and applications, further expanding the domain of inverse Rayleigh-based distributions.
Several generalizations of the inverse Rayleigh distribution have been recently proposed by numerous authors, with the aim of enhancing its adaptability. For example, Khan et al. [
11] studied the modified inverse Rayleigh distribution and discussed its theoretical properties. Khan and King [
12] enhanced the inverse Rayleigh distribution by proposing the transmuted modified inverse Rayleigh distribution, a new variant crafted through the utilization of the quadratic rank transmutation map (QRTM). Goual and Yousof [
13] introduced an extension of the inverse Rayleigh distribution, termed the Burr XII inverse Rayleigh model, by integrating the Burr XII family framework initially introduced by Cordeiro et al. [
14]. Ali [
15] explored the use of the inverse Rayleigh distribution in mixture models to analyze the complex nature of engineering systems’ lifetimes. Drawing on the weighted distributions framework established by Fisher [
16] and Rao [
17], Fatima and Ahmad [
18] introduced the Weighted Inverse Rayleigh (WIR) distribution. They conducted a comprehensive study of its statistical properties, contributing to the understanding and application of weighted distribution models in statistical analysis.
Rao and Mbwambo [
19] developed the exponentiated inverse Rayleigh distribution (EIRD) to offer a more adaptable approach for life data analysis. This study examines its key statistical characteristics and assesses different estimation techniques such as the maximum likelihood and least squares. Banerjee and Bhunia [
20] introduced the exponential transformed inverse Rayleigh distribution.
The generation of new distributions by adding one or more parameters to standard distributions enhances their applicability to complex data across various fields. Motivated by this approach, several authors have proposed different methods for generating new distributions. These include the Marshall–Olkin-G distribution [
21], the Beta-G distribution introduced by Eugene et al. [
22], the Kumaraswamy-G distribution by Cordeiro and Castro [
23], and the McDonald-G distribution by Alexander et al. [
24]. Shaw and Buckley [
25] introduced the transmuted-G class of distributions, which was further expanded by the development of the exponentiated transmuted-G distribution [
26] and the generalized transmuted G distribution [
27].
Definition 1 ([
27])
. A random variable X is said to have a generalized transmuted-G distribution if its cumulative distribution function (CDF) is given by:where denotes the baseline cumulative distribution function. The density function corresponding to this
is given by
where
denotes the baseline probability density function.
Definition 2. A continuous random variable X is said to have an inverse Rayleigh distribution if its PDF is given by: The CDF of the inverse Rayleigh distribution is given by:
Substituting the PDF and CDF of the inverse Rayleigh distribution into Equations (1) and (2) results in the development of a new three-parameter inverse Rayleigh distribution, named the generalized transmuted inverse Rayleigh distribution.
Definition 3. A continuous random variable X is said to have a generalized transmuted inverse Rayleigh distribution (GTIR) if its PDF is given by:for and The cumulative distribution function of the generalized transmuted inverse Rayleigh distribution is given by:
for
and
The hazard rate function (HRF) of the generalized transmuted inverse Rayleigh distribution is given by:
Gupta [
28] utilized the expression
to ascertain the monotonicity of the hazard function. Differentiating
with respect to
x, we obtain:
Now,
and
possess the same properties, and so, if
is unimodal, called an upside bathtub (UBT), we have
for
,
, and
for
where
can be obtained by solving the following equation:
Solving this equation analytically would be quite complex due to its structure, involving both polynomial and exponential terms in . Such equations usually do not have simple closed-form solutions and are typically approached with numerical methods for specific values of , , and .
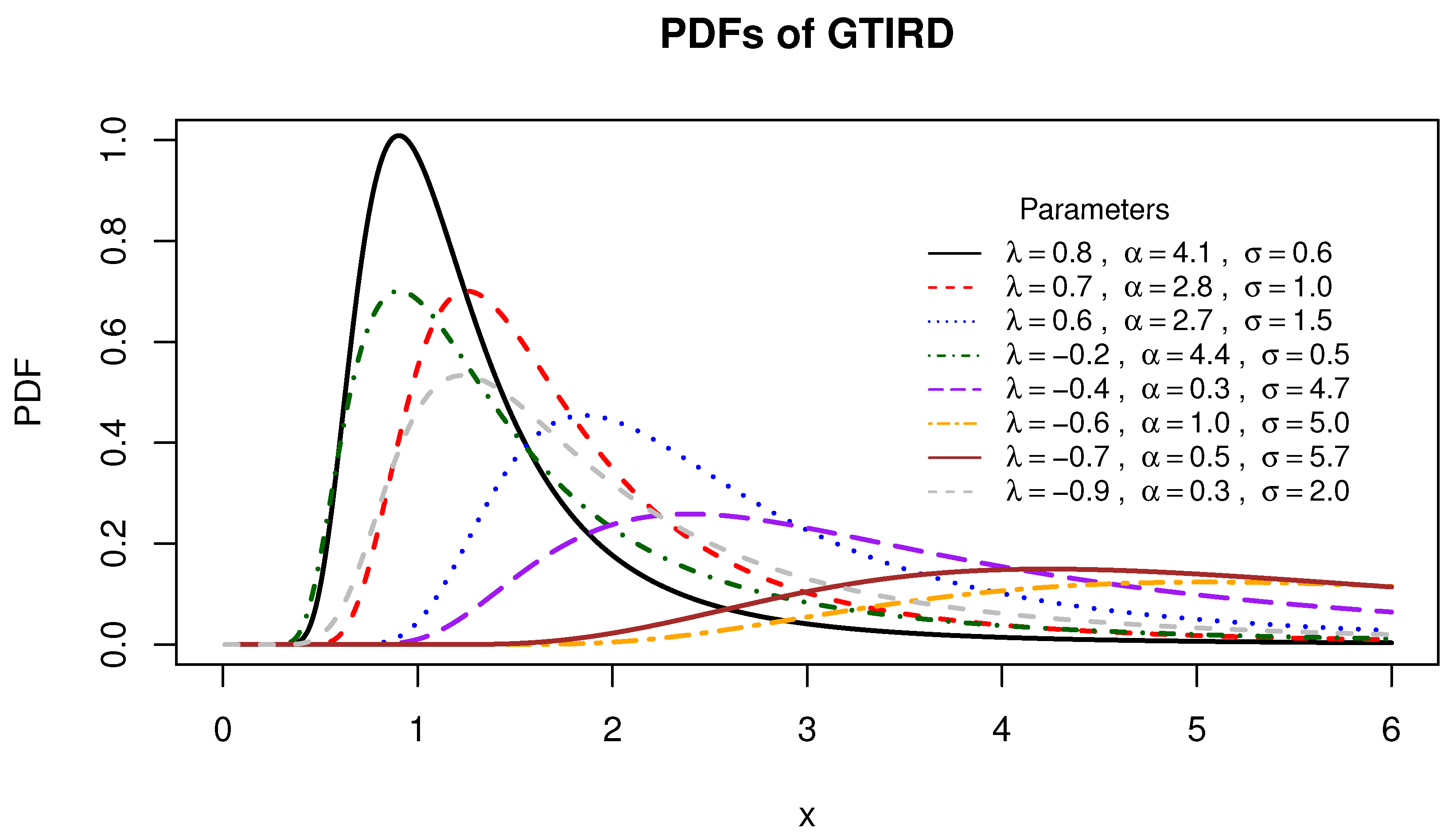
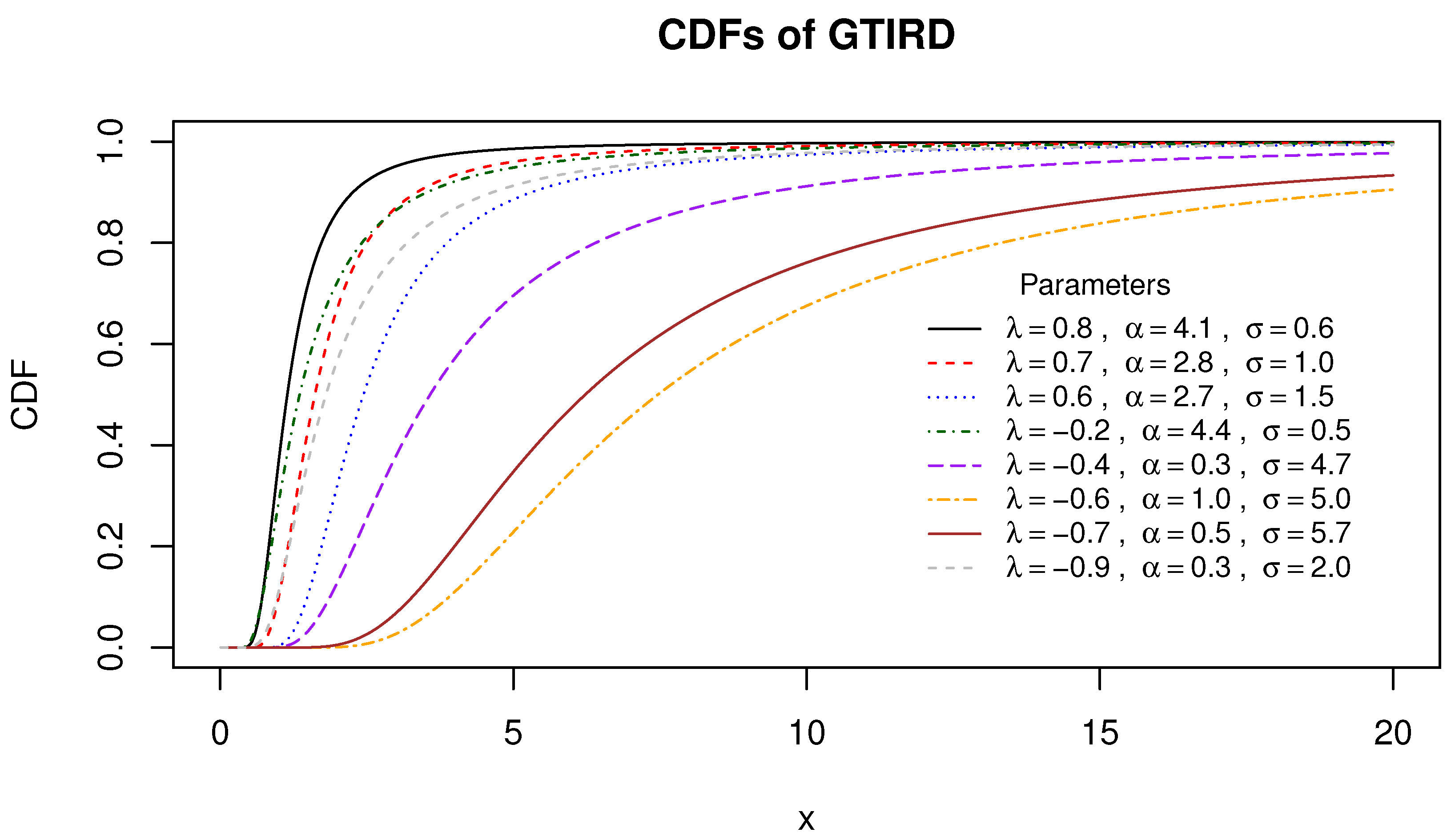
Figure 1,
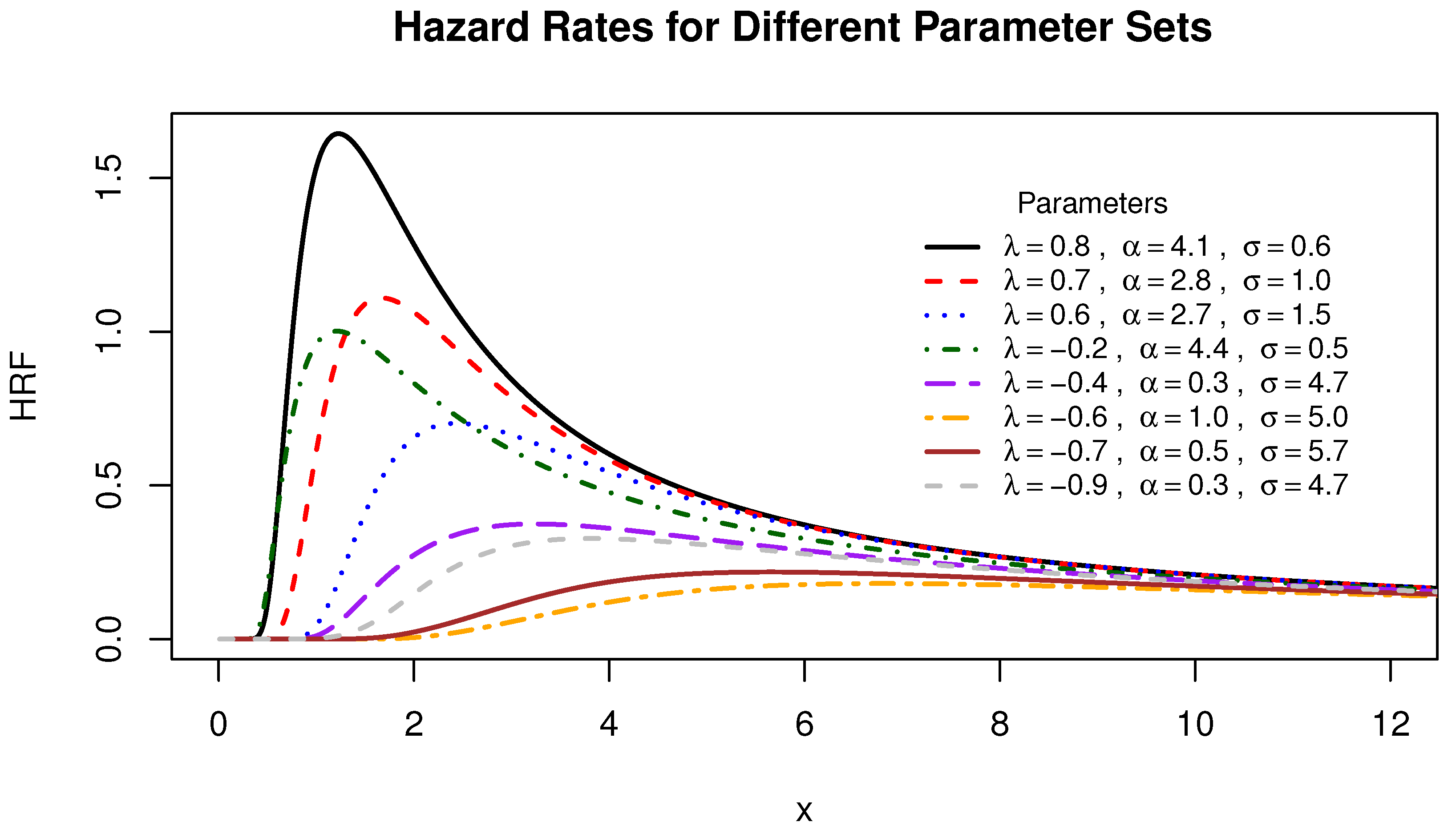
Figure 2 and
Figure 3 illustrate the variability in the shapes of the PDF, CDF, and HRF for the generalized transmuted inverse Rayleigh distribution.
Figure 1 illustrates that the probability density function of the generalized transmuted inverse Rayleigh distribution displays shapes marked by decreasing, increasing, and unimodal patterns. From
Figure 3, it is deduced that the hazard function of the generalized transmuted inverse Rayleigh distribution showcases a pattern characterized by decreasing, increasing, and unimodal shapes.
By varying the parameters, distinct distributions are obtained. For instance, when and , the inverse Rayleigh distribution is attained. For and , the transmuted inverse Rayleigh distribution is derived. Additionally, when , the exponentiated inverse Rayleigh distribution with a shape parameter of is obtained.
4. Quantile Function
In the study of probability distributions, the
th percentile, denoted as
, where
, is mathematically characterized by the value at which the cumulative distribution function (CDF),
F, attains the probability
p. This relationship is formalized by the equation:
Theorem 3. The quantile function of the generalized transmuted inverse Rayleigh distribution, with parameters λ, α, and σ, is given by Proof. Given the cumulative distribution function
, we start with the equation
For
, this equation simplifies to
By letting
, we obtain a quadratic equation in terms of
t:
Substituting
t back in terms of
, we obtain the quantile function as
For
, Equation (
14) simplifies to
which, upon rearrangement, yields the expression for
:
Solving for
, we obtain:
□
Typically, the primary quartiles are identified as , signifying the 25th percentile with ; , denoting the median or 50th percentile with ; and , which corresponds to the 75th percentile with . These values are derived by setting the probabilities , , and into . Furthermore, quartiles play a crucial role in determining the asymmetry and tail thickness of a distribution by aiding in the computation of its skewness and kurtosis.
Assume a uniformly distributed variable
U over the interval
, indicated as
. Utilizing the equation referenced as (
13), we can simulate a set of
n random numbers consistent with a generalized transmuted inverse Rayleigh distribution. The formula to compute each random value
is given by:
where
i = 1, 2, 3, …,
n.
15. Application to a Real Data Set
In this section, we analyze two real datasets:
Dataset 1: The first dataset originates from the study conducted by Bjerkedal [
34], which records the survival times (in days) of 72 guinea pigs after being infected with virulent tubercle bacilli. These observations are detailed in
Table 3 and are utilized to assess the fitting efficacy of the generalized transmuted inverse Rayleigh distribution in comparison to other statistical distributions: Kumaraswamy inverse Rayleigh [
35], exponentiated inverse Rayleigh (EIR) [
36], generalized inverse Rayleigh (GIR), odd Fréchet inverse Rayleigh (OFIR) [
37], and inverse Rayleigh (IR), among others. This comparison aims to demonstrate the potential superiority of the GTIR distribution in providing a more accurate fit for survival data, with the probability density functions (pdfs) of these distributions presented subsequently. The PDFs are given below:
Kumaraswamy inverse Rayleigh distribution:
Exponentiated inverse Rayleigh distribution:
Odd Fréchet inverse Rayleigh distribution:
Generalized inverse Rayleigh distribution:
where
,
,
,
,
,
, and
.
In order to compare the two distribution models, we considered criteria like the following:
Negative twice the log-likelihood ():
Akaike Information Criterion (AIC):
Corrected Akaike Information Criterion (AICC):
Bayesian Information Criterion (BIC):
Kolmogorov–Smirnov criterion (KS):
Here, k denotes the number of parameters in the model, n the sample size, and ℓ the peak value of the log-likelihood function for the model in question.
Models with lower values of the
, AIC, AICC, BIC, and KS are considered superior in terms of fit to the observed data.
Table 4 presents the computed values for the
, AIC, AICC, BIC, and KS.
The values presented in
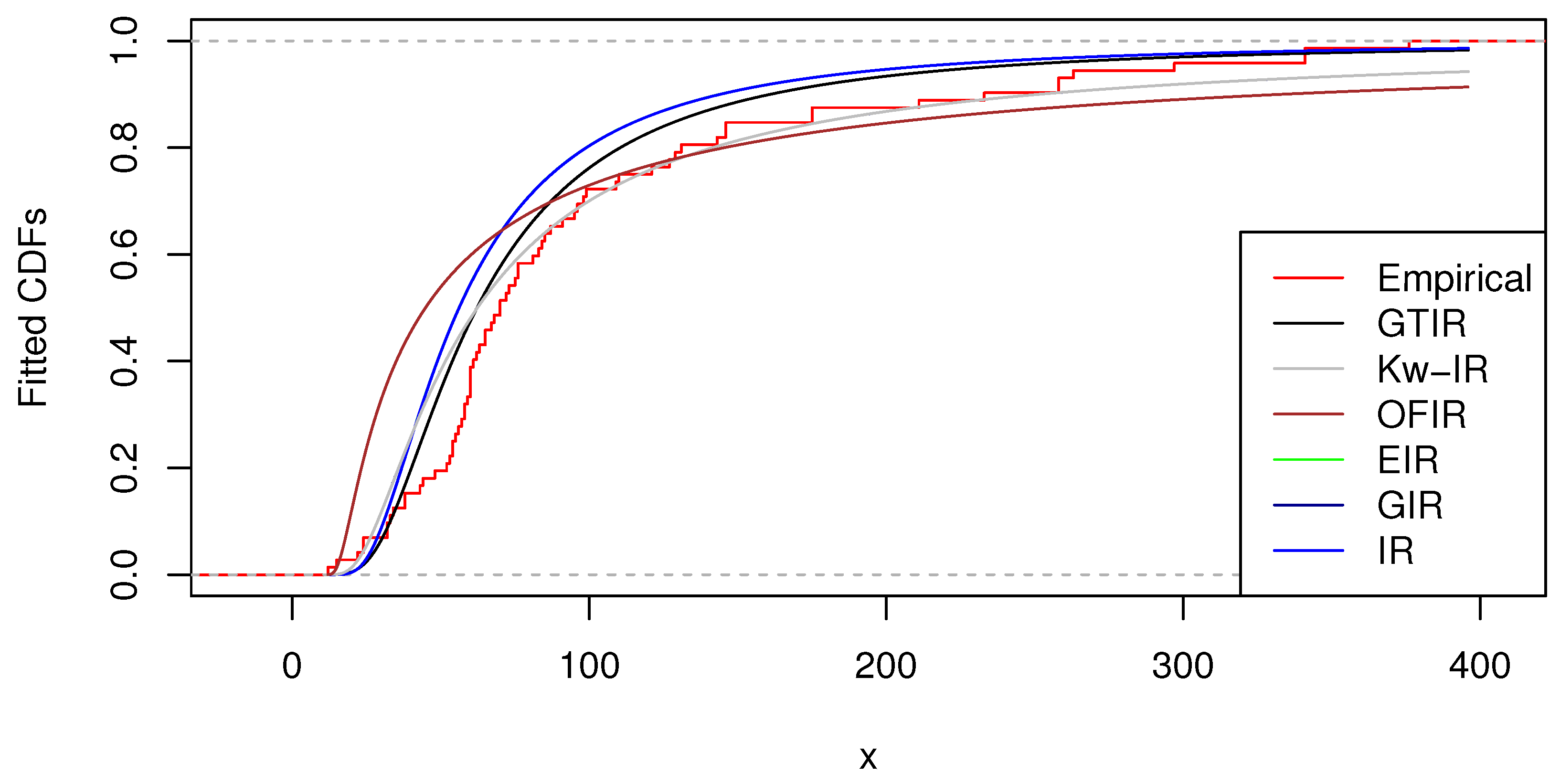
Table 4 demonstrate that the GTIR provides a superior fit to the data compared to the GIR, OFIR, Kw-IR, EIR, and IR distributions.
The likelihood ratio (LR) test statistic to test the hypotheses
vs.
for dataset I is
therefore, we reject the null hypothesis.
Figure 4 illustrates the empirical cumulative distribution function (ECDF), GIR, OFIR, Kw-IR, EIR, and IR distributions for the data presented in
Table 3.
The LSEs and MPSEs of (, ) from the GTIR for data set I are given by:
,
(, , and
(, , respectively.
Dataset 2: The second dataset, collected by Nichols and Padgett [
38], presents 100 observations on the breaking stress of carbon fibers of 50 mm in length. These data are showcased in
Table 5.
The results presented in
Table 6 indicate that, in terms of fitting the data, the generalized transmuted inverse Rayleigh distribution stands out as the most effective model among those considered. It demonstrates superior performance compared to the GIR, OFIR, Kw-IR, EIR, and IR distributions.
The likelihood ratio (LR) test statistic to test the hypotheses
vs.
for dataset II is
therefore, we reject the null hypothesis.
The LSEs and MPSEs of (, ) from the GTIR for data set II are given by:
,
(, , and
(, , respectively.





{kind=link}
{kind=link}
{kind=link}
{kind=link}