
Anti-Software Attack Ear Identification System Using Deep Feature Learning and Blockchain Protection


Abstract
1. Introduction
2. Related Work
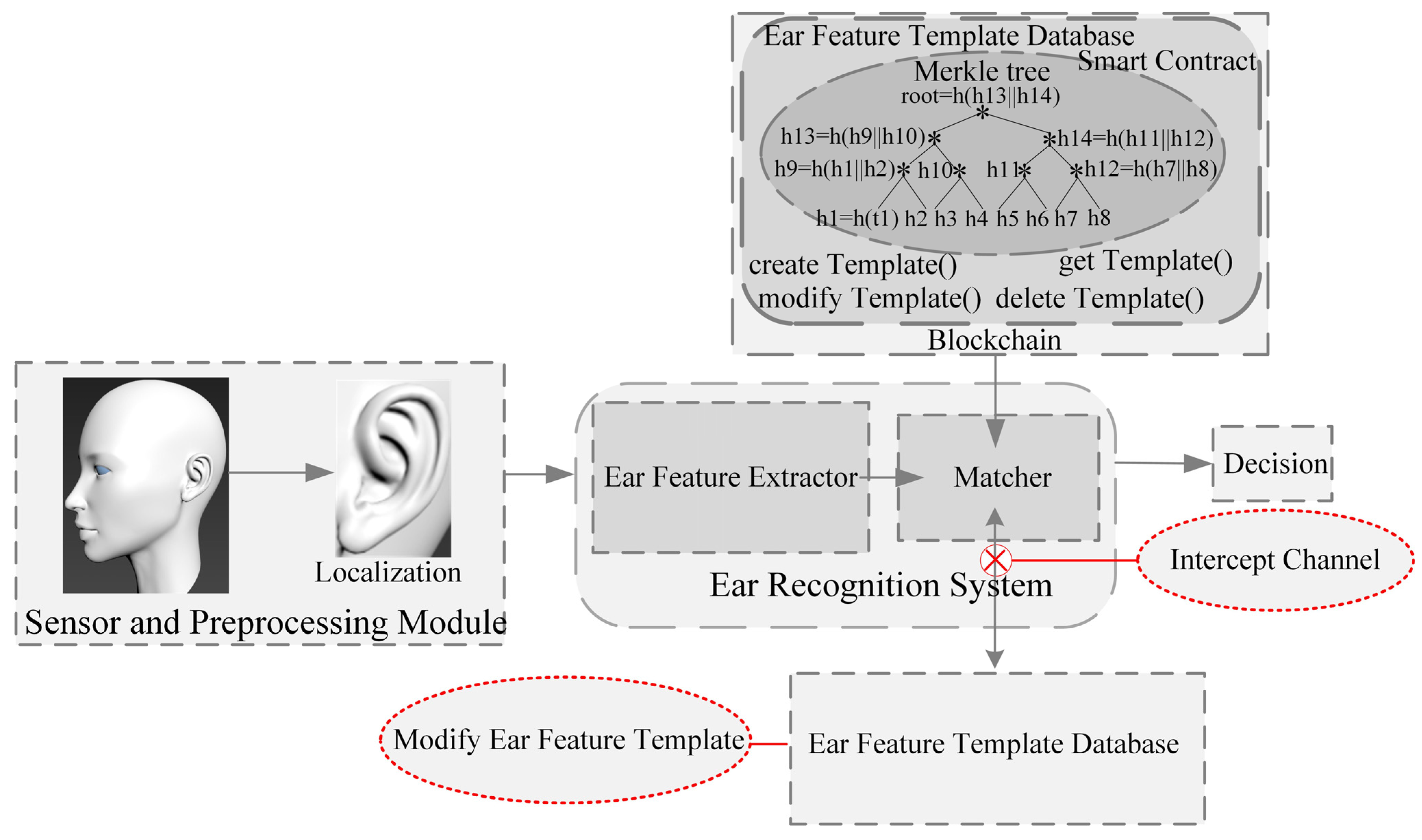
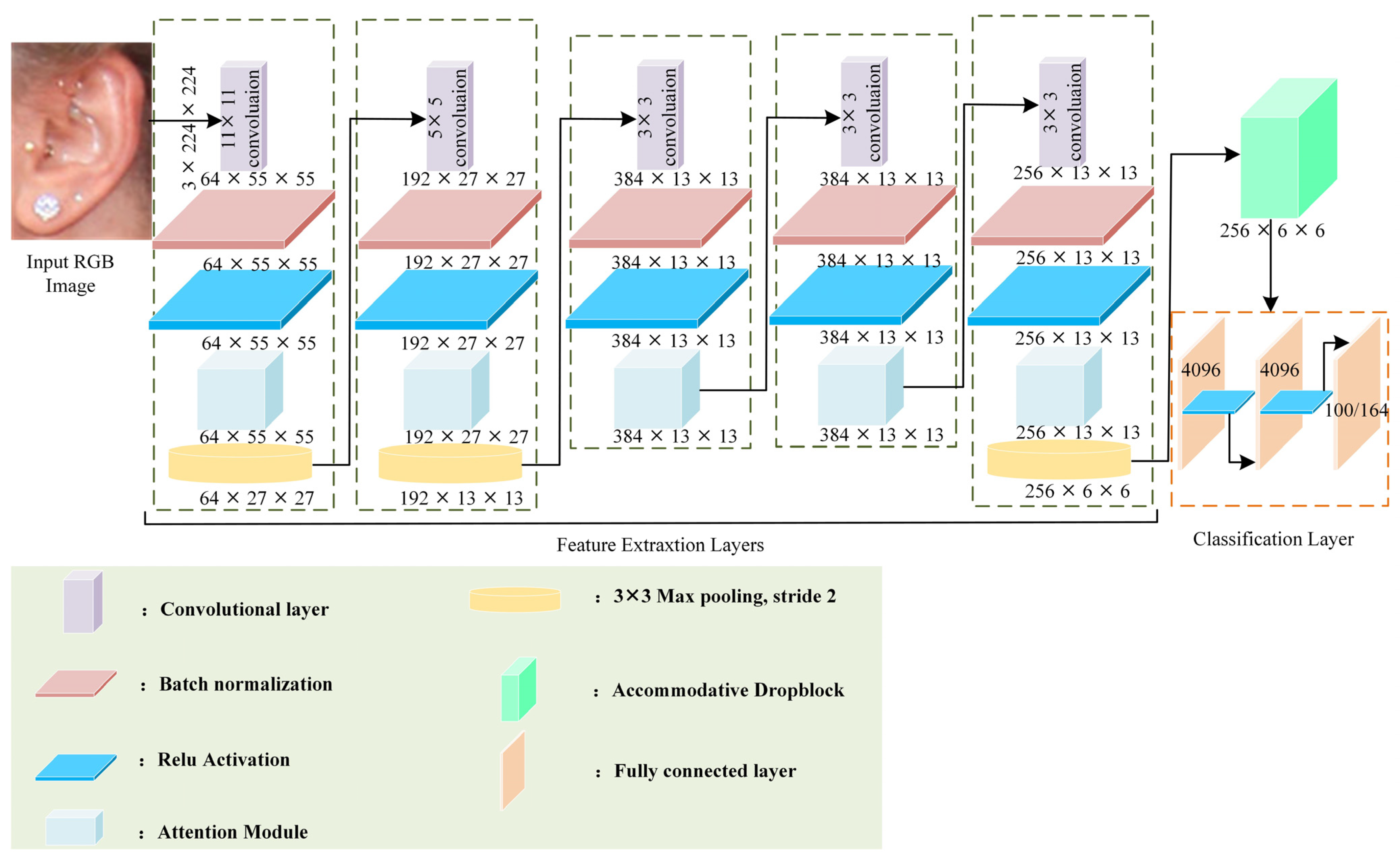
3. The Proposed Approach
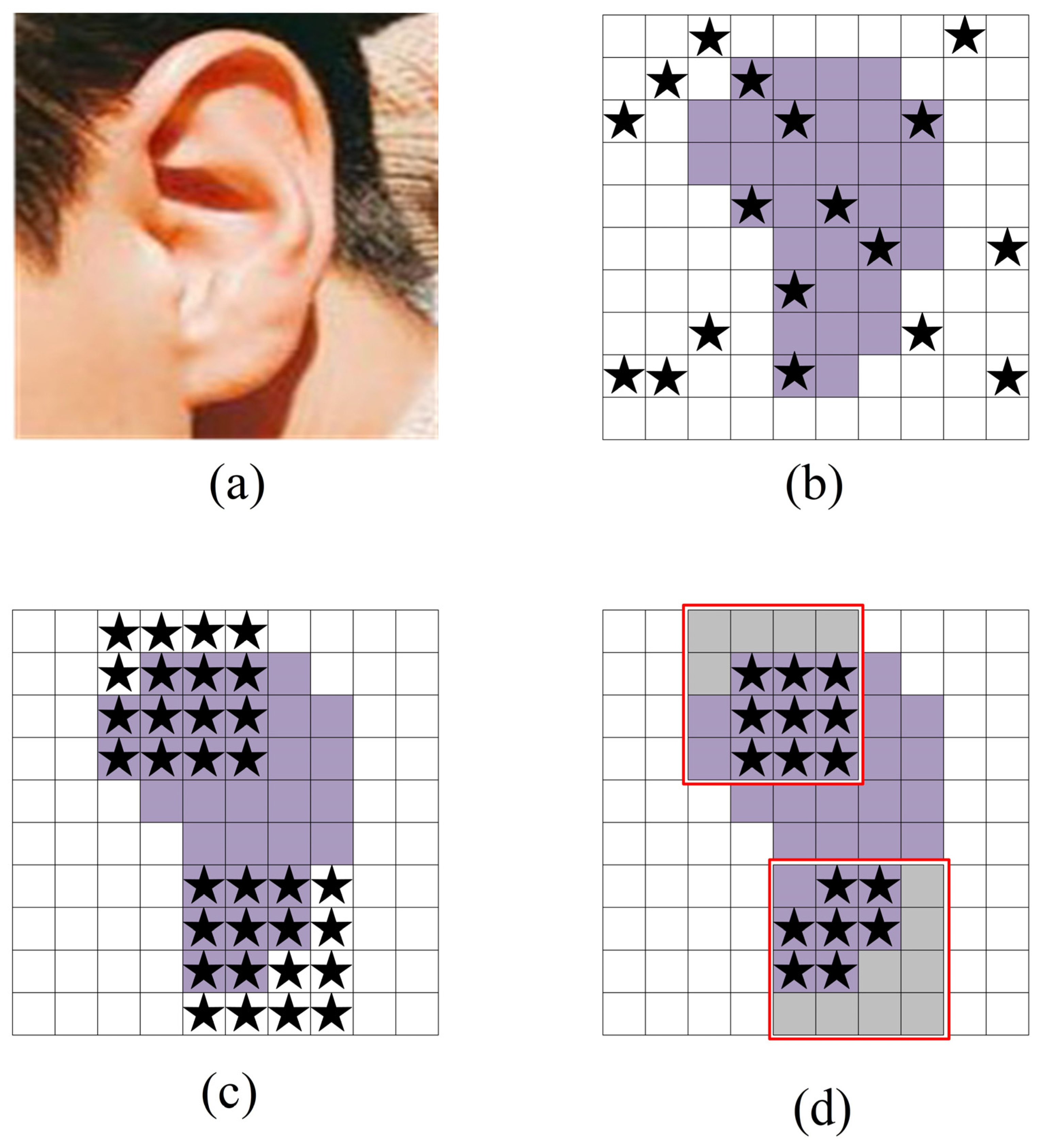
3.1. Accommodative DropBlock
| Algorithm 1: Accommodative DropBlock |
| Input: Feature map for the current layer, block_size, γ, drop_prob, z Output: The next layer of features 1: Randomly sample mask : (γ) 2: For each , we create a square block centered at and of size block_size × block_size. Set the top-zth percentile elements of each square block to zero and the rest to one. 3: The mean and Variance of feature values are: , . Z—Score Normalization: 4: Apply the mask: 5: Scaling of output features: |
3.2. Attention Module
4. Experiments and Results
4.1. Datasets and Experiment Setup
4.1.1. Dataset Introduction
4.1.2. Data Augmentation
4.1.3. Parameter Initialization and Evaluation Metrics
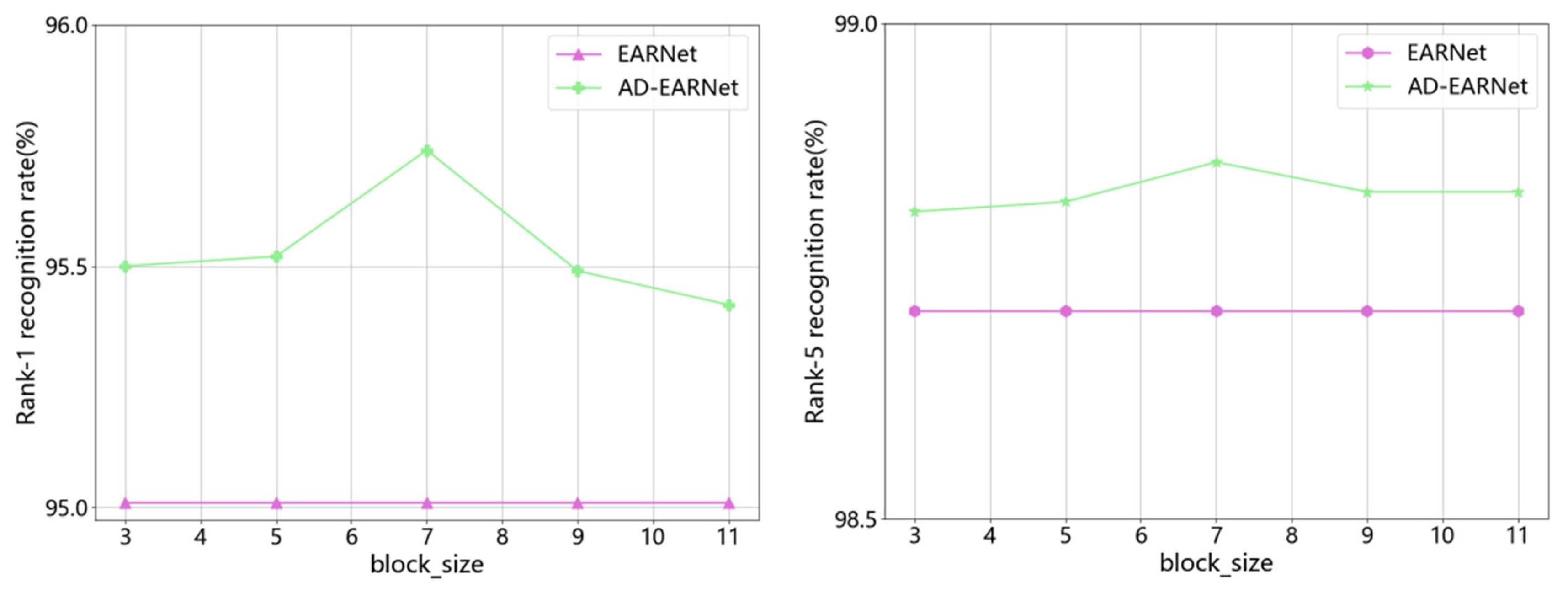
4.2. Analysis of block_size
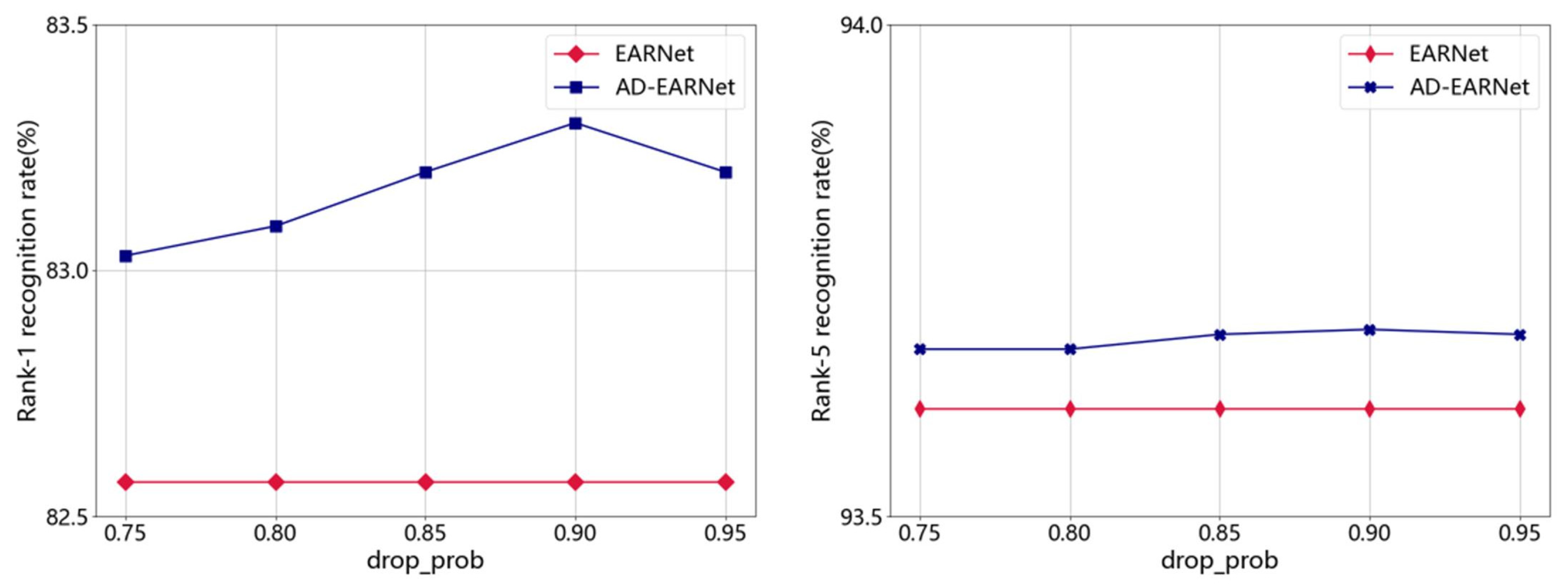
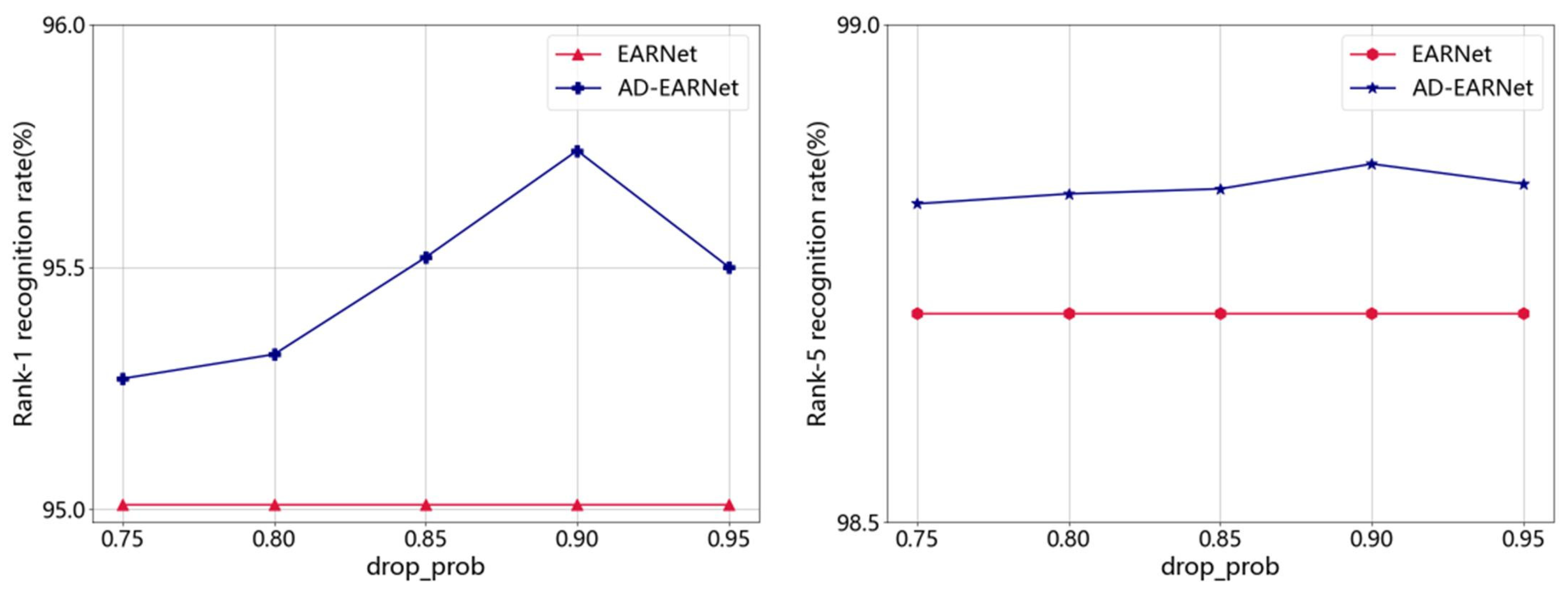
4.3. The Impact of drop_prob
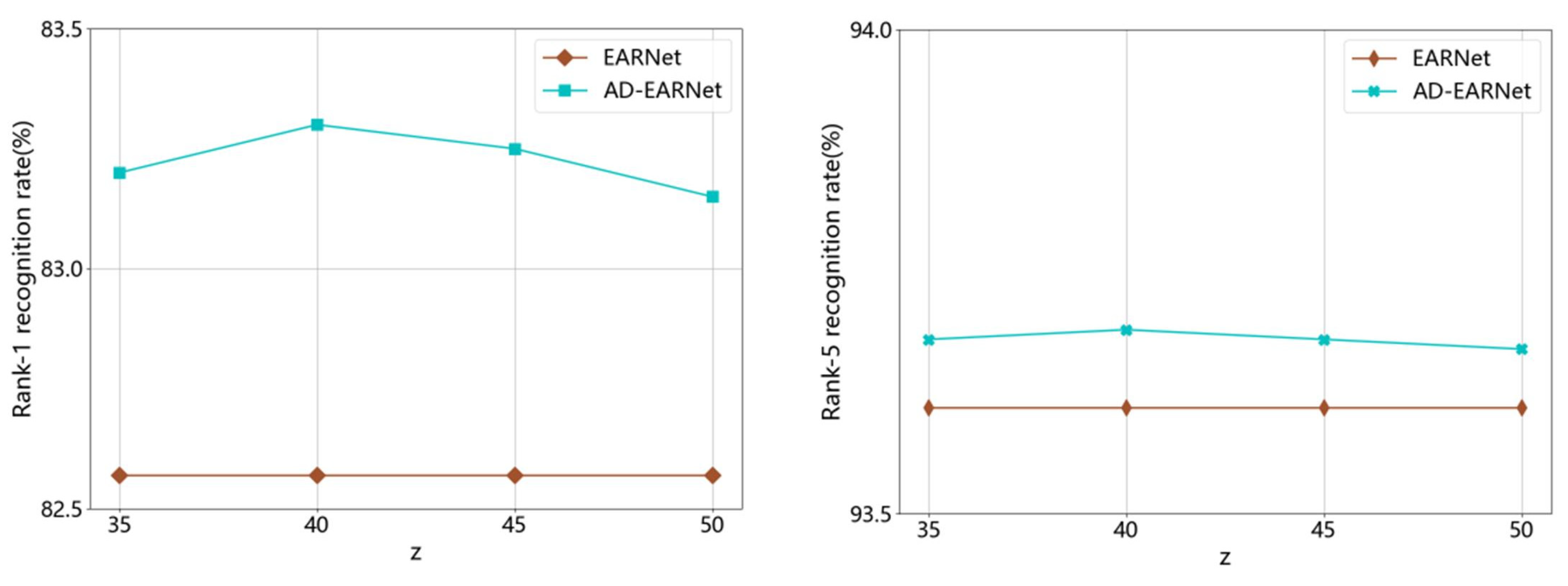
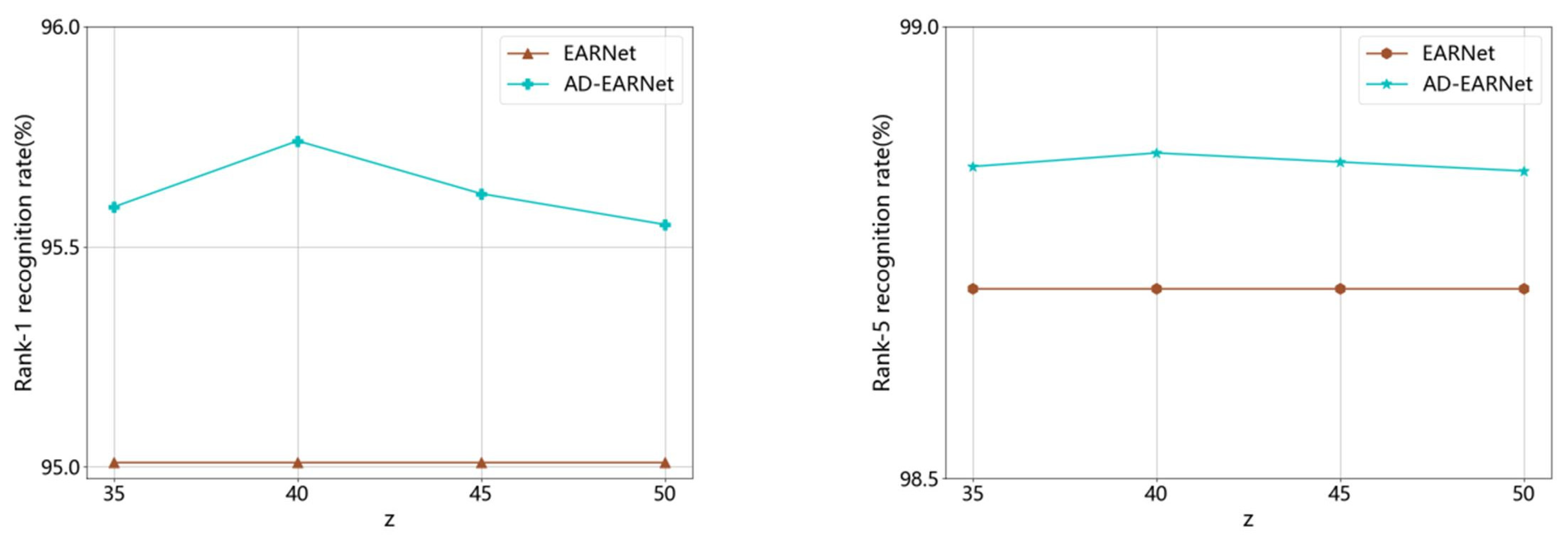
4.4. Analysis of z
4.5. Comparison with Other Commonly Used Regularization Methods
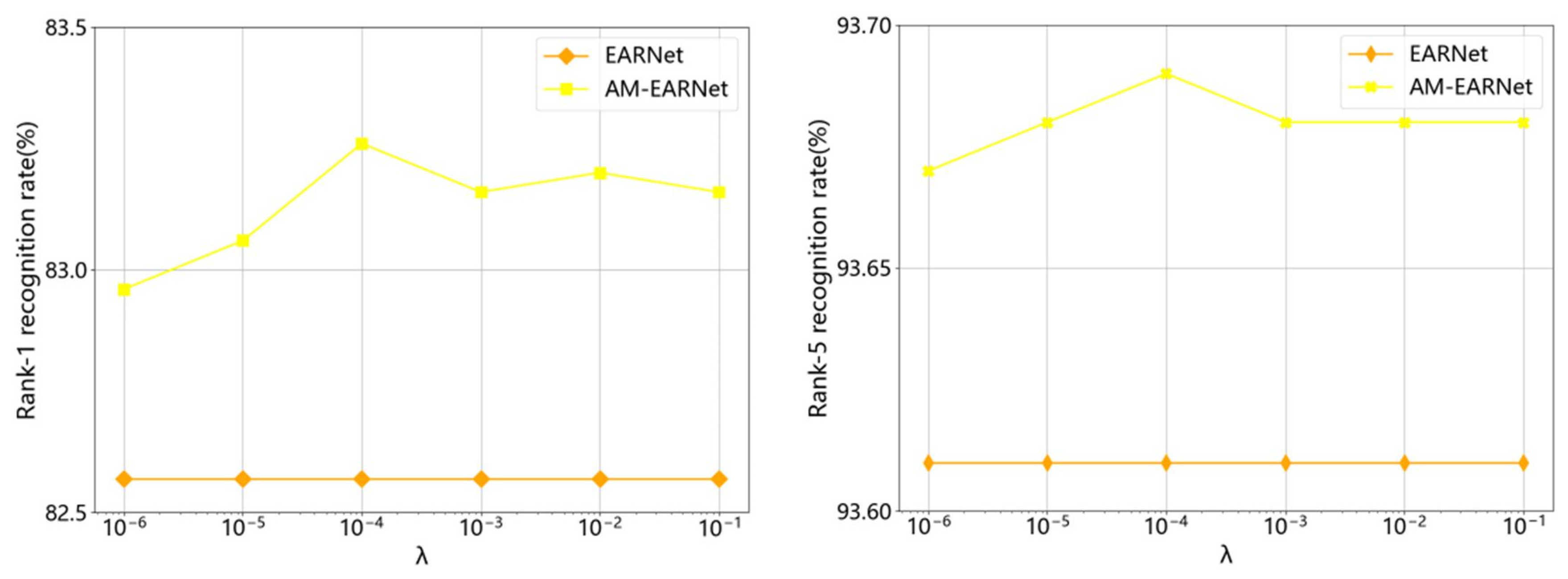
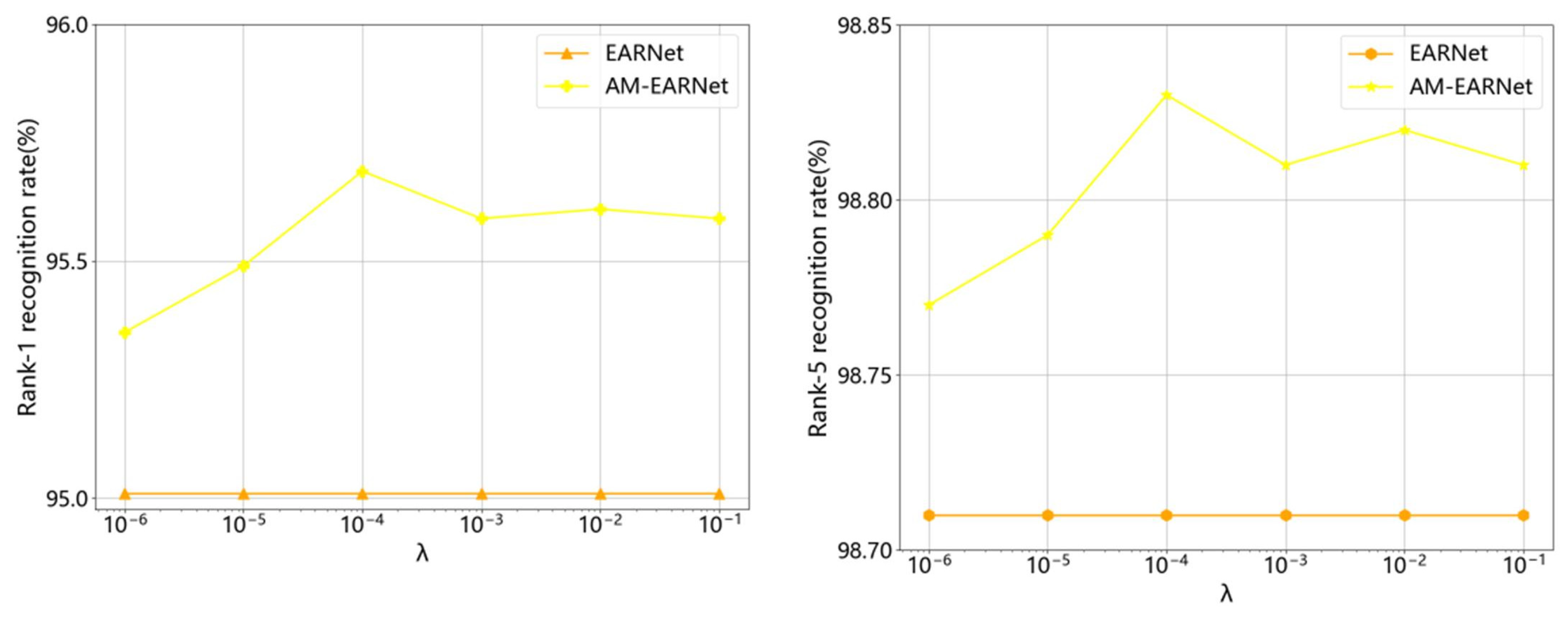
4.6. The Impact of λ
4.7. Ablation Experiment
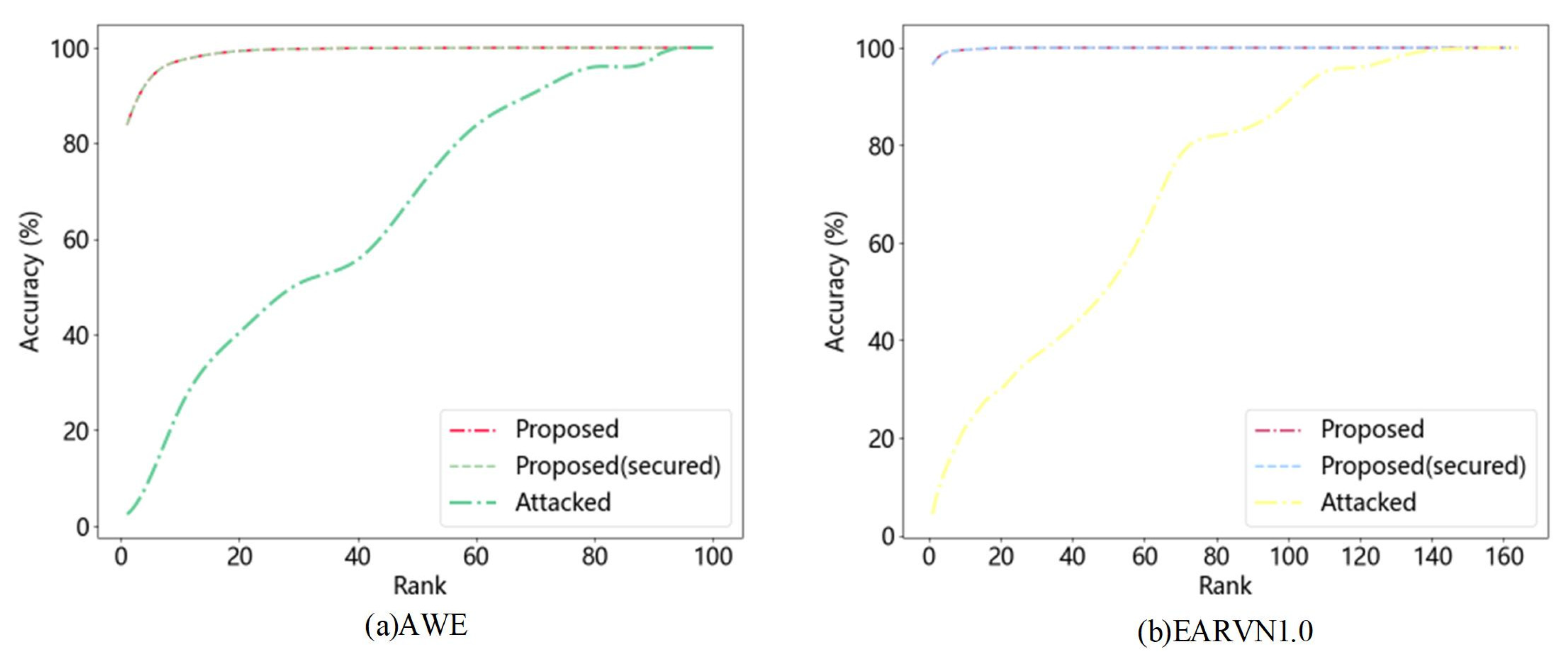
4.8. Analysis of the Role of Blockchain Protection
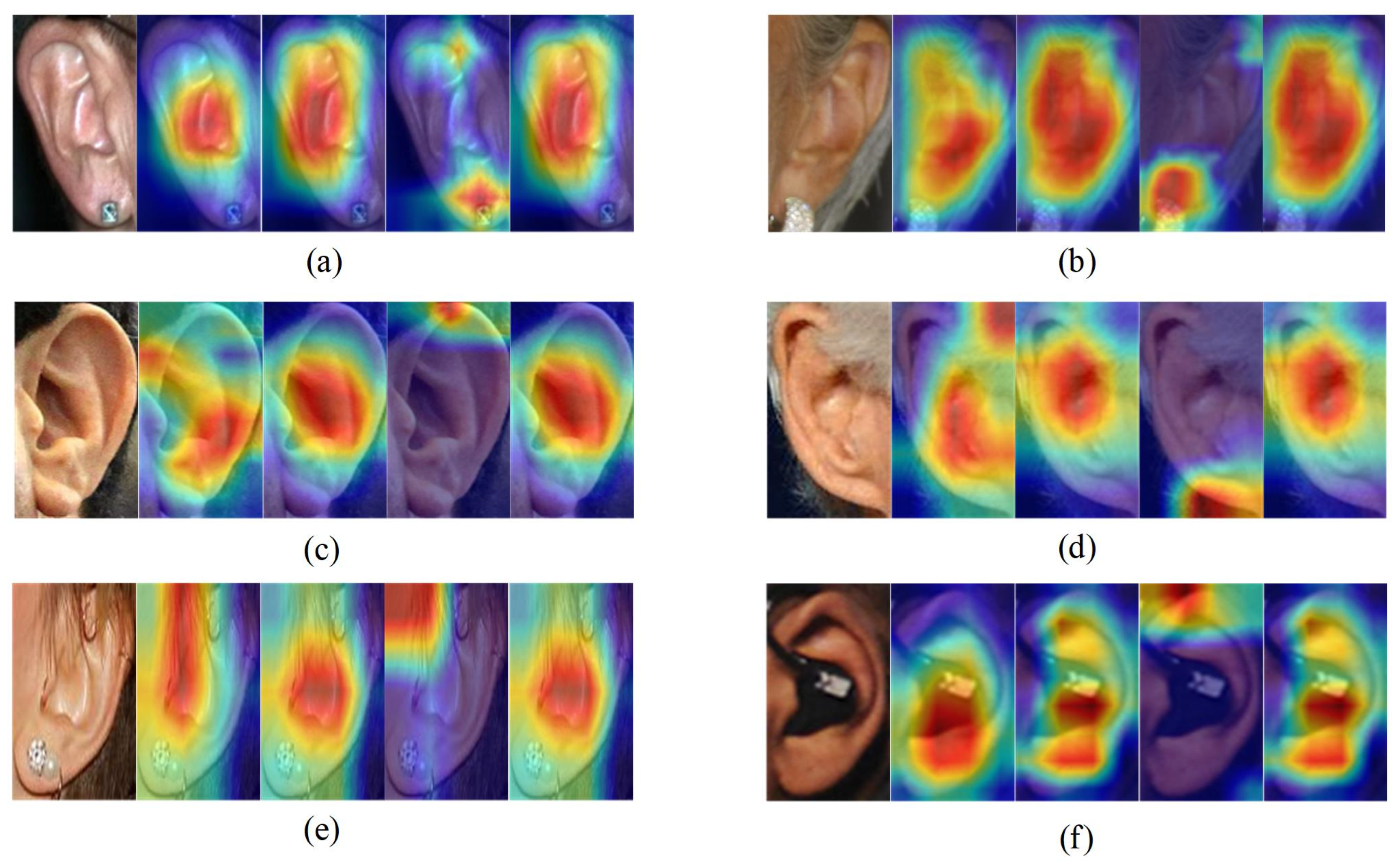
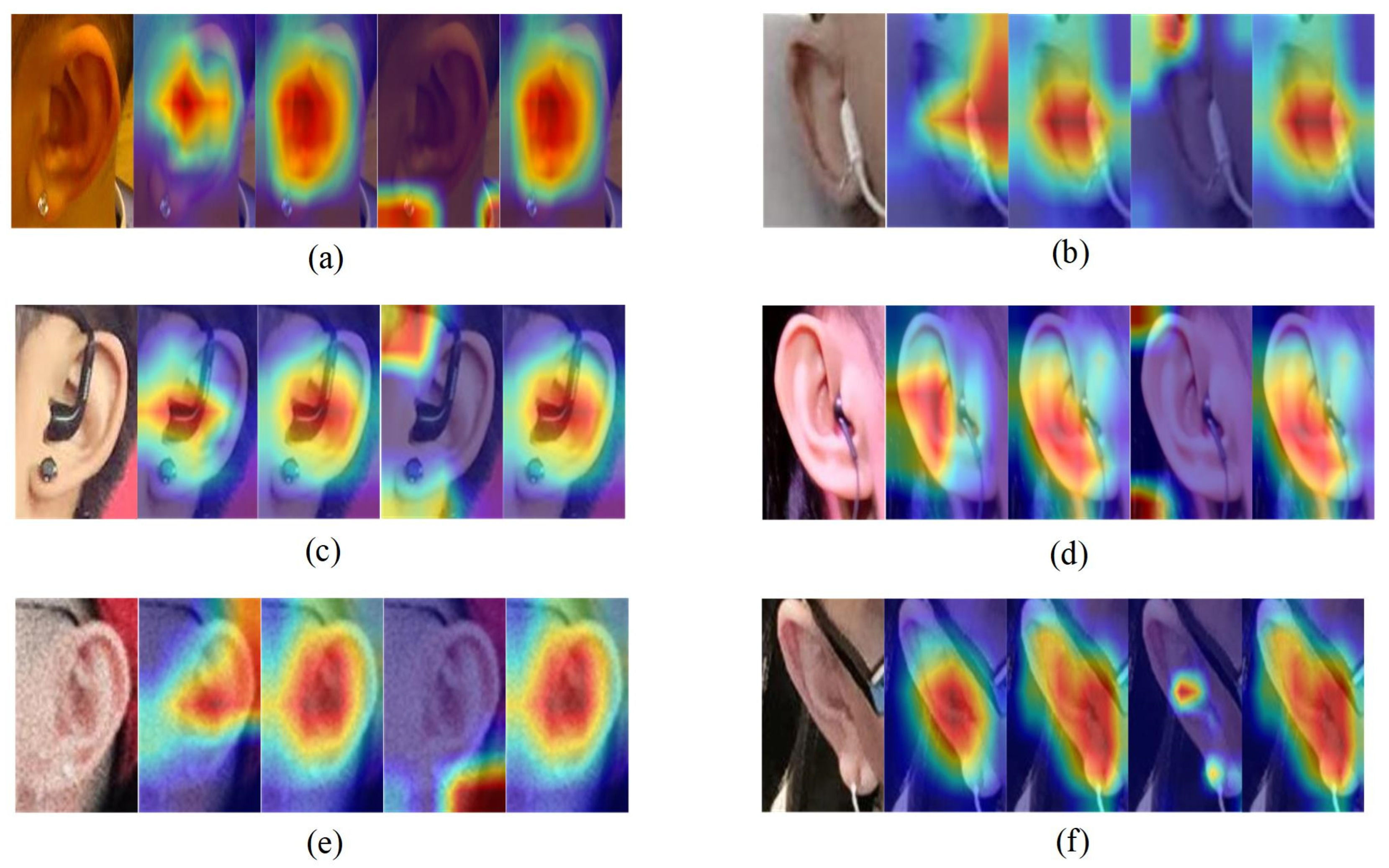
4.9. Visual Explanations
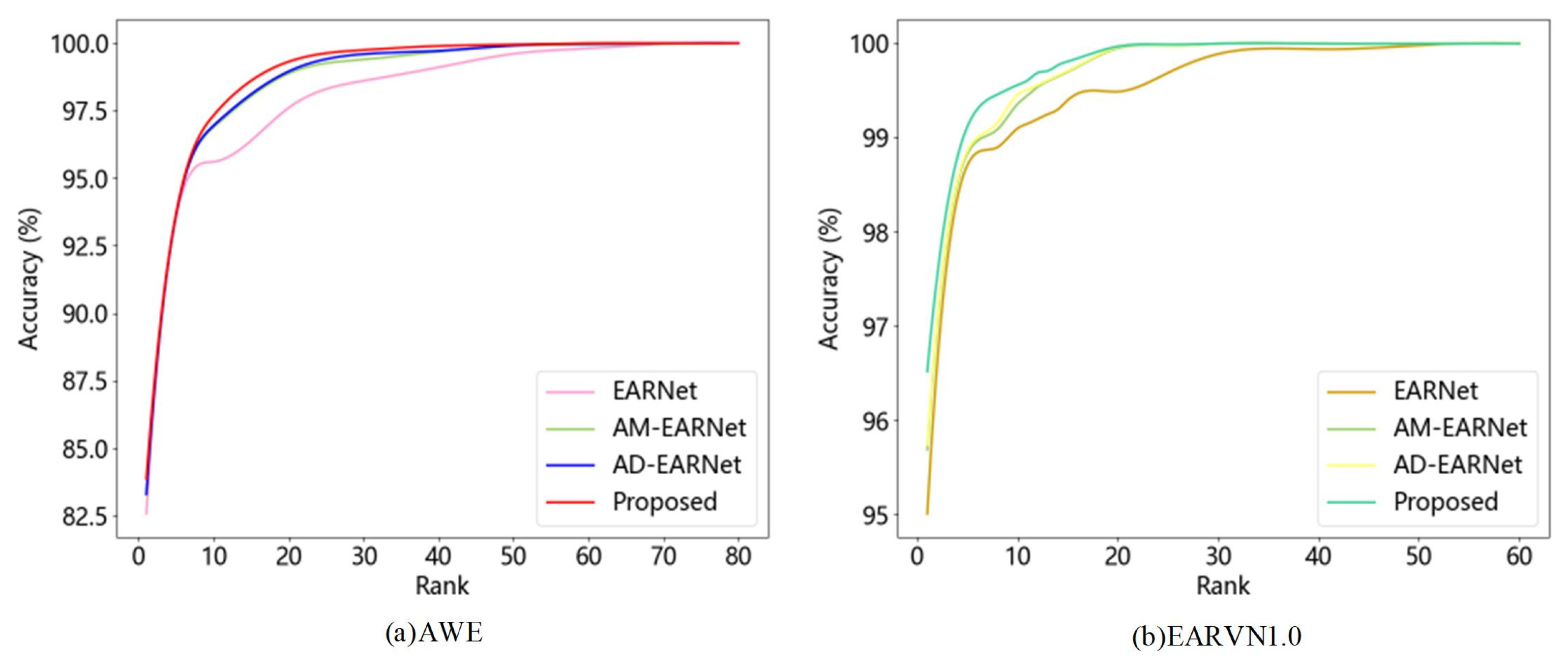
4.10. Compared with Other Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Appati, J.K.; Nartey, P.K.; Yaokumah, W.; Abdulai, J.-D. A systematic review of fingerprint recognition system development. Int. J. Softw. Sci. Comput. Intell. IJSSCI 2022, 14, 1–17. [Google Scholar] [CrossRef]
- Babu, G.; Khayum, P.A. Elephant herding with whale optimization enabled ORB features and CNN for Iris recognition. Multimed. Tools Appl. 2022, 81, 5761–5794. [Google Scholar] [CrossRef]
- Kaur, P.; Krishan, K.; Sharma, S.K.; Kanchan, T. Facial-recognition algorithms: A literature review. Med. Sci. Law 2020, 60, 131–139. [Google Scholar] [CrossRef] [PubMed]
- Manley, G.A. An evolutionary perspective on middle ears. Hear. Res. 2010, 263, 3–8. [Google Scholar] [CrossRef] [PubMed]
- Abate, A.F.; Nappi, M.; Riccio, D.; Ricciardi, S. Ear recognition by means of a rotation invariant descriptor. In Proceedings of the 18th International Conference On Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; pp. 437–440. [Google Scholar]
- Alkababji, A.M.; Mohammed, O.H. Real time ear recognition using deep learning. Telkomnika Telecommun. Comput. Electron. Control 2021, 19, 523–530. [Google Scholar] [CrossRef]
- Galbally, J.; Haraksim, R.; Beslay, L. A study of age and ageing in fingerprint biometrics. IEEE Trans. Inf. Secur. 2018, 14, 1351–1365. [Google Scholar] [CrossRef]
- Lanitis, A. A survey of the effects of aging on biometric identity verification. Int. J. Biom. 2010, 2, 34–52. [Google Scholar] [CrossRef]
- Alexander, K.S.; Stott, D.J.; Sivakumar, B.; Kang, N. A morphometric study of the human ear. J. Plast. Reconstr. Aesthetic Surg. 2011, 64, 41–47. [Google Scholar] [CrossRef]
- Krishan, K.; Kanchan, T.; Thakur, S. A study of morphological variations of the human ear for its applications in personal identification. Egypt. J. Forensic Sci. 2019, 9, 6. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, Y.; Oerlemans, A.; Lao, S.; Wu, S.; Lew, M.S. Deep learning for visual understanding: A review. Neurocomputing 2016, 187, 27–48. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Wang, J.; Gao, F.; Dong, J.; Du, Q. Adaptive dropblock-enhanced generative adversarial networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5040–5053. [Google Scholar] [CrossRef]
- Jain, A.K.; Nandakumar, K.; Ross, A. 50 years of biometric research: Accomplishments, challenges, and opportunities. Pattern Recognit. Lett. 2016, 79, 80–105. [Google Scholar] [CrossRef]
- Goel, A.; Agarwal, A.; Vatsa, M.; Singh, R.; Ratha, N. Securing CNN model and biometric template using blockchain. In Proceedings of the 2019 IEEE 10th International Conference on Biometrics Theory, Applications and Systems (BTAS), Tampa, FL, USA, 23–26 September 2019; pp. 1–7. [Google Scholar]
- Delgado-Mohatar, O.; Fierrez, J.; Tolosana, R.; Vera-Rodriguez, R. Blockchain meets biometrics: Concepts, application to template protection, and trends. arXiv 2020. [Google Scholar] [CrossRef]
- Zhang, W.; Yuan, Y.; Hu, Y.; Nandakumar, K.; Chopra, A.; Sim, S.; De Caro, A. Blockchain-Based Distributed Compliance in Multinational Corporations’ Cross-Border Intercompany Transactions: A New Model for Distributed Compliance Across Subsidiaries in Different Jurisdictions. In Proceedings of the Advances in Information and Communication Networks: Proceedings of the 2018 Future of Information and Communication Conference (FICC), San Francisco, CA, USA, 14–15 March 2019; Volume 2, pp. 304–320. [Google Scholar]
- Ghiasi, G.; Lin, T.-Y.; Le, Q.V. Dropblock: A regularization method for convolutional networks. Adv. Neural Inf. Process. Syst. 2018, 31, 1–11. [Google Scholar]
- Yang, L.; Zhang, R.-Y.; Li, L.; Xie, X. Simam: A simple, parameter-free attention module for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Online, 8–24 July 2021; pp. 11863–11874. [Google Scholar]
- Merkle, R.C. A digital signature based on a conventional encryption function. In Proceedings of the Conference on the Theory and Application Of Cryptographic Techniques, Santa Barbara, CA, USA, 16–20 August 1987; pp. 369–378. [Google Scholar]
- Moreno, B.; Sanchez, A.; Vélez, J.F. On the use of outer ear images for personal identification in security applications. In Proceedings of the IEEE 33rd Annual 1999 International Carnahan Conference on Security Technology (Cat. No. 99ch36303), Madrid, Spain, 5–7 October 1999; pp. 469–476. [Google Scholar]
- Choras, M.; Choras, R.S. Geometrical algorithms of ear contour shape representation and feature extraction. In Proceedings of the Sixth international Conference on Intelligent Systems Design and Applications, Jian, China, 16–18 October 2006; pp. 451–456. [Google Scholar]
- Choraś, M. Perspective methods of human identification: Ear biometrics. Opto-Electron. Rev. 2008, 16, 85–96. [Google Scholar] [CrossRef]
- Dong, J.; Mu, Z. Multi-pose ear recognition based on force field transformation. In Proceedings of the 2008 Second International Symposium on Intelligent Information Technology Application, Shanghai, China, 20–22 December 2008; pp. 771–775. [Google Scholar]
- Chang, K.; Bowyer, K.W.; Sarkar, S.; Victor, B. Comparison and combination of ear and face images in appearance-based biometrics. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1160–1165. [Google Scholar] [CrossRef]
- Alaraj, M.; Hou, J.; Fukami, T. A neural network based human identification framework using ear images. In Proceedings of the TENCON 2010-2010 IEEE Region 10 Conference, Fukuoka, Japan, 21–24 November 2010; pp. 1595–1600. [Google Scholar]
- Xie, Z.; Mu, Z. Ear recognition using LLE and IDLLE algorithm. In Proceedings of the 2008 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar]
- Yuan, L.; Mu, Z.-C.; Zhang, Y.; Liu, K. Ear recognition using improved non-negative matrix factorization. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; pp. 501–504. [Google Scholar]
- Dewi, K.; Yahagi, T. Ear photo recognition using scale invariant keypoints. In Proceedings of the Computational Intelligence, San Francisco, CA, USA, 20–22 November 2006; pp. 253–258. [Google Scholar]
- Kumar, A.; Wu, C. Automated human identification using ear imaging. Pattern Recognit. 2012, 45, 956–968. [Google Scholar] [CrossRef]
- Nosrati, M.S.; Faez, K.; Faradji, F. Using 2D wavelet and principal component analysis for personal identification based on 2D ear structure. In Proceedings of the 2007 International Conference on Intelligent and Advanced Systems, Kuala Lumpur, Malaysia, 25–28 November 2007; pp. 616–620. [Google Scholar]
- Benzaoui, A.; Kheider, A.; Boukrouche, A. Ear description and recognition using ELBP and wavelets. In Proceedings of the 2015 International Conference on Applied Research In Computer Science And Engineering (Icar), Beiriut, Lebanon, 8–9 October 2015; pp. 1–6. [Google Scholar]
- Jacob, L.; Raju, G. Ear recognition using texture features-a novel approach. In Proceedings of the Advances in Signal Processing and Intelligent Recognition Systems, Trivandrum, India, 13–15 March 2014; pp. 1–12. [Google Scholar]
- Ahila Priyadharshini, R.; Arivazhagan, S.; Arun, M. A deep learning approach for person identification using ear biometrics. Appl. Intell. 2021, 51, 2161–2172. [Google Scholar] [CrossRef]
- Štepec, D.; Emeršič, Ž.; Peer, P.; Štruc, V. Constellation-based deep ear recognition. In Deep Biometrics; Springer: Berlin/Heidelberg, Germany, 2020; pp. 161–190. [Google Scholar]
- Radhika, K.; Devika, K.; Aswathi, T.; Sreevidya, P.; Sowmya, V.; Soman, K. Performance analysis of NASNet on unconstrained ear recognition. In Nature Inspired Computing for Data Science; Springer: Berlin/Heidelberg, Germany, 2020; pp. 57–82. [Google Scholar]
- Ganapathi, I.I.; Ali, S.S.; Prakash, S.; Vu, N.-S.; Werghi, N. A survey of 3d ear recognition techniques. ACM Comput. Surv. 2023, 55, 1–36. [Google Scholar] [CrossRef]
- Benzaoui, A.; Khaldi, Y.; Bouaouina, R.; Amrouni, N.; Alshazly, H.; Ouahabi, A. A comprehensive survey on ear recognition: Databases, approaches, comparative analysis, and open challenges. Neurocomputing 2023, 537, 236–270. [Google Scholar] [CrossRef]
- Hadid, A.; Evans, N.; Marcel, S.; Fierrez, J. Biometrics systems under spoofing attack: An evaluation methodology and lessons learned. IEEE Signal Process. Mag. 2015, 32, 20–30. [Google Scholar] [CrossRef]
- Nourmohammadi-Khiarak, J.; Pacut, A. An ear anti-spoofing database with various attacks. In Proceedings of the 2018 International Carnahan Conference on Security Technology (ICCST), Montreal, QC, Canada, 22–25 October 2018; pp. 1–5. [Google Scholar]
- Toprak, I.; Toygar, Ö. Ear anti-spoofing against print attacks using three-level fusion of image quality measures. Signal Image Video Process. 2020, 14, 417–424. [Google Scholar] [CrossRef]
- Sepas-Moghaddam, A.; Pereira, F.; Correia, P.L. Ear presentation attack detection: Benchmarking study with first lenslet light field database. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 2355–2359. [Google Scholar]
- Emeršič, Ž.; Meden, B.; Peer, P.; Štruc, V. Evaluation and analysis of ear recognition models: Performance, complexity and resource requirements. Neural Comput. Appl. 2020, 32, 15785–15800. [Google Scholar] [CrossRef]
- Emeršič, Ž.; Štruc, V.; Peer, P. Ear recognition: More than a survey. Neurocomputing 2017, 255, 26–39. [Google Scholar] [CrossRef]
- Emeršič, Ž.; Gabriel, L.L.; Štruc, V.; Peer, P. Convolutional encoder–decoder networks for pixel-wise ear detection and segmentation. IET Biom. 2018, 7, 175–184. [Google Scholar] [CrossRef]
- Hoang, V.T. EarVN1. 0: A new large-scale ear images dataset in the wild. Data Brief 2019, 27, 104630. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Hassaballah, M.; Alshazly, H.A.; Ali, A.A. Ear recognition using local binary patterns: A comparative experimental study. Expert Syst. Appl. 2019, 118, 182–200. [Google Scholar] [CrossRef]
- Dodge, S.; Mounsef, J.; Karam, L. Unconstrained ear recognition using deep neural networks. IET Biom. 2018, 7, 207–214. [Google Scholar] [CrossRef]
- Zhang, Y.; Mu, Z.; Yuan, L.; Yu, C. Ear verification under uncontrolled conditions with convolutional neural networks. IET Biom. 2018, 7, 185–198. [Google Scholar] [CrossRef]
- Emeršič, Ž.; Štepec, D.; Štruc, V.; Peer, P. Training convolutional neural networks with limited training data for ear recognition in the wild. arXiv 2017. [Google Scholar] [CrossRef]
- Khaldi, Y.; Benzaoui, A. A new framework for grayscale ear images recognition using generative adversarial networks under unconstrained conditions. Evol. Syst. 2021, 12, 923–934. [Google Scholar] [CrossRef]
- Hassaballah, M.; Alshazly, H.A.; Ali, A.A. Robust local oriented patterns for ear recognition. Multimed. Tools Appl. 2020, 79, 31183–31204. [Google Scholar] [CrossRef]
- Khaldi, Y.; Benzaoui, A. Region of interest synthesis using image-to-image translation for ear recognition. In Proceedings of the 2020 International Conference on Advanced Aspects of Software Engineering (ICAASE), Constantine, Algeria, 28–30 November 2020; pp. 1–6. [Google Scholar]
- Khaldi, Y.; Benzaoui, A.; Ouahabi, A.; Jacques, S.; Taleb-Ahmed, A. Ear recognition based on deep unsupervised active learning. IEEE Sens. J. 2021, 21, 20704–20713. [Google Scholar] [CrossRef]
- Alshazly, H.; Linse, C.; Barth, E.; Idris, S.A.; Martinetz, T. Towards explainable ear recognition systems using deep residual networks. IEEE Access 2021, 9, 122254–122273. [Google Scholar] [CrossRef]
- Omara, I.; Hagag, A.; Ma, G.; Abd El-Samie, F.E.; Song, E. A novel approach for ear recognition: Learning Mahalanobis distance features from deep CNNs. Mach. Vis. Appl. 2021, 32, 38. [Google Scholar] [CrossRef]
- Kacar, U.; Kirci, M. ScoreNet: Deep cascade score level fusion for unconstrained ear recognition. IET Biom. 2019, 8, 109–120. [Google Scholar] [CrossRef]
- Chowdhury, D.P.; Bakshi, S.; Pero, C.; Olague, G.; Sa, P.K. Privacy preserving ear recognition system using transfer learning in industry 4.0. IEEE Trans. Ind. Inform. 2022, 19, 6408–6417. [Google Scholar] [CrossRef]
- Hansley, E.E.; Segundo, M.P.; Sarkar, S. Employing fusion of learned and handcrafted features for unconstrained ear recognition. IET Biom. 2018, 7, 215–223. [Google Scholar] [CrossRef]
- Aiadi, O.; Khaldi, B.; Saadeddine, C. MDFNet: An unsupervised lightweight network for ear print recognition. J. Ambient. Intell. Humaniz. Comput. 2022, 14, 13773–13786. [Google Scholar] [CrossRef] [PubMed]
- Xu, X.; Liu, Y.; Cao, S.; Lu, L. An efficient and lightweight method for human ear recognition based on MobileNet. Wirel. Commun. Mob. Comput. 2022, 2022, 9069007. [Google Scholar] [CrossRef]
- Ramos-Cooper, S.; Gomez-Nieto, E.; Camara-Chavez, G. VGGFace-Ear: An extended dataset for unconstrained ear recognition. Sensors 2022, 22, 1752. [Google Scholar] [CrossRef] [PubMed]
- Alshazly, H.; Linse, C.; Barth, E.; Martinetz, T. Deep convolutional neural networks for unconstrained ear recognition. IEEE Access 2020, 8, 170295–170310. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | AWE | EARVN1.0 | ||
|---|---|---|---|---|
| R1 (%) | R5 (%) | R1 (%) | R5 (%) | |
| EARNet | 82.57 | 93.61 | 95.01 | 98.71 |
| DB-EARNet | 82.87 | 93.63 | 95.40 | 98.78 |
| AD-EARNet | 83.30 | 93.69 | 95.74 | 98.86 |
| Model | AWE | EARVN1.0 | ||
|---|---|---|---|---|
| R1 (%) | R5 (%) | R1 (%) | R5 (%) | |
| EARNet | 82.57 | 93.61 | 95.01 | 98.71 |
| AM-EARNet | 83.26 | 93.69 | 95.69 | 98.83 |
| AD-EARNet | 83.30 | 93.69 | 95.74 | 98.86 |
| Proposed | 83.87 | 93.74 | 96.52 | 99.12 |
| Dataset | Rank-1 Recognition Rate (%) | |||
|---|---|---|---|---|
| Before Template Tampering | After Template Tampering | |||
| Proposed | Proposed (Secured) | Proposed | Proposed (Secured) | |
| AWE | 83.87 | 83.87 | 2.46 | 83.87 |
| EARVN1.0 | 96.52 | 96.52 | 4.37 | 96.52 |
| Dataset | Method | R1 (%) | R5 (%) |
|---|---|---|---|
| AWE | Hassaballah et al. [49] | 49.60 | - |
| Emersic et al. [44] | 49.60 | - | |
| Dodge et al. [50] | 56.35 | 74.80 | |
| Dodge et al. [50] | 68.50 | 83.00 | |
| Dodge et al. [50] | 80.03 | 93.48 | |
| Zhang et al. [51] | 50.00 | 70.00 | |
| Emersic et al. [52] | 62.00 | 80.35 | |
| Khaldi et al. [53] | 50.53 | 76.35 | |
| Hassaballah et al. [54] | 54.10 | - | |
| Khaldi et al. [55] | 48.48 | - | |
| Khaldi et al. [56] | 51.25 | - | |
| Alshazly et al. [57] | 67.25 | 84.00 | |
| Omara et al. [58] | 78.13 | - | |
| Kacar et al. [59] | 47.80 | 72.10 | |
| Chowdhury et al. [60] | 50.50 | 70.00 | |
| Hansley et al. [61] | 75.60 | 90.60 | |
| Aiadi et al. [62] | 82.50 | - | |
| Xue bin et al. [63] | 83.52 | 93.71 | |
| Proposed (secured) | 83.87 | 93.74 | |
| EARVN1.0 | Ramos-Cooper et al. [64] | 92.58 | 97.88 |
| Alshazly et al. [65] | 93.45 | 98.42 | |
| Xue bin et al. [63] | 96.10 | 99.28 | |
| Proposed (secured) | 96.52 | 99.12 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, X.; Liu, Y.; Liu, C.; Lu, L. Anti-Software Attack Ear Identification System Using Deep Feature Learning and Blockchain Protection. Symmetry 2024, 16, 85. https://doi.org/10.3390/sym16010085
Xu X, Liu Y, Liu C, Lu L. Anti-Software Attack Ear Identification System Using Deep Feature Learning and Blockchain Protection. Symmetry. 2024; 16(1):85. https://doi.org/10.3390/sym16010085
Chicago/Turabian StyleXu, Xuebin, Yibiao Liu, Chenguang Liu, and Longbin Lu. 2024. "Anti-Software Attack Ear Identification System Using Deep Feature Learning and Blockchain Protection" Symmetry 16, no. 1: 85. https://doi.org/10.3390/sym16010085
APA StyleXu, X., Liu, Y., Liu, C., & Lu, L. (2024). Anti-Software Attack Ear Identification System Using Deep Feature Learning and Blockchain Protection. Symmetry, 16(1), 85. https://doi.org/10.3390/sym16010085