


Lightweight Computational Complexity Stepping Up the NTRU Post-Quantum Algorithm Using Parallel Computing

 and
and 
Abstract
:1. Introduction
2. Literature Review
2.1. Post-Quantum Cryptographic (PQC) Schemes
- Hash-based cryptography
- Code-based cryptography
- Multivariate cryptography
- Lattice-based cryptography
- Isogeny-based cryptography
2.2. NTRU Lattice-Based Public Encryption Algorithm
2.2.1. Key Generation
2.2.2. Encryption
2.2.3. Decryption
2.2.4. NTRU Security Analysis
2.3. Comparison between NTRU, RSA, and ECC
2.4. Parallel Computing in Cryptography
- Parallelizing Encryption and Decryption Protocols: Parallel computing has been utilized to accelerate the encryption and decryption processes in various cryptographic algorithms. In [48], Aldahdooh presents a parallel implementation and analysis of several encryption algorithms (such as Advanced Encryption Standard (AES), Blowfish, Twofish, Data Encryption Standard (DES), Triple DES, and Serpent). Parallel processing is employed to enhance efficiency, and the experiments demonstrate significant improvement compared to sequential implementations. The algorithms are evaluated based on encryption time and speedup.
- Parallelizing Quantum Key Distribution (QKD): QKD is a fundamental application of quantum cryptography. Wu et al., in their work [49], propose a parallel simulation with an optimized scheme for QKD networks, specifically addressing network partitioning.
- Parallelizing Lattice-based Cryptography: Wan et al., in their work [50], presented an NTT box based on the NVIDIA AI accelerator, Tensor Core. After that, they presented a high-performance implementation of CRYSTALS-Kyber with the suggested NTT box and achieved considerable performance improvement. This work illustrated the tremendous potential of Tensor Core in LBC acceleration.
3. The Proposed Parallel Post-Quantum NTRU Encrypt Algorithm (PPQNTRUEncrypt)
3.1. Parallel NTRUEncrypt Model
Assumptions
- The Structure of the Parallel Machine:
- Operation description: Polynomial multiplication:
3.2. Parallelizing the NTRU Encryption and Decryption Models
3.2.1. Level One: Coarse-Grained Level of Parallelization (N ≥ M)
3.2.2. Level Two: Medium-Grained Level of Parallelism (N < M)
| Algorithm 1. Internal mechanism of the PPQNTRUEncrypt and Parallel processing of two polynomial multiplications |
| Assume that: There are “M” processing elements (PEs) {PE0, PE1, …, PEi, …, PEM-1}
|
For loop (1 to N) For loop (1 to M) Each PE assigned a task if N/M ≠ integer For loop (1 to ()) Each PE assigned tasks For loop (() to N) Each PE assigned tasks if N < M Load balancing must be taken into account
These steps repeated for each Polynomial Multiplication operation |
4. Methods and Experiments
- Parallel/execution time “Tpar”: The total time to complete executing the whole problem when using the parallel system, as shown in Equation (12).
- Speedup “SP”: The unit measuring the ability of the parallel system to speed up problem-solving compared with the serial/sequential one (Sp = TS/Tpar).
- Efficiency “EP”: The average participation of each PE (E = Sp/M)
- The improvement in the execution time, which is achieved through using “M” PEs, is given by the ratio. ratio =
4.1. Parallel Computing Using the Analytical Model
4.2. Parallel Computing Using Apache Spark Framework
- Usability: Spark supports programming in any language, including Python, Java, Scala, and R.
- Advanced analytics are possible, including data streaming and more difficult analytics like machine learning and graph algorithms.
- Real-time stream processing takes advantage of the micro batching [63] method, in which data streams are processed as a collection of extremely small batches, which the Spark batch engine then treats as a regular task.
4.2.1. Programming Model and Core Techniques of Spark
- Easy to use: Spark offers more than 80 high-level, simple operators (such as map, reduce, reduceByKey, and filter) that simplify the design of parallel computing frameworks without requiring users to consider the underlying complex parallel computing problems like data partitioning, task scheduling, and other issues. Additionally, by providing comparable APIs, Spark enables users to create user-defined functions in a variety of computer languages, including Java, Scala, and Python.
- Quicker than other frameworks like MapReduce: Spark has proven to be quicker than MapReduce in batch processing thanks to its in-memory computing.
- Support for computation: Spark is an integrated system that offers batch, interactive, iterative, and streaming processing options. Additionally, it offers a stack of high-level APIs and a sophisticated DAG execution engine for complex DAG applications. Additionally, it provides specialized tools for a variety of applications, such as Shark, Spark SQL, MLlib, and Graphx.
- Flexible running assistance. When running on YARN or Mesos, Spark can operate independently or share the cluster with other computing systems like MapReduce. Additionally, it offers APIs, for consumers to set up and use cloud computing (e.g., Amazon EC2). Additionally, it may allow access to a variety of data sources, such as HDFS, Tachyon, HBase, Cassandra, and Amazon S3.
4.2.2. Model Validation
4.3. Discussion of Results
| Algorithm 2. Two polynomial multiplications |
| Input: NTRU parameters (Polynomial1, Polynomial2)
poly2RDD = sc.parallelize([(exp, coeff) for coeff, exp in enumerate(polynomial2)])
.reduceByKey(lambda x, y: x + y) \ .sortByKey()
Output: Multiplication |
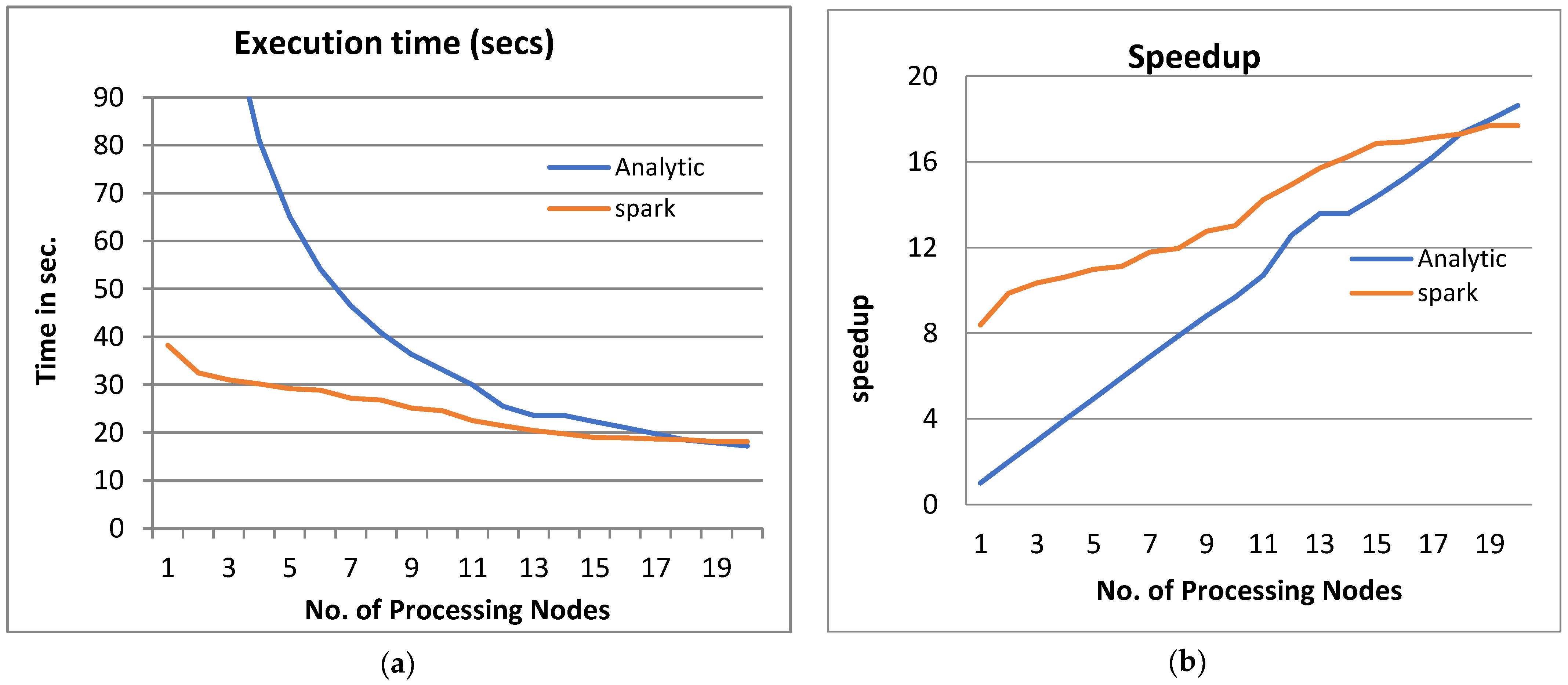
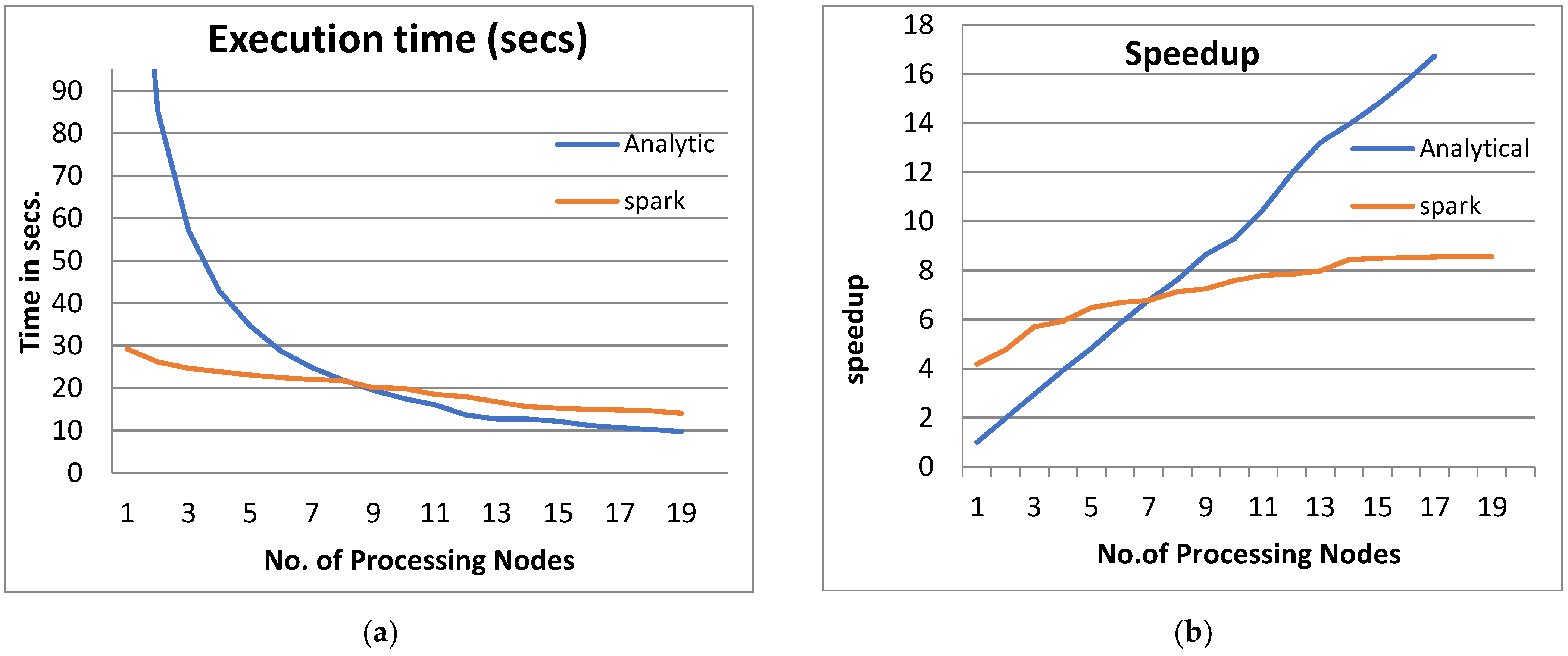
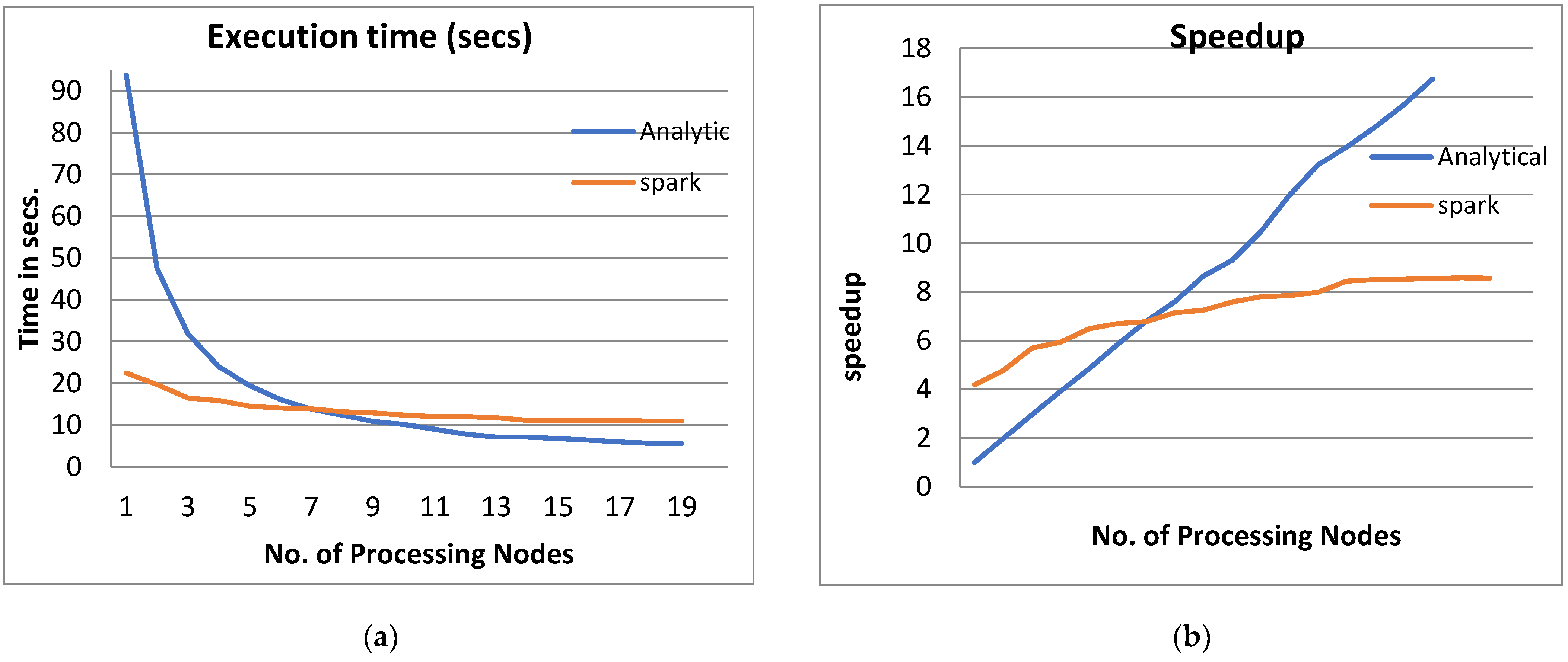
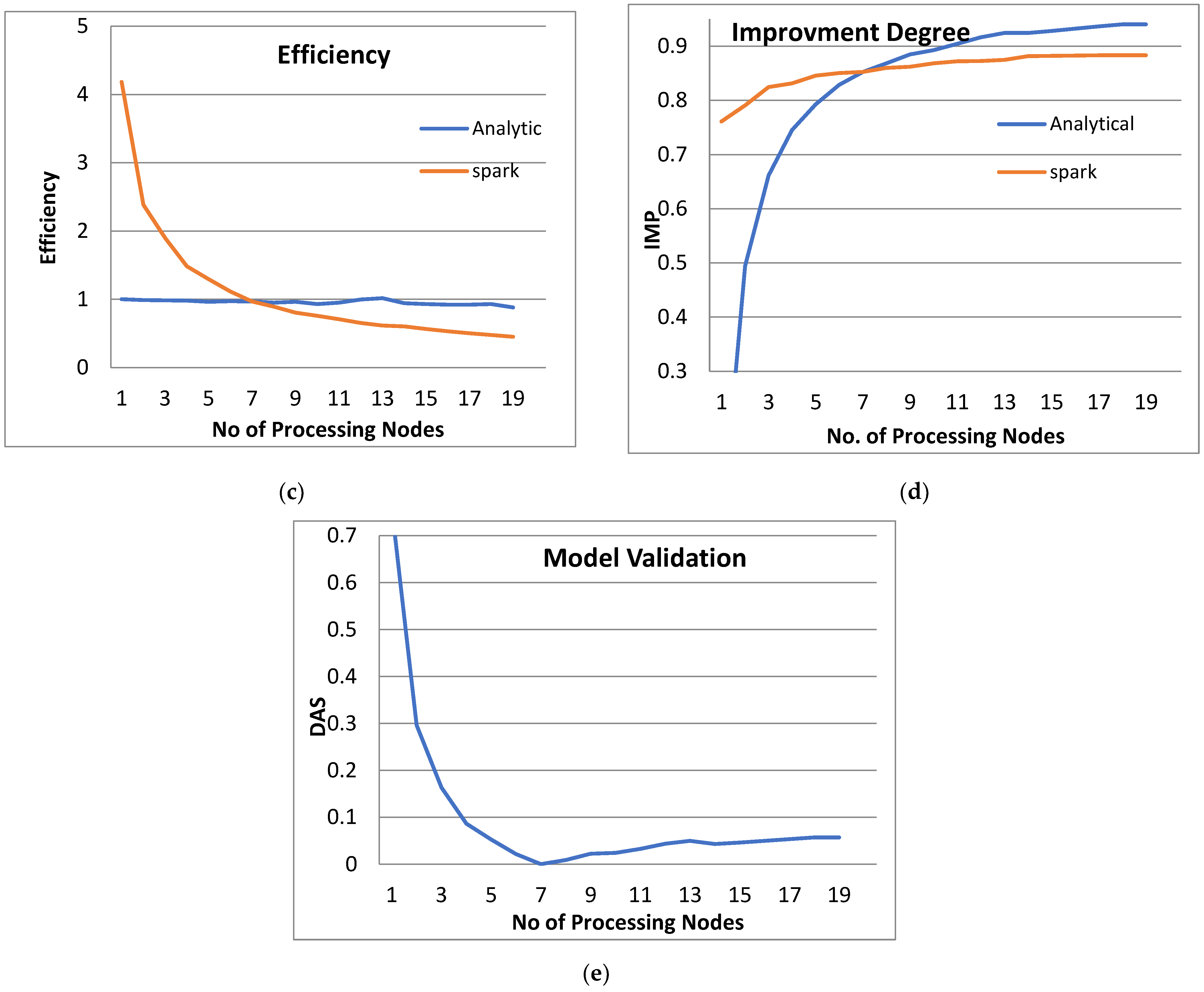
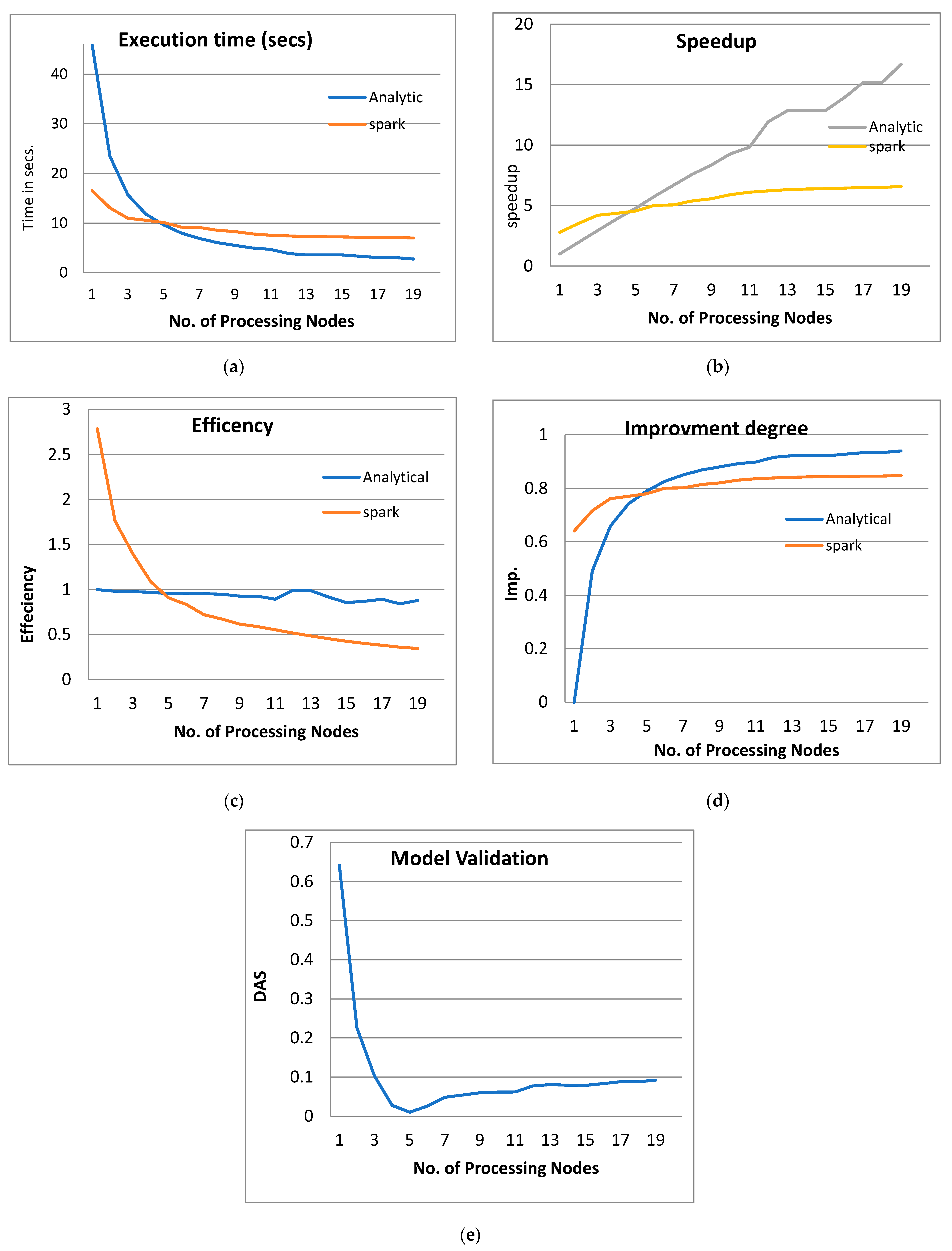
- From Figure 3a, Figure 4a, Figure 5a and Figure 6a, it is noted that when the number of PEs increases, the total parallel/execution time decreases regardless of the parameter set. This is clear when using both analytical and Spark implementation. That achieves the scalability characteristics of the PPQNTRUEncrypt algorithm.
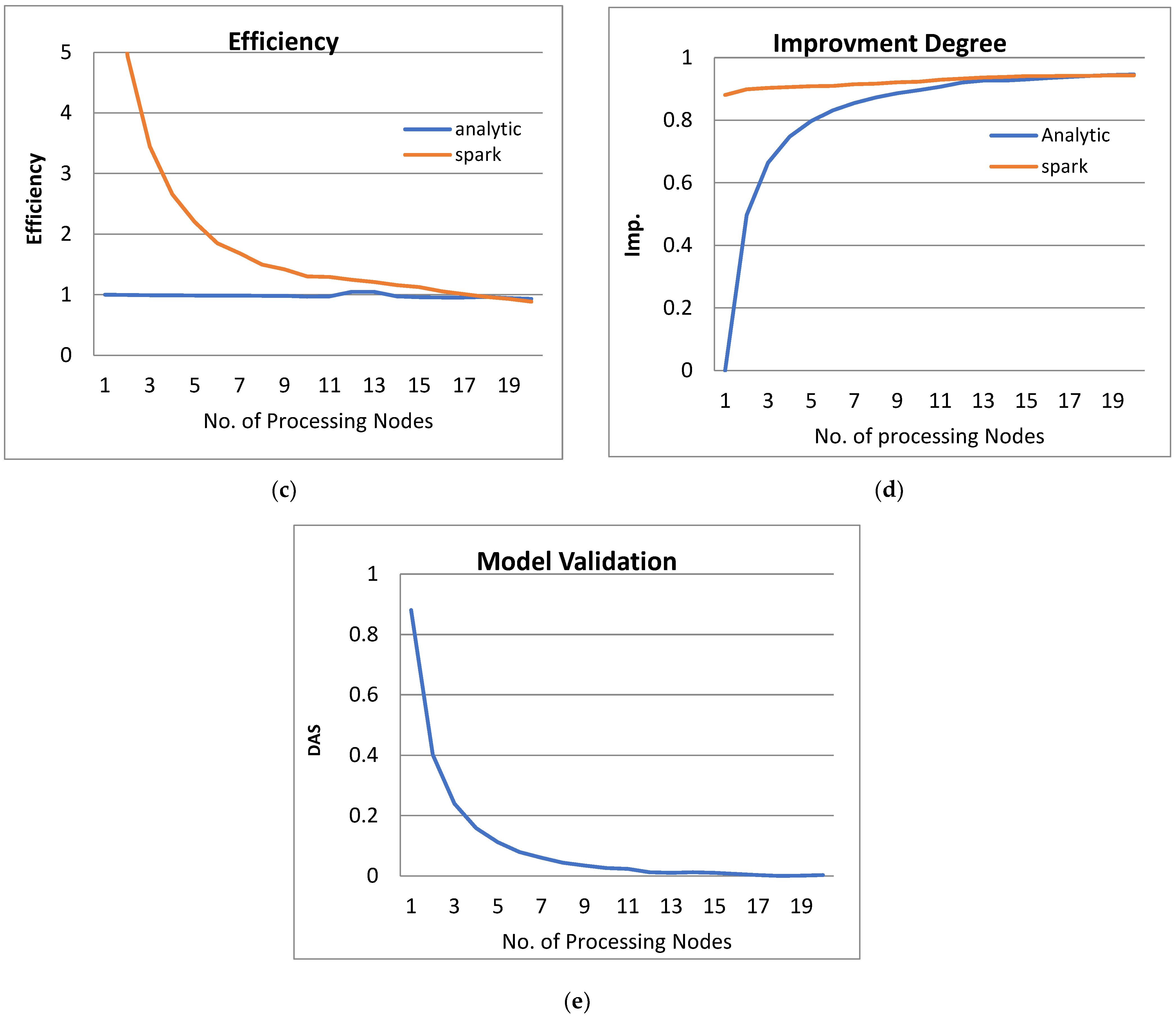
- Figures Figure 3b, Figure 4b, Figure 5b and Figure 6b show that the speedup increases when the number of PEs increases for both analytical and Spark implementation. Moreover, the system efficiency decreases unrelated to the parameter set, as shown in Figure 3c, Figure 4c, Figure 5c and Figure 6c. These figures show that efficiency is affected by the escalation of the PEs number. That is to say, when the number of PEs increases, the system efficiency decreases, which leads to unstable system efficiency. To solve this problem, the load must be reallocated between different PEs. This ascends the need to split each polynomial multiplication operation into parts (sub-tasks). Therefore, more than one PE works together to execute one polynomial multiplication operation. In this case, the overhead time due to inter-processor communication increases (because of the need to exchange large amounts of data). Therefore, the total parallel/execution time increases. For that reason, it is not preferable to resort to a load-balancing solution except in the case of a large value of “N”.
- In order to validate the Apache Spark model, a comparison between the performance of the system using the analytical model and its performance using Apache Spark is performed. This compassion is shown in Figure 3e, Figure 4e, Figure 5e and Figure 6e. The results indicated that the difference in the percentage of system performance improvement when using the analytical model and Apache Spark (Difference between analytical and Spark (DAS)) was very small and did not exceed 2%. (it ranges from 2% to 0.2%). It is observed that this difference decreases when the number of PEs (M) increases. Furthermore, this percentage decreases as the number of tasks (N) increases.
- Experimental results demonstrate that achieving significant system performance improvement requires a maximum of twenty processing elements (PEs). Beyond this threshold, the performance gains become economically and hardware-wise insignificant. In other words, the rate of improvement becomes economically and hardware-wise insignificant. Therefore, to ensure practicality, the proposed model suggests limiting the number of PEs to twenty, making it suitable for deployment in small devices like smartphones. Consequently, the authors establish a boundary on the number of PEs, specifically when applying the proposed model to compact devices such as smartphones.
- Adding extra nodes to a Spark cluster can initially enhance performance by increasing parallelism. However, there is a saturation point where the returns start diminishing. Once the number of worker nodes exceeds a certain threshold (specifically, twenty worker nodes), adding extra nodes may not yield significant performance improvements. In fact, it could introduce coordination overhead among the nodes.
- In summary, the findings affirm the effectiveness of employing distributed processing through big data analytics platforms for cryptographic techniques. Specifically, the PPQNTRUEncrypt model in this study utilizes the Apache Spark platform. This is particularly relevant due to the increasing number of connected nodes and the simultaneous encryption and decryption tasks. It can be inferred that the volume of required computational workload, such as polynomial multiplication commonly found in the cryptographic techniques (specifically NTRUEncrypt in this study), significantly increases, potentially involving hundreds of concurrent instances. Furthermore, the ability of the algorithm to operate in real-time becomes essential to accommodate the expanding number of nodes in the environment.
4.4. Limitations
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
- Figure 1: Directed Acyclic Graph (DAG) of the polynomial multiplication operation.
- Figure 2: Spark framework architecture.
- -
- Master Node: The master node is the central coordinator of the Spark application. It is responsible for dividing the application into tasks and distributing them to the different slave nodes for execution. The master node also tracks the progress of tasks and collects the results from each slave node. The master node generally runs on a dedicated machine.
- -
- Slave Nodes: The slave nodes are worker machines that execute the tasks assigned by the master node. Each slave node typically runs multiple executor processes that perform the actual computations. These executor processes are responsible for processing the data in parallel and communicating with the master node.
- Figure 3: The Performance of the PPQNTRUEncrypt for p = 3, q = 256 and N = 503.
- Figure 4: The Performance of the PPQNTRUEncrypt for p = 3, q = 128 and N = 347.
- Figure 5: The Performance of the PPQNTRUEncrypt for p = 3, q = 128 and N = 251.
- Figure 6: The Performance of the PPQNTRUEncrypt for p = 3, q = 128 and N = 167.
References
- Balamurugan, C.; Singh, K.; Ganesan, G.; Rajarajan, M. Code-based Post-Quantum Cryptography. Preprints 2021, 2021040734. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, K.; Wang, J.; Cheng, J.; Yang, Y.; Tang, S.; Yan, D.; Tang, Y.; Liu, Z.; Yu, Y.; et al. Experimental Authentication of Quantum Key Distribution with Post-Quantum Cryptography. Npj Quantum Inf. 2021, 7, 67. [Google Scholar] [CrossRef]
- Nielsen, M.; Chuang, I. Quantum Computation and Quantum Information. Phys. Today 2002, 54, 60. [Google Scholar] [CrossRef]
- Shor, P. Algorithms for Quantum Computation: Discrete Logarithms and Factoring. In Proceedings of the 35th Annual Symposium on Foundations of Computer Science, Santa Fe, NM, USA, 20–22 November 1994; IEEE Computer Society: Washington, DC, USA, 1994; pp. 124–134. [Google Scholar]
- Grover, L. A Fast Quantum Mechanical Algorithm for Database Search. In Proceedings of the 28th Annual ACM Symposium on Theory of Computing, Philadelphia, PA, USA, 22–24 May 1996; pp. 212–219. [Google Scholar]
- Buchmann, J.; Lauter, K.; Mosca, M. Postquantum Cryptography-State of the Art. IEEE Secur. Priv. 2017, 15, 12–13. [Google Scholar] [CrossRef]
- Umana, V. Post Quantum Cryptography. Ph.D. Thesis, Technical University of Denmark, Kongens Lyngby, Denmark, 2011. [Google Scholar]
- Wikipedia. Post-Quantum Cryptography. Available online: https://en.wikipedia.org/w/index.php?title=Post-quantumcryptography&oldid=999863701 (accessed on 12 December 2023).
- McEliece, R. A Public-Key Cryptosystem Based on Algebraic. Coding Thv 1978, 4244, 114–116. [Google Scholar]
- Merkle, R. Secrecy, Authentication, and Public Key Systems; Computer Science Series; UMI Research Press: Ann Arbor, MI, USA, 1982. [Google Scholar]
- Patarin, J. Hidden Fields Equations (HFE) and Isomorphisms of Polynomials (IP): Two New Families of Asymmetric Algorithms. In Proceedings of the International Conference on the Theory and Applications of Cryptographic Techniques, Saragossa, Spain, 12–16 May 1996; pp. 33–48. [Google Scholar]
- Hoffstein, J.; Pipher, J.; Silverman, J. NTRU: A ring-based public key cryptosystem. In International Algorithmic Number Theory Symposium; Springer: Berlin/Heidelberg, Germany, 1998; pp. 267–288. [Google Scholar]
- Regev, O. On Lattices, Learning with Errors, Random Linear Codes, and Cryptography. J. ACM (JACM) 2009, 56, 34. [Google Scholar] [CrossRef]
- Jao, D.; Feo, L. Towards Quantum-Resistant Cryptosystems from Supersingular Elliptic Curve Isogenies. PQCrypto 2011, 7071, 19–34. [Google Scholar]
- Kamal, A.; Ahmad, K.; Hassan, R.; Khalim, K. NTRU Algorithm: Nth Degree Truncated Polynomial Ring Units. In Functional Encryption, EAI/Springer Innovations in Communication and Computing; Springer: Cham, Switzerland, 2021. [Google Scholar] [CrossRef]
- El-Hassane, L.; Azize, A. Boosted Performances of NTRUencrypt Post-Quantum Cryptosystem. J. Cyber Secur. Mobil. 2021, 10, 725–744. [Google Scholar] [CrossRef]
- Mansouri, F. On the Parallelization of Integer Polynomial Multiplication. Master’s Theses, The School of Graduate and Postdoctoral Studies, The University of Western Ontario, London, ON, Canada, 2014. [Google Scholar]
- Butin, D. Hash-based signatures: State of play. IEEE Secur. Priv. 2007, 15, 37–43. [Google Scholar] [CrossRef]
- Bernstein, D.; Hülsing, A.; Kölbl, S.; Niederhagen, R.; Rijneveld, J.; Schwabe, P. The SPHINCS+ Signature Framework; Report 2019/1086; Cryptology ePrint Archive: 2019, University of California: San Diego, CA, USA.
- Joachim, R. An Overview to Code Based Cryptography. 2016. Available online: https://hkumath.hku.hk/~ghan/WAM/Joachim.pdf (accessed on 12 December 2023).
- Ding, J.; Petzoldt, A. Current state of Multivariate Cryptography. IEEE Secur. Priv. 2017, 15, 28–36. [Google Scholar] [CrossRef]
- Chen, M.; Ding, J.; Kannwischer, M.; Patarin, J.; Petzoldt, A.; Schmidt, D.; Yang, B. Rainbow Signature. Available online: https://www.pqcrainbow.org/ (accessed on 12 December 2023).
- Casanova, A.; Faueère, J.; Macario-Rat, G.; Patarin, J.; Perret, L.; Ryckeghem, J. GeMSS: A Great Multivariate Short Signature. Available online: https://www-polsys.lip6.fr/Links/NIST/GeMSS.html (accessed on 12 December 2023).
- Chi, D.; Choi, J.; Kim, J.; Kim, T. Lattice Based Cryptography for Beginners; Report 2015/938; Cryptology ePrint Archive: 2015; University of California: San Diego, CA, USA.
- Lepoint, T. Design and Implementation of Lattice-Based Cryptography. Ph.D. Thesis, Ecole Normale Euérieure de Paris—ENS, Paris, France, 2014. [Google Scholar]
- Alkim, D.; Ducas, L.; Pöppelmann, T.; Schwabe, P. Post-Quantum Key Exchange—A New Hope; Report 2015/1092; Cryptology ePrint Archive: University of California, San Diego, CA, USA, 2015. [Google Scholar]
- Ducas, L.; Durmus, A.; Lepoint, T.; Lyubashevsky, V. Lattice Signatures and Bimodal Gaussians; Report 2013/383; Cryptology ePrint Archive: University of California, San Diego, CA, USA, 2013. [Google Scholar]
- Bos, J.; Ducas, L.; Kiltz, E.; Lepoint, T.; Lyubashevsky, V.; Schanck, J.; Schwabe, P.; Seiler, G.; Stehlé, D. CRYSTALS—Kyber: A CCA-Secure Module-Lattice-Based KEM; Report 2017/634; Cryptology ePrint Archive: University of California, San Diego, Ca, USA, 2017. [Google Scholar]
- Chen, C.; Danba, O.; Hoffstein, J.; Hülsing, A.; Rijneveld, J.; Saito, T.; Schanck, J.; Schwabe, P.; Whyte, W.; Xagawa, K.; et al. NTRU: A Submission to the NIST Post-Quantum Standardization Effort. Available online: https://ntru.org/ (accessed on 12 December 2023).
- D’Anvers, J.; Karmakar, A.; Roy, S.; Vercauteren, F. Saber: Module-LWR Based Key Exchange, CPA-Secure Encryption and CCA-Secure KEM; Report 2018/230; Cryptology ePrint Archive: University of California, San Diego, CA, USA, 2018. [Google Scholar]
- Bernstein, D.; Chuengsatiansup, C.; Lange, T.; Vredendaal, C. NTRU Prime: Reducing Attack Surface at Low Cost; Report 2016/461; Cryptology ePrint Archive: University of California, San Diego, CA, USA, 2016. [Google Scholar]
- Ducas, L.; Lepoint, T.; Lyubashevsky, V.; Schwabe, P.; Seiler, G.; Stehle, D. CRYSTALS—Dilithium: Digital Signatures from Module Lattices; Report 2017/633; Cryptology ePrint Archive: University of California, San Diego, CA, USA, 2017. [Google Scholar]
- Fouque, P.; Hoffstein, J.; Kirchner, P.; Lyubashevsky, V.; Pornin, T.; Prest, T.; Ricosset, T.; Seiler, G.; Whyte, W.; Zhang, Z. Falcon: Fast-Fourier Lattice-Based Compact Signatures over NTRU. Available online: https://www.di.ens.fr/~prest/Publications/falcon.pdf (accessed on 12 December 2023).
- Supersingular Isogeny Diffie–Hellman Key Exchange (SIDH). Available online: https://en.wikipedia.org/wiki/Supersingular_isogeny_key_exchange (accessed on 12 December 2023).
- Costello, C.; Longa, P.; Naehrig, M. Efficient Algorithms for Supersingular Isogeny Diffie-Hellman. In Proceedings of the Annual International Cryptology Conference, Santa Barbara, CA, USA, 14–18 August 2016. [Google Scholar]
- Post-Quantum Cryptography|CSRC. Available online: https://csrc.nist.gov/projects/post-quantum-cryptography/post-quantum-cryptography-standardization (accessed on 12 December 2023).
- Lily Chen, Stephen Jordan, Yi-Kai Liu, Dustin Moody, Rene Peralta, Ray Perlner, and Daniel Smith-Tone, Report on Post-Quantum Cryptography; Technical Report NISTIR 8105; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2016.
- Gorjan Alagic, Jacob Alperin-Sheriff, Daniel Apon, David Cooper, Quynh Dang, John Kelsey, Yi-Kai Liu, Carl Miller, Dustin Moody, Rene Peralta, Ray Perlner, Angela Robinson, and Daniel Smith-Tone, Status Report on the Second Round of the NIST Post-Quantum Cryptography Standardization Process; Technical Report NISTIR 8309; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2020.
- Ahn, J.; Kwon, H.-Y.; Ahn, B.; Park, K.; Kim, T.; Lee, M.-K.; Kim, J.; Chung, J. Toward Quantum Secured Distributed Energy Resources: Adoption of Post-Quantum Cryptography (PQC) and Quantum Key Distribution (QKD). Energies 2022, 15, 714. [Google Scholar] [CrossRef]
- Kumar, M. Post-quantum cryptography Algorithm’s standardization and performance analysis. Array 2022, 15, 100242. [Google Scholar] [CrossRef]
- Dam, D.-T.; Tran, T.-H.; Hoang, V.-P.; Pham, C.-K.; Hoang, T.-T. A Survey of Post-Quantum Cryptography: Start of a New Race. Cryptography 2023, 7, 40. [Google Scholar] [CrossRef]
- Sabani, M.E.; Savvas, I.K.; Poulakis, D.; Garani, G.; Makris, G.C. Evaluation and Comparison of Lattice-Based Cryptosystems for a Secure Quantum Computing Era. Electronics 2023, 12, 2643. [Google Scholar] [CrossRef]
- Kumar, A.; Ottaviani, C.; Gill, S.S.; Buyya, R. Securing the future internet of things with post-quantum cryptography. Secur. Priv. 2022, 5, e200. [Google Scholar] [CrossRef]
- Septien-Hernandez, J.-A.; Arellano-Vazquez, M.; Contreras-Cruz, M.A.; Ramirez-Paredes, J.-P. A Comparative Study of Post-Quantum Cryptosystems for Internet-of-Things Applications. Sensors 2022, 22, 489. [Google Scholar] [CrossRef] [PubMed]
- Tata, P.; Narumanchi, H.; Emmadi, N. Analytical study of implementation issues of NTRU. In Proceedings of the International Conference on Advances in Computing, Communications and Informatics (ICACCI), Delhi, India, 24–27 September 2014; pp. 700–707. [Google Scholar] [CrossRef]
- Karbasi, A.; Atani, S.; Atani, R. PairTRU: Pairwise Non-commutative Extension of The NTRU Public key Cryptosystem. Int. J. Inf. Secur. Sci. 2018, 7, 11–19. [Google Scholar]
- D’Souza, R. The NTRU Cryptosystem: Implementation and Comparative Analysis; George Mason University: Fairfax, VA, USA, 2001. [Google Scholar]
- Aldahdooh, R. Parallel Implementation and Analysis of Encryption Algorithms. Master’s Thesis, Al-Azhar University-Gaza, Faculty of Engineering & Information Technology, Gaza, Gaza Strip. April 2018.
- Tallapally, S.; Manjula, B. Suitable encrypting algorithms in Parallel Processing for improved efficiency. IOP Conf. Ser. Mater. Sci. Eng. 2020, 981, 022017. [Google Scholar] [CrossRef]
- Wan, L.; Zheng, F.; Fan, G.; Wei, R.; Gao, L.; Wang, Y.; Lin, J.; Dong, J. A Novel High-Performance Implementation of CRYSTALS-Kyber with AI Accelerator. In European Symposium on Research in Computer Security, (ESORICS 2022): Computer Security—ESORICS; Springer: Cham, Switzerland, 2022; pp. 514–534. [Google Scholar]
- Kamal, A.A.; Youssef, A.M. Enhanced Implementation of the NTRUEncrypt Algorithm Using Graphics Cards. In Proceedings of the 1st International Conference on Parallel, Distributed and Grid Computing (PDGC-2010), Solan, India. 28–30 October 2010; pp. 168–174. [Google Scholar]
- Dai, W.; Schanck, J.; Sunar, B.; Whyte, W.; Zhang, Z. NTRU modular lattice signature scheme on CUDA GPUs. In Proceedings of the 2016 International Conference on High Performance Computing & Simulation (HPCS), Innsbruck, Austria, 18–22 July 2016. [Google Scholar] [CrossRef]
- Wong, X.-F.; Goi, B.-M.; Lee, W.-K.; Phan, R.C.-W. Performance Evaluation of RSA and NTRU over GPU with Maxwell and Pascal Architecture. J. Softw. Netw. 2017, 201–220. [Google Scholar] [CrossRef]
- Law, M.; Monagan, M. A parallel implementation for polynomial multiplication modulo a prime. In PASCO ‘15: Proceedings of the 2015 International Workshop on Parallel Symbolic Computation, Bath, UK, 10–12 July 2015; ACM Digital Library: New York, NY, USA, 2015; pp. 78–86. [Google Scholar] [CrossRef]
- Amit, C.; Gurvinder, S. Analysis & Integrated Modeling of the Performance Evaluation Techniques for Evaluating Parallel Systems; CSC Journals: Tulsa, OK, USA, 2008. [Google Scholar]
- Jain, R. The Art of Computer Systems Performance Analysis; Wiley: Hoboken, NJ, USA, 1991. [Google Scholar]
- Tang, S.; He, B.; Yu, C.; Li, Y.; Li, K. A Survey on Spark Ecosystem for Big Data Processing. arXiv 2018. [Google Scholar] [CrossRef]
- Hennessy, J.; Patterson, D. Computer Architecture: A Quantitative Approach; Morgan Kaufmann: Cambridge, MA, USA, 2003. [Google Scholar]
- Rasslan, M.; Elkabbany, G.; Aslan, H. New Generic Design to Expedite Asymmetric Cryptosystems using Three-level Parallelism. Int. J. Netw. Secur. (IJNS) 2018, 20, 371–380. [Google Scholar]
- Foldi, T.; von Csefalvay, C.; Perez, N. JAMPI: Efficient Matrix Multiplication in Spark Using Barrier Execution Mode. Big Data Cogn. Comput. 2020, 4, 32. [Google Scholar] [CrossRef]
- Park, T.; Seo, H.; Kim, J.; Park, H.; Kim, H. Efficient Parallel Implementation of Matrix Multiplication for Lattice-Based Cryptography on Modern ARM Processor. Secur. Commun. Netw. 2018, 2018, 7012056. [Google Scholar] [CrossRef]
- Jangla, G.; Amne, D. Development of an Intrusion Detection System based on Big Data for Detecting Unknown Attacks. Int. J. Adv. Res. Comput. Commun. Eng. 2015, 4, 229–232. [Google Scholar]
- Ellingwood, J. Hadoop, Storm, Samza, Spark, and Flink: Big Data Frameworks Compared. 2016. Available online: https://www.digitalocean.com/community/tutorials/hadoopstorm-samza-spark-and-flink-big-data-frameworks-compared (accessed on 12 December 2023).
- Deshai, N.; Sekhar, B.V.D.S.; Venkataramana, S. Mllib: Machine learning in apache spark. Int. J. Recent Technol. Eng. 2019, 8, 45–49. [Google Scholar]
- Kumar, G. Evaluation Metrics for Intrusion Detection Systems—A Study. Int. J. Comput. Sci. Mob. Appl. 2014, 2, 11–17. [Google Scholar]
- Kattemolle, J. Short introduction to Quantum Computing. 2017. Available online: https://www.kattemolle.com/KattemolleShortIntroToQC.pdf (accessed on 12 December 2023).
- Apache Software Foundation. Apache Spark Documentation. Available online: https://spark.apache.org/docs/latest/ (accessed on 12 December 2023).
- Mochurad, L.; Shchur, G. Parallelization of Cryptographic Algorithm Based on Different Parallel Computing Technologies. In Proceedings of the Symposium on Information Technologies & Applied Sciences (IT&AS’2021), Bratislava, Slovakia, 5 March 2021. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Post-Quantum Algorithm Type | Third Round Finalist | Technology | Alternate Candidates | Technology |
|---|---|---|---|---|
| Public Key Encryption/Key Encapsulation Mechanisms | Classic McEliece | Code | BIKE | Code |
| CRYSTALS KYBER | Lattice | FrodoKEM | Lattice | |
| NTRU | Lattice | HQC | Code | |
| SABER | Lattice | SIKE | Isogeny | |
| NTRU Prime | Lattice | |||
| Digital Signature Algorithms | CRYSTALS-DILITHIUM | Lattice | GeMSS | Multivariate Polynomial |
| FALCON | Lattice | PICNIC | Other | |
| RAINBOW | Multivariate Polynomial | SPHIMCS+ | RAINBOW |
| Post-Quantum Algorithm Type | Key Size | Operation Speed | Algorithms |
|---|---|---|---|
| Lattice | Medium | Fast | CRYSTALS-KYBER NTRU SABER FrodoKEM NTRU Prime |
| Code | Large | Fast | Classic McEliece BIKE HQC |
| Isogeny | Small | Slow | SIKE |
| Post-Quantum Algorithm | Key Size | CPU Usage | Operation Speed | Ciphertext Length |
|---|---|---|---|---|
| SABER | Medium | Medium | Fast | Medium |
| CRYSTALS-KYBER | Medium | Light | Fast | Small |
| NTRU | Small | High | Fast | Small |
| FrodoKEM | Large | High | Slow | Large |
| (a) NTRU Parameters | ||||
|---|---|---|---|---|
| Parameter | Description | Knowledge | ||
| p | Small Modulus to reduce coefficients | Public | ||
| q | Large Modulus to reduce coefficients | Public | ||
| N | Number. of coefficients in a polynomial | Public | ||
| f | Polynomial private key | Private | ||
| g | Used in public key generation | Private | ||
| h | Polynomial public key | Public | ||
| r | Random blinding polynomial | Private | ||
| df | Number of coefficients with value 1 in polynomial f | Public | ||
| (b) Security Levels for p, q, and N | ||||
| Security levels | ||||
| Parameters | Highest | High | Standard | Moderate |
| P | 3 | 3 | 3 | 3 |
| q | 256 | 128 | 128 | 128 |
| N | 503 | 347 | 251 | 167 |
| Security Levels (Bits) | RSA | ECC | NTRU-N |
|---|---|---|---|
| 80 | RSA-1024 | ECC 160-223 | NTRU-251 |
| 112 | RSA-2048 | ECC 224-255 | NTRU-347 |
| 128 | RSA-3072 | ECC 256-383 | NTRU-397 |
| 192 | RSA-7680 | ECC 384-511 | NTRU-587 |
| 256 | RSA-15360 | ECC 512 | NTRU-787 |
| NTRU 251 | RSA 1024 | ECC 163 | |
|---|---|---|---|
| Public key (bits) | 2008 | 1024 | 164 |
| Private key (bits) | 251 | 1024 | 163 |
| Plaintext block (bits) | 160 | 702 | 163 |
| Ciphertext block (bits) | 2008 | 1024 | 163 |
| Encryption speed (blocks/sec) Encryption speed (Mbits/sec) | 22,727 3.6 | 1280 0.9 | 458 0.075 |
| Encryption Speed (blocks/sec) Encryption speed (Mbits/sec) | 10,869 1.7 | 110 0.077 | 702 0.11 |
| Key Generations | Encryption | Decryption | |
|---|---|---|---|
| NTRU167 | 90 msecs | 21 s | 20 s |
| RSA512 | 5 s | 3.5 s | 34 s |
| NTRU263 | 150 msecs | 31 s | 30 s |
| RSA1024 | 10 s | 5.8 s | 100 s |
| NTRU503 | 420 msecs | 56 s | 55 s |
| RSA2048 | 50 s | 10.8 s | 345 s |
| N | The Time to Multiply One Element (bi.A) | The Time to Execute 100 × 100 Polynomial Multiplication |
|---|---|---|
| 503 | 38.25 | 19,239.8 s |
| 347 | 29.21 | 10,135.4 s |
| 251 | 22.42 | 5627.4 s |
| 167 | 16.53 | 2760.5 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Elkabbany, G.F.; Ahmed, H.I.S.; Aslan, H.K.; Cho, Y.-I.; Abdallah, M.S. Lightweight Computational Complexity Stepping Up the NTRU Post-Quantum Algorithm Using Parallel Computing. Symmetry 2024, 16, 12. https://doi.org/10.3390/sym16010012
Elkabbany GF, Ahmed HIS, Aslan HK, Cho Y-I, Abdallah MS. Lightweight Computational Complexity Stepping Up the NTRU Post-Quantum Algorithm Using Parallel Computing. Symmetry. 2024; 16(1):12. https://doi.org/10.3390/sym16010012
Chicago/Turabian StyleElkabbany, Ghada Farouk, Hassan I. Sayed Ahmed, Heba K. Aslan, Young-Im Cho, and Mohamed S. Abdallah. 2024. "Lightweight Computational Complexity Stepping Up the NTRU Post-Quantum Algorithm Using Parallel Computing" Symmetry 16, no. 1: 12. https://doi.org/10.3390/sym16010012
APA StyleElkabbany, G. F., Ahmed, H. I. S., Aslan, H. K., Cho, Y.-I., & Abdallah, M. S. (2024). Lightweight Computational Complexity Stepping Up the NTRU Post-Quantum Algorithm Using Parallel Computing. Symmetry, 16(1), 12. https://doi.org/10.3390/sym16010012