
Interest-Aware Message-Passing Layer-Refined Graph Convolutional Network for Recommendation

Abstract
:1. Introduction
- The constructed user-item graph is grouped into subgraphs by using user characteristics and graph structure information, and the user nodes in the subgraph can have more similar interests than the user nodes in other subgraphs.
- In this paper, we propose a layer refinement graph convolutional neural network recommendation algorithm IMPLayerGCN that focuses on interest transfer. This model refinements the hidden layer in the process of network propagation to alleviate the natural noise introduced by external factors in the recommendation scenario and make the user–item interaction graph sparser.
- A large number of experiments are carried out on the e-commerce dataset. The results show that the proposed model has a significant improvement on the same indicators compared to other recent baseline models.
2. Related Work
3. Methodology
3.1. Framework
3.2. Recap
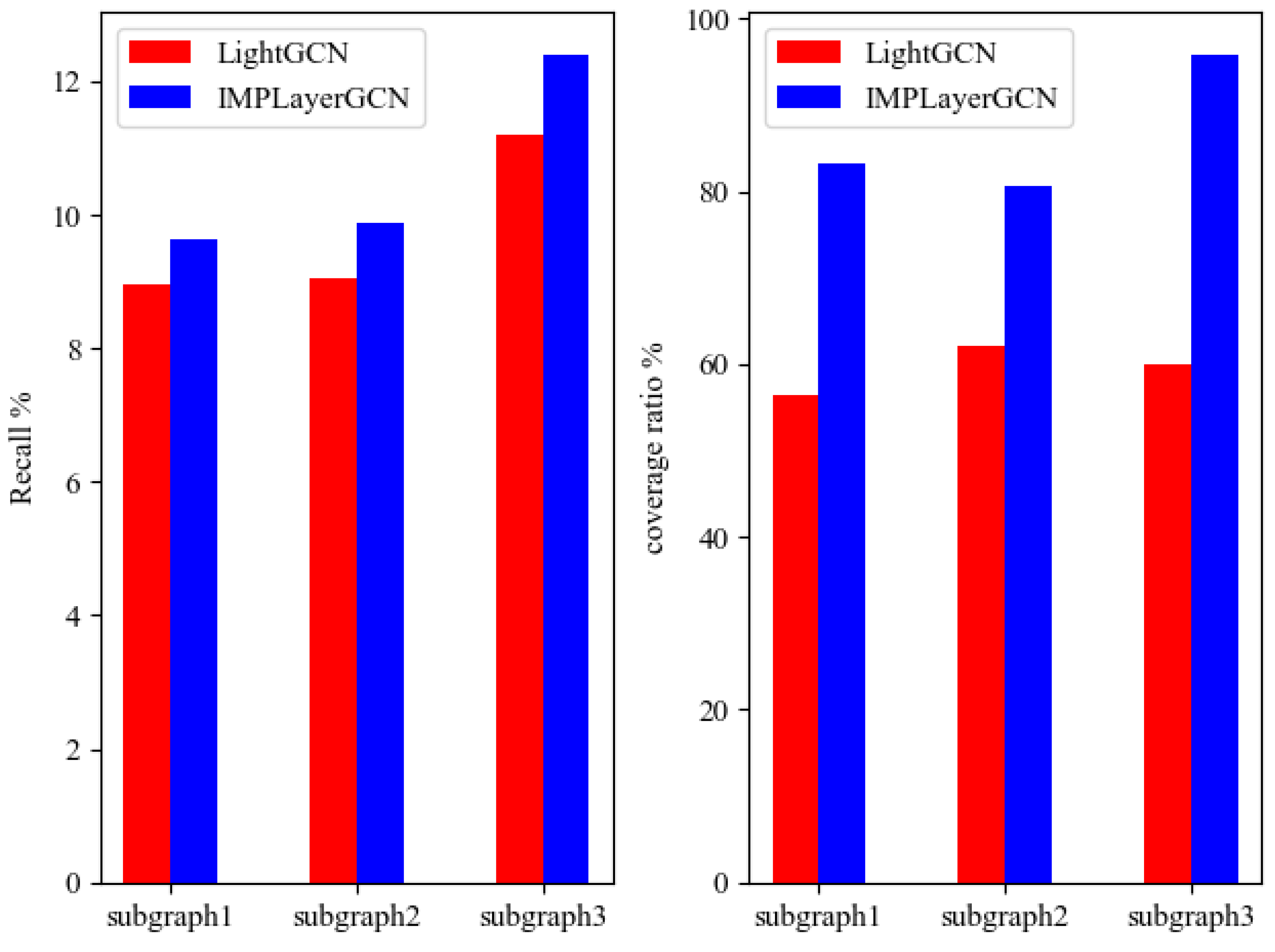
3.3. Layer Refined for Subgraph Learning
3.4. Generating the Subgraph
3.5. Model Optimization
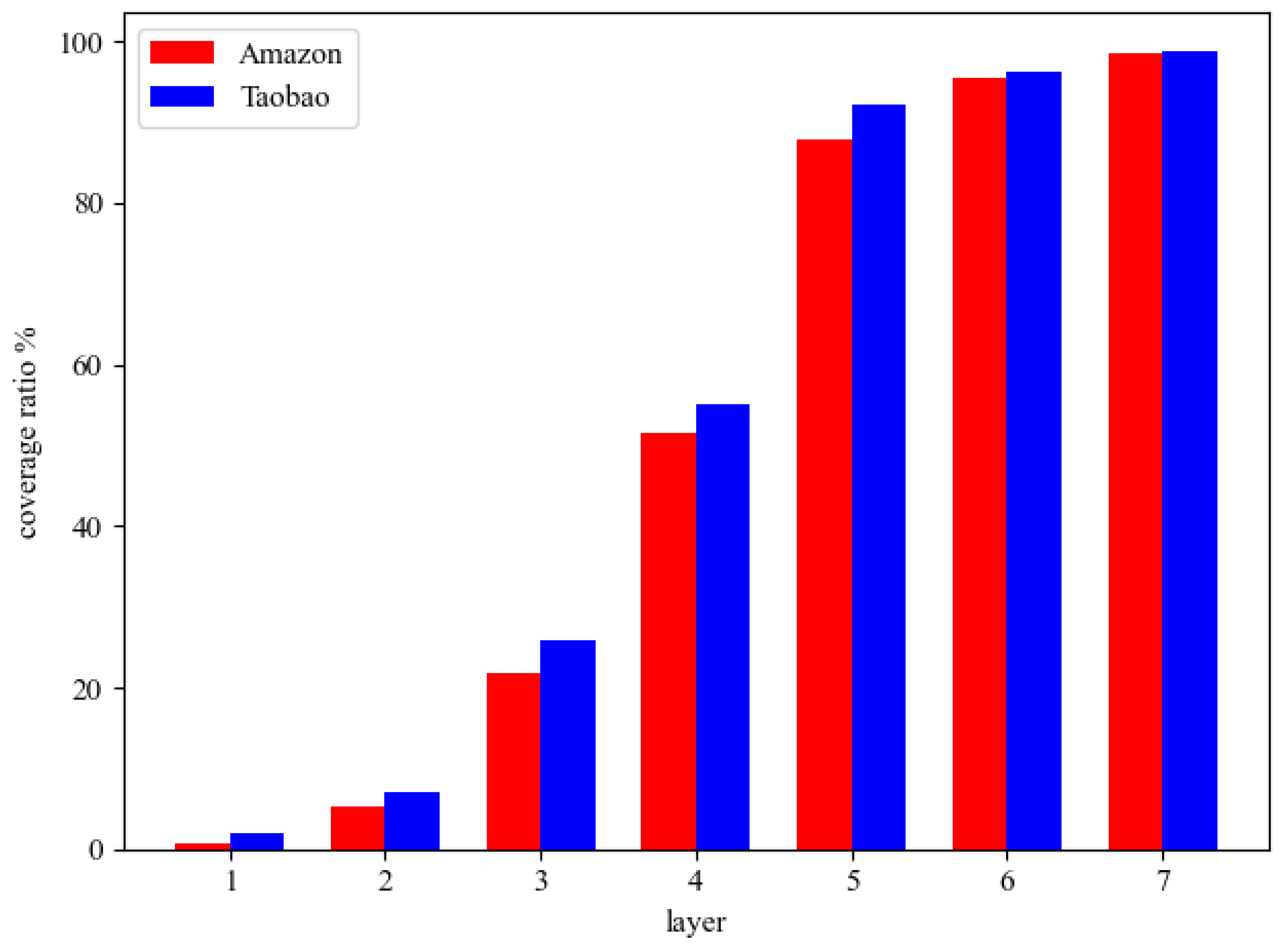
4. Experiments
4.1. Datasets
4.2. Baselines
- LightGCN [1] is a simplified graph convolutional network with only linear propagation and aggregation among neighbors. It averages the hidden layer embeddings for predicted end-user/item embedding calculations.
- A2-GCN [22] learns final embeddings using node classification and graph classification.
- CrossGCN [23] obtains cross-features on the basis of traditional matrix factorization methods and enhances feature learning capabilities.
- DHCN [24] uses the hypergraph to model user and item information, maximizes the interaction information between graph network learning nodes by constructing the line graph of the hypergraph, and integrates self-supervised learning into the training of the network for recommendation.
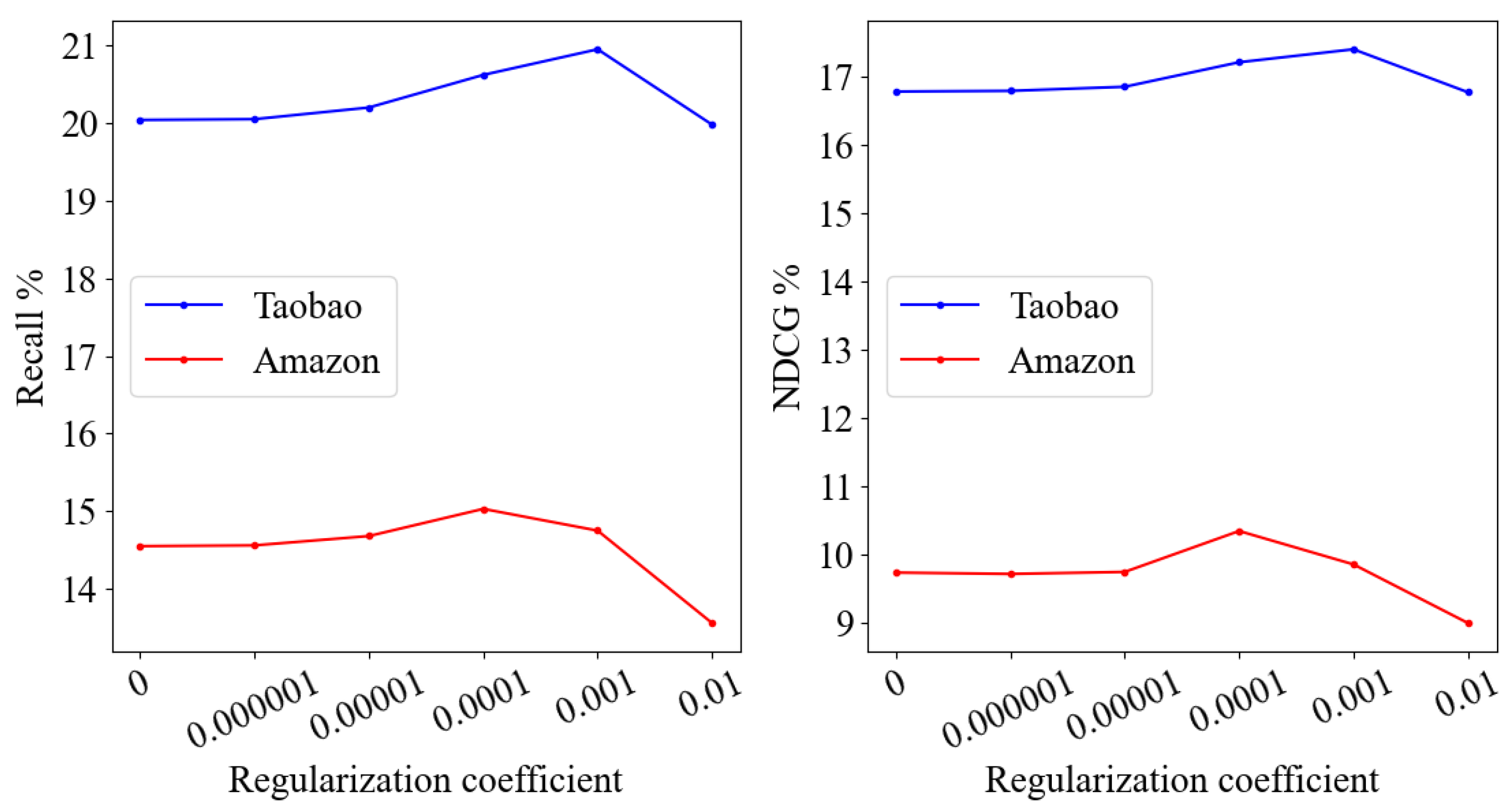
4.3. Experimental Settings
4.4. Results
4.5. Ablation Study
- IMPLayerGCN-SI: It removes graph structure information from the subgraph generation module.
- IMPLayerGCN-1st: It uses first-order propagation in subgraph learning.
- IMPLayerGCN-LR: It removes the layer refinement module.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- He, X.; Deng, K.; Wang, X.; Li, Y.; Zhang, Y.; Wang, M. Lightgcn: Simplifying and Powering Graph Convolution Network for Recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 25–30 July 2020. [Google Scholar]
- Li, S.; Yue, W.; Jin, Y. Patient-Oriented Herb Recommendation System Based on Multi-Graph Convolutional Network. Symmetry 2022, 14, 638. [Google Scholar] [CrossRef]
- Wu, Y.; Liu, H.; Yang, Y. Graph Convolutional Matrix Completion for Bipartite Edge Prediction. In Proceedings of the KDIR, Seville, Spain, 18–20 September 2018. [Google Scholar]
- Gao, C.; Zheng, Y.; Li, N.; Li, Y.; Qin, Y.; Piao, J.; Quan, Y.; Chang, J.; Jin, D.; He, X.; et al. A Survey of Graph Neural Networks for Recommender Systems: Challenges, Methods, and Directions. ACM Trans. Recomm. Syst. 2023, 1, 1–51. [Google Scholar] [CrossRef]
- Chen, L.; Wu, L.; Hong, R.; Zhang, K.; Wang, M. Revisiting Graph Based Collaborative Filtering: A Linear Residual Graph Convolutional Network Approach. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 27–34. [Google Scholar]
- Rong, Y.; Huang, W.; Xu, T.; Huang, J. Dropedge: Towards Deep Graph Convolutional Networks on Node Classification. arXiv 2019, arXiv:1907.10903. [Google Scholar]
- Luo, D.; Cheng, W.; Yu, W.; Zong, B.; Ni, J.; Chen, H.; Zhang, X. Learning to Drop: Robust Graph Neural Network via Topological Denoising. In Proceedings of the 14th ACM International Conference on Web Search and Data Mining, Jerusalem, Israel, 8–12 March 2021. [Google Scholar]
- Schlichtkrull, M.S.; De Cao, N.; Titov, I. Interpreting Graph Neural Networks for NLP with Differentiable Edge Masking. arXiv 2020, arXiv:2010.00577. [Google Scholar]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.S. Neural Collaborative Filtering. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017. [Google Scholar]
- Ying, R.; He, R.; Chen, K.; Eksombatchai, P.; Hamilton, W.L.; Leskovec, J. Graph Convolutional Neural Networks for Web-scale Recommender Systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, London, UK, 19–23 August 2018; pp. 974–983. [Google Scholar]
- Wang, X.; He, X.; Wang, M.; Feng, F.; Chua, T.S. Neural Graph Collaborative Filtering. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 165–174. [Google Scholar]
- Rianne van den, B.; Kipf, T.N.; Welling, M. Graph Convolutional Matrix Completion. arXiv 2017, arXiv:1706.02263. [Google Scholar]
- Wu, F.; Souza, A.; Zhang, T.; Fifty, C.; Yu, T.; Weinberger, K. Simplifying Graph Convolutional Networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6861–6871. [Google Scholar]
- Zhang, L.; Liu, Y.; Zhou, X.; Miao, C.; Wang, G.; Tang, H. Diffusion-based Graph Contrastive Learning for Recommendation with Implicit Feedback. In Database Systems for Advanced Applications: 27th International Conference (DASFAA); Springer International Publishing: Cham, Switzerland, 2022; pp. 232–247. [Google Scholar]
- Zhou, X.; Sun, A.; Liu, Y.; Zhang, J.; Miao, C. Selfcf: A Simple Framework for Self-supervised Collaborative Filtering. arXiv 2021, arXiv:2107.03019. [Google Scholar] [CrossRef]
- Lee, D.; Kang, S.; Ju, H.; Park, C.; Yu, H. Bootstrapping User and Item Representations for One-class Collaborative Filtering. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 11–15 July 2021; pp. 317–326. [Google Scholar]
- Mao, K.; Zhu, J.; Xiao, X.; Lu, B.; Wang, Z.; He, X. UltraGCN: Ultra Simplification of Graph Convolutional Networks for Recommendation. In Proceedings of the 30th ACM International Conference on Information and Knowledge Management, Online, 1–5 November 2021; pp. 1253–1262. [Google Scholar]
- Liu, F.; Cheng, Z.; Zhu, L.; Gao, Z.; Nie, L. Interest-Aware Message-passing Gcn for Recommendation. In Proceedings of the Web Conference, Online, 19–23 April 2021; pp. 1296–1305. [Google Scholar]
- Fan, S.; Zhu, J.; Han, X.; Shi, C.; Hu, L.; Ma, B.; Li, Y. Metapath-guided Heterogeneous Graph Neural Network for Intent Recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2478–2486. [Google Scholar]
- Zhang, H.; McAuley, J. Stacked Mixed-order Graph Convolutional Networks for Collaborative Filtering. In Proceedings of the 2020 SIAM International Conference on Data Mining, Cincinnati, OH, USA, 5–8 May 2020; pp. 73–81. [Google Scholar]
- Sun, J.; Zhang, Y.; Ma, C.; Coates, M.; Guo, H.; Tang, R.; He, X. Multi-graph Convolution Collaborative Filtering. In Proceedings of the 2019 IEEE International Conference on Data Mining (ICDM), Beijing, China, 8–11 November 2019; pp. 1306–1311. [Google Scholar]
- Liu, F.; Cheng, Z.; Zhu, L.; Liu, C.; Nie, L. An Attribute-aware Attentive GCN Model for Attribute Missing in Recommendation. IEEE Trans. Knowl. Data Eng. 2020, 34, 4077–4088. [Google Scholar] [CrossRef]
- Feng, F.; He, X.; Zhang, H.; Chua, T.-S. Cross-gcn: Enhancing Graph Convolutional Network with K-order Feature Interactions. IEEE Trans. Knowl. Data Eng. 2023, 35, 225–236. [Google Scholar] [CrossRef]
- Xia, X.; Yin, H.; Yu, J.; Wang, Q.; Cui, L.; Zhang, X. Self-supervised Hypergraph Convolutional Networks for Session-based Recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 4503–4511. [Google Scholar]
- Chen, M.; Wei, Z.; Huang, Z.; Ding, B.; Li, Y. Simple and Deep Graph Convolutional Networks. In Proceedings of the International Conference on Machine Learning, Vienna, Australia, 12–18 July 2020; pp. 1725–1735. [Google Scholar]
- Li, Q.; Han, Z.; Wu, X.-M. Deeper Insights into Graph Convolutional Networks for Semi-supervised Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Count of Users | Count of Items | Interactions |
|---|---|---|---|
| Amazon | 115,144 | 39,688 | 1,025,169 |
| Taobao | 82,633 | 136,710 | 4,230,631 |
| Model | Amazon | |||||
|---|---|---|---|---|---|---|
| N@10 | N@20 | N@50 | R@10 | R@20 | R@50 | |
| A2-GCN | 0.0411 | 0.0541 | 0.0801 | 0.0545 | 0.0736 | 0.0929 |
| DHCN | 0.0420 | 0.0554 | 0.0806 | 0.0572 | 0.0782 | 0.1038 |
| LightGCN | 0.0425 | 0.0557 | 0.0811 | 0.0584 | 0.0766 | 0.1157 |
| CrossGCN | 0.0502 | 0.0632 | 0.0985 | 0.0658 | 0.0854 | 0.1316 |
| IMPLayerGCN | 0.0539 | 0.0777 | 0.1034 | 0.0699 | 0.0998 | 0.1470 |
| Model | Taobao | |||||
|---|---|---|---|---|---|---|
| N@10 | N@20 | N@50 | R@10 | R@20 | R@50 | |
| A2-GCN | 0.1243 | 0.1292 | 0.1395 | 0.1351 | 0.1471 | 0.1574 |
| DHCN | 0.1239 | 0.1292 | 0.1384 | 0.1359 | 0.1489 | 0.1692 |
| LightGCN | 0.1275 | 0.1337 | 0.1403 | 0.1391 | 0.1551 | 0.1617 |
| CrossGCN | 0.1320 | 0.1475 | 0.1668 | 0.1415 | 0.1631 | 0.1880 |
| IMPLayerGCN | 0.1394 | 0.1560 | 0.1741 | 0.1419 | 0.1762 | 0.2094 |
| Model | Amazon | |||||
|---|---|---|---|---|---|---|
| N@10 | N@20 | N@50 | R@10 | R@20 | R@50 | |
| IMPLayerGCN-SI | 0.0531 | 0.0698 | 0.0966 | 0.0663 | 0.0794 | 0.1331 |
| IMPLayerGCN-1st | 0.0489 | 0.0637 | 0.0912 | 0.0656 | 0.0789 | 0.1304 |
| IMPLayerGCN-LR | 0.0522 | 0.0643 | 0.0948 | 0.0675 | 0.0856 | 0.1367 |
| IMPLayerGCN | 0.0539 | 0.0777 | 0.1034 | 0.0699 | 0.0998 | 0.1470 |
| Model | Taobao | |||||
|---|---|---|---|---|---|---|
| N@10 | N@20 | N@50 | R@10 | R@20 | R@50 | |
| IMPLayerGCN-SI | 0.1342 | 0.1503 | 0.1718 | 0.1368 | 0.1632 | 0.1891 |
| IMPLayerGCN-1st | 0.1321 | 0.1488 | 0.1670 | 0.1379 | 0.1613 | 0.1834 |
| IMPLayerGCN-LR | 0.1356 | 0.1536 | 0.1715 | 0.1418 | 0.1730 | 0.1976 |
| IMPLayerGCN | 0.1394 | 0.1560 | 0.1741 | 0.1419 | 0.1762 | 0.2094 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, X.; Wu, J.; Yu, J. Interest-Aware Message-Passing Layer-Refined Graph Convolutional Network for Recommendation. Symmetry 2023, 15, 1013. https://doi.org/10.3390/sym15051013
Yang X, Wu J, Yu J. Interest-Aware Message-Passing Layer-Refined Graph Convolutional Network for Recommendation. Symmetry. 2023; 15(5):1013. https://doi.org/10.3390/sym15051013
Chicago/Turabian StyleYang, Xingyao, Jinchen Wu, and Jiong Yu. 2023. "Interest-Aware Message-Passing Layer-Refined Graph Convolutional Network for Recommendation" Symmetry 15, no. 5: 1013. https://doi.org/10.3390/sym15051013
APA StyleYang, X., Wu, J., & Yu, J. (2023). Interest-Aware Message-Passing Layer-Refined Graph Convolutional Network for Recommendation. Symmetry, 15(5), 1013. https://doi.org/10.3390/sym15051013