1. Introduction
Steganography is the science and art of covert communication by slightly modifying the data in digital media, such as image, audio and video, without drawing any suspicion. In the past decade, many efforts have been dedicated to improving the security of image steganography [
1,
2,
3,
4,
5,
6], while less attention has been attached to video steganography. On the other hand, with the rapid development of electronic and multimedia technology, video is gradually being widely used in our daily lives, especially with the emergence of the H.264/AVC video format. Compared with other traditional cover medias, H.264/AVC videos have rich compression pipelines in terms of cover elements. Additionally, according to the difference on the selection of cover elements, currently, video steganography can be divided into the following categories: motion vector (MV)-based [
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17], quantized DCT coefficients based [
18,
19,
20,
21,
22,
23,
24,
25,
26], partition modes based [
27,
28,
29,
30,
31,
32] and quantization-parameters-based [
33,
34,
35], among which, motion vector (MV)-based H.264/AVC video steganography is currently the most prevalent.
Generally speaking, MV-based steganographic schemes can be further categorized into two popular types: heuristic schemes [
7,
8,
9] and content-adaptive ones [
10,
11,
12,
13,
14,
15,
16,
17]. For heuristic MV-based video steganography, secret messages are usually embedded into the candidate MVs through some predefined selection rules, but these rules tend to increase its potential security risks. Recently, with the emergence of the framework of minimal distortion embedding, content-adpative MV-based video steganographic schemes have been gradually proposed, which mainly focuses on the design of efficient distortion cost. For example, Cao et al. [
11] assigned a cost to each MV by exploiting its probabilities of satisfying the optimal criteria, and the secret messages were embedded into MVs by using WPCs (Wet Paper Codes) and STCs (Syndrome-Trellis Codes) [
36]. More recently, Zhang et al. [
12] proposed another video steganographic scheme called MVMPLO (Motion Vector Modification with Preserved Local Optimality) to preserve the local optimality in SAD (Sum of Absolute Differences) sense. Moreover, in order to maintain the statistical distribution of MV after embedding modifications, Yao et al. [
13] suggested modifying the MVs with slight changes in MV distributions and prediction errors.
To cope with the abuse of MV-based steganography, considerable progress has been made in developing symmetric MV-based steganalytic features [
37,
38,
39,
40,
41,
42,
43,
44,
45,
46,
47,
48,
49], including statistic-based features, calibration-based features and logic-based features. With regard to the statistic-based features, they are usually constructed based on the distribution of noise residuals calculated from adjacent MVs, with the assumption that the embedding modifications are additive independent. For instance, Su et al. [
37] utilized the statistical characteristics of neighboring MV differences to construct steganalytic features. Moreover, Tasdemir et al. [
38] proposed a spatio-temporal rich model-based steganalytic feature, which was built from the MV residuals filtered by a series of high-pass filters.
As for calibration-based features, they are usually constructed by the histogram of the difference between original MVs and corresponding recompressed ones. Following this way, Cao et al. [
39] proposed a calibrated feature by recompressing the H.264/AVC video to improve detection performance. Moreover, in response to the mismatching of motion estimation of cover and stego video after recompression, Wang et al. [
40] recently proposed an improved version by predicting the motion estimation before calibration.
It is well known that the MVs of cover videos are mostly locally optimal and inconsistent, but the steganographic embedding modification usually breaks these characteristics. Motivated by this defect, a kind of logic-based feature constructed from the logical probabilities of MVs subsequently appeared. Typically, Wang et al. [
41] constructed an AoSO (Add-or-Subtract-One) feature by checking whether an MV is locally optimal in SAD sense, which is the first logic-based feature. Based on this, Zhang et al. [
42] further utilized the Lagrangian cost function to check the local optimality and then proposed an enhanced feature called NPELO (Near-Perfect Estimation for Local Optimality). Moreover, in response to the case that the originally different MVs of the sub-blocks in the same macroblock tend to be consistent after embedding modifications, Zhai et al. [
43] proposed a more powerful feature called MVC (Motion Vector Consistency), which exhibits better detection performance in most cases.
It should be noted that statistic-based features require the block size to be fixed, but the fixed block size option has already been abandoned in the current practical video codings, e.g., H.264/AVC and H.265/HEVC, and uses variable block size instead; therefore, they can not be applied in the detection of variable block-size-based video steganography. As for calibration-based features, both the way of motion estimation and the coding parameters are required to be kept the same before and after calibration, otherwise, the detection performance will be degraded. Although they perform much more effectively than the statistic-based and calibration-based features, logic-based features still have the risk of being defeated by some target steganographic schemes [
11,
12,
16]. Given all this, it is desirable to construct an effective and general steganalytic feature for MV-based H.264/AVC video steganography. In this paper, we propose a novel steganalytic feature composed of diverse subfeatures for existing MV-based steganographic schemes. This work is mainly motivated by the numerical anomaly of local Lagrangian cost quotient introduced by the embedding modifications and, based on which, a local Lagrangian cost quotient (LLCQ)-based feature is proposed. Moreover, for further improving its detection performance, the previous efficient logic-based feature (Lg) is then introduced and integrated into the LLCQ, thereby forming a more powerful steganalytic feature, i.e., Lg-LLCQ. Experimental results show that our proposed Lg-LLCQ is much more effective and general compared with the existing steganalytic schemes. The main contributions of this paper are summarized as follows.
(1) The effects of the MV modifications on the statistic characteristics of local Lagrangian cost quotient are evaluated, and the steganalytic performances of LLCQ are provided, all of which indicate the effectiveness of the proposed LLCQ feature.
(2) The logic-based (Lg) feature and local Lagrangian cost quotient (LLCQ)-based features are merged for steganalysis, which provides better results than the corresponding single-type feature.
The rest of the paper is structured as follows. In
Section 2, Lagrangian cost functions in motion estimation and local optimality for video steganalysis of H.264 video are briefly described. The construction of our proposed steganalytic feature is presented in
Section 3, followed by the experimental results and analysis in
Section 4.1 for its verification of reasonability and feasibility. Finally, the paper is concluded in
Section 5.
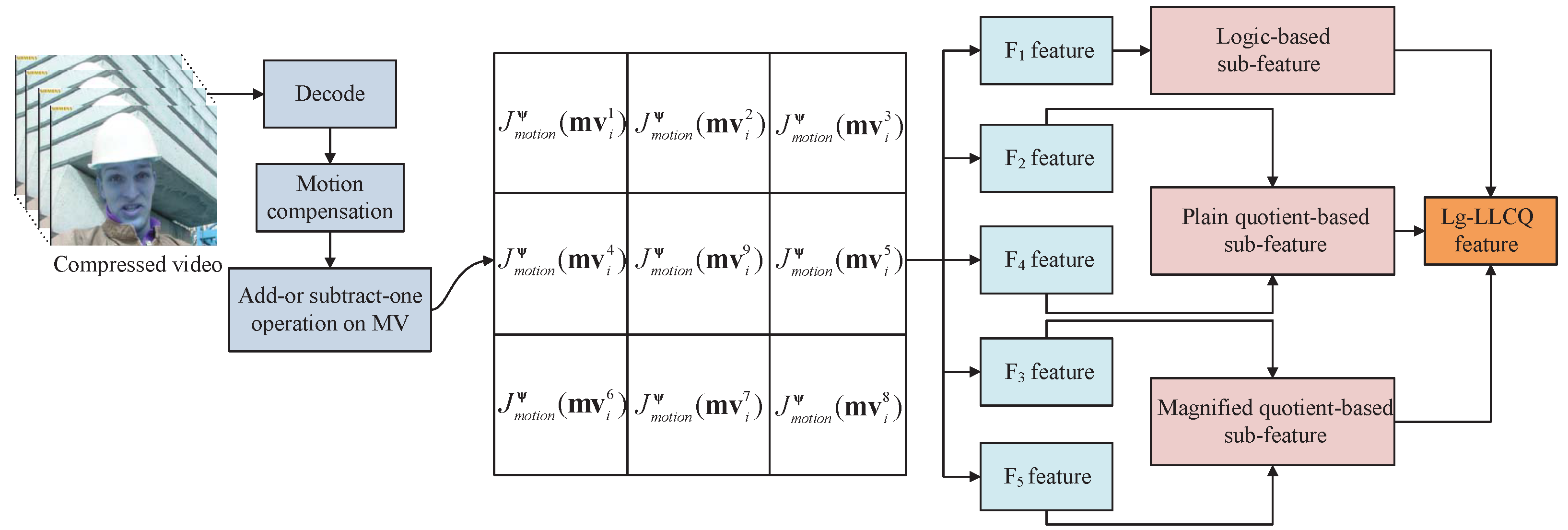
4. Experiments
In this section, extensive experiments are conducted to verify the effectiveness, generalization and stability of the proposed scheme. We compare the detection performance of our proposed Lg-LLCQ feature with three other state-of-the-art steganalytic features, i.e., AoSO, NPELO and MVC, under various application scenes. Specifically, seven kinds of setups are carefully constructed in the following. Setup 1 is the basic test that runs to determine the constant exponential parameter p, and Setup 2 is first performed to test the effectiveness of the LLCQ feature and then is constructed to further verify the effectiveness of the proposed combined Lg-LLCQ feature. The stability of the Lg-LLCQ feature is assessed under Setup 3, and the independent effects of the subfeatures in Lg-LLCQ, i.e., logic-based subfeature, plain quotient-based subfeature and magnified quotient-based subfeature, are carefully investigated and compared under Setup 4. The experiment under Setup 5 is mainly to show our method can be directly applied to the previous video coding standards. Setup 6 is carried out to test whether the proposed feature is still effective under cover sources and steganographic scheme mismatch scenes. Lastly, and most importantly, a well-designed experiment is conducted to evaluate the steganalytic performance of the proposed Lg-LLCQ feature under different video resolutions. Additionally, bold in the tables indicates the best performance under the given settings.
4.1. Experiment Setups
4.1.1. Datasets
In order to comprehensively compare the detection performance of different steganalytic features under different scenes, three public video datasets are introduced for experiments, i.e., DB1 [
54], DB2 [
52] and DB3 [
54]. DB1, DB2 and DB3 all consist of 100 video sequences. Each sequence in DB1 and DB3 includes 100 frames on average, while the sequence in DB2 includes 220 frames on average. Moreover, the video sequences in DB1 and DB2 are stored in the 4:2:0 color sampling format with the same resolution, i.e.,
, and the video sequences in DB3 are stored in the 4:2:0 color sampling format with resolution, i.e.,
.
4.1.2. Steganographic Schemes
To evaluate the effectiveness, generalization and stability of our proposed steganalytic feature, three advanced MV-based steganographic schemes are introduced for experiments. One of them is the conventional scheme proposed by Aly [
9] (denoted as Tar1), the other two are content-adaptive embedding schemes, i.e., MVMPLO [
12] (denoted as Tar2) and Cao et al. [
11] (denoted as Tar3). For fair comparison, the payload is depicted by a relative indicator, i.e., bpnsmv, also called relative payload, which is the ratio of the number of embedded bits to the total number of nonskip MVs, and all the involved steganographic schemes are implemented using JM 19.0 reference software [
53]. It should be noted that the payload is ranging from 0.1 bpnsmv +
to 0.5 bpnsmv +
in Tar3, where
is an additional
-bit in the second channel of Tar3.
4.1.3. Setups for Performance Evaluation
To better test the feasibility of the proposed steganalytic feature in practical application, six kinds of setups are elaborately constructed in this paper.
Setup 1: In this setup, the steganalytic performance and the average time consumption of feature extraction are evaluated under different parameter . All these experiments are conducted on DB1 by using Tar2 at payload 0.4 bpnsmv under QP = 28 and QP = 18, and the experiment environment is Visual Studio 2013 on a 3.0 GHz Intel Core E5-2653 CPU with 128 GB memory.
Setup 2: Two kinds of experiments are conducted in this setup. One aims at testing the effectiveness of the proposed LLCQ feature in detecting Tar2 on DB1 and DB2 under QP = 28 and QP = 18. The other is performed to further evaluate the steganalytic performance of the combined feature Lg-LLCQ against involved steganographic schemes with payloads 0.1∼0.5 bpnsmv under QP = 28 and QP = 18. Additionally, each video sample in these experiments is coded with , under which the prediction structure is IPPPPPPPPPIPP …, i.e., one I-slice followed by nine P slices with one reference frame.
Setup 3: In practical applications of steganalysis, the stego videos may contain various payloads and QPs. In order to evaluate the stability of our proposed features against this circumstance, we then mix the stego videos obtained under setup 2 for experiments.
Setup 4: For evaluating the independent effects of various subfeatures of the proposed Lg-LLCQ, the logic-based subfeature, plain quotient-based subfeature and magnified quotient-based subfeatures are separately employed to detect Tar2 and Tar3, wherein the stego videos are obtained under setup 2 at payloads 0.2∼0.4 bpnsmv.
Setup 5: To evaluate the applicability of the proposed Lg-LLCQ under fixed block size and different QPs, the size of all coding units is taken as 16 × 16, and the QPs are also set as 28 and 18. The proposed Lg-LLCQ and other involved steganalytic features are all employed to detect Tar2 at payloads 0.2 and 0.4 bpnsmv under the same coding configurations in setup 2.
Setup 6: The mismatch of cover sources and steganographic schemes is generally considered to be the most influential factor limiting the application of steganalysis in the real world. In this setup, to simulate the real detection scene, an experiment is performed to evaluate the applicability of our proposed feature by training and testing on different cover sources and steganographic schemes. To differentiate various steganalytic and steganographic schemes, in this part, we use the syntax of names following the convention: − , where indicates steganalytic scheme, i.e., AoSO, NPELO, MVC and Lg-LLCQ, and is the steganographic scheme, i.e., Tar2 and Tar3.
Setup 7: To evaluate the steganalytic performance of the proposed Lg-LLCQ on DB3, the proposed Lg-LLCQ and other involved steganalytic features are all employed to detect Tar2∼3 at payloads 0.1 and 0.3 bpnsmv under the same coding configurations in setup 2.
4.1.4. Training and Classification
In our experiments, the features are extracted from each video sample. Throughout all the steganalytic experiments, sixty percent cover–stego pairs are randomly selected for training, while the remaining are randomly shuffled and sent into the SVM classifier one by one for testing. The penalty factor
C and kernel factor
in Gaussian-kernel SVM are optimized by a five-fold cross-validation on the grid space
,
. The detection performance will be quantified as the average accuracy
, which is defined as
where
is averaged over 50 iterations on each steganalytic experiment and
and
represent the probability of false alarm and missed detection, respectively.
4.2. Performance Evaluation
4.2.1. Evaluation of Computational Complexity and Steganalytic Performance of the Proposed Features under Different Parameter P
In this part, we evaluate the computational complexity and steganalytic performance of our proposed Lg-LLCQ in terms of average computation time (Ave-Time) and average accuracy (
) under different exponential parameter
p, and the corresponding results are listed in
Table 1. As can be seen from
Table 1, an increasing
p does not always significantly improve detection performance, but negatively affects Ave-Time. In this regard, for the trade-off between Ave-Time and steganalytic performance, we set
p as 10 in this paper.
4.2.2. Steganalytic Performance Comparison
With the determination of parameter
p, we can then compare the detection performance of the proposed LLCQ with other state-of-the-art MV-based steganalytic schemes, i.e., AoSO, NPELO and MVC, in detecting Tar2, and the corresponding results are shown in
Table 2. As we can see from
Table 2, the proposed LLCQ achieves remarkable performance improvement over NPELO, which proves the conclusion drawn in
Section 3.3 that the LLCQ feature will be feasible for detecting the MV-based steganography. We then systematically compare the detection performance of the proposed combined feature, i.e., Lg-LLCQ, with involved steganalytic schemes at different payloads on DB1 and DB2, the corresponding results are summarized in
Table 3 and
Table 4, respectively. To further evaluate the detection performance,
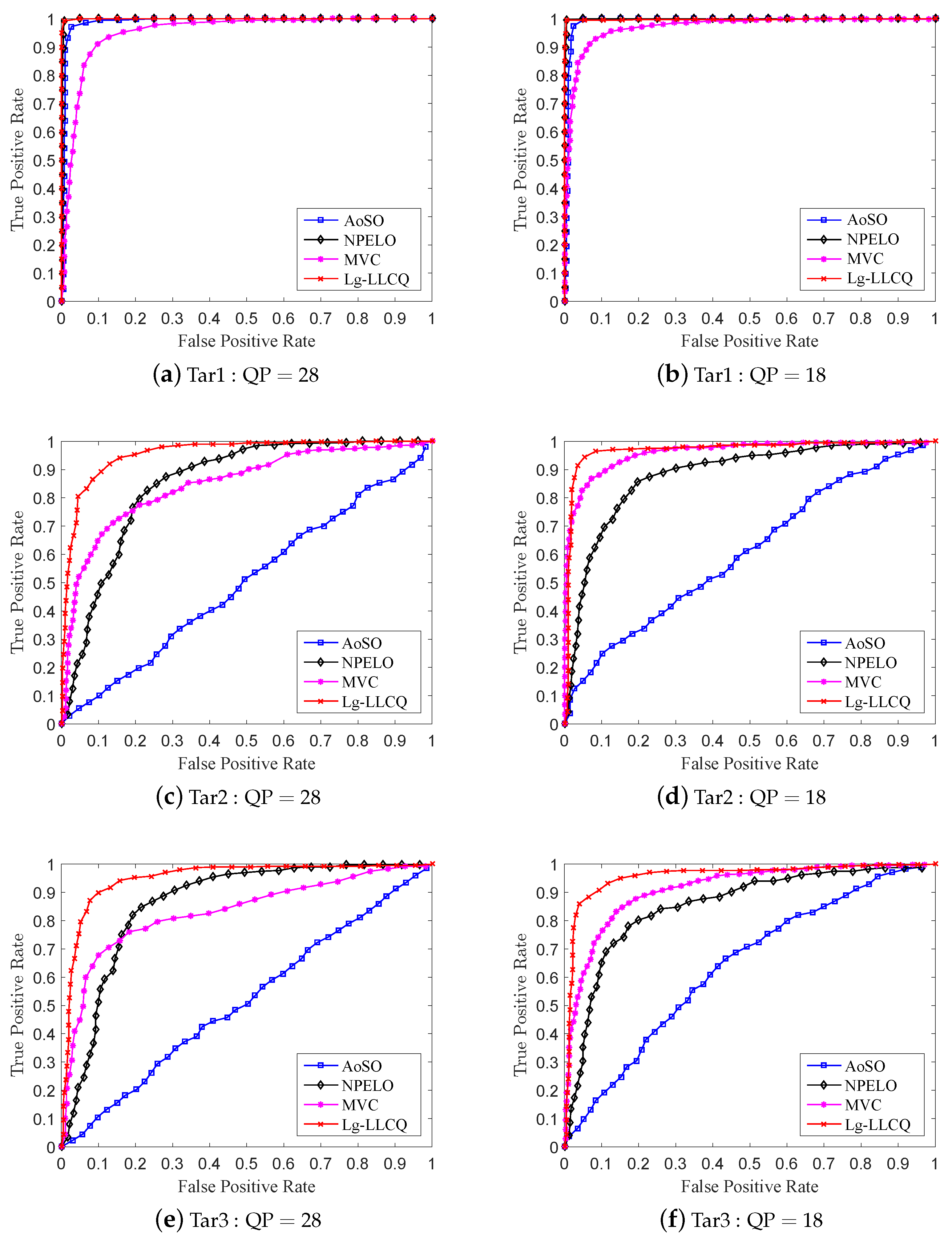
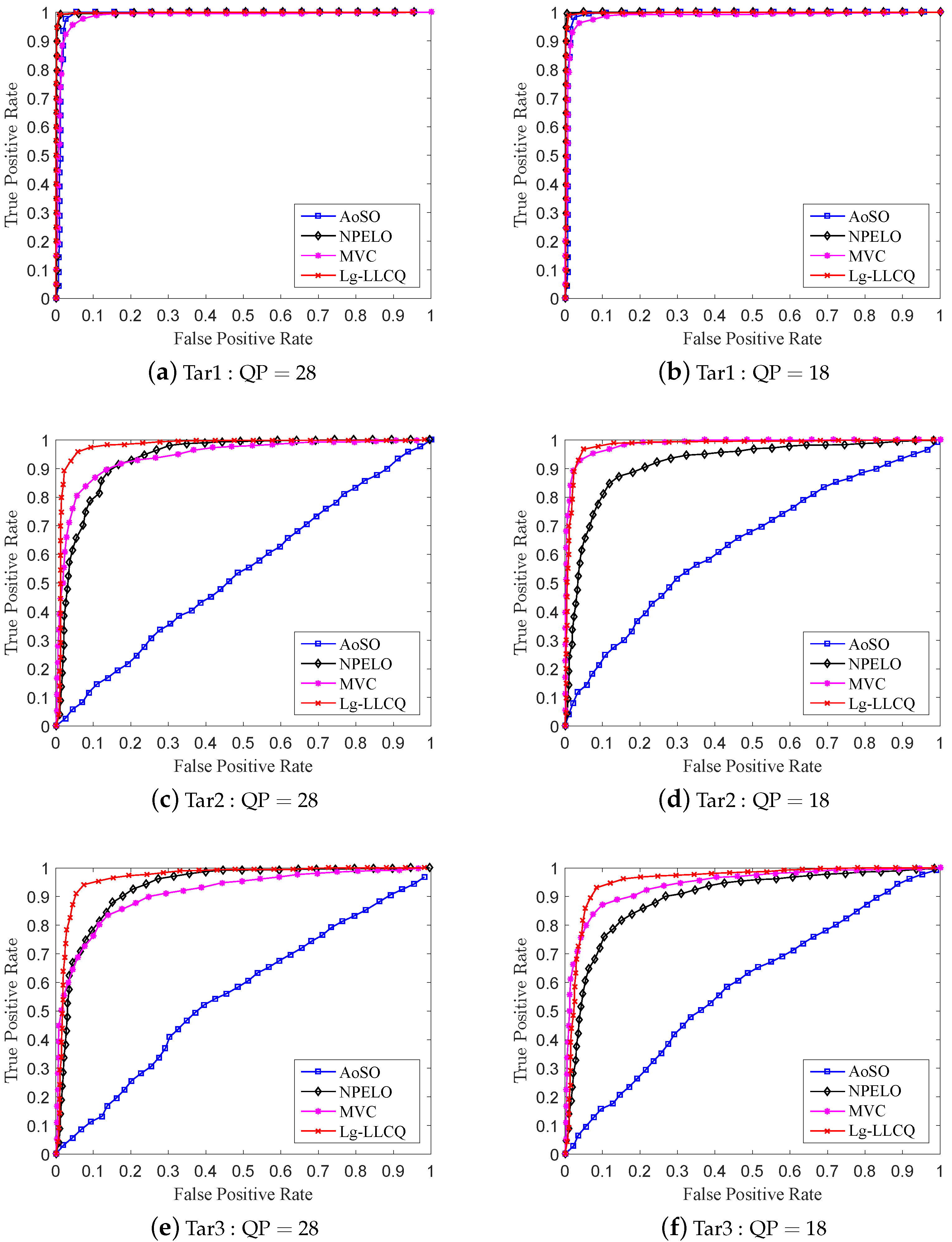
Figure 5 and
Figure 6 give the ROC curves for the detection of the involved steganographic schemes on DB1 and DB2 at 0.3 bpnsmv. For Tar1∼3, our proposed Lg-LLCQ exhibits excellent detection performance at various payloads under QP = 28 and QP = 18 and outperforms other competing methods, as shown in
Table 3 and
Table 4 and
Figure 5 and
Figure 6, indicating the effectiveness of the proposed Lg-LLCQ in detecting the involved steganographic schemes.
Referring to the results, we find that the tested steganalytic features show excellent performance in detecting Tar1. As for the detection on Tar2∼3, the AoSO performs the worst. This is because Tar2∼3 maintain the local optimality of MVs in SAD sense, which would have a dramatically negative influence on AoSO’s steganalytic performance. The NPELO shows comparable performance under QP = 28 but broadly inferior performance under QP = 18 in detecting Tar2∼3 as compared with MVC. The reason that contributed to the detection performance degradation under QP = 18 may be the way of MVs modifications. Specifically, the NPELO is built by checking the local optimality of MVs in rate-distortion sense. However, according to SAD-based modification criterion in Tar2∼3, the stego MVs have certain probabilities to preserve the local optimality in rate-distortion sense. Thus, they lead the detection performance of NPELO degradation under QP = 18 as compared with MVC. Although the MVC feature shows overall better performance in detecting Tar2∼3, it is still inferior to NPELO in some cases, i.e., some small payloads under QP = 28. The accepted internal mechanism is as follows. MVC is a steganalytic feature built by checking the consistency of MVs in small blocks. However, according to the principles of video encoding, when setting high QP in , the encoder tends to choose larger blocks to encode videos. Additionally, the small blocks in the encoded videos will accordingly decrease, adversely affecting the performance of MVC. The NPELO is designed based on the observation that the embedding modifications will break the local optimality of MVs. However, it is less effective in detecting some logic-maintaining steganographic schemes, e.g., Tar2∼3. Unlike NPELO, in which only the logic-based feature is utilized to detect the MV modifications, our proposed Lg-LLCQ takes into account both the logic-based feature and local Lagrangian cost quotient (LLCQ)-based feature for steganalysis, which may contribute to its substantial performance improvement over NPELO and overall performance improvement as compared with MVC in detecting Tar1∼3 under QP = 28 and QP = 18.
4.2.3. Stability Performance Evaluation
To evaluate the stability of our proposed Lg-LLCQ, the stego video samples with different embedding payloads and QPs under the same steganographic scheme will be grouped together for experiments. Under this circumstance, we compare the detection performance of our proposed Lg-LLCQ with AoSO, NPELO and MVC, and the corresponding experimental results are reported in
Table 5. It can be noted from
Table 5 that our scheme outperforms all competitors consistently, which demonstrates that our proposed Lg-LLCQ exhibits more stable steganalytic performance against the involved MV-based steganographic schemes.
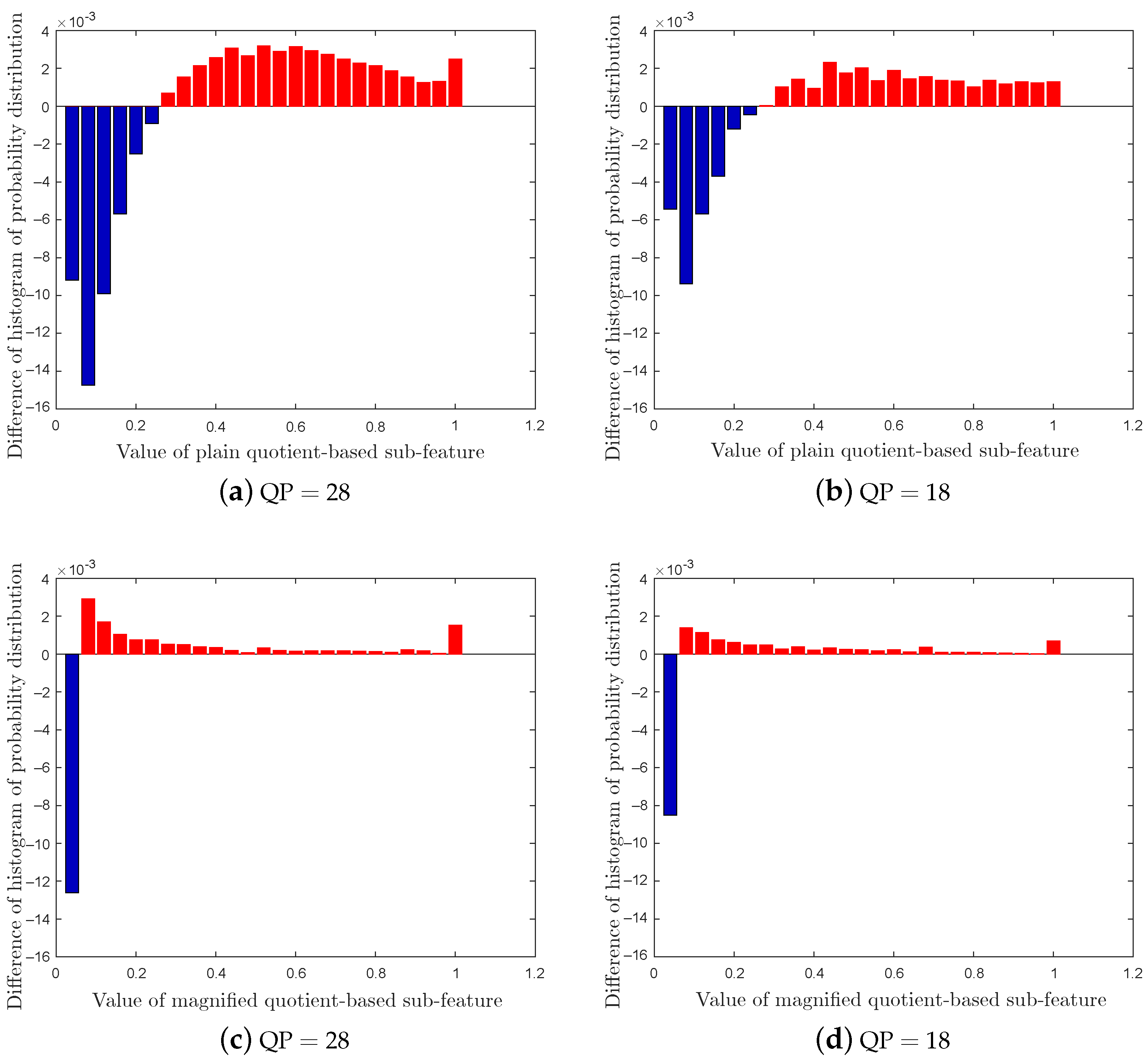
4.2.4. Evaluation of Steganalytic Performance of Subfeatures
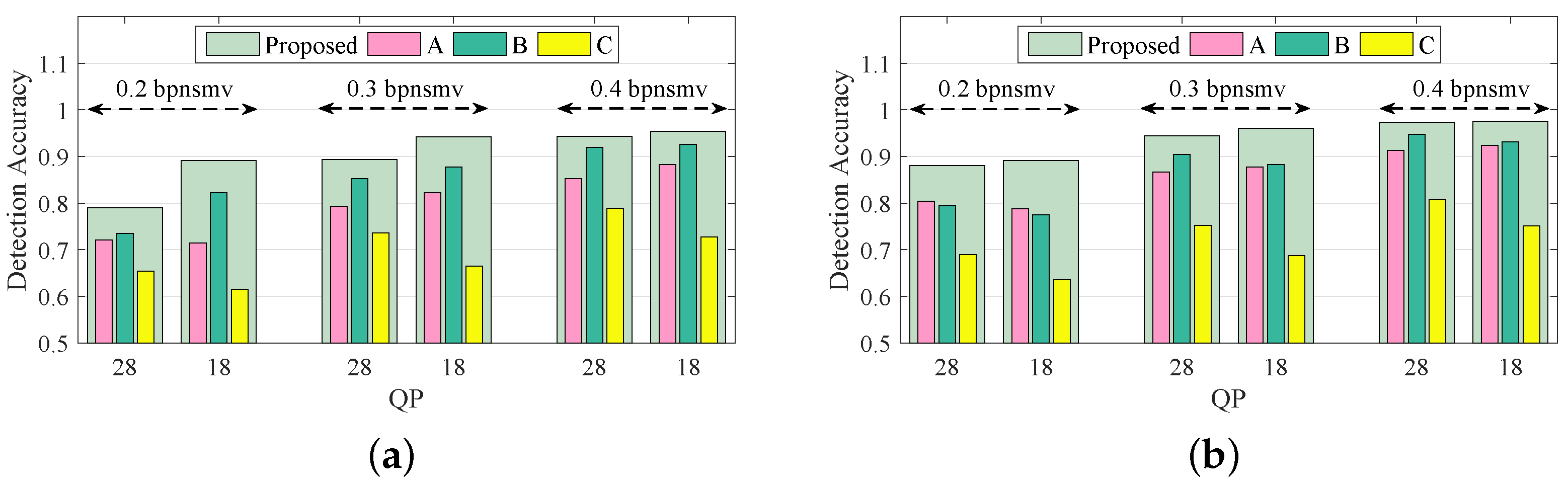
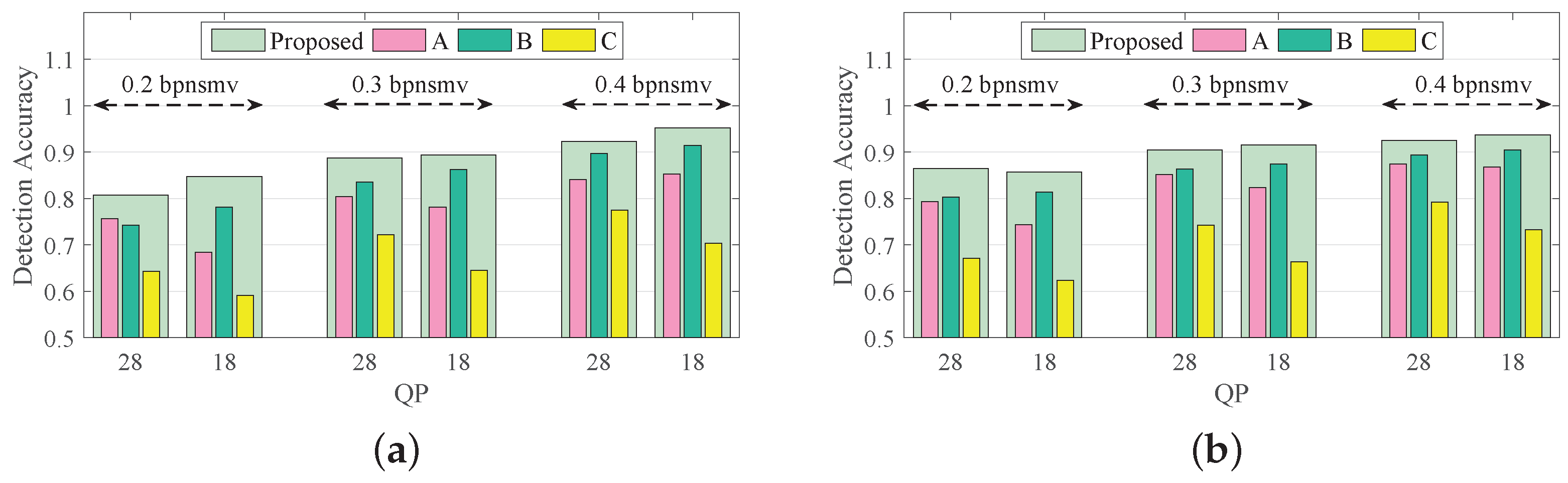
Setup 4 aims to evaluate the independent effects of subfeatures of the proposed Lg-LLCQ against Tar2∼3, and the results are shown in
Figure 7 and
Figure 8. It is observed that the proposed feature, built on a combination of all subfeatures, achieves outstanding gains in detecting Tar2∼3. It is also noted that (1) the logic-based subfeature and plain quotient-based subfeature provide satisfactory detection accuracies in most cases. (2) The magnified quotient-based subfeature enlarged some subtle distinctions between cover and stego videos to further boost the detection performance.
4.2.5. Applicability Performance Evaluation
We then compare the applicability of the proposed Lg-LLCQ with other steganalytic schemes, i.e., AoSO, NPELO and MVC at payloads 0.2 and 0.4 bpnsmv on DB1 and DB2. To accomplish this, we take Tar2 with fixed block size for experiments, and the corresponding results are summarized in
Table 6. They show that our proposed Lg-LLCQ still performs the best. On the other hand, they also show the MVC is totally ineffective in detecting Tar2, which can be attributed to the reason that MVC is defined for the sub-blocks within the same macroblock, while the encoder does not exist sub-blocks under fixed-size option in
. Although our proposed Lg-LLCQ is originally designed for the detection of H.264/AVC video steganography, owing to the general applicability of Lg-LLCQ, it can be easily extended to previous video coding standards, i.e., MPEG-2 and MPEG-4.
4.2.6. Evaluation of Steganalytic Performance under Cover Sources and Steganographic Schemes Mismatch
Since all the involved features achieve excellent performance in detecting Tar1, Tar1 is not considered in this setup. We then proceed to compare the detection performance of our proposed Lg-LLCQ with AoSO, NPELO and MVC under cover sources and steganographic scheme mismatch scenes, which are summarized in
Table 7. For Tar2∼3, our proposed Lg-LLCQ shows nearly perfect detection performance at various payloads under QP = 18 and QP = 28, indicating the effectiveness of the proposed Lg-LLCQ in the detection of Tar2∼3. Note that low QP value, e.g., QP = 18, will weaken the detection model of our proposed Lg-LLCQ in cover sources and steganographic scheme mismatch scenes due to small distortion. This could explain why our proposed Lg-LLCQ is slightly inferior to the MVC feature in detecting Tar2∼3 under QP = 18.
4.2.7. Evaluation of Steganalytic Performance under Different Video Resolutions
We then proceed to evaluate the detection performance of our proposed scheme on DB3. Three SOTA steganalytic schemes, i.e., AoSO, NPELO and MVC, are still included for performance comparison, and the corresponding experimental results are finally listed in
Table 8. It is observed that our proposed Lg-LLCQ can still perform the best among involved steganalytic schemes in detecting Tar2∼3 under the other resolution database.
Table 8 also shows an interesting result that all the test steganalytic schemes perform worse under higher QP value (i.e., QP = 28). This could be due to the fact that a high QP value leads to a decline in the number of MVs. In our paper, the payload is depicted by a relative indicator, i.e., bpnsmv, which is the ratio of the number of embedded bits to the total number of nonskip MVs. Therefore, as the number of MVs decreases, the corresponding embedding payload will also reduce, thereby leading to relatively fewer embedding traces, which finally makes it more difficult for steganalyzers to detect.













{kind=link}
{kind=link}
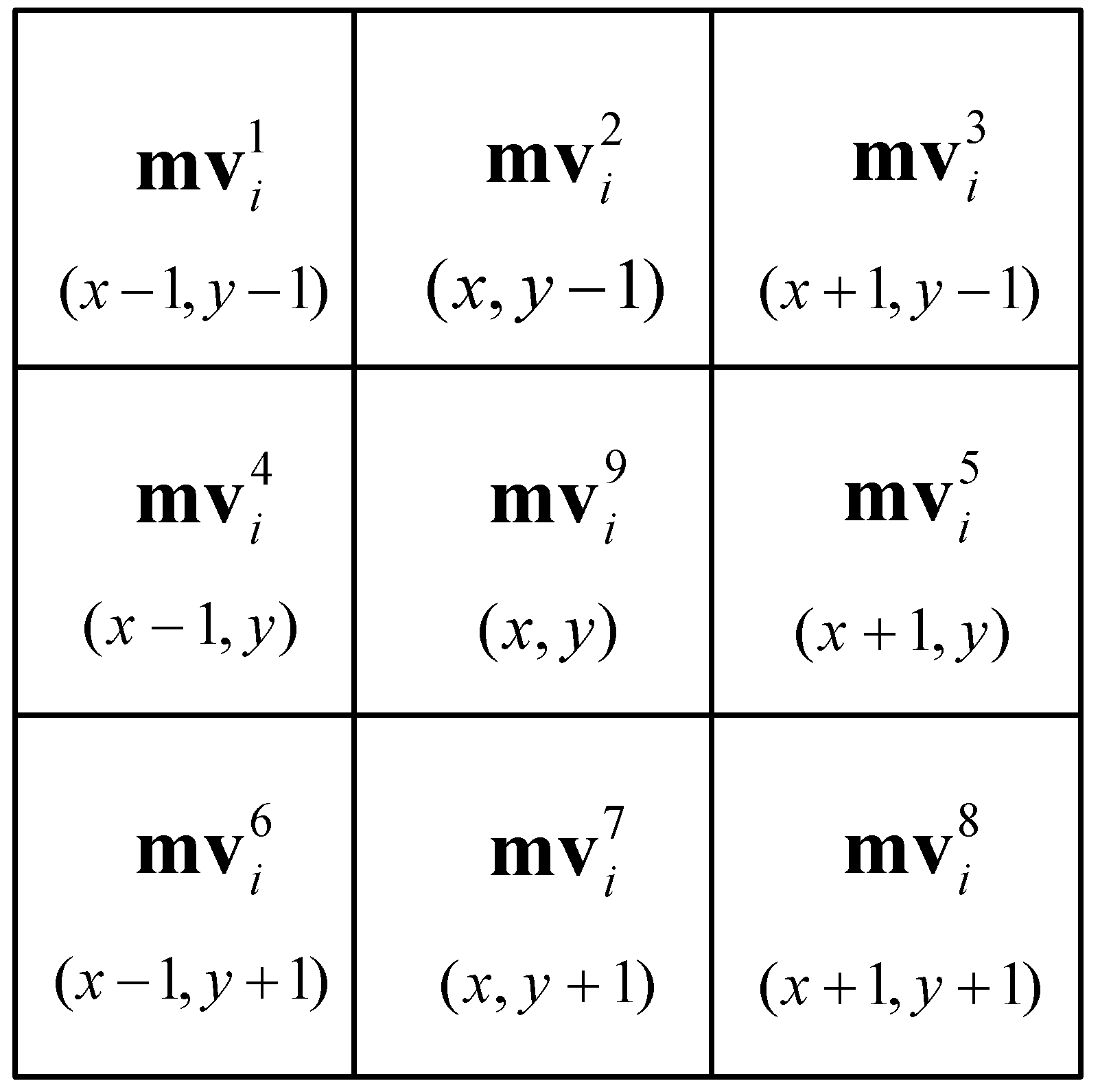{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}