1. Introduction
Modern control theory was created in the late 1960s with the development of model-based control (MBC) and optimal control techniques. MBC uses nonlinear difference (or differential) equations to describe the behavior of the dynamical system [
1]. To apply MBC, a designer first needs to obtain a mathematical model of the plant and then design the controller using this model. In the early 70s, intelligent control [
2] was developed as an alternative to traditional model-based control systems; in contrast with MBC, intelligent control uses human knowledge, operational research, and experimental evidence instead of a mathematical model to generate control actions. Fuzzy logic control has been one of the most successful intelligent control techniques from the earlier work of Mamdani [
3], to more recent applications [
4]. Another suitable method that is rapidly developing is data-driven control, which includes a broad family of techniques in which the mathematical model or the controller design is based entirely on datasets obtained directly from the process we need to control. Data-driven control includes methods such as reinforcement learning [
5]; iterative learning control (ILC) [
6]; and robust control tools such as Petersen’s Lemma [
7], together with neural networks and genetic algorithms [
8]. A critical advantage of fuzzy logic control is that it is implemented using a fuzzy inference system (FIS) that models the system’s knowledge base using fuzzy rules. Fuzzy rules have a human interpretation and can also be automatically or manually tuned; this is why we chose fuzzy controllers for this line of research. As in their model-based counterparts, designers of intelligent control systems also need to optimize the controllers’ parameters to handle the particularities of real-world problems. In the case of fuzzy controllers, several entities characterize the components of the fuzzy rule-based system. The core components are the fuzzy propositions constructing the fuzzy rules representing the knowledge of the system. Propositions are, in turn, constructed using fuzzy variables and fuzzy terms that are defined using MFs.
Optimizing the controllers’ parameters is challenging; on the one hand, we have a vast search space in the parameter’s domain. On the other, we need to execute one or more simulations to establish the performance of one configuration. These time-consuming problems make the manual tuning of parameters impractical [
9]. Engineers often use metaheuristics not only to tune or adjust the parameters of fuzzy controllers but also to define the entire fuzzy controller structure. Metaheuristics often use techniques inspired by natural processes. For instance, the operators used by genetic algorithms (GAs) [
10] are inspired by natural evolution. Using a chromosome to represent a candidate solution, the operators to generate a new population are a random crossover between individuals, a random mutation applied to the offspring, and a selection operator to decide which individuals will survive to the next generation. In this case, the crossover and selection operators impact how the search space is exploited, while the mutation operator influences the exploration of the search space near a promising solution. Evolutionary algorithms are not the only nature-inspired metaheuristic used in this area; other nature-inspired algorithms have been successfully employed in optimizing fuzzy inference systems for engineering and process control applications. These algorithms include both evolutionary algorithms (EAs) [
11] and swarm intelligence (SI) [
12]. Most researchers follow a fuzzy-evolutionary approach to optimize the parameters of fuzzy controllers [
9,
13].
In previous work [
14], we established that tuning the MFs of fuzzy controllers using population-based metaheuristics demands the extensive use of computational resources. This demand stems from establishing the fitness of all candidate solutions, which requires running several simulations [
15,
16] for each candidate; this is a problem inherent to population-based algorithms. However, because evolutionary algorithms evaluate candidate solutions in isolation; they are a perfect match for their parallel execution. In the literature, we found only a few studies attempting to distribute fuzzy controllers’ optimization; however, these studies did not consider or take advantage of recent cloud-native technologies [
17,
18,
19]. Cloud-native applications are designed as a composition of loosely coupled microservices, stateless processing nodes that react to events [
20] produced by other microservices, scheduled or triggered by clients. Microservices typically run in isolated runtime environments called containers, which encapsulate not only the runtime environment, but also software libraries; binaries; configuration files; and in general, everything needed for the node to run autonomously. A containerized application is easily operated on automation platforms capable of taking containerized microservice-based applications from a local computer to be deployed in a cloud or a disposable infrastructure [
21,
22]. An important design principle is the use of an event-driven architecture in which microservices communicate asynchronously by emitting and reacting to events; this is often realized via message queues or external messaging services.
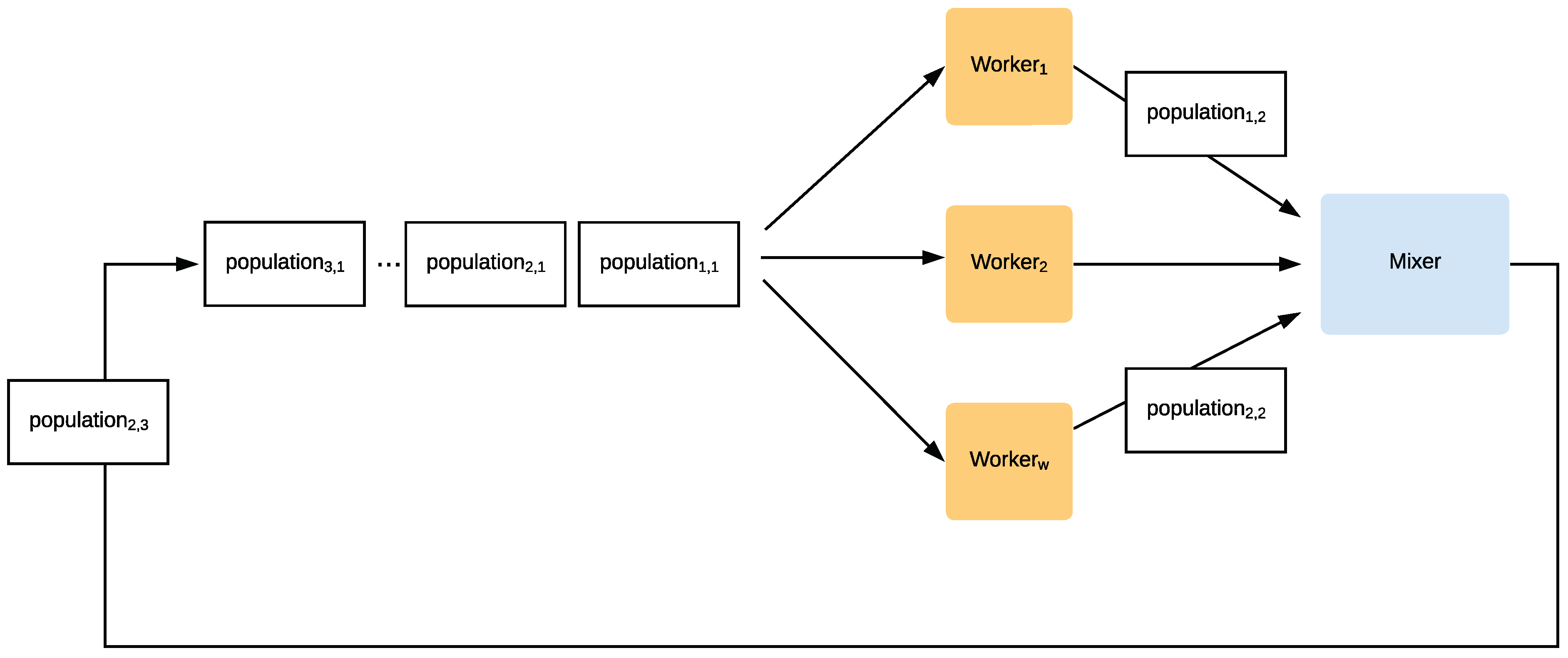
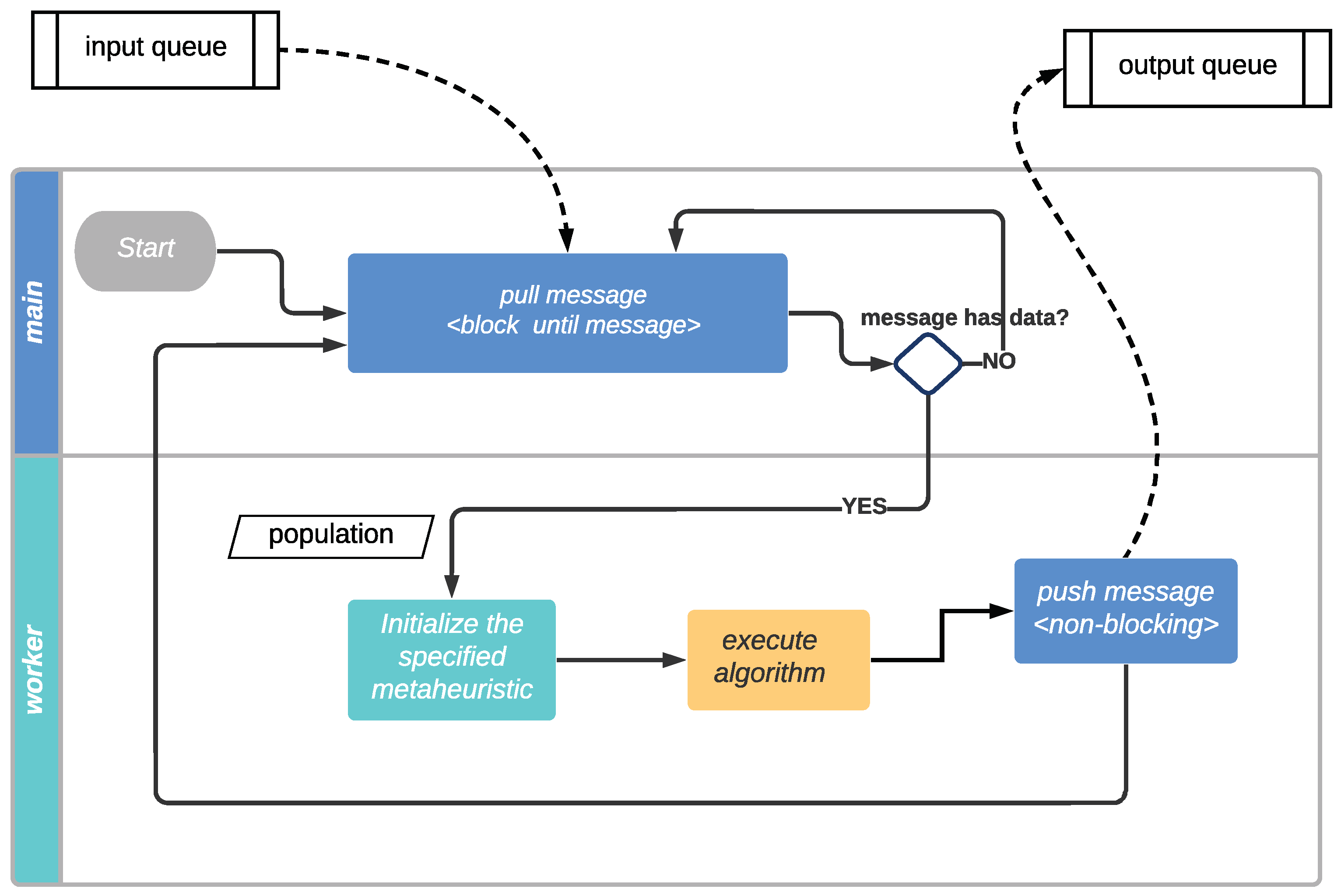
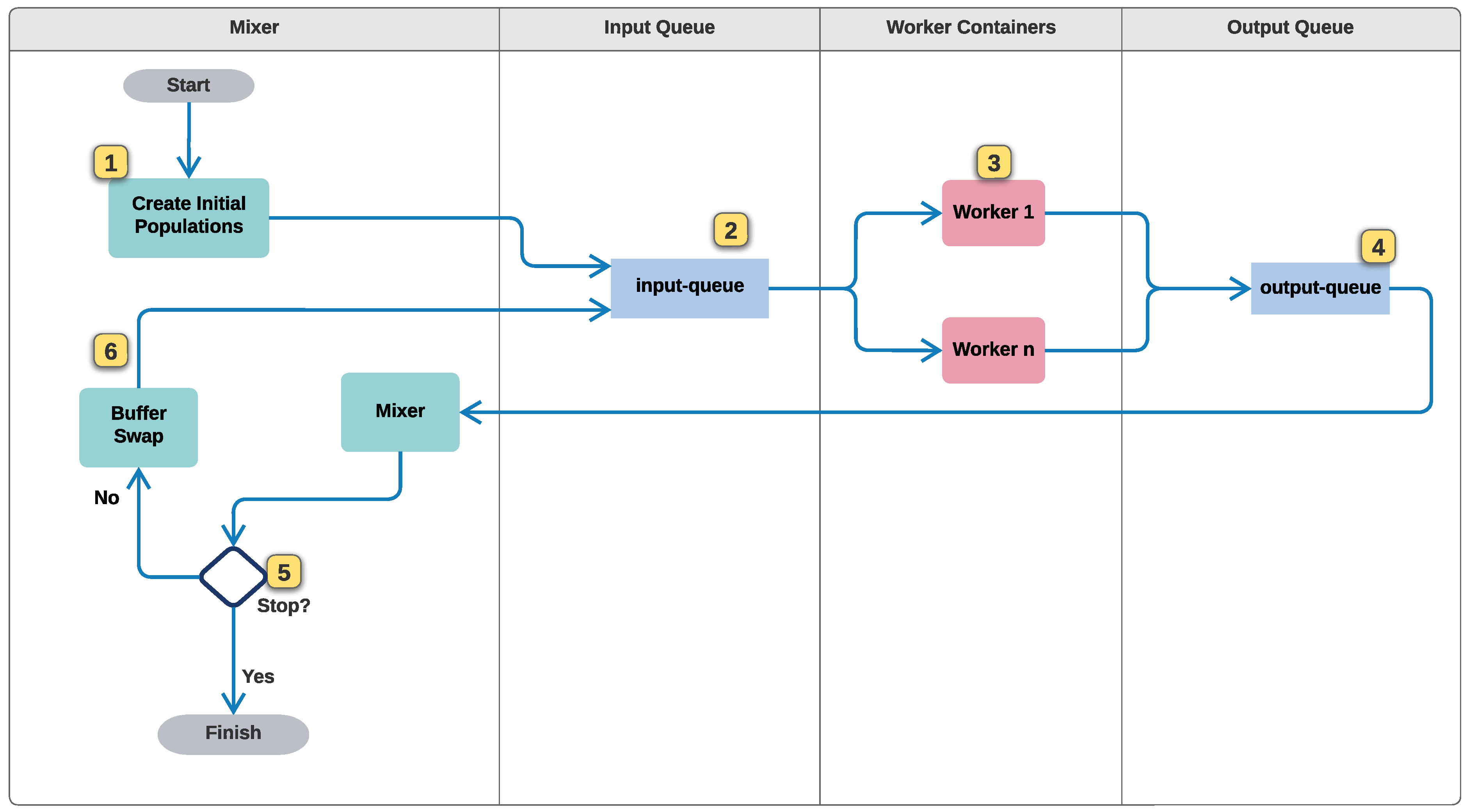
Our main contribution in this paper is a proposal of a distributed optimization method that speeds up the tuning of fuzzy control optimization problems with respect to sequential versions, without increasing the complexity for the user. This work proposes a multi-population, distributed optimization method considering current practices in constructing highly scalable, resilient, and replicable systems. Moreover, the architecture is capable of executing several bio-inspired algorithms simultaneously. In particular, we apply cloud-native principles and techniques [
23] to implement a system capable of executing a multi-worker, multi-population, multi-algorithm optimization framework to speed up the time needed to execute the evolutionary fuzzy controller design algorithm. To demonstrate the applicability and speedup provided by the proposed method, we report an experimental case study of optimizing a fuzzy controller for trajectory tracking. This particular problem required a considerable execution time in our previous work, and we expect to reduce this time considerably by applying the proposed method by distributing the work. Furthermore, this work addresses the problem of setting the parameters for each population; this is an important factor in multi-populations algorithms because it has been found in other work to have an impact on the execution time and the optimization results [
24,
25]. In this work, we compare two strategies: the homogeneous setting using the same parameters in all populations and a heterogeneous strategy using distinct parameters for all populations.
In summary, we solve a fuzzy control problem by using a cloud-native distributed algorithm with few tunable parameters that has been enhanced with respect to the previous version by improving the selection procedures. In this paper, we try to prove that it effectively lowers costs by being able to find the solution in less time, and in which circumstances this solution can be better than sequential alternatives.
We organize the paper as follows: In
Section 2, we present the state-of-the-art of distributed multi-population-based algorithms. In
Section 3, we describe the method and the experimental setup in
Section 4. The results of the experiments are presented in
Section 5, and finally, in
Section 6, we discuss the conclusions and future research directions.
2. State of the Art
Most of the lines of research we mentioned above emphasize parallelizing the evaluation of candidate solutions because this is the most resource-demanding part of the optimization algorithm. Alba and Tomassini [
26] called this type of implementation
global parallelization because, in this case, the population keeps the same panmictic-like properties found in a single global population, in which any individual can potentially mate with any other in the population. Only the fitness evaluation is carried out in parallel, following a standard primary/subordinate design. On the other hand, we have the multi-population or island models, in which the original population is partitioned into several demes or subpopulations that can run an isolated GA algorithm in parallel. Migration is an essential element of these parallel algorithms because it significantly affects how fast the solution is found. Migration describes how often and which individuals will be exchanged between populations. These earlier multi-population methods not only had the advantage of speeding the execution time but also, according to experimental results, added the benefit of preventing premature convergence to a local optimum by maintaining a higher diversity throughout the populations [
27]. Furthermore, Starkweather et al. [
24] concluded that distributed genetic algorithms are often superior to their single population counterparts, but this is only sometimes true; they compared different migration techniques and their relationship with performance.
Other population-based metaheuristics also have multi-population versions. For instance, there are many proposals on multi-swarm optimization methods [
25] for the PSO algorithm; however, because the PSO algorithm is based on position, velocity, and distance between particles, researchers put more effort into the topology of communication between swarms. Using multiple populations also allows for establishing different configurations in each population, changing the parameters affecting exploration and exploitation to balance the emphasis between both strategies. This subject has also been explored extensively by researchers in this area. By having multiple populations, there is even the possibility of having entirely different metaheuristics in each population; recent work showed that this can also benefit the overall results [
28,
29]. Another critical factor in multi-population-based algorithms is the coordination between the nodes executing the algorithms in parallel. Researchers in PGAs have implemented both synchronous and asynchronous parallelization. An example of synchronous parallelization is the controller/worker model, in which the controller must wait for all workers to finish before continuing the execution. In contrast, asynchronous parallelization does not need to wait for other processed to continue working because work is not synchronized; this improves the scalability and reduces the execution time. In the literature, many studies compare the two methods, but in terms of speed of execution, asynchronous algorithms are the best option. Another advantage of asynchronous solutions is that they facilitate the communication of autonomous cooperating entities, as shown in work such as A-Teams [
30], in which agents solve problems by modifying a shared memory without needing to know about each other or a coordination entity.
From early research on PGAs, many studies focused on the implementation details impacting the system’s performance. In this regard, current work emphasizes the exploitation of the most recent advances in computer technologies, for instance, the massive quantities of processing units found in modern GPUs [
31]. However, arguably, the most significant paradigm shift has recently come from the emergence of the cloud platform. Parallel evolutionary algorithms leverage commercial, and even free, cloud services to deploy implementations [
32]. A pioneering proposal was made by Veeramachaneni et al. [
33] with a native cloud genetic programming framework called FlexGP. This system not only worked on the cloud (using Amazon Elastic Compute Cloud, a virtual machine service) but also tackled the different challenges in distributed computing in a novel way; in the same way as in our algorithm, every virtual machine used different algorithm parameters (and sampled the training data differently); however, they revealed in their paper the challenge of booting virtual machines on the cloud.
Cloud-native architectures soon evolved to use computing nodes for which the startup time and the overall cost were more lightweight and used isolated, “containerized”, operating system images; these were initially called by the same name as the company that proposed them, Docker, but are now an open standard supervised by the Open Computing Initiative. These container-based architectures are nowadays mainstream [
34]; from the point of view of scientific computing, they enable replicability by not fully defining the infrastructure in which the experiment can run, thus creating “frozen” workflows that can be directly reused in new experiments on-premises, in paid infrastructure and even on your laptop. These methodologies and technologies eventually landed in the evolutionary computing field via the work published by Salza and Ferrucci [
35]. Their main challenge was reducing overhead, which is achieved via the containerization of the fitness evaluation tasks; this speeds up the evolutionary algorithm by reducing node startup overhead and communication overhead, since the virtual network interfaces that the container possesses are much faster than whole virtual machines; latency is also expected to be lower.
All these attempts just adapt new infrastructure to old computation models; they could be implemented in a local setup if resources were available. However, cloud-native architectures go beyond that, offering new programming and communication paradigms; its full use yields a high-performance architecture that is, at the same time, cheaper since they use fewer resources. Our KafkEO [
36] and EvoSwarm model [
37] follow an event-driven architecture, and instead of having a central node to execute the genetic algorithm, delegating only the fitness evaluation to subordinate nodes as Salza and Ferrucci do, workers evolve subpopulations for several generations.
A more recent work by Ivanovic and Simic [
38] centers on auto-scaling the number of microservices, considering the specifics of evolutionary algorithms. Increasing or reducing the number of workers as needed, for instance, increasing when the population needs to be evaluated or when a simulation will demand more resources. The aim is to reduce the overall computational cost. This work uses a primary/subordinate parallel execution with an event-driven architecture using the Kubernetes orchestration technology. A similar approach is followed by Dziurzanski et al. [
34], also using Kubernetes and an auto-scaler but implementing an island model using a multi-objective genetic algorithm. Two real-world smart factory optimization scenarios are used as test cases, and the system is deployed on a Kubernetes cluster. This work follows a novel approach proposed by Arellano-Verdejo et al. [
39], in which islands evolve, but there is no migration between them. When the entropy value of a pair of populations maximizes the diversity of the resulting island, these populations are merged into one, and the best-fitted individuals survive.
Instead of relying on message passing, some other proposed cloud native evolutionary algorithms use a pool-based approach [
40]. In pool-based algorithms, isolated algorithms exchange candidate solutions through a shared pool, where they put and take solutions asynchronously. Examples of these algorithms are the SofEA [
41], and EvoSpace [
42] models. These implementations use the scalable storage services CouchDB and Redis, respectively. EvoSpace has a cloud-based implementation [
43] and another version called evospace-js [
44] using web technologies, the server (controller node) is implemented in node.js, and the workers run in Docker containers.
In this work, we propose an EvoSwarm-inspired algorithm applied to a simulation-based controller optimization problem that is both demanding in computational resources and more representative of a real-world problem. In the next section, we describe the proposed algorithm and implementation details.
Table 1 gives a comparison of the key properties of the present work and related published work on cloud-native optimization methods.
5. Results
In this section, we present the results of the experiments, comparing a sequential and distributed implementation of the controller described in the previous sections, with the average RMSE of three paths to establish the fitness. First, we show the results regarding the RMSE obtained by the optimized controllers, and then, we center our attention on the time it took the experiments to complete.
5.1. RMSE
The RMSE results of several configurations are shown in
Table 8. In the first two columns, we show the results of the sequential algorithms as published in our previous work [
14]. We can see that the PSO algorithm obtained the best results overall, with a median RMSE of
0.00536160, the second-best result is the distributed heterogeneous version of the PSO-GA with a median of
0.00610783; this result is very close to the multi-algorithm version PSO with an RMSE of 0.00628949. After performing a statistical z-test between the distributed and sequential versions of the same algorithms, we did not find enough evidence to reject
with
. These results indicate that the results from the distributed and sequential versions are about the same, and the random parametrization of the multi-population version could be used, even having marginal benefits over the homogeneous version, without the need to find appropriate values for the parameters.
5.2. Execution Time Speedup
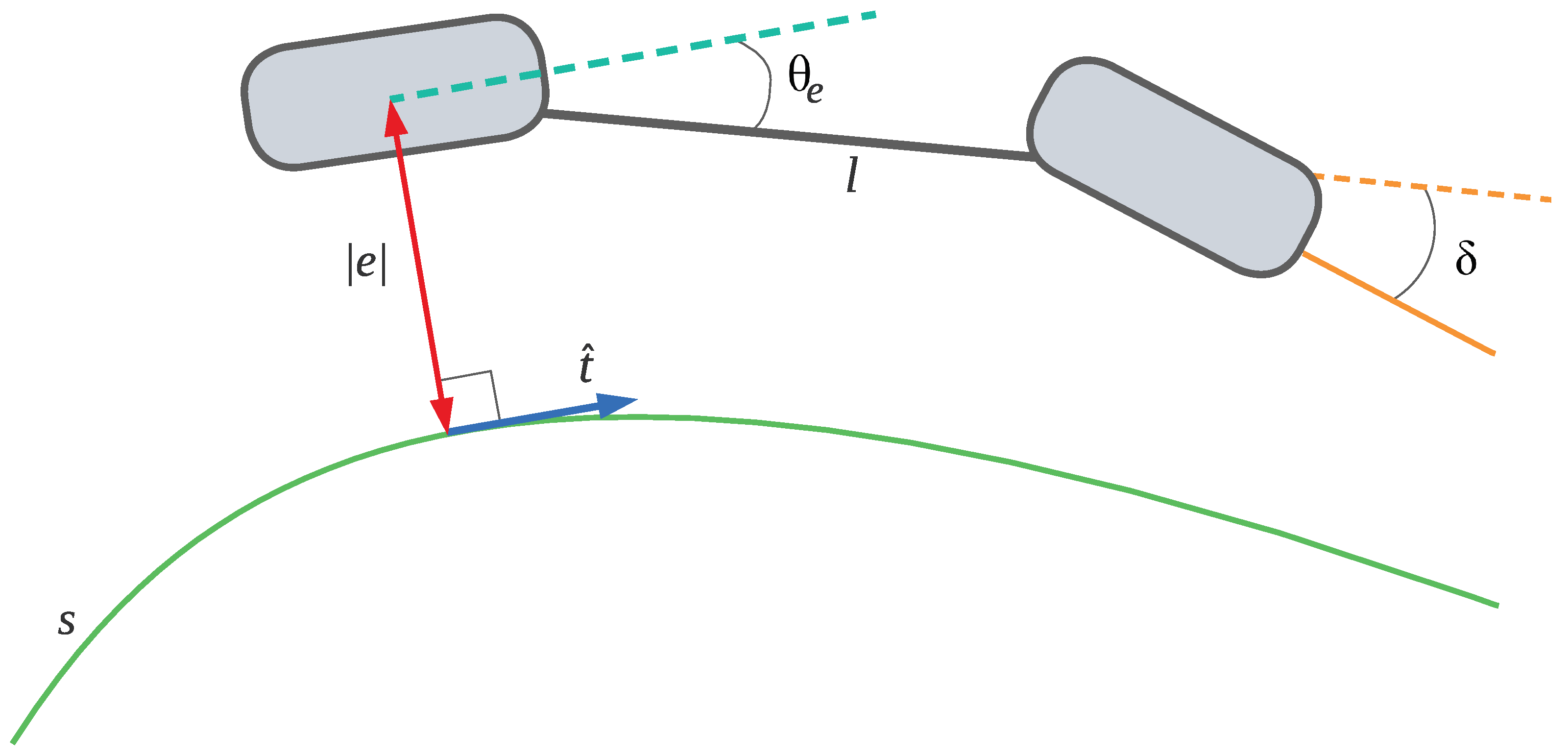
The complexity of the optimization process depends mainly on the cost of each simulation step. However, the cost depends on a multistep differential solver, the number of iterations of which changes depending on the initial conditions. Furthermore, there is also the added cost of obtaining the nearest point to the path in each step, as described in
Section 4.1. On the other hand, the population-based algorithms implemented follow the same procedure: initialize the population with
complexity, where
n is the size of the population. Then, there is the step of creating or updating a new population; this is normally
with
m iterations and
l parameters. Since this kind of metaheuristics does not have a deterministic number of steps to find a satisfactory solution, it is impossible to compute the computational complexity and, thus, compare algorithms on this basis. We will need to compare them experimentally. The observed execution times of sequential and multi-population configurations of the algorithms are shown in
Table 9. The table shows execution times in seconds and the speedup against the sequential alternative in subscripts. In the case of the PSO-GA combined version, we used the execution time of the sequential PSO algorithm as the base. In the first two columns, we have the base times of the sequential GA and PSO versions. We notice that the GA completes the execution in less time than the PSO algorithm, but as the results in the previous section show, the RMSE results are worse. On the left side of
Table 8, we present the execution times of both the homogeneous and heterogeneous alternatives. As expected, there is a speedup of around six times in the distributed PSO versions; this is not the case for the GA, reaching five times only on the heterogeneous distributed configuration. The PSO-GA heterogeneous variant gave the best speedup on average; this is an interesting result because it gives better results than the homogeneous PSO-GA configuration.
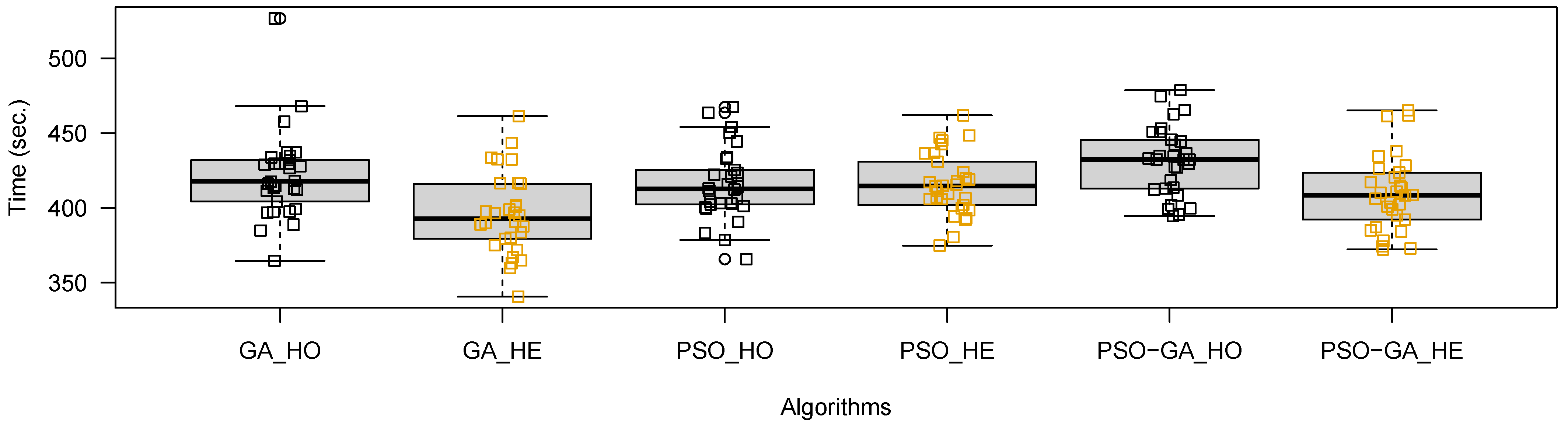
Figure 6 shows the boxplot of the execution times: the noticeable differences between the GA (
p = 0.000171) and PSO-GA (
p = 0.000264), are confirmed with a z-test (n = 30,
, independent samples); this was not the case for the PSO (
p = 0.5104).
These results confirm that a multi-population-based strategy offers a convenient speedup while keeping the results very similar to their sequential counterparts. Moreover, the combined algorithm offers better execution times, combining the continuous optimization capabilities of a PSO algorithm with the faster GA metaheuristic. Moreover, the randomized configuration parameters heterogeneous strategy gave better execution times when using the PSO-GA variant.
Finally, these experiments also exemplify the type of fuzzy controller optimizations we can perform and the speedup performance we can achieve with an implementation following an event-based architectural pattern. Another advantage of this pattern is that other researchers can replicate the experiments using a standard Docker deployment under the same software conditions. The containerized implementation could even be executed in a cloud environment from the same code base and Docker scripts, allowing the scalability options of more powerful virtual machines.
5.3. Discussion
From these experiments, we gather some insights into the problem and the algorithmic framework we have created to solve it. The sequential PSO algorithm is consistently beating all the other combinations from the algorithmic performance perspective, as seen in
Table 8. However, the combined, heterogeneous, distributed PSO-GA offers the second-best performance, and also the lowest worst-case result. This means that if we are looking for a framework that in a single shot offers the best guarantee to succeed, the PSO-GA is probably the best, offering a worst-case result that is better than the median in many other cases (for instance, anyone that involves only a genetic algorithm).
Although the evolutionary algorithm is worse than the PSO in every setup, combining them is consistently better than any of them; combining the different exploitation/exploration capabilities of both seems to balance their shortcomings in that area. Looking at
Table 9, however, reveals that this last combination obtains a very good median and average time to solution, with a 75% speedup over the sequential algorithm.
This leads us to conclude that the algorithm proposed in this paper is the best alternative if you want to obtain consistently good solutions in a very short amount of time, proving the value of the cloud-native design as well as the choices made in the population combination operators.
6. Conclusions
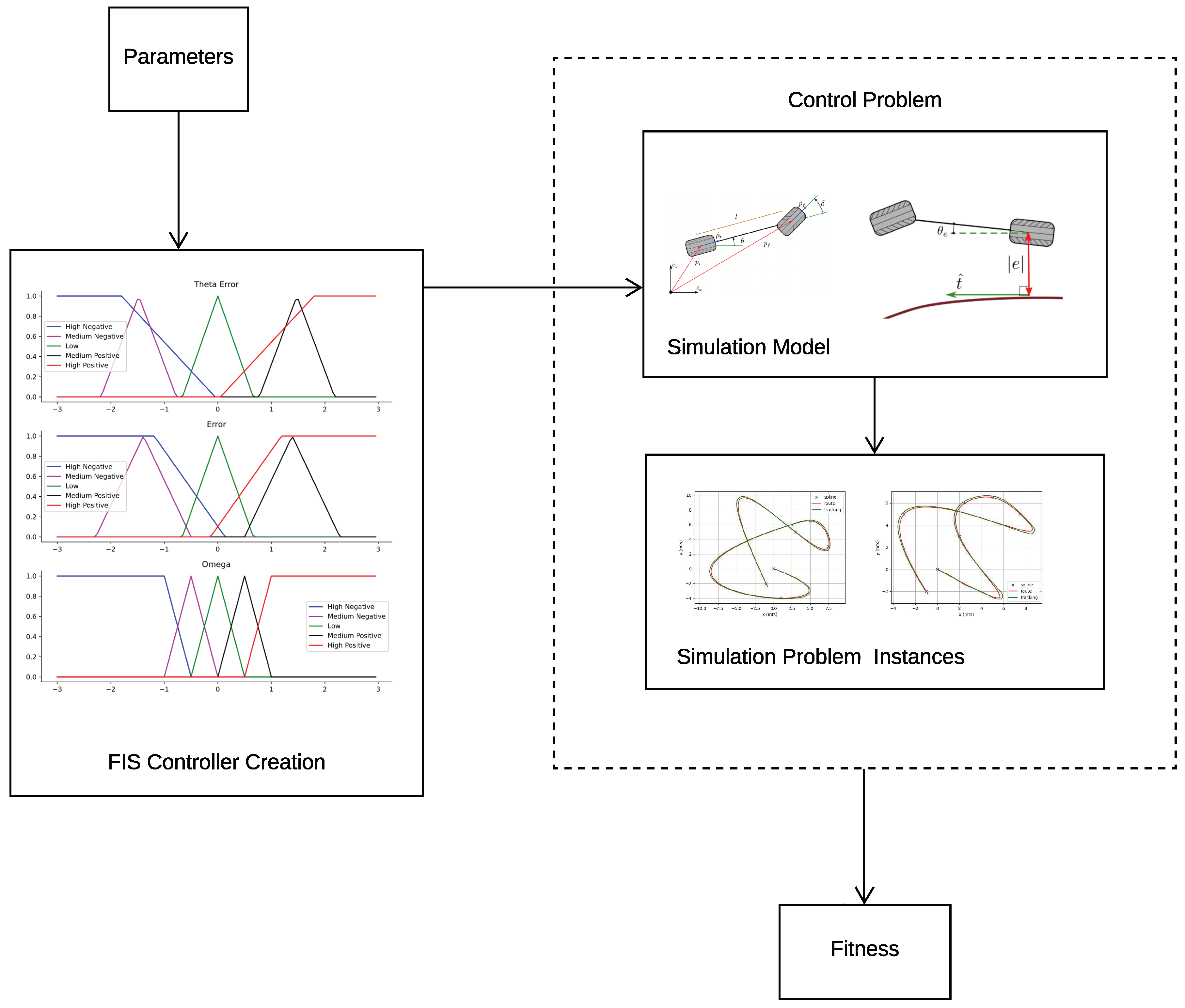
This paper presented a distributed, multi-population-based algorithm for fuzzy controller optimization. The implementation follows an event-based, cloud-native architectural pattern suitable for workstation or cloud platform deployment. We used industry-standard, open-source development tools and libraries, with Docker and docker-compose for container deployment and the Python language to develop a simulation and fuzzy controller environment. The code can be modified to add more control problems or metaheuristics. The algorithm is based on message queues for the asynchronous exchange of messages encoding populations of candidate solutions. The mixer component adds a buffer-based strategy for exchanging promising candidate solutions between populations. We propose the use of Docker containers as workers for the isolated execution of metaheuristics, similar to the island model. In this paper, we compared two multi-population versions using PSO, GA, and a combination of the two metaheuristics. As a case study, we used the proposed algorithm to optimize the parameters of the MFs of a fuzzy controller. The controller is applied to the autonomous path tracking using rear-wheel feedback. We optimized the controller using simulations to validate each candidate’s configuration; this was carried out by following three distinct paths and measuring the average RMSE.
We have performed an empirical evaluation of two multi-population configuration techniques. One configuration is based on a homogeneous configuration, using a set of parameters found experimentally. We also evaluated a heterogeneous configuration obtained by randomly initializing the parameters of each subpopulation. We found that the configuration strategy we chose significantly influences the execution time in some cases. We conclude that using the heterogeneous strategy on the combined PSO-GA improves the execution time. The results also show no statistical difference between the sequential and multi-population-based implementation of the algorithm, while there is a proportional speedup on the multi-population implementation. The distributed PSO version achieved better speedup than the distributed GA alternative, which could be explained because the GA has a lower execution time.
Having a multi-population algorithm opens many lines for further exploration. One possibility is to give each subpopulation different problem configurations, for instance, different simulation problems. Some populations could have paths with more difficulty or a shorter distance, while others have less complicated problems. Another option is using a multi-objective control problem, using other performance metrics, and having populations optimizing distinct objective functions. On the implementation side, a complete study of the speedup must include a different number of worker containers to see if the speedup scales with the number of workers/populations.
There are also different areas of application of this algorithm; in principle, metaheuristics such as the one proposed in this paper can be applied to any monomodal optimization problem where the fitness function can be formulated analytically. In this paper, we have proved that it can successfully be applied to fuzzy-based systems, since it can evolve them successfully and in a reasonable amount of time. This fact opens the possibility of applying it to relatively complicated problems to bring down the time required to obtain a solution by (roughly) an order of magnitude or, in a cloud environment, to reduce its cost; this will make this kind of system affordable to small and medium-sized enterprises who will be able to leverage it to add value to their portfolio. Since fuzzy controllers are used extensively on the Internet of Things [
52], this could be an excellent area of application. This is left, however, as future work.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}