
Innovative Dual-Stage Blind Noise Reduction in Real-World Images Using Multi-Scale Convolutions and Dual Attention Mechanisms



Abstract
:1. Introduction
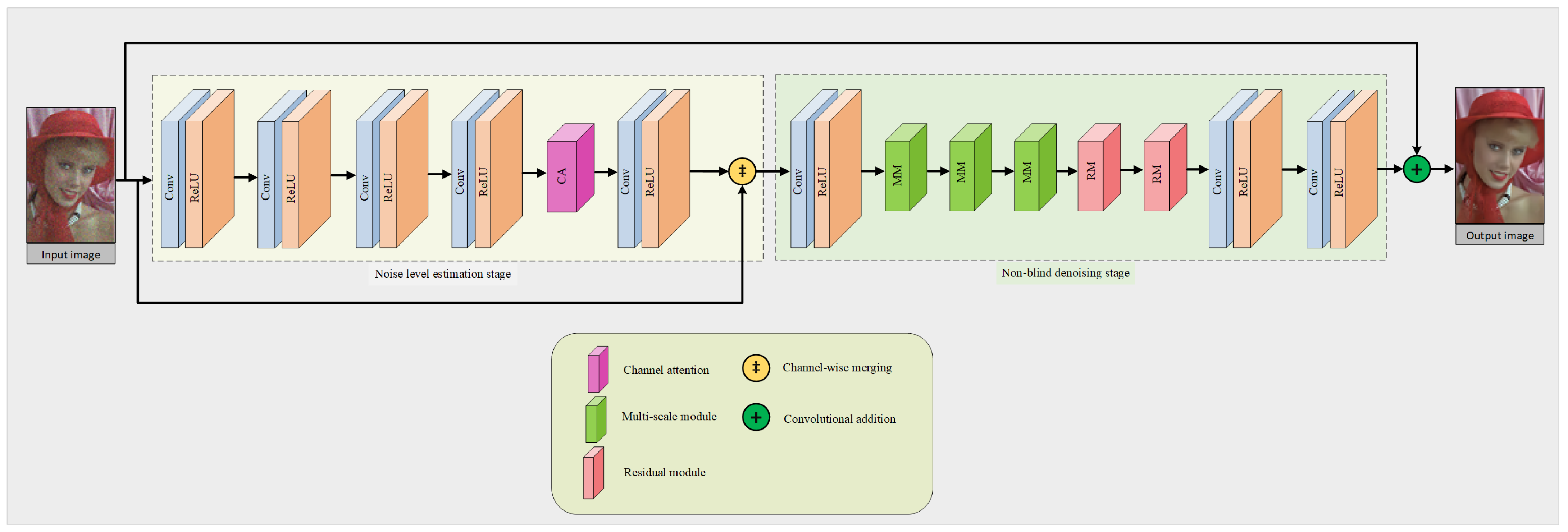
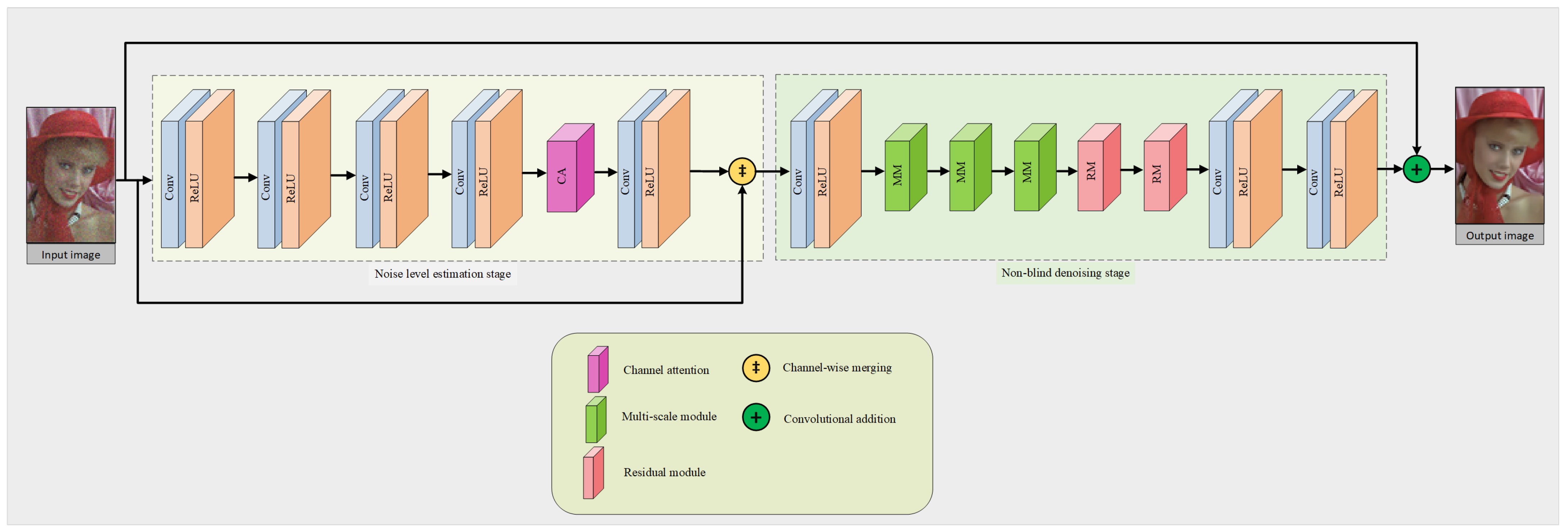
- We present a two-stage denoising network that is explicitly designed for denoising images captured in real-world scenarios. The first stage focuses on accurate noise level estimation, while the second stage performs targeted, non-blind denoising.
- We adopted a comprehensive approach that combined channel and spatial attention, thus leading to a new dual attention module. This module filters out less important information, thereby allowing essential data to be processed and conveyed with greater accuracy.
- Our design includes a specially crafted module that can extract features at multiple scales. This adaptability lets us tailor the network for various real-world scenarios by adjusting the quantities of these modules, thus balancing denoising efficiency with reduced network complexity.
- Based on our analysis of 16 benchmark datasets and using two metrics, when compared with over 20 traditional and contemporary algorithms, our proposed method proves to be both robust and adaptable. Furthermore, it quickly adjusts noise-degraded images and is suitable for a wide range of vision-based applications.
2. Related Work
2.1. Traditional Denoising Algorithms
2.2. Advances in Deep Learning-Based Denoising Algorithms
3. Theoretical Foundation
4. Algorithmic Framework
4.1. Dataset Pre-Processing
4.1.1. Training Datasets
4.1.2. Test Datasets
4.2. Quality Metrics
4.3. Phase of Noise Level Estimation in Image Data
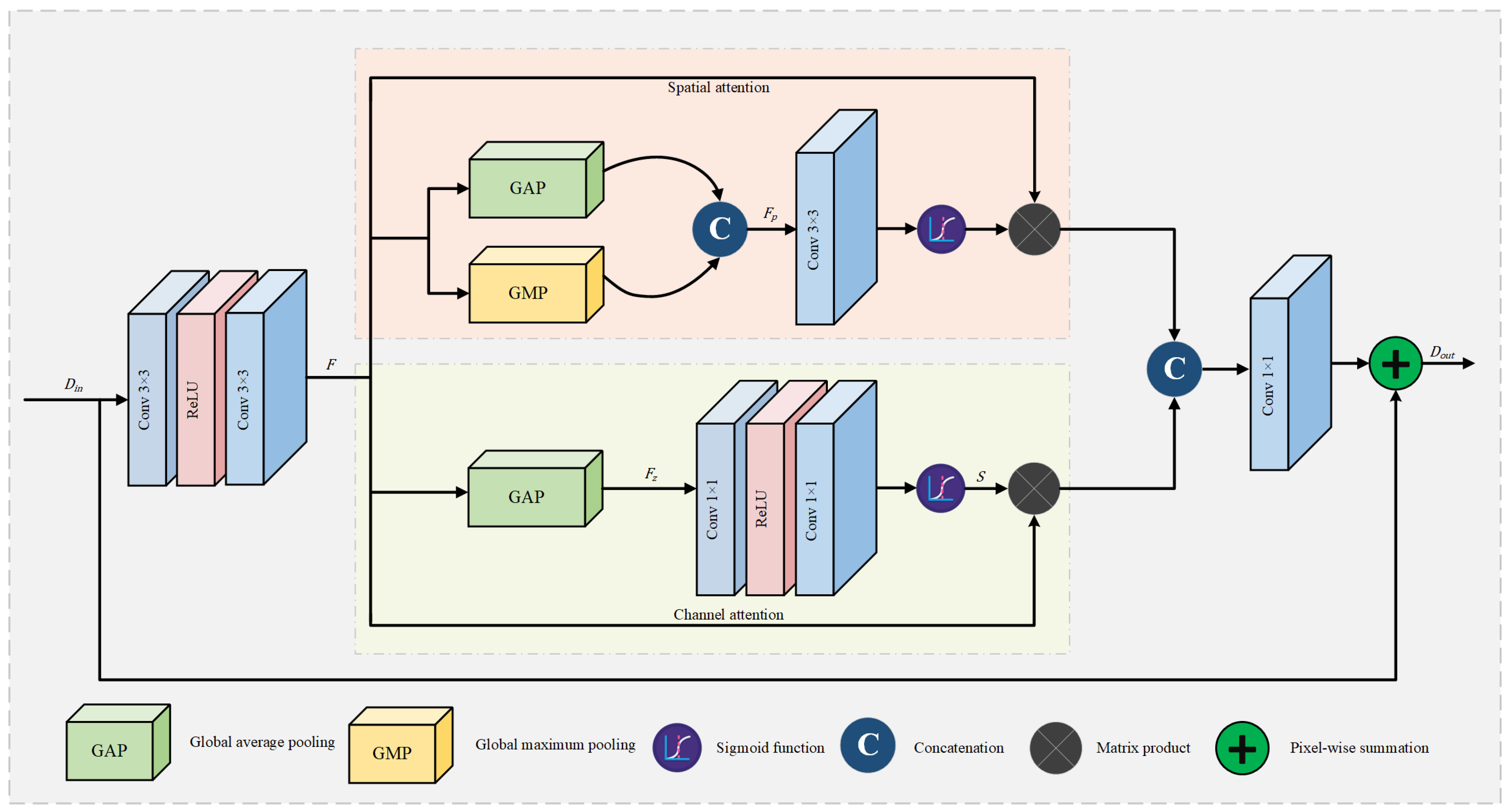
4.3.1. Dual Attention Mechanism
4.3.2. Channel Attention (CA)
4.3.3. Spatial Attention (SA)
4.4. Non-Blind Denoising Stage
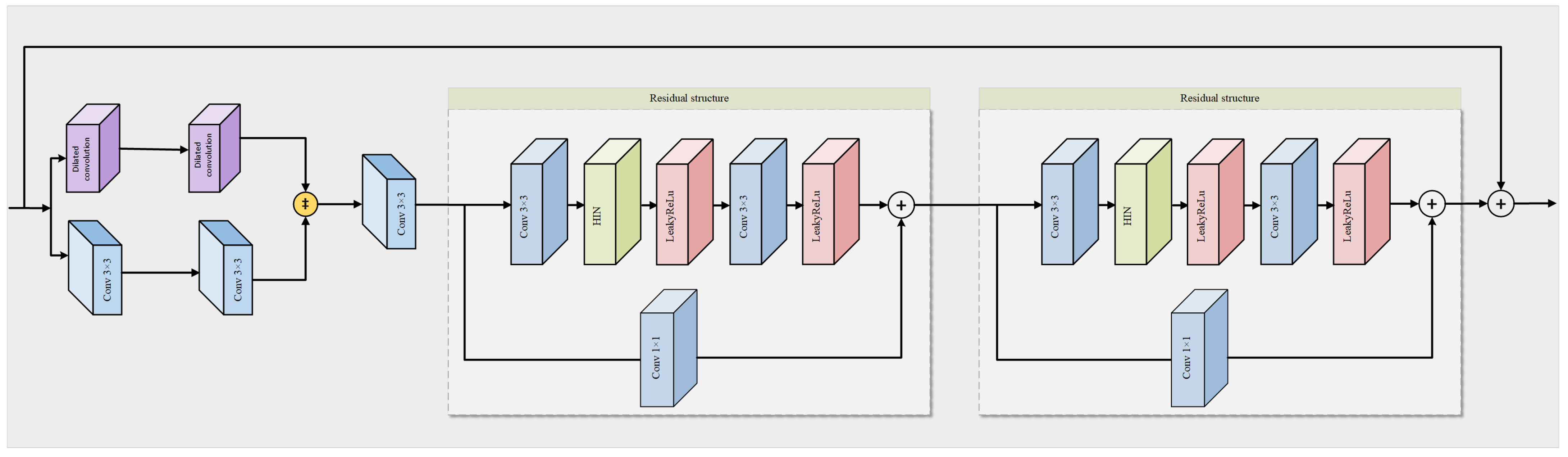
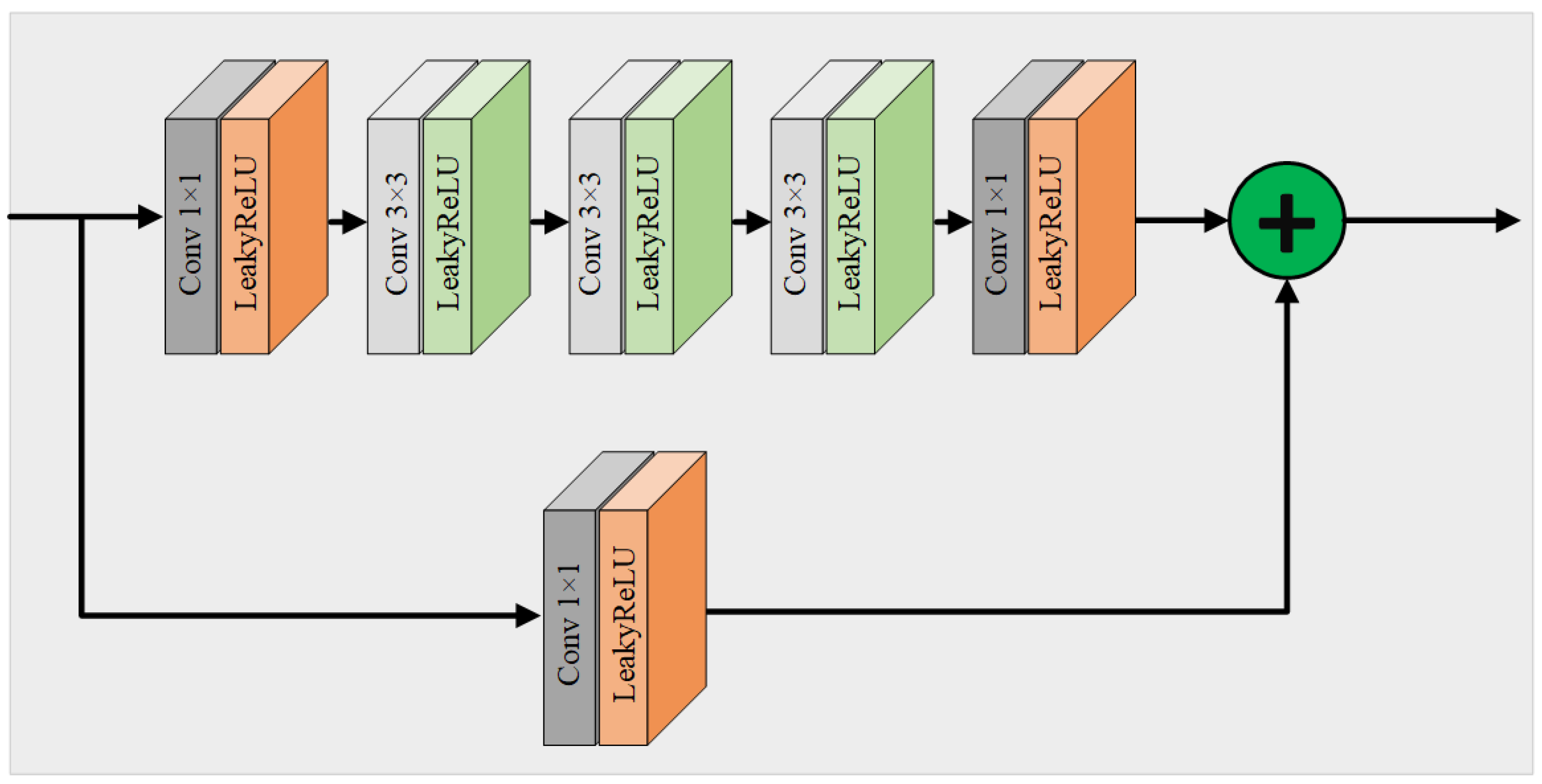
4.4.1. Multi-Scale Denoising Module Architecture
4.4.2. Residual Structure
4.4.3. Loss Function Selection: A Case for L1 Loss
5. Experimental Results
5.1. Implementation Details
- Training Duration: The model was trained extensively over a span of 4000 epochs. This duration was determined based on the convergence behavior observed during preliminary runs.
- Learning Rate Adaptation: An initial learning rate of was set for the first 1500 epochs. Post this, to ensure finer weight updates and to stabilize convergence, the learning rate was decayed by a factor of one-tenth every subsequent 1000 epochs.
- Hardware: We relied on the robust NVIDIA GTX 2080ti GPU, which ensured efficient parallel processing and reduced training times.
- Software Framework: All neural network components, including layers, optimizers, and loss functions, were implemented using the PyTorch framework, which provided flexibility and ease of experimentation.
5.2. Qualitative and Quantitative Assessment
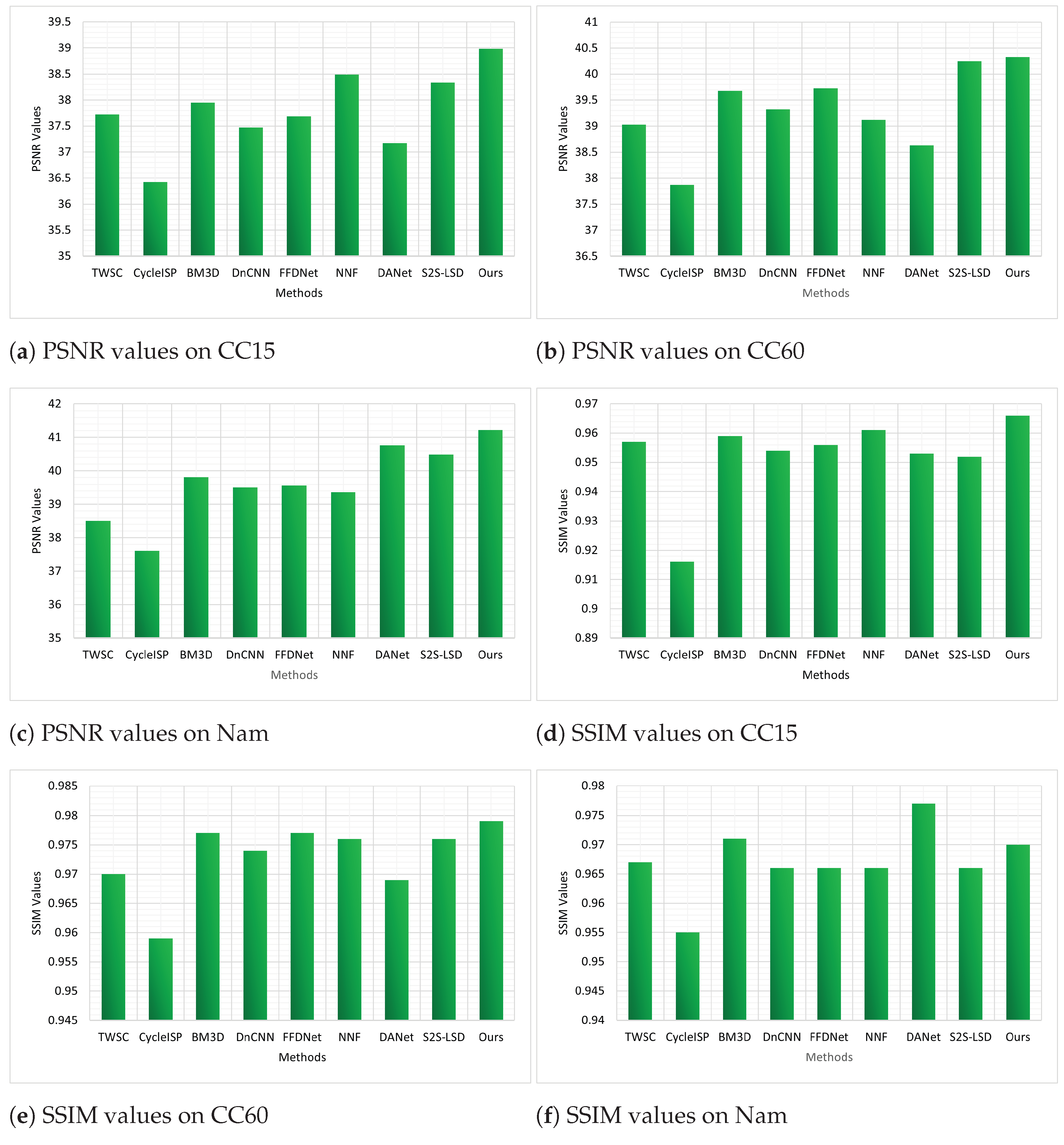
5.2.1. Denoising Color Images
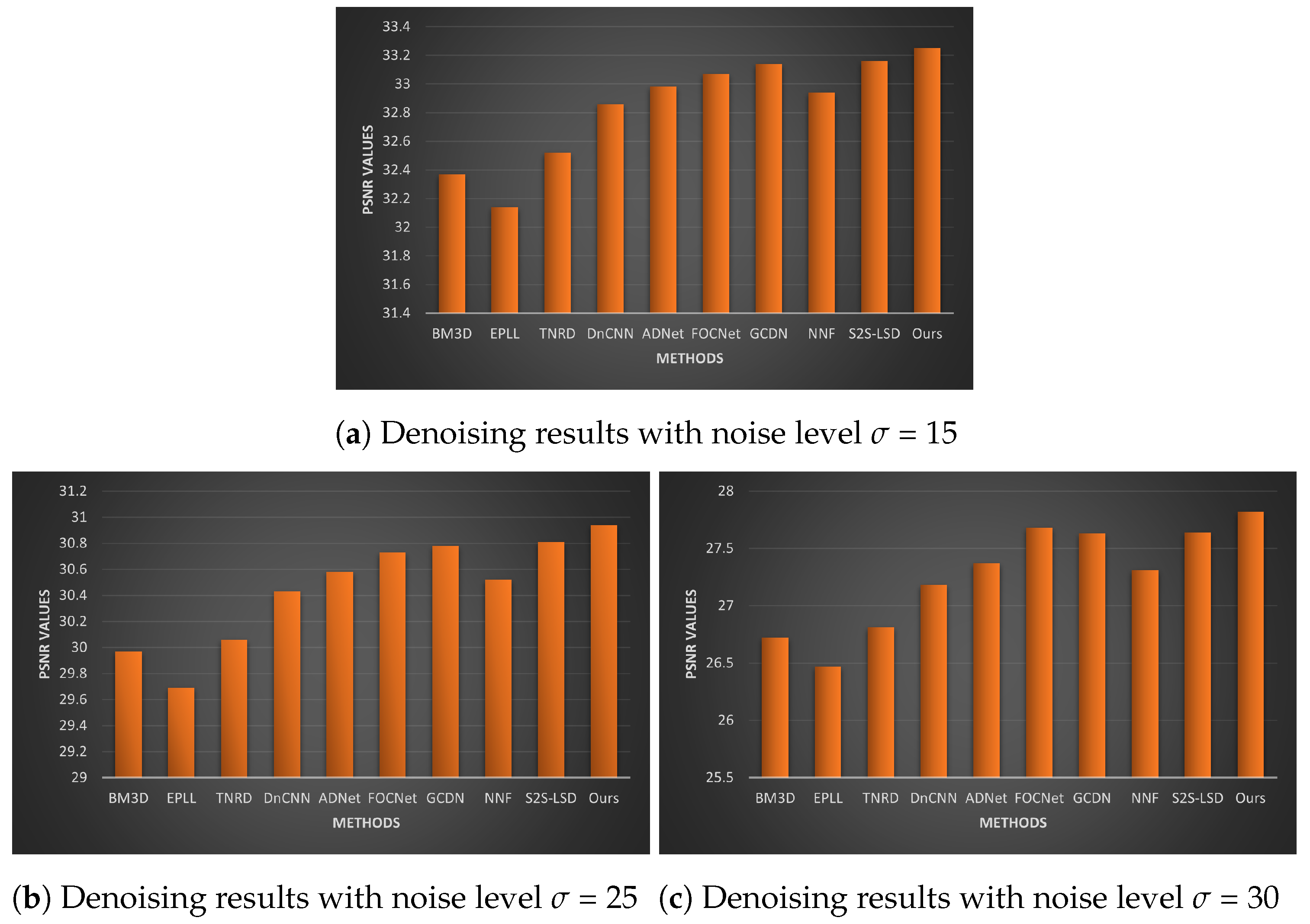
5.2.2. Denoising Grayscale Images
5.3. Computational Complexity
6. Discussion
Concluding Remarks
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Elad, M.; Kawar, B.; Vaksman, G. Image denoising: The deep learning revolution and beyond—A survey paper. SIAM J. Imaging Sci. 2023, 16, 1594–1654. [Google Scholar] [CrossRef]
- Zhou, L.; Zhou, D.; Yang, H.; Yang, S. Multi-scale network toward real-world image denoising. Int. J. Mach. Learn. Cybern. 2023, 14, 1205–1216. [Google Scholar] [CrossRef]
- Xu, S.; Chen, X.; Tang, Y.; Jiang, S.; Cheng, X.; Xiao, N. Learning from multiple instances: A two-stage unsupervised image denoising framework based on deep image prior. Appl. Sci. 2022, 12, 10767. [Google Scholar] [CrossRef]
- Budhiraja, S.; Goyal, B.; Dogra, A.; Agrawal, S. An efficient image denoising scheme for higher noise levels using spatial domain filters. Biomed. Pharmacol. J. 2018, 11, 625–634. [Google Scholar]
- Li, Z.; Liu, H.; Cheng, L.; Jia, X. Image denoising algorithm based on gradient domain guided filtering and NSST. IEEE Access 2023, 11, 11923–11933. [Google Scholar] [CrossRef]
- Abuturab, M.R.; Alfalou, A. Multiple color image fusion, compression, and encryption using compressive sensing, chaotic-biometric keys, and optical fractional Fourier transform. Opt. Laser Technol. 2022, 151, 108071. [Google Scholar] [CrossRef]
- Xu, H.; Jia, X.; Cheng, L.; Huang, H. Affine non-local Bayesian image denoising algorithm. Vis. Comput. 2023, 39, 99–118. [Google Scholar] [CrossRef]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef]
- Chen, F.; Huang, M.; Ma, Z.; Li, Y.; Huang, Q. An iterative weighted-mean filter for removal of high-density salt-and-pepper noise. Symmetry 2020, 12, 1990. [Google Scholar] [CrossRef]
- Lai, R.; Mo, Y.; Liu, Z.; Guan, J. Local and nonlocal steering kernel weighted total variation model for image denoising. Symmetry 2019, 11, 329. [Google Scholar] [CrossRef]
- Li, M.; Cai, G.; Bi, S.; Zhang, X. Improved TV Image Denoising over Inverse Gradient. Symmetry 2023, 15, 678. [Google Scholar] [CrossRef]
- Ou, Y.; Swamy, M.; Luo, J.; Li, B. Single image denoising via multi-scale weighted group sparse coding. Signal Process. 2022, 200, 108650. [Google Scholar] [CrossRef]
- Izadi, S.; Sutton, D.; Hamarneh, G. Image denoising in the deep learning era. Artif. Intell. Rev. 2023, 56, 5929–5974. [Google Scholar] [CrossRef]
- Foerster, J.; Farquhar, G.; Afouras, T.; Nardelli, N.; Whiteson, S. Counterfactual multi-agent policy gradients. Proc. AAAI Conf. Artif. Intell. 2018, 32. [Google Scholar] [CrossRef]
- Varga, B.; Kulcsár, B.; Chehreghani, M.H. Deep Q-learning: A robust control approach. Int. J. Robust Nonlinear Control. 2023, 33, 526–544. [Google Scholar] [CrossRef]
- Kim, Y.; Soh, J.W.; Park, G.Y.; Cho, N.I. Transfer learning from synthetic to real-noise denoising with adaptive instance normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 3482–3492. [Google Scholar]
- Zhang, H.; Li, Y.; Chen, H.; Gong, C.; Bai, Z.; Shen, C. Memory-efficient hierarchical neural architecture search for image restoration. Int. J. Comput. Vis. 2022, 130, 157–178. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Valsesia, D.; Fracastoro, G.; Magli, E. Deep graph-convolutional image denoising. IEEE Trans. Image Process. 2020, 29, 8226–8237. [Google Scholar] [CrossRef]
- Kim, D.W.; Ryun Chung, J.; Jung, S.W. Grdn: Grouped residual dense network for real image denoising and gan-based real-world noise modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Yu, K.; Wang, X.; Dong, C.; Tang, X.; Loy, C.C. Path-restore: Learning network path selection for image restoration. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 7078–7092. [Google Scholar] [CrossRef]
- Chen, X.; Shen, J. Monte Carlo Noise Reduction Algorithm Based on Deep Neural Network in Efficient Indoor Scene Rendering System. Adv. Multimed. 2022, 2022, 9169772. [Google Scholar] [CrossRef]
- Halidou, A.; Mohamadou, Y.; Ari, A.A.A.; Zacko, E.J.G. Review of wavelet denoising algorithms. Multimed. Tools Appl. 2023, 82, 41539–41569. [Google Scholar] [CrossRef]
- Wang, M.; Wang, S.; Ju, X.; Wang, Y. Image Denoising Method Relying on Iterative Adaptive Weight-Mean Filtering. Symmetry 2023, 15, 1181. [Google Scholar] [CrossRef]
- Teng, L.; Li, H.; Yin, S. Modified pyramid dual tree direction filter-based image denoising via curvature scale and nonlocal mean multigrade remnant filter. Int. J. Commun. Syst. 2018, 31, e3486. [Google Scholar] [CrossRef]
- Wang, Y.; Pang, Z.F. Image denoising based on a new anisotropic mean curvature model. Inverse Probl. Imaging 2023, 17, 870–889. [Google Scholar] [CrossRef]
- Abazari, R.; Lakestani, M. A hybrid denoising algorithm based on shearlet transform method and Yaroslavsky’s filter. Multimed. Tools Appl. 2018, 77, 17829–17851. [Google Scholar] [CrossRef]
- Goyal, B.; Dogra, A.; Sangaiah, A.K. An effective nonlocal means image denoising framework based on non-subsampled shearlet transform. Soft Comput. 2022, 26, 7893–7915. [Google Scholar] [CrossRef]
- Liu, C.; Zhang, L. A Novel Denoising Algorithm Based on Wavelet and Non-Local Moment Mean Filtering. Electronics 2023, 12, 1461. [Google Scholar] [CrossRef]
- You, N.; Han, L.; Zhu, D.; Song, W. Research on image denoising in edge detection based on wavelet transform. Appl. Sci. 2023, 13, 1837. [Google Scholar] [CrossRef]
- Al-Shamasneh, A.R.; Ibrahim, R.W. Image Denoising Based on Quantum Calculus of Local Fractional Entropy. Symmetry 2023, 15, 396. [Google Scholar] [CrossRef]
- Kumar, A.; Ahmad, M.O.; Swamy, M. An efficient denoising framework using weighted overlapping group sparsity. Inf. Sci. 2018, 454, 292–311. [Google Scholar] [CrossRef]
- Jia, H.; Yin, Q.; Lu, M. Blind-noise image denoising with block-matching domain transformation filtering and improved guided filtering. Sci. Rep. 2022, 12, 16195. [Google Scholar] [CrossRef] [PubMed]
- Mahdaoui, A.E.; Ouahabi, A.; Moulay, M.S. Image denoising using a compressive sensing approach based on regularization constraints. Sensors 2022, 22, 2199. [Google Scholar] [CrossRef]
- Liu, S.; Hu, Q.; Li, P.; Zhao, J.; Wang, C.; Zhu, Z. Speckle suppression based on sparse representation with non-local priors. Remote. Sens. 2018, 10, 439. [Google Scholar] [CrossRef]
- Bhargava, G.U.; Sivakumar, V.G. An Effective Method for Image Denoising Using Non-local Means and Statistics based Guided Filter in Nonsubsampled Contourlet Domain. Int. J. Intell. Eng. Syst. 2019, 12. [Google Scholar] [CrossRef]
- Qi, G.; Hu, G.; Mazur, N.; Liang, H.; Haner, M. A novel multi-modality image simultaneous denoising and fusion method based on sparse representation. Computers 2021, 10, 129. [Google Scholar] [CrossRef]
- Xie, Z.; Liu, L.; Luo, Z.; Huang, J. Image denoising using nonlocal regularized deep image prior. Symmetry 2021, 13, 2114. [Google Scholar] [CrossRef]
- Fan, L.; Li, H.; Shi, M.; Hua, Z.; Zhang, C. Two-stage image denoising via an enhanced low-rank prior. J. Sci. Comput. 2022, 90, 57. [Google Scholar] [CrossRef]
- Lü, J.; Luo, X.; Qi, S.; Peng, Z. Image denoising using weighted nuclear norm minimization with preserving local structure. Laser Optoelectron. Prog. 2019, 56, 161006. [Google Scholar]
- Buades, A.; Coll, B.; Morel, J.M. Non-local means denoising. Image Process. Line 2011, 1, 208–212. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef]
- Wang, J.; Lu, Y.; Lu, G. Lightweight image denoising network with four-channel interaction transform. Image Vis. Comput. 2023, 137, 104766. [Google Scholar] [CrossRef]
- Yan, H.; Chen, X.; Tan, V.Y.; Yang, W.; Wu, J.; Feng, J. Unsupervised image noise modeling with self-consistent GAN. arXiv 2019, arXiv:1906.05762. [Google Scholar]
- Zhao, D.; Ma, L.; Li, S.; Yu, D. End-to-end denoising of dark burst images using recurrent fully convolutional networks. arXiv 2019, arXiv:1904.07483. [Google Scholar]
- Yang, J.; Liu, X.; Song, X.; Li, K. Estimation of signal-dependent noise level function using multi-column convolutional neural network. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 2418–2422. [Google Scholar]
- Yu, S.; Park, B.; Jeong, J. Deep iterative down-up cnn for image denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Chen, J.; Chen, J.; Chao, H.; Yang, M. Image blind denoising with generative adversarial network based noise modeling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 3155–3164. [Google Scholar]
- Bian, S.; He, X.; Xu, Z.; Zhang, L. Hybrid Dilated Convolution with Attention Mechanisms for Image Denoising. Electronics 2023, 12, 3770. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Zhang, L. Learning a single convolutional super-resolution network for multiple degradations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 3262–3271. [Google Scholar]
- Shah, V.H.; Dash, P.P. Two stage self-adaptive cognitive neural network for mixed noise removal from medical images. Multimed. Tools Appl. 2023, 1–23. [Google Scholar] [CrossRef]
- Obeso, A.M.; Benois-Pineau, J.; Vázquez, M.S.G.; Acosta, A.Á.R. Visual vs internal attention mechanisms in deep neural networks for image classification and object detection. Pattern Recognit. 2022, 123, 108411. [Google Scholar] [CrossRef]
- Anwar, S.; Barnes, N. Real image denoising with feature attention. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3155–3164. [Google Scholar]
- Zhang, K.; Zuo, W.; Zhang, L. FFDNet: Toward a fast and flexible solution for CNN-based image denoising. IEEE Trans. Image Process. 2018, 27, 4608–4622. [Google Scholar] [CrossRef]
- Tabassum, S.; Gowre, S.C. Optimal image Denoising using patch-based convolutional neural network architecture. Multimed. Tools Appl. 2023, 82, 29805–29821. [Google Scholar] [CrossRef]
- Mei, Y.; Fan, Y.; Zhou, Y. Image super-resolution with non-local sparse attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 3517–3526. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H.; Shao, L. Multi-stage progressive image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 14821–14831. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, Y.; Song, X.; Chen, K. Channel and space attention neural network for image denoising. IEEE Signal Process. Lett. 2021, 28, 424–428. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, K.; Li, K.; Sun, G.; Kong, Y.; Fu, Y. Accurate and fast image denoising via attention guided scaling. IEEE Trans. Image Process. 2021, 30, 6255–6265. [Google Scholar] [CrossRef]
- Liu, Y.; Qin, Z.; Anwar, S.; Ji, P.; Kim, D.; Caldwell, S.; Gedeon, T. Invertible denoising network: A light solution for real noise removal. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13365–13374. [Google Scholar]
- Li, J.; Fang, F.; Mei, K.; Zhang, G. Multi-scale residual network for image super-resolution. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 517–532. [Google Scholar]
- Chen, L.; Lu, X.; Zhang, J.; Chu, X.; Chen, C. Hinet: Half instance normalization network for image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 182–192. [Google Scholar]
- Roy, A.; Singha, J.; Manam, L.; Laskar, R.H. Combination of adaptive vector median filter and weighted mean filter for removal of high-density impulse noise from colour images. IET Image Process. 2017, 11, 352–361. [Google Scholar] [CrossRef]
- Lyu, Q.; Guo, M.; Pei, Z. DeGAN: Mixed noise removal via generative adversarial networks. Appl. Soft Comput. 2020, 95, 106478. [Google Scholar] [CrossRef]
- Malinski, L.; Smolka, B. Self-tuning fast adaptive algorithm for impulsive noise suppression in color images. J. Real-Time Image Process. 2020, 17, 1067–1087. [Google Scholar] [CrossRef]
- Lone, M.R.; Khan, E. A good neighbor is a great blessing: Nearest neighbor filtering method to remove impulse noise. J. King Saud-Univ.-Comput. Inf. Sci. 2022, 34, 9942–9952. [Google Scholar] [CrossRef]
- Lu, X.; Li, F. Fine-tuning convolutional neural network based on relaxed Bayesian-optimized support vector machine for random-valued impulse noise removal. J. Electron. Imaging 2023, 32, 013006. [Google Scholar] [CrossRef]
- Satti, P.; Shrotriya, V.; Garg, B.; Surya Prasath, V. DIBS: Distance-and intensity-based separation filter for high-density impulse noise removal. Signal Image Video Process. 2023, 17, 4181–4188. [Google Scholar] [CrossRef]
- Ri, G.I.; Kim, S.J.; Kim, M.S. Improved BM3D method with modified block-matching and multi-scaled images. Multimed. Tools Appl. 2022, 81, 12661–12679. [Google Scholar] [CrossRef]
- Xu, J.; Zhang, L.; Zhang, D. A trilateral weighted sparse coding scheme for real-world image denoising. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 20–36. [Google Scholar]
- Quan, Y.; Chen, M.; Pang, T.; Ji, H. Self2self with dropout: Learning self-supervised denoising from single image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Washington, DC, USA; 2020; pp. 1890–1898. [Google Scholar]
- Zoran, D.; Weiss, Y. From learning models of natural image patches to whole image restoration. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 479–486. [Google Scholar]
- Chen, Y.; Pock, T. Trainable nonlinear reaction diffusion: A flexible framework for fast and effective image restoration. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1256–1272. [Google Scholar] [CrossRef]
- Tian, C.; Xu, Y.; Li, Z.; Zuo, W.; Fei, L.; Liu, H. Attention-guided CNN for image denoising. Neural Netw. 2020, 124, 117–129. [Google Scholar] [CrossRef]
- Jia, X.; Liu, S.; Feng, X.; Zhang, L. Focnet: A fractional optimal control network for image denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–19 June 2019; 2019; pp. 6054–6063. [Google Scholar]
- Liang, Z.; Wang, Y.; Wang, L.; Yang, J.; Zhou, S. Light field image super-resolution with transformers. IEEE Signal Process. Lett. 2022, 29, 563–567. [Google Scholar] [CrossRef]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H.; Shao, L. Cycleisp: Real image restoration via improved data synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 2696–2705. [Google Scholar]
- Yue, Z.; Zhao, Q.; Zhang, L.; Meng, D. Dual adversarial network: Toward real-world noise removal and noise generation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part X 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 41–58. [Google Scholar]
- Kulikov, V.; Yadin, S.; Kleiner, M.; Michaeli, T. Sinddm: A single image denoising diffusion model. In Proceedings of the International Conference on Machine Learning, PMLR, Honolulu, HI, USA, 23–29 July 2023; pp. 17920–17930. [Google Scholar]
- Thakur, R.K.; Maji, S.K. Multi scale pixel attention and feature extraction based neural network for image denoising. Pattern Recognit. 2023, 141, 109603. [Google Scholar] [CrossRef]
- Zhang, D.; Zhou, F. Self-supervised image denoising for real-world images with context-aware transformer. IEEE Access 2023, 11, 14340–14349. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Noise level | BM3D [71] | DnCNN [42] | DIBS [70] | FFDNet [54] | S2S-LSD [73] | NNF [68] | Ours |
|---|---|---|---|---|---|---|---|---|
| CBSD68 | 15 | 33.42 | 33.81 | 33.79 | 33.91 | 34.11 | 33.88 | 34.89 |
| 25 | 30.71 | 31.11 | 31.17 | 31.19 | 31.39 | 31.29 | 31.79 | |
| 50 | 27.41 | 27.89 | 27.79 | 27.96 | 28.09 | 28.04 | 28.89 | |
| p value | 0.009475 | 0.01719 | 0.027771 | 0.019703 | 0.036744 | 0.034747 | ||
| Kodak24 | 15 | 34.32 | 34.6 | 34.69 | 34.63 | 34.88 | 34.76 | 35.31 |
| 25 | 32.18 | 32.09 | 32.19 | 22.11 | 32.51 | 32.28 | 32.89 | |
| 50 | 28.51 | 28.89 | 28.91 | 29.01 | 29.31 | 29.45 | 29.86 | |
| p value | 0.031629 | 0.008397 | 0.016818 | 0.344042 | 0.012156 | 0.012579 | ||
| McMaster | 15 | 34.06 | 33.39 | 34.58 | 34.77 | 35.28 | 35.22 | 35.88 |
| 25 | 32.66 | 31.52 | 32.21 | 32.45 | 32.85 | 32.66 | 33.23 | |
| 50 | 28.62 | 28.72 | 28.82 | 29.28 | 29.62 | 29.42 | 30.01 | |
| p value | 0.075244 | 0.034982 | 0.004811 | 0.018127 | 0.023792 | 0.023792 |
| Datasets | Scale Factor | NNF [68] | FCNN [69] | DnCNN [42] | S2S-LSD [73] | Ours | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | ||
| Set5 | 2 | 0.929 | 33.64 | 0.953 | 36.62 | 0.959 | 37.58 | 0.959 | 37.66 | 0.969 | 37.79 |
| 3 | 0.868 | 30.39 | 0.908 | 32.74 | 0.922 | 33.75 | 0.923 | 33.93 | 0.925 | 32.45 | |
| 4 | 0.81 | 28.42 | 0.863 | 30.48 | 0.885 | 31.4 | 0.886 | 31.58 | 0.893 | 31.96 | |
| p value | 0.040788 | 0.034573 | 0.043145291 | 0.286164818 | 0.078202309 | 0.786163382 | 0.113155947 | 0.634808932 | |||
| Set14 | 2 | 0.868 | 30.22 | 0.906 | 32.42 | 0.913 | 33.03 | 0.913 | 33.19 | 0.915 | 33.32 |
| 3 | 0.774 | 27.53 | 0.821 | 29.27 | 0.832 | 29.81 | 0.834 | 29.94 | 0.837 | 30.04 | |
| 4 | 0.702 | 25.99 | 0.751 | 27.48 | 0.767 | 28.04 | 0.77 | 28.18 | 0.777 | 28.35 | |
| p value | 0.016861 | 0.00715 | 0.074865608 | 0.002147566 | 0.135841435 | 0.007463862 | 0.12011731 | 0.022352567 | |||
| Urban 100 | 2 | 0.841 | 26.66 | 0.897 | 29.53 | 0.914 | 30.74 | 0.916 | 31.02 | 0.92 | 31.33 |
| 3 | 0.737 | 24.46 | 0.801 | 26.25 | 0.828 | 27.15 | 0.833 | 27.38 | 0.84 | 27.57 | |
| 4 | 0.657 | 23.14 | 0.722 | 24.52 | 0.752 | 25.2 | 0.758 | 25.35 | 0.773 | 25.68 | |
| p value | 0.011694 | 0.032585 | 0.043368568 | 0.017686966 | 0.096437539 | 0.009895742 | 0.118517445 | 0.02406957 | |||
| BSD100 | 2 | 0.844 | 29.55 | 0.887 | 31.34 | 0.775 | 31.9 | 0.897 | 32.01 | 0.898 | 32.05 |
| 3 | 0.738 | 27.2 | 0.786 | 28.4 | 0.798 | 28.85 | 0.799 | 28.91 | 0.803 | 28.97 | |
| 4 | 0.667 | 25.96 | 0.71 | 26.9 | 0.725 | 27.2 | 0.726 | 27.35 | 0.734 | 27.49 | |
| p value | 0.004222 | 0.022013 | 0.043897929 | 0.004882648 | 0.359176086 | 0.070531418 | 0.166049611 | 0.12011731 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rahman, Z.; Aamir, M.; Bhutto, J.A.; Hu, Z.; Guan, Y. Innovative Dual-Stage Blind Noise Reduction in Real-World Images Using Multi-Scale Convolutions and Dual Attention Mechanisms. Symmetry 2023, 15, 2073. https://doi.org/10.3390/sym15112073
Rahman Z, Aamir M, Bhutto JA, Hu Z, Guan Y. Innovative Dual-Stage Blind Noise Reduction in Real-World Images Using Multi-Scale Convolutions and Dual Attention Mechanisms. Symmetry. 2023; 15(11):2073. https://doi.org/10.3390/sym15112073
Chicago/Turabian StyleRahman, Ziaur, Muhammad Aamir, Jameel Ahmed Bhutto, Zhihua Hu, and Yurong Guan. 2023. "Innovative Dual-Stage Blind Noise Reduction in Real-World Images Using Multi-Scale Convolutions and Dual Attention Mechanisms" Symmetry 15, no. 11: 2073. https://doi.org/10.3390/sym15112073
APA StyleRahman, Z., Aamir, M., Bhutto, J. A., Hu, Z., & Guan, Y. (2023). Innovative Dual-Stage Blind Noise Reduction in Real-World Images Using Multi-Scale Convolutions and Dual Attention Mechanisms. Symmetry, 15(11), 2073. https://doi.org/10.3390/sym15112073