

Proof-of-Useful-Work: BlockChain Mining by Solving Real-Life Optimization Problems
 , , , , , and
, , , , , and
Abstract
:1. Introduction
2. Preliminaries and Related Work
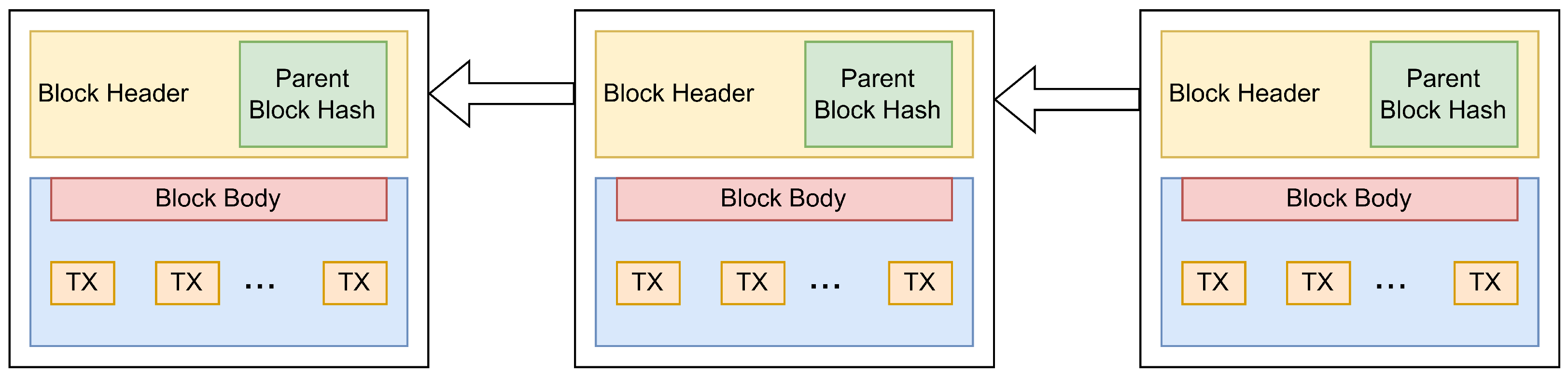
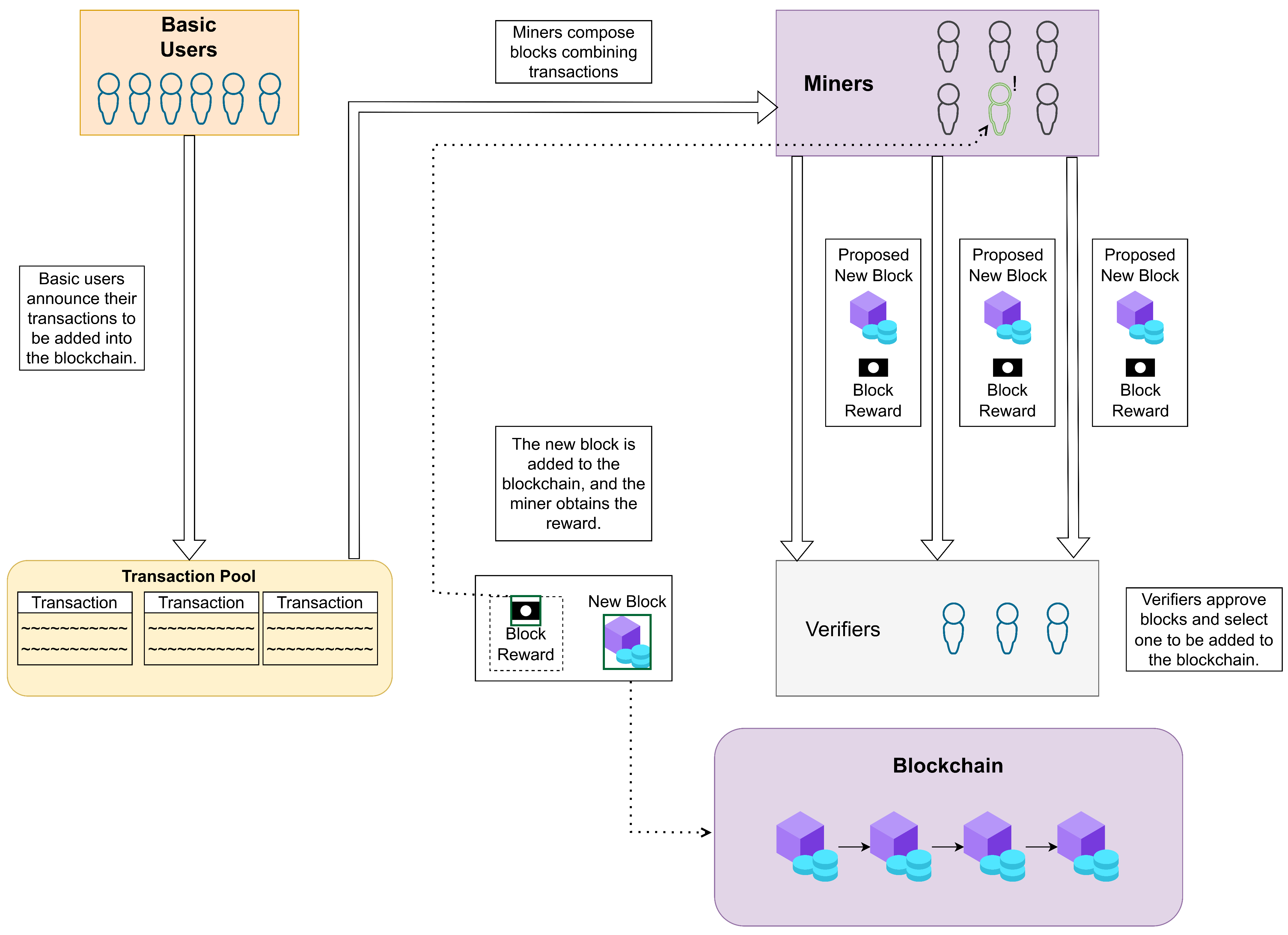
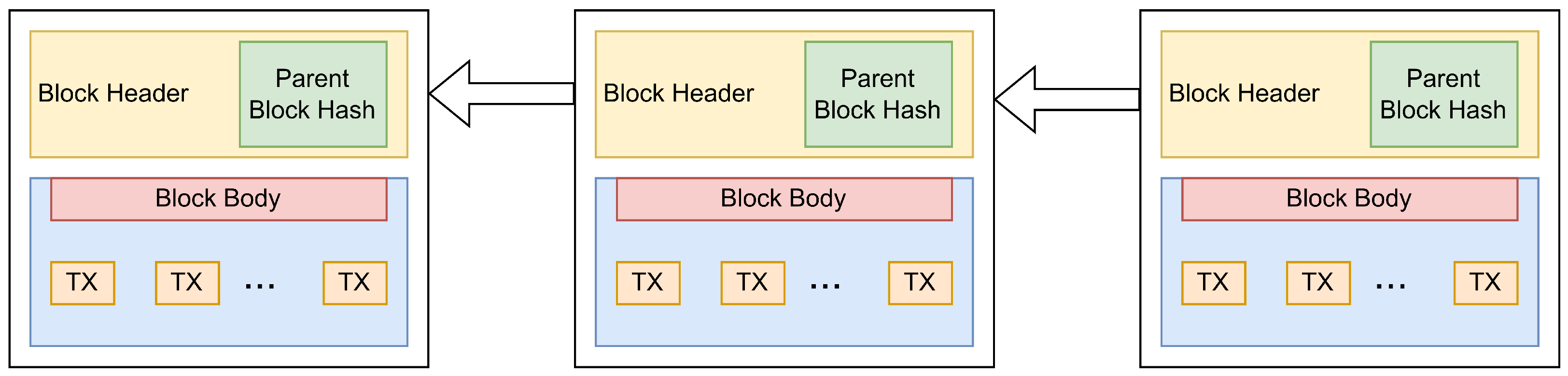
2.1. BC Background
2.2. Related Work
3. Our Solution Framework
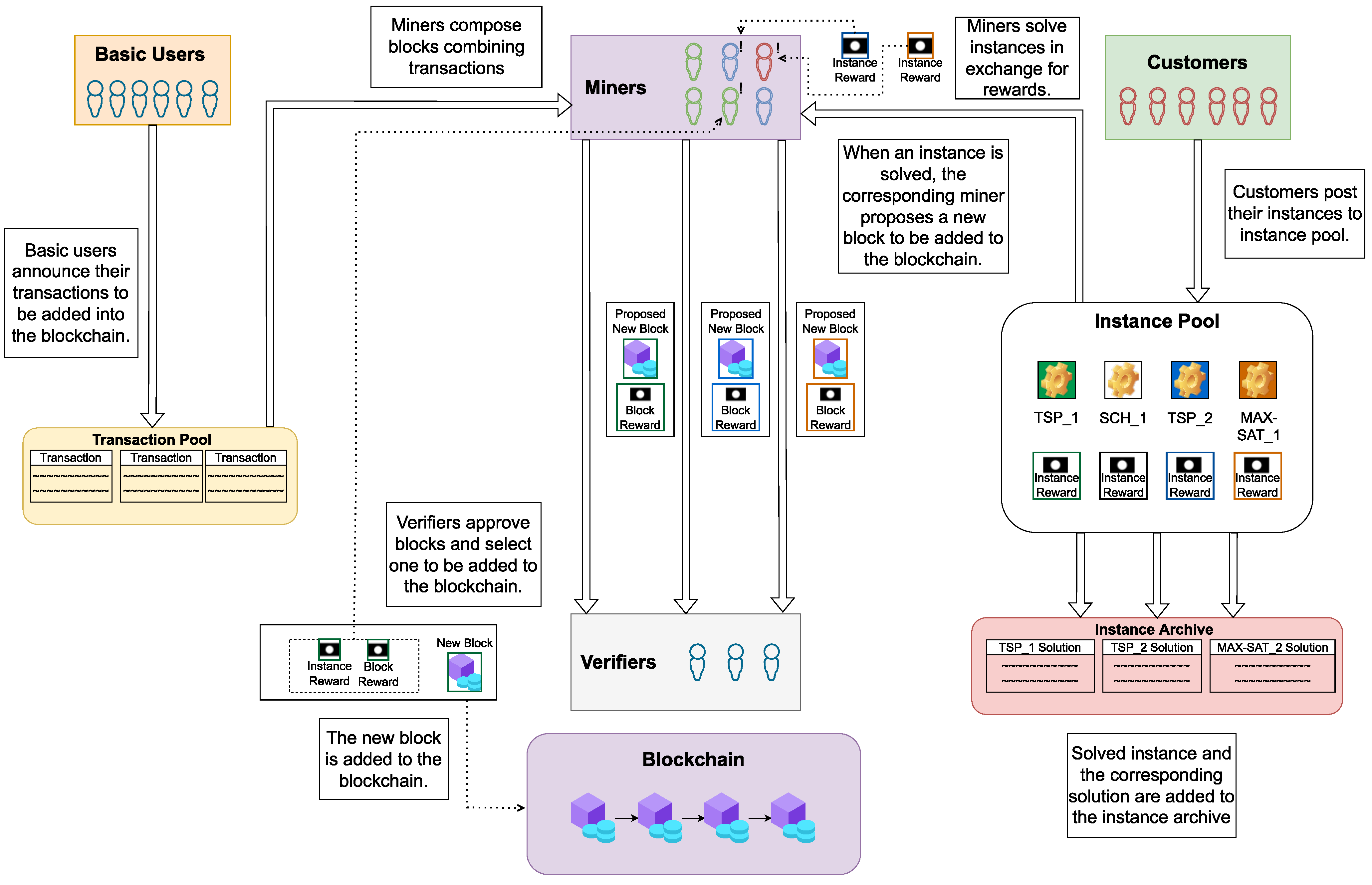
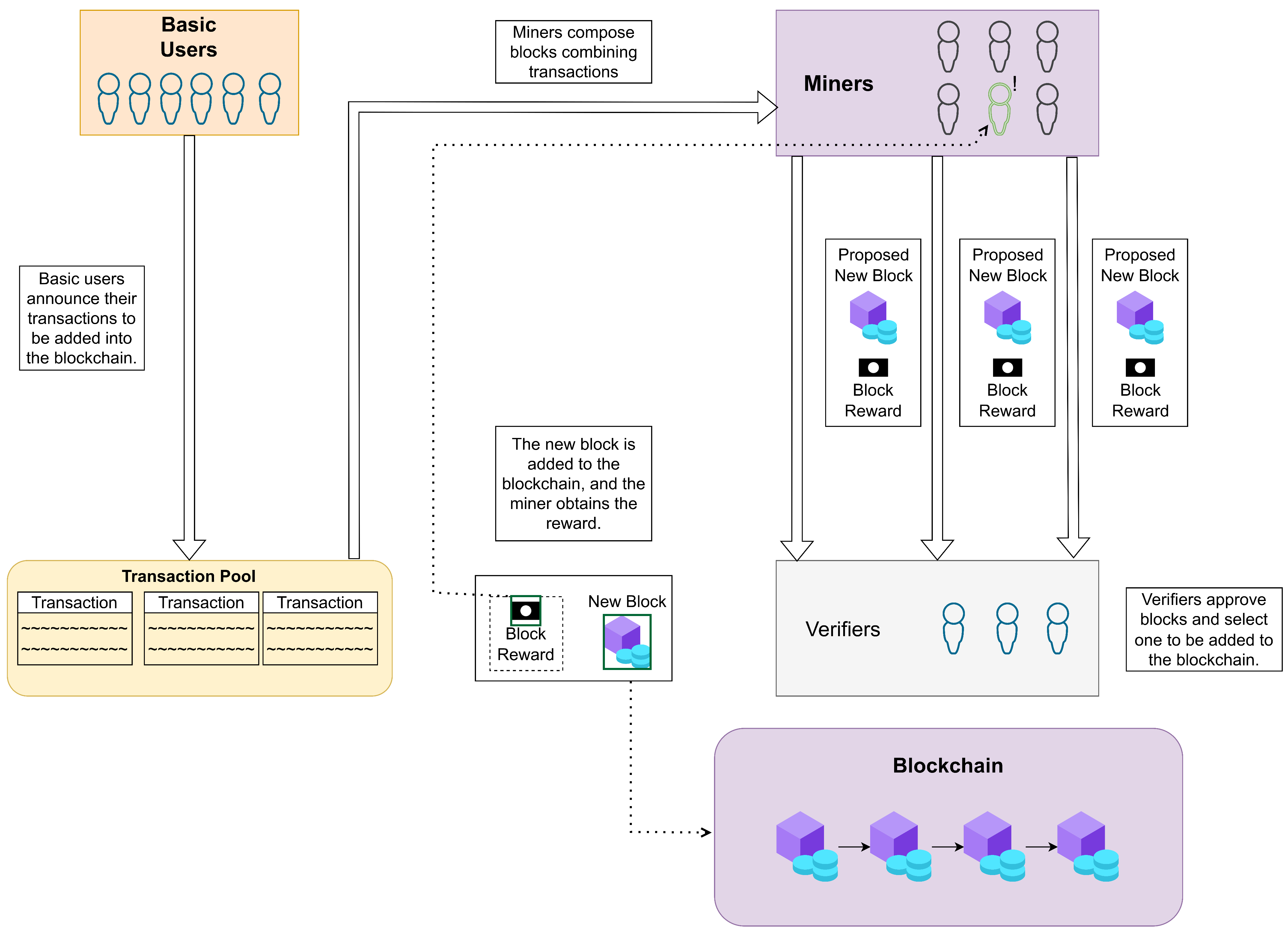
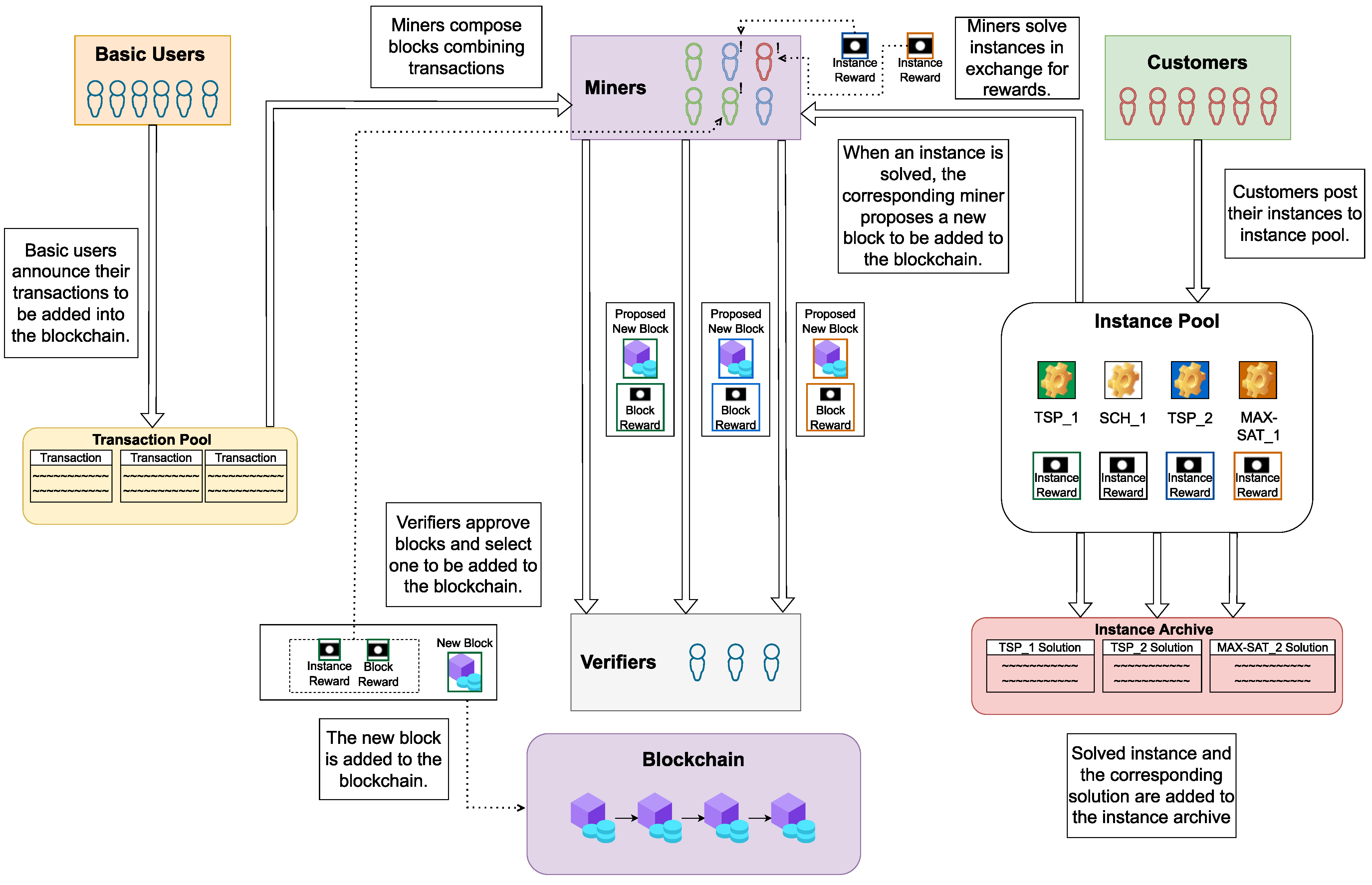
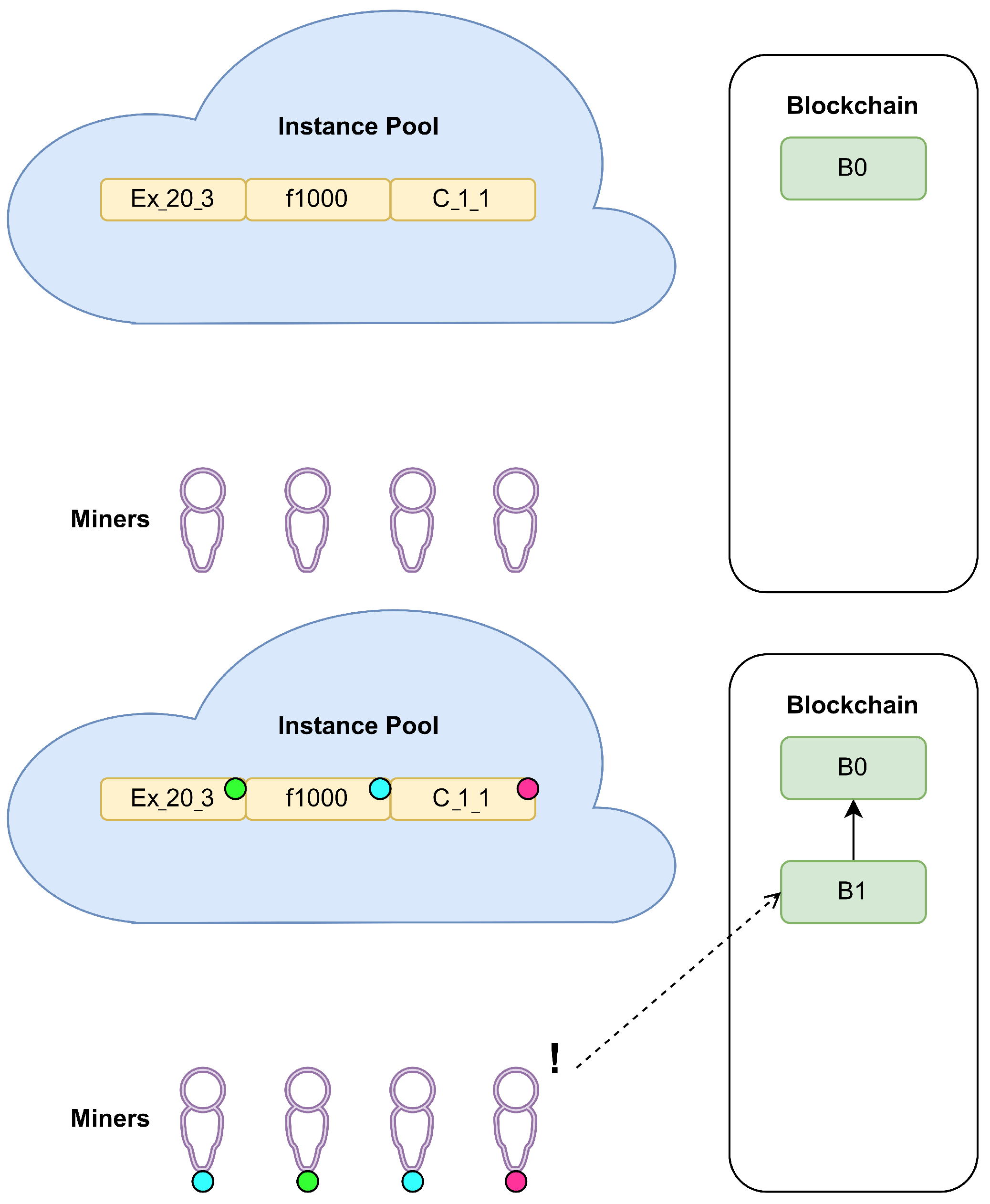
3.1. Proposed PoUW Consensus Protocol
- Customer identification;
- A timestamp;
- A valid address for CO problem instance data;
- The hash value of CO problem instance data;
- The solution threshold;
- The deadline for finding the solution; and
- The reward specification.
| Algorithm 1 Procedure for instance submission |
|
- INTERRUPT: This means that another miner has already announced a new block and it is undergoing the verification process. If they are close to solving instance i, the miner may decide to continue mining for some short time period and, if successful, to announce the obtained valid solution for i and publish the composed block B. Even if B is not accepted for inclusion in BC, the miner could be rewarded for providing a valid solution for instance i.
- SOLVED: This indicates that the solution method succeeded in finding a valid solution for CO problem instance i, and the miner can announce it and publish block B.
- FAILED: This stands for the case when a solution method reaches the stopping criterion without providing a valid solution for instance i. In that case, the CO problem instance is returned to the instance pool for another attempt related to some future block.
| Algorithm 2 Procedure for block mining |
|
| Algorithm 3 Procedure for solution retrieval |
|
| Algorithm 4 Procedure for block verification |
|
3.2. Benefits of COCP
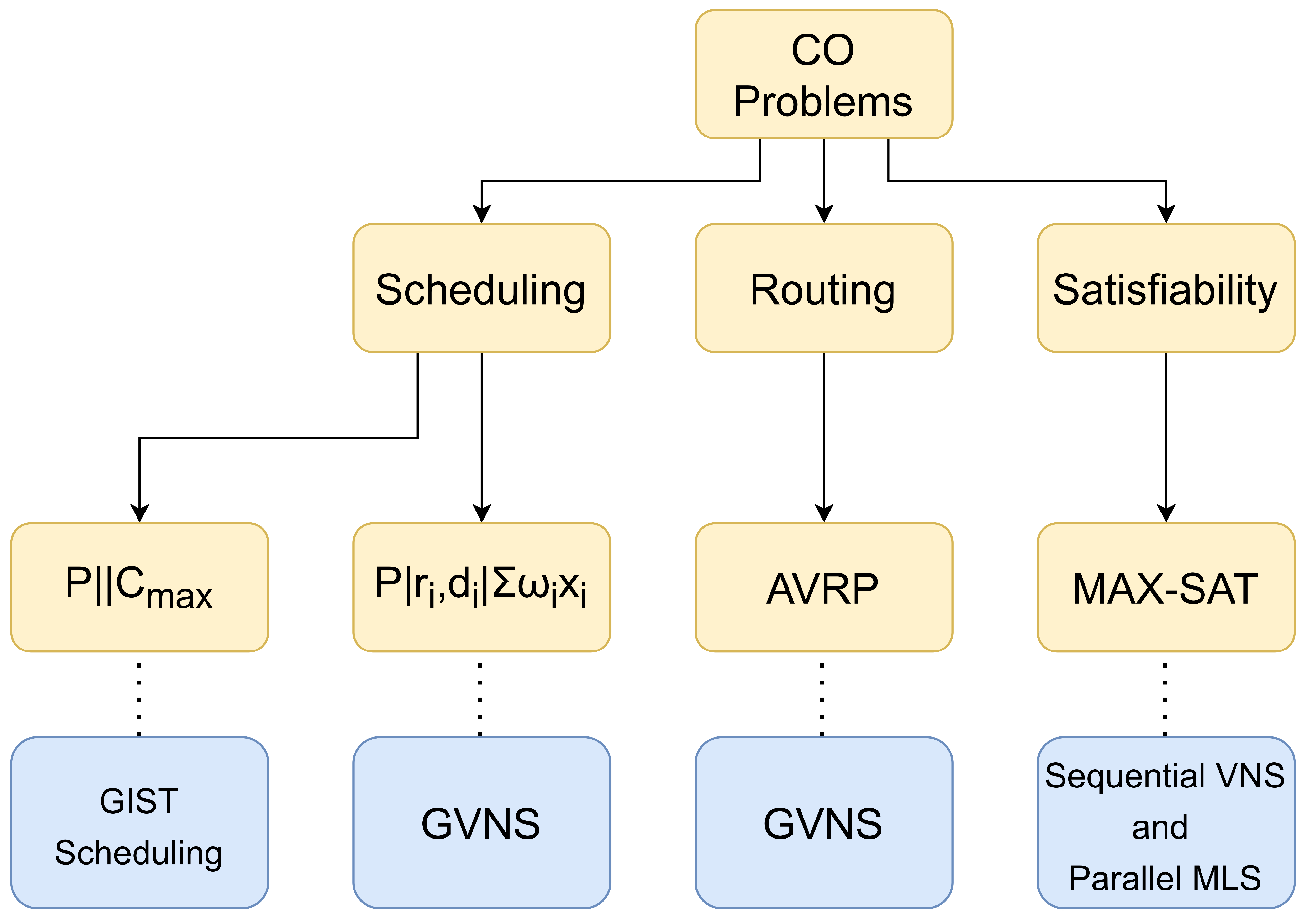
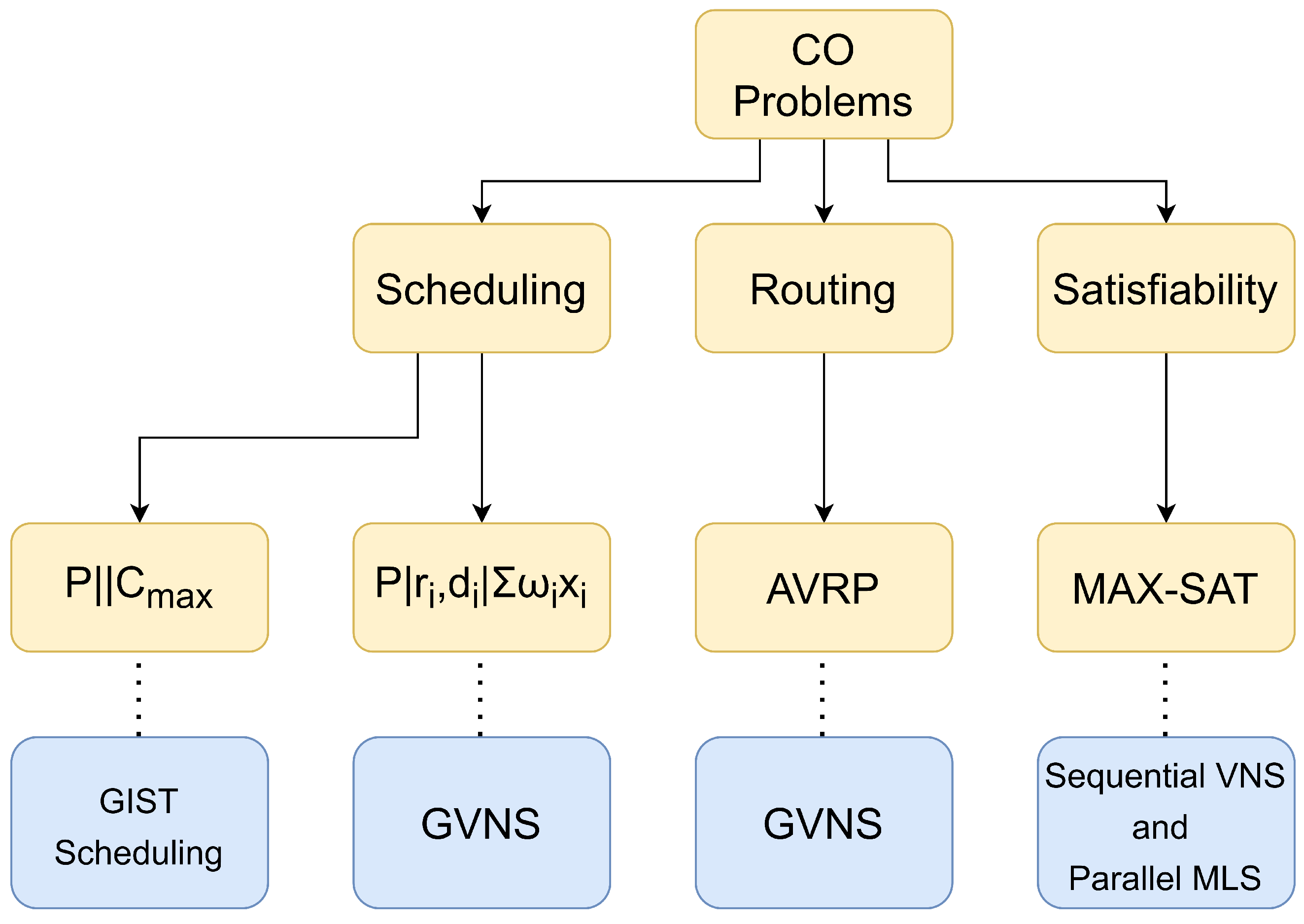
3.3. Some Examples of Optimization Problems
3.3.1. Scheduling Problems
Scheduling Independent Tasks for Identical Processors (P‖Cmax)
Weighted Scheduling Problem with Deadlines and Release Times
3.3.2. Asymmetric Vehicle Routing Problem
3.3.3. Maximum Satisfiability Problem
4. Results: COCP Simulation
4.1. Description of the Ethereum Platform
4.2. Simulation Setup
- Nine instances of the problem (C_1_1, …, C_1_9);
- Ten instances of (Sched1, …, Sched10);
- Nine instances of AVRP (named EX__, where n denotes the number of customers and m stands for the number of vehicles); and
- Six examples of MAX-SAT (f600, f1000, f2000, hole8, hole10, pr150_75).
4.3. Simulation Results
- 0.
- Ex_20_3
- 1.
- f1000
- 2.
- C_1_1
- 0.
- C_1_3
- 1.
- f2000
- 2.
- Ex_22_2
- 3.
- C_1_4
- 4.
- Sched5
- 5.
- f600
- 0.
- C_1_3
- 1.
- f2000
- 2.
- C_1_4
- 3.
- Sched5
- 4.
- f600
- 5.
- Sched4
- 6.
- Sched8
- 0.
- C_1_3
- 1.
- f600
- 2.
- Sched4
- 3.
- Sched8
- 4.
- pr150_75
- 5.
- hole10
- 6.
- Ex_25_3
- 7.
- C_1_9
- 0.
- C_1_3
- 1.
- f600
- 2.
- Sched4
- 3.
- hole10
- 4.
- Ex_25_3
- 5.
- C_1_9
- 6.
- Sched1
- 0.
- C_1_3
- 1.
- f600
- 2.
- Sched4
- 3.
- hole10
- 4.
- C_1_9
- 5.
- Sched1
- 6.
- Ex_19_2
- 7.
- C_1_7
- 8.
- Sched7
- 0.
- f600
- 1.
- Sched4
- 2.
- hole10
- 3.
- C_1_9
- 4.
- Sched1
- 5.
- C_1_7
- 6.
- Sched7
- 7.
- Ex_15_2
- 8.
- Ex_30_3
- 9.
- C_1_2
- 0.
- f600
- 1.
- Sched4
- 2.
- hole10
- 3.
- C_1_9
- 4.
- Sched1
- 5.
- C_1_7
- 6.
- Sched7
- 7.
- Ex_15_2
- 8.
- Ex_30_3
- 0.
- f600
- 1.
- hole10
- 2.
- C_1_7
- 3.
- Sched7
- 4.
- Ex_30_3
- 5.
- Sched6
- 6.
- C_1_5
- 7.
- Sched10
- 0.
- hole10
- 1.
- Ex_30_3
- 2.
- Sched6
- 3.
- C_1_5
- 4.
- Sched10
- 5.
- C_1_6
- 6.
- Sched2
- 7.
- Sched3
- 8.
- C_1_8
- 9.
- Sched9
- 0.
- hole10
- 1.
- C_1_5
- 2.
- Sched10
- 3.
- Sched2
- 4.
- Sched3
- 5.
- C_1_8
- 6.
- Sched9
- 0.
- C_1_5
- 1.
- Sched10
- 2.
- Sched3
- 3.
- C_1_8
- 4.
- Sched9
- 5.
- Ex_26_2
- 6.
- Ex_35_3
- 7.
- hole8
- 8.
- Ex_31_2
5. Discussion
5.1. Comments on Simulation Results
5.2. Challenges
- 1.
- Submission PrivilegesDescription: In some of the papers considering PoUW-based consensus protocols, there is a special type of user that can submit CO problem instances. They need to provide problem input data and incentives for the miners who solve them.Challenge resolution: We introduced a new category of users, customers, who pay to obtain high-quality solutions for the provided instances of real-life CO problems. Thus, we resolved challenge 1 regarding who is allowed to submit the CO problem instances. Customers can play any other role in the BC network; specifically, they could be considered basic users, because their payments should represent regular BC transactions.
- 2.
- Problem RangeDescription: The majority of prior papers considered a particular CO problem (e.g., TSP) for which the structure of the input data was known (i.e., the number of cities, distances between them, and optionally the pickup/delivery quantities, etc.). However, such an approach is very limited and the inclusion of various CO problems in these considerations may be more beneficial. On the other hand, in such a case, a proper user interface differentiating input data for distinct CO problems, as well as the corresponding solution methods, should be provided. In [8,10] the authors proposed the use of a generic solution framework that can accommodate numerous CO problems. This approach requires a pre-processing step in which the submitted CO problem instance is transformed into the form that is accepted by the generic framework.Challenge resolution: We envisioned that customers could submit instances of any CO problem of their choosing. The reasoning behind a resolution of challenge 2 in this manner is the fact that the number of clients requiring solutions for an instance of any particular problem may be negligible, whereas the number of CO problems and their variants is limitless for all practical purposes. In our COCP framework, CO problem instances are specified by a special kind of transaction or by a smart contract containing all the information necessary to decode which CO problem is to be considered and to select the appropriate solution method. We also envision the ease of appending new modules for different types or variants of CO problems. Expecting customers to provide algorithms for their CO problems (as is suggested in [9]) is reasonable only for scientific purposes. Otherwise, it is necessary to provide efficient solution methods as a part of the BC software system. Numerous optimization methods are available in open-source formats on the Internet.
- 3.
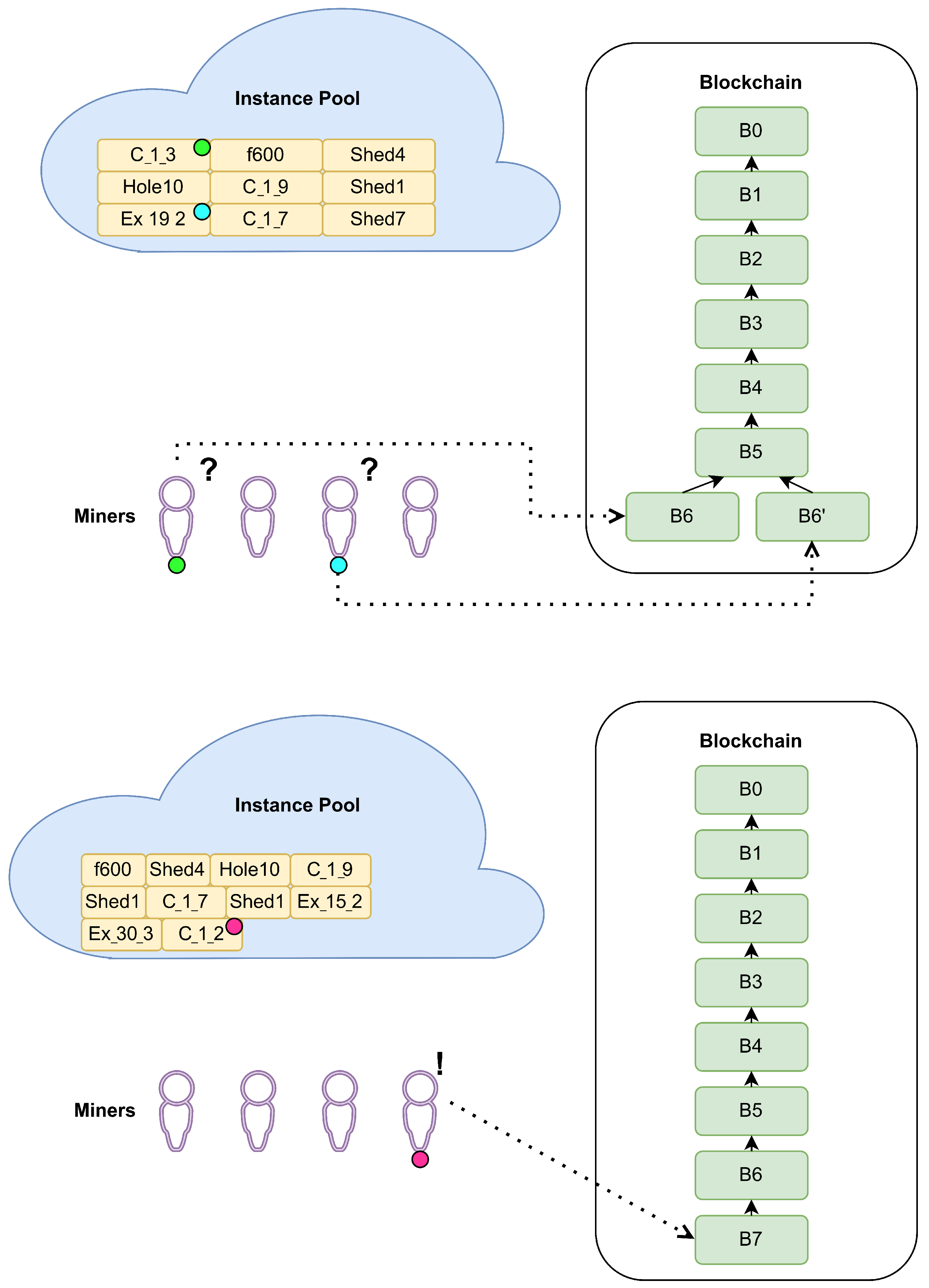
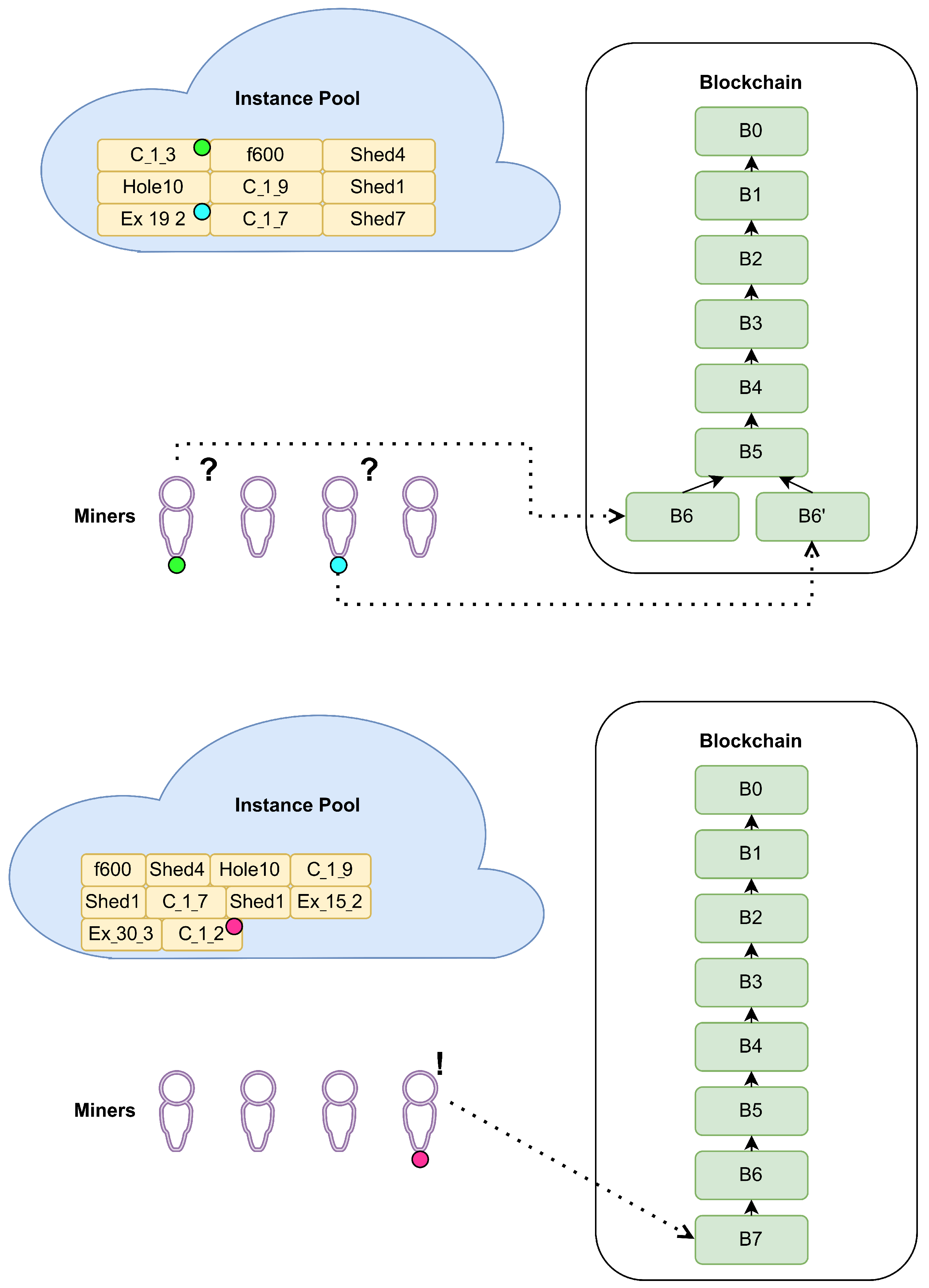
- Problem–Block CorrespondenceDescription: In the classical PoW, the nonce represents an adequate correspondence between the composed block and the work performed by the miner to publish it. When the PoUW is applied, this correspondence should be substituted by selecting an adequate submitted CO problem instance. It is important that the block structure refers to exactly one of the submitted instances. Some authors [8,10] use a nonce value (with the original meaning) to prove that a large number of solutions has been visited before an attempt to publish a composed block.Challenge resolution: When a pool of various instances is established, resolving challenge 3 involves choosing the instance that corresponds to the composed block, mimicking the connection between the hash value of a block and the nonce in the PoW-based consensus protocols. Only in a few papers in the literature is this correspondence problem mentioned; however, no adequate solution has been provided. The authors in [10] assumed that each instance has priority and the miners selected instances in accordance with that priority without specifying any more details. In [9] the authors suggested always dealing with a set of instances, rather than using only one. The authors also included mini-blocks that are put between actual blocks and each of them corresponds to one of the CO problem instances; however, the precise matching method is not provided.We resolved this challenge by performing a modulo operation between the hash value of the composed block and the number of instances currently available in the instance pool. Note that resolving this challenge also makes it very difficult, if not impossible, for a miner to choose instances to work on at will. The state of the instance pool at any moment should be common knowledge among all the BC participants. This is easy to ensure, bearing in mind that each instance has a timestamp marking the time of its submission. To ensure diversity in the block–instance correspondence, the number of instances in the pool has to be at least as large as the number of miners. This requirement is not strict: COCP can work correctly even if it is not fulfilled.
- 4.
- Ensuring UsefulnessDescription: The number of submitted CO problem instances must be as large as possible so that different blocks always correspond to different CO instances. In addition, the number of miners solving the same instance (during the process of mining a new block) decreases and the expected time for solving the corresponding CO problem instance increases. To estimate the number of required CO instances, we considered several use cases. The Bitcoin block insertion frequency is 10–15 min, and we require at least four to six instances per hour, i.e., 96–144 instances per day to ensure an instance for each inserted block. In some of the Ethereum BC systems, blocks are inserted every 10–15 s, and we need to provide 240–360 instances per hour. To the best of our knowledge, this problem has not been discussed in the relevant literature.Challenge resolution: The number of customers who would provide instances in a timely fashion is very important if we want COCP to perform useful work at all times. Customers such as delivery services (providing instances of various vehicle routing problems, especially in urban logistics), production companies, VLSI producers (who model the layout and connections between components through instances of the (MAX-)SAT problem), team builders or advertisers (who need to group their users into compact clusters/communities), and schedulers for cloud resources (especially when relatively small computing equipment has been rented for the execution of a large number of simple tasks), could jointly generate large numbers of instances. However, if we face a lack of CO problem instances we could generate classical cryptographic puzzles to represent CO problem instances and increase the instance pool.
- 5.
- Controlling HardnessDescription: It is very important to consider the trade-offs involved in keeping the complexities (i.e., the expected solution times) of all submitted CO problem instances very similar, even though it is very difficult to predict their complexities in advance. If miners obtain instances of lower complexity they might have a higher chance of solving the corresponding instance and obtaining an award. However, solving easy instances could be useful in some cases.Challenge resolution: In our study we assumed that both hard and easy instances were important for customers. Easy instances can be solved quickly and the solution could be provided to customers faster than if the instance was hard. The corresponding miners are rewarded accordingly. It may happen that some of the submitted CO problem instances are very hard, preventing the miners from solve them efficiently and thus introducing latency into the PoUW consensus protocol. However, in the PoUW it is not important to obtain an optimal solution of the considered CO instance. One of the input data corresponds to the solution threshold, i.e., the bound on the desired objective function value. For example, if we are addressing an instance of the TSP problem, the customer should specify the largest acceptable length of the resulting tour. As soon as the miner finds a solution with an objective function smaller than the given threshold, they can publish the corresponding block. If the instance is too hard and is not solved before another block is announced, it is returned to the instance pool for another solution attempt (as explained in Section 3.1). Solution methods are usually stochastic heuristics methods and each run may provide a different outcome. Each instance can be granted multiple solution attempts as long as its deadline is not passed. If the time required to obtain the desired quality solution is over the deadline, the instance is removed from the instance pool, and the customer may submit the instance again with an adjusted deadline value. To decrease the number of unusable instances, the optimization methods must be implemented in such a way as to accept the current best-known solution as an input parameter, i.e., to enable the continuation of the solution process. In such a way, it is possible to increase the time allowed to solve extremely hard instances. In general, NP-hard problems do not become easier when a good solution candidate is provided. However, in some cases it could help to solve them faster and make it possible to decrease the number of unusable instances.To be able to guarantee that the blocks are added in an approximately regular time interval, we set the stopping criterion of heuristic algorithms to the maximum CPU time, calculated in correspondence with the block insertion frequency. As the mining process is highly concurrent, we expect that at least one miner will be able to solve the instance within the given CPU time limit. However, if some of the instances are too easy, the corresponding blocks may be added more frequently. Therefore, we plan to include an instance pre-processing phase, in which an estimation of its hardness will be performed. This phase would enable us to balance the work of miners by requiring them to solve one hard instance or a group of several easy instances. The estimation of instance hardness is related to predicting the performance of stochastic heuristic algorithms. It is not an easy task; however, it has been studied by the CO research community and some results have already been published. It has been shown in the literature that stochastic (randomized) algorithms (solution methods based on a random number generator) exhibit exponential run-time distributions [79]. The question of predicting the performance of such algorithms is addressed by building so-called empirical hardness models, which take into account the parameters/features of the corresponding hard CO problem instances, as well as the algorithm’s parameter settings. A comprehensive review of different instance features and models can be found in [80]. The application of these methods in practice is a part of ongoing work.The lack of a pre-processing phase for the estimation of the instance hardness does not impede the proposed framework. Although some miners may need to solve easier instances, and some miners need to solve harder ones, the robustness of the system to this is the same as the robustness of the classic PoW regarding the luck of some miners.In order to prove that the miners invested a certain amount of work when executing the proof-of-solution consensus protocol, in [9] it was necessary to calculate the hash value of each solution and use it as a nonce in the classical PoW sense. This means that the miner had to evaluate as many solutions as was necessary to find the proper nonce value. In our approach, it is possible to use the number of objective function evaluations as the stopping criterion for the applied optimization method and to obtain a similar effect.
- 6.
- Efficient Hardware ExploitationDescription: In the classical PoW, the miners perform a large number of simple operations and they are equipped with suitable hardware resources. On the other hand, dealing with the selected CO problem instances in PoUW-based consensus protocols does not exploit hardware resources that are usually owned by a typical miner.Challenge resolution: Dealing with the selected CO problem usually does not require any special resources that are considered standard in the classical BC networks. Therefore, it may occur that the miners cannot engage their existing expensive hardware resources. In the literature, it has been suggested to implement a hybrid approach (involving both the PoW and the PoUW methods) and to allow miners to decide which consensus protocol they want to use. In order to increase their rewards, miners are motivated to use the PoUW approach (i.e., to select and solve an instance from the pool). We propose considering an alternative approach: To develop optimization algorithms suitable for execution on the hardware already owned by miners. For example, we developed a GPU-based metaheuristic approach to the MAX-SAT problem.
- 7.
- Data Management and Malicious BehaviorDescription: Some of the BC data security issues with respect to the malicious behavior of users include changing input or solution data and introducing confusion between an instance and its solution, stealing a solution from a successful miner, selfish mining, announcing a new block before obtaining a valid solution and hoping that the solution will be ready while the verifiers approve the block, and accessing instances and solutions from the archive.Challenge resolution: Regarding BC data security issues, we focused on the parts we introduced: input data and solution data for CO problem instances. Both data types can be very large and are thus not included in blocks of the BC system. Instead, they are stored in some public location that is accessible to everyone. For the input data, the location address is provided and included in the corresponding block via a transaction or via a smart contract. Upon finding a valid solution, the miner stores it in a private location, which is predefined and known to all participants. The name of the file containing the solution is the same as the name of a file with the instance input data and the solution file is always read-only. In addition to the input data location, the miner stores a pointer to the transaction or a smart contract that corresponds to the solved CO problem instance in the nonce field of the block’s header, enabling all participants to access its input data.The first example of data security issue involves preventing miners from performing selfish mining and other types of known frauds [81,82]. For example, miners could play the role of a customer and submit instances for which they already have high-quality solutions with the aim of composing and adding blocks to the BC without much effort. This is strongly discouraged by providing an adequate number of CO problem instances. Namely, when the number of instances in the pool is adequate, the effort needed to compose the block corresponding to any particular instance is very similar to the effort needed to solve the instance. Additionally, this is further discouraged as the malevolent miner must form a block that would provide a hash value that would pair up with the index of the instance that they posted, after applying the modulo operation. This is a difficult task to complete because the hash value of the block cannot be predicted and must always be calculated. In addition, the index of the problem may change over time because the content of the instance pool may be updated. It should also be noted that the malevolent miner cannot form the block in advance that pairs up with his instance, as he will not know the index of the instance until the instance enters the instance pool, which happens only when the transaction with the instance enters the BC. Moreover, the cost of announcing a CO problem instance is greater than the reward provided for its solution.The same argument holds for an attempt by a malicious miner to steal a solution from another miner and announce it as their own.The miner could try to announce a new block before obtaining a valid solution, hoping to obtain a valid solution before the verifiers approve the block. To prevent this security issue, the published block should contain both the hash value of the instance input data and of the solution in field2 (the mixHash field in our example).Some malicious users may try to change the input data of the CO problem instance and introduce confusion between instance and its solution. To prevent this security issue, a hash value of the problem data is stored in the transaction. Thus, any change can be detected by comparing this hash value with the one calculated from the file pointed by the location address.In the process of block verification, the verifiers access the instance data via the information provided in the field1 field and the solution obtained from the miner’s private location. Verification consists of reconstructing the hash value of the solution from field2 by performing the xor operation with the CO problem instance’s hash. Additionally, they check whether the miner ID corresponds to the miner ID associated with the solution saved in the instance archive. After this is completed, the verifier has all the data needed to validate the block. The hash value of the CO problem instance is calculated based on the instance data from the pool and compared with the corresponding hash value provided by the customer. On the other hand, the reconstructed hash of the solution is compared with the hash value calculated from the solution itself. If any pair of hashes does not contain the same values, we can detect malicious behavior and discard the corresponding block.To provide unhindered access to the solved CO problem instances and their solutions, the instance archive must be implemented in a distributed manner. Each instance and solution that are stored must be available at any time to the BC users because they need to perform mining and verification. There are already some distributed storage solutions that may be suitable for hosting the instance archive, such as SWARM (https://www.ethswarm.org/ accessed on 4 August 2022) and the InterPlanetary File System (https://ipfs.tech/ accessed on 4 August 2022). Both of these systems divide files into chunks and store multiple copies on various nodes, providing stable access to stored files that are resistant to tampering.
- 8.
- Increasing EfficiencyDescription: Distributed computing may significantly increase the efficiency of PoUW-based consensus protocols; however, this requires proper (parallel) optimization algorithms. Another type of distributed mining involves cooperation between miners in so-called pools of miners, specifically, a number of miners can team up in order to solve mining problems together and split the rewards accordingly. The main issue related to pools of miners considers the honesty of each pool member in maximally contributing toward the joint work. A dishonest miner could announce the solution as their own or even sell the solution to another mining pool.Challenge resolution: Distributed computing may significantly increase the efficiency of PoUW-based consensus protocols, however, this requires proper (parallel) optimization algorithms. Developing parallel optimization methods, both exact and heuristic, is a very fruitful field of research and the resulting algorithms can be efficiently used in COCP framework.Another type of distributed mining involves cooperation between the miners in so-called pools of miners, as considered in scenario 4: a group of miners can decide to work together and use their resources in order to find a solution to the mining problem and split the reward. These pools have an entity called a pool manager who forms a block and passes tasks to members of the pool for completion in order to mine the block. When the block is mined, the whole mining pool receives a reward which needs to be shared among its members based on the pool’s policy. Pools can have different policies, but they can be divided in two basic groups. One group consists of policies where the members of the pool receive payments immediately after completing a task given by the pool manager, whereas the policies of the other group split the reward of the mined block to the members based on the amount of the tasks they have solved. However, pool mining can have some drawbacks. First of all, the miners who join a pool must follow the decisions of the mining pool, and cannot make decisions by themselves when it comes to mining. Members of a pool also depend on the pool manager, who may be malicious, which may harm them. On the other hand, some of the members of the pool may exhibit malicious behavior, such as announcing the solution as their own or even selling the solution to another mining pool. Although this is a very important issue regarding the maintenance of the BC, it is outside the scope of our current research.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ANN | Artificial neural network |
| ASIC | Application-specific integrated circuit |
| AVRP | Asymmetric vehicle routing problem |
| BC | BlockChain |
| BFT | Byzantine fault tolerance |
| CNF | Conjunctive normal form |
| CO | Combinatorial optimization |
| COCP | Combinatorial optimization consensus protocol |
| CPU | Central processing unit |
| DG | Directed graph |
| DIPS | Difficulty-based incentives for problem solving |
| DPLS | Doubly parallel local search |
| DPS | Distributed problem solving |
| GPU | Graphics processing unit |
| GRASP | Greedy randomized adaptive search procedure |
| GVNS | General variable neighborhood search |
| IoT | Internet-of-Things |
| MAX-SAT | Maximum satisfiability problem |
| MILP | Mixed integer linear programming |
| ML | Machine learning |
| MLS | Multistart local search |
| NSGA-II | Non-dominated sorting genetic algorithm II |
| P2P | Peer-to-Peer |
| PCC | Proof-of-Collatz conjecture |
| PII | Personally identifiable information |
| PoA | Proof-of-authority |
| PoAc | Proof-of-activity |
| PoB | Proof-of-burn |
| PoC | Proof-of-capacity |
| PoCo | Proof-of-concept |
| PoET | Proof-of-elapsed-time |
| PoI | Proof-of-importance |
| PoS | Proof-of-stake |
| PoS | Proof-of-stake |
| PoUW | Proof-of-useful-work |
| PoW | Proof-of-work |
| TSP | Traveling salesman problem |
| VLSI | Very-large-scale integration |
| VRP | Vehicle routing problem |
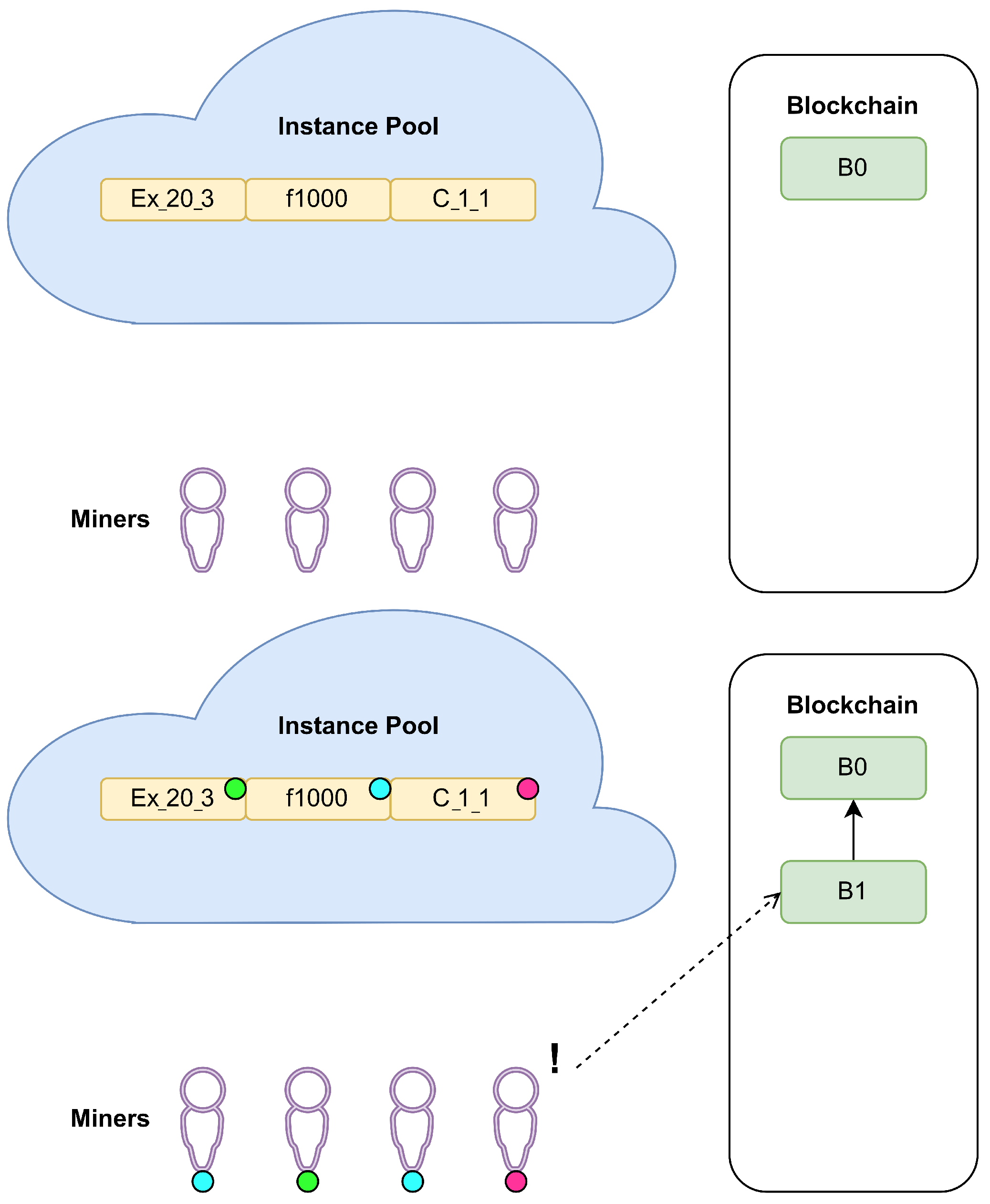
Appendix A. The Considered BC Example

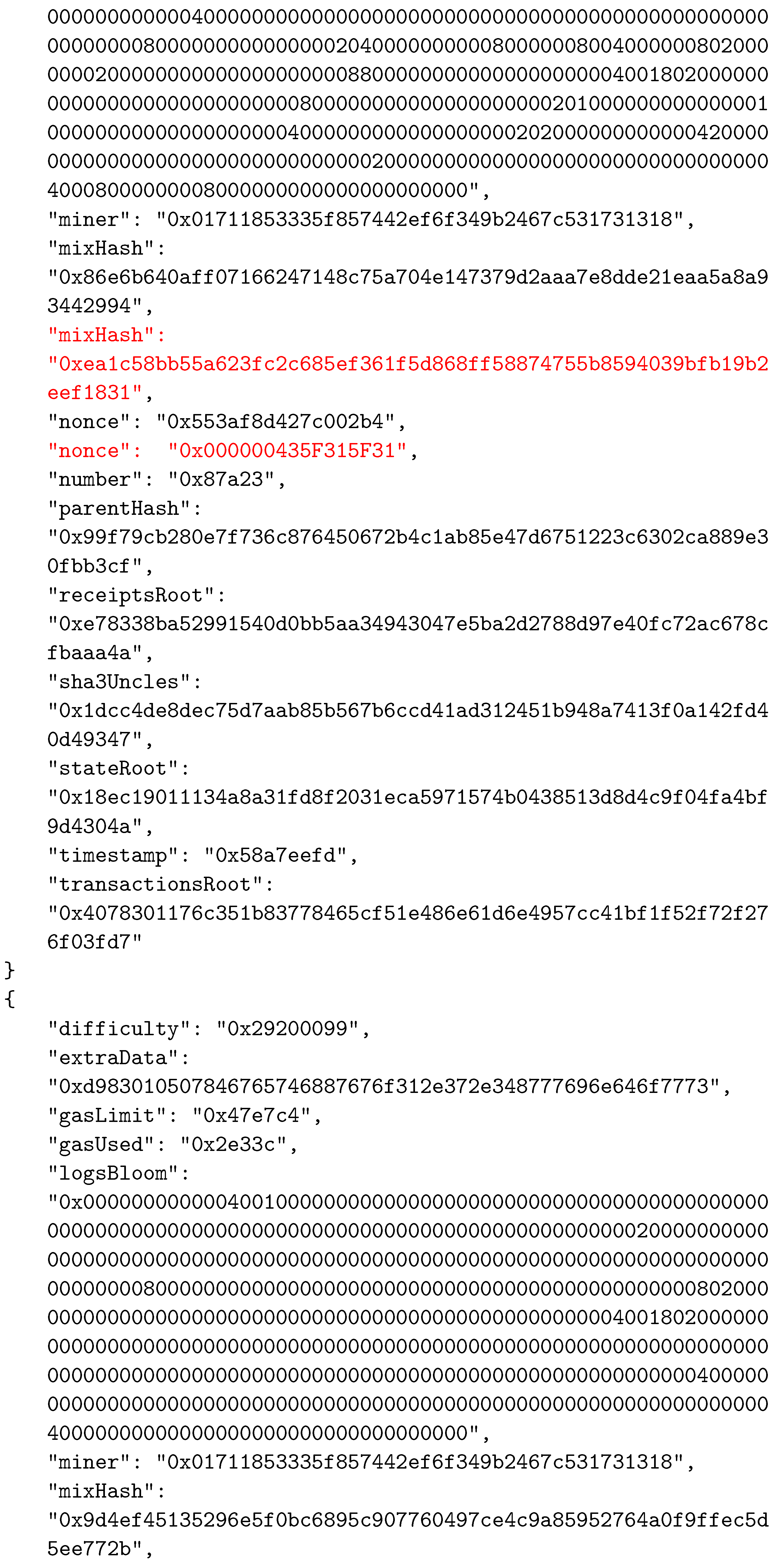

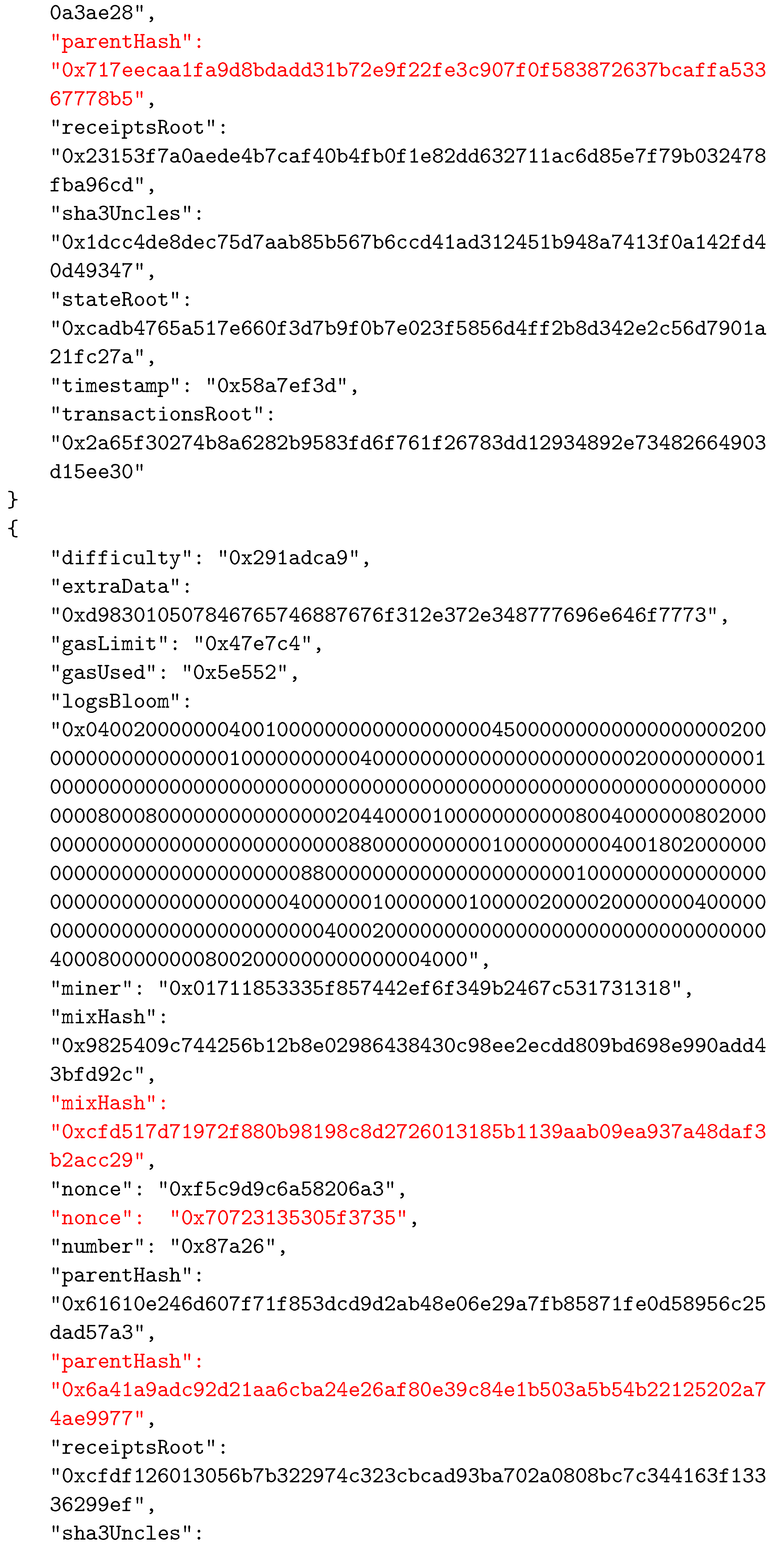
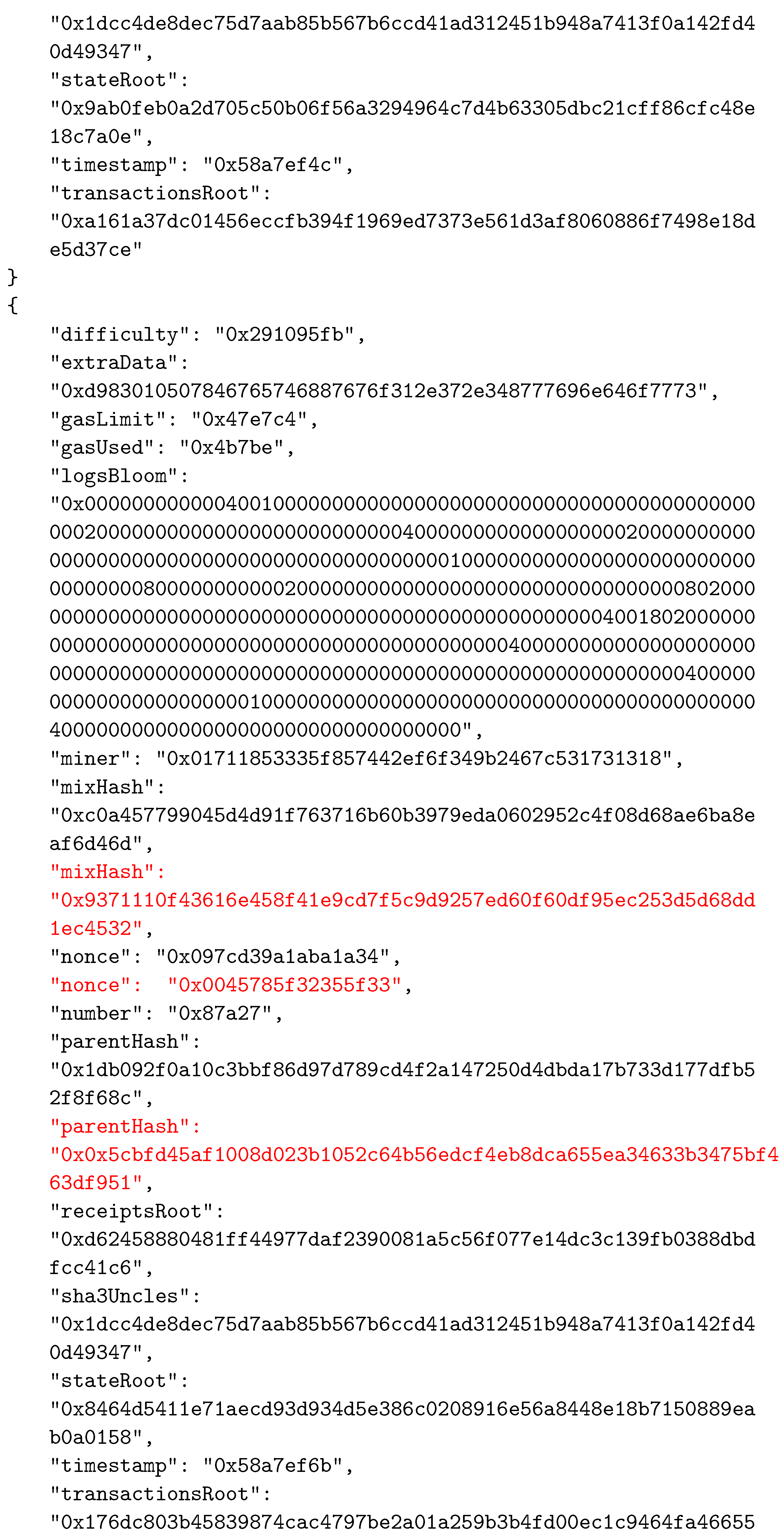


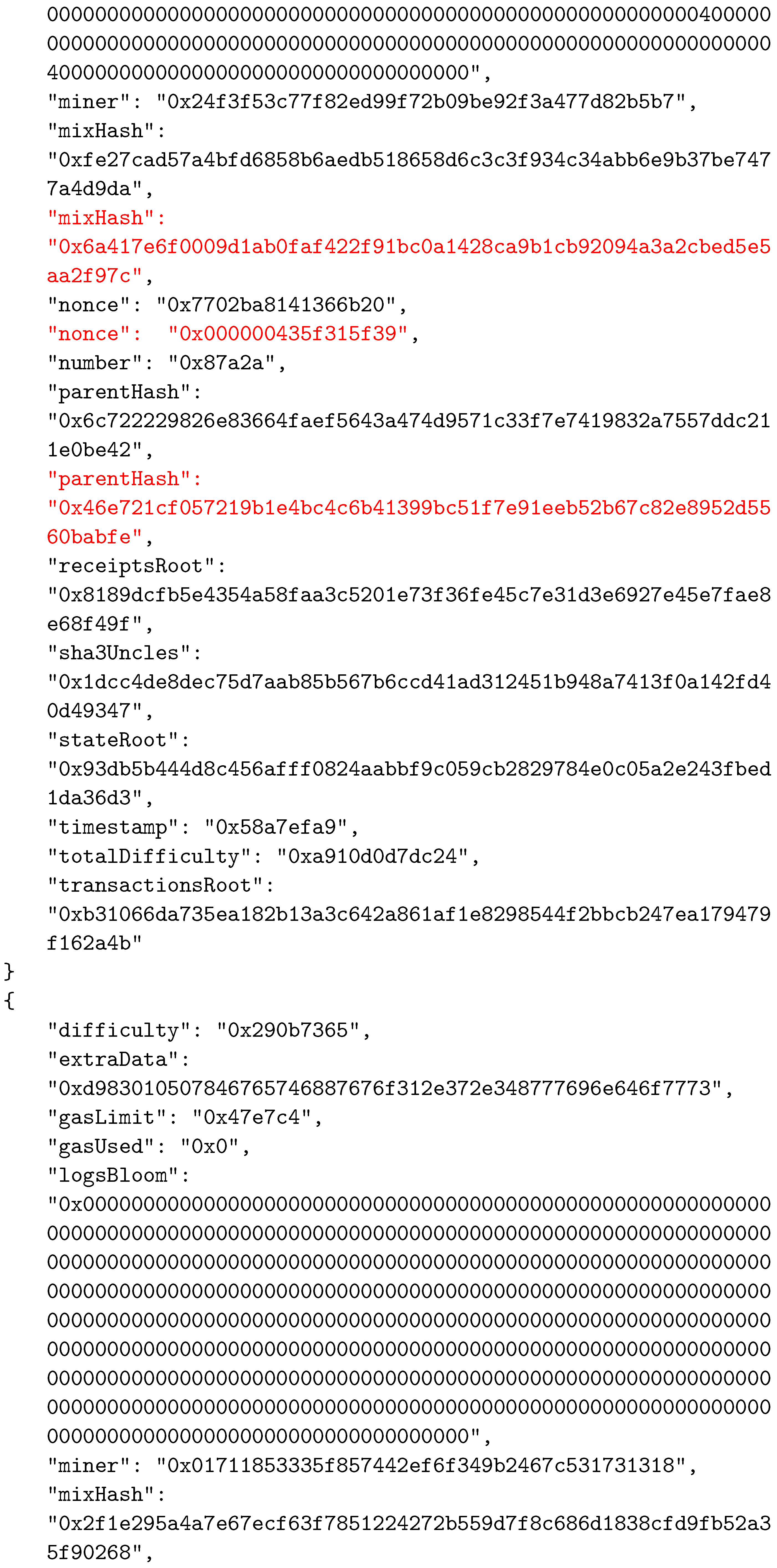
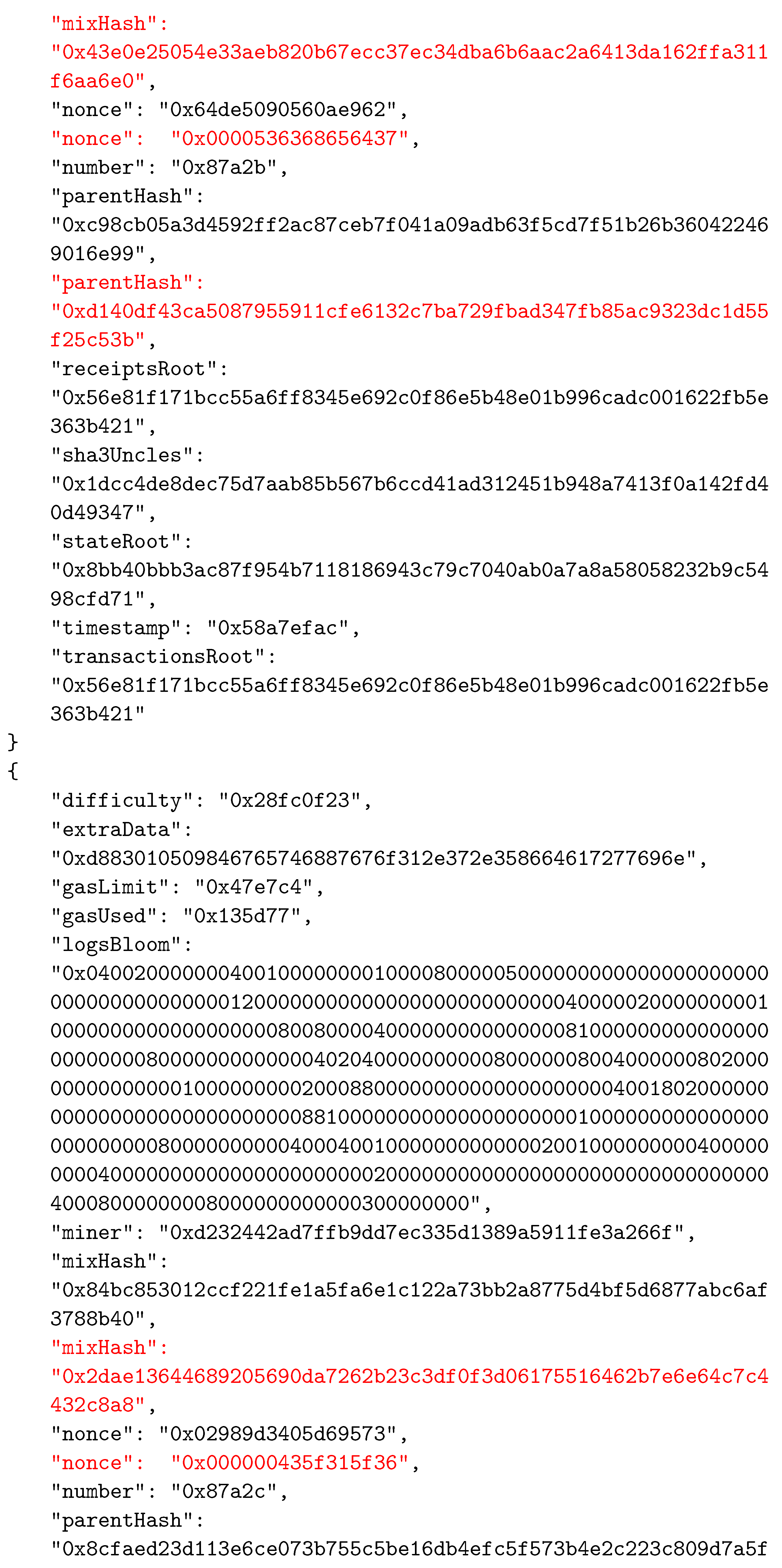
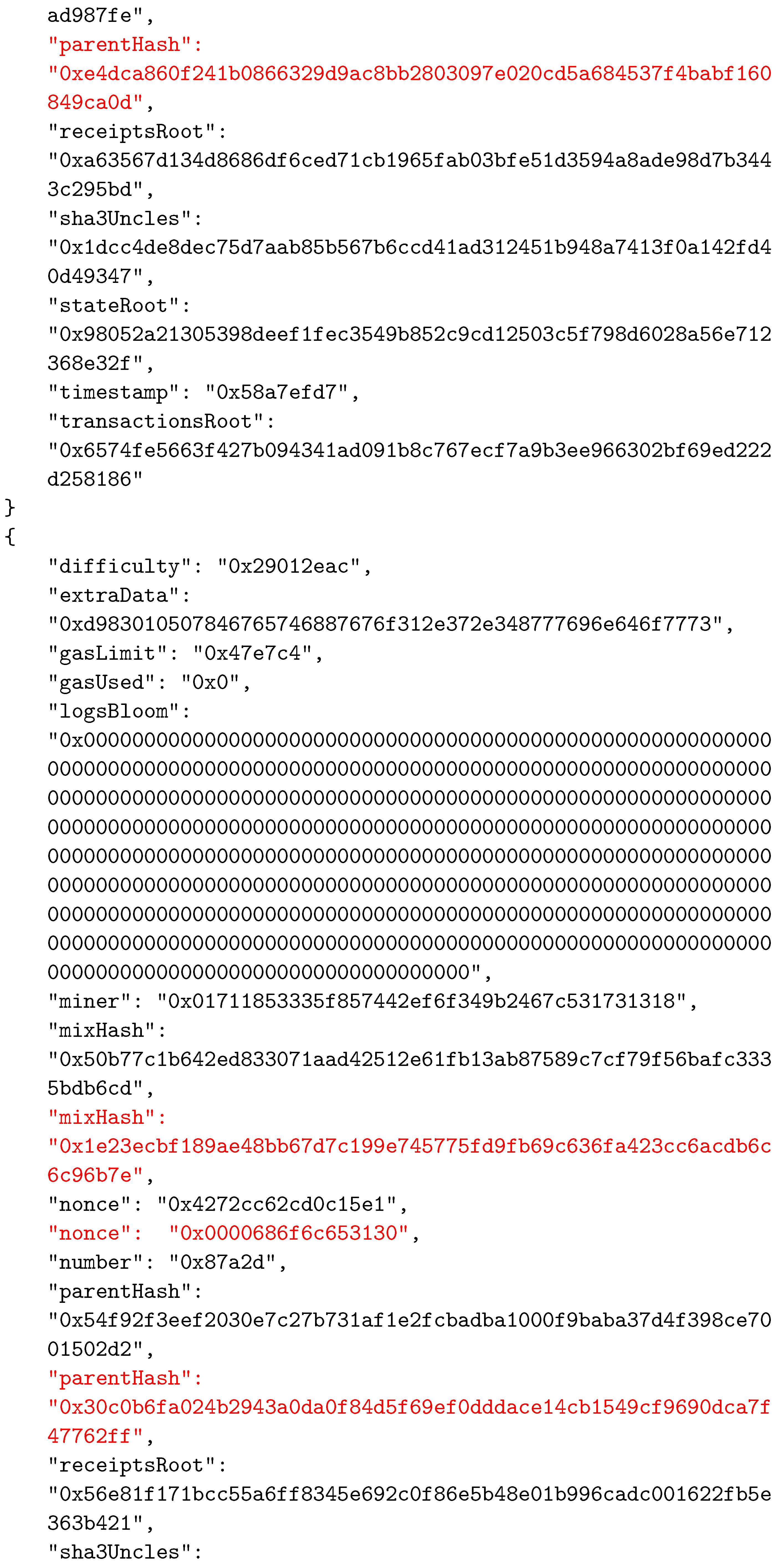

References
- Nakamoto, S. Bitcoin: A Peer-To-Peer Electronic Cash System. 2008. Available online: https://nakamotoinstitute.org/bitcoin/ (accessed on 12 May 2022).
- Yli-Huumo, J.; Ko, D.; Choi, S.; Park, S.; Smolander, K. Where is current research on blockchain technology?—A systematic review. PLoS ONE 2016, 11, e0163477. [Google Scholar] [CrossRef] [PubMed]
- Erbguth, J. Literature Review on Blockchain and Democracy. Available online: https://www.academia.edu/39122357/_Blockchain_and_democracy_by_J%C3%B6rn_Erbguth (accessed on 19 May 2022).
- Ali, M.; Ismail, A.; Elgohary, H.; Darwish, S.; Mesbah, S. A Procedure for Tracing Chain of Custody in Digital Image Forensics: A Paradigm Based on Grey Hash and Blockchain. Symmetry 2022, 14, 334. [Google Scholar] [CrossRef]
- Treiblmaier, H. Toward more rigorous blockchain research: Recommendations for writing blockchain case studies. In Blockchain and Distributed Ledger Technology Use Cases; Springer: Berlin/Heidelberg, Germany, 2020; pp. 1–31. [Google Scholar]
- Zheng, Z.; Xie, S.; Dai, H.; Chen, X.; Wang, H. An overview of blockchain technology: Architecture, consensus, and future trends. In Proceedings of the IEEE International Congress on Big Data (BigData Congress), Honolulu, HI, USA, 25–30 June 2017; pp. 557–564. [Google Scholar]
- McGinn, D.; McIlwraith, D.; Guo, Y. Towards open data blockchain analytics: A Bitcoin perspective. R. Soc. Open Sci. 2018, 5, 180298. [Google Scholar] [CrossRef] [PubMed]
- Fitzi, M.; Kiayias, A.; Panagiotakos, G.; Russell, A. Ofelimos: Combinatorial Optimization via Proof-of-Useful-WorknA Provably Secure Blockchain Protocol. IACR Cryptology ePrint Archive. 2021. Available online: https://eprint.iacr.org/2021/1379.pdf (accessed on 14 May 2022).
- Shibata, N. Proof-of-search: Combining blockchain consensus formation with solving optimization problems. IEEE Access 2019, 7, 172994–173006. [Google Scholar] [CrossRef]
- Ball, M.; Rosen, A.; Sabin, M.; Vasudevan, P.N. Proofs of Useful Work. IACR Cryptology ePrint Archive. 2017. Available online: https://eprint.iacr.org/2017/203.pdf (accessed on 4 June 2022).
- Mihaljević, M.J. A Security Enhanced Encryption Scheme and Evaluation of Its Cryptographic Security. Entropy 2019, 21, 701. [Google Scholar] [CrossRef]
- Bamakan, S.M.H.; Motavali, A.; Bondarti, A.B. A survey of blockchain consensus algorithms performance evaluation criteria. Expert Syst. Appl. 2020, 154, 113385. [Google Scholar] [CrossRef]
- Salah, K.; Rehman, M.H.U.; Nizamuddin, N.; Al-Fuqaha, A. Blockchain for AI: Review and open research challenges. IEEE Access 2019, 7, 10127–10149. [Google Scholar] [CrossRef]
- Oyinloye, D.P.; Teh, J.S.; Jamil, N.; Alawida, M. Blockchain Consensus: An Overview of Alternative Protocols. Symmetry 2021, 13, 1363. [Google Scholar] [CrossRef]
- Haouari, M.; Mhiri, M.; El-Masri, M.; Al-Yafi, K. A novel proof of useful work for a blockchain storing transportation transactions. Inf. Process. Manag. 2022, 59, 102749. [Google Scholar] [CrossRef]
- Turner, A.; Irwin, A.S.M. Bitcoin transactions: A digital discovery of illicit activity on the blockchain. J. Financ. Crime 2018, 25, 109–130. [Google Scholar] [CrossRef]
- FBI. Bitcoin Virtual Currency: Unique Features Present Distinct Challenges for Deterring Illicit Activity; Technical Report; Federal Bureau of Investigation, Report from the: Directorate of Intelligence; Cyber Intelligence Section and Criminal Intelligence Section: Washington, DC, USA, 2012. [Google Scholar]
- Raeesi, R. The Silk Road, Bitcoins and the global prohibition regime on the international trade in illicit drugs: Can this storm be weathered? Glendon J. Int. Stud. D’ÉTudes Int. Glendon 2015, 2, 8. [Google Scholar]
- Meiklejohn, S.; Pomarole, M.; Jordan, G.; Levchenko, K.; McCoy, D.; Voelker, G.M.; Savage, S. A fistful of bitcoins: Characterizing payments among men with no names. In Proceedings of the 2013 Conference on Internet Measurement Conference, Barcelona, Spain, 23–25 October 2013; pp. 127–140. [Google Scholar]
- Gonzalez, D.; Hayajneh, T. Detection and prevention of crypto-ransomware. In Proceedings of the 2017 IEEE 8th Annual Ubiquitous Computing, Electronics and Mobile Communication Conference (UEMCON), New York, NY, USA, 19–21 October 2017; pp. 472–478. [Google Scholar]
- Reid, F.; Harrigan, M. An Analysis of Anonymity in the Bitcoin System. In Security and Privacy in Social Networks; Springer: Berlin/Heidelberg, Germany, 2013; pp. 197–223. [Google Scholar]
- Chawathe, S.S. Clustering blockchain data. In Clustering Methods for Big Data Analytics; Springer: Cham, Switzerland, 2019; pp. 43–72. [Google Scholar]
- Ober, M.; Katzenbeisser, S.; Hamacher, K. Structure and anonymity of the bitcoin transaction graph. Future Internet 2013, 5, 237–250. [Google Scholar] [CrossRef]
- Otte, P.; de Vos, M.; Pouwelse, J. TrustChain: A Sybil-resistant scalable blockchain. Future Gener. Comput. Syst. 2020, 107, 770–780. [Google Scholar] [CrossRef]
- Ramljak, D.; Davidović, T.; Urošević, D.; Jakšić Krüger, T.; Matijević, L.; Todorović, M.; Jovanović, D. Combinatorial optimization for self contained blockchain: An example of useful synergy. In Proceedings of the XLVIII Symposium on Operational Research (SYM-OP-IS 2021), Banja Koviljača, Serbia, 20–23 September 2021; pp. 285–290. [Google Scholar]
- Drescher, D. Blockchain Basics: A Non-Technical Introduction in 25 Steps; Apress: New York, NY, USA, 2017. [Google Scholar]
- Lasla, N.; Alsahan, L.; Abdallah, M.; Younis, M. Green-PoW: An energy-efficient blockchain proof-of-work consensus algorithm. arXiv 2020, arXiv:2007.04086. [Google Scholar] [CrossRef]
- Cao, B.; Zhang, Z.; Feng, D.; Zhang, S.; Zhang, L.; Peng, M.; Li, Y. Performance analysis and comparison of PoW, PoS and DAG based blockchains. Digit. Commun. Netw. 2020, 6, 480–485. [Google Scholar] [CrossRef]
- King, S. Primecoin: Cryptocurrency with Prime Number Proof-of-Work. 2013. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.694.5890&rep=rep1&type=pdf (accessed on 12 June 2022).
- Tromp, J. Cuckoo cycle: A memory bound graph-theoretic proof-of-work. In Proceedings of the International Conference on Financial Cryptography and Data Security, San Juan, Puerto Rico, 26–30 January 2015; pp. 49–62. [Google Scholar]
- Biryukov, A.; Khovratovich, D. Equihash: Asymmetric proof-of-work based on the generalized birthday problem. Ledger 2017, 2, 1–30. [Google Scholar] [CrossRef]
- Aljassas, H.M.A.; Sasi, S. Performance evaluation of proof-of-work and collatz conjecture consensus algorithms. In Proceedings of the 2nd International Conference on Computer Applications & Information Security (ICCAIS), Riyadh, Saudi Arabia, 1–3 May 2019; pp. 1–6. [Google Scholar]
- Chin, Z.H.; Yap, T.T.V.; Tan, I.K.T. Genetic-Algorithm-Inspired Difficulty Adjustment for Proof-of-Work Blockchains. Symmetry 2022, 14, 609. [Google Scholar] [CrossRef]
- Loe, A.F.; Quaglia, E.A. Conquering generals: An NP-hard proof of useful work. In Proceedings of the 1st Workshop on Cryptocurrencies and Blockchains for Distributed Systems, Munich, Germany, 15 June 2018; pp. 54–59. [Google Scholar]
- Syafruddin, W.A.; Dadkhah, S.; Köppen, M. Blockchain Scheme Based on Evolutionary Proof of Work. In Proceedings of the 2019 IEEE Congress on Evolutionary Computation (CEC), Wellington, New Zealand, 10–13 June 2019; pp. 771–776. [Google Scholar]
- Li, W. Adapting Blockchain Technology for Scientific Computing. arXiv 2018, arXiv:1804.08230. [Google Scholar]
- Lihu, A.; Du, J.; Barjaktarevic, I.; Gerzanics, P.; Harvilla, M. A Proof of Useful Work for Artificial Intelligence on the Blockchain. arXiv 2020, arXiv:2001.09244. [Google Scholar]
- Chenli, C.; Li, B.; Shi, Y.; Jung, T. Energy-recycling blockchain with proof-of-deep-learning. In Proceedings of the 2019 IEEE International Conference on Blockchain and Cryptocurrency (ICBC), Seoul, Korea, 14–17 May 2019; pp. 19–23. [Google Scholar]
- Li, B.; Chenli, C.; Xu, X.; Shi, Y.; Jung, T. DLBC: A Deep Learning-Based Consensus in Blockchains for Deep Learning Services. arXiv 2020, arXiv:1904.07349v2. [Google Scholar]
- Li, B.; Chenli, C.; Xu, X.; Jung, T.; Shi, Y. Exploiting computation power of blockchain for biomedical image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019; pp. 2802–2811. [Google Scholar]
- Qiu, C.; Wang, X.; Yao, H.; Du, J.; Yu, F.R.; Guo, S. Networking Integrated Cloud-Edge-End in IoT: A Blockchain-Assisted Collective Q-Learning Approach. IEEE Internet Things J. 2020, 8, 12694–12704. [Google Scholar] [CrossRef]
- Baldominos, A.; Saez, Y. Coin. AI: A proof-of-useful-work scheme for blockchain-based distributed deep learning. Entropy 2019, 21, 723. [Google Scholar] [CrossRef] [PubMed]
- Chatterjee, K.; Goharshady, A.K.; Pourdamghani, A. Hybrid mining: Exploiting blockchain’s computational power for distributed problem solving. In Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing, Limassol, Cyprus, 8–12 April 2019; pp. 374–381. [Google Scholar]
- Philippopoulos, P.; Ricottone, A.; Oliver, C.G. Difficulty Scaling in Proof of Work for Decentralized Problem Solving. arXiv 2019, arXiv:1911.00435. [Google Scholar] [CrossRef]
- Davidović, T.; Todorović, M.; Ramljak, D.; Jakšić Krüger, T.; Matijević, L.; Jovanović, D.; Urošević, D. COCP: Blockchain Proof-of-Useful-Work Leveraging Real-Life Applications. In Proceedings of the International Conference on Blockchain Computing and Applications (BCCA 2022), San Antonio, TX, USA, 5–7 September 2022. [Google Scholar]
- Pinedo, M.L. Scheduling: Theory, Algorithms, and Systems; Springer Science & Business Media: Cham, Switzerland, 2012. [Google Scholar]
- Davidović, T.; Šelmić, M.; Teodorović, D.; Ramljak, D. Bee colony optimization for scheduling independent tasks to identical processors. J. Heuristics 2012, 18, 549–569. [Google Scholar] [CrossRef]
- Frachtenberg, E.; Schwiegelshohn, U. Preface. In Proceedings of the 15th Internation Workshop, JSSPP 2010, Job Scheduling Strategies for Parallel Processing, Atlanta, GA, USA, 23 April 2010; pp. V–VII. [Google Scholar]
- Graham, R.L. Bounds on multiprocessing timing anomalies. SIAM J. Appl. Math. 1969, 17, 416–429. [Google Scholar] [CrossRef]
- Mokotoff, E. An exact algorithm for the identical parallel machine scheduling problem. Eur. J. Oper. Res. 2004, 152, 758–769. [Google Scholar] [CrossRef]
- Mrad, M.; Souayah, N. An Arc-Flow Model for the Makespan Minimization Problem on Identical Parallel Machines. IEEE Access 2018, 6, 5300–5307. [Google Scholar] [CrossRef]
- Unlu, Y.; Mason, S.J. Evaluation of mixed integer programming formulations for non-preemptive parallel machine scheduling problems. Comput. Ind. Eng. 2010, 58, 785–800. [Google Scholar] [CrossRef]
- Fanjul-Peyro, L.; Ruiz, R. Iterated greedy local search methods for unrelated parallel machine scheduling. Eur. J. Oper. Res. 2010, 207, 55–69. [Google Scholar] [CrossRef]
- Paletta, G.; Ruiz-Torres, A.J. Partial solutions and multifit algorithm for multiprocessor scheduling. J. Math. Model. Algorithms Oper. Res. 2015, 14, 125–143. [Google Scholar] [CrossRef]
- Alharkan, I.; Bamatraf, K.; Noman, M.A.; Kaid, H.; Nasr, E.S.A.; El-Tamimi, A.M. An order effect of neighborhood structures in variable neighborhood search algorithm for minimizing the makespan in an identical parallel machine scheduling. Math. Probl. Eng. 2018, 2018, 3586731. [Google Scholar] [CrossRef]
- Laha, D.; Gupta, J.N. An improved cuckoo search algorithm for scheduling jobs on identical parallel machines. Comput. IE 2018, 126, 348–360. [Google Scholar] [CrossRef]
- Kamaraj, S.; Saravanan, M. Optimisation of identical parallel machine scheduling problem. Int. J. Rapid Manuf. 2019, 8, 123–132. [Google Scholar] [CrossRef]
- Ostojić, D.; Davidović, T.; Jakšić Krüger, T.; Ramljak, D. Comparative Analysis of Heuristic Approaches to P||Cmax. In Proceedings of the 11th International Conference on Operations Research and Enterprise Systems, ICORES 2021, Online, 4–6 February 2021; pp. 352–359. [Google Scholar]
- Graham, R.L.; Lawler, E.L.; Lenstra, J.K.; Kan, A.R. Optimization and approximation in deterministic sequencing and scheduling: A survey. In Annals of Discrete Mathematics; Elsevier: Amsterdam, The Netherlands, 1979; Volume 5, pp. 287–326. [Google Scholar]
- Stanković, U.; Matijević, L.; Davidović, T. Mathematical Models for the Weighted Scheduling Problem with Deadlines and Release Times. In Proceedings of the XLVIII Symposium on Operational Research (SYM-OP-IS 2021), Banja Koviljača, Serbia, 20–23 September 2021; pp. 327–332. [Google Scholar]
- Matijević, L.; Stanković, U.; Davidović, T. General Variable Neighborhood Search for the Weighted Scheduling Problem with Deadlines and Release Times. In Proceedings of the XLVIII Symposium on Operational Research (SYM-OP-IS 2021), Banja Koviljača, Serbia, 20–23 September 2021; pp. 207–212. [Google Scholar]
- Golden, B.L.; Raghavan, S.; Wasil, E.A. The Vehicle Routing Problem: Latest Advances and NEW Challenges; Springer: Berlin/Heidelberg, Germany, 2008; Volume 43. [Google Scholar]
- Toth, P.; Vigo, D. The Vehicle Routing Problem; SIAM: Philadelphia, PA, USA, 2002. [Google Scholar]
- Toth, P.; Vigo, D. Vehicle Routing: Problems, Methods, and Applications; SIAM: Philadelphia, PA, USA, 2014. [Google Scholar]
- Dantzig, G.B.; Ramser, J.H. The truck dispatching problem. Manag. Sci. 1959, 6, 80–91. [Google Scholar] [CrossRef]
- Ilin, V.; Matijević, L.; Davidović, T.; Pardalos, P.M. Asymmetric Capacitated Vehicle Routing Problem with Time Window. In Proceedings of the XLV Symposium on Operations Research (SYM-OP-IS 2018), Zlatibor, Serbia, 16–19 September 2018; pp. 174–179. [Google Scholar]
- Matijević, L.; Davidović, T.; Ilin, V.; Pardalos, P.M. General Variable Neighborhood Search for Asymmetric Vehicle Routing Problem. In Proceedings of the XLVI Symposium on Operations Research (SYM-OP-IS 2019), Kladovo, Serbia, 15–18 September 2019. [Google Scholar]
- Matijević, L.; Ilin, V.; Davidović, T.; Jakšić Krüger, T.; Pardalos, P.M. Asymmetric Vehicle Routing Problem with Time and Capacity Constraints: Exact and Heuristic approaches. 2020; submitted. [Google Scholar]
- Kilani, Y.; Bsoul, M.; Alsarhan, A.; Al-Khasawneh, A. A survey of the satisfiability-problems solving algorithms. Int. J. Adv. Intell. Paradig. 2013, 5, 233–256. [Google Scholar] [CrossRef]
- Xu, H.; Rutenbar, R.A.; Sakallah, K. sub-SAT: A formulation for relaxed boolean satisfiability with applications in routing. IEEE Trans.-Comput.-Aided Des. Integr. Circuits Syst. 2003, 22, 814–820. [Google Scholar] [CrossRef]
- Strickland, D.M.; Barnes, E.; Sokol, J.S. Optimal protein structure alignment using maximum cliques. Oper. Res. 2005, 53, 389–402. [Google Scholar] [CrossRef]
- Li, C.M.; Quan, Z. An efficient branch-and-bound algorithm based on maxsat for the maximum clique problem. In Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence, Atlanta, GA, USA, 11–15 July 2010. [Google Scholar]
- Vasquez, M.; Hao, J.K. A “logic-constrained” knapsack formulation and a tabu algorithm for the daily photograph scheduling of an earth observation satellite. Comput. Optim. Appl. 2001, 20, 137–157. [Google Scholar] [CrossRef]
- Jose, M.; Majumdar, R. Bug-Assist: Assisting fault localization in ANSI-C programs. In Proceedings of the International Conference on Computer Aided Verification, Snowbird, UT, USA, 14–20 July 2011; pp. 504–509. [Google Scholar]
- Jabbour, S.; Mhadhbi, N.; Raddaoui, B.; Sais, L. SAT-based models for overlapping community detection in networks. Computing 2020, 102, 1275–1299. [Google Scholar] [CrossRef]
- Morgado, A.; Heras, F.; Liffiton, M.; Planes, J.; Marques-Silva, J. Iterative and core-guided MaxSAT solving: A survey and assessment. Constraints 2013, 18, 478–534. [Google Scholar] [CrossRef]
- Wood, G. Ethereum: A Secure Decentralised Generalised Transaction Ledger Berlin Version b8ffc51. 2022. Available online: https://ethereum.github.io/yellowpaper/paper.pdf (accessed on 6 May 2022).
- Go Ethereum: Official Go Implementation of the Ethereum Protocol. Available online: https://geth.ethereum.org/ (accessed on 23 May 2022).
- Hutter, F.; Hamadi, Y.; Hoos, H.H.; Leyton-Brown, K. Performance prediction and automated tuning of randomized and parametric algorithms. In Proceedings of the 12th International Conference on Principles and Practice of Constraint Programming—CP 2006, Nantes, France, 25–29 September 2006; pp. 213–228. [Google Scholar]
- Hutter, F.; Xu, L.; Hoos, H.H.; Leyton-Brown, K. Algorithm runtime prediction: Methods & evaluation. Artif. Intell. 2014, 206, 79–111. [Google Scholar]
- Shalini, S.; Santhi, H. A survey on various attacks in bitcoin and cryptocurrency. In Proceedings of the 2019 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 4–6 April 2019; pp. 220–224. [Google Scholar]
- Saad, M.; Spaulding, J.; Njilla, L.; Kamhoua, C.A.; Nyang, D.; Mohaisen, A. Overview of attack surfaces in blockchain. In Blockchain for Distributed Systems Security; John Wiley & Sons: Hoboken, NJ, USA, 2019; pp. 51–66. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Categories | Consensus Algorithms |
|---|---|
| Based on effort or work | proof-of-benefit, proof-of-phone, proof-of-learning, proof-of-sincerity, proof-of-accuracy, proof-of-adjourn, proof-of-search, proof-of-evolution, and proof-of-experience |
| Based on wealth or resources | proof-of-participation-and-fees |
| Based on past behavior or reputation | proof-of-familiarity, proof-of-reputation, and proof-of-reputation X |
| Based on representation | proof-of-vote and CHB/CHBD |
| Data Field | Description |
|---|---|
| difficulty | A number that corresponds to the difficulty of the problem that is being solved for the current block. It is adjusted to ensure constant frequency in the addition of new blocks to the system. |
| extraData | A byte array that can contain any data related to the block, with a maximum length of 32 bytes. |
| gasLimit | A number that is the current limit of gas spending per block. Every transaction that is part of the block has a certain gas value, and their total gas value must be less than or equal to this number |
| gasUsed | Total value of gas spent by transactions of this block. |
| logsBloom | Represents the Bloom filter that consists of information that can be indexed, that are found in every log entry of the transactions. |
| miner | 160-bit Ethereum address of the miner who mined the block. |
| number | Ordinal number of the block. |
| parentHash | The hash value of the parent block’s header. |
| receiptsRoot | Hash of the root node of the trie that represents transaction receipts. |
| sha3uncles | The hash value of the uncle’s list for this block. Uncle blocks represent the blocks that were mined at the same time as the parent of the current block, but which did not become part of the canonical chain. However, using this field, uncle blocks are still recorded and the miners that created those blocks receive some reward. |
| stateRoot | The hash value of the state trie’s root node. |
| timestamp | A value that represents the Unix time at the moment when the block was created. |
| transactionRoot | The hash value of the root node of the trie containing all of the block’s transactions. |
| mixHash | 256-bit hash that, along with the nonce, is used to prove that the corresponding problem was solved during the mining process. |
| nonce | 64-bit value representing the solution of the mining problem. |
| Block | Pool of Instances | Solved Instances (Time) | # Solved |
|---|---|---|---|
| Ex_20_3, f1000, C_1_1 | Ex_20_3 (0.0027), f1000 (0.5828), C_1_1 (1.4114) | 3 | |
| C_1_3, f2000, Ex_22_2, C_1_4, Sched5, f600 | Ex_22_2 (0.0248) | 4 | |
| C_1_3, f2000, C_1_4, Sched5, f600, Sched4, Sched8 | f2000 (1.4957), Sched5 (0.0012), C_1_4 (1.2769) | 7 | |
| C_1_3, f600, Sched4, Sched8, pr150_75, hole10, Ex_25_3, C_1_9 | pr150_75 (0.3384), Sched8 (0.0002) | 9 | |
| C_1_3, f600, Sched4, hole10, Ex_25_3, C_1_9, Sched1 | Ex_25_3 (0.0444) | 10 | |
| C_1_3, f600, Sched4, hole10, C_1_9, Sched1, Ex_19_2, C_1_7, Sched7 | Ex_19_2 (0.0020), C_1_3 (0.7260) | 12 | |
| f600, Sched4, hole10, C_1_9, Sched1, C_1_7, Sched7, Ex_15_2, Ex_30_3, C_1_2 | C_1_2(1.4992) | 13 | |
| f600, Sched4, hole10, C_1_9, Sched1, C_1_7, Sched7, Ex_15_2, Ex_30_3 | C_1_9 (0.0003), Sched4 (0.0001), Sched1 (0.0001), Ex_15_2 (0.0050) | 17 | |
| f600, hole10, C_1_7, Sched7, Ex_30_3, Sched6, C_1_5, Sched10 | Sched7 (0.0002), f600 (0.4741), C_1_7 (0.5858) | 20 | |
| hole10, Ex_30_3, Sched6, C_1_5, Sched10, C_1_6, Sched2, Sched3, C_1_8, Sched9 | C_1_6 (0.8465), Sched6 (0.0007), Ex_30_3 (0.1481) | 23 | |
| hole10, C_1_5, Sched10, Sched2, Sched3, C_1_8, Sched9 | hole10 (0.1506), Sched2 (0.0008) | 25 |
| Challenge ID | Short Name | Long Name |
|---|---|---|
| 1 | Submission Privileges | Who is allowed to submit the CO problem instances |
| 2 | Problem Range | Which CO problems are allowed for submitting the corresponding instances |
| 3 | Problem–Block Correspondence | The correspondence between CO problem instances and the composed block |
| 4 | Ensuring Usefulness | The number of CO problem instances should be adequate to ensure usefulness and make the block–instance correspondence meaningful |
| 5 | Controlling Hardness | The hardness of CO problem instances should be controlled |
| 6 | Efficient Hardware Exploitation | Efficient exploitation of dedicated hardware already owned by miners |
| 7 | Data Management and Malicious Behavior | Addressing various types of malicious behavior in managing data |
| 8 | Increasing Efficiency | Increasing the efficiency of the whole system by distributing the work among the available resources of each miner or among several miners (comprising the pool of miners) and considering the arising security issues |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Todorović, M.; Matijević, L.; Ramljak, D.; Davidović, T.; Urošević, D.; Jakšić Krüger, T.; Jovanović, Đ. Proof-of-Useful-Work: BlockChain Mining by Solving Real-Life Optimization Problems. Symmetry 2022, 14, 1831. https://doi.org/10.3390/sym14091831
Todorović M, Matijević L, Ramljak D, Davidović T, Urošević D, Jakšić Krüger T, Jovanović Đ. Proof-of-Useful-Work: BlockChain Mining by Solving Real-Life Optimization Problems. Symmetry. 2022; 14(9):1831. https://doi.org/10.3390/sym14091831
Chicago/Turabian StyleTodorović, Milan, Luka Matijević, Dušan Ramljak, Tatjana Davidović, Dragan Urošević, Tatjana Jakšić Krüger, and Đorđe Jovanović. 2022. "Proof-of-Useful-Work: BlockChain Mining by Solving Real-Life Optimization Problems" Symmetry 14, no. 9: 1831. https://doi.org/10.3390/sym14091831
APA StyleTodorović, M., Matijević, L., Ramljak, D., Davidović, T., Urošević, D., Jakšić Krüger, T., & Jovanović, Đ. (2022). Proof-of-Useful-Work: BlockChain Mining by Solving Real-Life Optimization Problems. Symmetry, 14(9), 1831. https://doi.org/10.3390/sym14091831