
Optimizing the Routing of Urban Logistics by Context-Based Social Network and Multi-Criteria Decision Analysis

Abstract
1. Introduction
- To solve the product delivery delay problems in the urban logistics areas, this work proposes a novel approach of using symmetry/asymmetry traffic context data and multi-criteria decision analysis to optimize vehicle-route selection as part of urban-logistical planning.
- The paper uses data mining technologies to process the traffic context data from official urban transportation databases and metadata of Google Maps route planning in order to construct a context-based social network. Since the traffic features and routing criteria have symmetry/asymmetry properties to influence the decision of path selection, we adopt multi-criteria decision analysis to generate a ranking of candidate paths based on an evaluation of traffic data in context-based social networks to recommend to the deliveryman. The deliveryman can select a reasonable path for delivering products according to the ranking of candidate paths.
- The experimental results show that the work’s precision is 79.65%, recall is 80.70%, and F1-score is 80.17% in order to prove the vehicle-route recommendation effectiveness. It helps deliverymen send products as soon as possible to customers to retain the quality, especially in cold-chain logistics. The paper optimizes traffic-routing solutions for improved service quality of urban logistics in smart cities.
2. Related Work
2.1. Points-of-Interest (POI) Recommendations in Location-Based Social Networks (LBSNs)
2.2. Multi-Criteria Decision Analysis (MCDA)
3. Problem Definition
3.1. Routing Problems in Urban Logistics
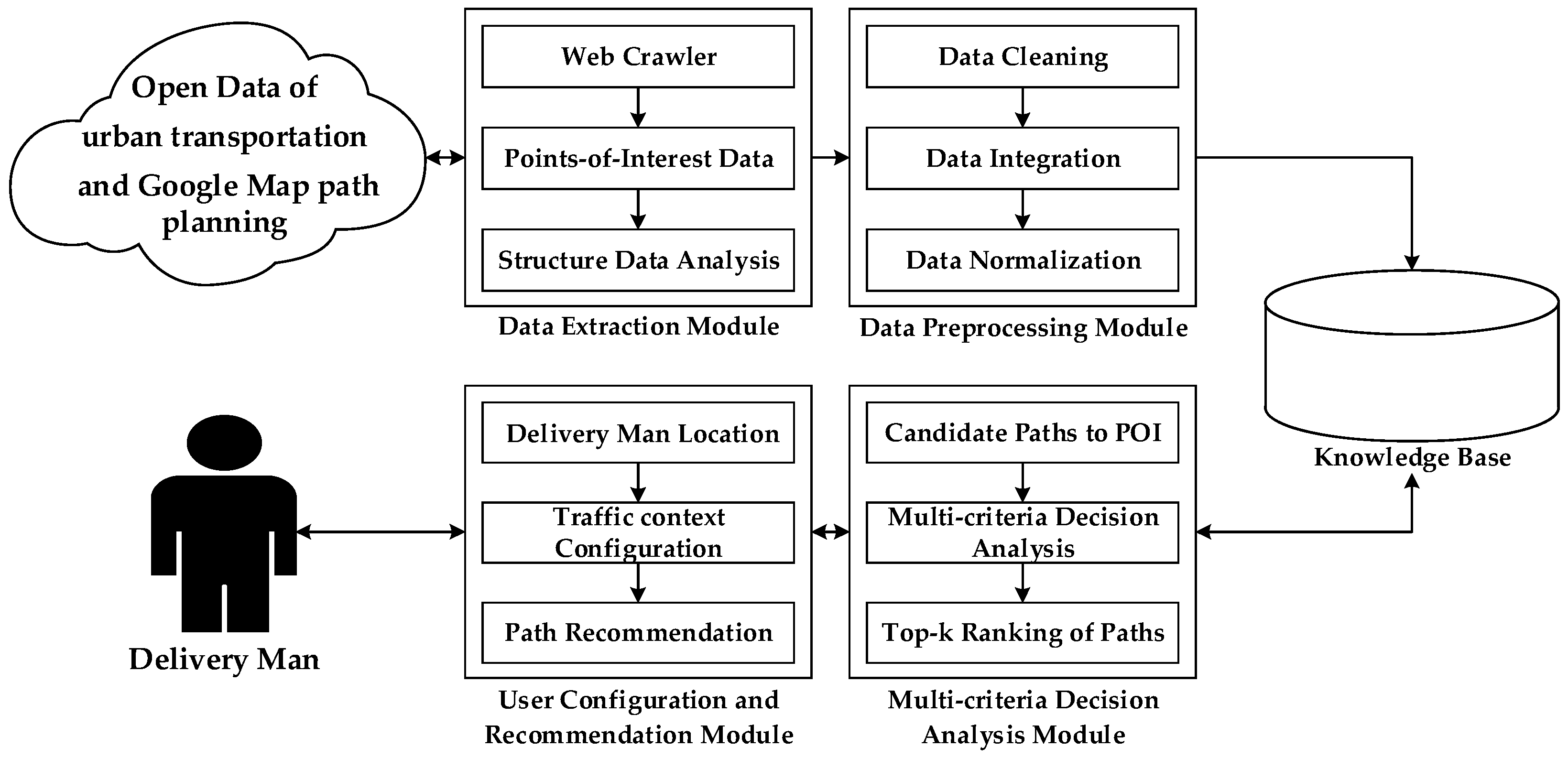
3.2. A Novel System to Optimize Traffic-Route Selection in Urban Logistics
| Data extraction algorithm: collects the symmetry/asymmetry information on the logistics destination, referred to as points-of-interest (POI), which is required by the deliveryman. Parameter definition is shown as follows. | |
| OpenDataUrl | The URL of open data website. |
| UrbantransportationUrl | The URL of urban transportation website. |
| GoogleMapUrl | The URL of Google Maps website. |
| POI | Data extraction from cloud servers. |
| urlSet | A URL set of the open data websites. |
| POISet | A set of the POI. |
| POIInformation | Information on POI. |
| POIData | A set of POI data. |
| JSONKey | The key of JSON. |
| JSONKeySet | A set of JSONKey. |
| Input: OpenDataUrl, UrbantransportationUrl, GoogleMapUrl Output: POIData
| |
| Data preprocessing algorithm: analyzes the POI description and relevant symmetry/asymmetry attributes to remove meaningless information. Parameter definition is shown as follows. | |
| POIData | A set of POI data. |
| DCPOIDataSet | A set of POI data after data cleaning. |
| DCPOIData | POI data after data cleaning. |
| UrbantransportationData | Urban transportation POI data after data cleaning. |
| GoogleMapData | Google Maps POI data after data cleaning. |
| DIPOIDataSet | A set of POI data after data integration. |
| DIPOIData | Symmetry/asymmetry POI data after data integration. |
| Input: POIData Output: DIPOIDataSet
| |
| Multi-criteria decision analysis algorithm: generates a ranking of candidate paths based on the evaluation of criteria in the context of traffic conditions. Parameter definition is shown as follows. | |
| CandidatePathSet | A data set of the candidate path with traffic context values regarding issues for a deliveryman. |
| RCandidatePathSet | A data set of the candidate path with normalized traffic context values. |
| WeightSet | A criteria weight set by the deliveryman configuration. |
| RankingOrder | Ranking order from use of a multi-criteria decision method. |
| MCDACandidatePathSet | A data set of the paths from use of multi-criteria decision analysis. |
| Input: CandidatePathSet, WeightSet Output: MCDACandidatePathSet
| |
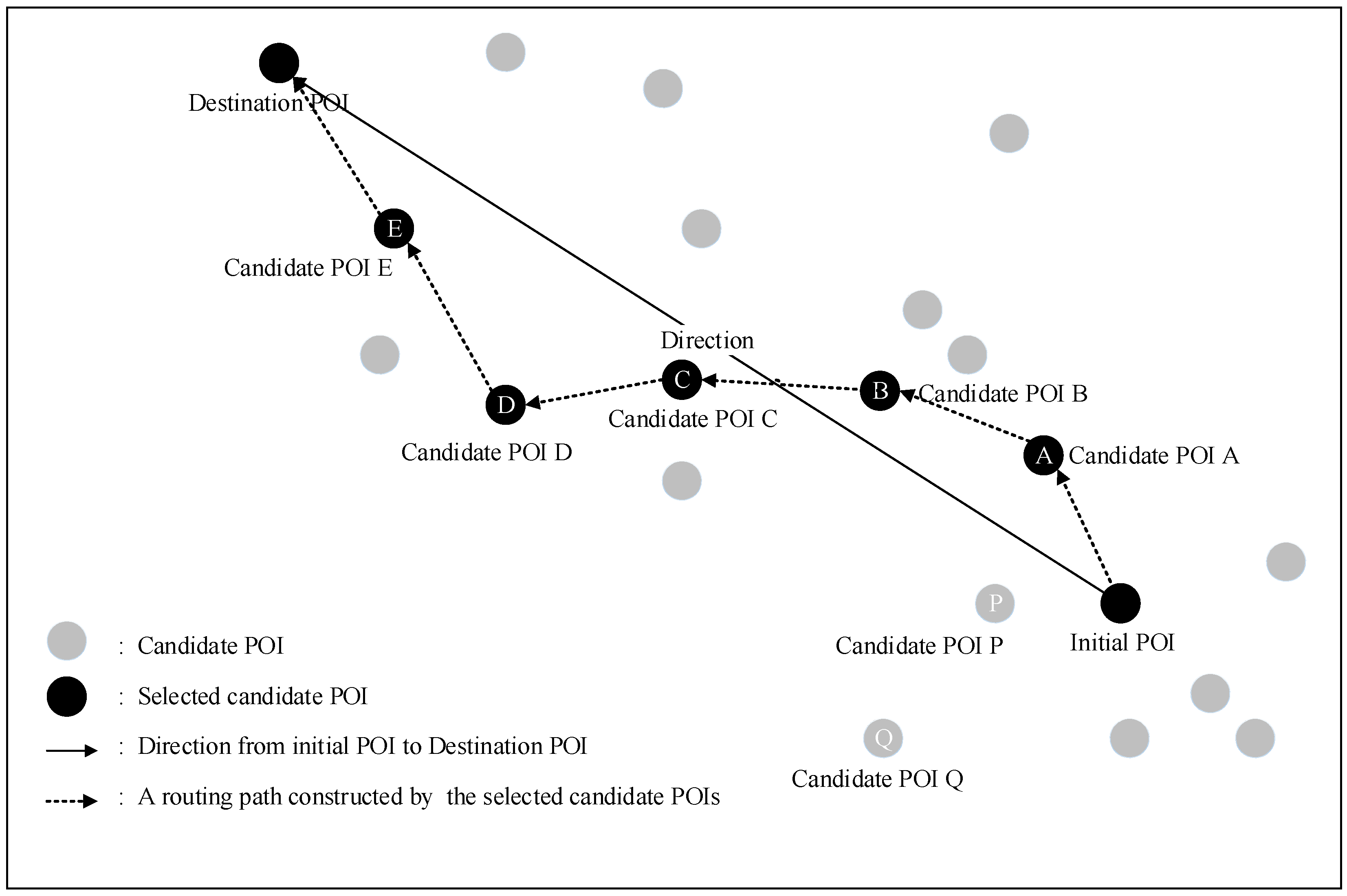
3.3. Utility Model for Candidate Paths
3.4. Discovering a Selection Order via the VIKOR Method
- Step 1: Construct the initial matrix , as shown in Equation (2).where indicates the number of candidate paths, indicates the number of candidate path context items.
- Step 2: Calculate the column vector by Equation (3) and normalize the matrix to obtain a normalized matrix .
- Step 3: Determine the ideal value by Equation (4) and the worst value by Equation (5). If the th function represents a benefit then:
- Step 4: Set the weight of the evaluation criteria by Equation (6). The weight matrix is configured by the user in this work.
- Step 5: Calculate the group utility of candidate path by Equation (7) and the individual regret of candidate path by Equation (8) where are the weights of criteria, expressing their relative importance.
- Step 6: Compute the values by Equation (9) where is introduced as weight of the strategy of the maximum group utility, here = 0.5.
- Step 7: Rank the candidate paths, sorting by the values , R, and , in decreasing order. The results are three ranking lists.
- Step 8: Propose as a compromise solution the candidate path () which is ranked the best by the measure (minimum) if the following two conditions are satisfied:
- Condition 1: Acceptable advantage.
- where is the candidate path with the second position in the ranking list by ; ; is the number of candidate paths.
- Condition 2: Acceptable stability in decision-making.
- Candidate path must also be the best ranked by and/or . This compromise solution is stable within a decision-making process, which could be: “voting by majority rule” (when is needed), or “by consensus” , or “with veto” (). Here, is the weight of the decision-making strategy of the maximum group utility.
3.5. Evaluation of System Framework
4. Case Study on Traffic-Routing Recommendation for Deliverymen
- Step 1: Construct the initial matrix where 10 indicates the number of candidate paths and 4 indicates the number of candidate path items.
- Step 2: Calculate the column vector by Equation (3) and normalize the matrix to obtain a normalized matrix .
- Step 3: Determine the ideal value by Equation (4) and the worst value by Equation (5). If the th function represents a benefit, then:
- Step 4: Set the weight of the evaluation criteria by Equation (6). The weight matrix is configured by the user in this work.
- Step 5: Calculate the group utility of candidate path by Equation (7) and the individual regret of candidate path by Equation (8) where are the weights of criteria, expressing their relative importance.
- Step 6: Compute the values by Equation (9) where is introduced as the weight of the strategy of the maximum group utility, here = 0.5.
- Step 7: Rank the candidate paths, sorting by the values S, R, and Q, in decreasing order. The results are three ranking lists.
- Step 8: Propose as a compromise solution the candidate path (), which is ranked the best by the measure (minimum) if the following two conditions are satisfied: in the case study, the top-k ranking order “P10→P09→P02→P04→P08→P01→P07→P05→P03→P06” is produced. The traffic path P10 is a reasonable path for the deliveryman because its ranking order is the first.
5. Experimental Results
5.1. Path Rankings from Different MCDA Methods
5.2. Evaluations and Discussions
6. Conclusions
- To solve the product delivery delay problems in the urban logistics areas, this work proposes a novel systematic framework of using symmetry/asymmetry traffic context data and multi-criteria decision analysis to optimize vehicle-route selection as part of urban-logistical planning.
- The paper uses data mining technologies to process the huge amount of traffic context data from official urban transportation databases and metadata of Google Maps route planning in order to construct a context-based social network. Since the traffic features and routing criteria have symmetry/asymmetry properties to influence the decision of path selection, we adopt multi-criteria decision analysis to generate a ranking of candidate paths based on an evaluation of traffic data in context-based social networks to recommend to the deliveryman. The deliveryman can select a reasonable path for delivering products according to the ranking of candidate paths.
- The experimental results show the path recommendation of the work’s precision is 79.65%, recall is 80.70%, and F1-score is 80.17% to prove the vehicle-route recommendation effectiveness. It helps deliverymen send products as soon as possible to customers to retain the quality, especially in cold-chain logistics. The paper optimizes traffic-routing solutions for improved service quality of urban logistics in smart cities.
- Expiry of collected data may cause the recommendation to have unexpected results. The open data in official urban transportation databases may update regularly but not immediately.
- If the traffic features are not contained in official urban transportation databases and metadata of Google Maps route planning, we cannot design the comprehensive criteria to evaluate, e.g., weather influence, traffic incidents, temporary road construction, etc. This work cannot handle complex real-time traffic features.
- This work does not consider the adaptive mechanism to adjust the weight configuration of criteria in multi-criteria decision analysis. The weight configuration of criteria may influence the path recommendation.
- As for now, the proposed approach is functional modularity but it lacks the space and time complexity analysis of each algorithm to identify its pros and cons.
- Using more comprehensive criteria with symmetry/asymmetry concepts, such as traffic status, logistics vehicle, deliverymen habits, and customer requirement features, in an effort to analyze usage scenarios more realistically.
- The human emotional analysis and deep learning models can be explored to strengthen the effectiveness of the proposed approach.
- Using the unified theory of acceptance and use of technology (UTAUT) to verify the user acceptance of this paper’s novel approach.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Schafer, J.B.; Konstan, J.A.; Riedl, J. E-commerce recommendation applications. Data Min. Knowl. Discov. 2001, 5, 115–153. [Google Scholar] [CrossRef]
- Mulvenna, M.D.; Anand, S.S.; Büchner, A.G. Personalization on the Net using Web mining: Introduction. Commun. ACM 2000, 43, 122–125. [Google Scholar] [CrossRef]
- Abbas, A.; Zhang, L.; Khan, S.U. A survey on context-aware recommender systems based on computational intelligence techniques. Computing 2015, 97, 667–690. [Google Scholar] [CrossRef]
- Wei, L.Y.; Zheng, Y.; Peng, W.C. Constructing popular routes from uncertain trajectories. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 195–203. [Google Scholar]
- Zhang, Z.; Che, O.; Cheang, B.; Lim, A.; Qin, H. A memetic algorithm for the multiperiod vehicle routing problem with profit. Eur. J. Oper. Res. 2013, 229, 573–584. [Google Scholar] [CrossRef]
- Liu, B.; Xiong, H. Point-of-Interest recommendation in location based social networks with topic and location awareness. In Proceedings of the 2013 Siam International Conference on Data Mining (SDM), Austin, TX, USA, 2–4 May 2013; pp. 396–404. [Google Scholar]
- Borris, J.; Moreno, A.; Valls, A. Intelligent tourism recommender systems: A survey. Expert Syst. Appl. 2014, 41, 7370–7389. [Google Scholar] [CrossRef]
- Bao, J.; Zheng, Y.; Wilkie, D.; Mokbel, M. Recommendations in location-based social net-works: A survey. GeoInformatica 2015, 19, 525–565. [Google Scholar] [CrossRef]
- Liu, B.; Xiong, H.; Papadimitriou, S.; Fu, Y.J.; Yao, Z.J. A general geographical probabilistic factor model for point of interest recommendation. IEEE Trans. Knowl. Data Eng. 2014, 27, 1167–1179. [Google Scholar] [CrossRef]
- Sheng, l.Z.; Irwin, K.; Michael, R.L. A survey of Point-of-interest Recommendation in Location-based social network. arXiv 2016, arXiv:1607.00647v1[cs.IR]. [Google Scholar]
- Ishizaka, A.; Nemery, P. Multi-Criteria Decision Analysis: Methods and Software; Wiley: New York, NY, USA, 2013. [Google Scholar]
- Aruldoss, M.; Lakshmi, T.M.; Venkatesan, V.P. A survey on multi criteria decision making methods and its applications. Am. J. Inf. Syst. 2013, 1, 31–43. [Google Scholar]
- Sojahrood, Z.B.; Taleai, M. A POI group recommendation method in location-based social networks based on user influence. Expert Syst. Appl. 2021, 171, 114593. [Google Scholar] [CrossRef]
- Pablo, S.; Alejandro, B. Point-of-interest recommender systems based on location-based social networks: A survey from an experimental perspective. ACM Comput. Surv. 2022, 1–35. [Google Scholar]
- Wang, Z.S.; Juang, J.F.; Teng, W.G. Predicting poi visits with a heterogeneous information network. In Proceedings of the 2015 Conference on Technologies and Applications of Artificial Intelligence (TAAI), IEEE, Tainan, Taiwan, 20–22 November 2015; pp. 388–395. [Google Scholar]
- Yu, Z.; Xu, H.; Yang, Z.; Guo, B. Personalized travel package with multi-point-of-interest recommendation based on crowdsourced user footprints. IEEE Trans. Hum.-Mach. Syst. 2016, 46, 151–158. [Google Scholar] [CrossRef]
- Abeer, A.N.; Norah, A.; Hend, A. Recommendation system algorithms on location-based social networks: Comparative study. Information 2022, 13, 188. [Google Scholar]
- Ke, C.K.; Lai, S.C.; Huang, L.T. Developing a Context-aware POI Network of Adaptive Vehicular Traffic Routing for Urban Logistics. In Proceedings of the 11th EAI International Wireless Internet Conference (WiCON 2018), Taipei, Taiwan, 15–16 October 2018. [Google Scholar]
- Ke, C.K.; Wu, M.Y.; Ho, W.C.; Lai, S.C.; Huang, L.T. Intelligent Point-of-Interest Recommendation for Tourism Planning via Density-based Clustering and Genetic Algorithm. In Proceedings of the 22nd Pacific Asia Conference on Information Systems (PACIS 2018), Yokohama, Japan, 26–30 June 2018. [Google Scholar]
- Nassereddine, M.; Eskandari, H. An integrated MCDM approach to evaluate public transportation systems in Tehran. Transp. Res. Part A Policy Pract. 2017, 106, 427–439. [Google Scholar] [CrossRef]
- Safavi, S.; Jalali, M.; Houshmand, M. Toward point-of-interest recommendation systems: A critical review on deep-learning Approaches. Electronics 2022, 11, 1998. [Google Scholar] [CrossRef]
- Griesner, J.B.; Abdessalem, T.; Naacke, H. POI Recommendation: Towards Fused Matrix Factorization with Geographical and Temporal Influences. In Proceedings of the 9th ACM Conference on Recommender Systems, Vienna, Austria, 16–20 September 2015; pp. 301–304. [Google Scholar]
- Cheng, C.; Yang, H.Q.; Lyu, M.R.; King, I. Where You Like to Go Next: Successive Point-of-Interest Recommendation. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 2605–2611. [Google Scholar]
- Feng, S.S.; Li, X.T.; Zeng, Y.F.; Cong, G.; Chee, Y.M.; Yuan, Q. Personalized Ranking Metric Embedding for Next New POI Recommendation. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 2069–2075. [Google Scholar]
- Han, J.K.; Yamana, H. Geographical Diversification in POI Recommendation: Toward Improved Coverage on Interested Areas. In Proceedings of the ACM Conference Series on Recommender Systems, Como, Italy, 27–31 August 2017; pp. 27–31. [Google Scholar]
- Liu, X.; Liu, Y.; Aberer, K. Personalized Point-of-Interest Recommendation by Mining Users’ Preference Transition. In Proceedings of the 22nd ACM International Conference on Information & Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; pp. 733–738. [Google Scholar]
- Hu, B.; Ye, Y.; Zhong, Y.; Pan, J.; Hu, M. TransMKR: Translation-based knowledge graph enhanced multi-task point-of-interest recommendation. Neurocomputing 2022, 474, 107–114. [Google Scholar] [CrossRef]
- Hossein, A.R.; Yashar, D.; Tommaso, D.N. The role of context fusion on accuracy, beyond-accuracy, and fairness of point-of-interest recommendation systems. Expert Syst. Appl. 2022, 205, 117700. [Google Scholar]
- Liu, X.; Yang, Y.; Xu, Y.; Yang, F.; Huang, Q.; Wang, H. Real-time POI recommendation via modeling long- and short-term user preferences. Neurocomputing 2022, 467, 454–464. [Google Scholar] [CrossRef]
- Xu, Z.; Xia, M. Identifying and eliminating dominated alternatives in multi-attribute decision making with intuitionistic fuzzy information. Appl. Soft Comput. 2012, 12, 1451–1456. [Google Scholar] [CrossRef]
- Liou, J.J.; Chuang, Y.T. Developing a hybrid multi-criteria model for selection of outsourcing providers. Expert Syst. Appl. 2010, 37, 3755–3761. [Google Scholar] [CrossRef]
- Tadić, S.; Zečević, S.; Krstić, M. A novel hybrid MCDM model based on fuzzy DEMATEL, fuzzy ANP and fuzzy VIKOR for city logistics concept selection. Expert Syst. Appl. 2014, 41, 8112–8128. [Google Scholar] [CrossRef]
- Liu, C.H.; Tzeng, G.H.; Lee, M.H.; Lee, P.Y. Improving metro–airport connection service for tourism development: Using hybrid MCDM models. Tour. Manag. Perspect. 2013, 6, 95–107. [Google Scholar] [CrossRef]
- Ke, C.K.; Chen, Y.L. A message negotiation approach to e-services by utility function and multi-criteria decision analysis. Comput. Math. Appl. 2012, 64, 1056–1064. [Google Scholar] [CrossRef][Green Version]
- Chen, Y.L.; Ke, C.K. Optimal mobile device selection for round-robin data exchange via adaptive multi-criteria decision analysis. Comput. Electr. Eng. 2016, 54, 119–130. [Google Scholar]
- Silaghi, G.C.; Arenas, A.E.; Silva, L.M. A Utility-Based Reputation Model for Service-Oriented Computing, towards Next Generation Grids; Springer: New York, NY, USA, 2007; pp. 63–72. [Google Scholar]
- Chen, M.C. A Comparative Study of Multi-Criteria Decision-Making Analysis Methods in the Application Recommendation Mechanism of Application Markets. Master’s Thesis, National Taichung University of Science and Technology, Taichung, Taiwan, 2016. [Google Scholar]
- García, J.M.; Junghans, M.; Ruiz, D.; Agarwal, S.; Ruiz-Cortés, A. Integrating semantic Web services ranking mechanisms using a common preference model. Knowl.-Based Syst. 2013, 49, 22–36. [Google Scholar] [CrossRef]
- Lin, S.Y.; Lai, C.H.; Wu, C.H.; Lo, C.C. A trustworthy QoS-based collaborative filtering approach for web service discovery. J. Syst. Softw. 2014, 93, 217–228. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Path No | Average Speed (Kilometer/Hour) | Congestion Degree (1 to 10) | Distance (Kilometer) | Personal Interest (1 to 10) |
|---|---|---|---|---|
| P01 | 33 | 6 | 2.08 | 5 |
| P02 | 42 | 2 | 1.65 | 7 |
| P03 | 30 | 8 | 1.79 | 4 |
| P04 | 44 | 2 | 2.62 | 6 |
| P05 | 25 | 8 | 1.74 | 8 |
| P06 | 46 | 3 | 4.02 | 2 |
| P07 | 38 | 4 | 1.24 | 4 |
| P08 | 43 | 6 | 3.58 | 6 |
| P09 | 46 | 3 | 1.93 | 7 |
| P10 | 52 | 1 | 3.90 | 8 |
| MCDA Method | Candidate Path Ranking Order |
|---|---|
| TOPSIS | P10→P02→P09→P04→P05→P08→P07→P01→P06→P03 |
| VIKOR | P10→P09→P02→P04→P08→P01→P07→P05→P03→P06 |
| ELECTRE | P02→P10→P09→P04→{P05, P08}→P07→P01→P06→P03 |
| PROMETHEE | P10→P02→P09→P04→P07→P05→P08→P06→P01→P03 |
| SAW | P10→P02→P09→P04→P07→P08→P05→P01→P06→P03 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, M.-Y.; Ke, C.-K.; Lai, S.-C. Optimizing the Routing of Urban Logistics by Context-Based Social Network and Multi-Criteria Decision Analysis. Symmetry 2022, 14, 1811. https://doi.org/10.3390/sym14091811
Wu M-Y, Ke C-K, Lai S-C. Optimizing the Routing of Urban Logistics by Context-Based Social Network and Multi-Criteria Decision Analysis. Symmetry. 2022; 14(9):1811. https://doi.org/10.3390/sym14091811
Chicago/Turabian StyleWu, Mei-Yu, Chih-Kun Ke, and Szu-Cheng Lai. 2022. "Optimizing the Routing of Urban Logistics by Context-Based Social Network and Multi-Criteria Decision Analysis" Symmetry 14, no. 9: 1811. https://doi.org/10.3390/sym14091811
APA StyleWu, M.-Y., Ke, C.-K., & Lai, S.-C. (2022). Optimizing the Routing of Urban Logistics by Context-Based Social Network and Multi-Criteria Decision Analysis. Symmetry, 14(9), 1811. https://doi.org/10.3390/sym14091811