
A Dynamic GLR-Based Fault Detection Method for Non-Gaussain Dynamic Processes



Abstract
:1. Introduction
2. Background and Problem Formulation
2.1. The Basics of GLR-Based Fault Detection Technique
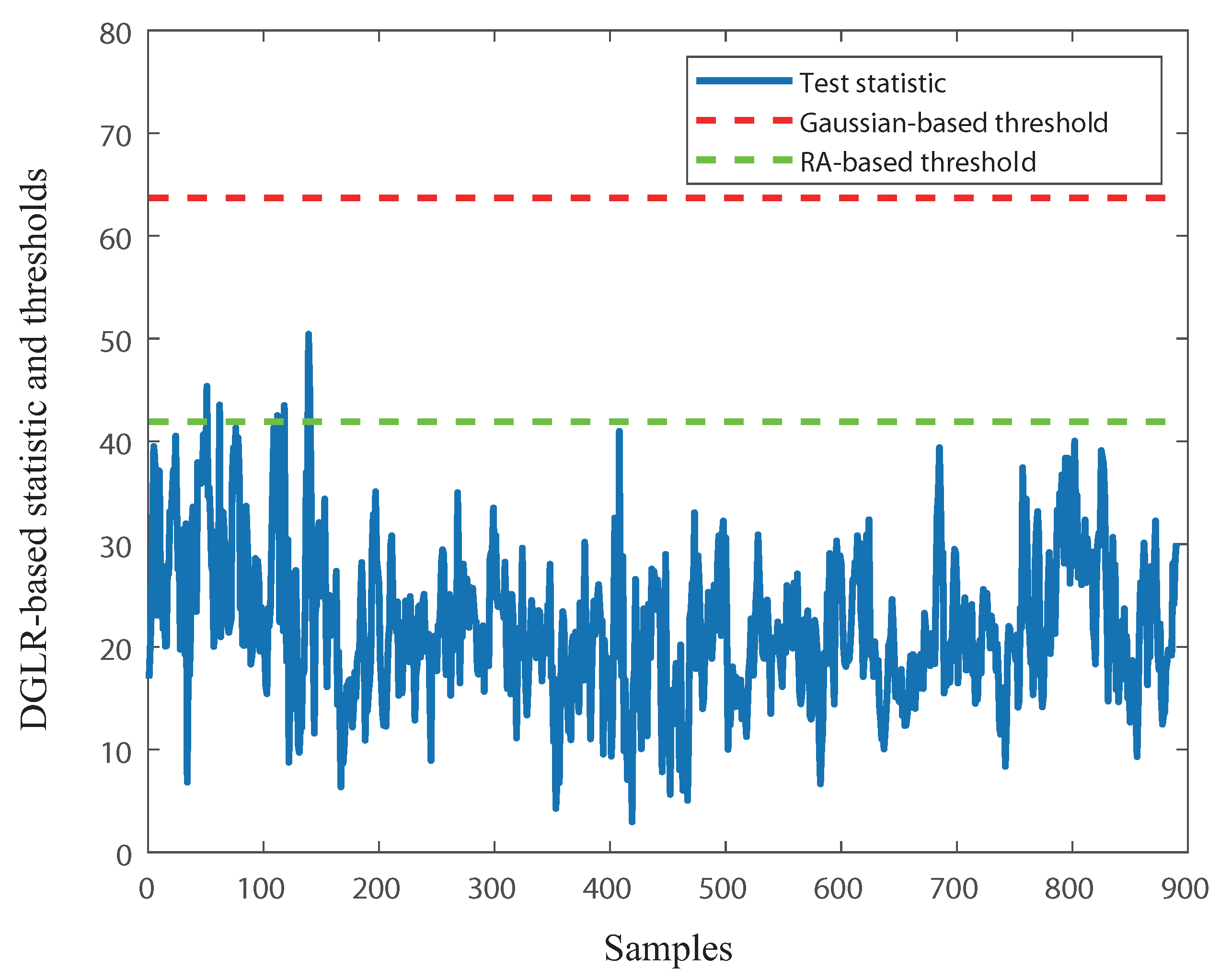
2.2. Randomized Algorithm-Based Threshold Setting
| Algorithm 1: Threshold-setting |
Given allowed and , let be some constant satisfying
S1: Set ; S2: Choose integer N according to the one-sided Chernoff inequality with , S3: Estimate FAR using the method given in [37]; S4: If then return and exit; S5: Else go to Step 3. |
3. The Proposed Method
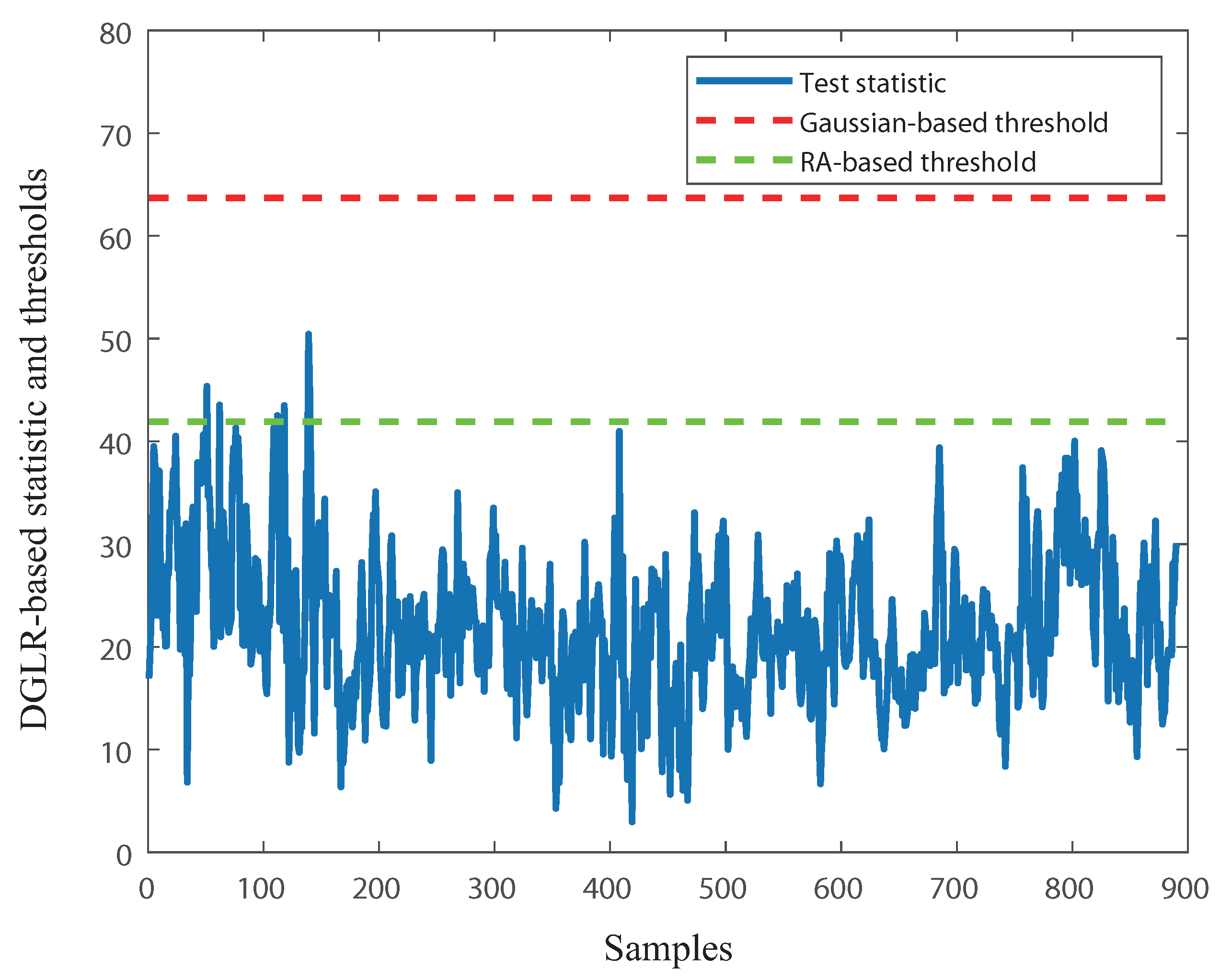
3.1. DGLR with RA-Based Threshold Setting Algorithm
- Off-line training. Using the stacking data to identify the unknown parameters, i.e., the mean value and the covariance matrix ;
- On-line implementation. Detecting faults with on-line data.
| Algorithm 2: DGLR-based fault detection method with RA-based threshold setting. |
Off-line training S1: Computation of
S2: Determine the corresponding thresholds using Algorithm 1 with a given significance level , in which the statistic, is estimated according to Equation (12); On-line implementation S3: Collect real-time measurement and calculate
S4: Build test statistic
S5: Check the decision logic: |
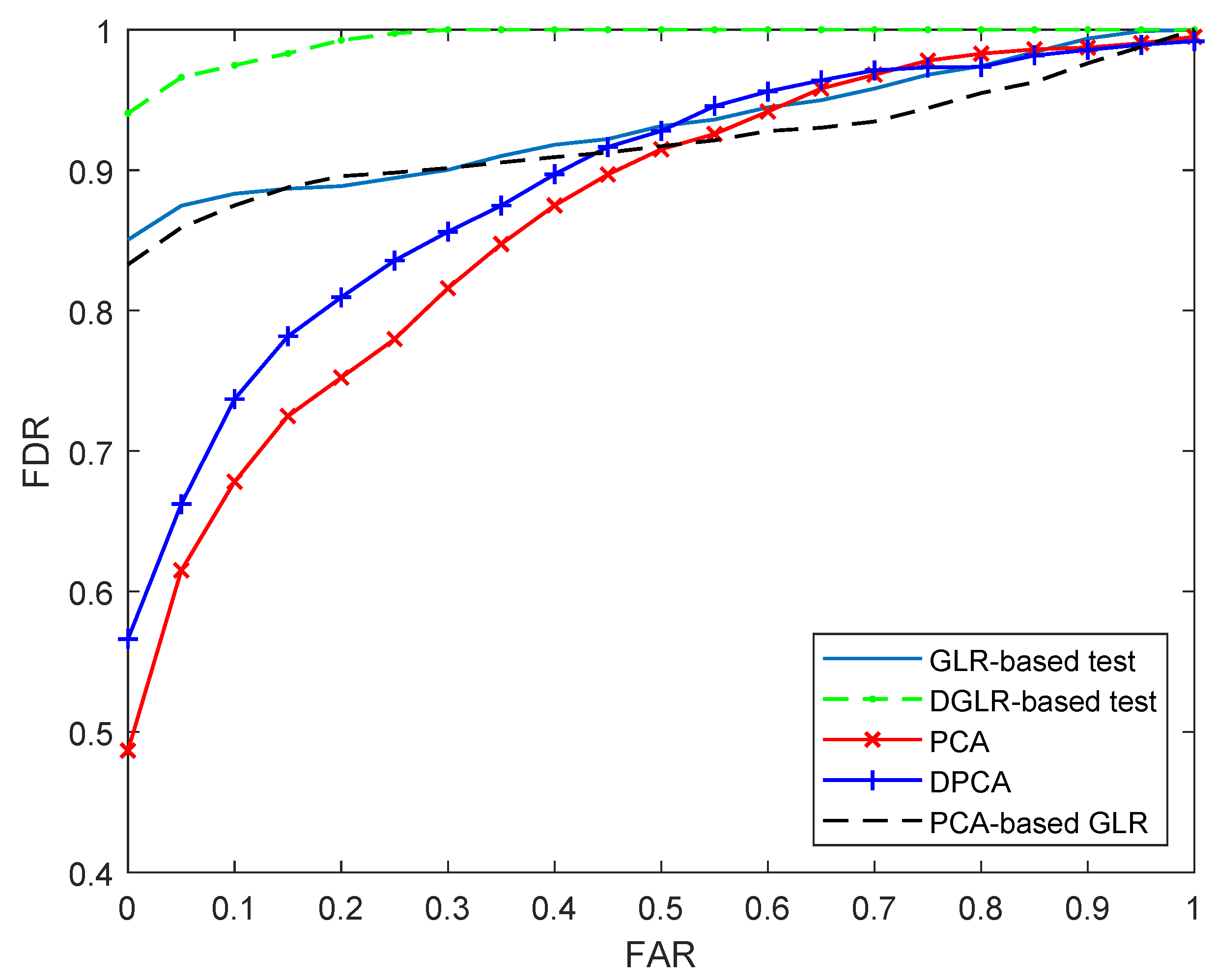
3.2. Comparison among GLR-Based, DGLR-Based, PCA-Based, DPCA-Based, and PCA-Based GLR Fault Detection Methods
4. Simulated Examples
4.1. Fault Detection in Synthetic Data
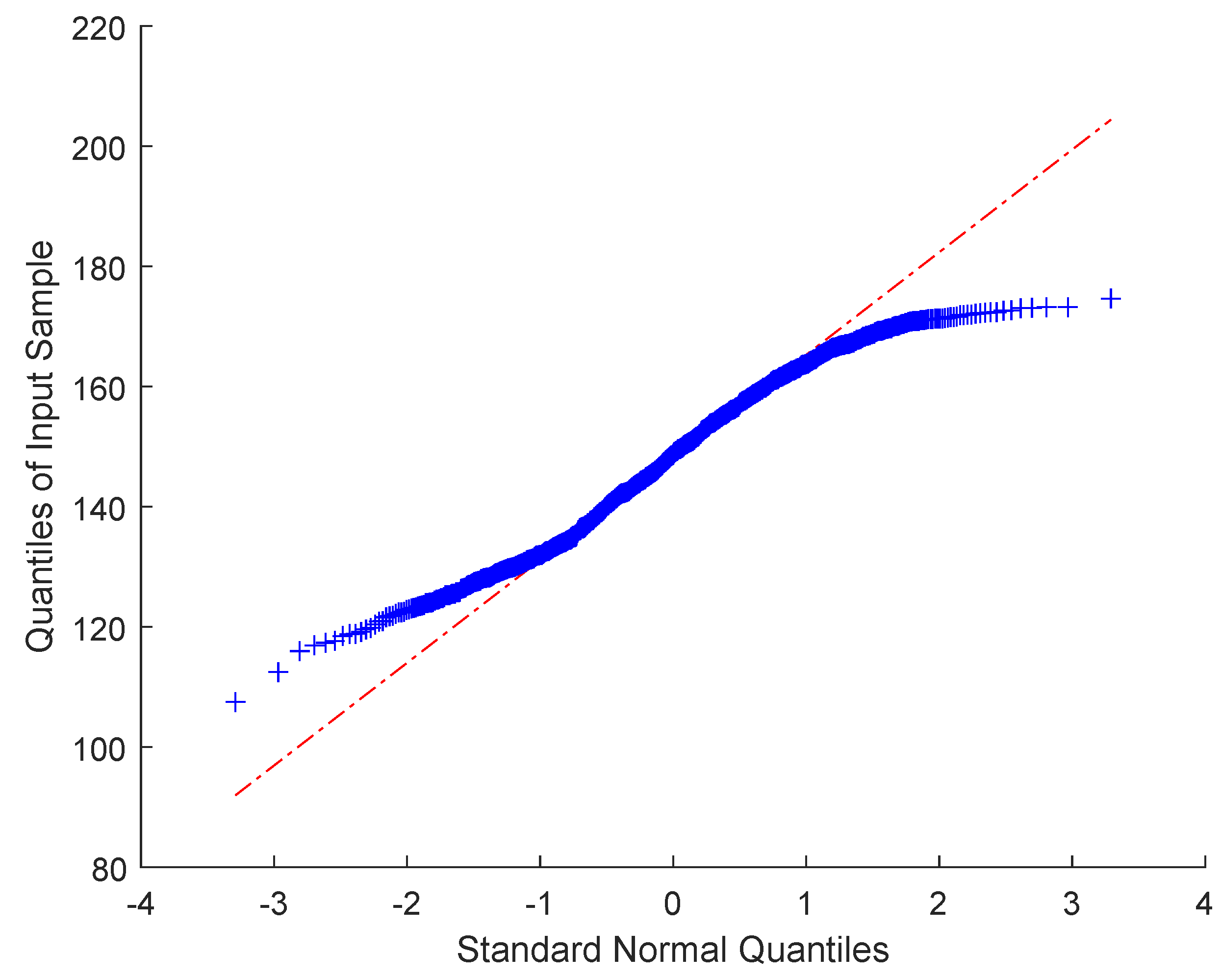
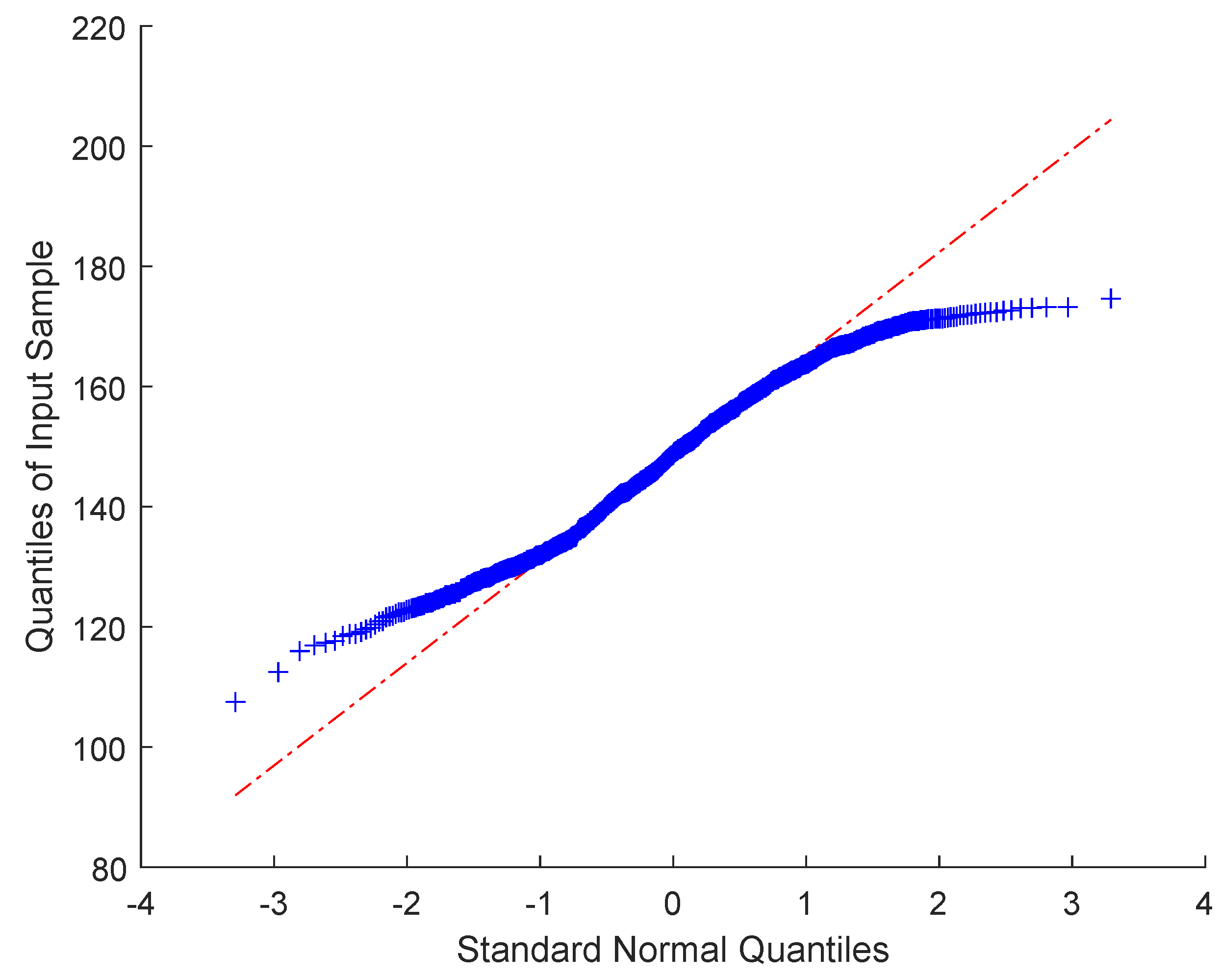
4.1.1. Data Generation
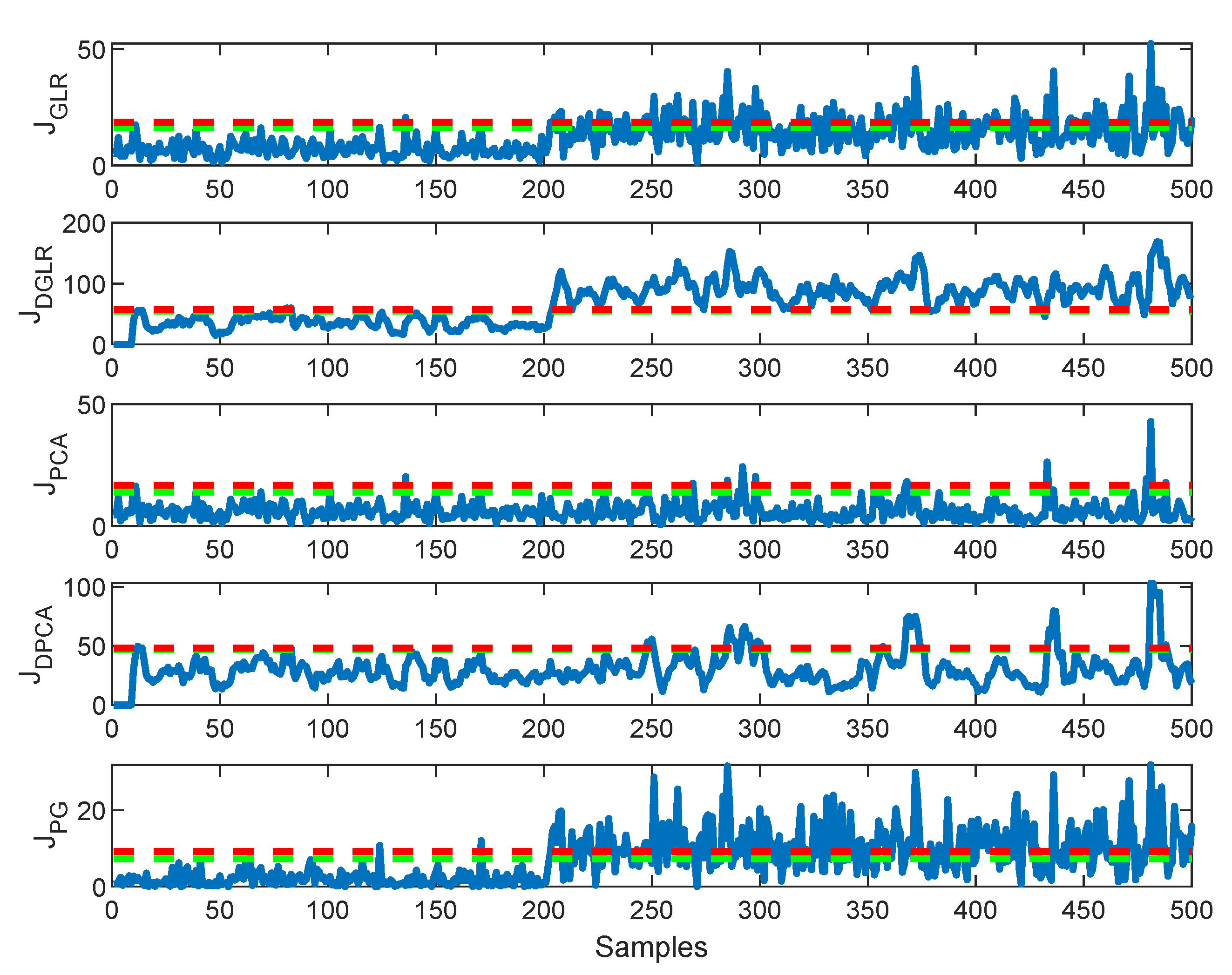
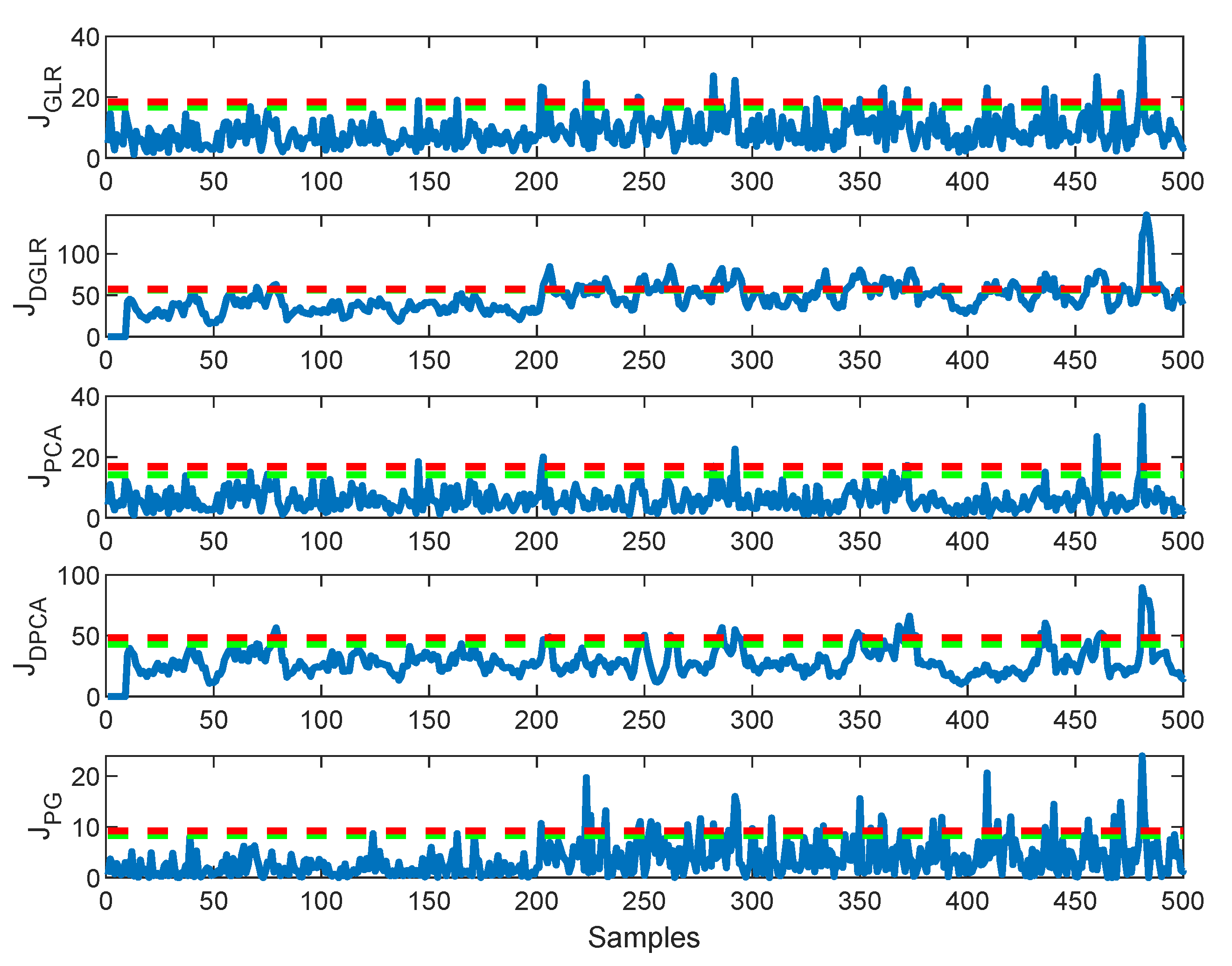
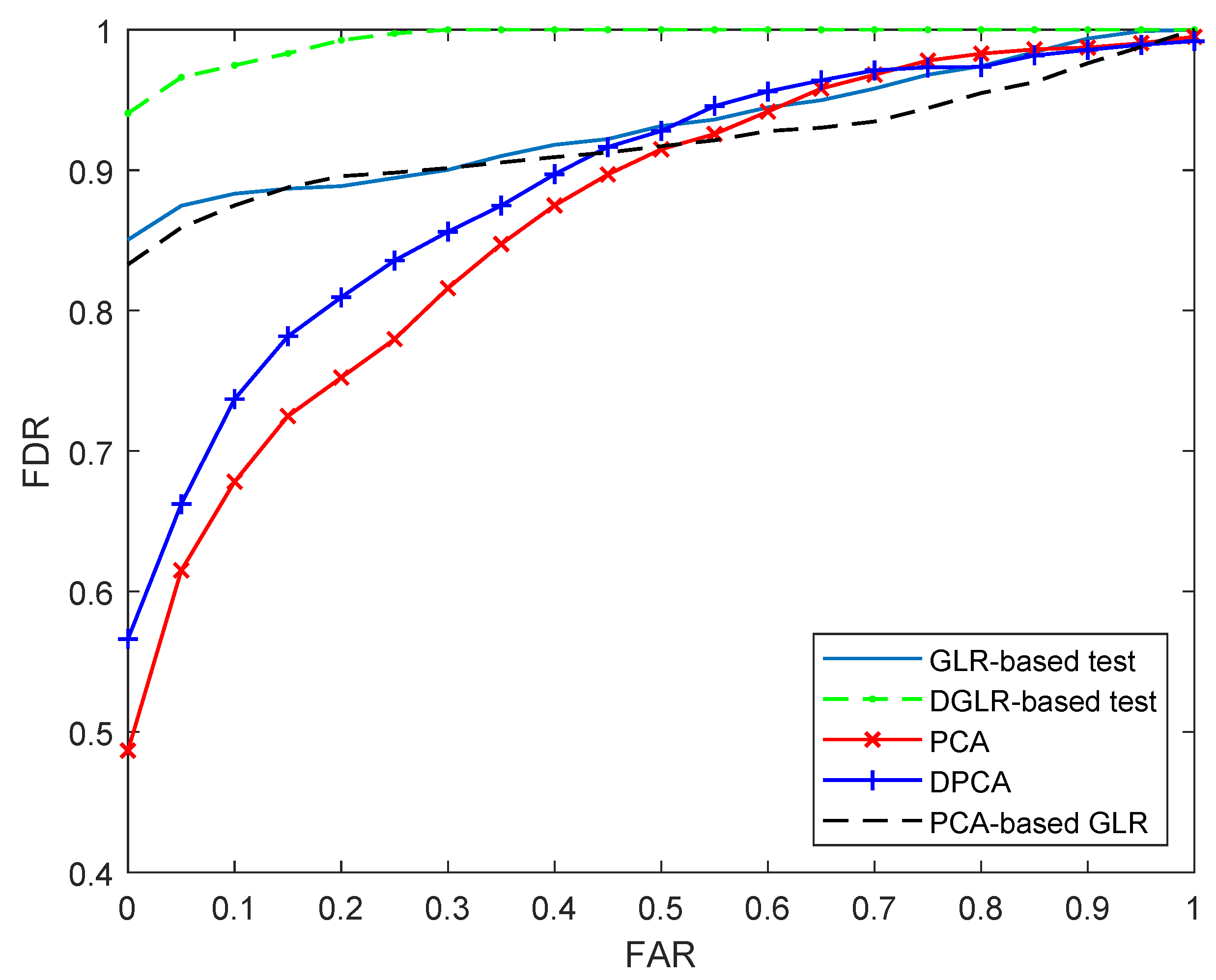
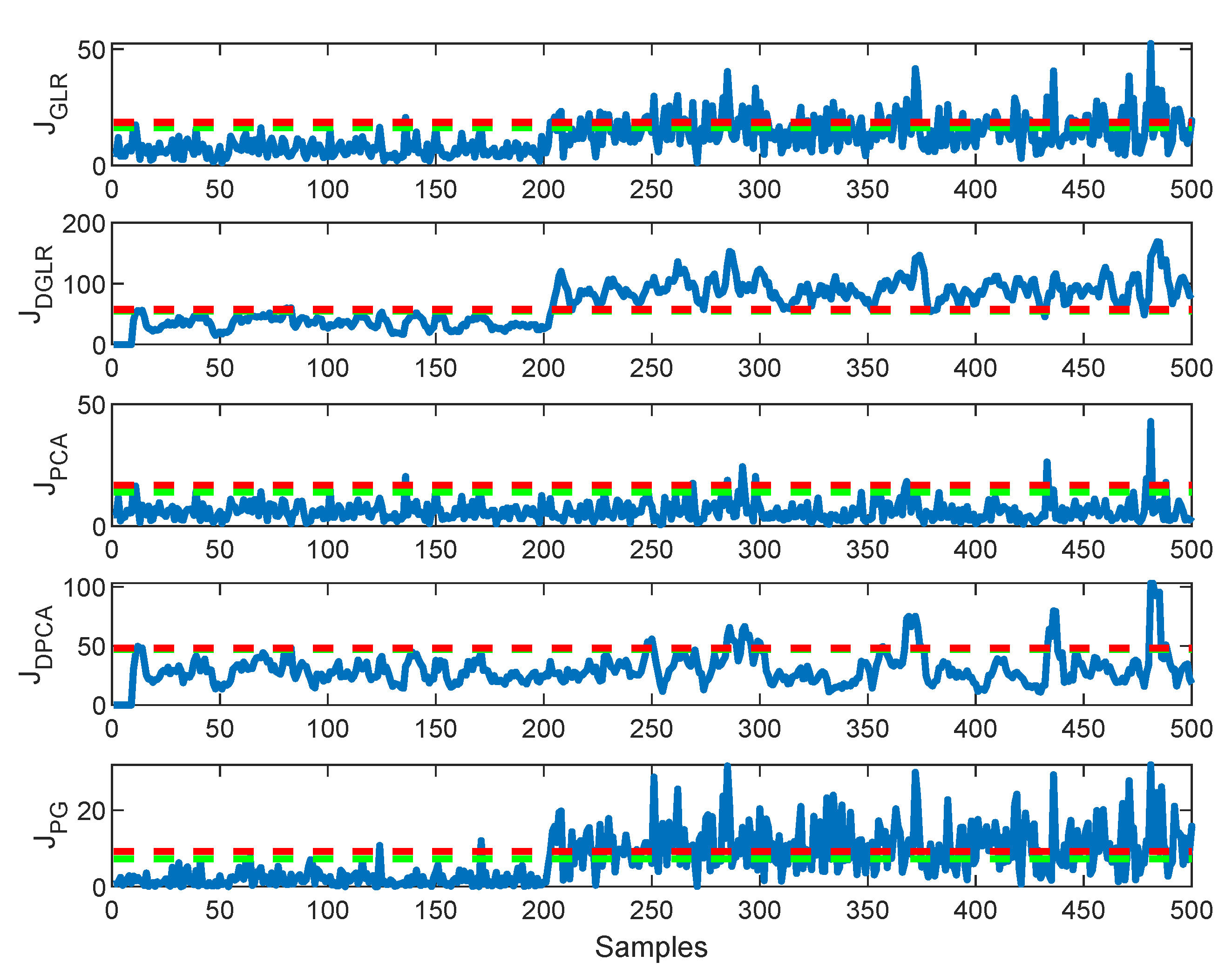
4.1.2. Comparing the Five Methods Using Faulty Data
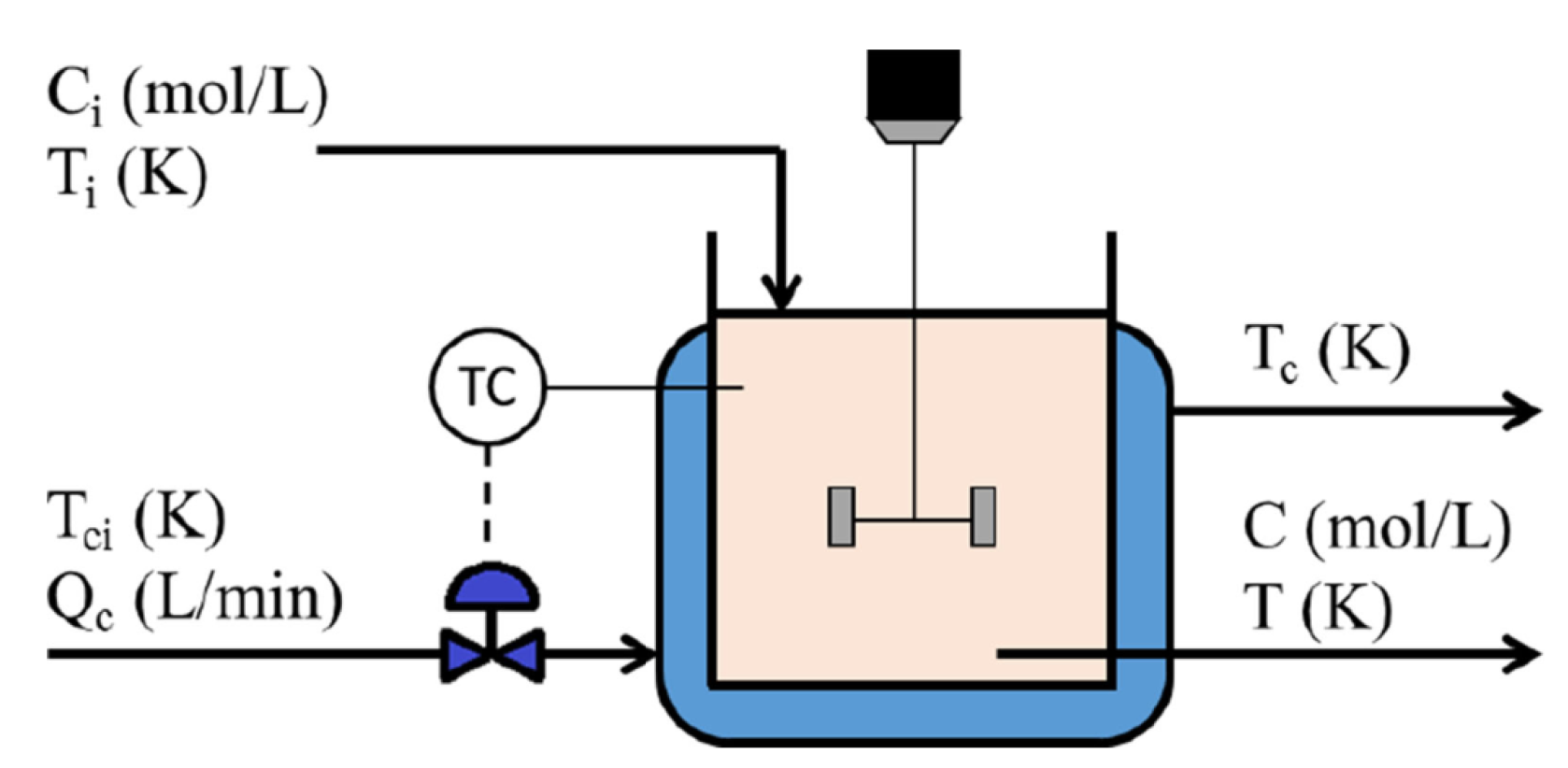
4.2. Fault Detection in CSTR Process
4.2.1. Data Generation
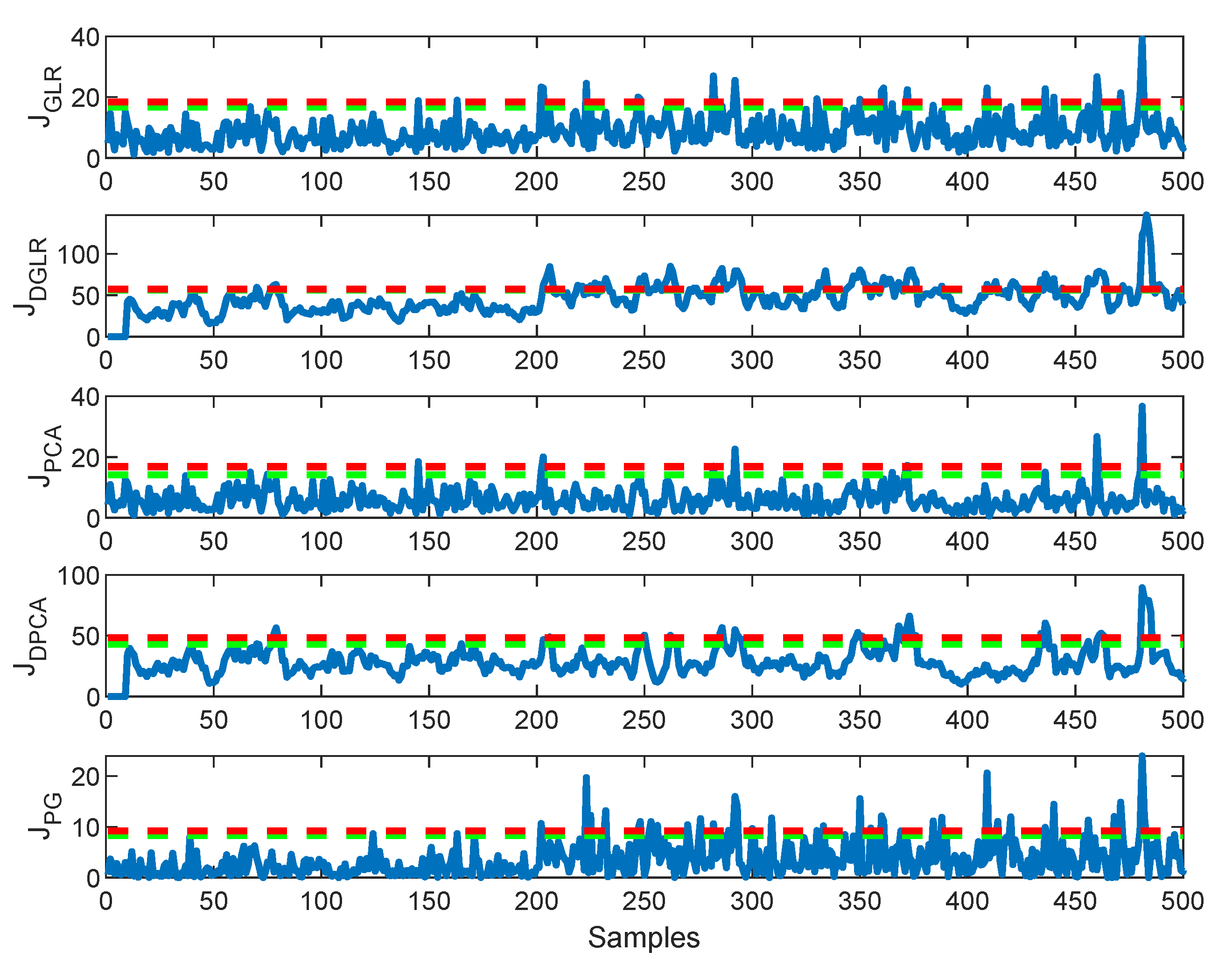
4.2.2. Comparing the Five Methods Using Faulty Data
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Maleki, M.R.; Amiri, A.; Castagliola, P. Measurement errors in statistical process monitoring: A literature review. Comput. Ind. Eng. 2017, 103, 316–329. [Google Scholar] [CrossRef]
- Zhao, C.; Chen, J.; Jing, H. Condition-Driven Data Analytics and Monitoring for Wide-Range Nonstationary and Transient Continuous Processes. IEEE Trans. Autom. Sci. Eng. 2021, 18, 1563–1574. [Google Scholar] [CrossRef]
- He, Z.; Chen, Z.; Zhou, H.; Wang, D.; Xing, Y.; Wang, J. A visualization approach for unknown fault diagnosis. Chemom. Intell. Lab. Syst. 2018, 172, 80–89. [Google Scholar] [CrossRef]
- Huang, K.; Zhang, L.; Yang, C.; Gui, W.; Hu, S. Unified Stationary and Nonstationary Data Representation for Process Monitoring in IIoT. IEEE Trans. Instrum. Meas. 2022, 71, 1–12. [Google Scholar] [CrossRef]
- Ding, S.X. Data-Driven Design of Fault Diagnosis and Fault-Tolerant Control Systems; Springer: London, UK, 2014. [Google Scholar]
- Luo, H.; Yang, X.; Krueger, M.; Ding, S.; Peng, K. A plug-and- play monitoring and control architecture for disturbance compensation in rolling mills. IEEE/ASME Trans. Mechatron. 2018, 23, 200–210. [Google Scholar] [CrossRef]
- Basseville, M.; Nikiforov, I. Detection of Abrupt Changes: Theory and Application; Prentice-Hall: New York, NY, USA, 1993. [Google Scholar]
- Gao, Z.W.; Cecati, C.; Ding, S.X. A Survey of Fault Diagnosis and Fault-Tolerant Techniques, Part I: Fault Diagnosis with Model-Based and Signal-Based Approaches. IEEE Trans. Ind. Electron. 2015, 62, 3757–3767. [Google Scholar] [CrossRef] [Green Version]
- Chaouch, H.; Charfeddine, S.; Ben Aoun, S.; Jerbi, H.; Leiva, V. Multiscale monitoring using machine learning methods: New methodology and an industrial application to a photovoltaic system. Mathematics 2022, 10, 890. [Google Scholar] [CrossRef]
- Chen, H.; Jiang, B.; Lu, N.; Mao, Z. Deep PCA Based Real-Time Incipient Fault Detection and Diagnosis Methodology for Electrical Drive in High-Speed Trains. IEEE Trans. Veh. Technol. 2018, 67, 4819–4830. [Google Scholar] [CrossRef]
- Cao, Y.; Yuan, X.; Wang, Y.; Gui, W. Hierarchical hybrid distributed PCA for plant-wide monitoring of chemical processes. Control. Eng. Pract. 2021, 111, 104784. [Google Scholar] [CrossRef]
- Liu, Q.; Kong, D.; Qin, S.J.; Xu, Q. Map-Reduce Decentralized PCA for Big Data Monitoring and Diagnosis of Faults in High-Speed Train Bearings. IFAC-PapersOnLine 2018, 51, 144–149. [Google Scholar] [CrossRef]
- Peng, K.X.; Zhang, K.; Li, G.; Zhou, D.H. Contribution rate plot for nonlinear quality-related fault diagnosis with application to the hot strip mill process. Control Eng. Pract. 2013, 21, 360–369. [Google Scholar] [CrossRef]
- Zhang, K.; Hao, H.Y.; Chen, Z.W.; Ding, S.X.; Peng, K.X. A Comparison and evaluation of key performance indicator-based multivariate statistics process monitoring approaches. J. Process. Control 2015, 33, 112–126. [Google Scholar] [CrossRef]
- Yin, S.; Wang, G.; Gao, H. Data-driven process monitoring based on modified orthogonal projections to latent Structures. IEEE Trans. Control. Syst. Technol. 2016, 24, 1480–1487. [Google Scholar] [CrossRef]
- Chen, Z.W.; Ding, S.X.; Zhang, K.; Li, Z.B.; Hu, Z.K. Canonical correlation analysis-based fault detection methods with application to alumina evaporation process. Control Eng. Pract. 2016, 46, 51–58. [Google Scholar] [CrossRef]
- Chen, Z.; Yang, C.; Peng, T.; Dan, H.; Li, C.; Gui, W. A Cumulative Canonical Correlation Analysis-Based Sensor Precision Degradation Detection Method. IEEE Trans. Ind. Electron. 2019, 66, 6321–6330. [Google Scholar] [CrossRef]
- Chen, H.; Li, L.; Shang, C.; Huang, B. Fault Detection for Nonlinear Dynamic Systems with Consideration of Modeling Errors: A Data-Driven Approach. IEEE Trans. Cybern. 2022, 1–11. [Google Scholar] [CrossRef]
- Ge, Z.Q.; Song, Z.H.; Gao, F.R. Review of recent research on data-based process monitoring. Ind. Eng. Chem. Res. 2013, 52, 3543–3562. [Google Scholar] [CrossRef]
- Ku, W.F.; Storer, R.H.; Georgakis, C. Disturbance detection and isolation by dynamic principal component analysis. Chemom. Intell. Lab. Syst. 1995, 30, 179–196. [Google Scholar] [CrossRef]
- Wang, X.; Kruger, U.; Irwin, G.W. Process Monitoring Approach Using Fast Moving Window PCA. Ind. Eng. Chem. Res. 2005, 44, 5691–5702. [Google Scholar] [CrossRef]
- Chen, Q.; Wynne, R.; Goulding, P.; Sandoz, D. The application of principal component analysis and kernel density estimation to enhance process monitoring. Control Eng. Pract. 2000, 8, 531–543. [Google Scholar] [CrossRef]
- Zhang, Q.; Basseville, M. Statistical detection and isolation of additive faults in linear time-varying systems. Automatica 2014, 50, 2527–2538. [Google Scholar] [CrossRef]
- Kini, K.R.; Madakyaru, M. Monitoring multivariate process using improved Independent component analysis-generalized likelihood ratio strategy. IFAC Pap. 2020, 53, 392–397. [Google Scholar] [CrossRef]
- Tang, M.; Yang, C.; Gui, W. Fault detection based on cost-sensitive support vector machine for alumina evaporation process. Control Eng. China 2011, 18, 645–649. [Google Scholar]
- Jiang, Q.; Yan, X.; Lv, Z.; Guo, M. Independent component analysis-based non-Gaussian process monitoring with preselecting optimal components and support vector data description. Int. J. Prod. Res. 2014, 52, 3273–3286. [Google Scholar] [CrossRef]
- He, Q.P.; Wang, J. Statistics pattern analysis: A new process monitoring framework and its application to semiconductor batch processes. AIChE J. 2011, 57, 107–121. [Google Scholar] [CrossRef]
- Chen, Z.W.; Ding, S.X.; Peng, T.; Yang, C.H.; Gui, W.H. Fault Detection for Non-Gaussian Processes Using Generalized Canonical Correlation Analysis and Randomized Algorithms. IEEE Trans. Ind. Electron. 2018, 65, 1559–1567. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning (Information Science and Statistics); Springer: Secaucus, NJ, USA, 2006. [Google Scholar]
- Chen, T.; Morris, J.; Martin, E. Probability density estimation via an infinite Gaussian mixture model: Application to statistical process monitoring. J. R. Stat. Soc. Ser. C (Appl. Stat.) 2006, 55, 699–715. [Google Scholar] [CrossRef] [Green Version]
- Odiowei, P.; Cao, Y. Nonlinear dynamic process monitoring using canonical variate analysis and kernel density estimations. IEEE Trans. Ind. Inform. 2010, 6, 36–45. [Google Scholar] [CrossRef] [Green Version]
- Gonzalez, R.; Huang, B.; Lau, E. Process monitoring using kernel density estimation and Bayesian networking with an industrial case study. ISA Trans. 2015, 58, 330–347. [Google Scholar] [CrossRef]
- Tschumitschew, K.; Klawonn, F. Incremental quantile estimation. Evol. Syst. 2010, 1, 253–264. [Google Scholar] [CrossRef]
- Harrou, F.; Nounou, M.N.; Nounou, H.N.; Madakyaru, M. Statistical fault detection using PCA-based GLR hypothesis testing. J. Loss Prev. Process. Ind. 2013, 26, 129–139. [Google Scholar] [CrossRef]
- Chamanbaz, M.; Dabbene, F.; Tempo, R.; Venkataramanan, V.; Wang, Q.G. Sequential randomized algorithms for convex optimization in the presence of uncertainty. IEEE Trans. Autom. Control 2016, 61, 2565–2571. [Google Scholar] [CrossRef] [Green Version]
- Faradonbeh, M.K.S.; Tewari, A.; Michailidis, G. Randomized algorithms for data-drivn stabilization of stochastic linear systems. In Proceedings of the 2019 IEEE Data Science Workshop (DSW), Minneapolis, MN, USA, 2–5 June 2019; pp. 170–174. [Google Scholar]
- Chen, Z.W. Data-Driven Fault Detection for Industrial Processes: Canonical Correlation Analysis and Projection based Methods. Ph.D. Thesis, University of Duisburg-Essen, Duisburg, Germany, 2016. [Google Scholar]
- McNabb, C.A.; Qin, S.J. Fault diagnosis in the feedback-invariant subspace of closed-loop systems. Ind. Eng. Chem. Res. 2005, 44, 2359–2368. [Google Scholar] [CrossRef]
- Pilario, K.E.S.; Cao, Y. Canonical variate dissimilarity analysis for process incipient fault detection. IEEE Trans. Ind. Inform. 2018, 14, 5308–5315. [Google Scholar] [CrossRef] [Green Version]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Application Conditions | Number of Test Statistics | Parameters |
|---|---|---|---|
| GLR(DGLR)-based | is available | and | m, n, and |
| PCA(DPCA)-based | is unavailable | and | m, , , and |
| PCA-based GLR | Both cases, in which PCA model is available | m, , , and |
| Fault IDs | Description | Value of |
|---|---|---|
| 1 | 0.2 | |
| 2 | 0.005 | |
| 3 | (0, 0.04) |
| Method | Test Statistics | RA-Based Threshold | Gaussian-Based Threshold |
|---|---|---|---|
| GLR | 20.0901 | ||
| DGLR | 32.0001 | ||
| PCA | 13.2775 | ||
| DPCA | 4.1991 | ||
| PCA-based GLR | 13.2775 |
| Parameter | Description | 100.0 | Unit |
|---|---|---|---|
| Q | Inlet flow rate | 150.0 | L/min |
| V | Tank volume | 10.0 | L |
| Jacket volume | 0.7 | L | |
| Heat of reaction | cal/mol | ||
| UA | Heat transfer coefficient | cal/min/K | |
| Pre-exponential factor to k | min−1 | ||
| Activation energy | K | ||
| Fluid density | 1000 | g/L | |
| Fluid heat capacity | 1.0 | cal/g/K |
| Fault IDs | Description of Faults | Value of |
|---|---|---|
| 1 | 0.001 | |
| 2 | 1.4 | |
| 3 | 0.7 | |
| 4 | 0.005 | |
| 5 | 5 |
| Fault IDs | |||||
|---|---|---|---|---|---|
| 1 | 79.74% | 85.38% | 16.39% | 61.16% | 86.49% |
| 2 | 99.35% | 96.75% | 99.35% | 96.76% | 99.35% |
| 3 | 54.34% | 95.77% | 8.03% | 15.85% | 85.53% |
| 4 | 9.03% | 48.37% | 11.57% | 50.48% | 20.57% |
| 5 | 6.75% | 36.36% | 5.46% | 14.88% | 21.54% |
| Fault IDs | |||||
|---|---|---|---|---|---|
| 1 | 42 | 34 | 16 | 47 | 47 |
| 2 | 2 | 2 | 2 | 2 | 2 |
| 3 | 2 | 3 | 27 | 47 | 47 |
| 4 | 18 | 4 | 18 | 4 | 4 |
| 5 | 1 | 2 | 1 | 2 | 2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, X.; Gao, L.; Jiao, Y.; Chen, Z. A Dynamic GLR-Based Fault Detection Method for Non-Gaussain Dynamic Processes. Symmetry 2022, 14, 1332. https://doi.org/10.3390/sym14071332
Pan X, Gao L, Jiao Y, Chen Z. A Dynamic GLR-Based Fault Detection Method for Non-Gaussain Dynamic Processes. Symmetry. 2022; 14(7):1332. https://doi.org/10.3390/sym14071332
Chicago/Turabian StylePan, Xiaogang, Long Gao, Yuanyuan Jiao, and Zhiwen Chen. 2022. "A Dynamic GLR-Based Fault Detection Method for Non-Gaussain Dynamic Processes" Symmetry 14, no. 7: 1332. https://doi.org/10.3390/sym14071332
APA StylePan, X., Gao, L., Jiao, Y., & Chen, Z. (2022). A Dynamic GLR-Based Fault Detection Method for Non-Gaussain Dynamic Processes. Symmetry, 14(7), 1332. https://doi.org/10.3390/sym14071332