
A Novel 2D Clustering Algorithm Based on Recursive Topological Data Structure


Abstract
:1. Introduction
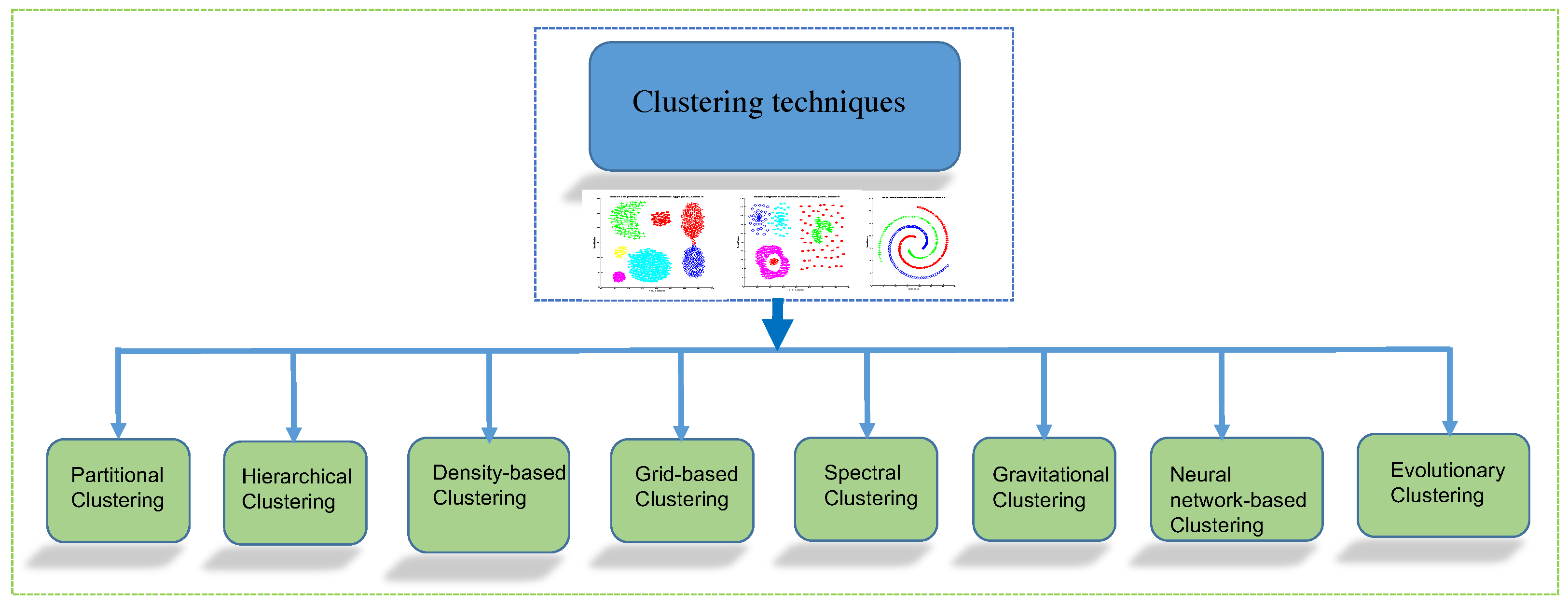
2. State of the Art
3. Proposal
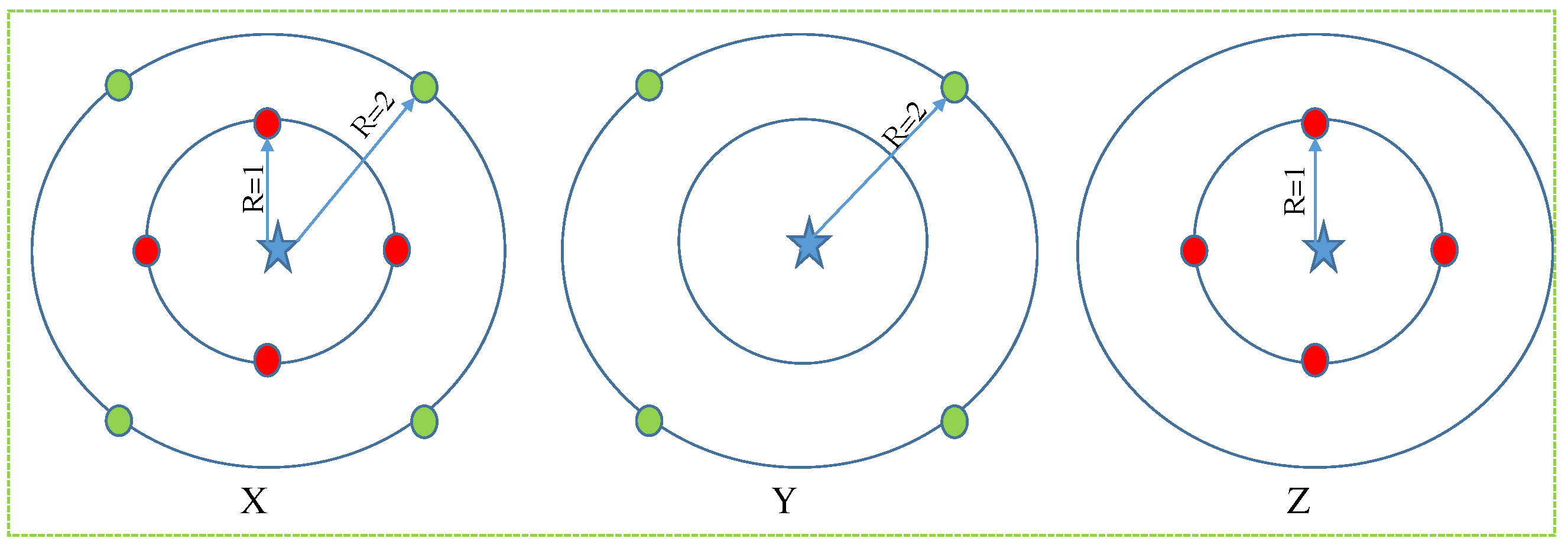
4. Theoretical Fundamentals of a Topological-Pseudometric-Based Clustering
- For each, .
- For and implies .
- .
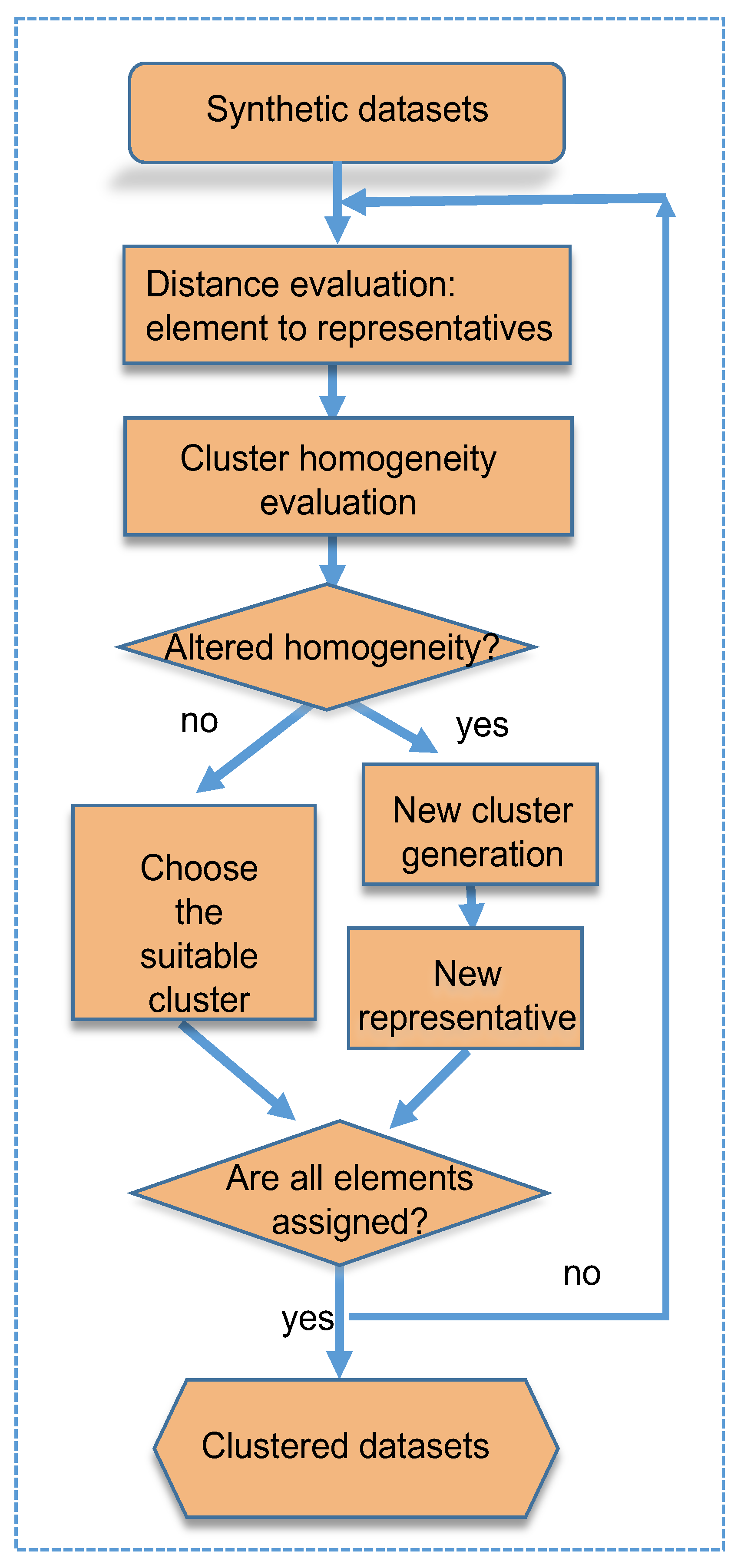
5. Methodology
- 1.
- Dataset are read: First, datasets are read as ascii files, where the first column represents the information on the x-axis, while the second column represents the information on the y-axis.
- 2.
- The manhattan distance is calculated on the totality of the data: A measure amount of all elements is defined by its manhattan distance, in this case, there is a two-dimension manhattan distance.
- 3.
- Local and general pseudometry is evaluated: Based on pseudometry defined in Definitions 1–3, local and general topology are taken into account in order to measure the cluster energy, defined in Definition 4.
- 4.
- The appropriate cluster is chosen: If the energy of the cluster is not affected by the new element, then it is integrated to the cluster, otherwise, a new one is generated.
- 5.
- The homogeneous-energy of the clusters is evaluated: At this stage, each cluster energy is calculated in order to update the cluster energy.
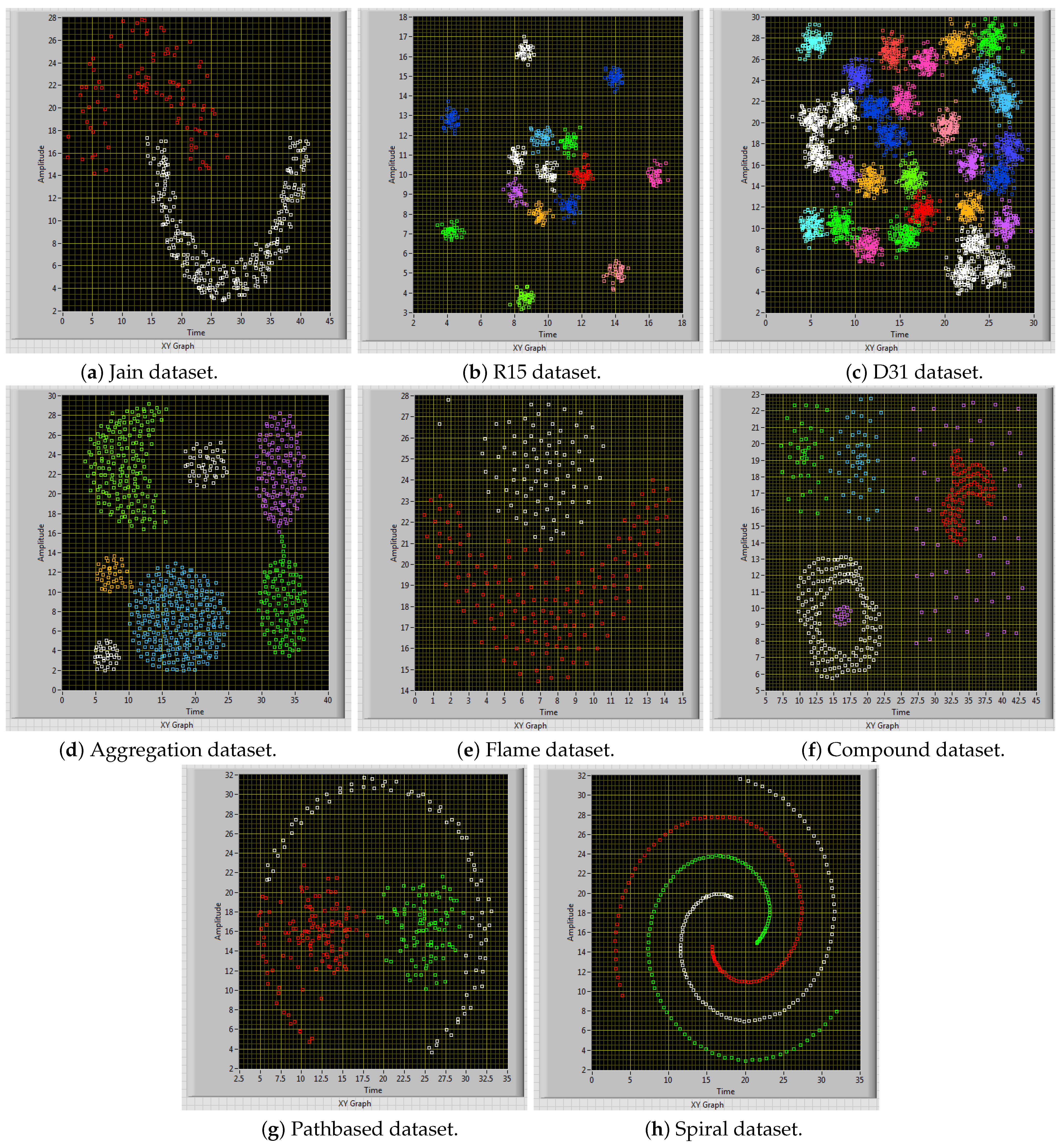
5.1. Datasets
5.2. Metric and Distance
5.3. Add the Object into the Suitable Cluster
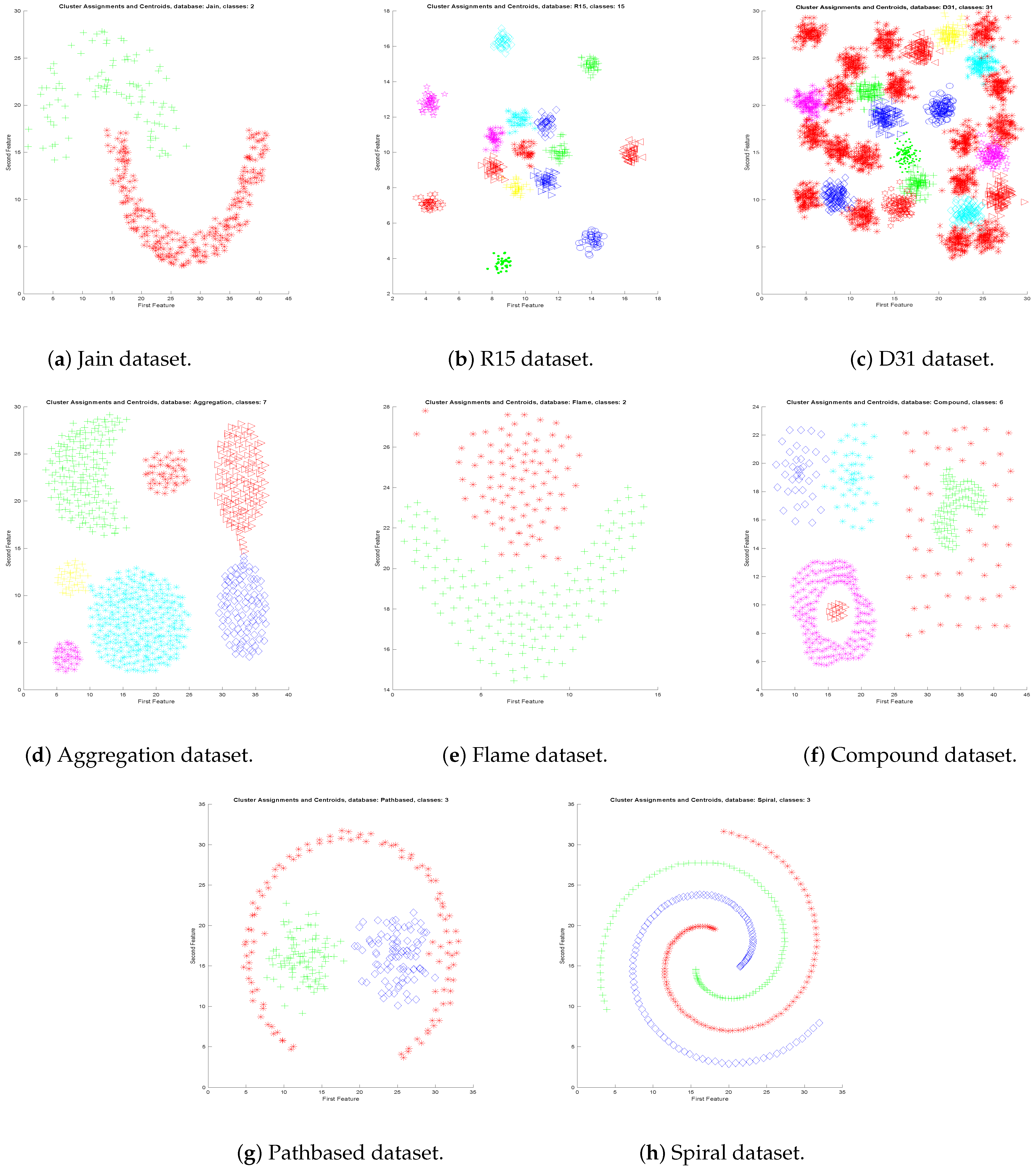
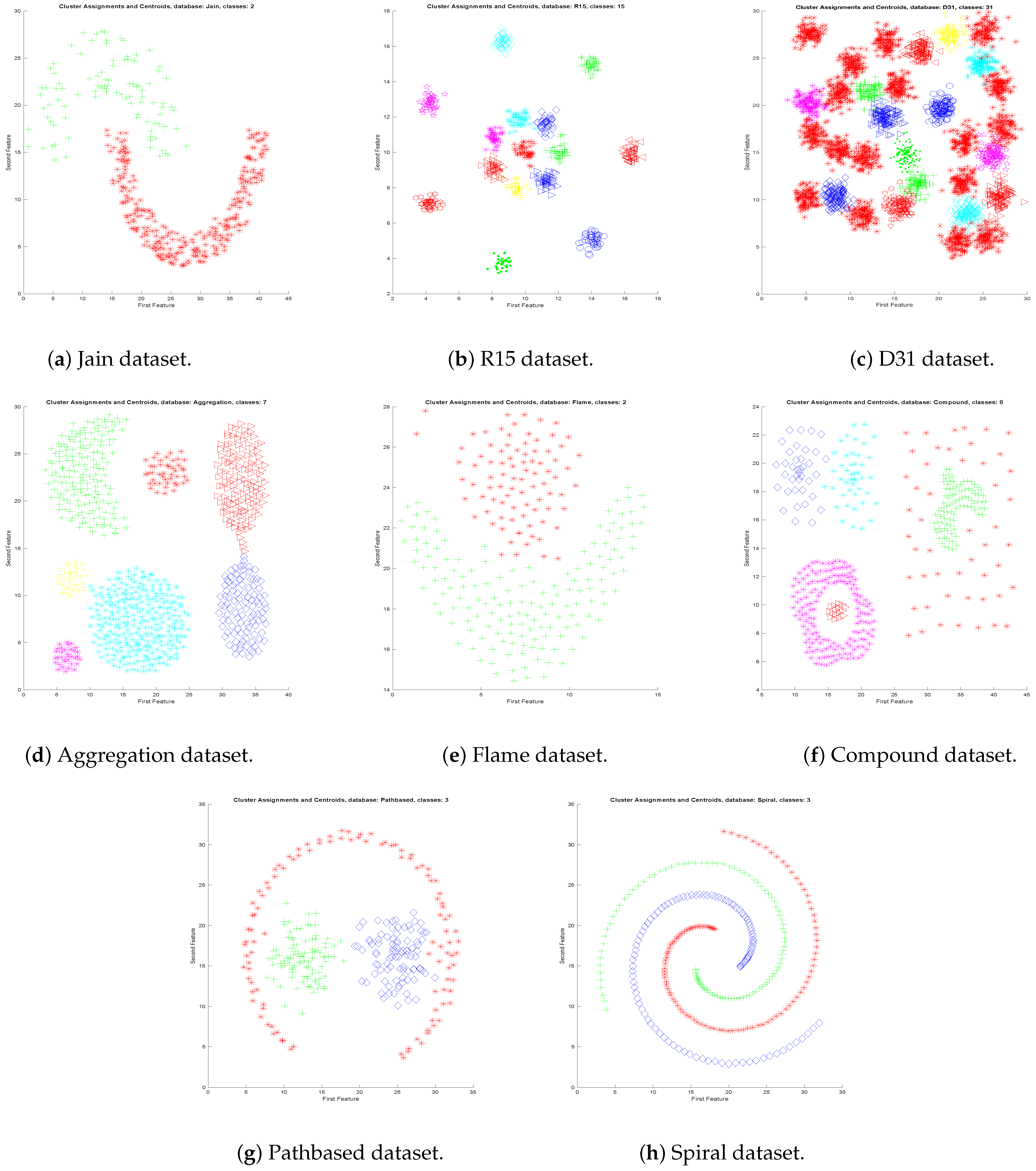
6. Experimental Results
- Medium: Results are good for Flame and Compound datasets (see Figure 5e,f). The clustering error is less than .
- Complex: For the third group, the results of the Pathbased and spiral datasets are good (see Figure 5g,h). The clustering error is less than just for Pathbase dataset. The result for Spiral dataset is .
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Saxena, A.; Prasad, M.; Gupta, A.; Bharill, N.; Patel, O.; Tiwari, A.; Er, M.; Ding, W.; Lin, C.T. A review of clustering techniques and developments. Neurocomputing 2017, 267, 664–681. [Google Scholar] [CrossRef] [Green Version]
- Dong, X.; Yu, Z.; Cao, W.; Shi, Y.; Ma, Q. A survey on ensemble learning. Front. Comput. Sci. 2020, 14, 241–258. [Google Scholar] [CrossRef]
- Zhao, Y.; Tarus, S.; Yang, L.; Sun, J.; Ge, Y.; Wang, J. Privacy-preserving clustering for big data in cyber-physical-social systems: Survey and perspectives. Inf. Sci. 2020, 515, 132–155. [Google Scholar] [CrossRef]
- Fränti, P.; Sieranoja, S. K-means properties on six clustering benchmark datasets. Appl. Intell. 2018, 48, 4743–4759. [Google Scholar] [CrossRef]
- Wan, S.P.; Yan, J.; Dong, J.Y. Personalized individual semantics based consensus reaching process for large-scale group decision making with probabilistic linguistic preference relations and application to COVID-19 surveillance. Expert Syst. Appl. 2022, 191, 116328. [Google Scholar] [CrossRef]
- Xu, D.; Tian, Y. A Comprehensive Survey of Clustering Algorithms. Ann. Data Sci. 2015, 2, 165–193. [Google Scholar] [CrossRef] [Green Version]
- Khandare, A.; Alvi, A.S. Clustering Algorithms: Experiment and Improvements. In Computing and Network Sustainability; Vishwakarma, H., Akashe, S., Eds.; Springer: Singapore, 2017; pp. 263–271. [Google Scholar]
- Patibandla, R.S.M.L.; Veeranjaneyulu, N. Survey on Clustering Algorithms for Unstructured Data. In Intelligent Engineering Informatics; Bhateja, V., Coello Coello, C.A., Satapathy, S.C., Pattnaik, P.K., Eds.; Springer: Singapore, 2018; pp. 421–429. [Google Scholar]
- Osman, M.M.A.; Syed-Yusof, S.K.; Abd Malik, N.N.N.; Zubair, S. A survey of clustering algorithms for cognitive radio ad hoc networks. Wirel. Netw. 2018, 24, 1451–1475. [Google Scholar] [CrossRef]
- Bindra, K.; Mishra, A.; Suryakant. Effective Data Clustering Algorithms. In Soft Computing: Theories and Applications; Ray, K., Sharma, T.K., Rawat, S., Saini, R.K., Bandyopadhyay, A., Eds.; Springer: Singapore, 2019; pp. 419–432. [Google Scholar]
- Djouzi, K.; Beghdad-Bey, K. A Review of Clustering Algorithms for Big Data. In Proceedings of the 2019 International Conference on Networking and Advanced Systems (ICNAS), Annaba, Algeria, 26–27 June 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Ahmad, A.; Khan, S.S. Survey of State-of-the-Art Mixed Data Clustering Algorithms. IEEE Access 2019, 7, 31883–31902. [Google Scholar] [CrossRef]
- Zhang, J.; Liang, Q.; Wang, H. Uniformities on strongly topological gyrogroups. Topol. Its Appl. 2021, 302, 107776. [Google Scholar] [CrossRef]
- Telikani, A.; Tahmassebi, A.; Banzhaf, W.; Gandomi, A. Evolutionary Machine Learning: A Survey. ACM Comput. Surv. 2022, 54, 161. [Google Scholar] [CrossRef]
- Jinyin, C.; Xiang, L.; Haibing, Z.; Xintong, B. A novel cluster center fast determination clustering algorithm. Appl. Soft Comput. 2017, 57, 539–555. [Google Scholar] [CrossRef]
- Schubert, E.; Rousseeuw, P. Faster k-Medoids Clustering: Improving the PAM, CLARA, and CLARANS Algorithms. In Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2019; Volume 11807. [Google Scholar]
- Liu, X.; Zhu, X.; Li, M.; Wang, L.; Zhu, E.; Liu, T.; Kloft, M.; Shen, D.; Yin, J.; Gao, W. Multiple Kernel k-means with Incomplete Kernels. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 1191–1204. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kanika; Rani, K.; Sangeeta; Preeti. Visual Analytics for Comparing the Impact of Outliers in k-Means and k-Medoids Algorithm. In Proceedings of the 2019 Amity International Conference on Artificial Intelligence (AICAI), Dubai, United Arab Emirates, 4–6 February 2019; pp. 93–97. [Google Scholar] [CrossRef]
- Gupta, T.; Panda, S.P. A Comparison of K-Means Clustering Algorithm and CLARA Clustering Algorithm on Iris Dataset. Int. J. Eng. Technol. 2019, 7, 4766–4768. [Google Scholar]
- Li, Y.; Cai, J.; Yang, H.; Zhang, J.; Zhao, X. A Novel Algorithm for Initial Cluster Center Selection. IEEE Access 2019, 7, 74683–74693. [Google Scholar] [CrossRef]
- Zhang, Y.; Bai, X.; Fan, R.; Wang, Z. Deviation-Sparse Fuzzy C-Means With Neighbor Information Constraint. IEEE Trans. Fuzzy Syst. 2019, 27, 185–199. [Google Scholar] [CrossRef]
- Tang, Y.; Ren, F.; Pedrycz, W. Fuzzy C-Means clustering through SSIM and patch for image segmentation. Appl. Soft Comput. 2020, 87, 105928. [Google Scholar] [CrossRef]
- Garcia, M.; Igusa, K. Continuously triangulating the continuous cluster category. Topol. Appl. 2020, 285, 107411. [Google Scholar] [CrossRef]
- Osuna-Galán, I.; Pérez-Pimentel, Y.; Avilés-Cruz, C.; Villegas-Cortez, J. Topology: A Theory of a Pseudometric-Based Clustering Model and Its Application in Content-Based Image Retrieval. Math. Probl. Eng. 2019, 2019, 4540731. [Google Scholar] [CrossRef]
- Lim, J.; Jun, J.; Kim, S.H.; McLeod, D. A Framework for Clustering Mixed Attribute Type Datasets. In Proceedings of the 4th International Conference on Emerging Databases-Technologies, Applications, and Theory (EDB 2012), Seoul, Korea, 23–25 August 2012. [Google Scholar]
- Nazari, Z.; Kang, D.; Asharif, M.; Sung, Y.; Ogawa, S. A new hierarchical clustering algorithm. In Proceedings of the 2015 International Conference on Intelligent Informatics and Biomedical Sciences (ICIIBMS), Okinawa, Japan, 28–30 November 2015; pp. 148–152. [Google Scholar]
- Rashedi, E.; Mirzaei, A.; Rahmati, M. Optimized aggregation function in hierarchical clustering combination. Intell. Data Anal. 2016, 20, 281–291. [Google Scholar] [CrossRef]
- Yao, W.; Dumitru, C.; Loffeld, O.; Datcu, M. Semi-supervised Hierarchical Clustering for Semantic SAR Image Annotation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 1993–2008. [Google Scholar] [CrossRef] [Green Version]
- Pitolli, G.; Aniello, L.; Laurenza, G.; Querzoni, L.; Baldoni, R. Malware family identification with BIRCH clustering. In Proceedings of the 2017 International Carnahan Conference on Security Technology (ICCST), Madrid, Spain, 23–26 October 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Cao, X.; Su, T.; Wang, P.; Wang, G.; Lv, Z.; Li, X. An Optimized Chameleon Algorithm Based on Local Features. In Proceedings of the 2018 10th International Conference on Machine Learning and Computing (ICMLC 2018), Macau, China, 26–28 February 2018; ACM: New York, NY, USA, 2018; pp. 184–192. [Google Scholar] [CrossRef]
- Yokoyama, S.; Bogardi-Meszoly, A.; Ishikawa, H. EBSCAN: An entanglement-based algorithm for discovering dense regions in large geo-social data streams with noise. In Proceedings of the 8th ACM SIGSPATIAL International Workshop on Location-Based Social Networks, Bellevue, WA, USA, 3–6 November 2015. [Google Scholar]
- Rehioui, H.; Idrissi, A.; Abourezq, M.; Zegrari, F. DENCLUE-IM: A New Approach for Big Data Clustering. Procedia Comput. Sci. 2016, 83, 560–567. [Google Scholar] [CrossRef] [Green Version]
- Kumar, K.M.; Reddy, A.R.M. A fast DBSCAN clustering algorithm by accelerating neighbor searching using Groups method. Pattern Recognit. 2016, 58, 39–48. [Google Scholar] [CrossRef]
- Behzadi, S.; Ibrahim, M.A.; Plant, C. Parameter Free Mixed-Type Density-Based Clustering. In Database and Expert Systems Applications; Hartmann, S., Ma, H., Hameurlain, A., Pernul, G., Wagner, R.R., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 19–34. [Google Scholar]
- Matioli, L.C.; Santos, S.; Kleina, M.; Leite, E.A. A new algorithm for clustering based on kernel density estimation. J. Appl. Stat. 2018, 45, 347–366. [Google Scholar] [CrossRef]
- Shu, Z.; Yang, S.; Wu, H.; Xin, S.; Pang, C.; Kavan, L.; Liu, L. 3D Shape Segmentation Using Soft Density Peak Clustering and Semi-Supervised Learning. CAD Comput.-Aided Des. 2022, 145. [Google Scholar] [CrossRef]
- Rashad, M.A.; El-Deeb, H.; Fakhr, M.W. Document Classification Using Enhanced Grid Based Clustering Algorithm. In New Trends in Networking, Computing, E-Learning, Systems Sciences, and Engineering; Elleithy, K., Sobh, T., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 207–215. [Google Scholar]
- Wagner, T.; Feger, R.; Stelzer, A. A fast grid-based clustering algorithm for range/Doppler/DoA measurements. In Proceedings of the 2016 European Radar Conference (EuRAD), London, UK, 5–7 October 2016; pp. 105–108. [Google Scholar]
- Lalitha, K.; Thangarajan, R.; Udgata, S.K.; Poongodi, C.; Sahu, A.P. GCCR: An Efficient Grid Based Clustering and Combinational Routing in Wireless Sensor Networks. Wirel. Pers. Commun. 2017, 97, 1075–1095. [Google Scholar] [CrossRef]
- Deng, C.; Song, J.; Sun, R.; Cai, S.; Shi, Y. Gridwave: A grid-based clustering algorithm for market transaction data based on spatial-temporal density-waves and synchronization. Multimed. Tools Appl. 2018, 77, 29623–29637. [Google Scholar] [CrossRef]
- Chen, J.; Lin, X.; Xuan, Q.; Xiang, Y. FGCH: A fast and grid based clustering algorithm for hybrid data stream. Appl. Intell. 2019, 49, 1228–1244. [Google Scholar] [CrossRef]
- Yang, Y.; Zhu, Z. A Fast and Efficient Grid-Based K-means++ Clustering Algorithm for Large-Scale Datasets. In The Fifth Euro-China Conference on Intelligent Data Analysis and Applications; Krömer, P., Zhang, H., Liang, Y., Pan, J.S., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 508–515. [Google Scholar]
- Menendez, H.; Camacho, D. GANY: A genetic spectral-based Clustering algorithm for Large Data Analysis. In Proceedings of the 2015 IEEE Congress on Evolutionary Computation (CEC), Sendai, Japan, 25–28 May 2015; pp. 640–647. [Google Scholar]
- Shang, R.; Zhang, Z.; Jiao, L.; Wang, W.; Yang, S. Global discriminative-based nonnegative spectral clustering. Pattern Recognit. 2016, 55, 172–182. [Google Scholar] [CrossRef]
- Alamdari, M.; Rakotoarivelo, T.; Khoa, N. A spectral-based clustering for structural health monitoring of the Sydney Harbour Bridge. Mech. Syst. Signal Process. 2017, 87, 384–400. [Google Scholar] [CrossRef]
- Tian, L.; Du, Q.; Kopriva, I.; Younan, N. Spatial-spectral Based Multi-view Low-rank Sparse Sbuspace Clustering for Hyperspectral Imagery. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 8488–8491. [Google Scholar]
- Nemade, V.; Shastri, A.; Ahuja, K.; Tiwari, A. Scaled and Projected Spectral Clustering with Vector Quantization for Handling Big Data. In Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bangalore, India, 18–21 November 2018; pp. 2174–2179. [Google Scholar]
- Ma, L.; Zhang, Y.; Leiva, V.; Liu, S.; Ma, T. A new clustering algorithm based on a radar scanning strategy with applications to machine learning data. Expert Syst. Appl. 2022, 191. [Google Scholar] [CrossRef]
- Dowlatshahi, M.; Nezamabadi-Pour, H. GGSA: A Grouping Gravitational Search Algorithm for data clustering. Eng. Appl. Artif. Intell. 2014, 36, 114–121. [Google Scholar] [CrossRef]
- Kumar, V.; Chhabra, J.; Kumar, D. Automatic cluster evolution using gravitational search algorithm and its application on image segmentation. Eng. Appl. Artif. Intell. 2014, 29, 93–103. [Google Scholar] [CrossRef]
- Nikbakht, H.; Mirvaziri, H. A new algorithm for data clustering based on gravitational search algorithm and genetic operators. In Proceedings of the 2015 The International Symposium on Artificial Intelligence and Signal Processing (AISP), Mashhad, Iran, 3–5 March 2015; pp. 222–227. [Google Scholar]
- Sheshasaayee, A.; Sridevi, D. Fuzzy C-means algorithm with gravitational search algorithm in spatial data mining. In Proceedings of the 2016 International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 26–27 August 2016; Volume 1, pp. 1–5. [Google Scholar]
- Deng, Z.; Qian, G.; Chen, Z.; Su, H. Identifying Tor Anonymous Traffic Based on Gravitational Clustering Analysis. In Proceedings of the 2017 9th International Conference on Intelligent Human-Machine Systems and Cybernetics (IHMSC), Hangzhou, China, 26–27 August 2017; Volume 2, pp. 79–83. [Google Scholar]
- Alswaitti, M.; Ishak, M.; Isa, N. Optimized gravitational-based data clustering algorithm. Eng. Appl. Artif. Intell. 2018, 73, 126–148. [Google Scholar] [CrossRef]
- Yuqing, S.; Junfei, Q.; Honggui, H. Structure design for RBF neural network based on improved K-means algorithm. In Proceedings of the 2016 Chinese Control and Decision Conference (CCDC), Yinchuan, China, 28–30 May 2016; pp. 7035–7040. [Google Scholar]
- Amin, H.; Deabes, W.; Bouazza, K. Clustering of user activities based on adaptive threshold spiking neural networks. In Proceedings of the 2017 Ninth International Conference on Ubiquitous and Future Networks (ICUFN), Milan, Italy, 4–7 July 2017; pp. 1–6. [Google Scholar]
- Abavisani, M.; Patel, V. Deep Multimodal Subspace Clustering Networks. IEEE J. Sel. Top. Signal Process. 2018, 12, 1601–1614. [Google Scholar] [CrossRef] [Green Version]
- Ren, Z.; Chen, J.; Ye, L.; Wang, C.; Liu, Y.; Zhou, W. Application of RBF Neural Network Optimized Based on K-Means Cluster Algorithm in Fault Diagnosis. In Proceedings of the 2018 21st International Conference on Electrical Machines and Systems (ICEMS), Jeju, Korea, 7–10 October 2018; pp. 2492–2496. [Google Scholar]
- Kimura, M. AutoClustering: A feed-forward neural network based clustering algorithm. In Proceedings of the 2018 IEEE International Conference on Data Mining Workshops (ICDMW), Singapore, 17–20 November 2019; Volume 2018, pp. 659–666. [Google Scholar]
- Cheng, Y.; Yu, S.; Liu, J.; Han, Z.; Li, Y.; Tang, Y.; Wu, C. Representation Learning Based on Autoencoder and Deep Adaptive Clustering for Image Clustering. Math. Probl. Eng. 2021, 2021, 3742536. [Google Scholar] [CrossRef]
- Engelking, R. General Topology; Springer International Publishing: Cham, Switzerland, 1989. [Google Scholar]
- Balcerzak, M.; Leonetti, P. On the relationship between ideal cluster points and ideal limit points. Topol. Its Appl. 2019, 252, 178–190. [Google Scholar] [CrossRef] [Green Version]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Clustering Algorithm | Works | Advantages | Disadvantages |
|---|---|---|---|
| Partitional | [14,15,16,17,18,19,20,21,22,23,24] |
|
|
| Hierarchical | [25,26,27,28,29,30] |
|
|
| Density-Based | [6,31,32,33,34,35,36] |
|
|
| Grid-Based | [37,38,39,40,41,42] |
|
|
| Spectral | [43,44,45,46,47,48] |
|
|
| Gravitational | [49,50,51,52,53,54] |
|
|
| Neural Network-Based | [55,56,57,58,59,60] |
|
|
| Dataset | Classes | Samples |
|---|---|---|
| Aggregation | K = 7 | N = 788 |
| Compound | K = 6 | N = 399 |
| Pathbase | K = 3 | N = 300 |
| Spiral | K = 3 | N = 312 |
| D31 | K = 31 | N = 3100 |
| R15 | K = 15 | N = 600 |
| Jain | K = 2 | N = 373 |
| Flame | K = 2 | N = 240 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Osuna-Galán, I.; Pérez-Pimentel, Y.; Aviles-Cruz, C. A Novel 2D Clustering Algorithm Based on Recursive Topological Data Structure. Symmetry 2022, 14, 781. https://doi.org/10.3390/sym14040781
Osuna-Galán I, Pérez-Pimentel Y, Aviles-Cruz C. A Novel 2D Clustering Algorithm Based on Recursive Topological Data Structure. Symmetry. 2022; 14(4):781. https://doi.org/10.3390/sym14040781
Chicago/Turabian StyleOsuna-Galán, Ismael, Yolanda Pérez-Pimentel, and Carlos Aviles-Cruz. 2022. "A Novel 2D Clustering Algorithm Based on Recursive Topological Data Structure" Symmetry 14, no. 4: 781. https://doi.org/10.3390/sym14040781
APA StyleOsuna-Galán, I., Pérez-Pimentel, Y., & Aviles-Cruz, C. (2022). A Novel 2D Clustering Algorithm Based on Recursive Topological Data Structure. Symmetry, 14(4), 781. https://doi.org/10.3390/sym14040781