1. Introduction
In this article, we consider the split feasibility problem (SFP) in the form
where
C and
Q are the nonempty closed convex subsets of the real Hilbert spaces
and
, respectively, and
is a bounded linear operator. The SFP was introduced by Censor and Elfving [
1] for inverse problems which arise from phase retrievals and medical image reconstruction [
2] and were later generalized to the multiple-sets split feasibility problem [
3].
Throughout this article, we assume that the SFP (
1) is consistent, i.e., its solution set, denoted by
is nonempty.
By transforming the SFP as an equivalent constrained optimization problem, Byrne [
2,
4] firstly introduced the well-known CQ algorithms, which have received a great deal of attention from many authors, who improved it in various ways; see, e.g., [
5,
6,
7,
8,
9,
10,
11,
12].
To solve the SFP (
1), Wang [
13] introduced the following gradient method which was called Polyak’s gradient method:
where
and
In fact, (
2) is a special case of the so-called simple projection method in [
14]. The authors [
15] proposed an iterative method for solving the multiple-sets split feasibility problem with splitting self-adaptive stepsizes, which reduces to the following scheme when applied to the SFP (
1):
where
and
and
Note that the difference of the schemes (
2) and (
3) is the choices of the stepsizes.
The Douglas–Rachford splitting method introduced in [
16] is a popular method to solve structured optimization problems. Let
g and
h be proper lower semicontinuous convex functions from a Hilbert space
to
. Consider the structured optimization problem:
Given the initial guess
, the Douglas–Rachford splitting method generates the iterative sequence via the following scheme:
where
is a parameter sequence and
is the proximal parameter sequence of the regularization terms. Note that the scheme (
4) with
was called the general splitting method in [
17] and becomes the Peaceman–Rachford splitting method when
It is easy to see that the split feasibility problem (
1) also equals the following unconstrained minimization problem:
where
and
is the indicator function of the set
C; that is,
if
, otherwise
. Recall that the gradient of
is
. Letting
and
in (
4) and using the linearization technique, the authors [
18] recently introduced the following general splitting methods with linearization for the SFP (
1):
where
is a sequence of positive numbers and
and
The weak convergence of the algorithm (
6) was established under the standard conditions, and the algorithm (
6) has good numerical performance comparing the algorithm (
2) and Algorithm 3.1 in [
10].
In this article, we present an iterative scheme by letting
and
in (
4) and using the linearization technique. The convergence of the corresponding scheme is analyzed.
The rest of the paper is constructed as follows. In
Section 2, we recall some definitions and known results for further analysis. In
Section 3, we present the Douglas–Rachford splitting method with linearization and its relaxed version. In
Section 4, we show the weak convergence of the proposed algorithm, which converges weakly to a solution of the SFP. In
Section 5, we give two numerical experiments to show the behavior of the algorithm. Finally, some concluding remarks are given in
Section 6.
2. Preliminaries
Let be a Hilbert space and K be a nonempty closed convex subset of . We use the notation:
The following identity will be used for the main results (see [
19], Corollary 2.15):
for all
and
.
Definition 1 ([
19], Definition 6.38)
. Let K be a nonempty convex subset of and let . The normal cone to K at x is For a point
x, the the classical metric projection of
x onto
K, denoted by
, is defined by
Lemma 1 ([
19], Proposition 4.4)
. For any and , the following hold:- (i)
- (ii)
;
- (iii)
It follows from Lemma 1 (iii) that
Recall that a mapping
is called to be
nonexpansive if
Lemma 1 (i) implies that is firmly nonexpansive and consequently nonexpansive.
The next lemma shows that the nonexpansive mappings are demiclosed at 0.
Lemma 2 ([
19], Theorem 4.27)
. Let K be a nonempty closed convex subset of and be a nonexpansive mapping. Let be a sequence in K and such that and as . Then . Lemma 3 ([
19], Lemma 2.47)
. Let K be a nonempty closed convex subset of and be a sequence in such that the following two conditions hold:- (i)
For all , exists;
- (ii)
Every sequential weak cluster point of is in K.
Then the sequence converges weakly to a point in K.
3. Douglas–Rachford Splitting Method with Linearization
In this section, we introduce Douglas–Rachford splitting method with linearization and its relaxed variant.
Using symmetry, we can set
and
in (
4). Now, we present a direct adaptation of the Douglas–Rachford splitting method (
4), which can solve the equivalent problem (
5) of the SFP (
1). (see Algorithm 1)
| Algorithm 1 Douglas–Rachford splitting method. |
Step 0. Input , . Step 1. Generate by
where and are sequences of positive numbers. Step 2. If a termination criterion is not met, then set and go to Step 1.
|
By the first-order optimality condition of the second formula of (
9) in Algorithm 1,
To calculate
, we need to get
, which is very difficult. In order to overcome this difficulty, we linearize
at
. Then, the second formula of (
9) becomes
Its first-order optimality condition is
Thus, we get the following linearized Douglas–Rachford splitting method:
After a simple calculation, we get
In what follows, we present the Douglas–Rachford splitting method with linearization. (see Algorithm 2)
| Algorithm 2 Douglas–Rachford splitting method with linearization. |
Step 0. Input , . Step 1. Given , generate by
where and are two sequences of positive numbers. Step 2. If and , then terminate. Otherwise, set and go to Step 1.
|
Remark 1. Algorithm 2 is a general scheme with two parameters sequences and , which includes the algorithms (2) and (3) as special cases. Indeed, - (i)
Let and , then, Algorithm 2 becomes the algorithm (2); - (ii)
Let and then, Algorithm 2 becomes the algorithm (3).
In the following, we extend the ranges of the parameter sequences
and
in the algorithm (
3). To this end, let
and
where
,
and
Then, Algorithm 2 becomes
Note that
and
. Comparing (
3) and (
10), the ranges of the parameter sequences
and
in the algorithm (
3) are extended from (0,1) to (0,2). It is worth noting that
and
cannot both be in (1,2). In fact, one is in (0,2), while the other is in (0,1). Due to
, Algorithm 2 is the Douglas–Rachford splitting method with linearization.
We give two choices of , as follows:
Note that the upper and lower bounds are imposed in the adaptive choice of to guarantee . Therefore, it is not fully adaptive.
Now, the following lemma shows the validity of the stopping criterion through Step 2 of the Douglas–Rachford splitting method with linearization.
Lemma 4. If and for some k, then generated by Algorithm 2
is a solution of the SFP (1). Proof. Using
and
, we get
, which implies
Thus,
We deduce that
is a solution of the SFP (
1) because of the first-order optimality condition
of problem (
5). □
In Algorithm 2, we generally assume that the projections
and
are easy to calculate. However, projection is sometimes impossible or difficult to calculate. In order to solve this problem, we consider a general situation of
C and
Q in SFP (
1).
and
are level sets, where
and
are convex functions. We assume that
and
are bounded operators and define the sets
and
as follows:
where
, and
where
.
Next, we define
and introduce the relaxed Douglas–Rachford splitting method with linearization. (see Algorithm 3)
| Algorithm 3 Relaxed Douglas–Rachford splitting method with linearization. |
Step 0. Input , . Step 1. Given , generate by
where and are two sequences of positive numbers. Step 2. If and , then terminate. Otherwise, set and go to Step 1.
|
4. Convergence Analysis
In this section, we prove the weak convergence of Algorithm 2 under the standard conditions.
Firstly, we present two lemmas which are key for the convergence of Algorithm 2.
Lemma 5. Let be the sequence generated by Algorithm 2 from any initial point and . Let Then it holds Proof. From (
16) and the definition of
, it follows
Combining (
14), (
17) and (
18), we deduce (
13). The proof is completed. □
Remark 2. The inequality (13) with the ranges of the parameters shows the monotonically decreasing property of the sequence . It is not the same as the inequality in [15], and the latter reduces to the following form for the SFP (1): It is difficult to compare them and show which is better in theory. The numerical experiments in Section 5 illustrate that the optimal choices of the parameters of and is that one is in (0,2) while the others are in (0,1). Lemma 6. Let be the sequence generated by Algorithm 2 from any initial point , . Let is given adaptively.
- (i)
If , it holds - (ii)
If , it holds
Proof. (i) In this case,
. Similar to Lemma 5, we have
The inequality (
21) becomes
After simple calculations, we get
where the last equality holds due to (
11). Combining (
22) and (
23), we get (
19);
(ii) In this case,
or
. By Lemma 5, it is easy to obtain (
20). □
Theorem 1. Let be generated by Algorithm 2; then, converges weakly to a solution of the SFP (1). Proof. By (
13), (
19) and (
20), we have
which implies that
is bounded and
exists. From the definition of
, it follows
Combining (
13), (
19), (
20) and (
24), we deduce
and
To use Lemma 3, we need to show
. To this end, take arbitrarily
and let
where
is a subsequence of
. From Lemma 2 and (
25), we get
. Combining (
26) and the weak lower semicontinuity of
f, we obtain
Hence, , i.e., . Thus, we have . By Lemma 3, we deduce that converges weakly to a point in . The proof is completed. □
Combining Theorem 1 and [
18] (Theorem 3.2), it is easy to verify the convergence of Algorithm 3.
Theorem 2. Let be generated by Algorithm 3; then, converges weakly to a solution of the SFP (
1)
. 5. Numerical Results
In this section, we show the behavior of Algorithm 2 by comparing it with the algorithms (
3) and (
2) through two numerical examples.
For convenience, we denote the vector with all elements 0 by and the vector with all elements 1 by in what follows. In the next two numerical examples, we take the objective function value as the stopping criterion.
Example 1 ([
6])
. Consider the SFP, where () and generated randomly andwhere d is the center of the ball C, , is the radius, d and r are both generated randomly. L and U are the boundary of the box Q and are also generated randomly, satisfying and , respectively. In the numerical experiment, we take the objective function value as the stopping criterion.
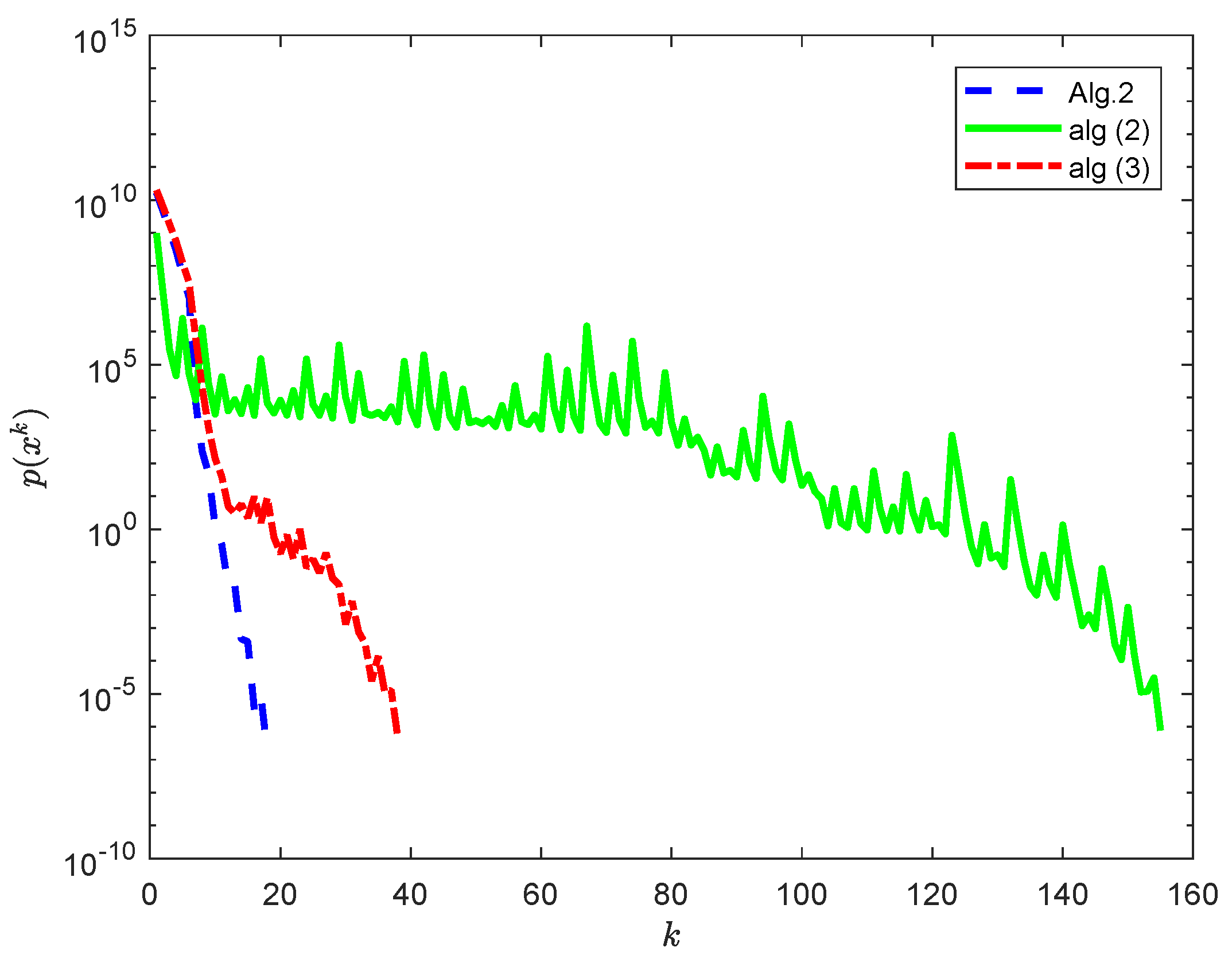
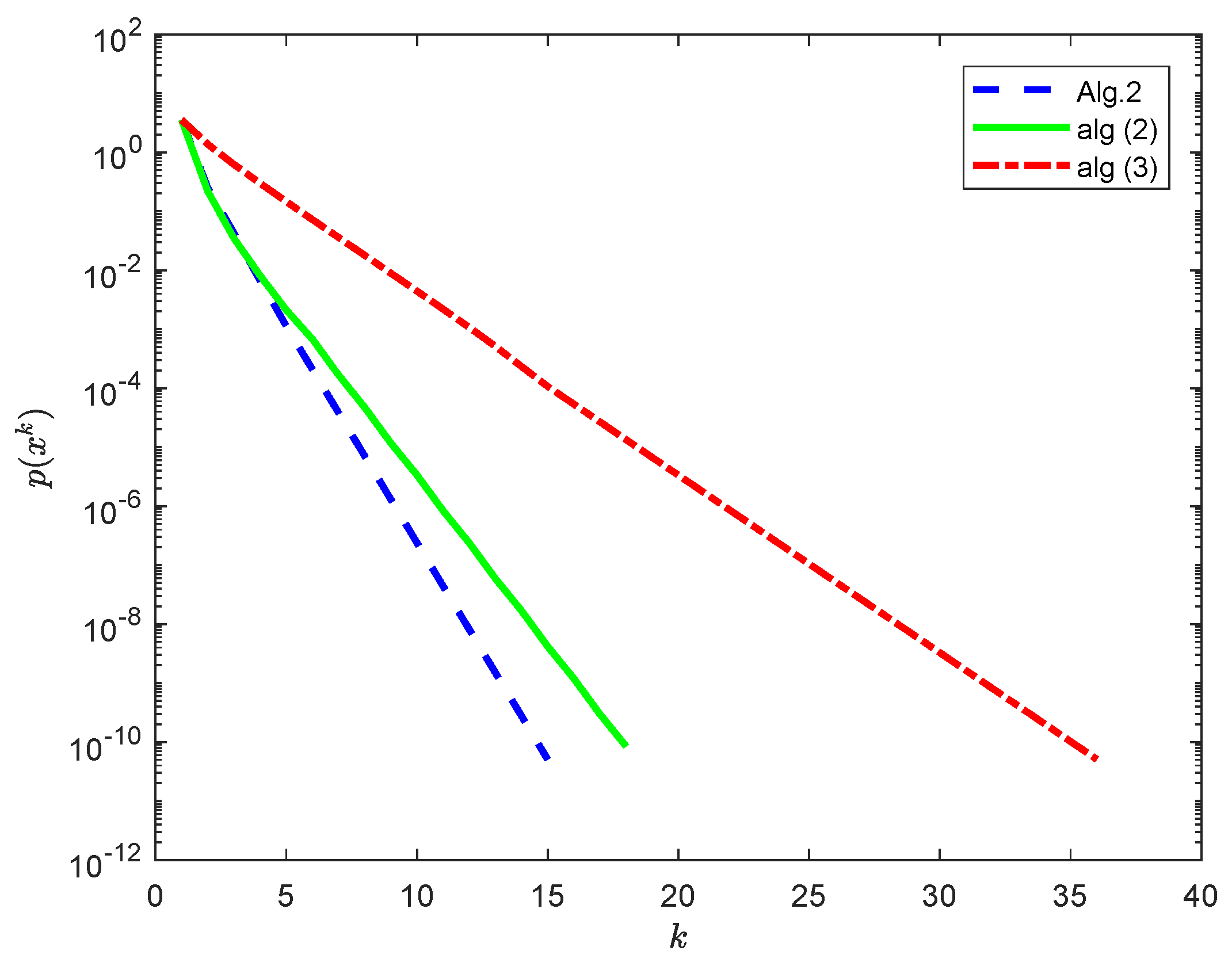
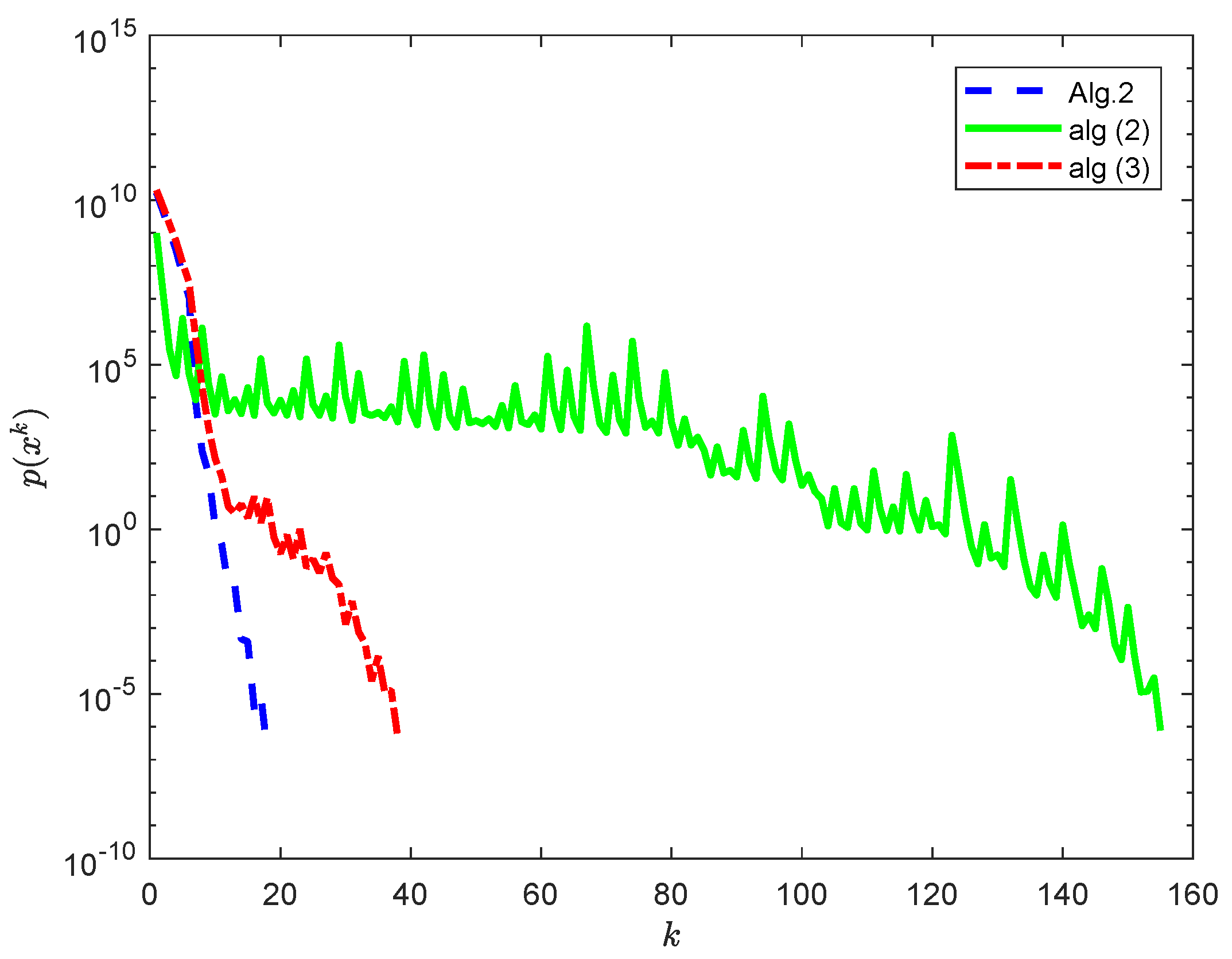
In
Figure 1, the initial point
is randomly chosen. For comparing Algorithm 2 with the algorithms (
2) and (
3), we take
,
and
in Algorithm 2,
in the algorithm (
2) and
and
in the algorithm (
3).
In
Table 1, we show the iteration steps and CPU time of Algorithm 2, algorithm (
2) and algorithm (
3) for 3 initial points. For case 1,
; for case 2,
= (100, −100, ⋯, 100, −100); and for case 3,
.
As shown in
Figure 1 and the iteration steps in
Table 1, Algorithm 2 behaves better than the algorithms (
2) and (
3).
Example 2. Suppose that with norm and inner product Letwhere and . In this case, we haveAdditionally, letwhere and ; then, we obtain Consider the matrixresulting from a discretization of the operator question of the first kind In the numerical experiment, the initial function is . We take as the stopping criterion.
For comparing Algorithm 2 with the algorithms (
2) and (
3), we take
,
and
in Algorithm 2,
in the algorithm (
2) and
and
in the algorithm (
3). From
Figure 2, we can see that the performance of Algorithm 2 is better than the algorithms (
2) and (
3).
6. Some Concluding Remarks
In this article, we introduce the Douglas–Rachford splitting method with linearization for the split feasibility problem, which is a general method and includes the methods in [
13,
15] as special cases. The weak convergence of the proposed method is established under the standard conditions. Numerical experiments illustrate the effectiveness of our methods.
The methods proposed in this article can be generalized to solve the multiple-sets split feasibility problem. It is interesting to investigate the other possible choices of the parameters and .
Recently, some authors have applied self-adaptive step sizes to split generalized equilibrium and fixed point problems [
20] and pseudo-monotone equilibrium problems [
21]. The numerical examples illustrate that the step sizes have excellent behaviour. Applying the self-adaptive step size to the split feasibility problem is worth investigating.




{kind=link}
{kind=link}