
A Survey of Automatic Source Code Summarization

 ,
,
Abstract
:1. Introduction
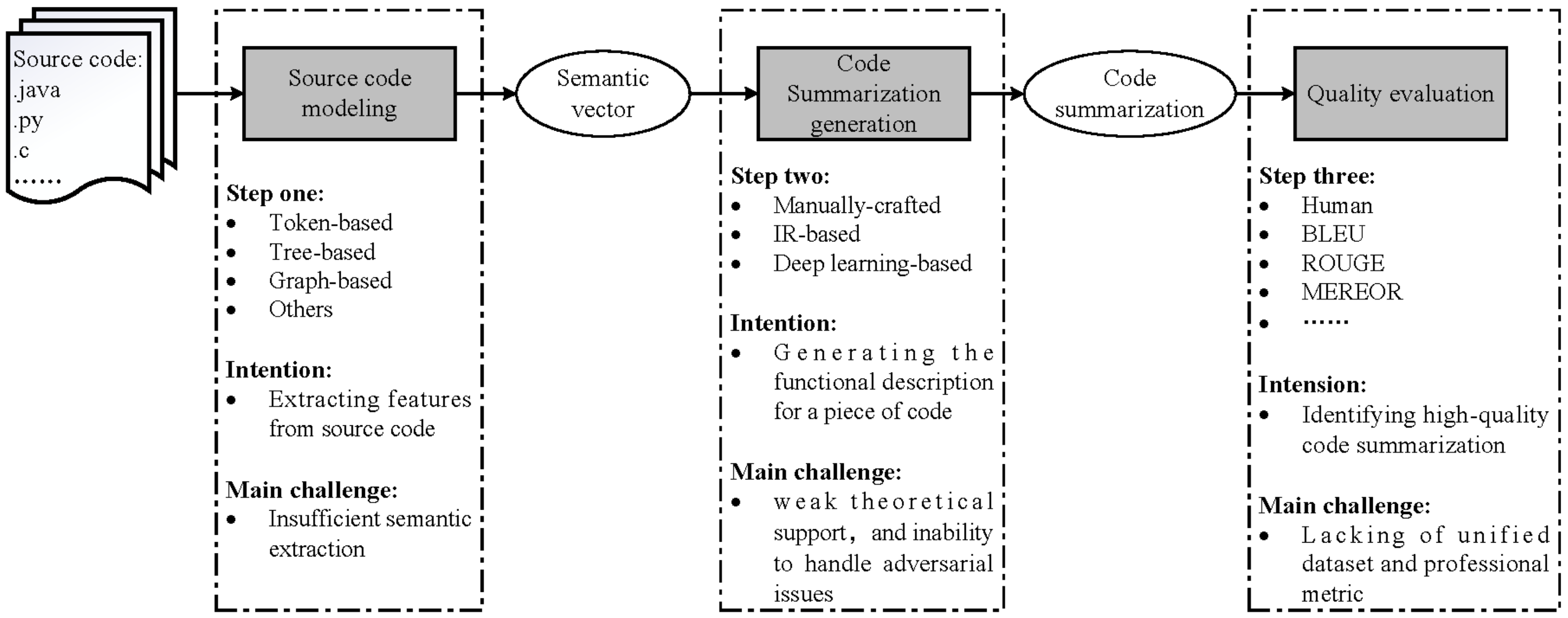
- The source code modeling used to extract features from source code, such as lexical information, syntax information, and semantics information. Here are the main difficulties:
- Different from plain text, the source code contains rich syntax and structure information;
- Faced with different programming languages, both the analysis methods and standards are different;
- Each developer has his own code logic and naming conventions, which makes the source code irregular;
- Various programming languages and identifier names lead to huge vocabularies of source code.
- In terms of ASCS methods, the Information Retrieval (IR)-based algorithms extract keywords from the source code, or look for summarization of similar codes. Distinctly, the effect of these algorithms depends on the quality of datasets. With the development of artificial intelligence technology, researchers have applied the methods of Natural Language Processing (NLP) for ASCS, and have achieved significant results. However, there are still some problems, such as long-term dependence, the limitations of ASCS algorithms, and the lack of high-quality datasets.
- The quality evaluation is another challenge. The existing ASCS algorithms are mostly evaluated on different datasets, which makes it difficult to compare the effect of the algorithms. Besides, the quality evaluation methods of NLP are used for code summarization, but the source code is different from natural language text. Thus, an efficient and low-cost ASCS evaluation method is an important issue that needs to be solved urgently. Here are the main challenges of quality evaluation:
- Lacking unified datasets;
- Lacking recognized and reasonable benchmarks used as the baseline;
- Lacking professional evaluation indicators.
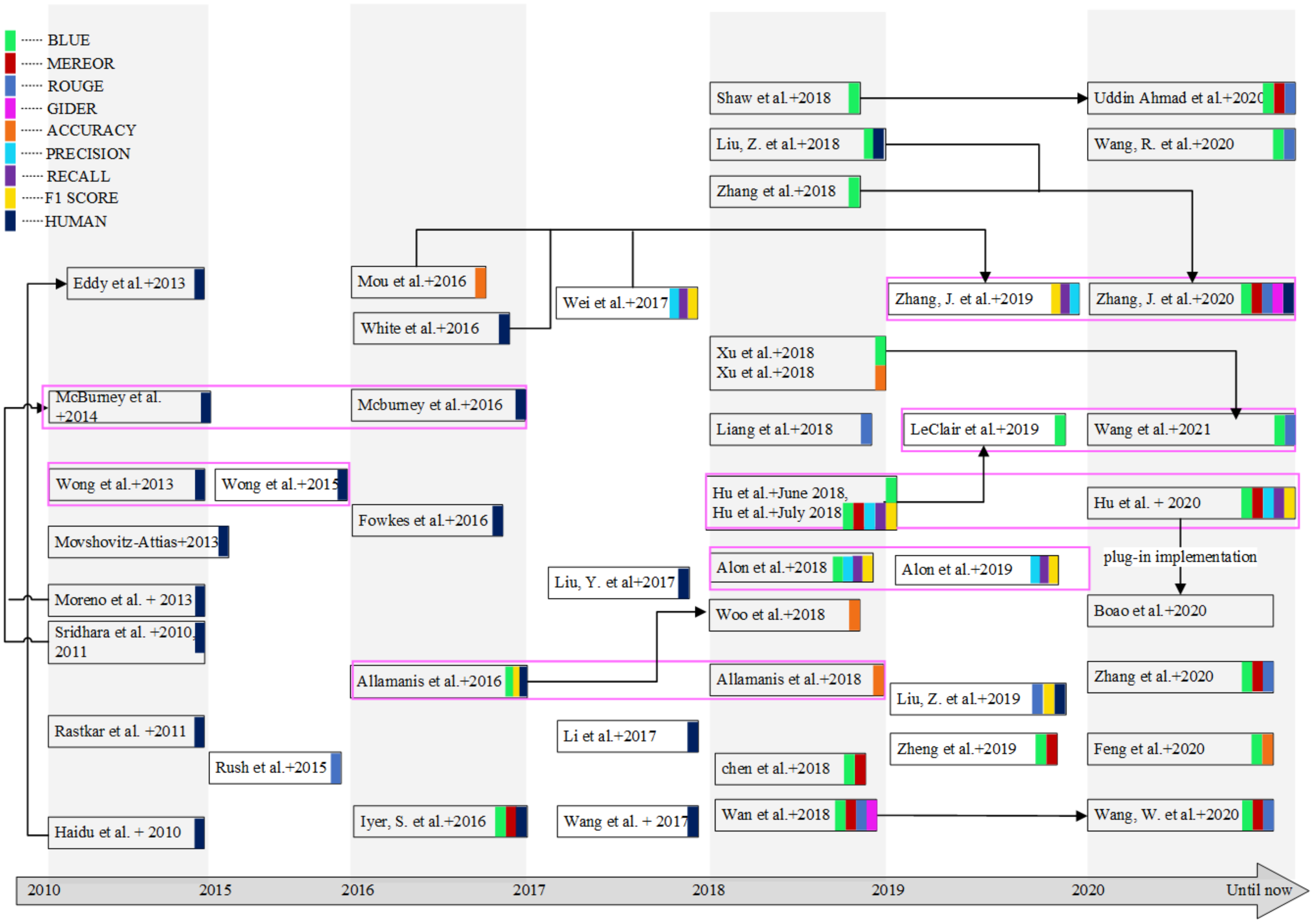
- It discusses the origin of ASCS technology, its evolution over the past decade;
- It concludes the advantages and disadvantages of the above representative methods, and the work with improved relationships between these approaches;
- It provides a synthesized summary of the challenges and future research that requires the attention of the researchers;
- It collates a comprehensive list of available datasets and codes, which are conducive to further research by scholars.
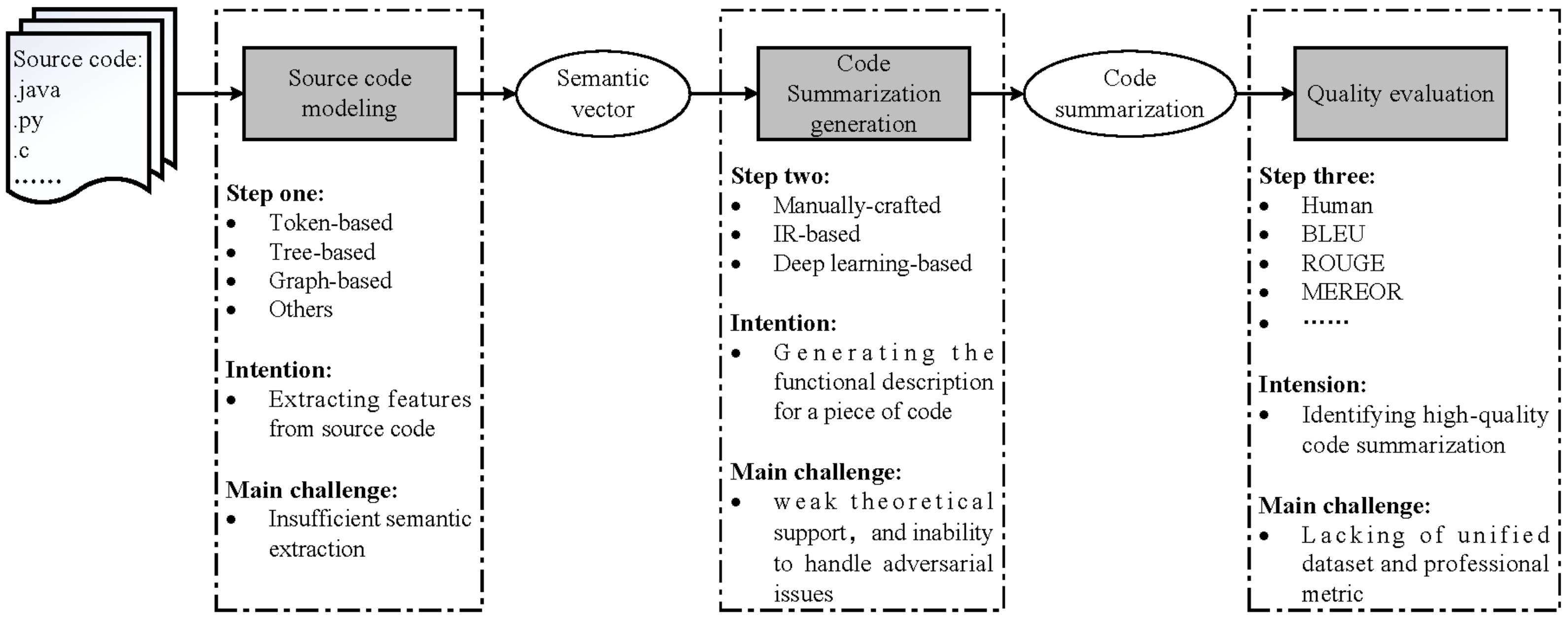
2. Overview of ASCS
3. Source Code Modeling
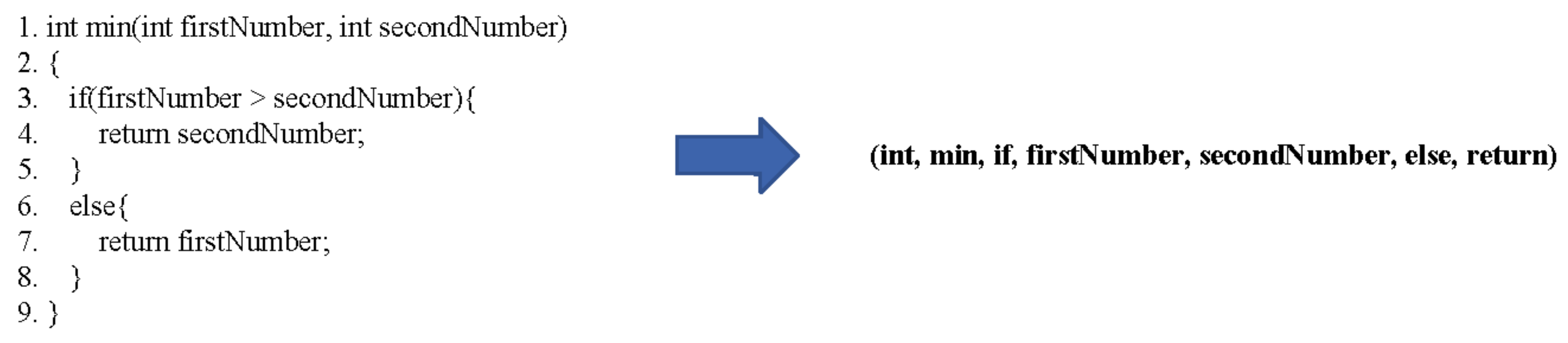
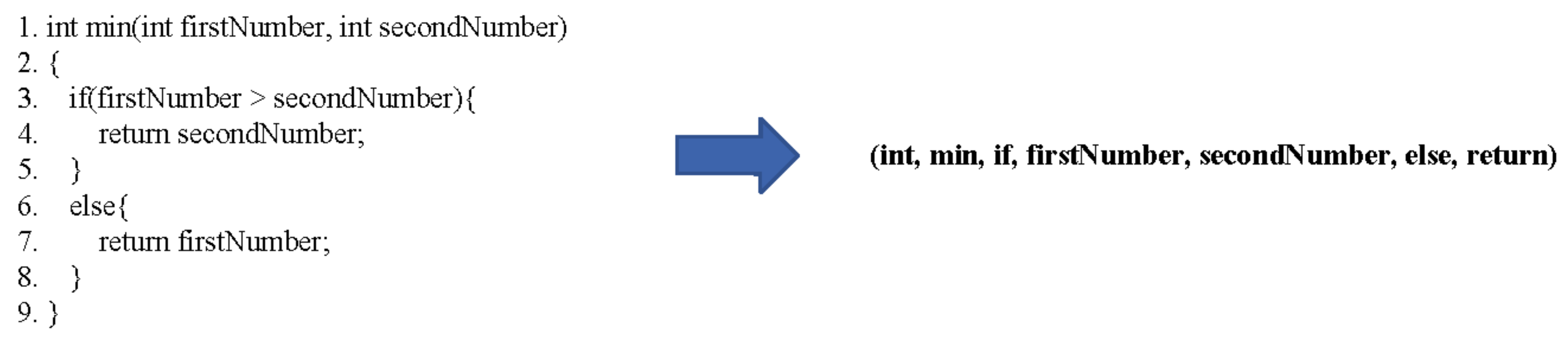
3.1. Token-Based Source Code Model
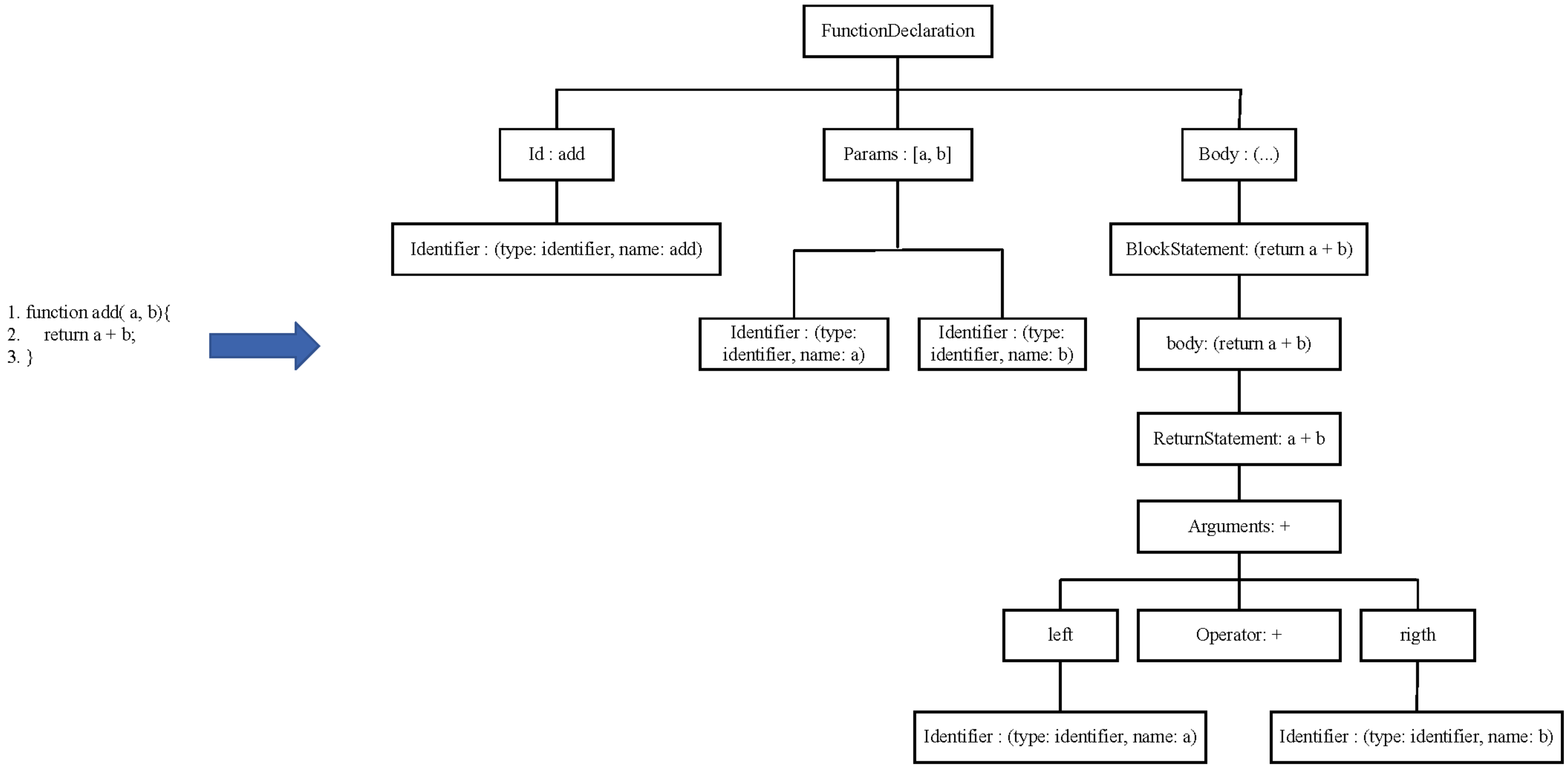
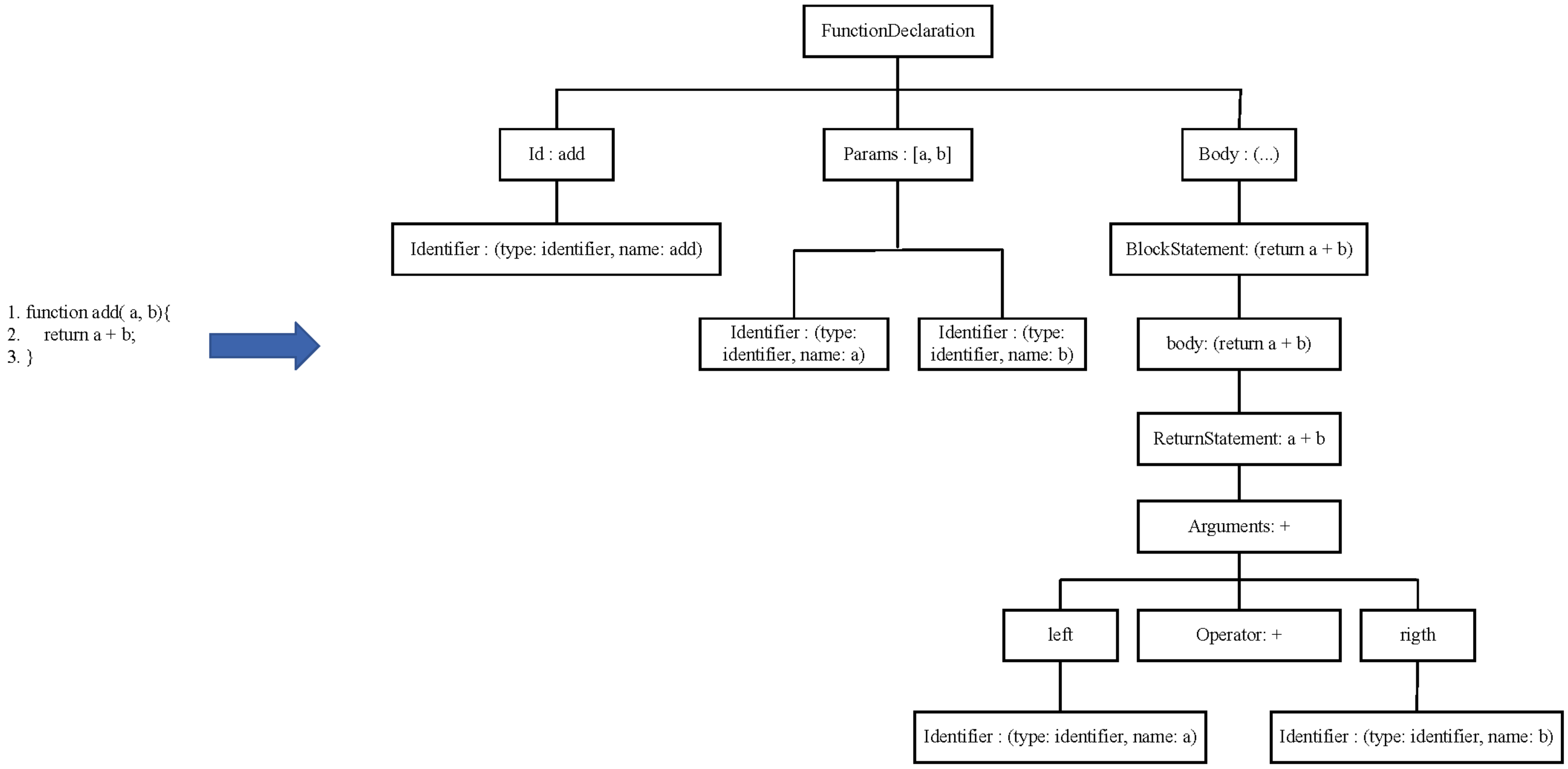
3.2. Tree-Based Source Code Model
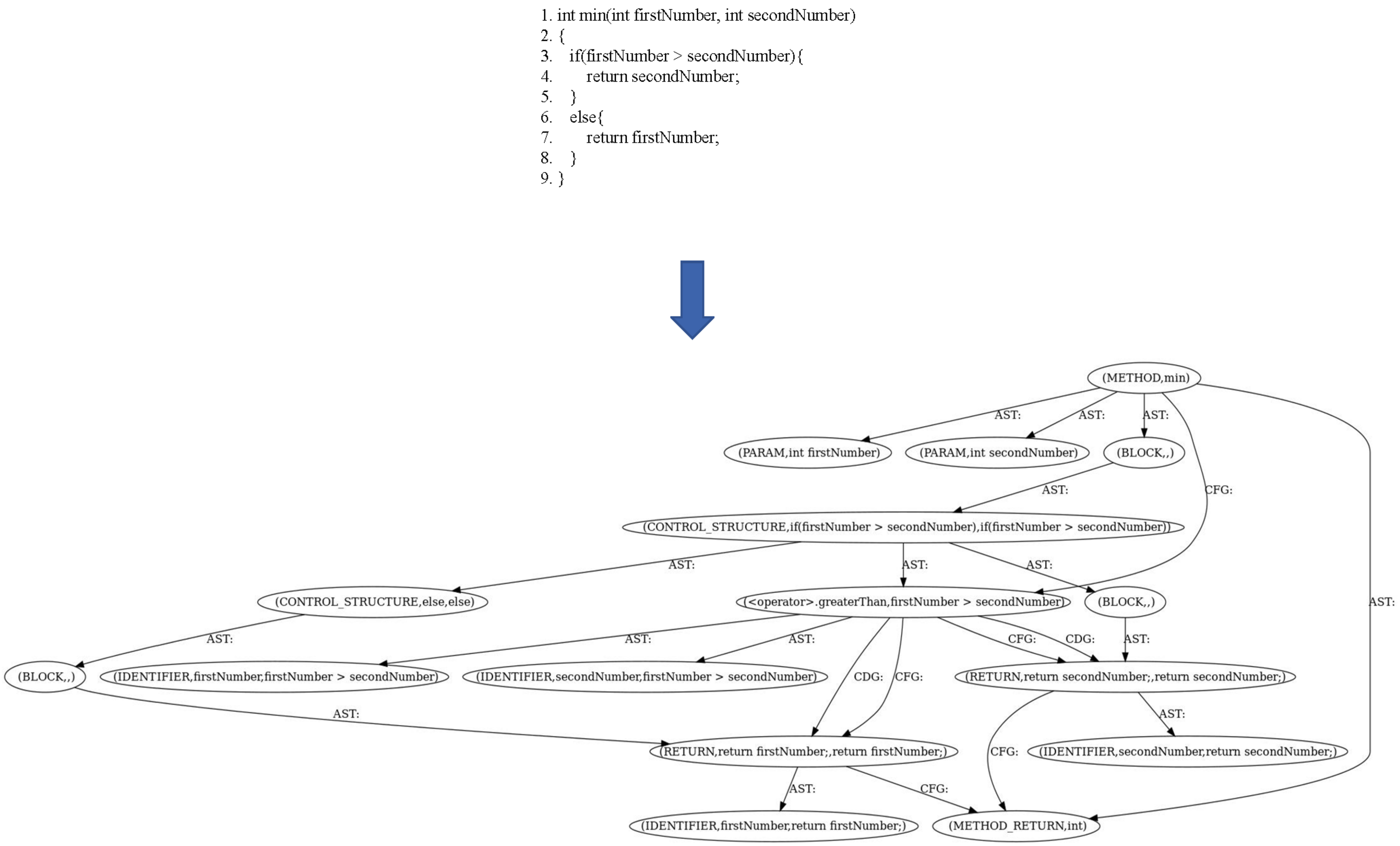
3.3. Graph-Based Source Code Model
3.4. Other Source Code Models
4. Code Summarization Generation
4.1. Manually-Crafted Templates-Based ASCS Generation
4.2. IR-Based ASCS Generation
4.3. DL-Based ASCS Generation
5. Quality Evaluation
5.1. Datasets
5.2. Automatic Evaluation Mechanism
5.3. Human Evaluation
6. Discussion and Conclusions
- The current research is almost generative or search-based, but combining the two to generate code summaries is a promising research direction;
- Large-scale language training model will be an inevitable requirement with the increasing daily data. In view of the complex structure and semantic information of source code, it will be a meaningful research direction to combine the graph neural network to represent source code in large-scale language training model;
- The CPG [114] is a good multi-feature integrated extraction tool. However, the existing works can only be applied in C/C++. In the future works, we can use it for many other programming languages;
- The challenges concluded in the paper are urgent issues to be solved in ASCS. If they were to be solved, it would greatly enhance the recognition and research significance.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Steidl, D.; Hummel, B.; Juergens, E. Quality analysis of source code comments. In Proceedings of the 2013 21st International Conference on Program Comprehension (ICPC), San Francisco, CA, USA, 20–21 May 2013. [Google Scholar]
- Yau, S.S.; Collofello, J.S. Some stability measures for software maintenance. IEEE Trans. Softw. Eng. 1980, SE-6, 545–552. [Google Scholar] [CrossRef]
- Woodfifield, S.N.; Dunsmore, H.E.; Shen, V.Y. The effect of modularization and comments on program comprehension. In Proceedings of the 5th International Conference on Software Engineering, San Diego, CA, USA, 9–12 March 1981; pp. 215–223. [Google Scholar]
- Tenny, T. Program readability: Procedures versus comments. IEEE Trans. Softw. Eng. 1988, 14, 1271–1279. [Google Scholar] [CrossRef] [Green Version]
- Xia, X.; Bao, L.; Lo, D.; Xing, Z.; Hassan, A.E.; Li, S. Measuring program comprehension: A large-scale field study with professionals. IEEE Trans. Softw. Eng. 2017, 44, 951–976. [Google Scholar] [CrossRef]
- Hu, X.; Li, G.; Xia, X.; Lo, D.; Jin, Z. Deep code comment generation. In Proceedings of the 26th Conference on Program Comprehension, Gothenburg, Sweden, 27 May–3 June 2018; pp. 200–210. [Google Scholar]
- Haiduc, S.; Aponte, J.; Marcus, A. Supporting program comprehension with source code summarization. In Proceedings of the 2010 ACM/Ieee 32nd International Conference on Software Engineering, Cape Town, South Africa, 2–8 May 2010; pp. 223–226. [Google Scholar]
- Haiduc, S.; Aponte, J.; Moreno, L.; Marcus, A. On the use of automated text summarization techniques for summarizing source code. In Proceedings of the 2010 17th Working Conference on Reverse Engineering, Beverly, MA, USA, 13–16 October 2010; pp. 35–44. [Google Scholar]
- Sridhara, G.; Hill, E.; Muppaneni, D.; Pollock, L.; Vijay-Shanker, K. Towards automatically generating summary comments for Java methods. In Proceedings of the ASE 2010, 25th IEEE/ACM International Conference on Automated Software Engineering, Antwerp, Belgium, 20–24 September 2010. [Google Scholar]
- Sridhara, G.; Pollock, L.L.; Vijay-Shanker, K. Automatically detecting and describing high level actions within methods. In Proceedings of the International Conference on Software Engineering, Honolulu, HI, USA, 21–28 May 2011. [Google Scholar]
- Moreno, L.; Aponte, J.; Sridhara, G.; Marcus, A.; Pollock, L.; Vijay-Shanker, K. Automatic generation of natural language summaries for Java classes. In Proceedings of the IEEE International Conference on Program Comprehension, San Francisco, CA, USA, 20–21 May 2013. [Google Scholar]
- Rastkar, S.; Murphy, G.C.; Bradley, A.W.J. Generating natural language summaries for crosscutting source code concerns. In Proceedings of the 2011 27th IEEE International Conference on Software Maintenance (ICSM), Williamsburg, VA, USA, 25–30 September 2011. [Google Scholar]
- McBurney, P.W.; McMillan, C. Automatic documentation generation via source code summarization of method context. In Proceedings of the 22nd International Conference on Program Comprehension, Hyderabad, India, 2–3 June 2014; pp. 279–290. [Google Scholar]
- Rush, A.M.; Chopra, S.; Weston, J. A neural attention model for abstractive sentence summarization. arXiv 2015, arXiv:1509.00685. [Google Scholar]
- Allamanis, M.; Peng, H.; Sutton, C. A convolutional Attention network for extreme summarization of source code. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 2091–2100. [Google Scholar]
- Wang, X.; Pollock, L.; Vijay-Shanker, K. Automatically generating natural language descriptions for object-related statement sequences. In Proceedings of the 2017 IEEE 24th International Conference on Software Analysis, Evolution and Reengineering (SANER), Klagenfurt, Austria, 20–24 February 2017; pp. 205–216. [Google Scholar]
- Hu, X.; Li, G.; Xia, X.; Lo, D.; Lu, S.; Jin, Z. Summarizing source code with transferred api knowledge. In Proceedings of the TwentySeventh International Joint Conference on Artificial Intelligence, IJCAI-18, Stockholm, Sweden, 13–19 July 2018; pp. 2269–2275. [Google Scholar]
- Huang, Y.; Jia, N.; Zhou, Q.; Chen, X.P.; Xiong, Y.F.; Luo, X.N. Method combining structural and semantic features to support code commenting decision. Ruan Jian Xue Bao/J. Softw. 2018, 29, 2226–2242, (In Chinese with English abstract). [Google Scholar]
- Wan, Y.; Zhao, Z.; Yang, M.; Xu, G.; Ying, H.; Wu, J.; Yu, P.S. Improving automatic source code summarization via deep reinforcement learning. In Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering, Montpellier, France, 3–7 September 2018; pp. 397–407. [Google Scholar]
- Al-Msie’deen, R.F.; Blasi, A.H. Supporting software documentation with source code summarization. arXiv 2018, arXiv:1901.01186. [Google Scholar] [CrossRef] [Green Version]
- Zheng, W.; Zhou, H.; Li, M.; Wu, J. CodeAttention: Translating source code to comments by exploiting the code constructs. Front. Comput. Sci. 2019, 13, 565–578. [Google Scholar] [CrossRef]
- LeClair, A.; Jiang, S.; McMillan, C. A neural model for generating natural language summaries of program subroutines. In Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), Montreal, QC, Canada, 25–31 May 2019; pp. 795–806. [Google Scholar]
- Zhang, J.; Wang, X.; Zhang, H.; Sun, H.; Liu, X. Retrieval-based neural source code summarization. In Proceedings of the 42nd International Conference on Software Engineering, Seoul, Korea, 5–11 October 2020. [Google Scholar]
- Wang, R.; Zhang, H.; Lu, G.; Lyu, L.; Lyu, C. Fret: Functional Reinforced Transformer with BERT for Code Summarization. IEEE Access 2020, 8, 135591–135604. [Google Scholar] [CrossRef]
- Feng, Z.; Guo, D.; Tang, D.; Duan, N.; Feng, X.; Gong, M.; Zhou, M. Codebert: A pre-trained model for programming and natural languages. arXiv 2020, arXiv:2002.08155. [Google Scholar]
- Uddin Ahmad, W.; Chakraborty, S.; Ray, B.; Chang, K.W. A Transformer-based Approach for Source Code Summarization. arXiv 2020, arXiv:2005.00653. [Google Scholar]
- Panichella, S.; Aponte, J.; Penta, M.D.; Marcus, A.; Canfora, G. Mining source code descriptions from developer communications. In Proceedings of the IEEE International Conference on Program Comprehension, Passau, Germany, 11–13 June 2012. [Google Scholar]
- Nazar, N.; Hu, Y.; Jiang, H. Summarizing software artifacts: A literature review. J. Comput. Sci. Technol. 2016, 31, 883–909. [Google Scholar] [CrossRef]
- Yang, B.; Liping, Z.; Fengrong, Z. A Survey on Research of Code Comment. In Proceedings of the the 2019 3rd International Conference, Wuhan, China, 12–14 January 2019. [Google Scholar]
- Chen, Z.; Monperrus, M. A literature study of embeddings on source code. arXiv 2019, arXiv:1904.03061. [Google Scholar]
- Song, X.; Sun, H.; Wang, X.; Yan, J. A Survey of Automatic Generation of Source Code Comments: Algorithms and Techniques. IEEE Access 2019, 7, 111411–111428. [Google Scholar] [CrossRef]
- Fluri, B.; Wursch, M.; Gall, H.C. Do code and comments co-evolve? On the relation between source code and comment changes. In Proceedings of the 14th Working Conference on Reverse Engineering (WCRE 2007), Vancouver, BC, Canada, 28–31 October 2007; pp. 70–79. [Google Scholar]
- Frantzeskou, G.; MacDonell, S.; Stamatatos, E.; Gritzalis, S. Examining the signifificance of high-level programming features in source code author classifification. J. Syst. Softw. 2008, 81, 447–460. [Google Scholar] [CrossRef] [Green Version]
- Mou, L.; Li, G.; Zhang, L.; Wang, T.; Jin, Z. Convolutional Neural Networks over Tree Structures for Programming Language Processing. In Proceedings of the Thirtieth AAAI conference on artificial intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- LeClair, A.; Eberhart, Z.; McMillan, C. Adapting neural text classification for improved software categorization. In Proceedings of the 2018 IEEE International Conference on Software Maintenance and Evolution (ICSME), Madrid, Spain, 23–29 September 2018; pp. 461–472. [Google Scholar]
- Gu, X.; Zhang, H.; Kim, S. Deep code search. In Proceedings of the 2018 IEEE/ACM 40th International Conference on Software Engineering (ICSE), Gothenburg, Sweden, 27 May–3 June 2018; pp. 933–944. [Google Scholar]
- Guo, D.; Ren, S.; Lu, S.; Feng, Z.; Tang, D.; Liu, S.; Zhou, M. GraphCodeBERT: Pre-training Code Representations with Data Flow. arXiv 2020, arXiv:2009.08366. [Google Scholar]
- Kamiya, T.; Kusumoto, S.; Inoue, K. CCFinder: A multilinguistic token-based code clone detection system for large scale source code. IEEE Trans. Softw. Eng. 2002, 28, 654–670. [Google Scholar] [CrossRef] [Green Version]
- White, M.; Tufano, M.; Vendome, C.; Poshyvanyk, D. Deep learning code fragments for code clone detection. In Proceedings of the 31st IEEE/ACM International Conference on Automated Software Engineering (ASE), Singapore, 3–7 September 2016; pp. 87–98. [Google Scholar]
- Wei, H.; Li, M. Supervised Deep Features for Software Functional Clone Detection by Exploiting Lexical and Syntactical Information in Source Code. In Proceedings of the IJCAI, Melbourne, Australia, 19–25 August 2017; pp. 3034–3040. [Google Scholar]
- Wong, E.; Yang, J.; Tan, L. Autocomment: Mining question and answer sites for automatic comment generation. In Proceedings of the 2013 28th IEEE/ACM International Conference on Automated Software Engineering (ASE), Silicon Valley, CA, USA, 11–15 November 2013; pp. 562–567. [Google Scholar]
- Jiang, S.; Armaly, A.; McMillan, C. Automatically generating commit messages from diffs using neural machine translation. In Proceedings of the 32nd IEEE/ACM International Conference on Automated Software Engineering, Urbana, IL, USA, 30 October–3 November 2017; pp. 135–146. [Google Scholar]
- Alon, U.; Brody, S.; Levy, O.; Yahav, E. code2seq: Generating sequences from structured representations of code. arXiv 2018, arXiv:1808.01400. [Google Scholar]
- Hu, X.; Li, G.; Xia, X.; Lo, D.; Jin, Z. Deep code comment generation with hybrid lexical and syntactical information. Empir. Softw. Eng. 2020, 25, 2179–2217. [Google Scholar] [CrossRef]
- Sharma, T.; Kechagia, M.; Georgiou, S.; Tiwari, R.; Sarro, F. A Survey on Machine Learning Techniques for Source Code Analysis. arXiv 2021, arXiv:2110.09610. [Google Scholar]
- Zhang, J.; Wang, X.; Zhang, H.; Sun, H.; Wang, K.; Liu, X. A novel neural source code representation based on abstract syntax tree. In Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), Montreal, QC, Canada, 25–31 May 2019. [Google Scholar]
- Ishio, T.; Etsuda, S.; Inoue, K. A lightweight visualization of interprocedural data-flow paths for source code reading. In Proceedings of the 2012 20th IEEE International Conference on Program Comprehension (ICPC), Passau, Germany, 11–13 June 2012. [Google Scholar]
- Ben-Nun, T.; Jakobovits, A.S.; Hoefler, T. Neural code comprehension: A learnable representation of code semantics. Adv. Neural Inf. Process. Syst. 2018, 31, 3585–3597. [Google Scholar]
- Johnson, R.; Zhang, T. Deep pyramid convolutional neural networks for text categorization. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, Canada, 30 July–4 August 2017; pp. 562–570. [Google Scholar]
- Tufano, M.; Watson, C.; Bavota, G.; Di Penta, M.; White, M.; Poshyvanyk, D. Deep learning similarities from different representations of source code. In Proceedings of the 2018 IEEE/ACM 15th International Conference on Mining Software Repositories (MSR), Gothenburg, Sweden, 27 May–3 June 2018; pp. 542–553. [Google Scholar]
- Wang, K.; Singh, R.; Su, Z. Dynamic neural program embedding for program repair. arXiv 2017, arXiv:1711.07163. [Google Scholar]
- Efstathiou, V.; Spinellis, D. Semantic source code models using identifier embeddings. In Proceedings of the 2019 IEEE/ACM 16th International Conference on Mining Software Repositories (MSR), Montreal, QC, Canada, 25–31 May 2019; pp. 29–33. [Google Scholar]
- Henkel, J.; Lahiri, S.K.; Liblit, B.; Reps, T. Code vectors: Understanding programs through embedded abstracted symbolic traces. In Proceedings of the 2018 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Athens, Greece, 23–28 August 2018; pp. 163–174. [Google Scholar]
- Alon, U.; Sadaka, R.; Levy, O.; Yahav, E. Structural language models of code. In Proceedings of the International Conference on Machine Learning, Virtual, 28–29 November 2020; Volume 119, pp. 245–256. [Google Scholar]
- Allamanis, M.; Brockschmidt, M.; Khademi, M. Learning to Represent Programs with Graphs. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Hussain, Y.; Huang, Z.; Zhou, Y.; Wang, S. CodeGRU: Context-aware deep learning with gated recurrent unit for source code modeling. Inf. Softw. Technol. 2020, 125, 106309. [Google Scholar] [CrossRef] [Green Version]
- Chen, F.; Kim, M.; Choo, J. Novel Natural Language Summarization of Program Code via Leveraging Multiple Input Representations. In Proceedings of the Findings of the Association for Computational Linguistics (EMNLP 2021), Punta Cana, Dominican Republic, 7–11 November 2021; pp. 2510–2520. [Google Scholar]
- Wang, J.; Xue, X.; Weng, W. Source code summarization technology based on syntactic analysis. J. Comput. Appl. 2015, 35, 1999. [Google Scholar]
- Iyer, S.; Konstas, I.; Cheung, A.; Zettlemoyer, L. Summarizing Source Code using a Neural Attention Model. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics 2016, Berlin, Germany, 7–12 August 2016; pp. 2073–2083. [Google Scholar]
- Mcburney, P.W.; Mcmillan, C. Automatic Source Code Summarization of Context for Java Methods. IEEE Trans. Softw. Eng. 2016, 42, 103–119. [Google Scholar] [CrossRef]
- Fowkes, J.; Chanthirasegaran, P.; Ranca, R.; Allamanis, M.; Lapata, M.; Sutton, C. TASSAL: Autofolding for source code summarization. In Proceedings of the 2016 IEEE/ACM 38th International Conference on Software Engineering Companion (ICSE-C), Austin, TX, USA, 14–22 May 2016; pp. 649–652. [Google Scholar]
- Chen, Q.; Zhou, M. A neural framework for retrieval and summarization of source code. In Proceedings of the 2018 33rd IEEE/ACM International Conference on Automated Software Engineering (ASE), Montpellier, France, 3–7 September 2018; pp. 826–831. [Google Scholar]
- Liang, Y.; Zhu, K.Q. Automatic generation of text descriptive comments for code blocks. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Alon, U.; Zilberstein, M.; Levy, O.; Yahav, E. code2vec: Learning distributed representations of code. In Proceedings of the ACM on Programming Languages, Athens, Greece, 21–22 October 2019; Volume 3, pp. 1–29. [Google Scholar]
- Liu, Z.; Xia, X.; Treude, C.; Lo, D.; Li, S. Automatic generation of pull request descriptions. In Proceedings of the 2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE), San Diego, CA, USA, 11–15 November 2019; pp. 176–188. [Google Scholar]
- Zhang, S.K.; Xie, R.; Ye, W. Keyword G asedSourceCodeSummarization. J. Comput. Res. Dev. 2020, 57, 1987, (In Chinese with English abstract). [Google Scholar]
- LeClair, A.; Haque, S.; Wu, L.; McMillan, C. Improved code summarization via a graph neural network. In Proceedings of the 28th International Conference on Program Comprehension, Seoul, Korea, 13–15 July 2020; pp. 184–195. [Google Scholar]
- Zügner, D.; Kirschstein, T.; Catasta, M.; Leskovec, J.; Günnemann, S. Language-agnostic representation learning of source code from structure and context. arXiv 2021, arXiv:2103.11318. [Google Scholar]
- Bansal, A.; Haque, S.; McMillan, C. Project-level encoding for neural source code summarization of subroutines. In Proceedings of the 2021 IEEE/ACM 29th International Conference on Program Comprehension (ICPC), Madrid, Spain, 20–21 May 2021; pp. 253–264. [Google Scholar]
- Shahbazi, R.; Sharma, R.; Fard, F.H. API2Com: On the Improvement of Automatically Generated Code Comments Using API Documentations. In Proceedings of the 2021 IEEE/ACM 29th International Conference on Program Comprehension (ICPC), Madrid, Spain, 20–21 May 2021; pp. 411–421. [Google Scholar]
- Socher, R.; Lin, C.C.; Manning, C.; Ng, A.Y. Parsing natural scenes and natural language with recursive neural networks. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), Bellevue, WA, USA, 28 June–2 July 2011; pp. 129–136. [Google Scholar]
- Li, Y.; Tarlow, D.; Brockschmidt, M.; Zemel, R. Gated graph sequence neural networks. arXiv 2015, arXiv:1511.05493. [Google Scholar]
- Ou, M.; Cui, P.; Pei, J.; Zhang, Z.; Zhu, W. Asymmetric transitivity preserving graph embedding. In Proceedings of the 22Nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Wang, M.; Tang, Y.; Wang, J.; Deng, J. Premise selection for theorem proving by deep graph embedding. Adv. Neural Inf. Process. Syst. 2017, 30, 2783–2793. [Google Scholar]
- Zhou, Y.; Liu, S.; Siow, J.; Du, X.; Liu, Y. Devign: Effective vulnerability identification by learning comprehensive program semantics via graph neural networks. Adv. Neural Inf. Process. Syst. 2019, 32, 10197–10207. [Google Scholar]
- Hill, E. Integrating Natural Language and Program Structure Information to Improve Software Search and Exploration; University of Delaware: Newark, DE, USA, 2010. [Google Scholar]
- Movshovitz-Attias, D.; Cohen, W. Natural language models for predicting programming comments. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, Sofia, Bulgaria, 4–9 August 2013; Volume 2, pp. 35–40. [Google Scholar]
- Eddy, B.P.; Robinson, J.A.; Kraft, N.A.; Carver, J.C. Evaluating source code summarization techniques: Replication and expansion. In Proceedings of the 2013 21st International Conference on Program Comprehension (ICPC), San Francisco, CA, USA, 20–21 May 2013; pp. 13–22. [Google Scholar]
- Wong, E.; Liu, T.; Tan, L. Clocom: Mining existing source code for automatic comment generation. In Proceedings of the 2015 IEEE 22nd International Conference on Software Analysis, Evolution, and Reengineering (SANER), Montreal, QC, Canada, 2–6 March 2015; pp. 380–389. [Google Scholar]
- Li, W.P.; Zhao, J.F.; Xie, B. Summary Extraction Method for Code Topic Based on LDA. Comput. Sci. 2017, 44, 35–38, (In Chinese with English abstract). [Google Scholar]
- Liu, Y.; Sun, X.B.; Li, B. Research on Automatic Summarization for Java Packages. J. Front. Comput. Sci. Technol. 2017, 11, 46–54, (In Chinese with English abstract). [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block Attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 10 September 2018; pp. 3–19. [Google Scholar]
- Xu, K.; Wu, L.; Wang, Z.; Yu, M.; Chen, L.; Sheinin, V. Exploiting rich syntactic information for semantic parsing with graph-to-sequence model. arXiv 2018, arXiv:1808.07624. [Google Scholar]
- Xu, K.; Wu, L.; Wang, Z.; Feng, Y.; Witbrock, M.; Sheinin, V. Graph2seq: Graph to sequence learning with Attention-based neural networks. arXiv 2018, arXiv:1804.00823. [Google Scholar]
- Zhang, J.; Utiyama, M.; Sumita, E.; Neubig, G.; Nakamura, S. Guiding neural machine translation with retrieved translation pieces. arXiv 2018, arXiv:1804.02559. [Google Scholar]
- Liu, Z.; Xia, X.; Hassan, A.E.; Lo, D.; Xing, Z.; Wang, X. Neural-machine-translation-based commit message generation: How far are we? In Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering, New York, NY, USA, 3–7 September 2018; pp. 373–384. [Google Scholar]
- Shaw, P.; Uszkoreit, J.; Vaswani, A. Self-attention with relative position representations. arXiv 2018, arXiv:1803.02155. [Google Scholar]
- Wang, W.; Zhang, Y.; Sui, Y.; Wan, Y.; Zhao, Z.; Wu, J.; Xu, G. Reinforcement-Learning-Guided Source Code Summarization via Hierarchical Attention. IEEE Trans. Softw. Eng. 2020, 48, 102–119. [Google Scholar] [CrossRef]
- Li, B.; Yan, M.; Xia, X.; Li, G.; Lo, D. DeepCommenter: A deep code comment generation tool with hybrid lexical and syntactical information. In Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Virtual Event, 8–13 November 2020; pp. 1571–1575. [Google Scholar]
- LeClair, A.; Bansal, A.; McMillan, C. Ensemble Models for Neural Source Code Summarization of Subroutines. In Proceedings of the 2021 IEEE International Conference on Software Maintenance and Evolution (ICSME), Luxembourg, 27 September–1 October 2021; pp. 286–297. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.; Le, Q.V.; Salakhutdinov, R. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv 2019, arXiv:1901.02860. [Google Scholar]
- Yao, Z.; Peddamail, J.R.; Sun, H. CoaCor: Code annotation for code retrieval with reinforcement learning. In Proceedings of the The World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 2203–2214. [Google Scholar]
- Yu, Z.; Zheng, W.; Wang, J.; Tang, Q.; Nie, S.; Wu, S. CodeCMR: Cross-Modal Retrieval For Function-Level Binary Source Code Matching. Adv. Neural Inf. Process. Syst. 2020, 33, 3872–3883. [Google Scholar]
- Miceli-Barone, A.V.; Sennrich, R. A parallel corpus of Python functions and documentation strings for automated code documentation and code generation. In Proceedings of the Eighth International Joint Conference on Natural Language Processing, Taipei, Taiwan, 27 November–1 December 2017; Volume 48, pp. 1–5. [Google Scholar]
- Lopes, C. UCI Source Code Data Sets. Available online: http://www.ics.uci.edu/-lopes/datasets/ (accessed on 18 November 2019).
- LeClair, A.; McMillan, C. Recommendations for datasets for source code summarization. arXiv 2019, arXiv:1904.02660. [Google Scholar]
- Svajlenko, J.; Islam, J.F.; Keivanloo, I.; Roy, C.K.; Mia, M.M. Towards a big data curated benchmark of inter-project code clones. In Proceedings of the Software Maintenance and Evolution (ICSME), Victoria, BC, Canada, 29 September–3 October 2014; pp. 476–480. [Google Scholar]
- Wang, X. Java Opensource Repository. Available online: https://www.eecis.udel.edu/~xiwang/open-source-projects-data.html (accessed on 19 October 2019).
- Gousios, G.; Vasilescu, B.; Serebrenik, A.; Zaidman, A. Lean GHTorrent: GitHub data on demand. In Proceedings of the 11th Working Conference on Mining Software Repositories, Hyderabad, India, 31 May–1 June 2014; pp. 384–387. [Google Scholar]
- Lu, S.; Guo, D.; Ren, S.; Huang, J.; Svyatkovskiy, A.; Blanco, A.; Clement, C.; Drain, D.; Jiang, D.; Liu, S.; et al. Codexglue: A machine learning benchmark dataset for code understanding and generation. arXiv 2021, arXiv:2102.04664. [Google Scholar]
- Husain, H.; Wu, H.H.; Gazit, T.; Allamanis, M.; Brockschmidt, M. Codesearchnet challenge: Evaluating the state of semantic code search. arXiv 2019, arXiv:1909.09436. [Google Scholar]
- Shi, E.; Wang, Y.; Du, L.; Chen, J.; Han, S.; Zhang, H.; Zhang, D.; Sun, H. Neural Code Summarization: How Far Are We? arXiv 2021, arXiv:2107.07112. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL), Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Lin, C.-Y. ROUGE: A package for automatic evaluation of summaries. In Proceedings of the Workshop on Text Summarization of ACL, Barcelona, Spain, 25–26 July 2004; pp. 74–81. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 9 June 2005; pp. 65–72. [Google Scholar]
- Vedantam, R.; Zitnick, C.L.; Parikh, D. CIDEr: Consensus-based Image Description Evaluation. arXiv 2014, arXiv:1411.5726. [Google Scholar]
- Aizawa, A. An information-theoretic perspective of tf–idf measures. Inf. Process. Manag. 2003, 39, 45–65. [Google Scholar] [CrossRef]
- Khamis, N.; Witte, R.; Rilling, J. Automatic quality assessment of source code comments: The JavadocMiner. In Proceedings of the International Conference on Application of Natural Language to Information Systems, Cardiff, UK, 23–25 June 2010; pp. 68–79. [Google Scholar]
- Gao, X.S.; Du, J.; Wang, Q. Quality Evaluation Framework of Source Code Analysis Comments. Comput. Syst. Appl. 2015, 24, 1–8, (In Chinese with English abstract). [Google Scholar]
- Sun, X.; Geng, Q.; Lo, D.; Duan, Y.; Liu, X.; Li, B. Code comment quality analysis and improvement recommendation: An automated approach. Int. J. Softw. Eng. Knowl. Eng. 2016, 26, 981–1000. [Google Scholar] [CrossRef]
- Yu, H.; Li, B.; Wang, P.X. Source code comments quality assessment method based on aggregation of classification algorithms. J. Comput. Appl. 2016, 36, 3448–3453, (In Chinese with English abstract). [Google Scholar]
- Wang, D.; Guo, Y.; Dong, W.; Wang, Z.; Liu, H.; Li, S. Deep Code-Comment Understanding and Assessment. IEEE Access 2019, 7, 174200–174209. [Google Scholar] [CrossRef]
- Ren, S.; Guo, D.; Lu, S.; Zhou, L.; Liu, S.; Tang, D.; Sundaresan, N.; Zhou, M.; Blanco, A.; Ma, S. CodeBLEU: A Method for Automatic Evaluation of Code Synthesis. arXiv 2020, arXiv:2009.10297. [Google Scholar]
- Yamaguchi, F.; Golde, N.; Arp, D.; Rieck, K. Modeling and Discovering Vulnerabilities with Code Property Graphs. In Proceedings of the 2014 IEEE Symposium on Security and Privacy, Berkeley, CA, USA, 18–21 May 2014. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
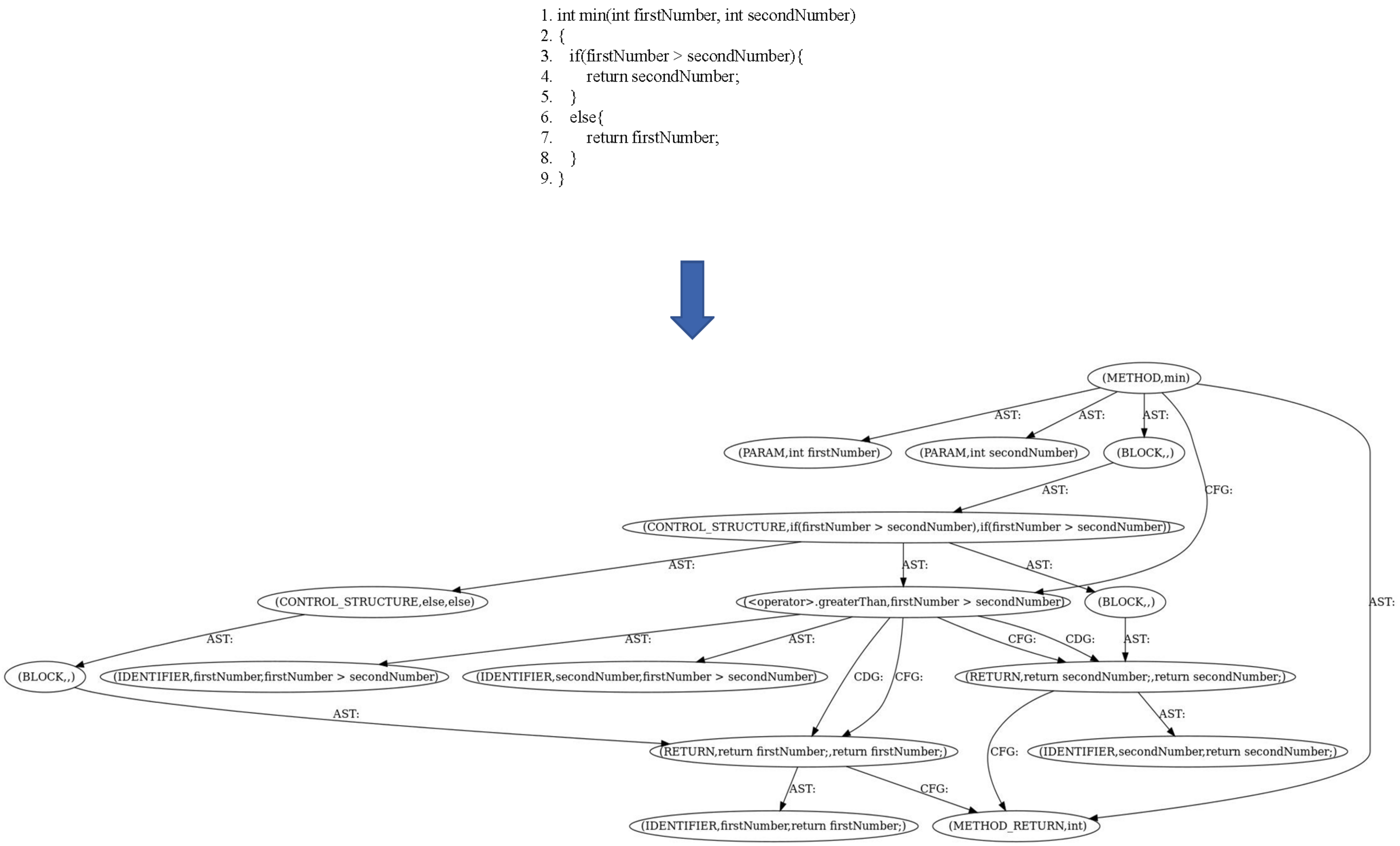{kind=link}
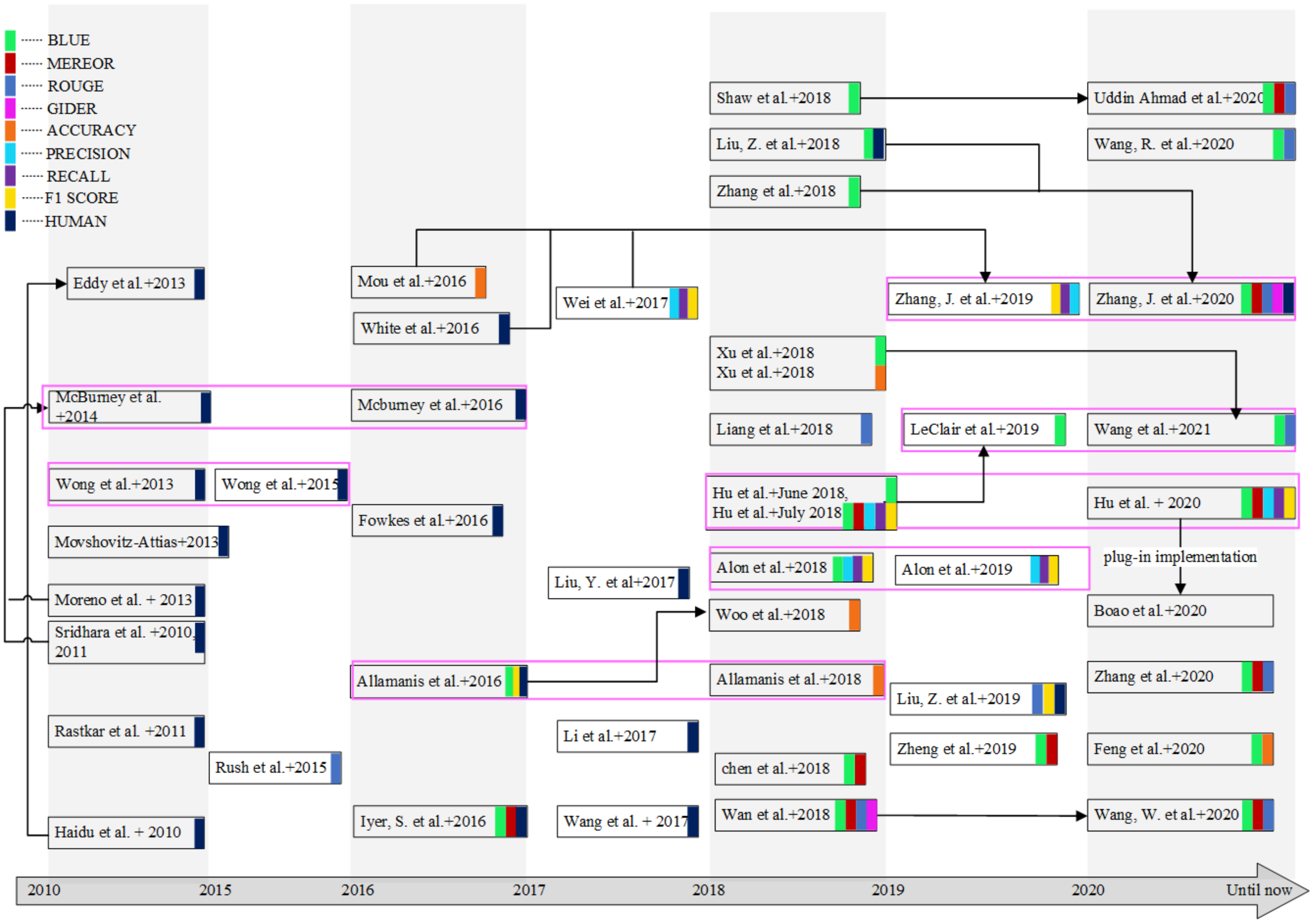{kind=link}
| Models | Year | Venue | Seq | Stc | ML | Src Representation | Tasks |
|---|---|---|---|---|---|---|---|
| Attention [15] | 2016 | ICML | ✓ | × | ✓ | Subtokens | SCS |
| TBCNN [34] | 2016 | AAAI | ✓ | ✓ | ✓ | AST | CP, CCD |
| LSTM [59] | 2016 | ACL | ✓ | × | ✓ | tokens | SCS, CR |
| SWUM [60] | 2016 | TSE | ✓ | × | ✓ | tokens | SCS |
| VSM [61] | 2016 | ICSE | ✓ | ✓ | × | AST | SCS |
| LSTM [40] | 2017 | IJCAI | ✓ | ✓ | ✓ | AST | CCD |
| LSTM [6] | 2018 | ICPC | ✓ | ✓ | ✓ | AST | SCS |
| Seq2seq [17] | 2018 | IJCAJ | ✓ | × | ✓ | (API, comments) (API, code, comments) | SCS |
| LSTM [19] | 2018 | ASE | ✓ | ✓ | ✓ | AST, sourcecode | SCS |
| Bi-LSTM [43] | 2018 | ICLR | ✓ | ✓ | ✓ | AST, (token, path, token) | PF, SCS |
| HOPE [50] | 2018 | MSR | ✓ | ✓ | ✓ | identifier, AST, CFG, Bytecode | CCD |
| RNN [51] | 2018 | ICLR | ✓ | ✓ | ✓ | variable/statetrace | PR |
| Word2vec [53] | 2018 | ESEC | ✓ | ✓ | ✓ | abstractedsymbolictraces | ECM |
| GGNN [55] | 2018 | ICLR | ✓ | ✓ | ✓ | AST, PDG | PF |
| MLP [62] | 2018 | ASE | ✓ | × | ✓ | tokens | SCS |
| RNN [63] | 2018 | AAAI | ✓ | ✓ | ✓ | AST | SCS, SCC |
| GRU [22] | 2019 | ICSE | ✓ | ✓ | ✓ | text, ASTnodetokens | SCS |
| Bi-LSTM [46] | 2019 | ICSE | ✓ | ✓ | ✓ | AST, ST-trees | SCC, CCD |
| Bi-LSTM [64] | 2019 | POPL | ✓ | ✓ | ✓ | AST, (token, path, token) | PF |
| Bi-LSTM [65] | 2019 | ASE | ✓ | ✓ | ✓ | text | SCS |
| Bi-LSTM [23] | 2020 | ICSE | × | ✓ | ✓ | AST, codesequence | SCS |
| BERT [24] | 2020 | Access | ✓ | ✓ | ✓ | functionalkeywords | SCS |
| Transformer [25] | 2020 | arXiv | ✓ | × | ✓ | comments, code | SCS, CR |
| Transformer [26] | 2020 | ACL | × | ✓ | ✓ | AST | SCS |
| GRU [44] | 2020 | ESE | ✓ | ✓ | ✓ | tokens, AST | SCS |
| Regularizer [56] | 2020 | IST | ✓ | ✓ | ✓ | AST | SCG |
| GRU [66] | 2020 | JCRD | ✓ | ✓ | ✓ | (code, API, comments), (function, comments) | SCS |
| GRU [67] | 2020 | ACL | ✓ | ✓ | ✓ | text, ASTnodetokens | SCS |
| GNN [68] | 2021 | arXiv | ✓ | ✓ | ✓ | AST, context | SCS |
| Seq2Seq [69] | 2021 | ICPC | ✓ | × | ✓ | (seq, comment), (context, comment) | SCS |
| API2Com [70] | 2021 | ICPC | ✓ | ✓ | ✓ | AST, API, seq | SCS |
| Methods | Venue | Datesets | Opened-Source |
|---|---|---|---|
| AutoComment [41] | ASE | Java(SO) | * |
| TASSAL [61] | ICSE | Java(GH) | https://github.com/mast-group/tassal (accessed on 25 November 2019) |
| conv_attention [15] | ICML | Java(GH) | http://groups.inf.ed.ac.uk/cup/codeattention (accessed on 25 February 2020) |
| Allamanis et al. [55] | ICLR | C#(GH) | https://aka.ms/iclr18-prog-graphs-dataset (accessed on 2 March 2020) |
| Mcburney et al. [60] | TSE | Java(GH) | * |
| CODENN [59] | ACL | C#, SQL(SO) | https://stackoverflow.com/ (accessed on 2 March 2020) |
| DeepCom [6] | ICPC | Java(GH) | https://github.com/xing-hu/DeepCom (accessed on 3 March 2021) |
| TL-CodeSum [17] | IJCAJ | Java(GH) | https://github.com/xing-hu/TL-CodeSum (accessed on 3 March 2021) |
| Hybrid-DeepCom [44] | ESE | Java [6] | https://github.com/xing-hu/DeepCom (accessed on 5 March 2021) |
| BVAE [62] | ASE | C#, SQL [59] | https://stackoverflow.com/ (accessed on 28 November 2019) |
| HybridDRL [19] | ASE | Python [94] | https://github.com/wanyao1992/code_summarization_public (accessed on 7 February 2021) |
| CodeRNN [63] | AAAI | Java(GH) | https://adapt.seiee.sjtu.edu.cn/CodeComment/ (accessed on 29 November 2020) |
| Attn+PG+RL [65] | ASE | Java(GH) | https://tinyurl.com/y3yk6oey (accessed on 28 November 2019) |
| Code2vec [64] | POPL | Java(GH) | https://github.com/tech-srl/code2vec (accessed on 15 December 2019) |
| Code2seq [43] | ICLR | Java(GH),C# [59] | https://github.com/tech-srl/code2seq (accessed on 15 December 2019) |
| Ast-attendgru [22] | ICSE | Java [95] | http://www.ics.uci.edu/-lopes/datasets/ (accessed on 18 December 2020) |
| LeClair et al. [67] | ACL | Java [96] | http://leclair.tech/data/funcom/ (accessed on 15 February 2020) |
| ASTNN [46] | ICSE | C(OJ), Java [93] | https://github.com/zhangj1994/astnn (accessed on 15 January 2021) |
| Rencos [23] | ICSE | Java [17], Python [94] | https://github.com/xing-hu/TL-CodeSum (accessed on 23 February 2021) |
| CodeBERT [25] | arXiv | Go, Java, JS, PHP, Python, Ruby | https://github.com/microsoft/CodeBERT (accessed on 23 February 2021) |
| TBCNN [34] | AAAI | C(OJ) | http://programming.grids.cn (accessed on 28 February 2021) |
| CDLH [40] | IJCAI | Java [93], C(OJ) | http://programming.grids.cn (accessed on 5 May 2021) |
| DL-based [50] | MSR | Java(GH) | https://archive.apache.org/dist/commons (accessed on 23 May 2021) |
| Code-GRU [56] | IST | Java(GH) | https://github.com/yaxirhuxxain/Source-Code-Suggestion (accessed on 23 May 2021) |
| CodeAttention [21] | FCS | Java(GH) | https://github.com/wenhaozheng-nju/CodeAttention (accessed on 25 May 2021) |
| Tansformer-based [26] | ACL | Java [17], Python [94] | https://github.com/wasiahmad/NeuralCodeSum (accessed on 23 February 2021) |
| Fret [24] | Access | Java(GH), Python [94] | https://github.com/xing-hu/EMSE-DeepCom (accessed on 23 March 2020) |
| fc-pc [68] | ICPC | Java(GH), Python | https://github.com/aakashba/projcon (accessed on 5 November 2021) |
| KBCoS [66] | JCRD | Java [6], Python [94] | https://github.com/xing-hu/TL-CodeSum (accessed on 26 February 2021) https://github.com/EdinburghNLP/code-docstring-corpus (accessed on 26 February 2021) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Wang, J.; Zhou, Q.; Xu, T.; Tang, K.; Gui, H.; Liu, F. A Survey of Automatic Source Code Summarization. Symmetry 2022, 14, 471. https://doi.org/10.3390/sym14030471
Zhang C, Wang J, Zhou Q, Xu T, Tang K, Gui H, Liu F. A Survey of Automatic Source Code Summarization. Symmetry. 2022; 14(3):471. https://doi.org/10.3390/sym14030471
Chicago/Turabian StyleZhang, Chunyan, Junchao Wang, Qinglei Zhou, Ting Xu, Ke Tang, Hairen Gui, and Fudong Liu. 2022. "A Survey of Automatic Source Code Summarization" Symmetry 14, no. 3: 471. https://doi.org/10.3390/sym14030471
APA StyleZhang, C., Wang, J., Zhou, Q., Xu, T., Tang, K., Gui, H., & Liu, F. (2022). A Survey of Automatic Source Code Summarization. Symmetry, 14(3), 471. https://doi.org/10.3390/sym14030471