
An Active Set Limited Memory BFGS Algorithm for Machine Learning

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- How can we guarantee the positive definiteness of iterative matrix without line search?
- How can we guarantee the convergence of the proposed L-BFGS method?
2. Premise Setting and Algorithm
2.1. LMLBFGS Algorithm
| Algorithm 1: Modified stochastic LBFGS algorithm (LMLBFGS). |
| Input: Given , batch size , , the memory size r, a positive definite matrix , and a positive constant 1: for do 2: Compute by (7) and Hessian matrix by Algorithm 2; 3: Compute the iteration point . 4: end for |
2.2. Extension of Our LMLBFGS Algorithm with Variance Reduction
| Algorithm 2: Hessian matrix updating. |
| Input: correction pairs , memory parameter r, and Output: new 1: 2: for do 3: 4: if 5: 6: end if 7: end for 8: return |
| Algorithm 3: Modified stochastic LBFGS algorithm with variance reduction (LMLBFGS-VR). |
| Input: Given , , batch size , , the memory size r and a constant Output: Iterationxis chosen randomly from a uniform 1: for do 2: 3: compute 4: for do 5: Samlple a minibatch with 6: Calculate where ; 7: Compute ; 8: end for 9: Generate the updated Hessian matrix by Algorithm 2; 10: 11: end for |
3. Global Convergence Analysis
3.1. Basic Assumptions
3.2. Key Propositions, Lemmas, and Theorem
- (1)
- ,
- (2)
- and, for all k,
3.3. Global Convergence Theorem
- (i)
- .
- (ii)
- for , and
4. The Complexity of the Proposed Algorithm
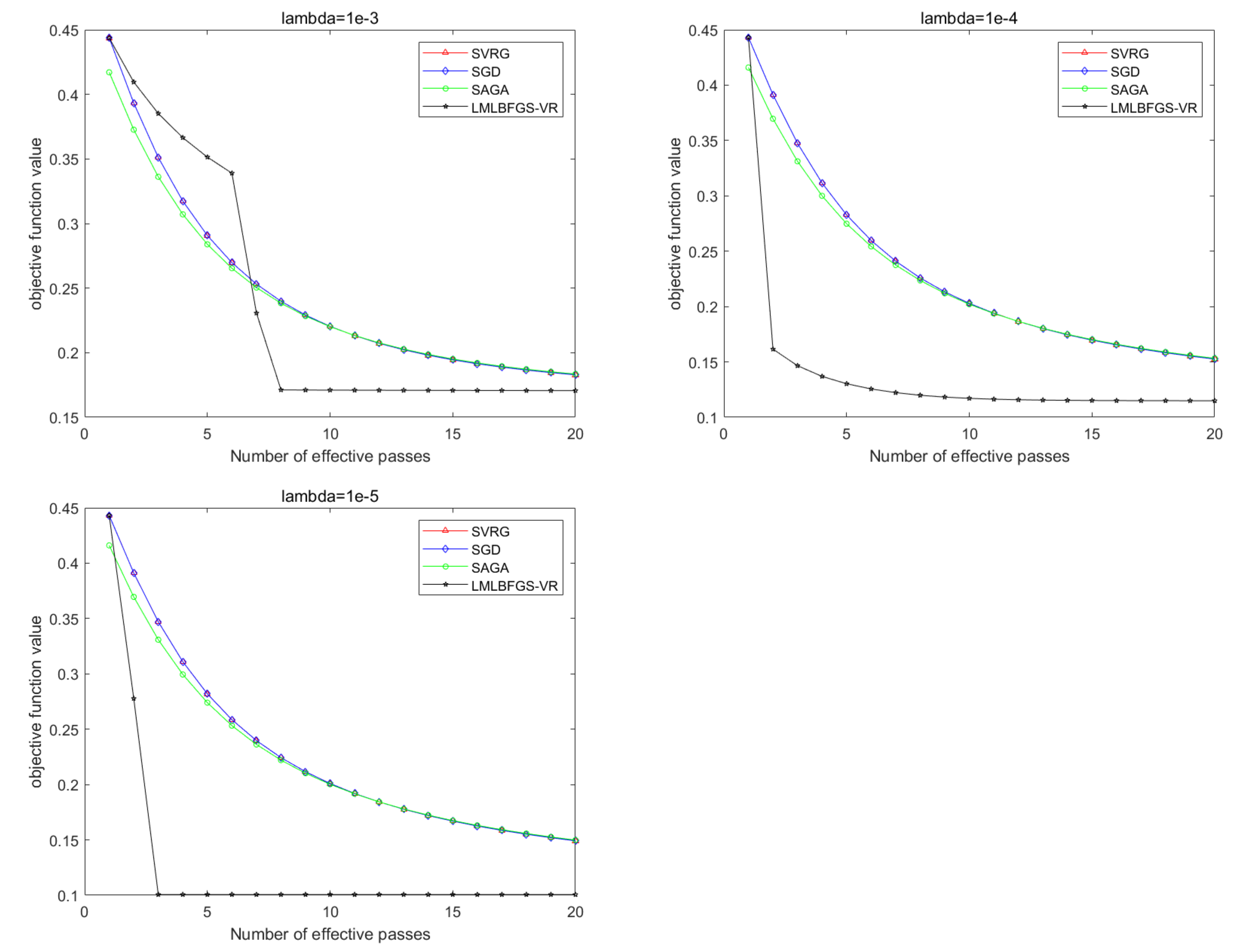
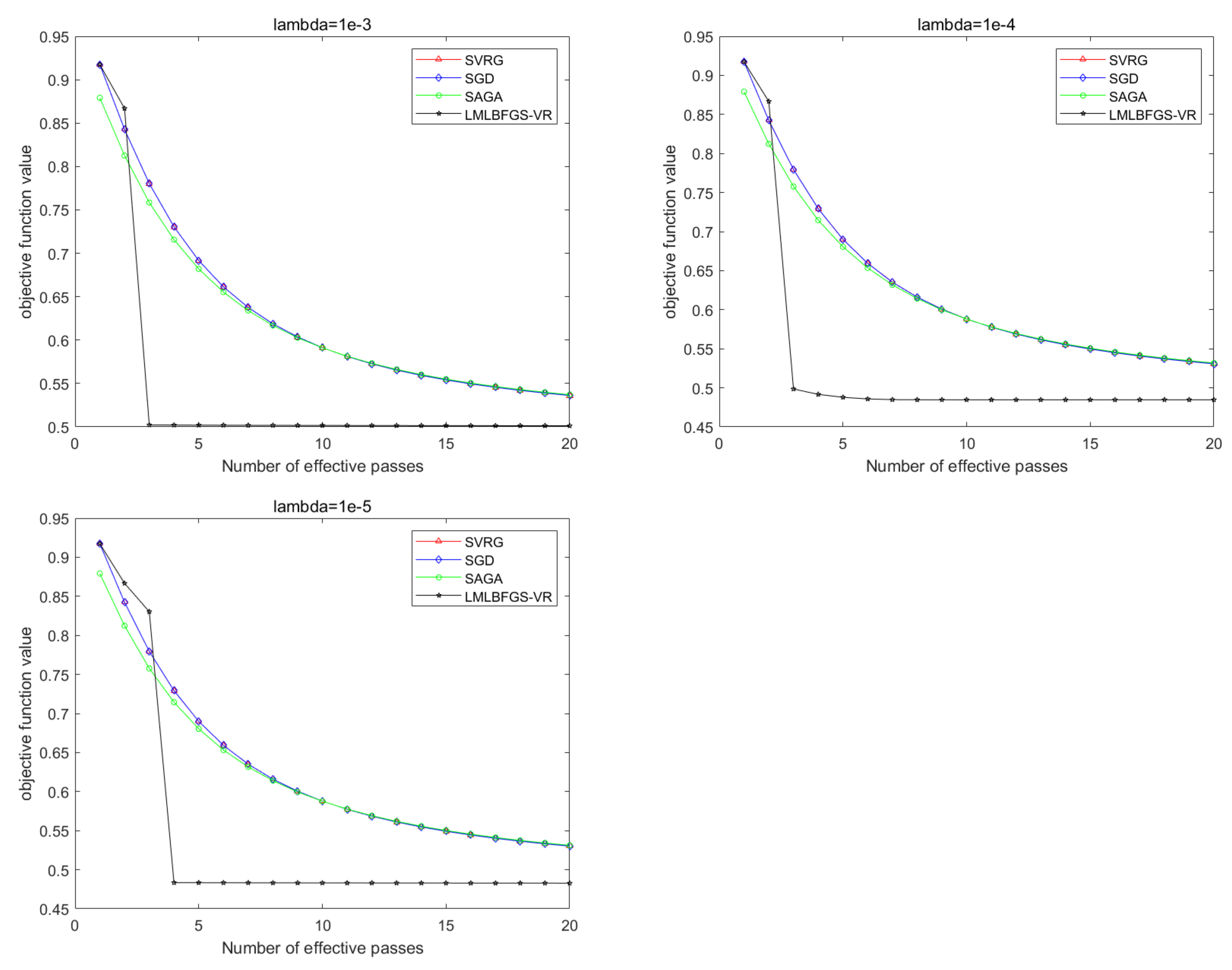
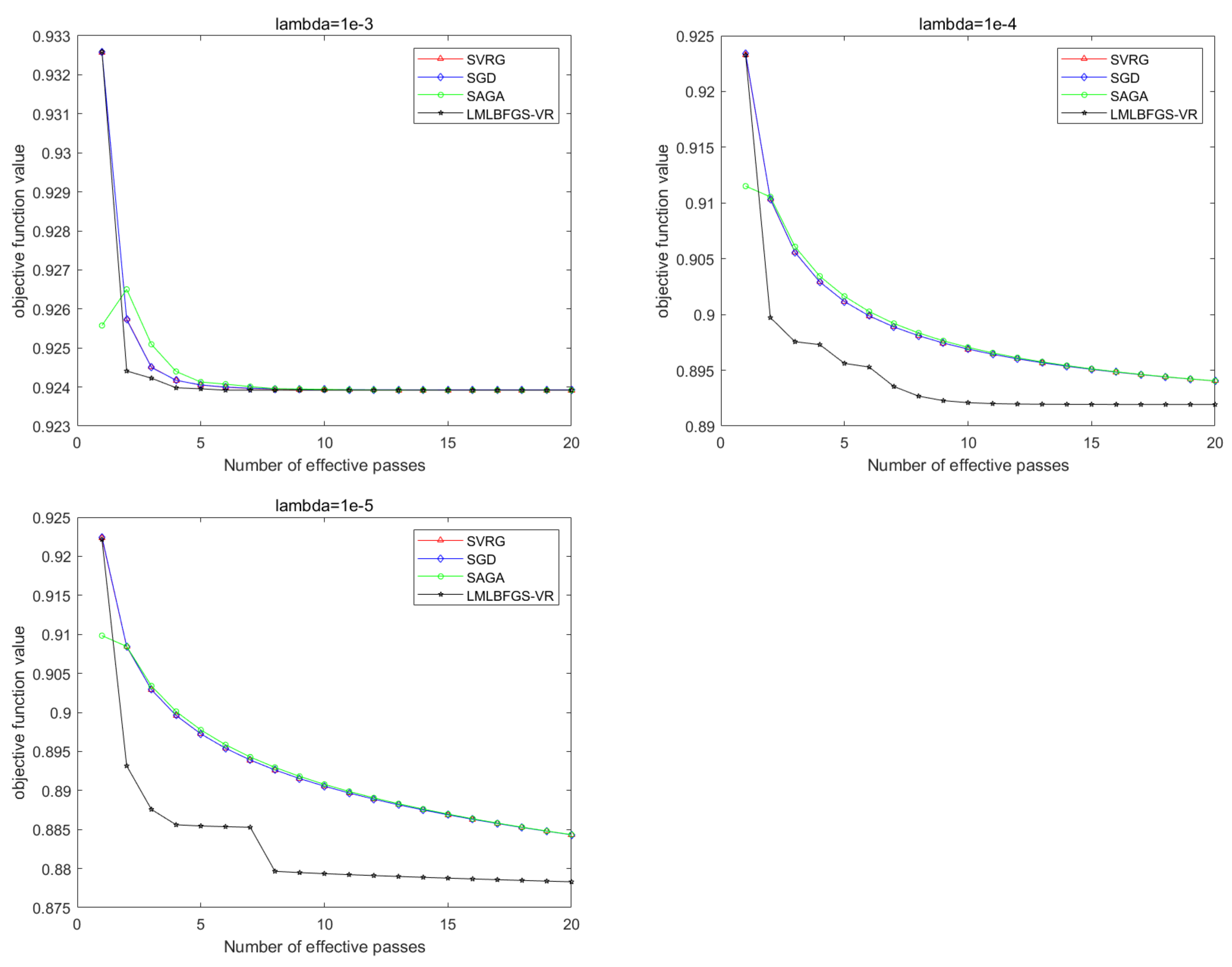
5. Numerical Results
5.1. Experiments with Synthetic Datasets
5.2. Numerical Results for Problem 1
5.3. Numerical Results for Problem 2
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Robbins, H.; Monro, S. A stochastic approximation method. Ann. Math. Stat. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- Chung, K.L. On a stochastic approximation method. Ann. Math. Stat. 1954, 25, 463–483. [Google Scholar] [CrossRef]
- Polyak, B.T.; Juditsky, A.B. Acceleration of stochastic approximation by averaging. SIAM J. Control Optim. 1992, 30, 838–855. [Google Scholar] [CrossRef]
- Ruszczyǹski, A.; Syski, W. A method of aggregate stochastic subgradients with online stepsize rules for convex stochastic programming problems. In Stochastic Programming 84 Part II; Springer: Berlin/Heidelberg, Germany, 1986; pp. 113–131. [Google Scholar]
- Wright, S.; Nocedal, J. Numerical Optimization; Springer: Berlin/Heidelberg, Germany, 1999; Volume 35, p. 7. [Google Scholar]
- Bordes, A.; Bottou, L. SGD-QN: Careful quasi-Newton stochastic gradient descent. J. Mach. Learn. Res. 2009, 10, 1737–1754. [Google Scholar]
- Byrd, R.H.; Hansen, S.L.; Nocedal, J.; Singer, Y. A stochastic quasi-Newton method for large-scale optimization. SIAM J. Optim. 2016, 26, 1008–1031. [Google Scholar] [CrossRef]
- Gower, R.; Goldfarb, D.; Richtárik, P. Stochastic block BFGS: Squeezing more curvature out of data. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; Volume 48, pp. 1869–1878. [Google Scholar]
- Covei, D.P.; Pirvu, T.A. A stochastic control problem with regime switching. Carpathian J. Math. 2021, 37, 427–440. [Google Scholar] [CrossRef]
- Wei, Z.; Li, G.; Qi, L. New quasi-Newton methods for unconstrained optimization problems. Appl. Math. Comput. 2006, 175, 1156–1188. [Google Scholar] [CrossRef]
- Durrett, R. Probability: Theory and Examples; Cambridge University Press: Cambridge, UK, 2019. [Google Scholar]
- Deng, N.Y.; Li, Z.F. Ome global convergence properties of a conic-variable metric algorithm for minimization with inexact line searches. Numer. Algebra Control Optim. 1995, 5, 105–122. [Google Scholar]
- Allen-Zhu, Z.; Hazan, E. Variance reduction for faster non-convex optimization. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; Volume 48, pp. 699–707. [Google Scholar]
- Shalev-Shwartz, S.; Shamir, O.; Sridharan, K. Learning kernel-based halfspaces with the 0–1 loss. SIAM J. Comput. 2011, 40, 1623–1646. [Google Scholar] [CrossRef] [Green Version]
- Ghadimi, S.; Lan, G. Stochastic first-and zeroth-order methods for nonconvex stochastic programming. SIAM J. Optim. 2013, 23, 2341–2368. [Google Scholar] [CrossRef] [Green Version]
- Mason, L.; Baxter, J.; Bartlett, P.; Frean, M. Boosting algorithms as gradient descent in function space. Proc. Adv. Neural Inf. Process. Syst. 1999, 12, 512–518. [Google Scholar]
- Johnson, R.; Zhang, T. Accelerating stochastic gradient descent using predictive variance reduction. Adv. Neural Inf. Process. Syst. 2013, 26, 315–323. [Google Scholar]
- Defazio, A.; Bach, F.; Lacoste-Julien, S. SAGA: A fast incremental gradient method with support for non-strongly convex composite objectives. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 1646–1654. [Google Scholar]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, H.; Li, Y.; Zhang, M. An Active Set Limited Memory BFGS Algorithm for Machine Learning. Symmetry 2022, 14, 378. https://doi.org/10.3390/sym14020378
Liu H, Li Y, Zhang M. An Active Set Limited Memory BFGS Algorithm for Machine Learning. Symmetry. 2022; 14(2):378. https://doi.org/10.3390/sym14020378
Chicago/Turabian StyleLiu, Hanger, Yan Li, and Maojun Zhang. 2022. "An Active Set Limited Memory BFGS Algorithm for Machine Learning" Symmetry 14, no. 2: 378. https://doi.org/10.3390/sym14020378
APA StyleLiu, H., Li, Y., & Zhang, M. (2022). An Active Set Limited Memory BFGS Algorithm for Machine Learning. Symmetry, 14(2), 378. https://doi.org/10.3390/sym14020378