
Information Hiding Based on Two-Level Mechanism and Look-Up Table Approach





Abstract
:1. Introduction
- A more secure encryption model based on Logistic mapping is devised;
- The hash code based on the two-level image mechanism is more diverse and reduces the unconcealable rate of the secret message;
- A new combination of reversible information hiding and coverless information hiding is designed, which greatly improves capacity and the image quality;
- The proposed method solves the additional storage of location table without sacrificing hiding capacity and no large image database is required;
- Compared with other similar algorithms, our method has more security and better image quality and higher storage capacity.
2. Related Works
2.1. Logistic Mapping
2.2. Previous Method
3. Proposed Method
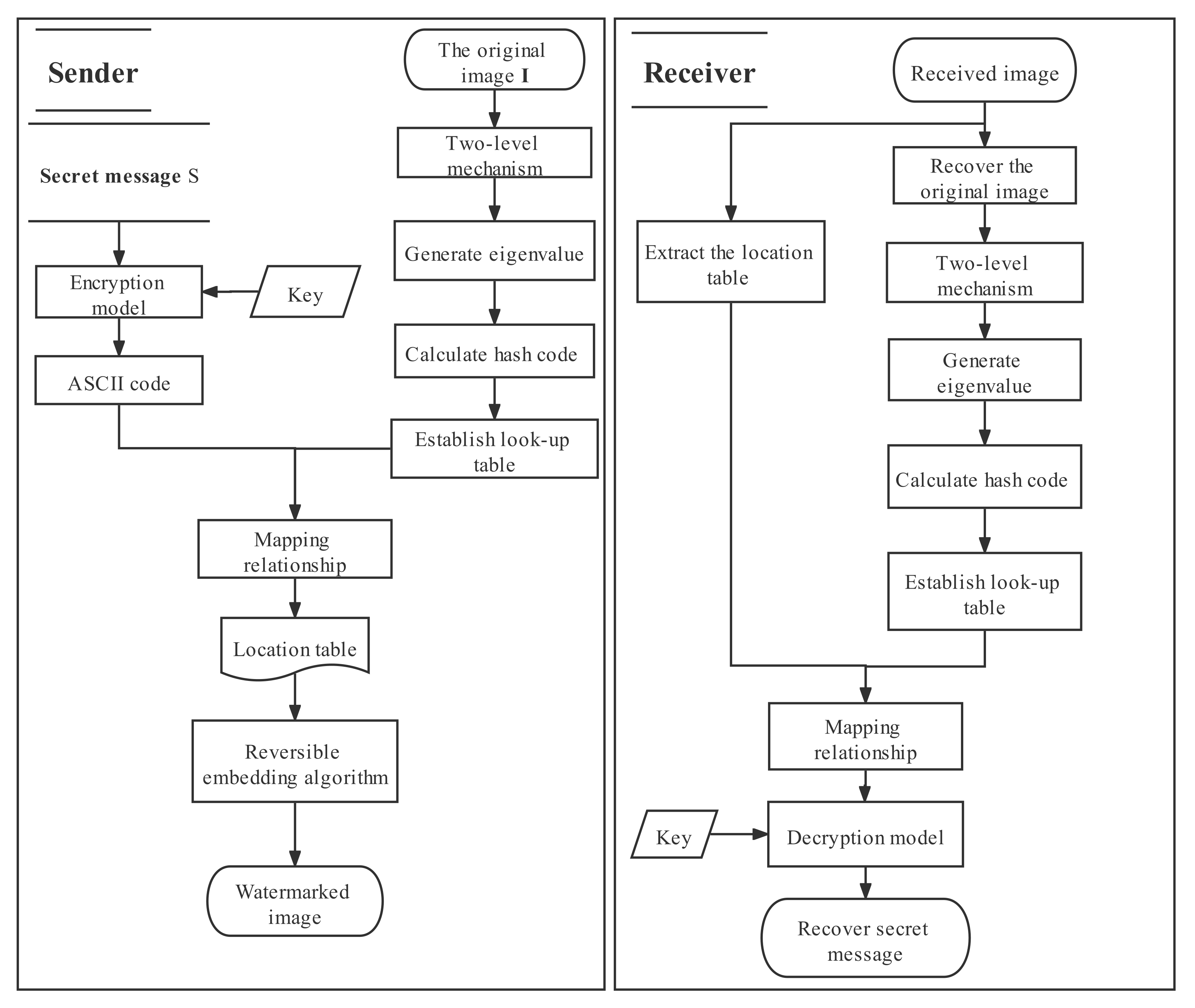
3.1. Encrypt the Secret Message
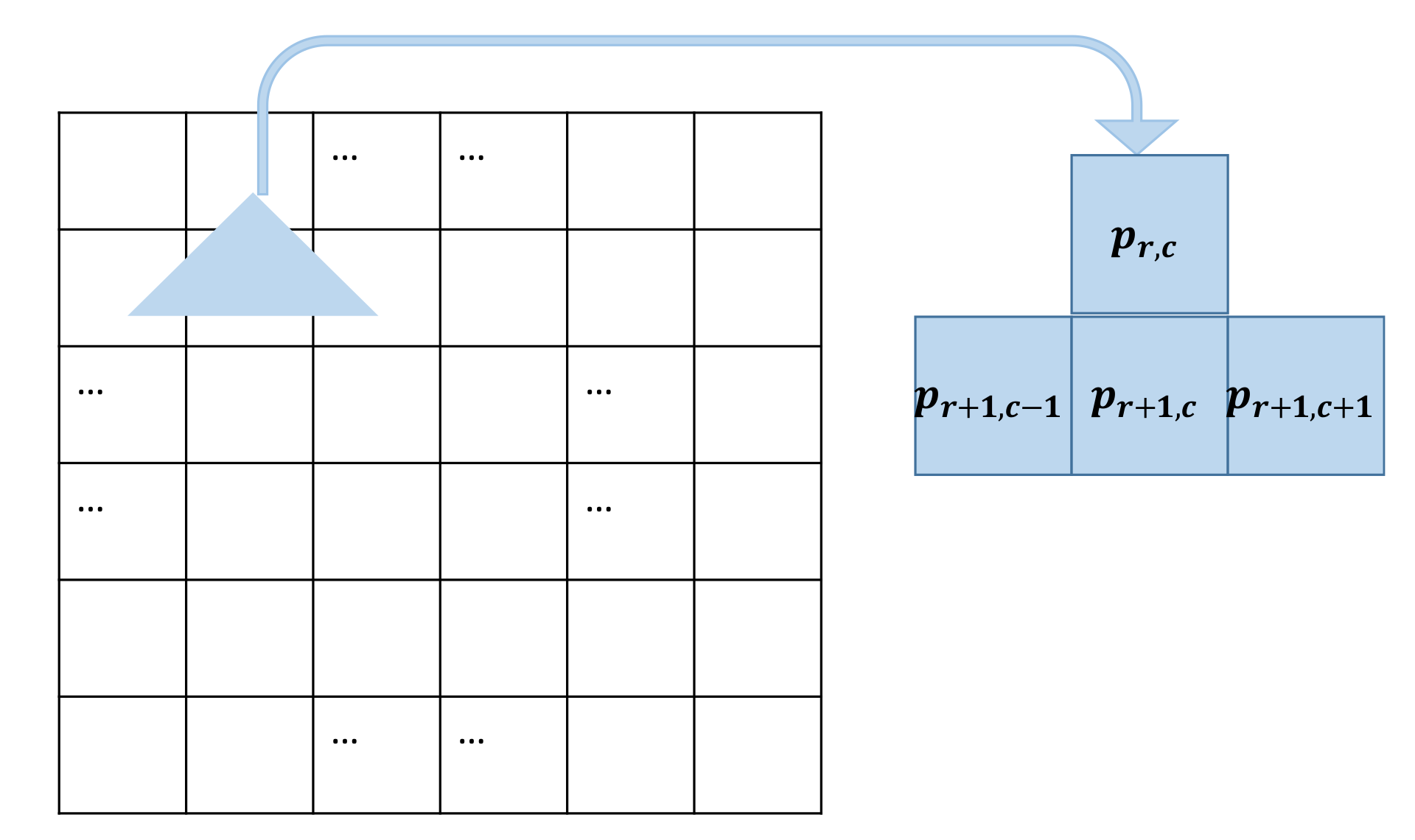
3.2. Hiding the Secret Message
| Algorithm 1 Pseudo-code of the hiding model. |
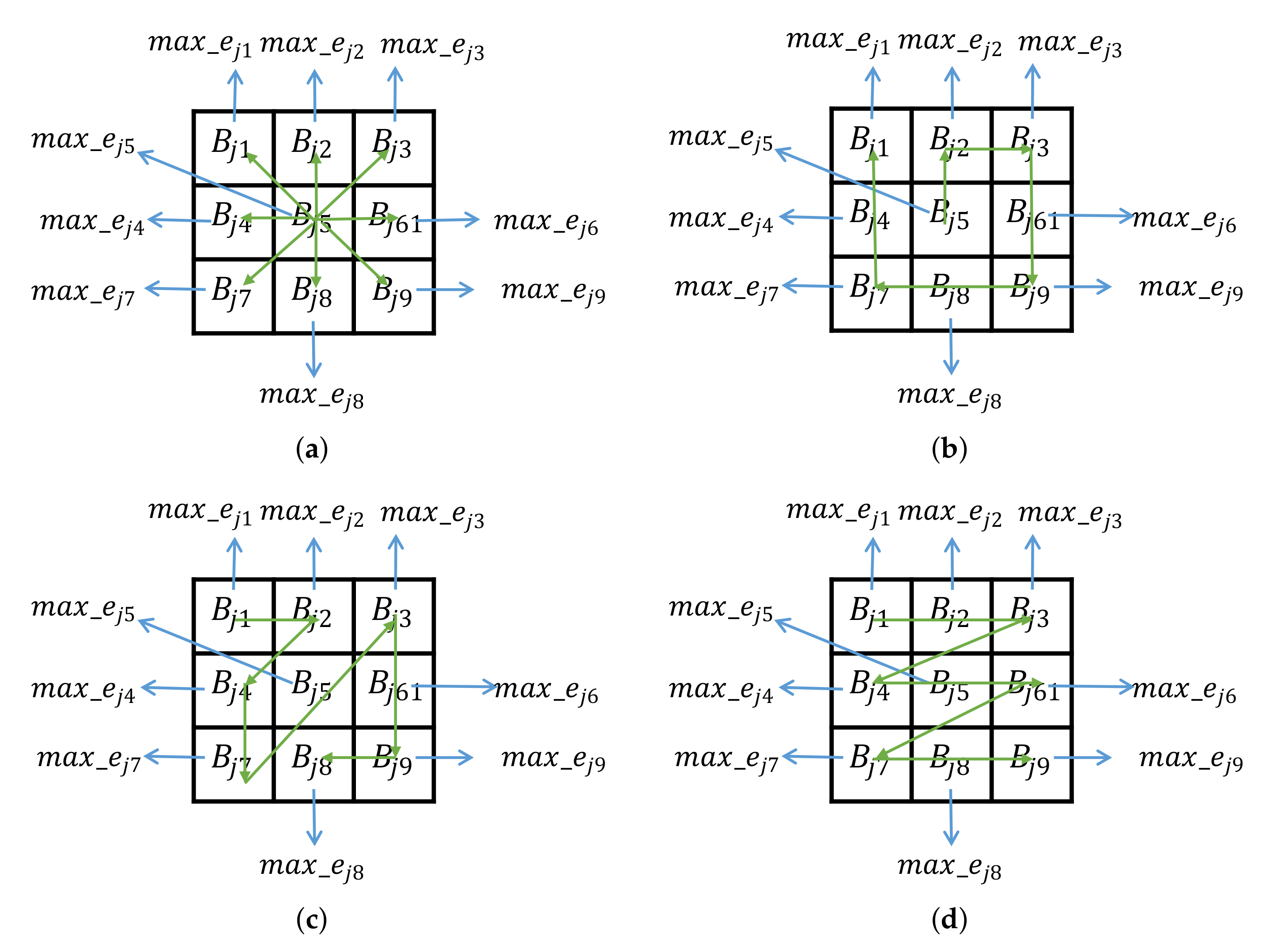
Require: Original image , secret message S, the initial key , parameter , w, c, b, Ensure: Watermarked image Step 1. Generate one-dimensional sequence Y that the length is as same as the secret message using Equations (5) and (6) with the initial key . Step 2. Encrypt the secret message S by exclusive-or operation with Y and obtain the encrypted sequence . Step 3. Divide host image into two sub-images and based on the two-level mechanism by Equations (8)–(10). Step 4. Split two sub-images into image block with fixed-size b. Step 5. Further split into nine sub-blocks with the small size where l denotes the l-th sub-block in the image block . Step 6. Calculate the eigenvalue of all sub-blocks and find the largest value by Equation (2). Step 7. Acquire the hash code by arranging the eigenvalues of the sub-blocks in every image block where uses three arrangements of seven arrangements randomly. Step 8. Generate the ASCII code with every 8-bit hash code and an ASCII code corresponding to a block. Step 9. Establish look-up table including ASCII codes and their location. Step 10. Convert the encrypted message to ASCII code . Step 11. Match with the equal image block and record the location of the corresponding image block in order in the position table. Step 12. Embed the location table and additional information into the original image using above PEE. The additional information includes the encryption key, parameter w, c, b, , the arrangements selected, and the size of the secret message. |
3.3. Extract the Secret Message and Recover the Original Image
| Algorithm 2 Pseudo-code of the extraction and recover model. |
Require: Watermarked image Ensure: Recovered host image and the secret message Step 1. Extract the location table, additional information, and recover the original image . Step 2. Divide the recovered image using the same method. Step 3. Calculate the corresponding eigenvalue and hash code. Step 4. Convert the hash codes to ASCII code. Step 5. Establish the look-up table. Step 6. Acquire the encrypted secret sequence from the look-up table and the location table by the mapping relation. Step 7. Generate one-dimensional sequence that the length is as same as the secret message using Equations (5) and (6) with the initial key . Step 8. Decrypt the secret message by executing exclusive or operation between and the encrypted sequence. |
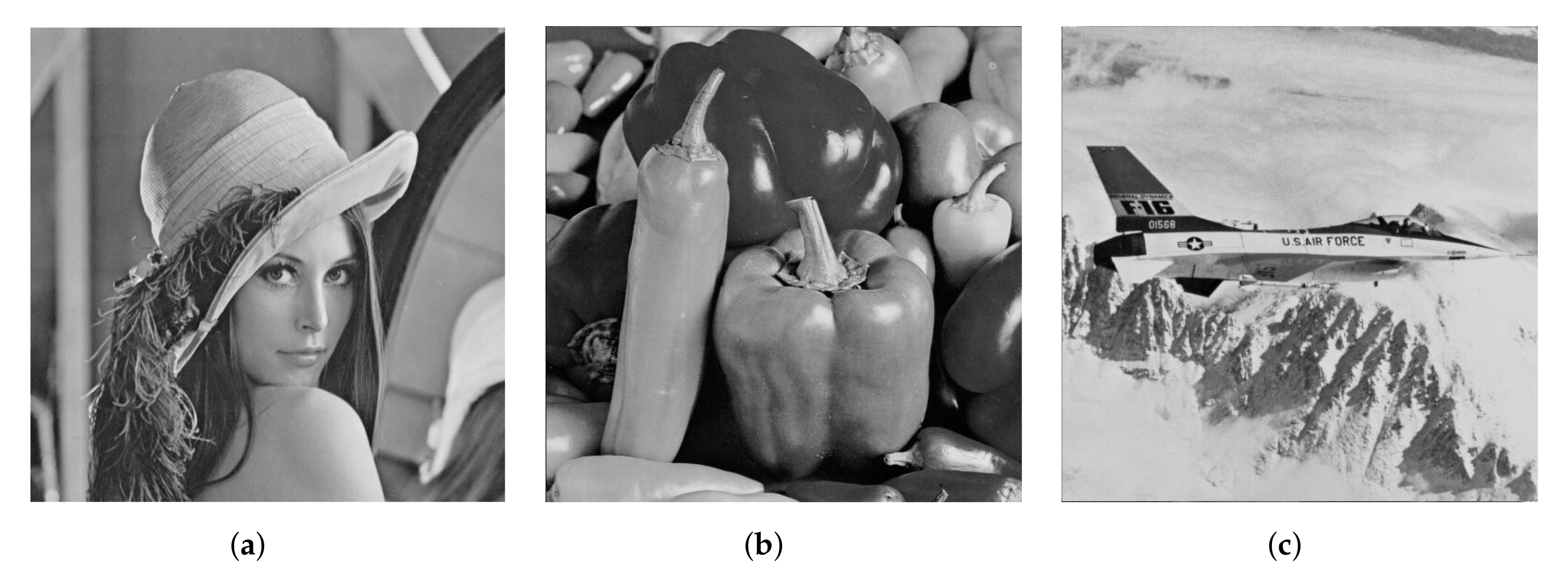
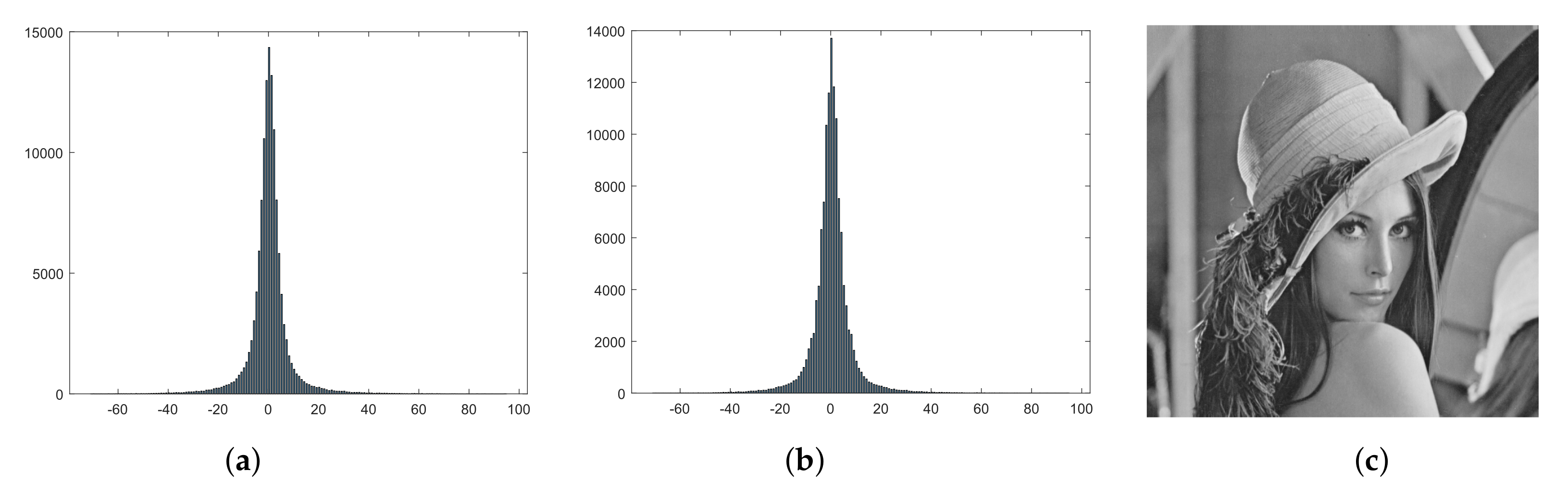
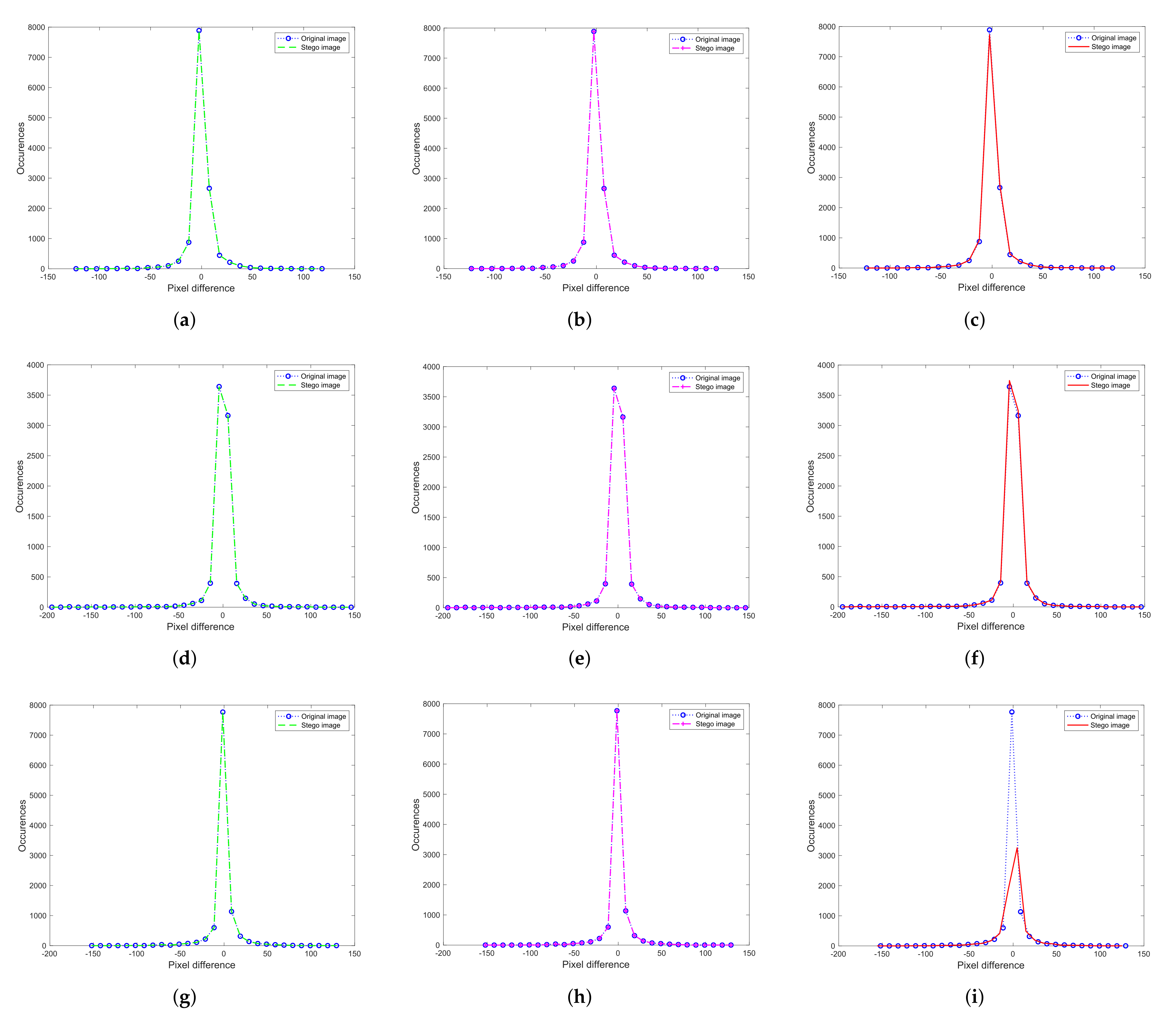
4. Experiment and Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| Original image | |
| Watermarked image | |
| Secret message | |
| Initial key on the encryption algorithm | |
| Y | One-dimensional sequence used for encryption |
| n-th value in Y | |
| System control parameter | |
| The k-th eigenvalue in the l-th sub-block | |
| The largest value in all eigenvalues of the l-th sub-block | |
| The l-th sub-block of j-th block | |
| Hash code | |
| The length of secret message | |
| p | The pixel value in the image |
| The high-level plane | |
| The low-level plane | |
| w | The number of bits divided in the plane |
| The predicted pixel value | |
| The pixel value of the original image at row r and column i | |
| The error value between the pixel value and the predicted value | |
| T | Threshold |
| The modified error value | |
| The modified pixel value | |
| One bit in secret message S | |
| The average of the information | |
| Correlation coefficient between p and | |
| The pixel value in the original image | |
| The pixel value in the stego image | |
| The total rows of image | |
| the total columns of image | |
| PSO | Particle Swarm Optimization |
| IWT | Integer Wavelet Transformation |
| PEE | Prediction Error Expansion |
| PDH | Pixel Difference Histogram |
References
- Pfleeger, C.P. The fundamentals of information security. IEEE Softw. 1997, 14, 15–16. [Google Scholar] [CrossRef]
- Shelupanov, A.; Evsyutin, O.; Konev, A.; Kostyuchenko, E.; Kruchinin, D.; Nikiforov, D. Information Security Methods—Modern Research Directions. Symmetry 2019, 11, 150. [Google Scholar] [CrossRef] [Green Version]
- Mei, X.S.; Chen, H.T.; Fan, H.Y.; Lu, Z.M.; Yeh, J.h. A Robust Digital Image Watermarking Scheme for Content Protection. J. Netw. Intell. 2020, 5, 54–61. [Google Scholar]
- Zhang, Z.; Chen, S.; Sun, X.; Liang, Y. Trajectory privacy protection based on spatial-time constraints in mobile social networks. J. Netw. Intell. 2021, 6, 485–499. [Google Scholar]
- Sahu, A.K.; Swain, G. A novel n-rightmost bit replacement image steganography technique. 3D Res. 2019, 10, 2. [Google Scholar] [CrossRef]
- Muhuri, P.K.; Ashraf, Z.; Goel, S. A novel image steganographic method based on integer wavelet transformation and particle swarm optimization. Appl. Soft Comput. 2020, 92, 106257. [Google Scholar] [CrossRef]
- Song, P.C.; Chu, S.C.; Pan, J.S.; Yang, H. Simplified Phasmatodea population evolution algorithm for optimization. Complex Intell. Syst. 2021, 1–19. [Google Scholar] [CrossRef]
- Pan, J.S.; Song, P.C.; Pan, C.A.; Abraham, A. The Phasmatodea Population Evolution Algorithm and Its Application in 5G Heterogeneous Network Downlink Power Allocation Problem. J. Internet Technol. 2021, 22, 1199–1213. [Google Scholar]
- Pan, J.S.; Sun, X.X.; Chu, S.C.; Abraham, A.; Yan, B. Digital watermarking with improved SMS applied for QR code. Eng. Appl. Artif. Intell. 2021, 97, 104049. [Google Scholar] [CrossRef]
- Ni, Z.; Shi, Y.Q.; Ansari, N.; Su, W. Reversible data hiding. IEEE Trans. Circuits Syst. Video Technol. 2006, 16, 354–362. [Google Scholar]
- Luo, H.; Chu, S.C.; Lu, Z.M. Self embedding watermarking using halftoning technique. Circuits Syst. Signal Process. 2008, 27, 155–170. [Google Scholar] [CrossRef]
- Shi, Y.Q.; Li, X.; Zhang, X.; Wu, H.T.; Ma, B. Reversible data hiding: Advances in the past two decades. IEEE Access 2016, 4, 3210–3237. [Google Scholar] [CrossRef]
- Nguyen, T.D.; Le, H.D. A reversible data hiding scheme based on (5, 3) Hamming code using extra information on overlapped pixel blocks of grayscale images. Multimed. Tools Appl. 2021, 80, 13099–13120. [Google Scholar] [CrossRef]
- Linb, C.Y.Y.C.H.; Hua, W.C. Reversible data hiding for high-quality images based on integer wavelet transform. J. Inf. Hiding Multimed. Signal Process. 2012, 3, 142–150. [Google Scholar]
- Honsinger, C.W.; Jones, P.W.; Rabbani, M.; Stoffel, J.C. Lossless Recovery of an Original Image Containing Embedded Data. U.S. Patent 6,278,791, 21 August 2001. [Google Scholar]
- Hu, Y.; Lee, H.K.; Li, J. DE-based reversible data hiding with improved overflow location map. IEEE Trans. Circuits Syst. Video Technol. 2008, 19, 250–260. [Google Scholar]
- Faragallah, O.S.; Elaskily, M.A.; Alenezi, A.F.; El-sayed, H.S.; Kelash, H.M. Quadruple histogram shifting-based reversible information hiding approach for digital images. Multimed. Tools Appl. 2021, 80, 26297–26317. [Google Scholar] [CrossRef]
- Weng, S.; Zhao, Y.; Pan, J.S.; Ni, R. A novel reversible watermarking based on an integer transform. In Proceedings of the 2007 IEEE International Conference on Image Processing, San Antonio, TX, USA, 16 September–19 October 2007; Volume 3, pp. III-241–III-244. [Google Scholar]
- Tian, J. Reversible data embedding using a difference expansion. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 890–896. [Google Scholar] [CrossRef] [Green Version]
- Alattar, A.M. Reversible watermark using the difference expansion of a generalized integer transform. IEEE Trans. Image Process. 2004, 13, 1147–1156. [Google Scholar] [CrossRef] [PubMed]
- Thodi, D.M.; Rodriguez, J.J. Prediction-error based reversible watermarking. In Proceedings of the 2004 International Conference on Image Processing, ICIP’04, Singapore, 24–27 October 2004; Volume 3, pp. 1549–1552. [Google Scholar]
- Tseng, H.W.; Hsieh, C.P. Prediction-based reversible data hiding. Inf. Sci. 2009, 179, 2460–2469. [Google Scholar] [CrossRef]
- Weng, S.; Chu, S.C.; Cai, N.; Zhan, R. Invariability of Mean Value Based Reversible Watermarking. J. Inf. Hiding Multim. Signal Process. 2013, 4, 90–98. [Google Scholar]
- Weng, S.; Zhao, Y.; Ni, R.; Pan, J.S. Lossless data hiding based on prediction-error adjustment. Sci. China Ser. F Inf. Sci. 2009, 52, 269–275. [Google Scholar] [CrossRef]
- Yu, Y.; Lei, M.; Liu, X.; Qu, Z.; Wang, C. Novel zero-watermarking scheme based on DWT-DCT. China Commun. 2016, 13, 122–126. [Google Scholar] [CrossRef]
- Weng, S.; Chen, Y.; Hong, W.; Pan, J.S.; Chang, C.C.; Liu, Y. An improved integer transform combining with an irregular block partition. Symmetry 2019, 11, 49. [Google Scholar] [CrossRef] [Green Version]
- Yan, Y.S.; Cai, H.L.; Yan, B. Data Hiding in Symmetric Circular String Art. Symmetry 2020, 12, 1227. [Google Scholar] [CrossRef]
- Pan, J.S.; Luo, H.; Lu, Z.M. Look-up table based reversible data hiding for error diffused halftone images. Informatica 2007, 18, 615–628. [Google Scholar] [CrossRef]
- Zhou, Z.; Su, Y.; Zhang, Y.; Xia, Z.; Du, S.; Gupta, B.B.; Qi, L. Coverless Information Hiding Based on Probability Graph Learning for Secure Communication in IoT Environment. IEEE Internet Things J. 2021. [Google Scholar] [CrossRef]
- Zhou, Z.; Cao, Y.; Wang, M.; Fan, E.; Wu, Q.J. Faster-RCNN Based Robust Coverless Information Hiding System in Cloud Environment. IEEE Access 2019, 7, 179891. [Google Scholar] [CrossRef]
- Zou, L.; Sun, J.; Gao, M.; Wan, W.; Gupta, B.B. A novel coverless information hiding method based on the average pixel value of the sub-images. Multimed. Tools Appl. 2019, 78, 7965–7980. [Google Scholar] [CrossRef]
- Cao, Y.; Zhou, Z.; Sun, X.; Gao, C. Coverless information hiding based on the molecular structure images of material. Comput. Mater. Contin. 2018, 54, 197–207. [Google Scholar]
- Wang, Y.; Wu, B. An intelligent search method of mapping relation for coverless information hiding. J. Cyber Secur. 2020, 5, 48–61. [Google Scholar]
- Abdulsattar, F.S. Towards a high capacity coverless information hiding approach. Multimed. Tools Appl. 2021, 80, 18821–18837. [Google Scholar] [CrossRef]
- Weng, S.; Pan, J.s.; Li, L. Reversible data hiding based on an adaptive pixel-embedding strategy and two-layer embedding. Inf. Sci. 2016, 369, 144–159. [Google Scholar] [CrossRef]
- Wu, T.Y.; Chen, C.M.; Wang, K.H.; Pan, J.S.; Zheng, W.; Chu, S.C.; Roddick, J.F. Security Analysis of Rhee et al.’s Public Encryption with Keyword Search Schemes: A Review. J. Netw. Intell. 2018, 3, 16–25. [Google Scholar]
- Andrecut, M. Logistic map as a random number generator. Int. J. Mod. Phys. B 1998, 12, 921–930. [Google Scholar] [CrossRef]
- Pareek, N.K.; Patidar, V.; Sud, K.K. Image encryption using chaotic logistic map. Image Vis. Comput. 2006, 24, 926–934. [Google Scholar] [CrossRef]
- Li, C.; Xie, T.; Liu, Q.; Cheng, G. Cryptanalyzing image encryption using chaotic logistic map. Nonlinear Dyn. 2014, 78, 1545–1551. [Google Scholar]
- Elshoush, H.T.; Ali, I.A.; Mahmoud, M.M.; Altigani, A. A novel approach to information hiding technique using ASCII mapping based image steganography. J. Inf. Hiding Multimed. Signal Process. 2021, 12, 65–82. [Google Scholar]
- Zhou, Z.; Wu, Q.J.; Yang, C.N.; Sun, X.; Pan, Z. Coverless image steganography using histograms of oriented gradients-based hashing algorithm. J. Internet Technol. 2017, 18, 1177–1184. [Google Scholar]
- Zhang, X.; Peng, F.; Long, M. Robust coverless image steganography based on DCT and LDA topic classification. IEEE Trans. Multimed. 2018, 20, 3223–3238. [Google Scholar] [CrossRef]
- Sahu, A.K.; Swain, G. Reversible image steganography using dual-layer LSB matching. Sens. Imaging 2020, 21, 1–21. [Google Scholar] [CrossRef]
- Pradhan, A.; Sahu, A.K.; Swain, G.; Sekhar, K.R. Performance evaluation parameters of image steganography techniques. In Proceedings of the 2016 International Conference on Research Advances in Integrated Navigation Systems (RAINS), Bangalore, India, 6–7 May 2016; pp. 1–8. [Google Scholar]
- Swain, G. Very high capacity image steganography technique using quotient value differencing and LSB substitution. Arab. J. Sci. Eng. 2019, 44, 2995–3004. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index∖Image | Original Image | Encrypted Image | ||
|---|---|---|---|---|
| Logistic Mapping [38] | Sin-Logistic Mapping | Our Model | ||
| Entropy | 7.2081 | 7.9945 | 7.9623 | 7.9954 |
| Horizontal | 0.9687 | −0.0868 | 0.0620 | 0.0352 |
| Vertical | 0.9372 | −0.0934 | −0.1215 | −0.0391 |
| Diagonal | 0.9057 | 0.0722 | 0.0514 | 0.0188 |
| Hash Codes | [34] | Two-Level Mechanism | ||||
|---|---|---|---|---|---|---|
| Lena | Pepper | Plane | Lena | Pepper | Plane | |
| Arr.1 | 148 | 139 | 158 | 186 | 161 | 198 |
| Arr.2 | 179 | 180 | 214 | 186 | 182 | 207 |
| Arr.3 | 155 | 163 | 169 | 170 | 161 | 186 |
| Arr.4 | 208 | 188 | 158 | 251 | 166 | 248 |
| Arr.5 | 192 | 191 | 201 | 217 | 210 | 227 |
| Arr.6 | 171 | 160 | 195 | 170 | 166 | 191 |
| Arr.7 | 143 | 123 | 170 | 183 | 176 | 210 |
| Hiding Capability | [34] | Our Method | ||
|---|---|---|---|---|
| Hash Code (Types) | No-Find (Bits) | Hash Code (Types) | No-Find (Bits) | |
| Lena | 208 | 156 | 256 | 0 |
| Pepper | 188 | 219 | 256 | 0 |
| Plane | 158 | 305 | 256 | 0 |
| Approaches | Capacity (bits) |
|---|---|
| HOGs [41] | 8 |
| DCT+LDA [42] | 1–15 |
| faster-RCNN [43] | 20 and 25 |
| [34] (non-overlapping) | 6272 |
| [34] (overlapping) | 55,112 |
| Our proposed method | 84,005 |
| Methods | PSNR | SSIM |
|---|---|---|
| Sahu and Swain [5] | 51.25 | 0.999 |
| Muhuri et al. [6] | 51.668 | 0.998 |
| Sahu and Swain [43] | 48.2 | 0.997 |
| [34] | ∞ | 1 |
| Our method | 52.024 | 1 |
| Attacks | [34] | Our Hiding Method |
|---|---|---|
| No attack | 80.10% | 100% |
| Median (3 × 3) | 65.90% | 72.60% |
| Median (5 × 5) | 59.60% | 68.20% |
| Gaussian low-pass filter (w = 3) | 69% | 75.80% |
| Gaussian noise (r = 0.001) | 39.30% | 6.90% |
| Salt and pepper noise | 3.70% | 1% |
| Speckle noise | 39.90% | 10.60% |
| Sharpening attack (r = 0.05) | 88.50% | 78.80% |
| Histogram equalization | 0.80% | 0.80% |
| Average filter | 69% | 77.30% |
| Motion blur | 58.50% | 59.70% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, J.-S.; Sun, X.-X.; Yang, H.; Snášel, V.; Chu, S.-C. Information Hiding Based on Two-Level Mechanism and Look-Up Table Approach. Symmetry 2022, 14, 315. https://doi.org/10.3390/sym14020315
Pan J-S, Sun X-X, Yang H, Snášel V, Chu S-C. Information Hiding Based on Two-Level Mechanism and Look-Up Table Approach. Symmetry. 2022; 14(2):315. https://doi.org/10.3390/sym14020315
Chicago/Turabian StylePan, Jeng-Shyang, Xiao-Xue Sun, Hongmei Yang, Václav Snášel, and Shu-Chuan Chu. 2022. "Information Hiding Based on Two-Level Mechanism and Look-Up Table Approach" Symmetry 14, no. 2: 315. https://doi.org/10.3390/sym14020315
APA StylePan, J.-S., Sun, X.-X., Yang, H., Snášel, V., & Chu, S.-C. (2022). Information Hiding Based on Two-Level Mechanism and Look-Up Table Approach. Symmetry, 14(2), 315. https://doi.org/10.3390/sym14020315