


Facial Expression Recognition Based on Dual-Channel Fusion with Edge Features


Abstract
1. Introduction
2. Related Work
3. Proposed Method
3.1. Edge Image Feature Extraction
3.2. Feature Fusion
4. Experiments
4.1. Datasets
- CK+
- Fer2013
- RafDb
4.2. Experimental Details Settings
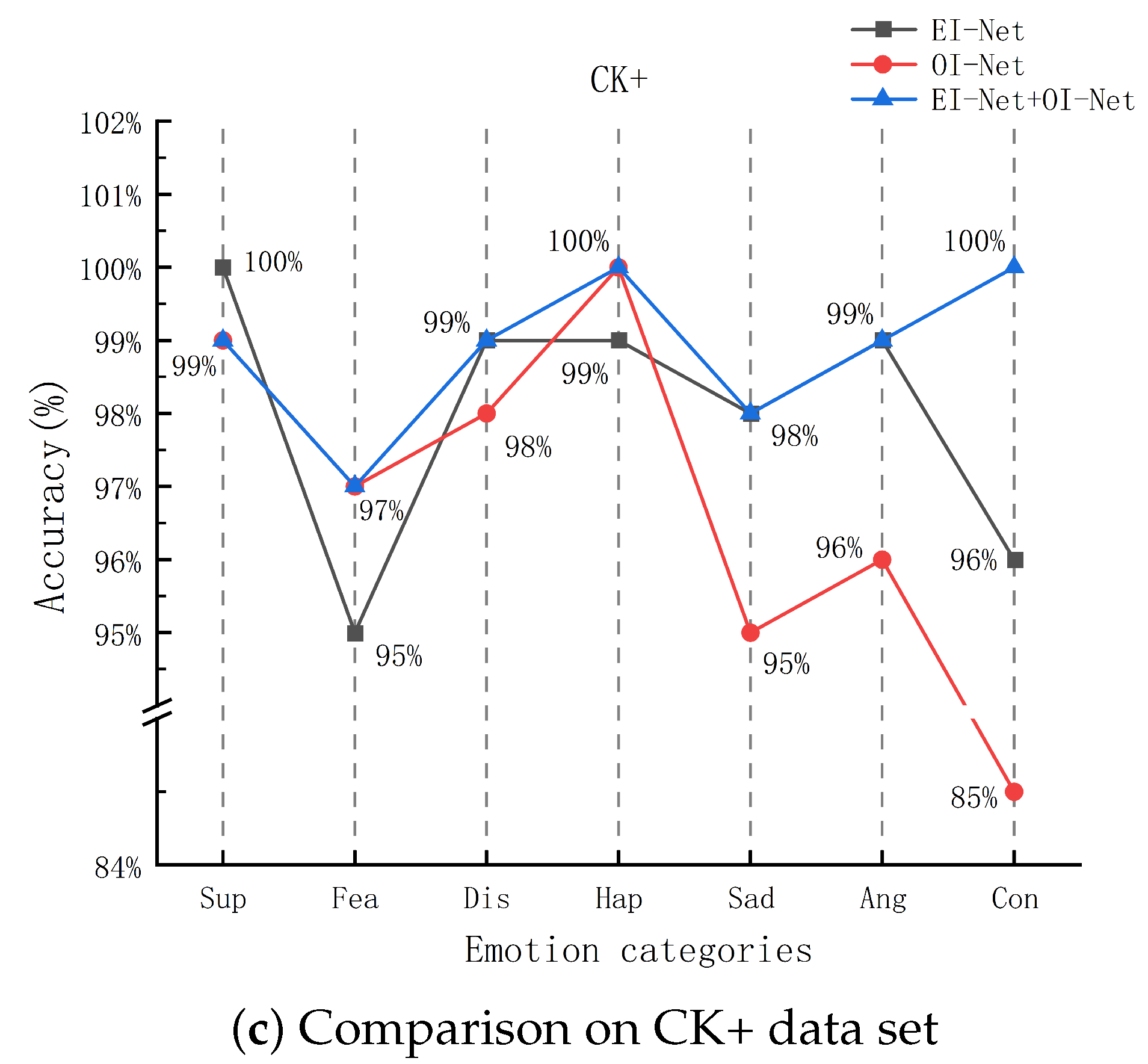
4.3. Ablation Experiment
4.3.1. Discussion of and
4.3.2. Comparison of Proposed Method with Single Channel
4.4. Confusion Matrices and Comparison with State-of-the-Art Methods
4.4.1. Confusion Matrices
4.4.2. Comparison with State-of-the-Art Methods
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kumari, J.; Rajesh, R.; Pooja, K. Facial expression recognition: A survey. Procedia Comput. Sci. 2015, 58, 486–491. [Google Scholar] [CrossRef]
- Mehrabian, A.; Russell, J.A. An Approach to Environmental Psychology; The MIT Press: Cambridge, MA, USA, 1974. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Caramihale, T.; Popescu, D.; Ichim, L. Emotion classification using a tensorflow generative adversarial network implementation. Symmetry 2018, 10, 414. [Google Scholar] [CrossRef]
- Hu, M.; Zheng, Y.; Yang, C.; Wang, X.; He, L.; Ren, F. Facial expression recognition using fusion features based on center-symmetric local octonary pattern. IEEE Access 2019, 7, 29882–29890. [Google Scholar] [CrossRef]
- Meena, H.K.; Joshi, S.D.; Sharma, K.K. Facial expression recognition using graph signal processing on HOG. IETE J. Res. 2021, 67, 667–673. [Google Scholar] [CrossRef]
- Shanthi, P.; Nickolas, S. An efficient automatic facial expression recognition using local neighborhood feature fusion. Multimed. Tools Appl. 2021, 80, 10187–10212. [Google Scholar] [CrossRef]
- Xie, S.; Hu, H.; Wu, Y. Deep multi-path convolutional neural network joint with salient region attention for facial expression recognition. Pattern Recognit. 2019, 92, 177–191. [Google Scholar] [CrossRef]
- Minaee, S.; Minaei, M.; Abdolrashidi, A. Deep-emotion: Facial expression recognition using attentional convolutional network. Sensors 2021, 21, 3046. [Google Scholar] [CrossRef] [PubMed]
- Wang, K.; Peng, X.; Yang, J.; Meng, D.; Qiao, Y. Region attention networks for pose and occlusion robust facial expression recognition. IEEE Trans. Image Process. 2020, 29, 4057–4069. [Google Scholar] [CrossRef] [PubMed]
- Levi, G.; Hassner, T. Emotion recognition in the wild via convolutional neural networks and mapped binary patterns. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, Seattle, WA, USA, 9–13 November 2015; pp. 503–510. [Google Scholar]
- Zhang, H.; Huang, B.; Tian, G. Facial expression recognition based on deep convolution long short-term memory networks of double-channel weighted mixture. Pattern Recognit. Lett. 2020, 131, 128–134. [Google Scholar] [CrossRef]
- Bougourzi, F.; Dornaika, F.; Mokrani, K.; Taleb-Ahmed, A.; Ruichek, Y. Fusing Transformed Deep and Shallow features (FTDS) for image-based facial expression recognition. Expert Syst. Appl. 2020, 156, 113459. [Google Scholar] [CrossRef]
- Yu, M.; Zheng, H.; Peng, Z.; Dong, J.; Du, H. Facial expression recognition based on a multi-task global-local network. Pattern Recognit. Lett. 2020, 131, 166–171. [Google Scholar] [CrossRef]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 679–698. [Google Scholar] [CrossRef]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The extended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 94–101. [Google Scholar]
- Carrier, P.L.; Courville, A.; Goodfellow, I.J.; Mirza, M.; Bengio, Y. FER-2013 Face Database; Universit de Montral: Montral, QC, Canada, 2013. [Google Scholar]
- Li, S.; Deng, W.; Du, J. Reliable crowdsourcing and deep locality-preserving learning for expression recognition in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2852–2861. [Google Scholar]
- Gan, Y.; Chen, J.; Yang, Z.; Xu, L. Multiple attention network for facial expression recognition. IEEE Access 2020, 8, 7383–7393. [Google Scholar] [CrossRef]
- Li, Y.; Zeng, J.; Shan, S.; Chen, X. Occlusion aware facial expression recognition using CNN with attention mechanism. IEEE Trans. Image Process. 2018, 28, 2439–2450. [Google Scholar] [CrossRef]
- Miao, S.; Xu, H.; Han, Z.; Zhu, Y. Recognizing facial expressions using a shallow convolutional neural network. IEEE Access 2019, 7, 78000–78011. [Google Scholar] [CrossRef]
- Wang, K.; Peng, X.; Yang, J.; Lu, S.; Qiao, Y. Suppressing uncertainties for large-scale facial expression recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 6897–6906. [Google Scholar]
- Gao, H.; Ma, B. A robust improved network for facial expression recognition. Front. Signal Process. 2020, 4, 4. [Google Scholar] [CrossRef]
- Shi, C.; Tan, C.; Wang, L. A facial expression recognition method based on a multibranch cross-connection convolutional neural network. IEEE Access 2021, 9, 39255–39274. [Google Scholar] [CrossRef]
- Chuanjie, Z.; Changming, Z. Facial Expression Recognition Integrating Multiple CNN Models. In Proceedings of the 2020 IEEE 6th International Conference on Computer and Communications (ICCC), Chengdu, China, 11–14 December 2020; pp. 1410–1414. [Google Scholar]
- Xie, W.; Shen, L.; Duan, J. Adaptive weighting of handcrafted feature losses for facial expression recognition. IEEE Trans. Cybern. 2019, 51, 2787–2800. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Hou, S. Facial expression recognition based on the fusion of CNN and SIFT features. In Proceedings of the 2020 IEEE 10th International Conference on Electronics Information and Emergency Communication (ICEIEC), Beijing, China, 17–19 July 2020; pp. 190–194. [Google Scholar]
- Li, H.; Xu, H. Deep reinforcement learning for robust emotional classification in facial expression recognition. Knowl.-Based Syst. 2020, 204, 106172. [Google Scholar] [CrossRef]
- Xia, Y.; Yu, H.; Wang, X.; Jian, M.; Wang, F.Y. Relation-aware facial expression recognition. IEEE Trans. Cogn. Dev. Syst. 2021, 14, 1143–1154. [Google Scholar] [CrossRef]
- Li, H.; Wang, N.; Yu, Y.; Yang, X.; Gao, X. LBAN-IL: A novel method of high discriminative representation for facial expression recognition. Neurocomputing 2021, 432, 159–169. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (a) RafDb Confusion matrices | |||||||
| Sur | Fea | Dis | Hap | Sad | Ang | Neu | |
| Sur | 79% | 3% | 2% | 7% | 6% | 0 | 3% |
| Fea | 8% | 57% | 1% | 10% | 11% | 9% | 4% |
| Dis | 5% | 0 | 58% | 9% | 4% | 8% | 16% |
| Hap | 0 | 1% | 0 | 95% | 3% | 0 | 1% |
| Sad | 0 | 1% | 0 | 4% | 89% | 5% | 2% |
| Ang | 0 | 2% | 0 | 4% | 7% | 87% | 0 |
| Neu | 1% | 2% | 2% | 3% | 5% | 0 | 87% |
| (b) Fer2013 Confusion matrices | |||||||
| Ang | Dis | Fea | Hap | Sad | Sur | Neu | |
| Ang | 99% | 1% | 0 | 0 | 0 | 0 | 0 |
| Dis | 1% | 99% | 0 | 0 | 0 | 0 | 0 |
| Fea | 0 | 0 | 100% | 0 | 0 | 0 | 0 |
| Hap | 0 | 0 | 0 | 100% | 0 | 0 | 0 |
| Sad | 0 | 0 | 0 | 0 | 98% | 2% | 0 |
| Sur | 0 | 0 | 0 | 0 | 0 | 98% | 2% |
| Con | 0 | 0 | 0 | 0 | 0 | 0 | 100% |
| (c) CK+ Confusion matrices | |||||||
| Ang | Dis | Fea | Hap | Sad | Sur | Neu | |
| Ang | 63% | 1% | 8% | 3% | 14% | 2% | 9% |
| Dis | 9% | 78% | 4% | 2% | 5% | 0 | 2% |
| Fea | 10% | 0 | 54% | 2% | 18% | 7% | 9% |
| Hap | 1% | 0 | 1% | 91% | 3% | 1% | 3% |
| Sad | 6% | 0 | 6% | 5% | 66% | 0 | 17% |
| Sur | 1% | 0 | 7% | 3% | 2% | 84% | 3% |
| Neu | 4% | 0 | 4% | 4% | 14% | 1% | 73% |
| Method | Pretraining | RafDb | Fer2013 | CK+ |
|---|---|---|---|---|
| [24] Gan et al. | ✔ | 85.69% | - | 96.28% |
| [25] ACNN | ✔ | 85.07% | - | - |
| [26] SHCNN | - | - | 69.10% | - |
| [27] SCN | ✔ | 87.03% | - | - |
| [15] Wang et al. | ✔ | 86.90% | - | - |
| [28] Gao H | - | - | 65.2% | - |
| [14] Minaee et al. | - | - | 70.02% | 98.0% |
| [29] MBCC-CNN | - | - | 71.52% | 98.48% |
| [30] Multiple CNN | - | - | 70.1% | 94.9% |
| [31] Xie et al. | - | - | 72.67% | 97.11% |
| [32] CNN+ SIFT | - | - | 72.85% | 93.46% |
| [33] DCNN+RLPS | - | 72.84% | 72.35% | - |
| [34] ReCNN | ✔ | 87.06% | - | - |
| [35] LBAN-IL | ✔ | 77.80% | 73.11% | - |
| Ours | - | 87.58% | 73.36% | 98.68% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, X.; Liu, S.; Xiang, Q.; Cheng, J.; He, H.; Xue, B. Facial Expression Recognition Based on Dual-Channel Fusion with Edge Features. Symmetry 2022, 14, 2651. https://doi.org/10.3390/sym14122651
Tang X, Liu S, Xiang Q, Cheng J, He H, Xue B. Facial Expression Recognition Based on Dual-Channel Fusion with Edge Features. Symmetry. 2022; 14(12):2651. https://doi.org/10.3390/sym14122651
Chicago/Turabian StyleTang, Xiaoyu, Sirui Liu, Qiuchi Xiang, Jintao Cheng, Huifang He, and Bohuan Xue. 2022. "Facial Expression Recognition Based on Dual-Channel Fusion with Edge Features" Symmetry 14, no. 12: 2651. https://doi.org/10.3390/sym14122651
APA StyleTang, X., Liu, S., Xiang, Q., Cheng, J., He, H., & Xue, B. (2022). Facial Expression Recognition Based on Dual-Channel Fusion with Edge Features. Symmetry, 14(12), 2651. https://doi.org/10.3390/sym14122651