

Multichannel Variational Autoencoder-Based Speech Separation in Designated Speaker Order

Abstract
:1. Introduction
2. Problem Formulation
3. Related Work
4. Proposed Method
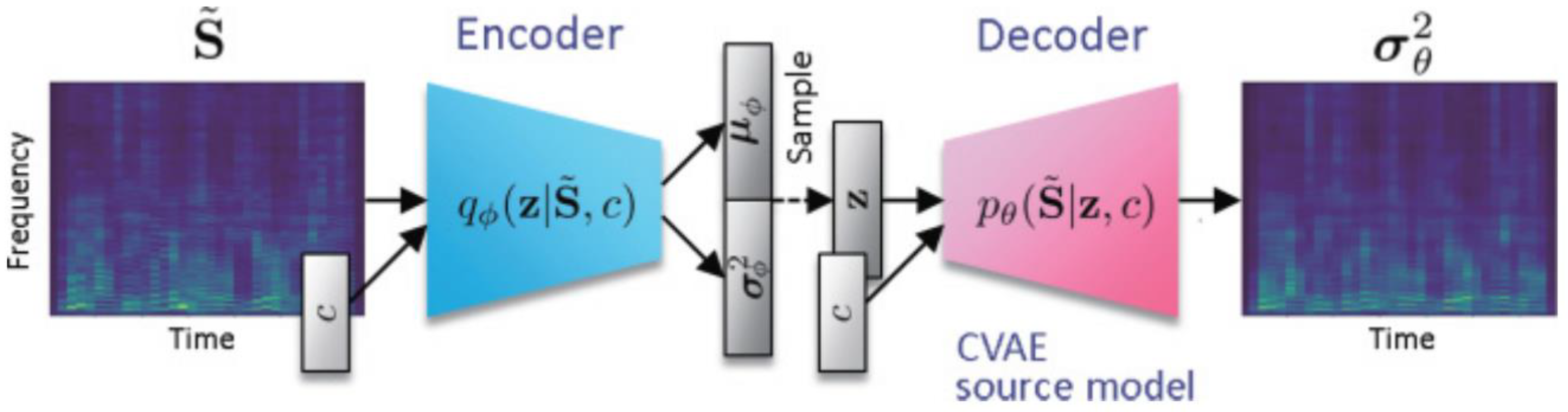
4.1. The Proposed VAE Model
4.2. Instance Normalization
4.3. Output in Designated Speaker Order
| Algorithm 1: IN-MVAE |
| Train E(s), E(c), and D with (23) |
| Initialize g with all elements being 1 and W using the ILRMA run for 30 iterations |
| Calculate the initially separated signal yini = Winix and initialize z(c) with content encoder outputs using z(c) = E(c)(yini) |
| Assign z(s) by the rearranged { } using the proposed permutation alignment scheme |
| Repeat Update z(c) with (11) using backpropagation for a fixed number of iterations |
| Update W and g using (15)–(18) |
| until convergence |
| Calculate the final separated signal y = Wx |
| Rearrange {yj} in designated speaker order using the proposed permutation alignment scheme |
5. Experiments
5.1. Simulation Environment
5.2. Performance Comparison with Existing Methods
5.3. Performance Evaluation with Different Gender Combinations
5.4. Performance Evaluation under Different Reverberation Times
5.5. Generalization Performance
6. Discussion and Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Makino, S.; Lee, T.-W.; Sawada, H. Blind Speech Separation; Springer: Dordrecht, The Netherlands, 2007; ISBN 9781402064791. [Google Scholar]
- Hyvärinen, A.; Hoyer, P. Emergence of Phase- and Shift-Invariant Features by Decomposition of Natural Images into Independent Feature Subspaces. Neural Comput. 2000, 12, 1705–1720. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, I.; Hao, J.; Lee, T.-W. Adaptive Independent Vector Analysis for the Separation of Convoluted Mixtures Using EM Algorithm. In Proceedings of the 2008 IEEE International Conference on Acoustics, Speech and Signal Processing, Las Vegas, NV, USA, 31 March–4 April 2008; pp. 145–148. [Google Scholar]
- Hao, J.; Lee, I.; Lee, T.-W.; Sejnowski, T.J. Independent Vector Analysis for Source Separation Using a Mixture of Gaussians Prior. Neural Comput. 2010, 22, 1646–1673. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gu, Z.; Lu, J.; Chen, K. Speech Separation Using Independent Vector Analysis with an Amplitude Variable Gaussian Mixture Model. In Proceedings of the INTERSPEECH 2019, Graz, Austria, 15–19 September 2019; pp. 1358–1362. [Google Scholar]
- Anderson, M.; Adali, T.; Li, X.-L. Joint Blind Source Separation with Multivariate Gaussian Model: Algorithms and Performance Analysis. IEEE Trans. Signal Process. 2012, 60, 1672–1683. [Google Scholar] [CrossRef]
- Liang, Y.; Naqvi, S.M.; Wang, W.; Chambers, J.A. Frequency Domain Blind Source Separation Based on Independent Vector Analysis with a Multivariate Generalized Gaussian Source Prior. In Blind Source Separation: Advances in Theory, Algorithms and Applications; Naik, G.R., Wang, W., Eds.; Signals and Communication Technology; Springer: Berlin, Heidelberg, 2014; pp. 131–150. ISBN 9783642550164. [Google Scholar]
- Khan, J.B.; Jan, T.; Khalil, R.A.; Altalbe, A. Hybrid Source Prior Based Independent Vector Analysis for Blind Separation of Speech Signals. IEEE Access 2020, 8, 132871–132881. [Google Scholar] [CrossRef]
- Kitamura, D.; Ono, N.; Sawada, H.; Kameoka, H.; Saruwatari, H. Determined Blind Source Separation Unifying Independent Vector Analysis and Nonnegative Matrix Factorization. IEEE ACM Trans. Audio Speech Lang. Process. 2016, 24, 1626–1641. [Google Scholar] [CrossRef]
- Sawada, H.; Ono, N.; Kameoka, H.; Kitamura, D.; Saruwatari, H. A Review of Blind Source Separation Methods: Two Converging Routes to ILRMA Originating from ICA and NMF. APSIPA Trans. Signal Inf. Process. 2019, 8, e12. [Google Scholar] [CrossRef] [Green Version]
- Ono, N. Stable and Fast Update Rules for Independent Vector Analysis Based on Auxiliary Function Technique. In Proceedings of the 2011 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, NY, USA, 16–19 October 2011; pp. 189–192. [Google Scholar]
- Lee, D.D.; Seung, H.S. Learning the Parts of Objects by Non-Negative Matrix Factorization. Nature 1999, 401, 788–791. [Google Scholar] [CrossRef] [PubMed]
- Lee, D.; Seung, H.S. Algorithms for Non-Negative Matrix Factorization. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2001; Volume 13. [Google Scholar]
- Xie, Y.; Xie, K.; Yang, J.; Xie, S. Underdetermined Blind Source Separation Combining Tensor Decomposition and Nonnegative Matrix Factorization. Symmetry 2018, 10, 521. [Google Scholar] [CrossRef] [Green Version]
- Kameoka, H.; Li, L.; Inoue, S.; Makino, S. Supervised Determined Source Separation with Multichannel Variational Autoencoder. Neural Comput. 2019, 31, 1891–1914. [Google Scholar] [CrossRef] [PubMed]
- Mogami, S.; Sumino, H.; Kitamura, D.; Takamune, N.; Takamichi, S.; Saruwatari, H.; Ono, N. Independent Deeply Learned Matrix Analysis for Multichannel Audio Source Separation. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 1557–1561. [Google Scholar]
- Makishima, N.; Mogami, S.; Takamune, N.; Kitamura, D.; Sumino, H.; Takamichi, S.; Saruwatari, H.; Ono, N. Independent Deeply Learned Matrix Analysis for Determined Audio Source Separation. IEEE ACM Trans. Audio Speech Lang. Process. 2019, 27, 1601–1615. [Google Scholar] [CrossRef]
- Wang, D.; Chen, J. Supervised Speech Separation Based on Deep Learning: An Overview. IEEE ACM Trans Audio Speech Lang Process. 2018, 26, 1702–1726. [Google Scholar] [CrossRef]
- Doersch, C. Tutorial on Variational Autoencoders. arXiv 2021, arXiv:1606.05908. [Google Scholar]
- Hyvärinen, A.; Karhunen, J.; Oja, E. Independent Component Analysis; Wiley: New York, USA, 2001; ISBN 9780471405405. [Google Scholar]
- Seki, S.; Kameoka, H.; Li, L.; Toda, T.; Takeda, K. Underdetermined Source Separation Based on Generalized Multichannel Variational Autoencoder. IEEE Access 2019, 7, 168104–168115. [Google Scholar] [CrossRef]
- Li, L.; Kameoka, H.; Makino, S. Fast MVAE: Joint Separation and Classification of Mixed Sources Based on Multichannel Variational Autoencoder with Auxiliary Classifier. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 546–550. [Google Scholar]
- Kameoka, H.; Kaneko, T.; Tanaka, K.; Hojo, N. ACVAE-VC: Non-Parallel Many-to-Many Voice Conversion with Auxiliary Classifier Variational Autoencoder. arXiv 2020, arXiv:1808.05092. [Google Scholar] [CrossRef]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Instance Normalization: The Missing Ingredient for Fast Stylization. arXiv 2017, arXiv:1607.08022. [Google Scholar]
- Wang, Q.; Zhang, Y.; Yin, S.; Wang, Y.; Wu, G. A Novel Underdetermined Blind Source Separation Method Based on OPTICS and Subspace Projection. Symmetry 2021, 13, 1677. [Google Scholar] [CrossRef]
- Chou, J.; Yeh, C.; Lee, H. One-Shot Voice Conversion by Separating Speaker and Content Representations with Instance Normalization. arXiv 2019, arXiv:1904.05742. [Google Scholar]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An ASR Corpus Based on Public Domain Audio Books. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar]
- Hadad, E.; Heese, F.; Vary, P.; Gannot, S. Multichannel Audio Database in Various Acoustic Environments. In Proceedings of the 2014 14th International Workshop on Acoustic Signal Enhancement (IWAENC), Juan-les-Pins, France, 8–11 September 2014; pp. 313–317. [Google Scholar]
- Vincent, E.; Gribonval, R.; Fevotte, C. Performance Measurement in Blind Audio Source Separation. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 1462–1469. [Google Scholar] [CrossRef] [Green Version]
- Rix, A.W.; Beerends, J.G.; Hollier, M.P.; Hekstra, A.P. Perceptual Evaluation of Speech Quality (PESQ)-a New Method for Speech Quality Assessment of Telephone Networks and Codecs. In Proceedings of the 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing. Proceedings (Cat. No.01CH37221), Salt Lake City, UT, USA, 7–11 May 2001; Volume 2, pp. 749–752. [Google Scholar]
- Taal, C.H.; Hendriks, R.C.; Heusdens, R.; Jensen, J. A Short-Time Objective Intelligibility Measure for Time-Frequency Weighted Noisy Speech. In Proceedings of the 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, TX, USA, 14–19 March 2010; pp. 4214–4217. [Google Scholar]
- Snyder, D.; Garcia-Romero, D.; Sell, G.; Povey, D.; Khudanpur, S. X-Vectors: Robust Dnn Embeddings for Speaker Recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; IEEE: New York, NY, USA, 2018; pp. 5329–5333. [Google Scholar]
- Prince, S.J.; Elder, J.H. Probabilistic Linear Discriminant Analysis for Inferences about Identity. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 26 December 2007; IEEE: New York, NY, USA, 2007; pp. 1–8. [Google Scholar]
- Anjos, A.; El-Shafey, L.; Wallace, R.; Günther, M.; McCool, C.; Marcel, S. Bob: A Free Signal Processing and Machine Learning Toolbox for Researchers. In Proceedings of the 20th ACM International Conference on Multimedia, Nara, Japan, 29 October 2012; pp. 1449–1452. [Google Scholar]
- Liang, Y.; Naqvi, S.M.; Chambers, J. Overcoming Block Permutation Problem in Frequency Domain Blind Source Separation When Using AuxIVA Algorithm. Electron. Lett. 2012, 48, 460–462. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| Description | Parameter |
|---|---|
| Number of Mel basis | 512 |
| Sampling rate | 16 kHz |
| STFT length | 128 ms |
| Hop length | 32 ms |
| Analysis window | Hanning |
| Optimizer | Adam |
| Learning rate | 0.0001 |
| Weight in loss | λrec = 10, λkl = 1 |
| Algorithm | ΔSIR (dB) | ΔSDR (dB) | ΔPESQ | ΔSTOI | Number of BP Problems | Sorting Accuracy |
|---|---|---|---|---|---|---|
| AuxIVA | 10.19 | 5.77 | 0.50 | 0.09 | 16 | 0.88 |
| ILRMA | 14.51 | 7.28 | 0.60 | 0.11 | 16 | 0.94 |
| MVAE | 20.35 | 7.84 | 0.76 | 0.12 | 7 | 0.98 |
| IN-MVAE | 22.41 | 9.42 | 0.79 | 0.13 | 0 | 1 |
| Combination Mode | ΔSIR (dB) | ΔSDR (dB) | ΔPESQ | ΔSTOI | Number of BP Problems | Sorting Accuracy |
|---|---|---|---|---|---|---|
| FM | 22.41 | 9.42 | 0.79 | 0.13 | 0 | 1 |
| FF | 21.83 | 9.41 | 0.84 | 0.14 | 1 | 1 |
| MM | 21.76 | 9.03 | 0.77 | 0.14 | 0 | 1 |
| Reverberation Time (ms) | ΔSIR (dB) | ΔSDR (dB) | ΔPESQ | ΔSTOI | Number of BP Problems | Sorting Accuracy |
|---|---|---|---|---|---|---|
| 160 | 24.78 | 10.83 | 1.30 | 0.16 | 2 | 0.98 |
| 360 | 22.41 | 9.42 | 0.79 | 0.13 | 0 | 1 |
| 610 | 20.20 | 8.17 | 0.56 | 0.11 | 0 | 1 |
| ΔSIR (dB) | ΔSDR (dB) | ΔPESQ | ΔSTOI | Number of BP Problems | Sorting Accuracy |
|---|---|---|---|---|---|
| 21.90 | 9.25 | 0.80 | 0.14 | 0 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liao, L.; Cheng, G.; Ruan, H.; Chen, K.; Lu, J. Multichannel Variational Autoencoder-Based Speech Separation in Designated Speaker Order. Symmetry 2022, 14, 2514. https://doi.org/10.3390/sym14122514
Liao L, Cheng G, Ruan H, Chen K, Lu J. Multichannel Variational Autoencoder-Based Speech Separation in Designated Speaker Order. Symmetry. 2022; 14(12):2514. https://doi.org/10.3390/sym14122514
Chicago/Turabian StyleLiao, Lele, Guoliang Cheng, Haoxin Ruan, Kai Chen, and Jing Lu. 2022. "Multichannel Variational Autoencoder-Based Speech Separation in Designated Speaker Order" Symmetry 14, no. 12: 2514. https://doi.org/10.3390/sym14122514
APA StyleLiao, L., Cheng, G., Ruan, H., Chen, K., & Lu, J. (2022). Multichannel Variational Autoencoder-Based Speech Separation in Designated Speaker Order. Symmetry, 14(12), 2514. https://doi.org/10.3390/sym14122514