
Using Adaptive Directed Acyclic Graph for Human In-Hand Motion Identification with Hybrid Surface Electromyography and Kinect
 , ,
, ,
Abstract
1. Introduction
- There are lower gripping accuracy, poorer stability, and reliability in the absence of geometric closure and force closure;
- It is difficult to achieve precise orientation and operation, as well as the poor dynamic response;
- It can’t fulfill the tasks that require high grasping force with a lack of precise force control.
2. Human In-Hand Motion Identification Method
2.1. Multiclass Support Vector Machines
2.2. Decision DAGSVM
2.3. DAGSVM Optimization
2.4. Model Optimization
3. In-Hand Manipulation Capture System Architecture
3.1. System Principle
3.2. Multi-Modal Data Acquisition Platform
3.2.1. Surface Electromyography
3.2.2. Kinect Sensor
3.3. Motion Capturing
4. Multi-Modal Signal Processing Method
4.1. Motion Segmentation
4.2. Feature Extraction
4.2.1. Feature Extraction from the SEMG Signal
4.2.2. Feature Extraction from the Kinect Signal
5. Experimental Results
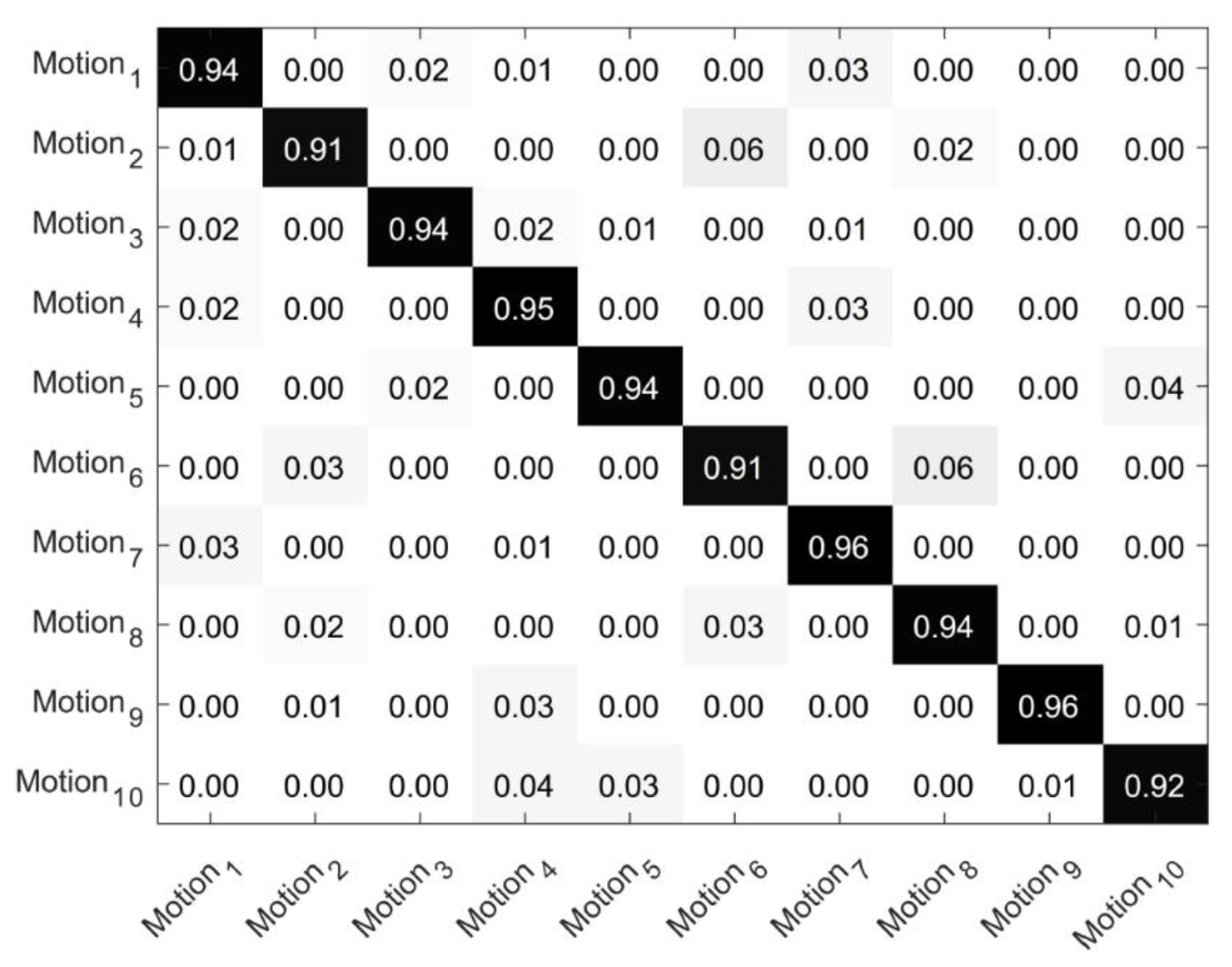
5.1. Human In-Hand Motion Recognition Results
5.2. Comparison Results of Different Subjects
5.3. Comparison Results of Different Multiclass SVM-Based Methods
5.4. Comparison Results of Different Machine Learning Methods
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, T.M.; Tao, Y.; Liu, H. Current Researches and Future Development Trend of Intelligent Robot: A Review. Int. J. Autom. Comput. 2018, 15, 525–546. [Google Scholar] [CrossRef]
- Fang, Y.; Zhou, D.; Li, K.; Liu, H. Interface prostheses with classifier-feedback-based user training. IEEE Trans. Biomed. Eng. 2017, 64, 2575–2583. [Google Scholar] [PubMed]
- Li, G.; Ma, F.; Guo, J.; Zhao, H. Bringing robotics to formal education: The Thymio open-source hardware robot. IEEE Robot. Autom. Mag. 2017, 24, 77–85. [Google Scholar]
- Wang, L.; Hu, W.; Tan, T. Recent developments in human motion analysis. Pattern Recognit. 2017, 36, 585–601. [Google Scholar] [CrossRef]
- Xue, Y.; Ju, Z.; Xiang, K.; Chen, J.; Liu, H. Multiple sensors based hand motion recognition using adaptive directed acyclic graph. Appl. Sci. 2017, 7, 358. [Google Scholar] [CrossRef]
- Vishwakarma, D.K. Hand gesture recognition using shape and texture evidences in complex background. In Proceedings of the 2017 International Conference on Inventive Computing and Informatics (ICICI), Coimbatore, India, 23–24 November 2017; pp. 278–283. [Google Scholar]
- Xue, Y.; Ju, Z.; Xiang, K.; Chen, J.; Liu, H. Multimodal Human Hand Motion Sensing and Analysis—A Review. IEEE Trans. Cogn. Dev. Syst. 2019, 11, 162–175. [Google Scholar]
- Elliott, J.M.; Connolly, K. A classification of manipulative hand movements. Dev. Med. Child Neurol. 1984, 26, 283–296. [Google Scholar] [CrossRef] [PubMed]
- Exner, C.E. The zone of proximal development in in-hand manipulation skills of nondysfunctional 3-and 4-year-old children. Am. J. Occup. Ther. 1990, 44, 884–891. [Google Scholar] [CrossRef] [PubMed]
- Pont, K.; Wallen, M.; Bundy, A. Conceptualising a modified system for classification of in-hand manipulation. Aust. Occup. Ther. J. 2009, 56, 2–15. [Google Scholar] [CrossRef] [PubMed]
- Xue, Y.; Yu, Y.; Yin, K.; Li, P.; Xie, S.; Ju, Z. Human In-Hand Motion Recognition Based on Multi-Modal Perception Information Fusion. IEEE Sens. J. 2022, 22, 6793–6805. [Google Scholar] [CrossRef]
- IBullock, M.; Ma, R.R.; Dollar, A.M. A hand-centric classification of human and robot dexterous manipulation. IEEE Trans. Haptics 2013, 6, 129–144. [Google Scholar] [CrossRef] [PubMed]
- Andrychowicz, O.M.; Baker, B.; Chociej, M.; Józefowicz, R.; McGrew, B.; Pachocki, J.; Petron, A.; Plappert, M.; Powell, G.; Ray, A.; et al. Learning dexterous in-hand manipulation. Int. J. Robot. Res. 2020, 39, 3–20. [Google Scholar] [CrossRef]
- Pagoli, A.; Chapelle, F.; Corrales, J.A.; Mezouar, Y.; Lapusta, Y. A soft robotic gripper with an active palm and reconfigurable fingers for fully dexterous in-hand manipulation. IEEE Robot. Autom. Lett. 2021, 6, 7706–7713. [Google Scholar] [CrossRef]
- Li, K.; Zhang, J.; Wang, L.; Zhang, M.; Li, J.; Bao, S. A review of the key technologies for sEMG-based human-robot interaction systems. Biomed. Signal Process. Control 2020, 62, 102074. [Google Scholar] [CrossRef]
- Xu, H.; Xiong, A. Advances and Disturbances in sEMG-Based Intentions and Movements Recognition: A Review. IEEE Sens. J. 2021, 21, 13019–13028. [Google Scholar] [CrossRef]
- Hu, Y.; Wong, Y.; Wei, W.; Du, Y.; Kankanhalli, M.; Geng, W. A novel attention-based hybrid CNN-RNN architecture for sEMG-based gesture recognition. PLoS ONE 2018, 13, e0206049. [Google Scholar] [CrossRef] [PubMed]
- Ma, R.; Zhang, L.; Li, G.; Jiang, D.; Xu, S.; Chen, D. Grasping force prediction based on sEMG signals. Alex. Eng. J. 2020, 59, 1135–1147. [Google Scholar] [CrossRef]
- Wang, L.; Huynh, D.Q.; Koniusz, P. A Comparative Review of Recent Kinect-Based Action Recognition Algorithms. IEEE Trans. Image Process. 2020, 29, 15–28. [Google Scholar] [CrossRef] [PubMed]
- Ju, Z.; Ouyang, G.; Liu, H. EMG-EMG correlation analysis for human hand movements. In Proceedings of the 2013 IEEE Workshop on Robotic Intelligence in Informationally Structured Space (RiiSS), Singapore, 16–19 April 2013; pp. 38–42. [Google Scholar]
- Sun, J.; Wang, Y.; Li, J.; Wan, W.; Cheng, D.; Zhang, H. View-invariant gait recognition based on kinect skeleton feature. Multimed. Tools Appl. 2018, 77, 24909–24935. [Google Scholar] [CrossRef]
- Chauhan, V.K.; Dahiya, K.; Sharma, A. Problem formulations and solvers in linear SVM: A review. Artif. Intell. Rev. 2019, 52, 803–855. [Google Scholar] [CrossRef]
- Hsu, C.-W.; Lin, C.-J. A comparison of methods for multiclass support vector machines. IEEE Trans. Neural Netw. 2002, 13, 415–425. [Google Scholar] [PubMed]
- Tkach, D.; Huang, H.; Kuiken, T.A. Study of stability of time domain features for electromyographic pattern recognition. J. Neuroeng. Rehabil. 2010, 7, 21. [Google Scholar] [CrossRef] [PubMed]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Training Time | SVs | Size | Merits | Demerits |
|---|---|---|---|---|---|
| One-versus-rest | Short | K | Large | Simple Effective | Misclassification |
| One-versus-one | Long | K*(k − 1)/2 | Moderate | High accuracy | Inseparable problem |
| Direct MSVM | Long | No SVs | Large | Natural optimization | Complex computation |
| DAGSVM | Long | K*(k − 1)/2 | Large | Efficient to train Avoid misclassification No rejected classification | Error accumulation |
| Classified Features | Equation |
|---|---|
| MAV | |
| WL | |
| RMS | |
| AAC | |
| ZC | |
| SSC | |
| N: the length of the segment | |
| : the i-th sample | |
| : a threshold |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xue, Y.; Yu, Y.; Yin, K.; Du, H.; Li, P.; Dai, K.; Ju, Z. Using Adaptive Directed Acyclic Graph for Human In-Hand Motion Identification with Hybrid Surface Electromyography and Kinect. Symmetry 2022, 14, 2093. https://doi.org/10.3390/sym14102093
Xue Y, Yu Y, Yin K, Du H, Li P, Dai K, Ju Z. Using Adaptive Directed Acyclic Graph for Human In-Hand Motion Identification with Hybrid Surface Electromyography and Kinect. Symmetry. 2022; 14(10):2093. https://doi.org/10.3390/sym14102093
Chicago/Turabian StyleXue, Yaxu, Yadong Yu, Kaiyang Yin, Haojie Du, Pengfei Li, Kejie Dai, and Zhaojie Ju. 2022. "Using Adaptive Directed Acyclic Graph for Human In-Hand Motion Identification with Hybrid Surface Electromyography and Kinect" Symmetry 14, no. 10: 2093. https://doi.org/10.3390/sym14102093
APA StyleXue, Y., Yu, Y., Yin, K., Du, H., Li, P., Dai, K., & Ju, Z. (2022). Using Adaptive Directed Acyclic Graph for Human In-Hand Motion Identification with Hybrid Surface Electromyography and Kinect. Symmetry, 14(10), 2093. https://doi.org/10.3390/sym14102093