Abstract
We use a recently proposed fast test of copula radial symmetry based on multiplier bootstrap and obtain an equivalent randomization test. The literature shows the statistical superiority of the randomization approach in the bivariate case. We extend the comparison of statistical performance focusing on the high-dimensional regime in a simulation study. We document radial asymmetry in the joint distribution of the percentage changes of sectorial industrial production indices of the European Union.
1. Introduction
Let , be the marginal cumulative distribution functions (CDFs) of a continuous random vector . The application of the component-wise probability integral transform (PIT) leads to a standard uniform random vector :
We call a d-dimensional vector with all components equal to one. The following distributional identity represents the hypothesis of copula radial symmetry:
This relationship was named, in the 2-dimensional case, radial symmetry of the copula function [1,2]. The empirical finance literature documents the absence of copula radial symmetry. Radial symmetry, in this case, is one of the manifestations of financial contagion or increased dependence of the returns on different assets during market downturns [3,4,5]. Moreover, this asymmetry of financial returns has consequences in asset allocation [6]. This behavior could be present also for macroeconomic variables because their dependence could change in recession periods. However, the literature rarely explored this possibility due to smaller samples and the lower frequency of macroeconomic variables. The lack of observations is even more relevant considering Eurostat macroeconomic variables, where most samples started in 1995. Therefore, one of the paper’s objectives is to understand if the proposed statistical procedures have access to applications in the European macroeconomic data domain. In particular, the most urgent requirement is the number of observations available for macroeconomic series. Therefore, the paper’s main contribution aims to reduce the sample size required for proper inference. The other constraint is the possibility of handling time series dependence characteristic of the macroeconomic environment. This issue was already present in previous financial applications of similar tests, and the solution was twofold: the extension to prefiltered residuals of a parametric time series model [7] or the nonparametric extension to strongly mixing data [8]. In this paper, we follow the prefiltering path. We can frame the symmetry using copula functions. We provide only the results and definitions needed in the following, but the interested reader could find excellent introductions to copula functions in [2,9,10]. According to the work in [11], the joint CDF of at each is equivalent to
C is of the copula coming from F and represents the joint CDF of . A similar approach applies to the marginal survival functions of , , . At each , we can write the joint survival function of :
Analogously to the copula case, then, the survival copula is the CDF of .
Using the definitions of copula and survival copula, Equation (1) boils down the following identity:
By Equation (2), for testing , we can use a measure of distributional distance. A nonparametric consistent estimation of this distance could be based on Empirical distribution. Let us consider an independent sample of size n from d-dimensional random vector , be. We denote the indicator for the set A as . In addition, we call , and . With those definitions, the empirical copula and the empirical survival copula are
Many measures of the distance between the copula and its survival counterpart lead to a test statistic of . Our preferred choice is a Cramér–von Mises statistic under the random measure generated by the empirical copula:
The 2-dimensional version of this statistic was introduced in [12] and investigated further in [13,14]. In particular, the work in [14] shows that Equation (3) is the most powerful statistic for a random vector of dimension two. Other bivariate nonparametric approaches for the same test are in [15,16]. Multivariate nonparametric radial tests are studied in [17,18,19].
We can derive the asymptotic null distribution of using the limiting behavior of the empirical copula process and the empirical survival copula processes:
The author of [20] obtains the following weak convergence result for the empirical copula process:
where is a d-dimensional Brownian sheet with covariance function
The analogous result for the Empirical survival copula process is obtained as a corollary of proposition 1 in [21] (see also [19]),
where is a d-dimensional Brownian sheet with covariance function
Under the null, Equation (3) becomes
In proposition 2 of [19] it is showed that, under the null, and its multiplier copies weakly converge to independent copies of
In the same paper, an extensive simulation study shows that the statistical procedure based on Equation (3) has size and power better than the proposal introduced in [17]. However, it is comparable to the competitor proposed in [18]. In addition, the procedure in [19] is faster to compute. The latter feature could help deal with high-dimensional data.
Recently the authors of [22], limiting themselves to the bivariate case, propose to approximate the distribution of Equation (3) and other statistics using randomization instead of the multiplier bootstrap. They show better finite sample behavior compared to the use of the multiplier techniques. In this paper, we generalize their approach to random vectors of higher dimensions and compare the behavior of multiplier and randomization procedures using random vectors with up to 100 components. We call the m-th multiplier statistic replicate with of [19] as with and the randomization replicate .
The paper is structured as follows. Section 2 generalizes asymptotic results in [22] to random vectors of any fixed dimension d. Section 3 investigates through simulations the finite sample behavior of the randomization test and compares it with the multiplier bootstrap procedure proposed in [19]. In Section 4, we apply the procedure to sectorial monthly industrial production at the EU27 level. Section 5 summarizes our findings and proposes further developments.
2. Materials and Methods
In this section, we describe the feasible randomization procedure introduced in [22] and derive the asymptotic behavior of its generalization for random vectors with more than two components. Proof can be found in the Appendix A. We consider a group of two transformations , , :
is a group under the operation of composition and we can derive a second group of transformations , by setting , where:
is also a group under the composition operation and under Equation (1)
In [22], the following feasible randomization procedure is proposed:
- draw as an independently distributed vector of Bernoulli random variables and set
- draw n independent standard uniform random variables and set, for
- For and compute
- Compute
- repeat steps 1–4 for a large number of times M and compute the approximate p-value
The careful reader may notice that in the description of feasible randomization, we have one step less than in [22]. The actual procedure, implemented by them and for which they study the asymptotic behavior, is described above their Equation (3.5). The description there is in line with ours. We denote with convergence conditional on the data in probability as in [23]. Consistently with the work in [22] neglecting step 3 in the procedure leads to under the null. This is shown in Lemma 1 and 2 below.
Lemma 1.
Let and be defined as follows:
Then,
where is centered and Gaussian with continuous sample paths. The covariance kernel of is given by
where ∧ is the component-wise minimum.
Lemma 2.
If then .
The limit needed for approximating the distribution of Equation (10) is instead . Lemmas 3 and 4 shows that introducing step 3 leads to the right limit under the following assumption from [20] and the null hypothesis.
Hypothesis 1.
For each , the jth first-order partial derivative exists and is continuous on the set .
Lemma 3.
Suppose that C satisfies Hypothesis 1. Then,
where can be written
where is centered and Gaussian with continuous sample paths and has covariance given in Equation (15).
The feasibility of the randomization test relies on the following distributional identity under the null:
Lemma 4.
If then .
In the following proposition, we obtain the asymptotic behavior of the randomization test replicates:
Proposition 1.
Consider an independent sample of size n from a random vector of dimension d having copula C, . Under the null of copula radial symmetry and the assumption Hypothesis 1, we obtain, as , the following results:
where are independent copies of .
It follows from Proposition 1 that the approximate p-values for the tests of based on are given by Equation (12).
3. Simulation Study
This section use simulations to study the finite sample properties of the different tests of multivariate copula radial symmetry. In all the experiments performed, the number of bootstrap or randomization replicates is M = 250, and the estimated probabilities of rejection are computed using 1000 Monte Carlo-independent replicates. Each table in the section presents varying number of observations , dimensions of the copula levels of dependence. In particular, the dependence is measured by Kendall’s on pairs of random variables imposing values in the set . We compare the tests and . Random sampling from the different copulas comes from the R package copula [24]. Before considering the statistical performance, we study the computational performance of the different procedures and report in Table 1, as an example, the running times for the number of observations and dimension , estimated from 1000 replicates, under the Frank copula model, using Matlab on a Windows 10 laptop with an Intel i7-6500U CPU and 8 GB of RAM.

Table 1.
Running Times of , , as estimated from 1000 replicates, in the , case, under the Frank copula model.
As we can see, the computing time for the randomization procedure is five times slower than the multiplier procedure. The discussion of statistical performance is in the following subsections.
3.1. Elliptical Family
Table 2 and Table 3 report results for Normal, t-student copula functions that are radially symmetric, allowing us to investigate the different procedures’ success in replicating the distribution of the test statistics under the null hypothesis. Consistently with [22], for random vectors of low dimension, the randomization test is less conservative than the multiplier test. The situation deteriorates considering high dimensional random vectors. The multiplier test never rejects the null hypothesis, while the randomization test remains close to the nominal level. The major difficulties for the randomization test are at a low level of dependence. Comparing Table 2 and Table 3 we can also see that fatter tails in the t-Student case, slightly raise the rejection percentage. In general, we can conclude that while the multiplier test is completely unreliable in the high dimensional setting, using 250 observations suffice to obtain a suitable size for the randomization test.
Table 2.
Rejection percentages at 5% significance level, as estimated from 1000 replicates, for the tests based on and under the normal copula.
Table 3.
Rejection percentages at 5% significance level, as estimated from 1000 replicates, for the tests based on and under the Student-t copula with degrees of freedom.
3.2. Archimedean Family
We investigate the following Archimedean copulas: the Frank Copula (Table 4), which is symmetric in two dimensions and mildly asymmetric beyond dimension two, and the asymmetric Clayton and Gumbel families (Table 5 and Table 6, respectively).
Table 4.
Rejection percentages at 5% significance level, as estimated from 1000 replicates, for the tests based on and under the Frank copula.
Table 5.
Rejection percentages at 5% significance level, as estimated from 1000 replicates, for the tests based on and under the Clayton copula.
Table 6.
Rejection percentages at 5% significance level, as estimated from 1000 replicates, for the tests based on and under the Gumbel copula.
In Table 4, results about the Frank family are reported. In dimension 2, we reproduce the situation discussed for the elliptic family. In the non-symmetric cases, power increases with dimension for randomization, detecting symmetry violation in high dimension already with 100 observations. The multiplier test appears not reliable in the high-dimensional case. The statistical power decrease with dependence as measured by the pairwise Kendall’s .
In the Clayton and Gumbel case (Table 5 and Table 6), asymmetry is strong, again power increases with dimension for the randomization test and is not adequate in high dimensions for the multiplier test. The relation between power and dependence is not monotonic. The randomization can discriminate against Clayton and Gumbel alternatives already with 100 observations.
4. Empirical Application
We apply the proposed procedure to the percentage changes of seasonally and calendar adjusted monthly industrial production by industry by NACE rev2 up to the second digit for mining and manufacture sectors at the EU27 level. In the Table 7, we detail the labels of 31 the sectors used. The sample started in 2001. In particular, we have 248 observations. Therefore, in line with our simulation study, we can consider the randomization procedure reliable in this setting. Nevertheless, the time series present autocorrelation, and we filtered them before applying the test. We fitted an AR(12) model without selecting the lags to each series and tested using the Ljung–Box statistics the absence of autocorrelation up to lag 18 and up to lag 24. Only the sector “Mining support service activities” exhibited autocorrelation, and we switched to estimating an AR(15) for this series. The new model for this sector resulted in no significant autocorrelation up to lag 24. In [7], the author performs a detailed theoretical investigation of prefiltering procedure for that kind of test. Corollary 1 of the latter paper presents the asymptotic equivalence of replacing i.i.d observations with residuals of a fitted general class of models. The class considered includes independent univariate autoregressive processes (see also [25]). The filtering approach was used in the bivariate case, in [22] for symmetry test with randomization, in [26] for a copula change point test. Moreover, the authors of [25] use prefiltering in the context of bivariate and trivariate independence tests. Finally, in [27], the results in [7] are further generalized, including the behavior of multiplier and ordinary bootstrap procedures, and applied to multivariate change point test. The simulation studies in the cited literature make us confident that inference for our radial symmetry test is not altered prefiltering. In addition, we performed a limited set of experiments under AR(12) univariate processes and the null of radial symmetry. The results are indistinguishable from the i.i.d. case and are available upon request.
Table 7.
Mining and Manufacturing 2-digit Nace rev. 2 industrial sectors.
The objective of the application is the statistical formalization of the stylized fact that dependence increase in recessions.
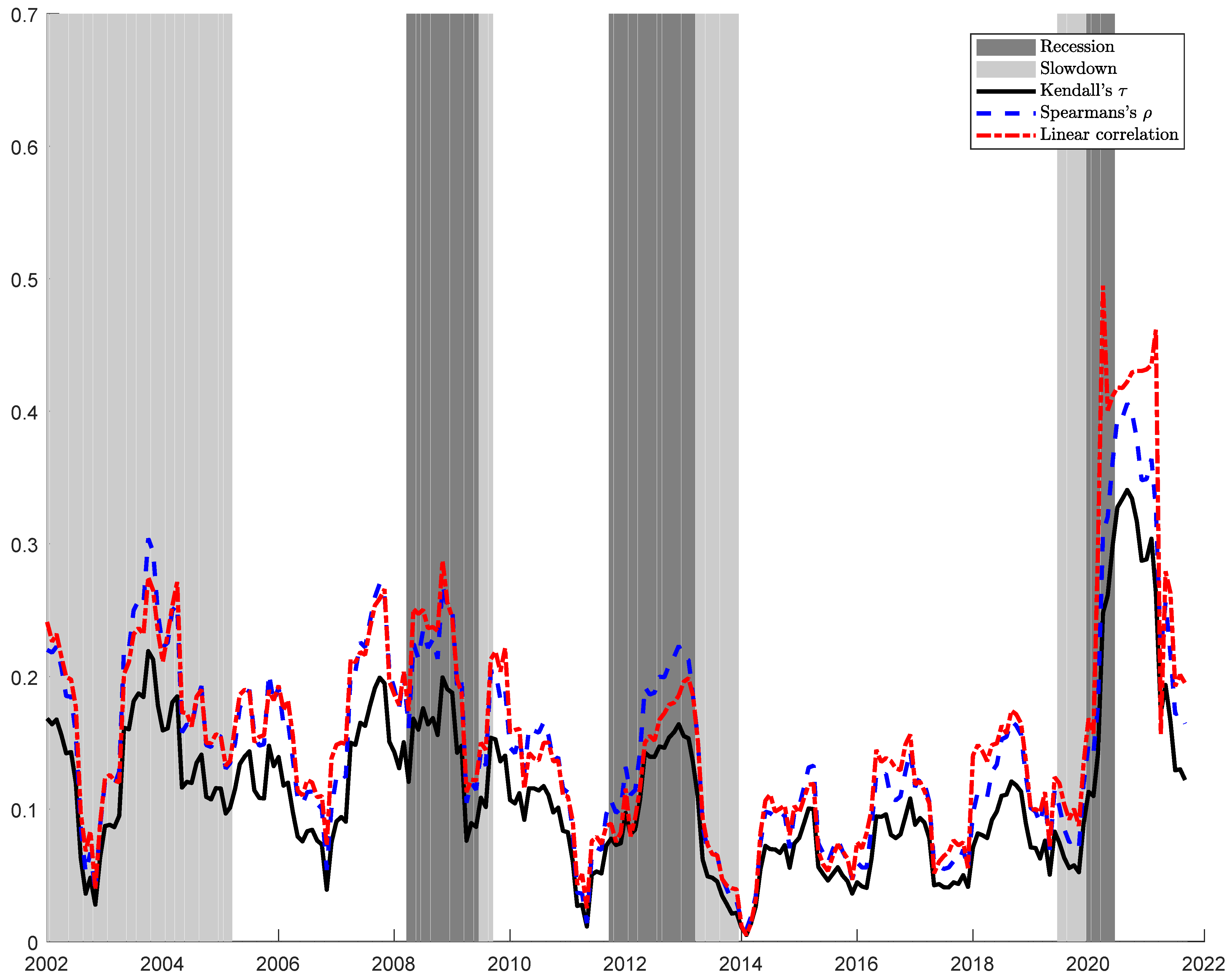
In Figure 1, we compute, using a rolling window of one year, an average over the possible couples of sectors residuals from autoregressive models of the most used measure of bivariate dependence: Linear (Pearson) correlation, Rank Correlation (Spearman’s ), and Kendall’s . Recessions and slowdown periods are from Eurostat’s Business Cycle Clock (BCC). The proposed dependence indicators all increase during recessions. However, we cannot understand if this increase is a statistical fluke due to the small sample. One possible way of formally testing for differences in dependence during a recession is testing the overall radial symmetry of the residual copula. While applying the multiplier bootstrap procedure results in a p-value of 0.8400 and not detecting asymmetry, the randomization procedure produces a p-value of 0.000, strongly suggesting the absence of symmetry. Asymmetry highlights the need for models of the distribution of residuals different from the usual Normal or t-Student assumption.
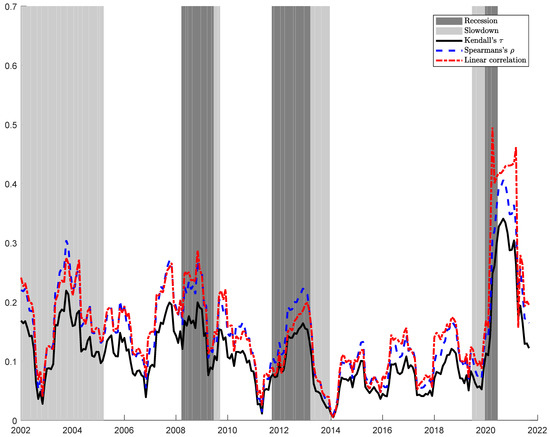
Figure 1.
Average Linear correlation, Spearman’s , and Kendall’s , computed using a rolling window of one year. Recessions and slowdown periods are from Eurostat’s Business Cycle Clock (BCC).
5. Conclusions
This paper extends the randomization approach in testing radial symmetry in [22] to more than two variables. It also compares in a simulation study with a high number of variables and its computing and statistical performance with the performance of the multiplier bootstrap procedure developed in [19]. However, even if the multiplier approach is computationally advantageous, it is statistically unreliable with a high number of series and observations up to 250. Instead, the randomization approach delivers reasonable size and power with 250 observations and 100 series, particularly for moderate and high values of pairwise Kendall’s tau. Understanding this striking difference in the high dimensional regime would require the study of the asymptotic behavior of the empirical copula process when both n and d go to infinity. This investigation is outside the scope of the paper but would be an exciting avenue for future research. The number of observations is sufficient to investigate asymmetry in a macroeconomic context where the highest frequency of the time series is monthly. Consequently, the samples are much smaller than in a financial application. We apply the randomization test to a European macroeconomic dataset, including growth rates of industrial production in 30 different sectors and 241 observations. Given our simulation study, the rejection of the null of radial symmetry below the 0.01% significance level, a consequence of the smallness of the randomization p-value of the test applied to the industrial production data, has to be considered statistically sounded. To our knowledge, we are the firsts to document radial asymmetry in the joint distribution of the percentage changes of sectorial industrial production indexes of the European Union. This finding allows better models of the joint distribution of the residuals, potentially leading to a better forecast of the economy-wide industrial production. In addition, this detection of asymmetry in industrial production could be a symptom of a change in dependence among sectorial production in recessions and booms, similar to what is happening to asset prices when subject to financial contagion. Those two consequences of our findings will be an exciting avenue for further investigation and research.
Author Contributions
Formal analysis, L.F.; Methodology, L.F.; Supervision, M.B. and D.G.; Writing—original draft, L.F. All authors have read and agreed to the published version of the manuscript.
Funding
Monica Billio acknowledges financial support from Italian Ministry MIUR under the PRIN project Hi-Di NET—Econometric Analysis of High Dimensional Models with Network Structures in Macroeconomics and Finance (grant 2017TA7TYC).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data for the Empirical application is publicly available in the Eurostat Database (https://ec.europa.eu/eurostat/data/database) (accessed on 20 November 2021).
Acknowledgments
The views expressed by Lorenzo Frattarolo are the author’s alone and do not necessarily correspond to those of the European Commission.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proofs and Auxiliary Results
Lemma A1.
For any , we have
Proof.
If for some , , both terms are zero. Therefore, w.l.o.g we consider only the case for which for each . Let us call , then we obtain
As with probability 1, and for every we cannot have for more than one i the last term is bounded by , using the same reasoning we compute the following:
Let us define with:
and this leads to
By the strong consistency of the empirical copula then
where is the C-Volume on the hyperbox [2]. □
Appendix A.1. Proof of Lemma 1
Proof.
Let us define
Following arguments analogous to the proof of Lemma A.3 in [22] we obtain the bounds
As they are asymptotically equivalent, the limit of and will be equal to the limit of
In particular if we define
the expectation conditional on the data is
and we obtain
and are simple maps from their underlying probability space into . Therefore, they are borel measurable and satisfy the second condition of definition 4.1 in [22]. As in [22], we will apply Theorem 11.16 in [23] originally due to that in [28]. As the following relation holds
we obtain the following result:
we can focus only on , in addition, using the Equations (A2) and (11) is times the difference of a coordinate-wise non decreasing function and a decreasing function in .
We should check that the triangular array verify a.s. conditions (A)–(E) of Theorem 11.16 in Kosorok and that is almost measurable Suslin (AMS).
- (A)
- Maneageability of the ’s with envelopes is a consequence of the monotonicity of the , as discussed in [23].
- (B)
- If , using the independence of and , it follows that . In the case we obtain:Then, we the following expectation can be computed:Using Lemma A1 it follows that
- (C)
- .
- (D)
- for each .
- (E)
- Using the same line of reasoning of [22] in their proof of Lemma 4.1 point (E), we obtainso the uniform strong consistency of the empirical copula along with Lemma A1 ensures that condition (E) is satisfied a.s. with
It remains to show that the triangular array is almost measurable Suslin (AMS). We verify Kosorok’s separability condition for that by Lemma 11.15 of [23] implies AMS. Analogously to the last part of the proof of Lemma 4.1 in [22], given that takes values on the grid , it can be shown that for every
and infimum is attained in where is the floor function applied to x. This condition suffice to prove separability and consequently AMS. By Theorem 11.16 in [23] and by the conditional continuous mapping theorem (Theorem 4.1 in [22]) and Equation (A3) . The statement of the theorem follows from the asymptotic equivalence in Equation (A1). □
Appendix A.2. Proof of Lemma 2
Proof.
The covariance between and are the weak limit of the multivariate empirical processes and where
with with known marginal distributions , . The Covariance between and is the limit of the covariance between and :
Because of the independence of and if ,
Appendix A.3. Proof of Lemma 3
Proof.
The proof is analogous to the proof of Lemma 4.3 in [22].
We introduce the map [29]
where , denotes the set of all distribution functions H on , whose marginal CDFs satisfy , . Theorem 2.4 in [29] implies that is Hadamard differentiable at any copula C satisfying under Hypothesis 1, tangentially to
where is the space of continuous real valued functions on . The derivative in the direction is .
We would like to use Equations (14) and (A5) and the conditional delta method (Theorem 4.2 in [22]) applied to the map to obtain the result. We face the same difficulty experienced in [22]. and do not have marginals grounded at zero. Letting denote the set of CDF on and we generalize the sequence of maps introduced in the latter paper by defining . The rest of the proof follows the line of the proof of Lemma 4.3 in [22] by recognizing that and . □
Appendix A.4. Proof of Lemma 4
Proof.
According to Lemma 3 . From the work in [29], we have , and from the proof of Proposition 1 in [19] , then under
From Lemma 2 and using Equation (A6) . □
Appendix A.5. Proof of Proposition 1
We consider only one multiplier replicate being the generalization to M replicates straightforward. Under the null and assumption Hypothesis 1, using Lemma Using Lemma 3, the conditional continuous mapping theorem (Theorem 4.1 in [22]) and a constant , we can write
By the weak convergence of the empirical copula process the following limit holds true:
Let be the space of function that are continuous ; the space of cadlag function on ; and the subspace of consisting of the functions with total variation bounded by one. Let us introduce the map , defined by
By Lemma 1 in [19] is Hadamard differentiable tangentially to at each in , such that . with derivative given by
Then, an application of the conditional delta method (Theorem 4.2 in [22]) gives
or equivalently
The statement of the theorem for one replica follows from Lemma 4.
References
- Nelsen, R.B. Some concepts of bivariate symmetry. J. Nonparametr. Stat. 1993, 3, 95–101. [Google Scholar] [CrossRef]
- Nelsen, R.B. An Introduction to Copulas, 2nd ed.; Springer Series in Statistics; Springer: New York, NY, USA, 2006. [Google Scholar]
- Longin, F.; Solnik, B. Extreme correlation of international equity markets. J. Financ. 2001, 56, 649–676. [Google Scholar] [CrossRef]
- Ang, A.; Chen, J. Asymmetric correlations of equity portfolios. J. Financ. Econ. 2002, 63, 443–494. [Google Scholar] [CrossRef]
- Billio, M.; Pelizzon, L. Contagion and interdependence in stock markets: Have they been misdiagnosed? J. Econ. Bus. 2003, 55, 405–426. [Google Scholar] [CrossRef]
- Patton, A.J. On the Out-of-Sample Importance of Skewness and Asymmetric Dependence for Asset Allocation. J. Financ. Econom. 2004, 2, 130–168. [Google Scholar] [CrossRef] [Green Version]
- Rémillard, B. Goodness-of-Fit Tests for Copulas of Multivariate Time Series. Econometrics 2017, 5, 13. [Google Scholar] [CrossRef] [Green Version]
- Bücher, A.; Kojadinovic, I. A dependent multiplier bootstrap for the sequential empirical copula process under strong mixing. Bernoulli 2016, 22, 927–968. [Google Scholar] [CrossRef] [Green Version]
- Joe, H. Dependence Modeling with Copulas; Chapman & Hall/CRC Monographs on Statistics & Applied Probability: Boca Raton, FL, USA, 2014. [Google Scholar]
- Durante, F.; Sempi, C. Principles of Copula Theory; CRC Press: Boca Raton, FL, USA, 2015. [Google Scholar]
- Sklar, M. Fonctions de répartition à n dimensions et leurs marges. Publ. Inst. Stat. Univ. Paris 1959, 8, 229–231. [Google Scholar]
- Bouzebda, S.; Cherfi, M. Test of symmetry based on copula function. J. Stat. Plan. Inference 2012, 142, 1262–1271. [Google Scholar] [CrossRef]
- Dehgani, A.; Dolati, A.; Úbeda Flores, M. Measures of radial asymmetry for bivariate random vectors. Stat. Pap. 2013, 54, 271–286. [Google Scholar] [CrossRef]
- Genest, C.; Nešlehová, J.G. On tests of radial symmetry for bivariate copulas. Stat. Pap. 2014, 55, 1107–1119. [Google Scholar] [CrossRef]
- Rosco, J.F.; Joe, H. Measures of tail asymmetry for bivariate copulas. Stat. Pap. 2013, 54, 709–726. [Google Scholar] [CrossRef]
- Li, B.; Genton, M.G. Nonparametric identification of copula structures. J. Am. Stat. Assoc. 2013, 108, 666–675. [Google Scholar] [CrossRef]
- Krupskii, P. Copula-based measures of reflection and permutation asymmetry and statistical tests. Stat. Pap. 2017, 58, 1165–1187. [Google Scholar] [CrossRef]
- Bahraoui, T.; Quessy, J.F. Tests of radial symmetry for multivariate copulas based on the copula characteristic function. Electron. J. Stat. 2017, 11, 2066–2096. [Google Scholar] [CrossRef]
- Billio, M.; Frattarolo, L.; Guégan, D. Multivariate radial symmetry of copula functions: Finite sample comparison in the i.i.d case. Depend. Model. 2021, 9, 43–61. [Google Scholar] [CrossRef]
- Segers, J. Asymptotics of empirical copula processes under non-restrictive smoothness assumptions. Bernoulli 2012, 18, 764–782. [Google Scholar] [CrossRef]
- Quessy, J.F. A general framework for testing homogeneity hypotheses about copulas. Electron. J. Stat. 2016, 10, 1064–1097. [Google Scholar] [CrossRef]
- Beare, B.K.; Seo, J. Randomization test of copula symmetry. Econ. Theory 2020, 36, 1025–1063. [Google Scholar] [CrossRef] [Green Version]
- Kosorok, M. Introduction to Empirical Processes and Semiparametric Inference; Springer Series in Statistics; Springer: New York, NY, USA, 2010. [Google Scholar]
- Hofert, M.; Kojadinovic, I.; Maechler, M.; Yan, J. Copula: Multivariate Dependence with Copulas; R Package Version 1.0-1. 2020. Available online: https://CRAN.R-project.org/package=copula (accessed on 20 November 2021).
- Duchesne, P.; Ghoudi, K.; Rémillard, B. On testing for independence between the innovations of several time series. Can. J. Stat. 2012, 40, 447–479. [Google Scholar] [CrossRef]
- Bucher, A.; Jaschke, S.; Wied, D. Nonparametric tests for constant tail dependence with an application to energy and finance. J. Econom. 2015, 187, 154–168. [Google Scholar] [CrossRef]
- Nasri, B.R.; Rémillard, B.N.; Bahraoui, T. Change-point problems for multivariate time series using pseudo-observations. J. Multivar. Anal. 2022, 187, 104857. [Google Scholar] [CrossRef]
- Pollard, D. Empirical Processes: Theory and Applications; Conference Board of the Mathematical Science: NSF-CBMS Regional Conference Series in Probability and Statistics; Institute of Mathematical Statistics: Hayward, CA, USA, 1990. [Google Scholar]
- Bücher, A.; Volgushev, S. Empirical and sequential empirical copula processes under serial dependence. J. Multivar. Anal. 2013, 119, 61–70. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).