
Execution Time Prediction for Cypher Queries in the Neo4j Database Using a Learning Approach

Abstract
1. Introduction
- Resource allocation [16,17]: The computational resources (e.g., memory, CPU, cache size) are adjusted to meet the operating requirements of the load and then help the systems achieve optimal utilization. In most cases, the goal of predicting query tasks is to ensure the timeliness of the load and to maximize resource utilization.
2. Related Work
2.1. Relational-Based Queries
2.2. Graph-Based Queries
3. Cypher Queries
3.1. Overview of the Cypher Query Plan
3.2. Overview of Performance Prediction Architecture
4. Cypher Query Execution Time Prediction
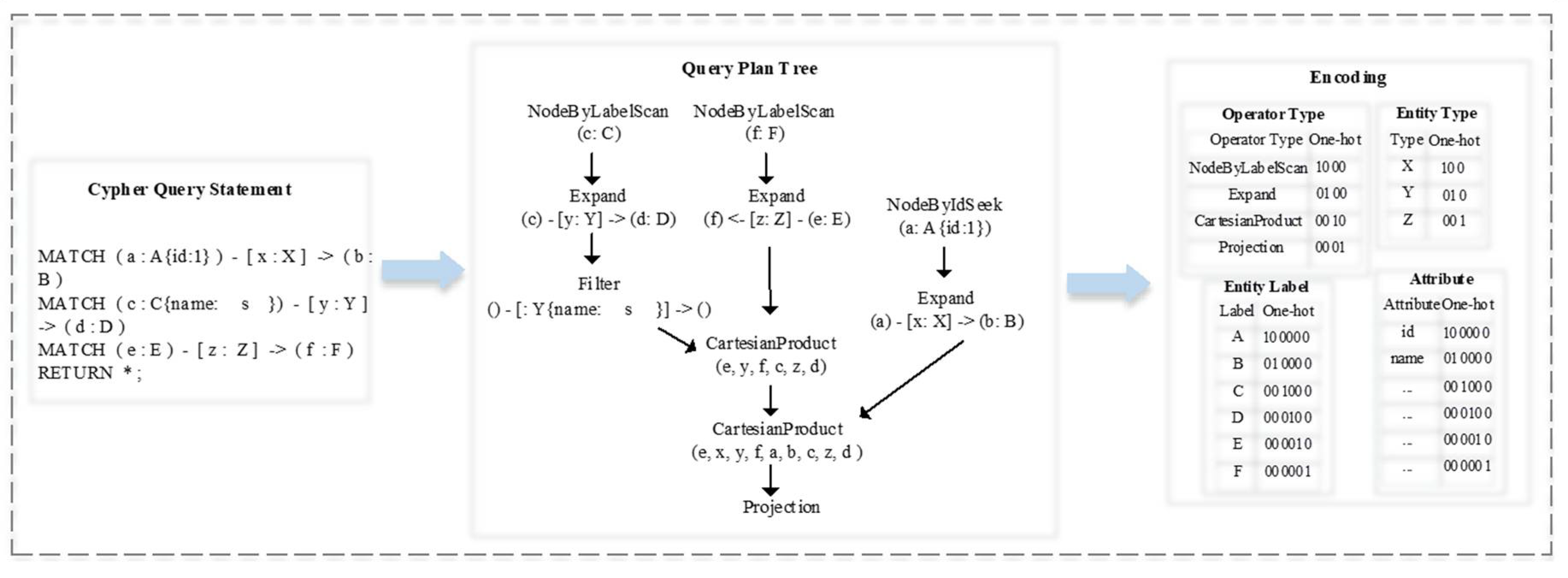
4.1. Feature Extraction and Encoding
4.1.1. Encoding Query Plan
4.1.2. Encoding Graph Pattern
4.2. Prediction Model
5. Experimental Evaluation
5.1. Datasets
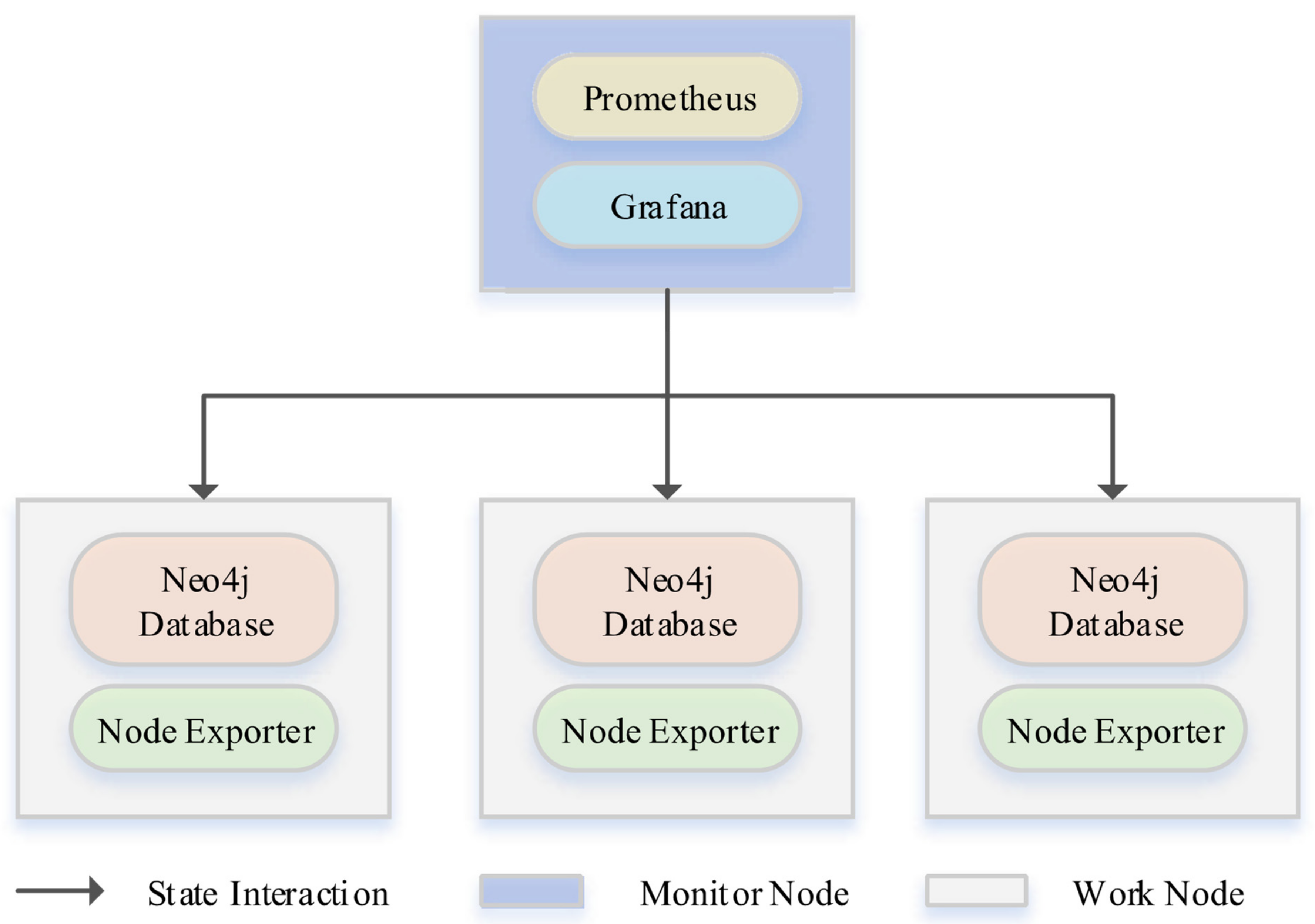
5.2. Monitor
5.3. Evaluation Techniques
5.4. Experiment Results of Prediction Models
6. Conclusions
- Query-driven and data-driven methods have their advantages and disadvantages; how to combine the two methods to improve performance prediction accuracy is important for research work.
- Sparse and high-dimensional representation is a challenge in learning-based methods; existing research works have explored some methods of representation learning [30], but there is still a significant amount of research space for the dense input.
- The execution time of a plan depends on the sum of the time cost of all operators. Therefore, in addition to the query plan and pattern features, we should consider the impact of the hardware deployment environment and the state of the database (e.g., buffer, stream queries, concurrent queries) for the query performance.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Drakopoulos, G.; Kanavos, A.; Tsakalidis, A.K. Evaluating Twitter Influence Ranking with System Theory. In Proceedings of the 12th International Conference on Web Information Systems and Technologies (WeBIST), Rome, Italy, 23–25 April 2016; pp. 113–120. [Google Scholar]
- Lysenko, A.; Roznovăţ, I.A.; Saqi, M.; Mazein, A.; Rawlings, C.J.; Auffray, C. Representing and querying disease networks using graph databases. BioData Min. 2016, 9, 1–19. [Google Scholar] [CrossRef]
- Guirguis, S.; Sharaf, M.A.; Chrysanthis, P.K.; Labrinidis, A.; Pruhs, K. Adaptive scheduling of web transactions. In Proceedings of the IEEE 25th International Conference on Data Engineering, Shanghai, China, 29 March–2 April 2009; pp. 357–368. [Google Scholar]
- Paulheim, H. Knowledge graph refinement: A survey of approaches and evaluation methods. Semant. Web 2017, 8, 489–508. [Google Scholar] [CrossRef]
- Rizvi, S.Z.R.; Fong, P.W.L. Efficient Authorization of Graph-database Queries in an Attribute-supporting ReBAC Model. ACM Trans. Priv. Secur. (TOPS) 2020, 23, 1–33. [Google Scholar] [CrossRef]
- Dinari, H. A Survey on Graph Queries Processing: Techniques and Methods. Int. J. Comput. Netw. Inf. Secur. 2017, 9, 48–56. [Google Scholar] [CrossRef][Green Version]
- Scabora, L.C.; Spadon, G.; Oliveira, P.H.; Rodrigues, J.F.; Traina, C. Enhancing recursive graph querying on RDBMS with data clustering approaches. In Proceedings of the 35th Annual ACM Symposium on Applied Computing, Brno, Czech Republic, 30 March–3 April 2020; pp. 404–411. [Google Scholar]
- Hauff, C.; Azzopardi, L. When is query performance prediction effective? In Proceedings of the 32nd international ACM SIGIR conference on Research and Development in Information Retrieval—SIGIR, Boston, MA, USA, 19–23 July 2009; pp. 829–830. [Google Scholar]
- Zendel, O.; Shtok, A.; Raiber, F. Information needs, queries, and query performance prediction. In Proceedings of the 42nd International ACM uSIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 395–404. [Google Scholar]
- Holzschuher, F.; Peinl, R. Performance of graph query languages: Comparison of cypher, gremlin and native access in neo4j. In Proceedings of the Joint EDBT/ICDT 2013 Workshops, Genoa, Italy, 18–22 March 2013; pp. 195–204. [Google Scholar]
- Li, J.; Ma, X.; Singh, K. Machine learning based online performance prediction for runtime parallelization and task scheduling. In Proceedings of the 2009 IEEE International Symposium on Performance Analysis of Systems and Software, Boston, MA, USA, 26–28 April 2009; pp. 89–100. [Google Scholar]
- Macdonald, C.; Tonellotto, N.; Ounis, I. Learning to predict response times for online query scheduling. In Proceedings of the 35th International ACM SIGIR Conference on Research and Development in Information Retrieval, Portland, OR, USA, 12–16 August 2012; pp. 621–630. [Google Scholar]
- Raza, B.; Kumar, Y.J.; Malik, A.K.; Anjum, A.; Faheem, M. Performance prediction and adaptation for database management system workload using Case-Based Reasoning approach. Inf. Syst. 2018, 76, 46–58. [Google Scholar] [CrossRef]
- Duggan, J.; Cetintemel, U.; Papaemmanouil, O. Performance prediction for concurrent database workloads. In Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data, Athens, Greece, 12–16 June 2011; pp. 337–348. [Google Scholar]
- Raza, B.; Mateen, A.; Sher, M.; Awais, M.M. Self-prediction of performance metrics for the database management system workload. Int. J. Comput. Theory Eng. 2012, 4, 198. [Google Scholar] [CrossRef]
- Li, J.; König, A.C.; Narasayya, V.; Chaudhuri, S. Robust estimation of resource consumption for SQL queries using statistical techniques. arXiv 2012, arXiv:1208.0278. [Google Scholar] [CrossRef]
- Duggan, J.; Papaemmanouil, O.; Cetintemel, U.; Upfal, E. Contender: A Resource Modeling Approach for Concurrent Query Performance Prediction. In Proceedings of the Extending Database Technology, Athens, Greece, 24–28 March 2014; pp. 109–120. [Google Scholar]
- Murugesan, M.; Shen, J.; Qi, Y. Resource Estimation for Queries in Large-Scale Distributed Database System. U.S. Patent 10,762,539, 1 September 2020. [Google Scholar]
- Kang, B.; Kim, D.; Kang, S.H. Periodic performance prediction for real-time business process monitoring. Ind. Manag. Data Syst. 2012, 112, 4–23. [Google Scholar] [CrossRef]
- Zhao, P.; Han, J. On graph query optimization in large networks. In Proceedings of the VLDB Endowment, Singapore, 13–17 September 2010; pp. 340–351. [Google Scholar]
- Das, S.; Goyal, A.; Chakravarthy, S. Plan before you execute: A cost-based query optimizer for attributed graph databases. In Proceedings of the International Conference on Big Data Analytics and Knowledge Discovery, Porto, Portugal, 6–8 September 2016; pp. 314–328. [Google Scholar]
- Namaki, M.H.; Sasani, K.; Wu, Y. Performance prediction for graph queries. In Proceedings of the 2nd International Workshop on Network Data Analytics, Chicago, IL, USA, 19 May 2017; pp. 1–9. [Google Scholar]
- Sasani, K.; Namaki, M.H.; Wu, Y. Multi-metric graph query performance prediction. In Proceedings of the International Conference on Database Systems for Advanced Applications, Gold Coast, QLD, Australia, 21–24 May 2018; pp. 289–306. [Google Scholar]
- He, B.; Ounis, I. Query performance prediction. Inf. Syst. 2006, 31, 585–594. [Google Scholar] [CrossRef]
- Wu, W.; Chi, Y.; Zhu, S.; Tatemura, J.; Hacigümüs, H.; Naughton, J.F. Predicting query execution time: Are optimizer cost models really unusable? In Proceedings of the 2013 IEEE 29th International Conference on Data Engineering (ICDE), Brisbane, QLD, Australia, 8–12 April 2013; pp. 1081–1092. [Google Scholar]
- Wu, W.; Chi, Y.; Hacígümüş, H. Towards predicting query execution time for concurrent and dynamic database workloads. Proc. VLDB Endow. 2013, 6, 925–936. [Google Scholar] [CrossRef]
- Hasan, R.; Gandon, F. A Machine Learning Approach to SPARQL Query Performance Prediction. In Proceedings of the International Joint Conferences on Web Intelligence (WI) and Intelligent Agent Technologies (IAT) IEEE, Washington, DC, USA, 11–14 August 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 266–273. [Google Scholar]
- Zhang, W.E.; Sheng, Q.Z.; Taylor, K. Learning-based SPARQL query performance prediction. In Proceedings of the International Conference on Web Information Systems Engineering, Shanghai, China, 8–10 November 2016; pp. 313–327. [Google Scholar]
- Zhang, W.E.; Sheng, Q.Z.; Qin, Y. Learning-based SPARQL query performance modeling and prediction. World Wide Web 2018, 21, 1015–1035. [Google Scholar] [CrossRef]
- Marcus, R.; Papaemmanouil, O. Plan-structured deep neural network models for query performance prediction. arXiv 2019, arXiv:1902.00132. [Google Scholar] [CrossRef]
- Zhou, X.; Sun, J.; Li, G. Query performance prediction for concurrent queries using graph embedding. Proc. VLDB Endow. 2020, 13, 1416–1428. [Google Scholar] [CrossRef]
- Namaki, M.H.; Chowdhury, F.A.; Islam, M.; Doppa, J.; Wu, Y. Learning to Speed Up Query Planning in Graph Databases. arXiv 2018, arXiv:1801.06766. [Google Scholar]
- Izsó, B.; Szatmári, Z.; Bergmann, G. Towards precise metrics for predicting graph query performance. In Proceedings of the 28th IEEE/ACM International Conference on Automated Software Engineering (ASE), Silicon Valley, CA, USA, 11–15 November 2013; pp. 421–431. [Google Scholar]
- Chu, Z.; Yu, J.; Hamdulla, A. A novel deep learning method for query task execution time prediction in graph database. Future Gener. Comput. Syst. 2020, 112, 534–548. [Google Scholar] [CrossRef]
- Fu, X.; Wang, L. Data dimensionality reduction with application to simplifying RBF network structure and improving classifica-tion performance. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2003, 33, 399–409. [Google Scholar]
- Zhang, M.L. M l-rbf: Rbf neural networks for multi-label learning. Neural Process. Lett. 2009, 29, 61–74. [Google Scholar] [CrossRef]
- Chen, D. Research on traffic flow prediction in the big data environment based on the improved RBF neural network. IEEE Trans. Ind. Inform. 2017, 13, 2000–2008. [Google Scholar] [CrossRef]
- Broomhead, D.S.; Lowe, D. Radial Basis Functions, Multi-Variable Functional Interpolation and Adaptive Networks; Royal Signals and Radar Establishment: Malvern, UK, 1988. [Google Scholar]
- Ganapathi, A.; Kuno, H.; Dayal, U.; Wiener, J.L.; Fox, A.; Jordan, M.; Patterson, D. Predicting Multiple Metrics for Queries: Better Decisions Enabled by Machine Learning. In Proceedings of the 2009 IEEE 25th International Conference on Data Engineering, Shanghai, China, 29 March–2 April 2009; pp. 592–603. [Google Scholar]
- Loh, W.Y. Classification and regression trees. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2011, 1, 14–23. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Aha, D.W.; Kibler, D.; Albert, M.K. Instance-based learning algorithms. Mach. Learn. 1991, 6, 37–66. [Google Scholar] [CrossRef]
- Shevade, S.K.; Keerthi, S.S.; Bhattacharyya, C. Improvements to the SMO algorithm for SVM regression. IEEE Trans. Neural Netw. 2000, 11, 1188–1193. [Google Scholar] [CrossRef] [PubMed]
- Negi, P.; Marcus, R.; Mao, H. Cost-Guided Cardinality Estimation: Focus Where it Matters. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering Workshops (ICDEW), Dallas, TX, USA, 20–24 April 2020. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Operators | Type | Specification |
|---|---|---|
| AllNodeScan | Leaf | Scans all nodes from the node store |
| NodeByLabelScan | Leaf | Utilizes the built-in index on node labels |
| NodeByIndexScan | Leaf | Scans all nodes in a user-defined index |
| NodeByIndexSeek | Leaf | Finds nodes using a user-defined index |
| Expand (All) | None | Traverses all relationships from a given node |
| CreateUniqueConstraint | Leaf, Updating | Creates a unique constraint on a property for all nodes having a certain label |
| NodeHashJoin | Eager | Combines two independent results based on an overlapping set of nodes |
| CartesianProduct | None | Combines two independent results without any overlapping components |
| Operations | Type | Specification |
|---|---|---|
| N1 | Node pattern Node pattern with label | (a) (a: A) |
| N2 | Edge pattern Edge pattern with relationship type Edge pattern with node label and relationship type | (a)-[r]-(b) (a)-[r: R]-(b) (a: A)-[r: R]-(b: B) |
| N3 | Path pattern Variable-length pattern with lower bound Variable-length pattern with upper bound Variable-length pattern with lower and upper bound Variable-length pattern with any length | (a)-[r1]-(b)-[r2]-(c) e.g., (a)-[∗1..]-(b) e.g., (a)-[∗..2]-(b) e.g., (a)-[∗1..2]-(b) (a)-[*]-(b) |
| N4 | Cycle pattern | (a)-[r1]-(a) (a)-[r1]-(b)-[r2]-(a) (a)-[r1]-(b)-[r2]-(c)-[r3]-(a) |
| Software | Version |
|---|---|
| Neo4j | neo4j-enterprise-3.5.0 |
| JDK | jdk1.8.0_151 |
| Prometheus Node | prometheus-2.22.1 |
| Exporter Node | exporter-1.0.1 |
| Grafana | grafana_7.3.1 |
| OS | Ubuntu16 |
| Datasets | Benchmark | LR | SVR | RT | FCNN | RBF |
|---|---|---|---|---|---|---|
| Northwind | N1 | 2.28 | 2.49 | 2.22 | 2.53 | 1.93 |
| N2 | 15.96 | 15.53 | 15 | 15.88 | 13.92 | |
| N3 | 15.25 | 18.61 | 13.89 | 15.21 | 13.99 | |
| N4 | 18.87 | 15.24 | 10.64 | 13.87 | 10.68 | |
| FIFA2021 | N1 | 6.26 | 6.75 | 6.06 | 6.01 | 5.95 |
| N2 | 16.52 | 6.6 | 6.44 | 7.23 | 6.23 | |
| N3 | 11.04 | 9.39 | 9.38 | 15.02 | 8.84 | |
| N4 | 7.56 | 7.07 | 7.18 | 10.16 | 5.09 | |
| CORD-19 | N1 | 7.70 | 8.14 | 8.17 | 11.46 | 6.87 |
| N2 | 5.18 | 5.04 | 5.01 | 5.98 | 5.0 | |
| N3 | 7.04 | 6.89 | 6.90 | 7.24 | 6.78 | |
| N4 | 13.06 | 12.56 | 12.54 | 16.86 | 12.23 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, Z.; Yu, J.; Guo, B. Execution Time Prediction for Cypher Queries in the Neo4j Database Using a Learning Approach. Symmetry 2022, 14, 55. https://doi.org/10.3390/sym14010055
He Z, Yu J, Guo B. Execution Time Prediction for Cypher Queries in the Neo4j Database Using a Learning Approach. Symmetry. 2022; 14(1):55. https://doi.org/10.3390/sym14010055
Chicago/Turabian StyleHe, Zhenzhen, Jiong Yu, and Binglei Guo. 2022. "Execution Time Prediction for Cypher Queries in the Neo4j Database Using a Learning Approach" Symmetry 14, no. 1: 55. https://doi.org/10.3390/sym14010055
APA StyleHe, Z., Yu, J., & Guo, B. (2022). Execution Time Prediction for Cypher Queries in the Neo4j Database Using a Learning Approach. Symmetry, 14(1), 55. https://doi.org/10.3390/sym14010055