
Evolving Hybrid Cascade Neural Network Genetic Algorithm Space–Time Forecasting

 ,
,  ,
,  ,
,  ,
,  ,
, 
Abstract
:1. Introduction
2. Methods
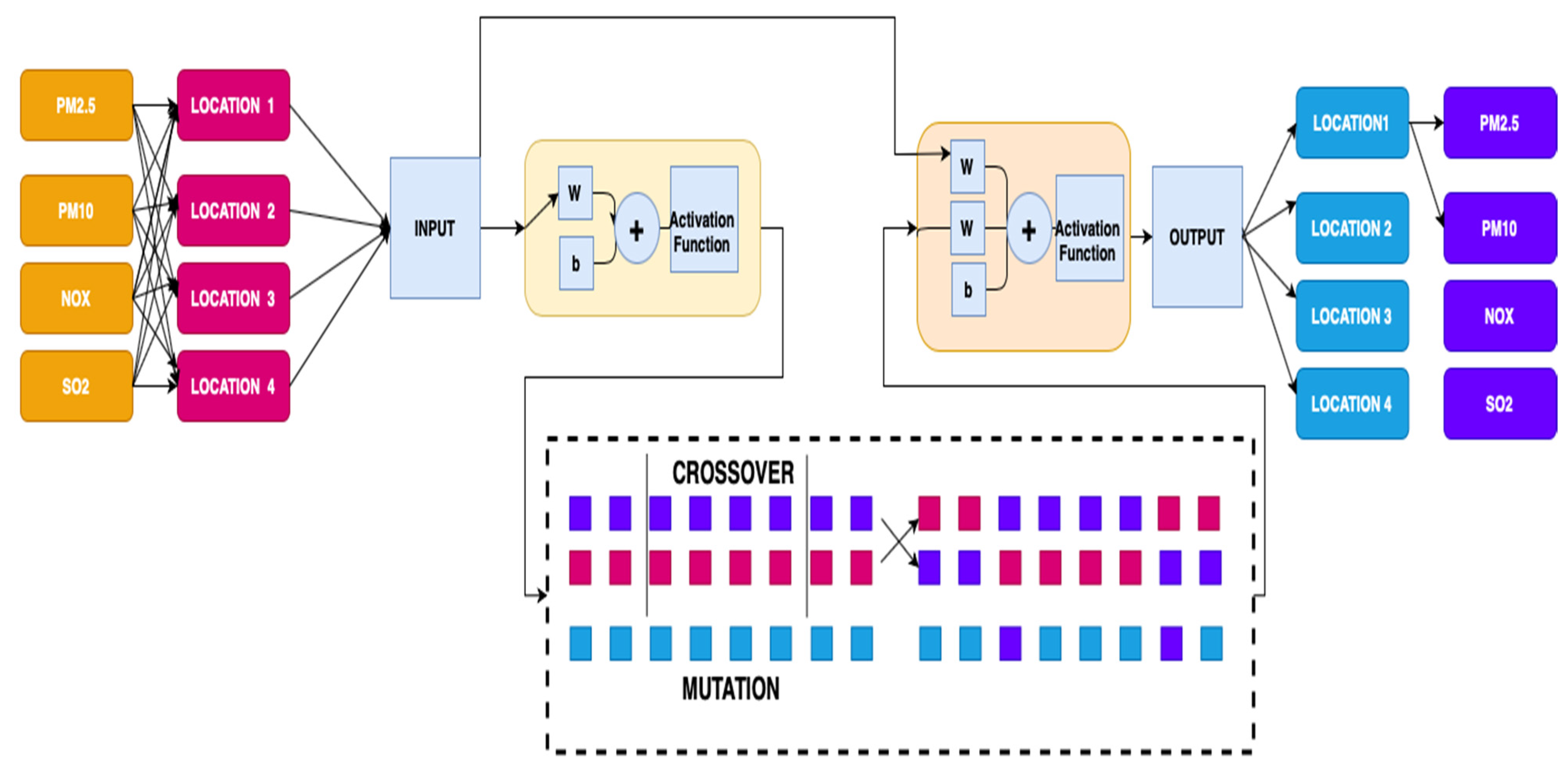
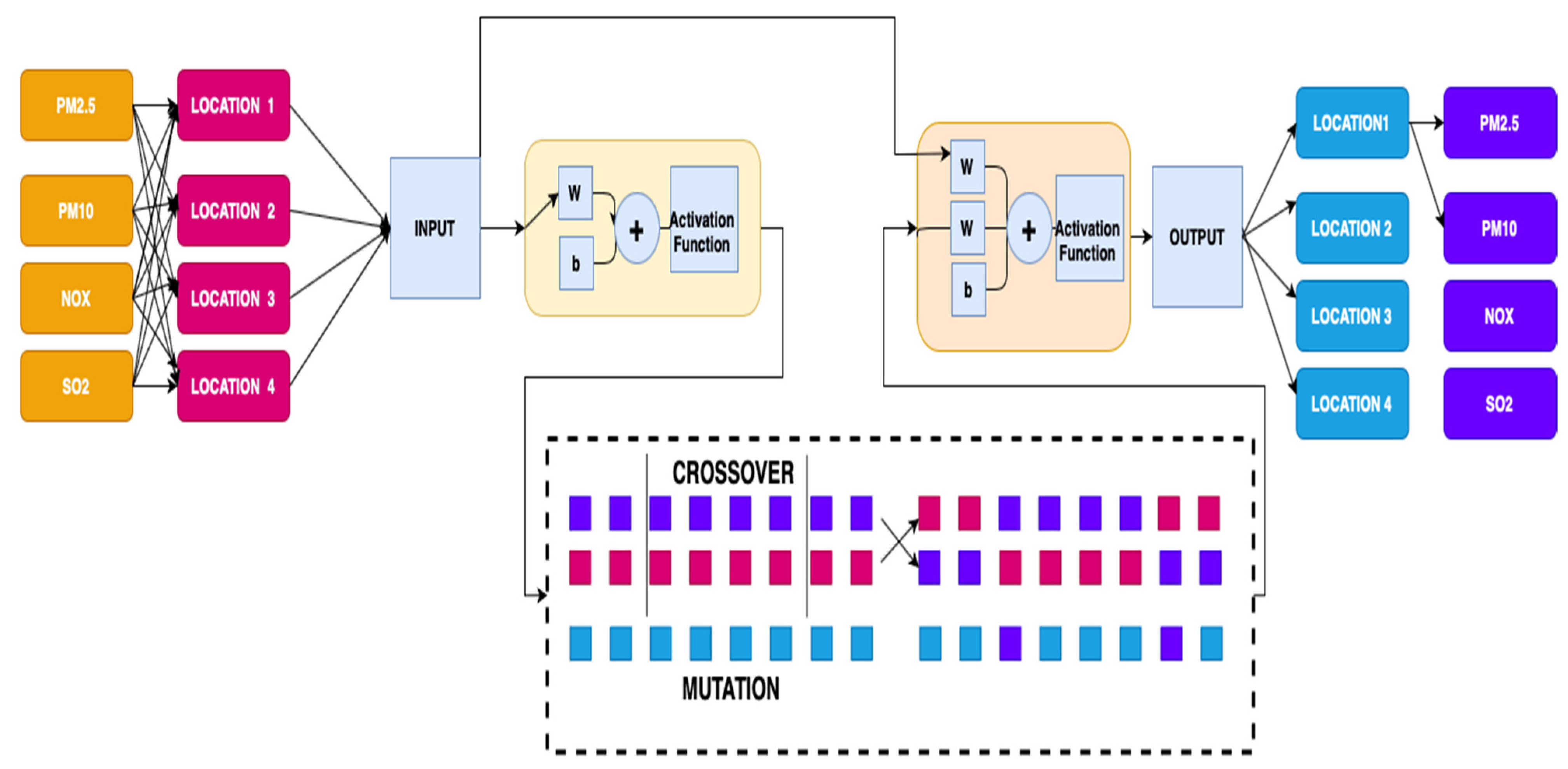
2.1. Cascade Neural Network
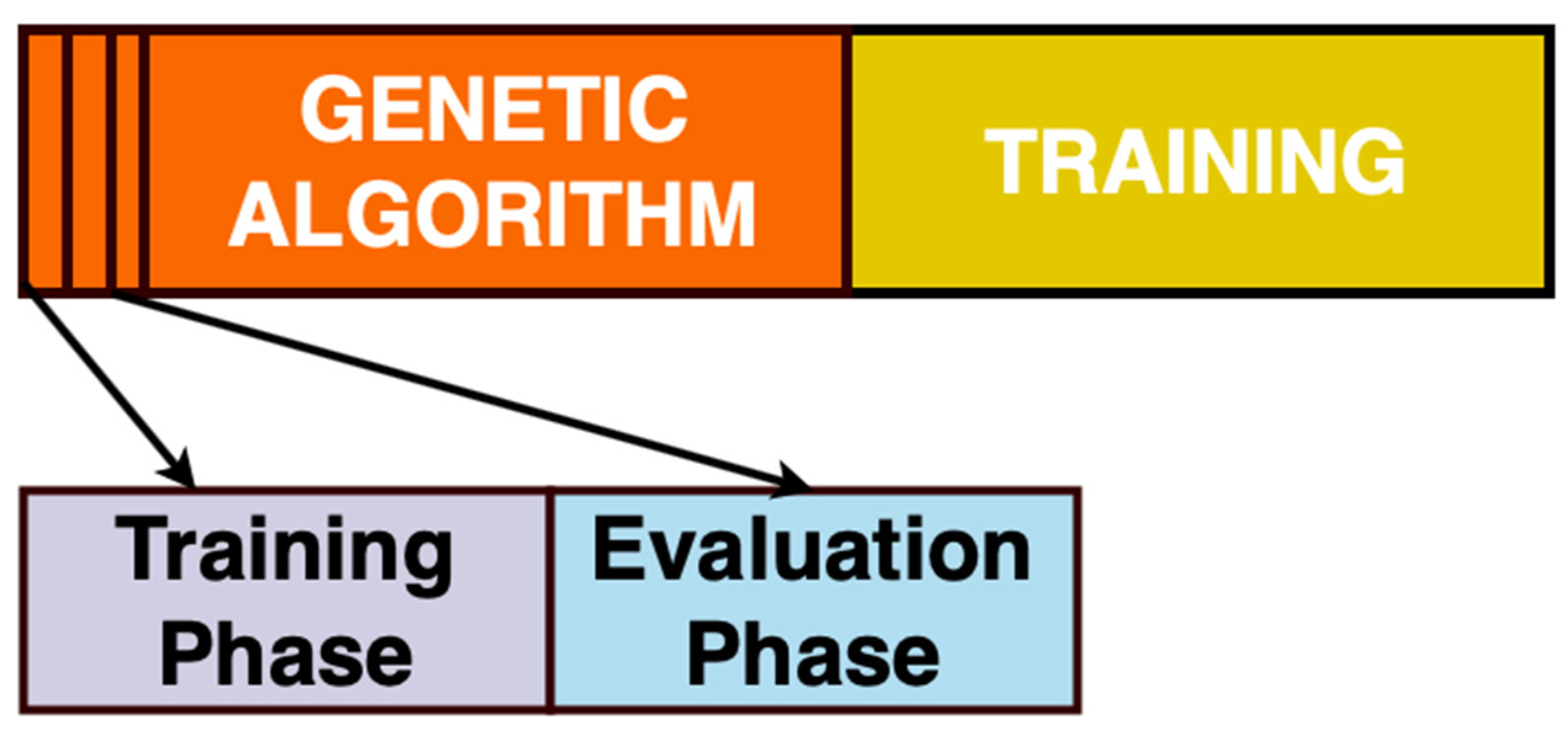
2.2. Genetic Algorithm
| Algorithm 1. Scheme of the GA | |
| 1: | INITIALIZE population and EVALUATE |
| 2: | while termination condition is not satisfied do |
| 3: | SELECT parents |
| 4: | CROSSOVER pairs of parents |
| 5: | MUTATE the resulting offspring |
| 6: | EVALUATE new candidates |
| 7: | REPLACE individuals for the next generation |
| 8: | end while |
2.3. Cascade Neural Network Genetic Algorithm
| Algorithm 2. Function Cascade Neural Network | |
| 1: | input |
| 2: | setk = 0 |
| 3: | calculate Cascade Weighted |
| 4: | k = 0; for i = 1:nh for j = 1:m k = k + 1; Wi1(i,j) = W(k); end end |
| 5: | calculate weighted input and output |
| 6: | fori = 1:o for j = 1:m k = k + 1; Wi2(i,j) = W(k); end end |
| 7: | calculate weighted Bias Input |
| 8: | fori = 1:nh k = k + 1; Wbi(i,1) = W(k); end |
| 9: | calculate weighted output |
| 10: | fori = 1:o for j = 1:nh k = k + 1; Wo(i,j) = W(k); end end |
| 11: | calculate weighted Bias Output |
| 12: | fori = 1:o k = k + 1; Wbo(i,1) = W(k); end |
3. Simulation and Results
3.1. Construction of VAR-Cascade
3.2. Study Area
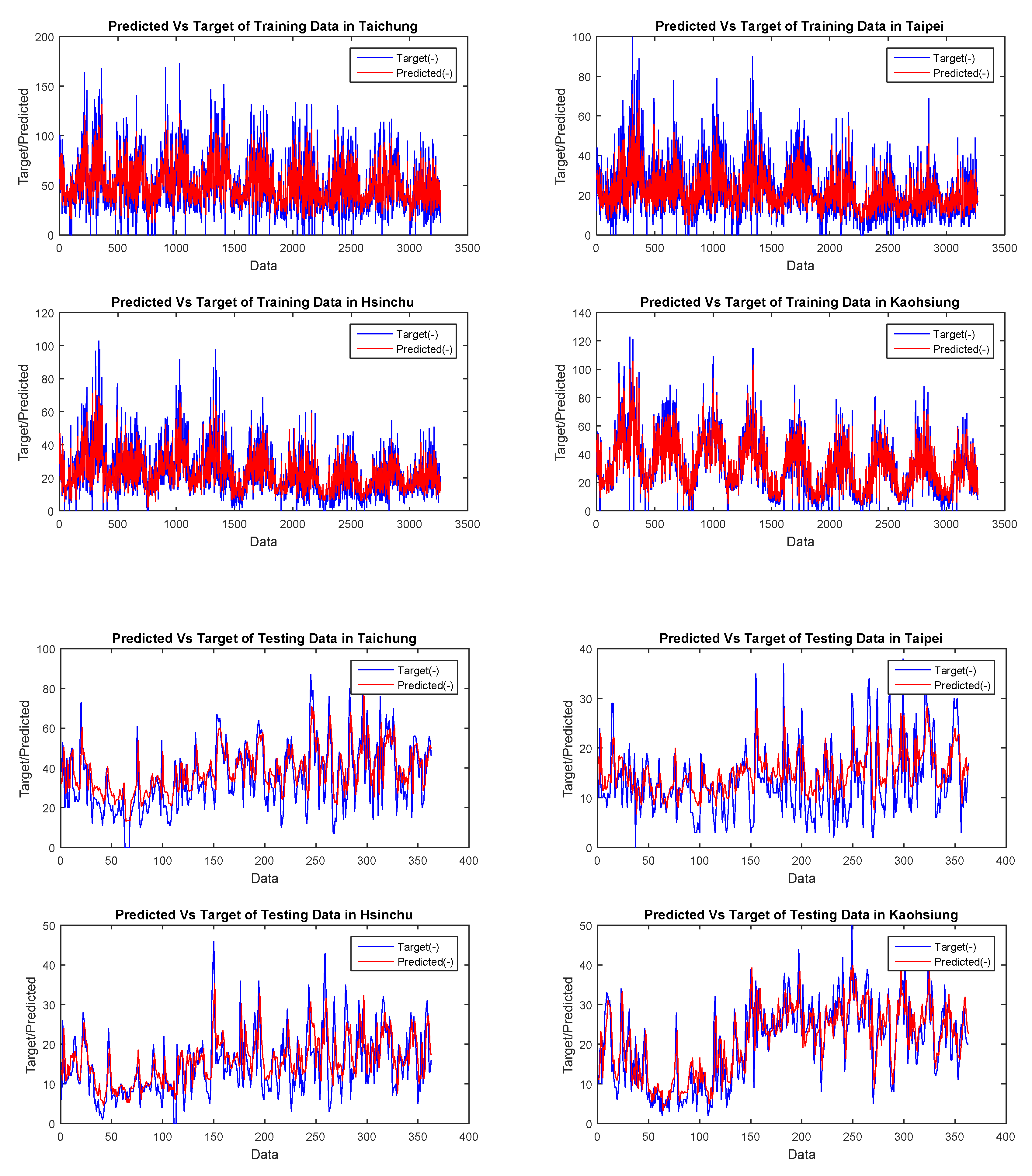
3.3. Air Pollution Forecasting Using VAR-Cascade-GA
3.4. Does the Activation Function Provide High Accuracy and Speed Up the Time Lapse?
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
References
- Querol, X.; Alastuey, A.; Ruiz, C.R.; Artiñano, B.; Hansson, H.C.; Harrison, R.M.; Buringh, E.; Ten Brink, H.M.; Lutz, M.; Bruckmann, P.; et al. Speciation and origin of PM10 and PM2.5 in selected European cities. Atmos. Environ. 2004, 38, 6547–6555. [Google Scholar] [CrossRef]
- Fan, J.; Wu, L.; Ma, X.; Zhou, H.; Zhang, F. Hybrid support vector machines with heuristic algorithms for prediction of daily diffuse solar radiation in air-polluted regions. Renew. Energy 2020, 145, 2034–2045. [Google Scholar] [CrossRef]
- Masseran, N.; Safari, M.A.M. Intensity–duration–frequency approach for risk assessment of air pollution events. J. Environ. Manag. 2020, 264, 110429. [Google Scholar] [CrossRef] [PubMed]
- Masseran, N.; Safari, M.A.M. Modeling the transition behaviors of PM 10 pollution index. Environ. Monit. Assess. 2020, 192, 441. [Google Scholar] [CrossRef] [PubMed]
- De Vito, S.; Piga, M.; Martinotto, L.; Di Francia, G. CO, NO2 and NOx urban pollution monitoring with on-field calibrated electronic nose by automatic bayesian regularization. Sens. Actuators B Chem. 2009, 143, 182–191. [Google Scholar] [CrossRef]
- Winarso, K.; Yasin, H. Modeling of air pollutants SO2 elements using geographically weighted regression (GWR), geographically temporal weighted regression (GTWR) and mixed geographically temporalweighted regression (MGTWR). ARPN J. Eng. Appl. Sci. 2016, 11, 8080–8084. [Google Scholar]
- Zhang, J.J.; Wei, Y.; Fang, Z. Ozone pollution: A major health hazard worldwide. Front. Immunol. 2019, 10, 2518. [Google Scholar] [CrossRef] [Green Version]
- Bernstein, J.A.; Alexis, N.; Barnes, C.; Bernstein, I.L.; Bernstein, J.A.; Nel, A.; Peden, D.; Diaz-Sanchez, D.; Tarlo, S.M.; Williams, P.B. Health effects of air pollution. J. Allergy Clin. Immunol. 2004, 114, 1116–1123. [Google Scholar] [CrossRef]
- Xing, Y.F.; Xu, Y.H.; Shi, M.H.; Lian, Y.X. The impact of PM2.5 on the human respiratory system. J. Thorac. Dis. 2016, 8, E69–E74. [Google Scholar]
- Rossati, A. Global warming and its health impact. Int. J. Occup. Environ. Med. 2017, 8, 7–20. [Google Scholar] [CrossRef] [Green Version]
- Suhartono, S.; Subanar, S. Development of model building procedures in wavelet neural networks for forecasting non-stationary time series. Eur. J. Sci. Res. 2009, 34, 416–427. [Google Scholar]
- Suhermi, N.; Suhartono; Prastyo, D.D.; Ali, B. Roll motion prediction using a hybrid deep learning and ARIMA model. Procedia Comput. Sci. 2018, 144, 251–258. [Google Scholar] [CrossRef]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Chen, R.C.; Dewi, C.; Huang, S.W.; Caraka, R.E. Selecting critical features for data classification based on machine learning methods. J. Big Data 2020, 7, 52. [Google Scholar] [CrossRef]
- Caraka, R.E.; Lee, Y.; Chen, R.C.; Toharudin, T. Using Hierarchical Likelihood towards Support Vector Machine: Theory and Its Application. IEEE Access 2020, 8, 194795–194807. [Google Scholar] [CrossRef]
- Mueller, J.-A.; Lemke, F. Self-Organising Data Mining: An Intelligent Approach to Extract Knowledge from Data. 1999. Available online: https://www.knowledgeminer.eu/pdf/sodm.pdf (accessed on 6 May 2021).
- De Gooijer, J.G.; Hyndman, R.J. 25 years of time series forecasting. Int. J. Forecast. 2006, 22, 443–473. [Google Scholar] [CrossRef] [Green Version]
- Kaimian, H.; Li, Q.; Wu, C.; Qi, Y.; Mo, Y.; Chen, G.; Zhang, X.; Sachdeva, S. Evaluation of different machine learning approaches to forecasting PM2.5 mass concentrations. Aerosol Air Qual. Res. 2019, 19, 1400–1410. [Google Scholar] [CrossRef] [Green Version]
- Guo, Y.; Liu, Y.; Oerlemans, A.; Lao, S.; Wu, S.; Lew, M.S. Deep learning for visual understanding: A review. Neurocomputing 2016, 187, 27–48. [Google Scholar] [CrossRef]
- Szandała, T. Review and comparison of commonly used activation functions for deep neural networks. arXiv 2020. Available online: https://arxiv.org/abs/2010.09458 (accessed on 6 May 2021).
- Sony, S.; Dunphy, K.; Sadhu, A.; Capretz, M. A systematic review of convolutional neural network-based structural condition assessment techniques. Eng. Struct. 2021, 226, 111347. [Google Scholar] [CrossRef]
- Caraka, R.E.; Chen, R.C.; Yasin, H.; Pardamean, B.; Toharudin, T.; Wu, S.H. Prediction of Status Particulate Matter 2.5 using State Markov Chain Stochastic Process and HYBRID VAR-NN-PSO. IEEE Access 2019, 7, 161654–161665. [Google Scholar] [CrossRef]
- Kuster, C.; Rezgui, Y.; Mourshed, M. Electrical load forecasting models: A critical systematic review. Sustain. Cities Soc. 2017, 35, 257–270. [Google Scholar] [CrossRef]
- Cios, K.J.; Pedrycz, W.; Swiniarski, R.W.; Kurgan, L.A. Data Mining: A Knowledge Discovery Approach; Springer: Boston, MA, USA, 2007; ISBN 9780387333335. [Google Scholar]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. The M4 Competition: 100,000 time series and 61 forecasting methods. Int. J. Forecast. 2020, 36, 54–74. [Google Scholar] [CrossRef]
- Makridakis, S.G.; Wheelwright, S.C.; Hyndman, R.J. Forecasting: Methods and Applications. J. Forecast. 1998, 1–656. [Google Scholar] [CrossRef]
- Wong, K.W.; Wong, P.M.; Gedeon, T.D.; Fung, C.C. Rainfall prediction model using soft computing technique. Soft Comput. 2003, 7, 434–438. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Mislan, M.; Haviluddin, H.; Hardwinarto, S.; Sumaryono, S.; Aipassa, M. Rainfall Monthly Prediction Based on Artificial Neural Network: A Case Study in Tenggarong Station, East Kalimantan—Indonesia. Procedia Comput. Sci. 2015, 59, 142–151. [Google Scholar] [CrossRef] [Green Version]
- Darwin, C. The Correspondence of Charles Darwin: 1821–1860; Cambridge University Press: Cambridge, UK, 2002. [Google Scholar]
- Pfeiffer, J.R. Evolutionary theory. In George Bernard Shaw in Context; Cambridge University Press: Cambridge, UK, 2015; ISBN 9781107239081. [Google Scholar]
- Wuketits, F.M. Charles darwin and modern moral philosophy. Ludus Vitalis 2009, 17, 395–404. [Google Scholar]
- García-Martínez, C.; Rodriguez, F.J.; Lozano, M. Genetic algorithms. In Handbook of Heuristics; Springer: Cham, Switzerland, 2018; ISBN 9783319071244. Available online: https://www.springer.com/gp/book/9783319071237 (accessed on 6 May 2021).
- Sivanandam, S.; Deepa, S. Introduction to Genetic Algorithms; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Gupta, J.N.D.; Sexton, R.S. Comparing backpropagation with a genetic algorithm for neural network training. Omega 1999, 27, 679–684. [Google Scholar] [CrossRef]
- Caraka, R.E.; Chen, R.C.; Yasin, H.; Lee, Y.; Pardamean, B. Hybrid Vector Autoregression Feedforward Neural Network with Genetic Algorithm Model for Forecasting Space-Time Pollution Data. Indones. J. Sci. Technol. 2021, 6, 243–266. [Google Scholar]
- Kubat, M.; Kubat, M. The Genetic Algorithm. In An Introduction to Machine Learning; Springer International Publishing: Cham, Switzerland, 2017. [Google Scholar]
- Moscato, P.; Cotta, C. A Modern Introduction to Memetic Algorithms. In Handbook of Metaheuristics; Springer: Boston, MA, USA, 2010; pp. 141–183. Available online: https://link.springer.com/chapter/10.1007/978-1-4419-1665-5_6 (accessed on 6 May 2021).
- Makridakis, S.; Wheelwright, S.C. Forecasting Methods for Management. Oper. Res. Q. 1974, 25, 648–649. [Google Scholar] [CrossRef]
- Makridakis, S. A Survey of Time Series. Int. Stat. Rev. Rev. Int. Stat. 1976, 44, 29. [Google Scholar] [CrossRef]
- Warsito, B.; Santoso, R.; Suparti; Yasin, H. Cascade Forward Neural Network for Time Series Prediction. J. Phys. Conf. Ser. 2018, 1025, 012097. [Google Scholar] [CrossRef]
- Schetinin, V. A learning algorithm for evolving cascade neural networks. Neural Process. Lett. 2003, 17, 21–31. [Google Scholar] [CrossRef]
- Ding, S.; Zhao, H.; Zhang, Y.; Xu, X.; Nie, R. Extreme learning machine: Algorithm, theory and applications. Artif. Intell. Rev. 2015, 44, 103–115. [Google Scholar] [CrossRef]
- Suhartono; Prastyo, D.D.; Kuswanto, H.; Lee, M.H. Comparison between VAR, GSTAR, FFNN-VAR and FFNN-GSTAR Models for Forecasting Oil Production Methods. Mat. Malays. J. Ind. Appl. Math. 2018, 34, 103–111. [Google Scholar]
- Prastyo, D.D.; Nabila, F.S.; Lee, M.H.S.; Suhermi, N.; Fam, S.F. VAR and GSTAR-based feature selection in support vector regression for multivariate spatio-temporal forecasting. In Communications in Computer and Information Science; Springer: Singapore, 2018; pp. 46–57. [Google Scholar]
- Zhang, P.G. Time series forecasting using a hybrid ARIMA and neural network model. Neurocomputing 2003, 50, 159–175. [Google Scholar] [CrossRef]
- Geurts, M.; Box, G.E.P.; Jenkins, G.M. Time Series Analysis: Forecasting and Control. J. Mark. Res. 2006. [Google Scholar] [CrossRef]
- McLeod, A.I.; Yu, H.; Mahdi, E. Time Series Analysis with R. Handb. Stat. 2011, 30, 661–672. [Google Scholar] [CrossRef]
- Liao, W.T. Clustering of time series data—A survey. Pattern Recognit. 2005, 38, 1857–1874. [Google Scholar] [CrossRef]
- Subba Rao, T. Time Series Analysis. J. Time Ser. Anal. 2010, 31, 139. [Google Scholar] [CrossRef]
- Mudelsee, M. Climate Time Series Analysis: Regression; Springer: Dordrecht, The Netherlands, 2010; Volume 42, ISBN 978-90-481-9481-0. [Google Scholar]
- Zhu, X.; Pan, R.; Li, G.; Liu, Y.; Wang, H. Network vector autoregression. Ann. Stat. 2017, 45, 1096–1123. [Google Scholar] [CrossRef] [Green Version]
- Nourani, V.; Baghanam, A.H.; Adamowski, J.; Gebremichael, M. Using self-organizing maps and wavelet transforms for space-time pre-processing of satellite precipitation and runoff data in neural network based rainfall-runoff modeling. J. Hydrol. 2013, 476, 228–243. [Google Scholar] [CrossRef]
- Ippoliti, L.; Valentini, P.; Gamerman, D. Space-time modelling of coupled spatiotemporal environmental variables. J. R. Stat. Soc. Ser. C Appl. Stat. 2012. [Google Scholar] [CrossRef]
- Sharma, S.; Sharma, S. Understanding Activation Functions in Neural Networks. Int. J. Eng. Appl. Sci. Technol. 2017, 4, 310–316. [Google Scholar]
- Apicella, A.; Donnarumma, F.; Isgrò, F.; Prevete, R. A survey on modern trainable activation functions. Neural Netw. 2021, 138, 14–32. [Google Scholar] [CrossRef]
- Al-Rikabi, H.M.H.; Al-Ja’afari, M.A.M.; Ali, A.H.; Abdulwahed, S.H. Generic model implementation of deep neural network activation functions using GWO-optimized SCPWL model on FPGA. Microprocess. Microsyst. 2020, 77, 103141. [Google Scholar] [CrossRef]
- Boob, D.; Dey, S.S.; Lan, G. Complexity of training ReLU neural network. Discret. Optim. 2020, 100620. [Google Scholar] [CrossRef]
- Liu, B. Understanding the loss landscape of one-hidden-layer ReLU networks. Knowl. Based Syst. 2021, 220, 106923. [Google Scholar] [CrossRef]
- Bouwmans, T.; Javed, S.; Sultana, M.; Jung, S.K. Deep neural network concepts for background subtraction: A systematic review and comparative evaluation. Neural Netw. 2019, 117, 8–66. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
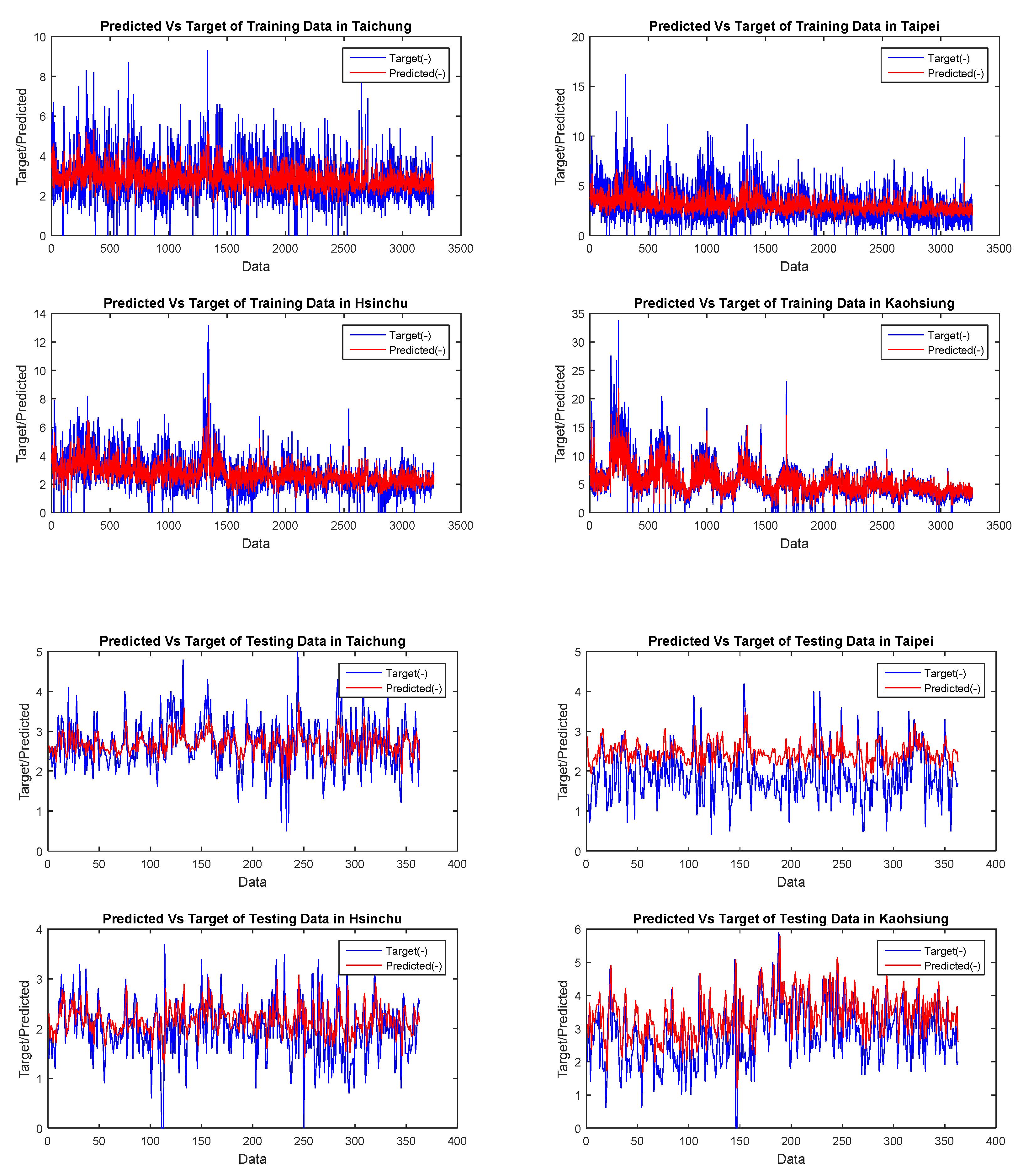{kind=link}
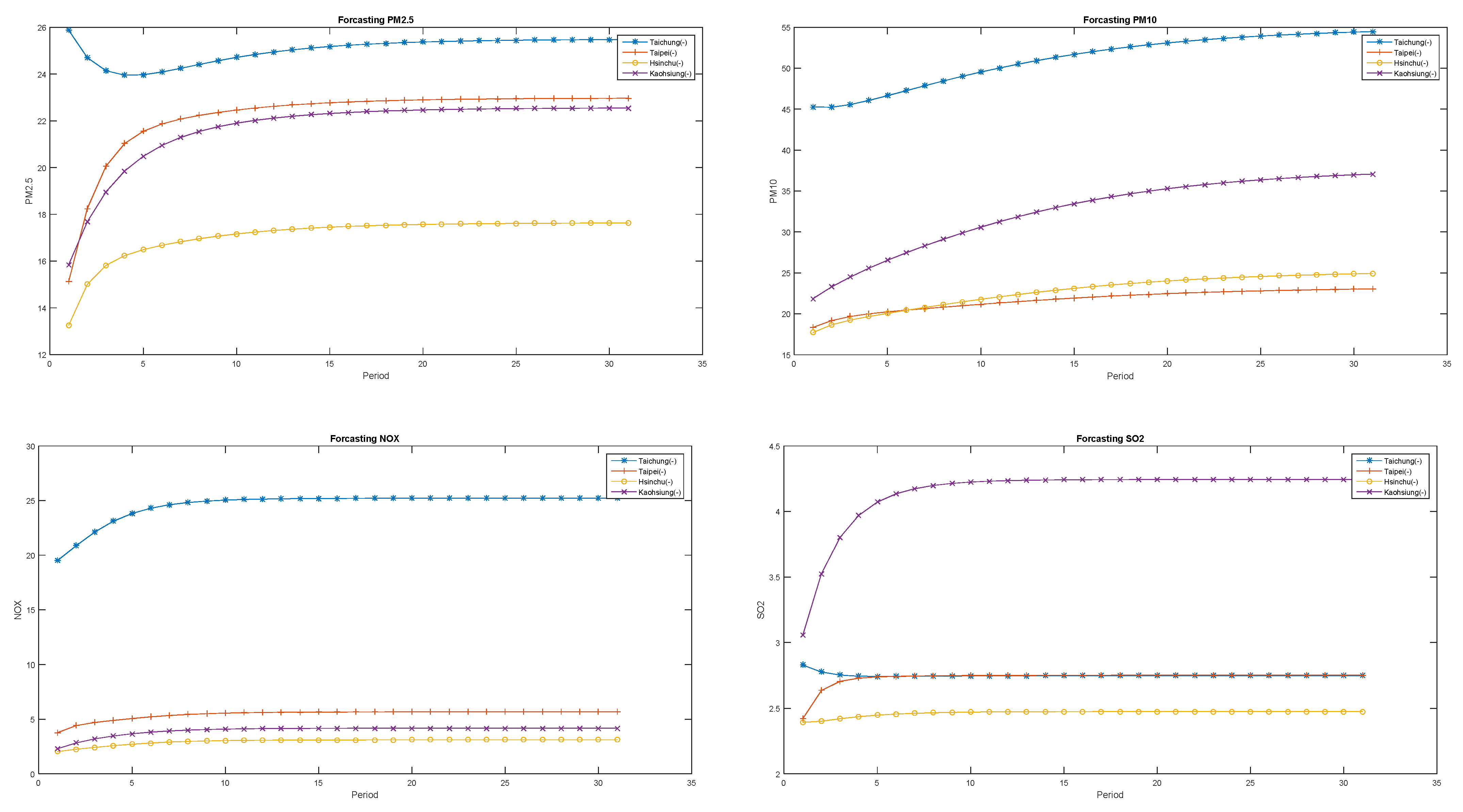{kind=link}
| Pollution | Location | N | Mean | SE Mean | StDev | Variance | Minimum | Q1 | Median | Q3 | Maximum | Range |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PM10 | TAICHUNG | 3632 | 50.642 | 0.419 | 24.949 | 622.476 | 5 | 32 | 45.5 | 65 | 173 | 168 |
| TAIPEI | 3632 | 21.244 | 0.208 | 12.412 | 154.052 | 1 | 12 | 19 | 27 | 100 | 99 | |
| HSINCHU | 3632 | 22.46 | 0.219 | 13.135 | 172.521 | 1 | 13 | 19 | 29 | 103 | 102 | |
| KAOHSIUNG | 3632 | 31.719 | 0.31 | 18.477 | 341.414 | 1 | 17 | 29 | 44 | 123 | 122 | |
| SO2 | TAICHUNG | 3632 | 2.8706 | 0.017 | 1.0208 | 1.042 | 0 | 2.2 | 2.7 | 3.4 | 9.3 | 9.3 |
| TAIPEI | 3632 | 2.9835 | 0.0263 | 1.5742 | 2.4781 | 0.4 | 1.9 | 2.6 | 3.7 | 16.2 | 15.8 | |
| HSINCHU | 3632 | 2.6778 | 0.0186 | 1.1125 | 1.2377 | 0.1 | 1.9 | 2.5 | 3.2 | 13.2 | 13.1 | |
| KAOHSIUNG | 3632 | 5.3129 | 0.0515 | 3.0833 | 9.5066 | 0 | 3.3 | 4.5 | 6.4 | 33.8 | 33.8 | |
| PM2.5 | TAICHUNG | 3632 | 26.623 | 0.264 | 15.66 | 245.244 | 1 | 15 | 23 | 35 | 106 | 105 |
| TAIPEI | 3632 | 23.635 | 0.203 | 12.161 | 147.892 | 3.97 | 15.107 | 20.84 | 29.023 | 109.83 | 105.86 | |
| HSINCHU | 3632 | 18.179 | 0.13 | 7.763 | 60.265 | 0.63 | 13.04 | 16.34 | 21.102 | 76.72 | 76.09 | |
| KAOHSIUNG | 3632 | 23.854 | 0.163 | 9.747 | 95.014 | 5.27 | 16.49 | 21.495 | 29.697 | 68.96 | 63.69 | |
| NOX | TAICHUNG | 3632 | 22.944 | 0.171 | 10.26 | 105.269 | 4.35 | 15.23 | 20.57 | 28.63 | 81.43 | 77.08 |
| TAIPEI | 3632 | 6.196 | 0.106 | 6.315 | 39.874 | 0.09 | 1.85 | 4.15 | 8.28 | 65.14 | 65.05 | |
| HSINCHU | 3632 | 3.2786 | 0.0546 | 3.2643 | 10.6559 | 0 | 1.52 | 2.3 | 3.79 | 45.65 | 45.65 |
| Pollution | Portion | Training | Testing | Average | Elapsed Time | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | SMAPE | RMSE | MAE | SMAPE | RMSE | MAE | SMAPE | |||
| PM2.5 | 50:50 | 9.84 | 6.89 | 3.91 | 7.89 | 5.70 | 3.83 | 8.87 | 6.30 | 3.87 | 76.42 |
| PM10 | 13.53 | 9.57 | 3.84 | 11.37 | 8.05 | 3.86 | 12.45 | 8.81 | 3.85 | 71.86 | |
| NOX | 5.53 | 3.55 | 6.94 | 4.37 | 2.73 | 6.95 | 4.95 | 3.14 | 6.95 | 74.23 | |
| SO2 | 1.72 | 1.18 | 3.60 | 1.15 | 0.80 | 3.61 | 1.44 | 0.99 | 3.61 | 75.51 | |
| PM2.5 | 60:40 | 9.86 | 6.88 | 3.89 | 7.41 | 5.42 | 3.57 | 8.63 | 6.15 | 3.73 | 76.56 |
| PM10 | 13.49 | 9.54 | 3.76 | 10.67 | 7.57 | 3.56 | 12.08 | 8.55 | 3.66 | 75.24 | |
| NOX | 6.48 | 3.48 | 6.93 | 4.10 | 2.65 | 6.24 | 5.29 | 3.06 | 6.59 | 73.15 | |
| SO2 | 1.65 | 1.13 | 3.48 | 1.07 | 0.80 | 3.43 | 1.36 | 0.97 | 3.46 | 76.13 | |
| PM2.5 | 70:30 | 9.43 | 6.62 | 3.83 | 7.13 | 5.27 | 3.50 | 8.28 | 5.95 | 3.67 | 71.13 |
| PM10 | 13.30 | 9.29 | 3.74 | 10.09 | 7.13 | 3.74 | 11.70 | 8.21 | 3.74 | 77.87 | |
| NOX | 5.31 | 3.36 | 6.98 | 4.01 | 2.54 | 7.12 | 4.66 | 2.95 | 7.05 | 74.41 | |
| SO2 | 1.60 | 1.09 | 3.36 | 1.00 | 0.77 | 3.41 | 1.30 | 0.93 | 3.38 | 80.90 | |
| PM2.5 | 80:20 | 9.25 | 6.46 | 3.81 | 6.83 | 4.99 | 3.50 | 8.04 | 5.73 | 3.65 | 74.25 |
| PM10 | 13.10 | 9.07 | 3.74 | 9.19 | 6.56 | 4.13 | 11.14 | 7.82 | 3.93 | 74.25 | |
| NOX | 5.25 | 3.29 | 7.11 | 3.79 | 2.49 | 6.68 | 4.52 | 2.89 | 6.90 | 72.37 | |
| SO2 | 1.54 | 1.05 | 3.42 | 0.92 | 0.70 | 3.36 | 1.23 | 0.88 | 3.39 | 80.24 | |
| PM2.5 | 90:10 * | 9.03 | 6.34 | 3.77 | 6.78 | 4.94 | 3.47 | 7.90 | 5.64 | 3.62 | 83.83 |
| PM10 | 12.77 | 8.85 | 3.77 | 8.02 | 5.93 | 4.09 | 10.40 | 7.39 | 3.93 | 75.00 | |
| NOX | 5.11 | 3.20 | 6.90 | 3.70 | 2.43 | 6.53 | 4.40 | 2.81 | 6.72 | 80.47 | |
| SO2 | 1.48 | 1.10 | 3.37 | 0.80 | 0.62 | 2.77 | 1.14 | 0.86 | 3.07 | 71.71 | |
| Pollution | Activation Function | Training | Testing | Average | Elapsed Time | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | SMAPE | RMSE | MAE | SMAPE | RMSE | MAE | SMAPE | |||
| PM2.5 | logsig | 9.02 | 6.30 | 3.77 | 6.77 | 4.94 | 3.54 | 7.90 | 5.62 | 3.66 | 78.03 |
| PM10 | 12.79 | 8.86 | 3.71 | 8.12 | 6.02 | 4.05 | 10.46 | 7.44 | 3.88 | 75.48 | |
| NOX | 5.04 | 3.15 | 6.84 | 3.79 | 2.43 | 6.62 | 4.42 | 2.79 | 6.73 | 72.43 | |
| SO2 | 1.48 | 1.01 | 3.35 | 0.82 | 0.63 | 3.00 | 1.15 | 0.82 | 3.18 | 76.59 | |
| PM2.5 | radbas | 9.06 | 6.37 | 3.80 | 6.80 | 5.00 | 3.51 | 7.93 | 5.69 | 3.66 | 80.97 |
| PM10 | 12.79 | 8.85 | 3.79 | 8.11 | 6.03 | 4.19 | 10.45 | 7.44 | 3.99 | 74.77 | |
| NOX | 5.09 | 3.16 | 6.83 | 3.75 | 2.40 | 6.19 | 4.42 | 2.78 | 6.51 | 82.35 | |
| SO2 | 1.49 | 1.01 | 3.36 | 0.83 | 0.64 | 2.93 | 1.16 | 0.83 | 3.15 | 73.33 | |
| PM2.5 | SoftMax | 9.07 | 6.35 | 3.78 | 6.70 | 4.91 | 3.46 | 7.89 | 5.63 | 3.62 | 75.47 |
| PM10 | 12.81 | 8.90 | 3.75 | 8.13 | 6.04 | 4.24 | 10.47 | 7.47 | 3.99 | 74.70 | |
| NOX | 5.11 | 3.19 | 7.12 | 3.64 | 2.35 | 6.23 | 4.38 | 2.77 | 6.67 | 72.11 | |
| SO2 | 1.48 | 1.01 | 3.42 | 0.84 | 0.66 | 3.12 | 1.16 | 0.84 | 3.27 | 77.53 | |
| PM2.5 | tribas | 9.03 | 6.34 | 3.80 | 6.81 | 4.97 | 3.52 | 7.92 | 5.66 | 3.66 | 93.20 |
| PM10 | 12.81 | 8.90 | 3.75 | 8.13 | 6.04 | 4.24 | 10.47 | 7.47 | 3.99 | 74.70 | |
| NOX | 5.13 | 3.21 | 6.98 | 3.68 | 2.37 | 6.53 | 4.41 | 2.79 | 6.75 | 72.29 | |
| SO2 | 1.49 | 1.01 | 3.36 | 0.84 | 0.65 | 2.94 | 1.16 | 0.83 | 3.15 | 80.35 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Caraka, R.E.; Yasin, H.; Chen, R.-C.; Goldameir, N.E.; Supatmanto, B.D.; Toharudin, T.; Basyuni, M.; Gio, P.U.; Pardamean, B. Evolving Hybrid Cascade Neural Network Genetic Algorithm Space–Time Forecasting. Symmetry 2021, 13, 1158. https://doi.org/10.3390/sym13071158
Caraka RE, Yasin H, Chen R-C, Goldameir NE, Supatmanto BD, Toharudin T, Basyuni M, Gio PU, Pardamean B. Evolving Hybrid Cascade Neural Network Genetic Algorithm Space–Time Forecasting. Symmetry. 2021; 13(7):1158. https://doi.org/10.3390/sym13071158
Chicago/Turabian StyleCaraka, Rezzy Eko, Hasbi Yasin, Rung-Ching Chen, Noor Ell Goldameir, Budi Darmawan Supatmanto, Toni Toharudin, Mohammad Basyuni, Prana Ugiana Gio, and Bens Pardamean. 2021. "Evolving Hybrid Cascade Neural Network Genetic Algorithm Space–Time Forecasting" Symmetry 13, no. 7: 1158. https://doi.org/10.3390/sym13071158
APA StyleCaraka, R. E., Yasin, H., Chen, R.-C., Goldameir, N. E., Supatmanto, B. D., Toharudin, T., Basyuni, M., Gio, P. U., & Pardamean, B. (2021). Evolving Hybrid Cascade Neural Network Genetic Algorithm Space–Time Forecasting. Symmetry, 13(7), 1158. https://doi.org/10.3390/sym13071158