Abstract
Relation extraction is a crucial task in natural language processing (NLP) that aims to extract all relational triples from a given sentence. Extracting overlapping relational triples from complex texts is challenging and has received extensive research attention. Most existing methods are based on cascade models and employ language models to transform the given sentence into vectorized representations. The cascaded structure can cause exposure bias issue; however, the vectorized representation of each sentence needs to be closely related to the relation extraction with pre-defined relation types. In this paper, we propose a label-aware parallel network (LAPREL) for relation extraction. To solve the exposure bias issue, we apply a parallel network, instead of the cascade framework, based on the table-filling method with a symmetric relation pair tagger. To obtain task-related sentence embedding, we embed the prior label information into the token embedding and adjust the sentence embedding for each relation type. The proposed method can also effectively deal with overlapping relational triples. Compared with 10 baselines, extensive experiments are conducted on two public datasets to verify the performance of our proposed network. The experimental results show that LAPREL outperforms the 10 baselines in extracting relational triples from complex text.
1. Introduction
Relation extraction is a fundamental task in information extraction in which relational triples are extracted in the form of () with pre-defined relation types from a given unstructured sentence. The extracted relational triples are useful for natural language understanding and other downstream tasks, such as automating the construction of a knowledge base.
However, extracting relational triples from unstructured text is a challenging task. As shown in Figure 1, for Normal style, from the person “Shannon” in the text “Shannon was born in Michigan” and the location “Michigan”, the relation type “birth place” is determined between the two entities based on the semantics of the original text. Note that the extracted relational triples (“Shannon”, “birth _place”, “Michigan”) need to satisfy the appropriate order (). In addition, each entity can belong to different relational triples, which complicates the relation extraction more challenging. For the EPO style, the two extracted entities “Robert Downey Jr.” and “Iron Man” satisfy two relation types “act_in” and “direct_movie”. For the SEO style, the extracted entity “Timothy D. Cook” has the relation type “CEO_of” with the entity “Apple” and the relation type “birth_place” with the entity “Alabama”.
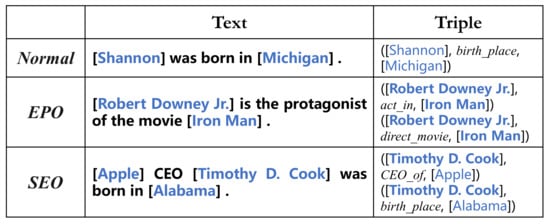
Figure 1.
Examples of Normal, EntityPairOverlap (EPO), and SingleEntityOverlap (SEO).
The early methods are mainly pipelined-based methods [1,2,3,4,5]. These methods divide relation extraction into two steps: all possible entities in the sentence are first extracted, and then, the relationships between these entities are analyzed. However, this cascaded structure ignores the inherent connection between the two steps. Relationship analysis on all candidate entities misclassifies some unrelated entity pairs. To alleviate the error propagation issue, joint models have attracted widespread research attention [6,7,8,9,10,11,12,13].
Although the previous studies have enabled significant progress, NovelTagging [13] extracts relational triples through a tagging method, which tags each word with only one label. In addition, there is the problem of overlapping relational triples. As shown in Figure 1, according to the degree of overlap of different relational triples, Zeng et al. [14] divided all sentences into three categories: Normal, EntityPairOverlap (EPO), and SingleEntityOverlap (SEO).
To solve the triple-overlapping issue, many studies have been conducted [14,15,16,17,18,19]. However, these existing relation extraction models need to face two other issues. First, exposure bias exists between the different steps of the cascaded relation extraction model. Most of the existing relation extraction models are divided into two or more cascaded steps. Take a two-step relation extraction model as an example. In the training process, the input of the second step is the theoretical gold output of the first step. In the testing process, however, the input of the second step is the predicted result of the first step. The difference between the cascaded steps in the training and testing phases leads to exposure bias. Second, the vectorized representation of sentences needs to have a close correlation with the relation extraction task. Natural language processing is built for downstream tasks: transforming text into semantic vectorized representations. The current embedding model is based on a large amount of corpus. The vectorized representation of sentences needs to be adjusted to be more suitable for relation extraction tasks with pre-defined relation types.
To solve the above two issues, we propose a label-aware parallel network for relation extraction. First, to resolve the exposure bias, we adopt a parallel framework. The central part of the framework is a symmetric table-filling method used to extract relational triples. The table-filling method extracts relational triples by analyzing the correlation between the task-related sequence embedding of a sentence and its symmetric sequence embedding. For each relation type, we construct a correlation matrix to represent the relationship between each word in the sentence. Second, to strengthen the connection between each given sentence and the relation extraction task with pre-defined relation types, we employ prior label information to supplement the words in the sentence and then adjust the sentence embedding for different relation types to obtain the sentence embedding with close task relevance. Learning a large amount of corpus through Transformer block [20], the pre-trained language model BERT [21] contains rich semantic information as well as certain redundant information that is not related to the relation extraction task with pre-defined relation types. Based on BERT, we obtain the correlation matrix between the label embedding and the sentence embedding. Then, the sentence embedding can be supplemented with the label embedding. In addition, the sentence embedding is adjusted by the attention mechanism to obtain the task-related sentence embedding suitable for different relation types, and then the corresponding relational triples are extracted. Our contributions are summarized as follows:
- We propose a parallel relation extraction framework. The entity recognition module is employed to correct the fuzzy boundary relation extraction module based on the table-filling method; therefore, the relational triples are extracted accurately.
- To ensure the sentence embedding and relation extraction tasks have a stronger connection, we add the label information to the sentence embedding through the label-aware mechanism. We employ trainable parameters to increase the adaptability of sentence embedding to different relation types.
- To verify the effectiveness of our method, we conducted extensive experiments on two public datasets: NYT and WebNLG. We compared the proposed method with 10 baselines.
The remainder of this paper is structured as follows: Section 2 provides the formulaic formulation of the task. In Section 3, the proposed LAPREL framework is described in detail in two parts: the encoder and the decoder. Section 4 presents the numerous experiments and the comparisons with the 10 baselines. Section 5 presents the related work with a brief analysis. Section 6 outlines the conclusion of the proposed framework for relation extraction and briefly describes future work.
2. Problem Formulation
Relation extraction aims to extract each relational triple (), or (), from a given unstructured sentence S. The relation type r is obtained from a pre-defined set R. The subject s and the object o are obtained from the entity set E. The extracted relational triples can be employed to construct knowledge bases, knowledge questions and answers, and other fields.
The purpose of relation extraction is to construct a suitable model using the existing information S and R, and obtain the target information (). Two key issues need to be addressed in the design of the model. First, the sentence representation indicates the need for a close association with the task. Second, the cascade structure suffers from exposure bias. The common cascade model of extracting entities first and then analyzing relations can be expressed in axiomatic terms as and .
In the proposed model, the pre-defined relation set R is used to enhance the task relevance of the sentence representation. We perform relation extraction using a parallel model instead of the cascade model. The whole process can be described as .
3. Method
Given a sentence, a relation extraction task aims to extract each relational triple. All subjects and objects are from an entity set E, and all relation categories are from a pre-defined set R.
As shown in Figure 2, the proposed model consisted of two parts: an encoder and a decoder. The encoder encoded the given text into a vectorized form; the decoder consisted of an entity recognizer and a relational classifier.
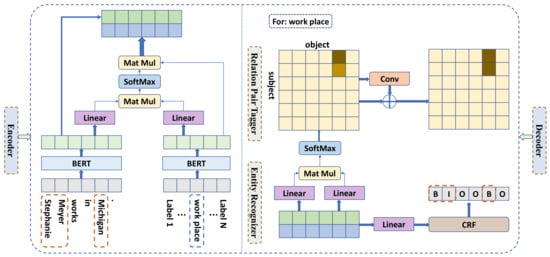
Figure 2.
The framework of the LAPREL model with an example. LAPREL is divided into two parts: an encoder and a decoder. For the given example “Stephanie Meyer works in Michigan”, we aim to find all relational triples from it. To effectively integrate prior knowledge, we encode the given text and relation type set R to obtain a task-related sentence representation. The decoder part consists of two parts: a relation pair tagger and an entity recognizer. Through the relation pair tagger, we analyze the relationship between all word pairs in a given text to obtain the possible relational triple . Through the entity recognizer, we obtain the entities and with more accurate boundaries in the text. The results of the entity recognizer strokes and supplements the relation matrix obtained from the relation pair tagger and obtains more accurate relational triples.
3.1. Encoder
Sentence embedding. Given a sentence S of length n, the BERT [21] encoder was employed to encode the sentence into a vectorized form. The BERT encoder was mainly composed of an N-layer Transformer [20] structure. Through encoding, we obtained the sentence embedding (The symbols of matrices and vectors in the paper are bolded.):
where , d is the dimension of the token embedding, and represents the process of the sequence passing through the BERT encoder.
Label-aware embedding. Given a relation label of length m, the BERT encoder was employed to encode the label into a vectorized form. All relation labels are from the pre-defined set R.
where and . To obtain the label embedding , we concatenate the together:
where and is the total number of labels in R. Then, we need to calculate the correlation between and to denote by . The label-aware embedding can be obtained as:
where , are trainable parameters, , , and N is the number of layers of the Transformer in BERT.
Sequence embedding. To achieve sequence embedding, which contained context information and label information, we needed to concatenate and in the embedding dimension. The sequence embedding could be obtained as:
where and are employed in the decoder part.
3.2. Decoder
Relation pair tagger. The purpose of the relation pair tagger was to find all entity pairs that had pre-defined relation types. To solve the overlapping triple problem, we modeled each relation type.
To effectively extract relational triples, the table-filling method [22] was employed to calculate the relation between different word pairs. In Figure 3, the table-filling method calculated the association between the task-related sequence embedding and its symmetric sequence embedding. In the relation extraction module, we constructed m relational tables to extract relational triples in a given sentence.
where , are trainable parameters, , , , , and .
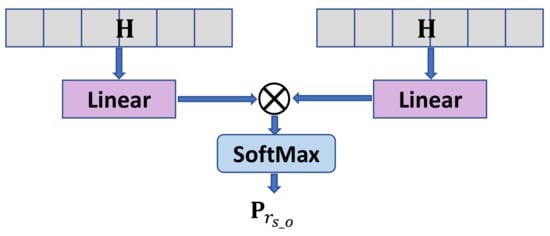
Figure 3.
Main part of the symmetric relation pair tagger.
Given a sequence, we obtained a token pair table representing the correlation between different tokens under each relation type. If a relation existed between subject and object tokens, then the corresponding positions in the token pair table under the corresponding relation type were tagged. During the training process, the loss function of the relation pair tagger was as follows:
where represents the possible correlation between the ith token and the jth token under the relation type r. If is satisfied, then ; otherwise, .
Entity recognizer. To overcome the entity pair’s fuzzy boundary problem in the relation pair tagger, the entity recognizer was employed to define the entity boundary again. The results of the entity recognizer could complement and perfect the results of the relation pair tagger. Additionally, the results of the relation pair tagger roughly show the entity pairs that had relationships, and the redundant entities that had no relationships in the entity recognizer were filtered.
In this module, we integrated the tagging scheme, in which B is the beginning position of the entity, I is the middle position of the entity, and O is the non-entity position.
To more accurately identify the entity boundary, we followed the design of Bi-LSTM+CRF [23] for named entity recognition (NER) to learn the logical relationship between different tags through the conditional random field (CRF) [24].
We employed as the input sequence, where represents the ith token in , represents the label sequence corresponding to the input sequence, and represents the set of all possible output label sequences of the input sequence. Given the input sequence , the possibility of outputting the label sequence could be obtained as:
where and is the number of labels.
During the training process, the loss function of the entity recognizer was as follows:
where represents the possibility that the ith token was tagged as the label of different entity types.
The decoding of the entity recognizer was mainly achieved by returning the label sequence corresponding to the maximum conditional probability of :
where represents the predicted label sequence. In the decoding process, we employed the Viterbi algorithm to find the best label sequence.
Joint Learning. To effectively extract relational triples, the loss functions of the previous two modules were synthesized to obtain the joint loss function:
The weight of the loss function of the two modules could be adjusted according to the actual situation to obtain better results. In this paper, the weight of the loss function of the two modules was 1:1.
4. Datasets
We implemented the relation extraction task on two public datasets NYT [25] and WebNLG [26]. The statistics of the two datasets are shown in Table 1.

Table 1.
Statistics of the NYT and WebNLG datasets. Note that a sentence can belong to both EPO and SEO.
4.1. NYT
New York Times (NYT) was constructed through the distant supervision method. Through the filtering method introduced by Zeng et al. [14], sentences with more than 100 words or sentences that contained no positive relational triples were filtered out. The processed dataset contained 56,195 instances for training and 5000 instances for testing. There were 24 types of relations remaining in the dataset.
4.2. WebNLG
WebNLG was originally used for natural language generation (NLG) tasks. We retained the sentences of the first criterion and filtered out sentences that did not contain positive relational triples. The processed dataset contained 5019 instances for training, 703 instances for test, and 500 instances for verification. There were 256 types of relations in the dataset.
5. Experiment
To verify the effectiveness of our proposed model, we conducted numerous experiments on the NYT and WebNLG datasets. We also compared LAPREL with 10 baselines.
5.1. Settings and Evaluation Metrics
5.1.1. Setting
Table 2 shows LAPREL’s parameter settings. In the LAPREL experiments, we set the number of training epochs to 100. To avoid the overfitting issue, when the F1 score did not increase for a certain period of time, the training stopped. Specifically, on NYT and WebNLG, the training stop conditions were the F1 score not improving for 8 and 11, respectively. The batch size was 8, the optimizer was Adam, and the learning rate was 2 × 10 . For the pre-trained language model, we employed [BERT-Base, Cased] (Available at https://storage.googleapis.com/bert_models/2018_10_18/cased_L-12_H-768_A-12.zip (accessed on 20 May 2021)), and there were 768 word embedding dimensions. There were 200 dimensions of hidden layer word embedding after model adjustment.
Table 2.
The hyperparameters of the LAPREL model.
5.1.2. Evaluation Metrics
To effectively compare LAPREL with the baselines, we used the same evaluation method as the previous method. We used strict precision, recall, and F1 score to evaluate the validity of the results. Only when the subject, object, and relation in the predicted relational triple were the same as the gold relational triple was the result considered to be valid.
5.2. Baselines
We compared our proposed method with 10 baseline models.
- NovelTagging [13] involves a novel tagging scheme using the nearest principle to extract relational triples, which transforms the relation extraction task to a sequence tagging problem.
- CopyRE [14] has a seq2seq model with a copy mechanism, which copies each relational triple from a sentence in three time periods.
- GraphRel [16] employs graph neural network to analyze the relationship edges between each pair of word nodes.
- CopyMTL [17] incorporates a multi-task model to improve the ability of CopyRE to deal with the problem of multi-token entities.
- OrderRL [15] combines reinforcement learning with a seq2seq model to handle the issue where CopyRE cannot accurately identify the order of the head-entity and tail-entity.
- ETL-Span [27] divides the relation extraction task into two cascaded subtasks with close correlation, which employs a hierarchical boundary tagger to find all head-entities and locate the corresponding tail-entities.
- WDec [18] adopts a novel seq2seq model with a representation scheme to extract overlapping relational triples.
- RSAN [28] applies a relation-based attention mechanism to adjust the weight distribution of sentence vectors for different relation types.
- SMHSA [22] applies a supervised attention-based model to jointly extract relational triples for different types of relations.
- CasRel [19] has a cascaded tagging framework, which extracts the object corresponding to each candidate subject for each pre-defined relation type.
5.3. Results
5.3.1. Main Results
Table 3 provides the experimental results produced by our proposed method and the baselines. The experimental results on NYT show that our proposed method was better than the baselines. Specifically, our method received higher scores than CasRel: 1.0%, 1.9%, 1.5% in precision, recall, and F1 score, respectively. However, on WebNLG, our proposed method received lower scores than CasRel in precision and F1 score. Table 1 shows that, compared with NYT, the training set, test set, and validation set of the WebNLG had fewer instances but more relation types. The unbalanced distribution of the instances in WebNLG limits the effectiveness of relation extraction models.
Table 3.
Precision, recall, and F1 score of different models on NYT and WebNLG datasets.
5.3.2. Detailed Results
To further verify the effectiveness of our proposed method, we conducted two sets of experiments to produce more detailed results.
The first set of experiments showed the superiority of our method in extracting relational triples from sentences containing relational triples with different degrees of overlap. Table 4 shows that the proposed method outperformed CasRel in all three types of examples on NYT. On WebNLG, LAPREL (EPO = 97.1% and SEO = 92.5%) outperformed CasRel (EPO = 94.7% and SEO = 92.2%) in both EPO and SEO experiments. For the three types of sentences, our method still produced stable results with the increase in overlapping parts. Specifically, our proposed method achieved better results in five out of six experiments. To effectively handle the overlapping problem of different relational triples, the proposed method constructed different relational tables for different relation types.
Table 4.
F1 score of extracting relational triples with different overlapping patterns (Normal, EPO, and SEO). ‘*’ marks the results reproduced by us.
The second set of experiments showed the effect of our method on extracting triples from sentences containing relational triples of different numbers. As shown in Table 5, according to the number of relational triples in the sentence (1; 2; 3; 4; ≥5), all sentences were divided into five categories. From the table, the following observations can be obtained.
Table 5.
F1 score of extracting relational triples from sentences with different number of triples (i.e., N).
First, our method produced stable effects on five types of sentences. As the number of relational triples in the sentence increased, the experimental results of CopyRE, GraphRel, and SMHSA gradually decreased. The effects of LAPREL and CasRel were more stable. Second, our proposed method achieved better results in 8 out of 10 experiments.
In summary, the proposed method could stably and effectively extract relational triples from sentences. In addition, LAPREL could handle the problem of overlapping relational triples, and simultaneously deal with the exposure bias between different steps of most relation extraction models.
6. Related Work
Relation extraction is an important task in natural language processing. In this section, we briefly introduce related work.
The early studies were mainly pipelined-based approaches [1,2,3,4,5] where the relation extraction model is divided into two independent steps: entity extraction and relation classification. These methods ignore the inherent correlation of the two steps, leading to the problem of error transmission. To strengthen the connection between the two steps, the joint model aroused widespread interest. The methods of the joint model are mainly divided into four categories: dependency forests, tagging, seq2se, and table-filling.
Dependency forests. These methods analyze the association between words in sentences by relying on the dependency forests methods and then extract relational triples. Song et al. [29] first integrated dependency forests to capture features to analyze the association between words for relation extraction. FORESTFT-DDCNN [30] employs full dependency forests to encode all dependency trees into a continuous 3D space to analyze the connections between different words. LF-GCN [31] employa a latent structure in the dependency forests, thereby improving the accuracy of the dependency parser. These methods are mainly used in medical relation extraction.
However, these methods ignore prior label information. Moreover, the complexity of the method based on dependency forests is higher than that of the table-filling method.
Tagging. These methods tag each word in the sentence as a pre-defined label and then extract relational triples. These methods improved the effect of relation extraction through the design of different tagging strategies and using different methods to associate the tagged entities together. NovelTagging [13] transforms the relation extraction task into a sequence tagging task, tags each word, and then obtains the relational triples through the nearest principle. However, each entity extracted by the tagging strategy belongs to at most one relational triple. RSAN [28] adjusts the weight of words in the sentence under different relation types through a relation-based attention mechanism and then extracts the relational triples through the tagging method. However, the tagging strategy struggles to effectively extract different relational triples with the same relational type in a sentence. ETL-Span [27] employs a tagger to tag the subject and object that are related to each other. CasRel [19] first extracts all possible subjects and then tags the objects corresponding to each subject under different relation types.
Although the triple-overlapping problem can be solved, these two methods divide the relation extraction into cascade steps with the exposure bias problem.
Seq2seq. The seq2seq methods can directly extract relational triples from sentences in an end-to-end manner. CopyRE [14] encodes the sentence uniformly and decodes it through the copy mechanism, finally copying each entity pair containing different relation types from the sentence. OrderRE [15] solves the problem that the copy mechanism is not sensitive to the order between the subject and the object in the relational triples, and improves the effect of CopyRE. CopyMTL [17], to address the difficulty of obtaining multi-token entities in the copy mechanism of CopyRE, adopts a multi-task learning method to further extract relational triples completely. These three methods are based on a sequence-to-sequence model that divides the relation extraction into cascade steps with redundant operations.
Table-filling. These methods construct a word table square matrix from a given sentence, analyze the connection between each word pairs, and then extract relational triples by filling each word table. GraphRel [16] uses each word as a node and analyzes whether there are associated edges between the nodes through a graph convolutional network (GCN), and then extracts relational triples. However, this method cannot predict entire entities. SAHMA [22] employs an attention mechanism to adjust each word in the sentence under different relation types and builds different relational word tables to extract relational triples. Although the semantic information of the sentences is considered, the a prior label information is not effectively employed.
LAPREL is based on a table-filling method, which avoids exposure bias issue. In addition, LAPREL effectively uses a prior label information to improve the effectiveness of the relation extraction task with pre-defined relation types.
7. Conclusions
In this paper, we proposed a label-aware parallel network (LAPREL) for relation extraction. LAPREL has the following three advantages: First, a prior label information is embedded into the model to make the vectorized representation of the sentence more relevant to the task. Second, different word tables are constructed for different relation types to mitigate the triple-overlapping issue. Third, a parallel structure is adopted to reduce the exposure bias caused by the transmission errors in the cascade step. The experimental results on NYT and WebNLG showed that our proposed model performs outstandingly in relation extraction. We will continue to study more effective parallel frameworks to adapt to multi-step relation extraction.
Author Contributions
Conceptualization, J.Y.; methodology, H.L.; software, X.L.; investigation, X.L.; resources, J.Y.; writing—original draft preparation, X.L.; writing—review and editing, P.H.; supervision, J.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Anhui Provincial Natural Science Foundation (No.1908085 MF202) and the Independent Scientific Research Program of National University of Defense Science and Technology (No. ZK18-03-14).
Data Availability Statement
Not applicable.
Acknowledgments
The authors would like to acknowledge the editor and referees for their valuable suggestions.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zelenko, D.; Aone, C.; Richardella, A. Kernel Methods for Relation Extraction. J. Mach. Learn. Res. 2003, 3, 1083–1106. [Google Scholar]
- Zhou, G.; Su, J.; Zhang, J.; Zhang, M. Exploring various knowledge in relation extraction. In Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics (ACL’05), Ann Arbor, MI, USA, 25–30 June 2005; pp. 427–434. [Google Scholar]
- Mintz, M.; Bills, S.; Snow, R.; Jurafsky, D. Distant supervision for relation extraction without labeled data. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, Singapore, 2–7 August 2009; pp. 1003–1011. [Google Scholar]
- Chan, Y.S.; Roth, D. Exploiting syntactico-semantic structures for relation extraction. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 551–560. [Google Scholar]
- Gormley, M.R.; Yu, M.; Dredze, M. Improved relation extraction with feature-rich compositional embedding models. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1774–1784. [Google Scholar]
- Yu, X.; Lam, W. Jointly identifying entities and extracting relations in encyclopedia text via a graphical model approach. In Proceedings of the Coling 2010: Posters, Beijing, China, 23–27 August 2010; pp. 1399–1407. [Google Scholar]
- Li, Q.; Ji, H. Incremental joint extraction of entity mentions and relations. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Baltimore, MD, USA, 22–27 June 2014; pp. 402–412. [Google Scholar]
- Miwa, M.; Sasaki, Y. Modeling joint entity and relation extraction with table representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1858–1869. [Google Scholar]
- Ren, X.; Wu, Z.; He, W.; Qu, M.; Voss, C.R.; Ji, H.; Abdelzaher, T.F.; Han, J. Cotype: Joint extraction of typed entities and relations with knowledge bases. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 1015–1024. [Google Scholar]
- Gupta, P.; Schütze, H.; Andrassy, B. Table filling multi-task recurrent neural network for joint entity and relation extraction. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 2537–2547. [Google Scholar]
- Miwa, M.; Bansal, M. End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 1105–1116. [Google Scholar]
- Katiyar, A.; Cardie, C. Going out on a limb: Joint extraction of entity mentions and relations without dependency trees. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 917–928. [Google Scholar]
- Zheng, S.; Wang, F.; Bao, H.; Hao, Y.; Zhou, P.; Xu, B. Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1227–1236. [Google Scholar]
- Zeng, X.; Zeng, D.; He, S.; Liu, K.; Zhao, J. Extracting relational facts by an end-to-end neural model with copy mechanism. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 506–514. [Google Scholar]
- Zeng, X.; He, S.; Zeng, D.; Liu, K.; Liu, S.; Zhao, J. Learning the extraction order of multiple relational facts in a sentence with reinforcement learning. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 367–377. [Google Scholar]
- Fu, T.J.; Li, P.H.; Ma, W.Y. GraphRel: Modeling text as relational graphs for joint entity and relation extraction. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1409–1418. [Google Scholar]
- Zeng, D.; Zhang, H.; Liu, Q. CopyMTL: Copy Mechanism for Joint Extraction of Entities and Relations with Multi-Task Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 9507–9514. [Google Scholar]
- Nayak, T.; Ng, H.T. Effective modeling of encoder-decoder architecture for joint entity and relation extraction. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 8528–8535. [Google Scholar]
- Wei, Z.; Su, J.; Wang, Y.; Tian, Y.; Chang, Y. A novel cascade binary tagging framework for relational triple extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Seattle, WA, USA, 5–10 July 2020; pp. 1476–1488. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Liu, J.; Chen, S.; Wang, B.; Zhang, J.; Li, N.; Xu, T. Attention as Relation: Learning Supervised Multi-head Self-Attention for Relation Extraction. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021. [Google Scholar]
- Ma, X.; Hovy, E. End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 1064–1074. [Google Scholar]
- Lafferty, J.; McCallum, A.; Pereira, F.C. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. In Proceedings of the Eighteenth International Conference on Machine Learning, Williamstown, MA, USA, 28 June– 1 July 2001; pp. 282–289. [Google Scholar]
- Riedel, S.; Yao, L.; McCallum, A. Modeling relations and their mentions without labeled text. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Berlin, Germany, 2010; pp. 148–163. [Google Scholar]
- Gardent, C.; Shimorina, A.; Narayan, S.; Perez-Beltrachini, L. Creating training corpora for nlg micro-planning. In Proceedings of the 55th annual meeting of the Association for Computational Linguistics (ACL), Vancouver, BC, Canada, 30 July–4 August 2017. [Google Scholar]
- Yu, B.; Zhang, Z.; Shu, X.; Wang, Y.; Liu, T.; Wang, B.; Li, S. Joint Extraction of Entities and Relations Based on a Novel Decomposition Strategy. In Proceedings of the 24th European Conference on Artificial Intelligence, Santiago de Compostela, Spain, 29 August–8 September 2020. [Google Scholar]
- Yuan, Y.; Zhou, X.; Pan, S.; Zhu, Q.; Song, Z.; Guo, L. A Relation-Specific Attention Network for Joint Entity and Relation Extraction. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021; pp. 4054–4060. [Google Scholar]
- Song, L.; Zhang, Y.; Gildea, D.; Yu, M.; Wang, Z.; Su, J. Leveraging dependency forest for neural medical relation extraction. arXiv 2019, arXiv:1911.04123. [Google Scholar]
- Jin, L.; Song, L.; Zhang, Y.; Xu, K.; Ma, W.y.; Yu, D. Relation extraction exploiting full dependency forests. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8034–8041. [Google Scholar]
- Guo, Z.; Nan, G.; Lu, W.; Cohen, S.B. Learning latent forests for medical relation extraction. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021; pp. 3651–3675. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).