
The Evaluation on the Process Capability Index CL for Exponentiated Frech’et Lifetime Product under Progressive Type I Interval Censoring


Abstract
:1. Introduction
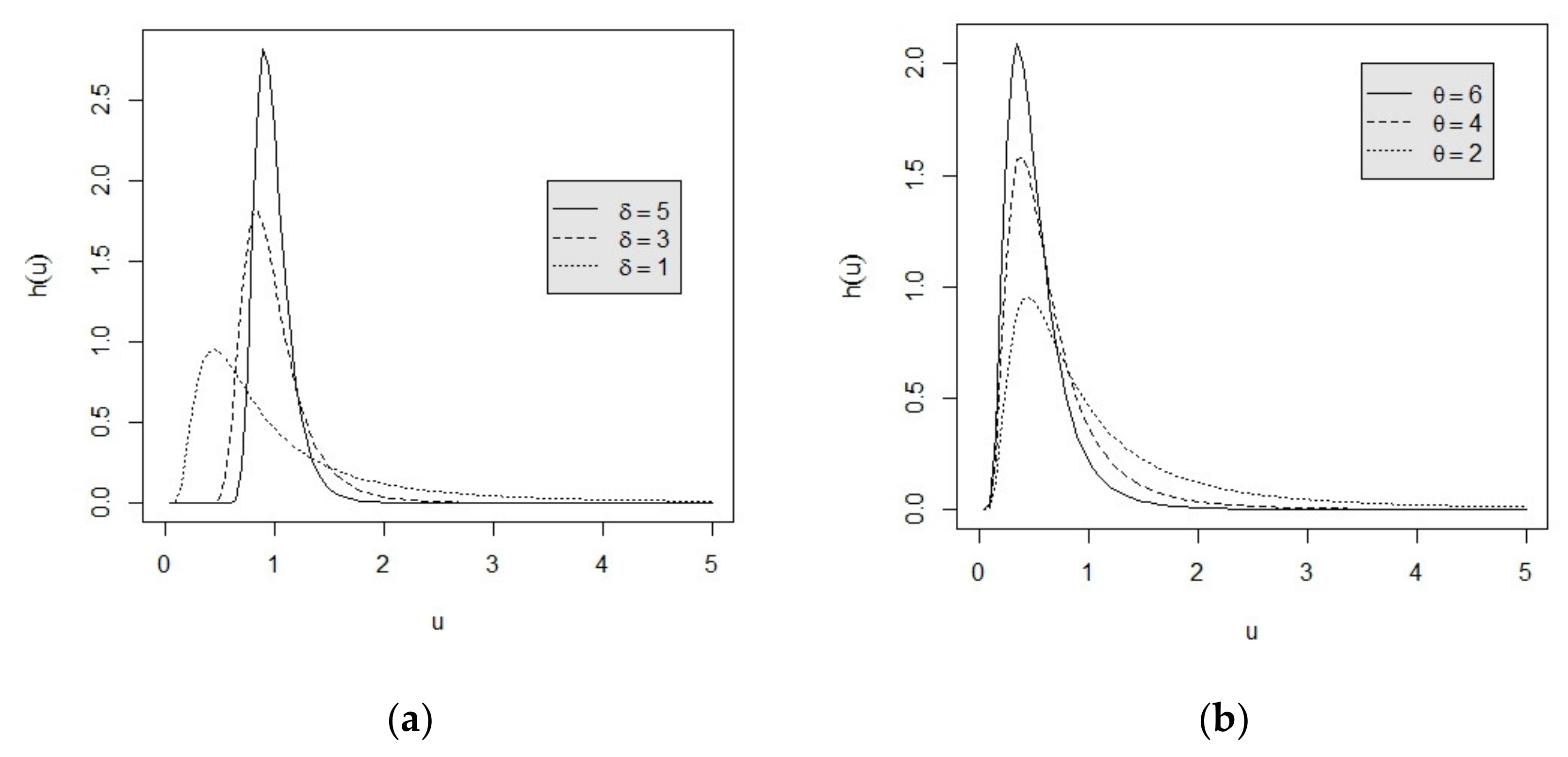
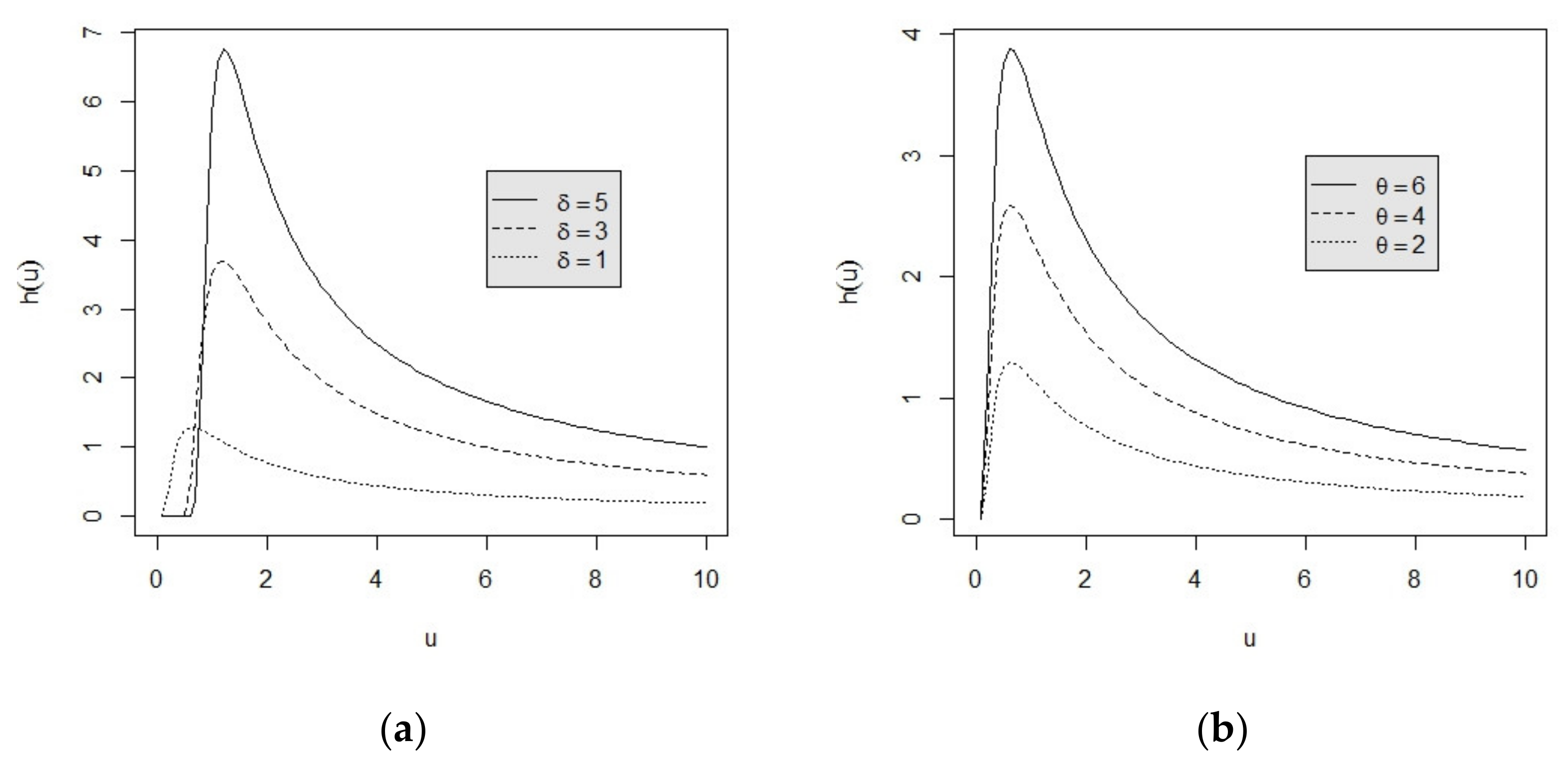
2. The Monotonic Relationship between the Lifetime Performance Index and the Conforming Rate
3. Results
3.1. The Maximum Likelihood Estimator for the Lifetime Performance Index and the Testing Procedure
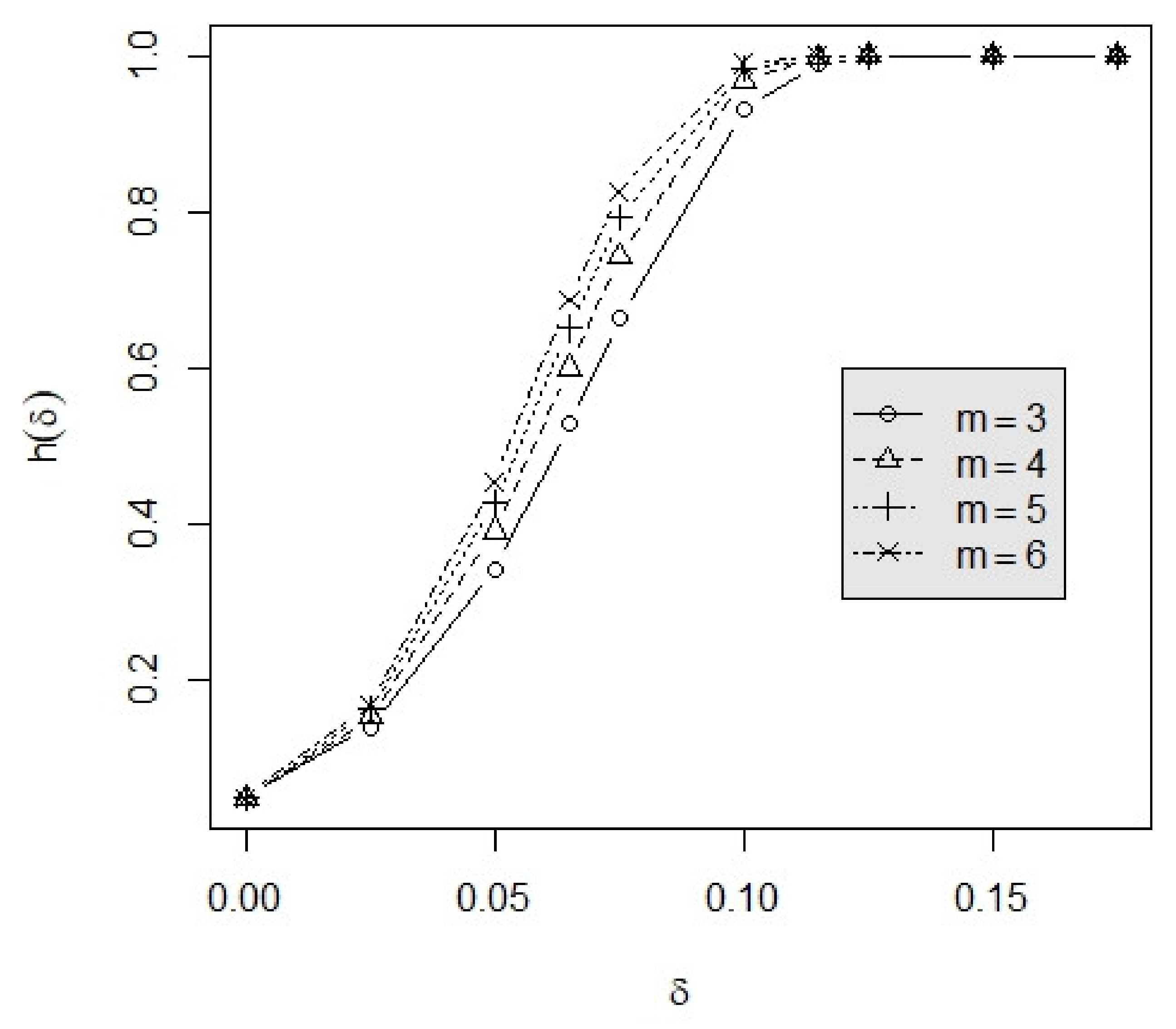
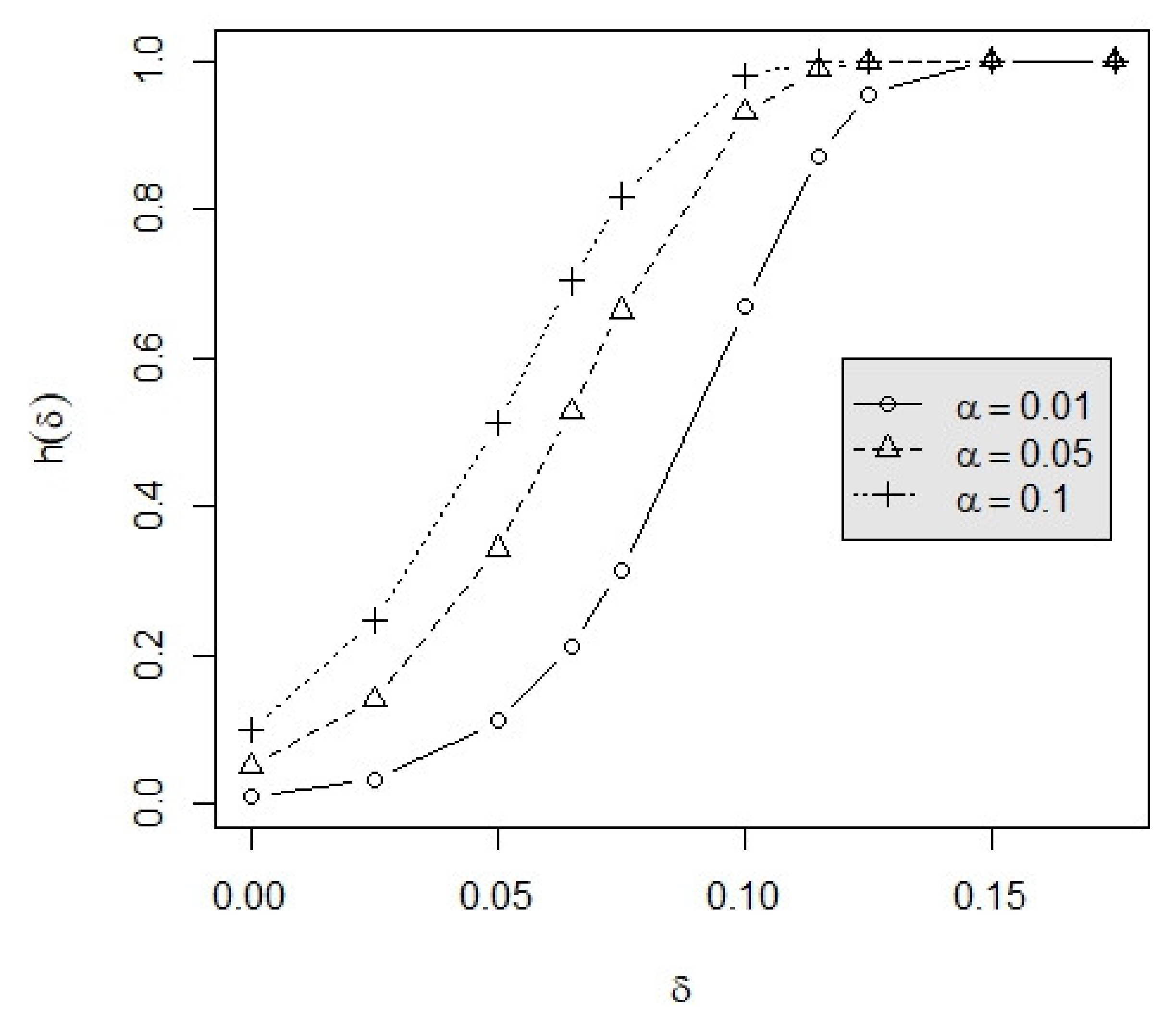
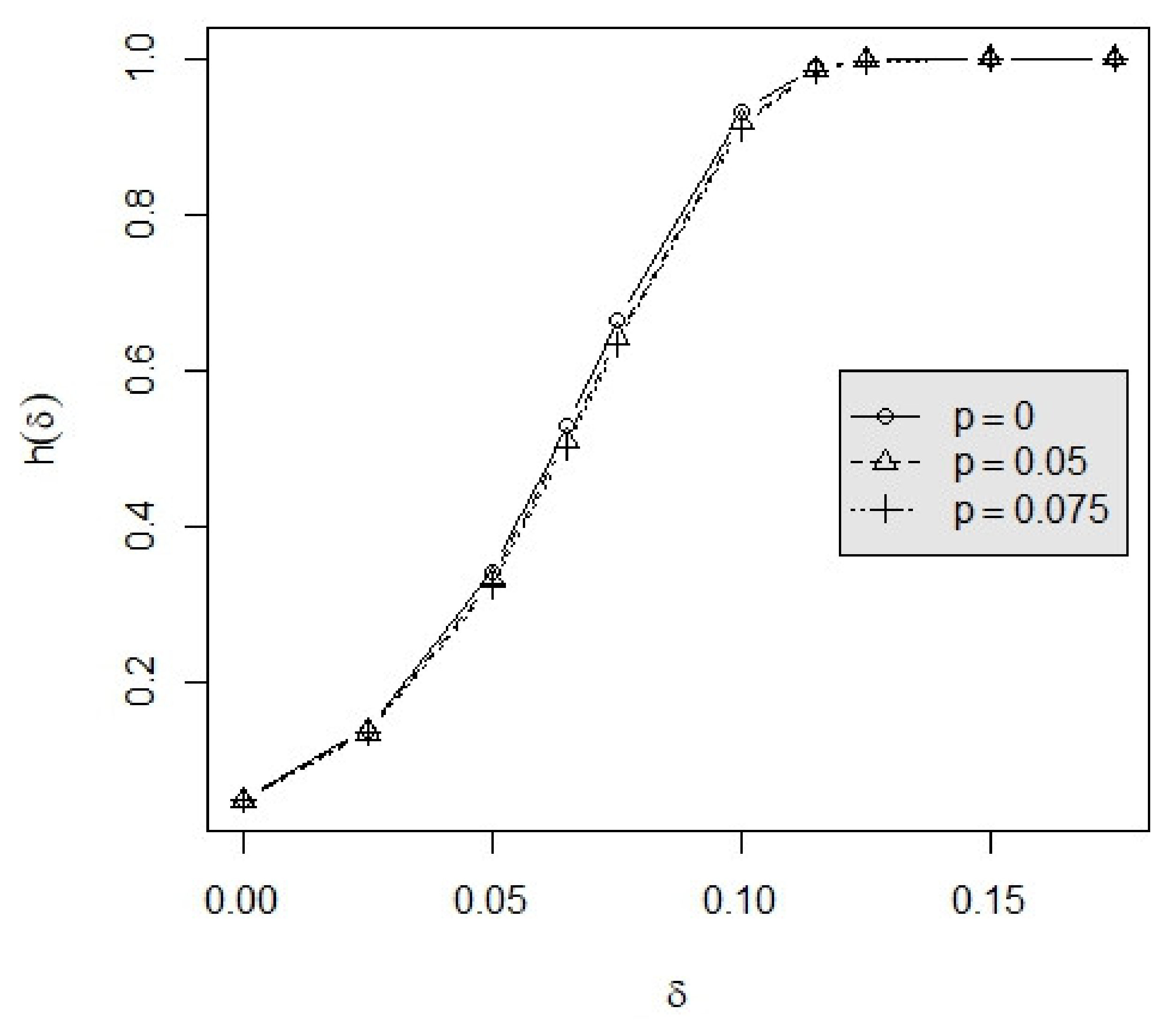
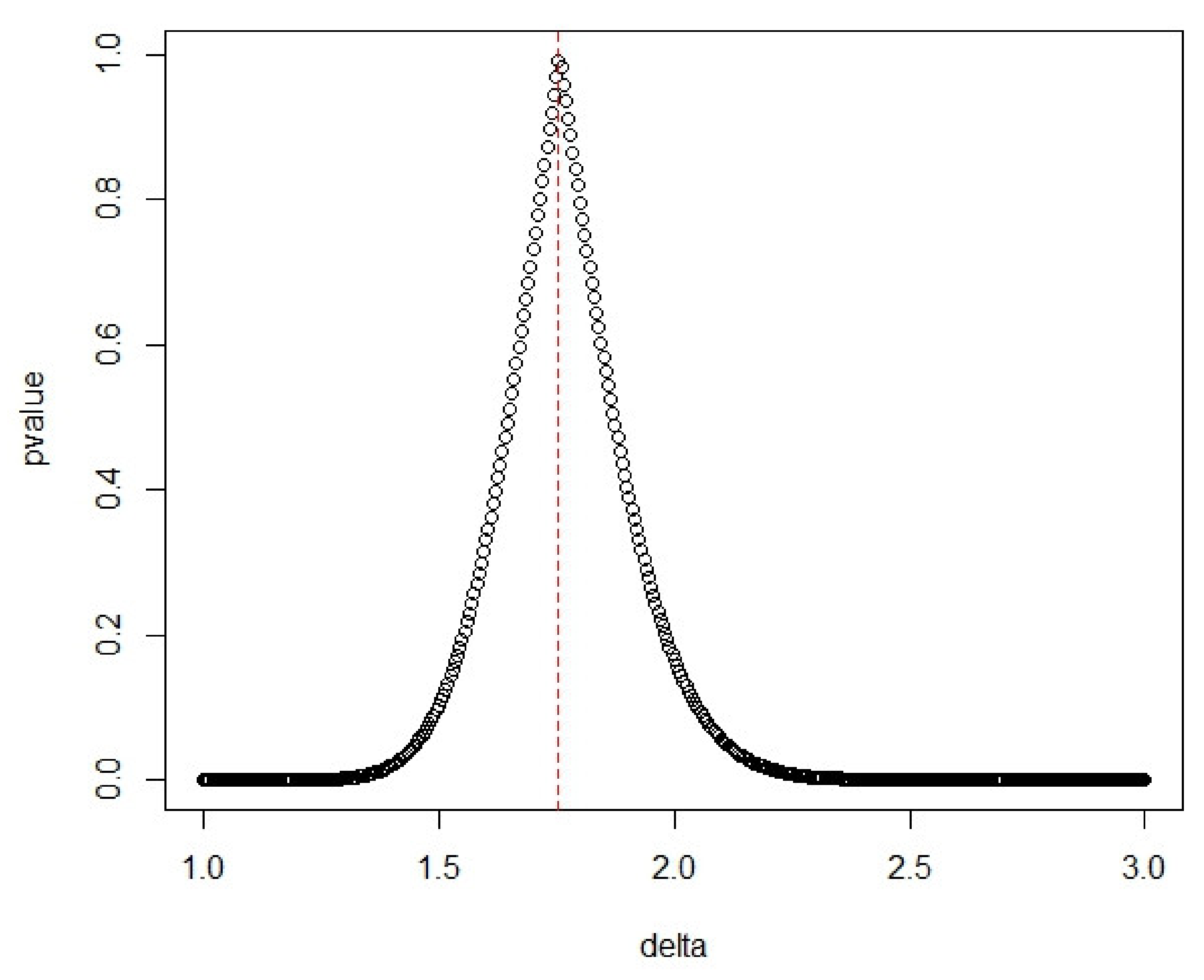
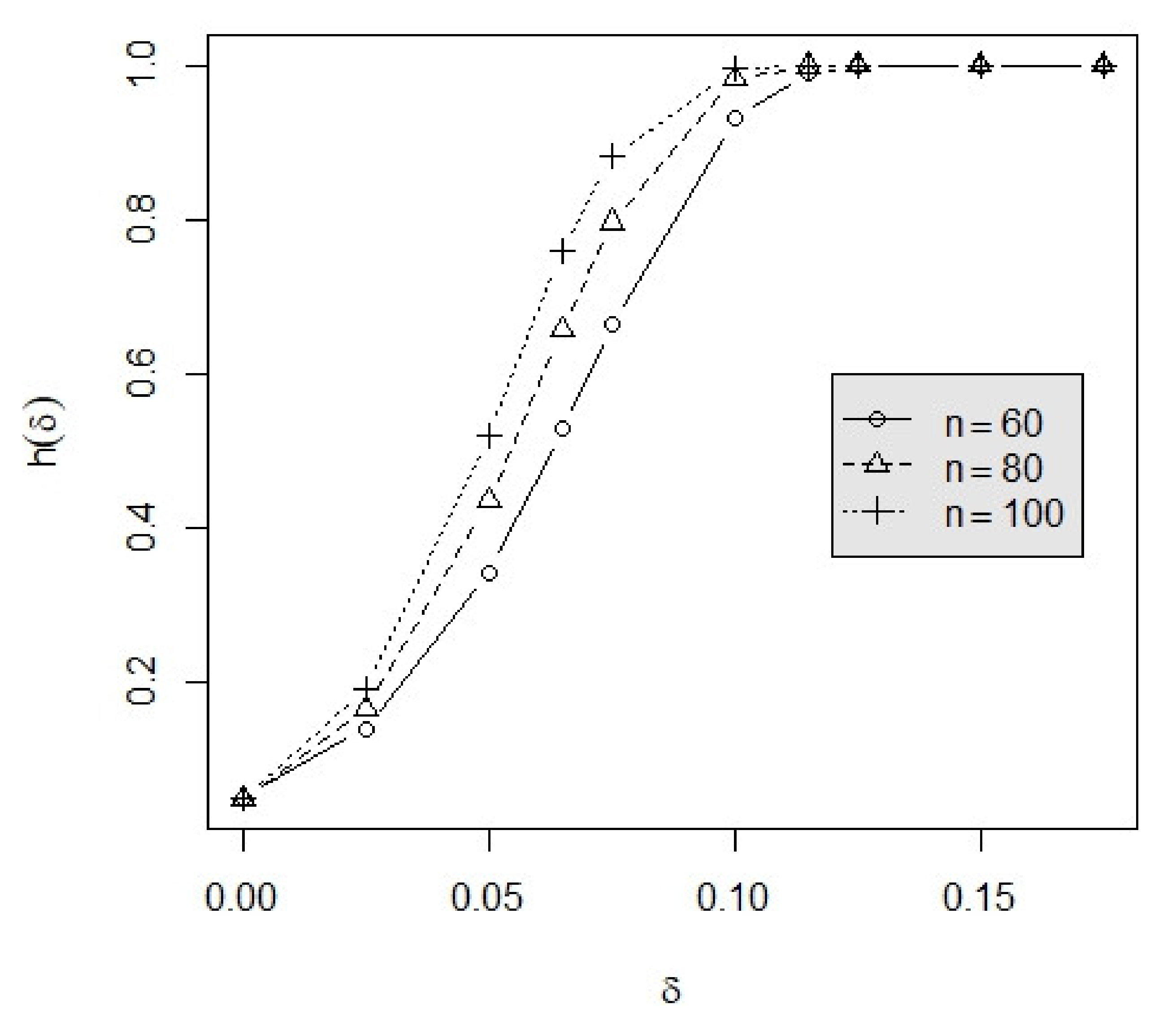
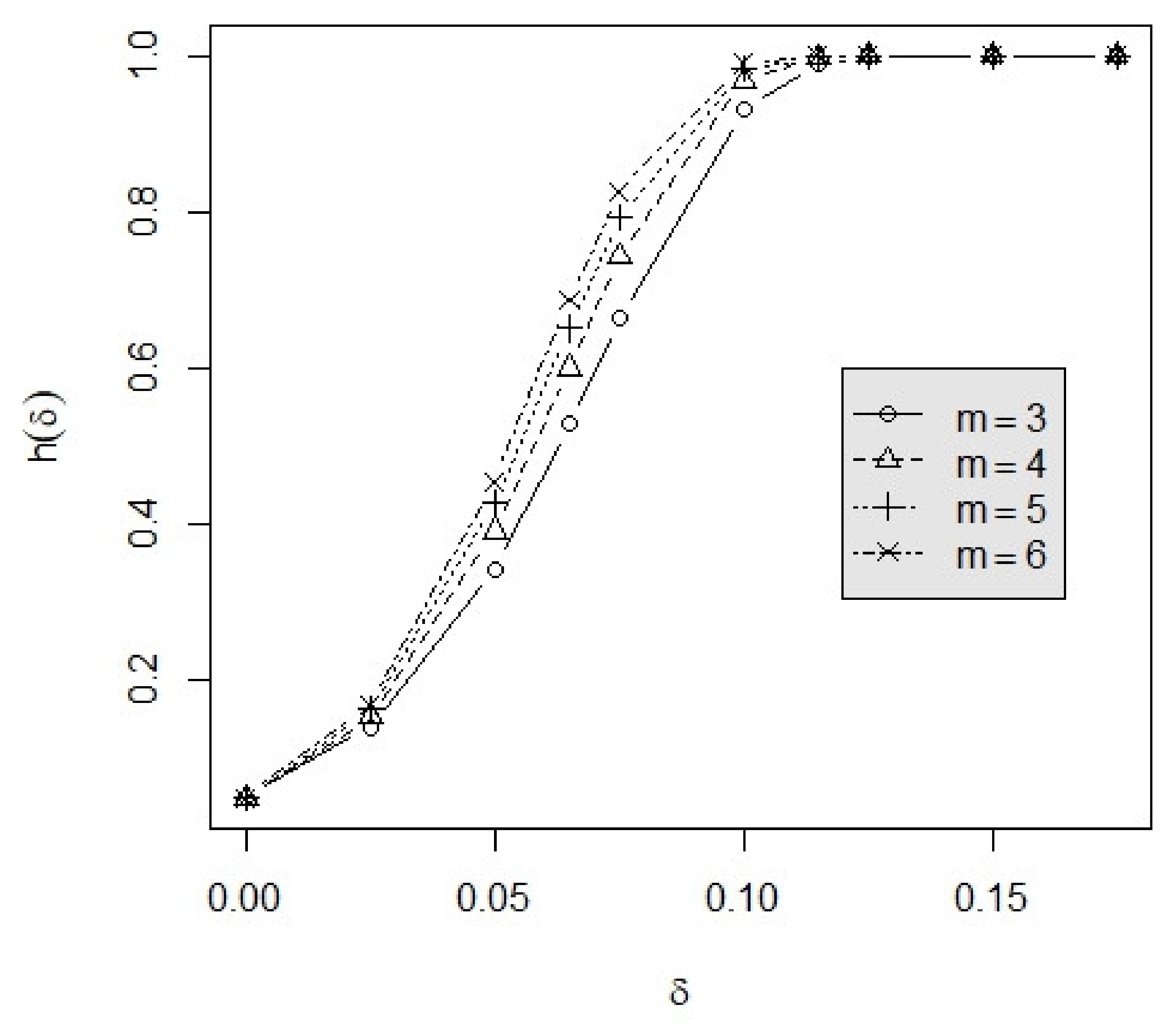
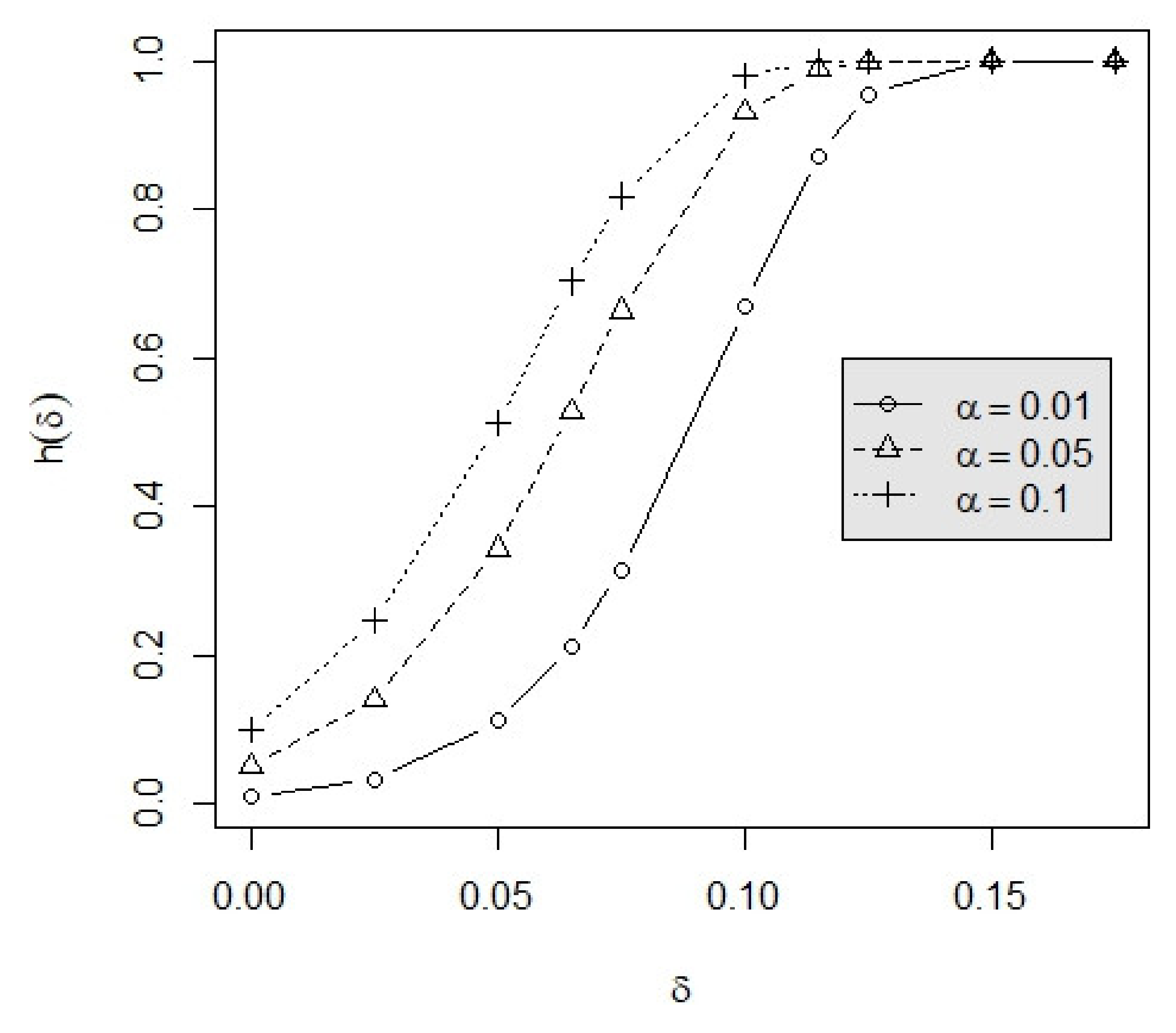
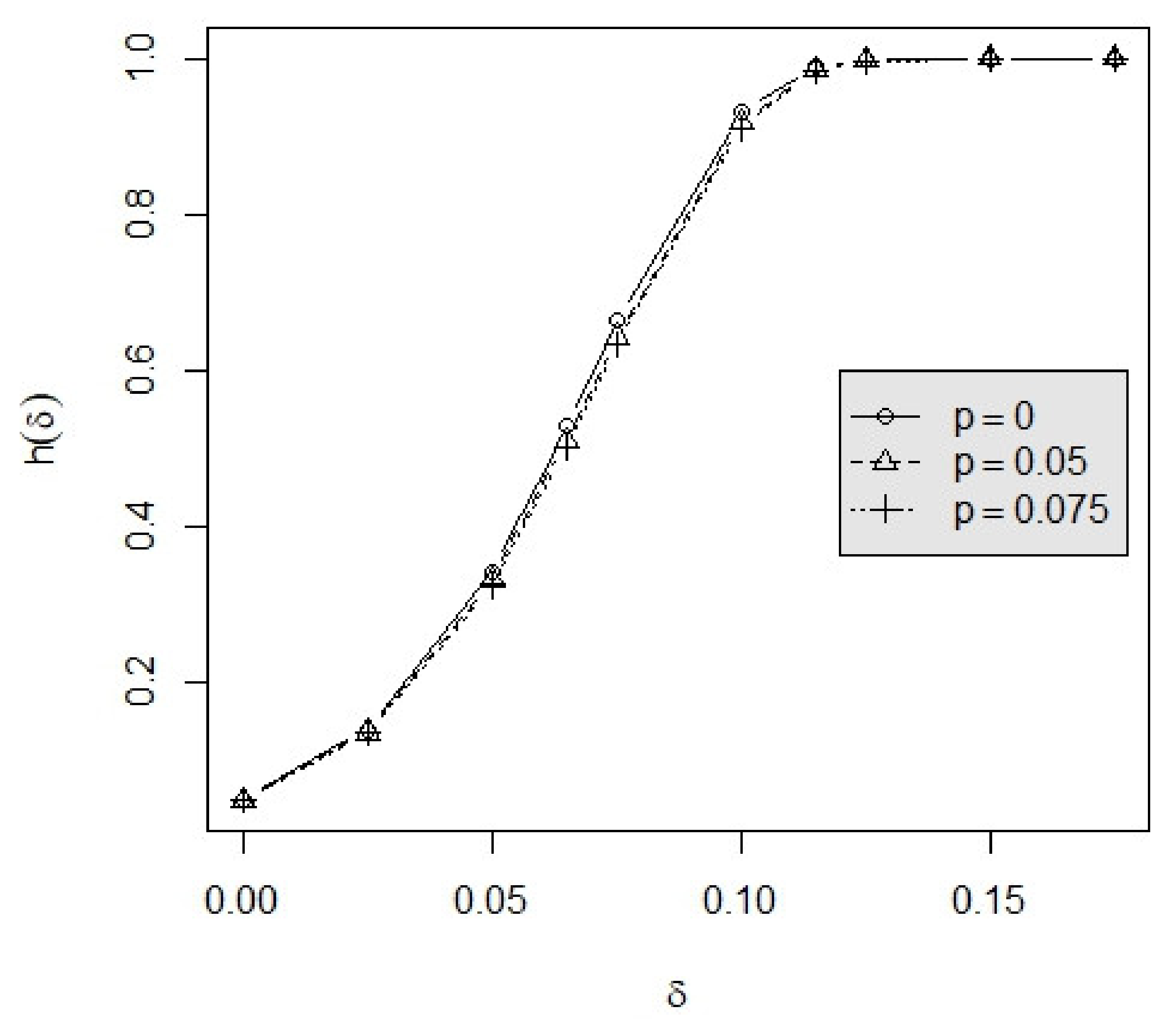
3.2. Example
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| m | n | 0.000 | 0.025 | 0.050 | 0.075 | 0.100 | 0.125 | |
| 3 | 60 | 0.000 | 0.0500 | 0.1404 | 0.3432 | 0.6636 | 0.9298 | 0.9982 |
| 0.050 | 0.0500 | 0.1372 | 0.3312 | 0.6429 | 0.9174 | 0.9972 | ||
| 0.075 | 0.0500 | 0.1356 | 0.3253 | 0.6325 | 0.9106 | 0.9966 | ||
| 80 | 0.000 | 0.0500 | 0.1664 | 0.4358 | 0.7960 | 0.9817 | 0.9999 | |
| 0.050 | 0.0500 | 0.1622 | 0.4208 | 0.7770 | 0.9766 | 0.9999 | ||
| 0.075 | 0.0500 | 0.1601 | 0.4134 | 0.7673 | 0.9737 | 0.9998 | ||
| 100 | 0.000 | 0.0500 | 0.1918 | 0.5206 | 0.8818 | 0.9957 | 1.0000 | |
| 0.050 | 0.0500 | 0.1866 | 0.5035 | 0.8667 | 0.9941 | 1.0000 | ||
| 0.075 | 0.0500 | 0.1840 | 0.4950 | 0.8587 | 0.9931 | 1.0000 | ||
| 4 | 60 | 0.000 | 0.0500 | 0.1532 | 0.3919 | 0.7422 | 0.9670 | 0.9997 |
| 0.050 | 0.0500 | 0.1482 | 0.3732 | 0.7142 | 0.9561 | 0.9995 | ||
| 0.075 | 0.0500 | 0.1457 | 0.3642 | 0.7001 | 0.9497 | 0.9992 | ||
| 80 | 0.000 | 0.0500 | 0.1833 | 0.4960 | 0.8631 | 0.9941 | 1.0000 | |
| 0.050 | 0.0500 | 0.1767 | 0.4733 | 0.8404 | 0.9909 | 1.0000 | ||
| 0.075 | 0.0500 | 0.1735 | 0.4622 | 0.8285 | 0.9889 | 1.0000 | ||
| 100 | 0.000 | 0.0500 | 0.2126 | 0.5882 | 0.9313 | 0.9991 | 1.0000 | |
| 0.050 | 0.0500 | 0.2045 | 0.5632 | 0.9155 | 0.9984 | 1.0000 | ||
| 0.075 | 0.0500 | 0.2006 | 0.5508 | 0.9069 | 0.9979 | 1.0000 | ||
| 5 | 60 | 0.000 | 0.0500 | 0.1626 | 0.4275 | 0.7922 | 0.9823 | 0.9999 |
| 0.050 | 0.0500 | 0.1558 | 0.4026 | 0.7590 | 0.9732 | 0.9999 | ||
| 0.075 | 0.0500 | 0.1526 | 0.3907 | 0.7421 | 0.9676 | 0.9998 | ||
| 80 | 0.000 | 0.0500 | 0.1957 | 0.5390 | 0.9010 | 0.9977 | 1.0000 | |
| 0.050 | 0.0500 | 0.1868 | 0.5093 | 0.8766 | 0.9957 | 1.0000 | ||
| 0.075 | 0.0500 | 0.1826 | 0.4950 | 0.8634 | 0.9943 | 1.0000 | ||
| 100 | 0.000 | 0.0500 | 0.2280 | 0.6350 | 0.9558 | 0.9997 | 1.0000 | |
| 0.050 | 0.0500 | 0.2170 | 0.6031 | 0.9405 | 0.9994 | 1.0000 | ||
| 0.075 | 0.0500 | 0.2118 | 0.5874 | 0.9317 | 0.9991 | 1.0000 | ||
| m | n | 0.000 | 0.025 | 0.050 | 0.075 | 0.100 | 0.125 | |
| 3 | 60 | 0.000 | 0.1000 | 0.2473 | 0.5124 | 0.8179 | 0.9786 | 0.9998 |
| 0.050 | 0.1000 | 0.2426 | 0.4991 | 0.8025 | 0.9737 | 0.9997 | ||
| 0.075 | 0.1000 | 0.2403 | 0.4926 | 0.7946 | 0.9710 | 0.9996 | ||
| 80 | 0.000 | 0.1000 | 0.2833 | 0.6076 | 0.9053 | 0.9959 | 1.0000 | |
| 0.050 | 0.1000 | 0.2775 | 0.5927 | 0.8937 | 0.9945 | 1.0000 | ||
| 0.075 | 0.1000 | 0.2746 | 0.5853 | 0.8876 | 0.9936 | 1.0000 | ||
| 100 | 0.000 | 0.1000 | 0.3170 | 0.6866 | 0.9524 | 0.9993 | 1.0000 | |
| 0.050 | 0.1000 | 0.3102 | 0.6712 | 0.9447 | 0.9989 | 1.0000 | ||
| 0.075 | 0.1000 | 0.3068 | 0.6633 | 0.9405 | 0.9987 | 1.0000 | ||
| 4 | 60 | 0.000 | 0.1000 | 0.2657 | 0.5650 | 0.8730 | 0.9918 | 1.0000 |
| 0.050 | 0.1000 | 0.2586 | 0.5454 | 0.8544 | 0.9883 | 1.0000 | ||
| 0.075 | 0.1000 | 0.2551 | 0.5358 | 0.8447 | 0.9861 | 0.9999 | ||
| 80 | 0.000 | 0.1000 | 0.3064 | 0.6658 | 0.9435 | 0.9990 | 1.0000 | |
| 0.050 | 0.1000 | 0.2975 | 0.6445 | 0.9314 | 0.9983 | 1.0000 | ||
| 0.075 | 0.1000 | 0.2932 | 0.6340 | 0.9247 | 0.9978 | 1.0000 | ||
| 100 | 0.000 | 0.1000 | 0.3444 | 0.7458 | 0.9760 | 0.9999 | 1.0000 | |
| 0.050 | 0.1000 | 0.3339 | 0.7246 | 0.9689 | 0.9998 | 1.0000 | ||
| 0.075 | 0.1000 | 0.3288 | 0.7139 | 0.9649 | 0.9997 | 1.0000 | ||
| 5 | 60 | 0.000 | 0.1000 | 0.2791 | 0.6019 | 0.9049 | 0.9963 | 1.0000 |
| 0.050 | 0.1000 | 0.2696 | 0.5767 | 0.8844 | 0.9937 | 1.0000 | ||
| 0.075 | 0.1000 | 0.2651 | 0.5644 | 0.8735 | 0.9921 | 1.0000 | ||
| 80 | 0.000 | 0.1000 | 0.3231 | 0.7051 | 0.9627 | 0.9997 | 1.0000 | |
| 0.050 | 0.1000 | 0.3113 | 0.6785 | 0.9508 | 0.9993 | 1.0000 | ||
| 0.075 | 0.1000 | 0.3057 | 0.6654 | 0.9440 | 0.9990 | 1.0000 | ||
| 100 | 0.000 | 0.1000 | 0.3642 | 0.7841 | 0.9861 | 1.0000 | 1.0000 | |
| 0.050 | 0.1000 | 0.3503 | 0.7585 | 0.9800 | 0.9999 | 1.0000 | ||
| 0.075 | 0.1000 | 0.3437 | 0.7456 | 0.9763 | 0.9999 | 1.0000 | ||
References
- Montalvo, C.; Peck, D.; Rietveld, E. A Longer Lifetime for Products: Benefits for Consumers and Companies; Directorate General for Internal Policies: Luxembourg; Policy Deparment A: Economic and Scientific Policy of European Parliament: Brussels, Belgium, 2016. [Google Scholar]
- Montgomery, D.C. Introduction to Statistical Quality Control; John Wiley and Sons: New York, NY, USA, 1985. [Google Scholar]
- Tong, L.I.; Chen, K.S.; Chen, H.T. Statistical testing for assessing the performance of lifetime index of electronic components with exponential distribution. Int. J. Qual. Reliab. Manag. 2002, 19, 812–824. [Google Scholar] [CrossRef]
- Wu, S.F.; Lin, Y.P. Computational testing algorithmic procedure of assessment for lifetime performance index of products with one-parameter exponential distribution under progressive type I interval censoring. Math. Comput. Simul. 2016, 120, 79–90. [Google Scholar] [CrossRef]
- Wu, S.F.; Lin, M.J. Computational testing algorithmic procedure of assessment for lifetime performance index of products with weibull distribution under progressive type I interval censoring. J. Comput. Appl. Math. 2017, 311, 364–374. [Google Scholar] [CrossRef]
- Wu, S.F.; Lu, J.Y. Computational testing algorithmic procedure of assessment for lifetime performance index of Pareto products under progressive type I interval censoring. Comput. Stat. 2017, 32, 647–666. [Google Scholar] [CrossRef]
- Wu, S.F. The performance assessment on the lifetime performance index of products following Chen lifetime distribution based on the progressive type I interval censored sample. J. Comput. Appl. Math. 2017, 334, 27–38. [Google Scholar] [CrossRef]
- Wu, S.F.; Chen, T.C.; Chang, W.J.; Chang, W.C.; Lin, C. A hypothesistesting procedure for the evaluation on the lifetime performance index of products with Burr XII distribution under progressive type I interval censoring. Commun. Stat. Simul. Comput. 2018, 47, 2670–2683. [Google Scholar] [CrossRef]
- Wu, S.F.; Lin, Y.T.; Chang, W.J.; Chang, C.W.; Lin, C.A. Computational algorithm for the evaluation on the lifetime performance index of products with Rayleigh distribution under progressive type I interval censoring. J. Comput. Appl. Math. 2018, 328, 508–519. [Google Scholar] [CrossRef]
- Wu, S.F.; Hsieh, Y.T. The assessment on the lifetime performance index of products with Gompertz distribution based on the progressive type I interval censored sample. J. Comput. Appl. Math. 2019, 351, 66–76. [Google Scholar] [CrossRef]
- Frech’et, M. Sur la loi de probabilit de l’ecart maximum. Ann. Soc. Polon. Math. 1927, 6, 93–116. [Google Scholar]
- Nadarajah, S.; Kotz, S. The Exponentiated Type Distributions. Acta Appl. Math. 2006, 92, 97–111. [Google Scholar] [CrossRef]
- Rao, G.S.; Rosaiah, K.; Sridhar Babu, M. Group acceptance sampling plans for resubmitted lots under exponentiated Fréchet distribution. Int. J. Comput. Sci. Math. 2019, 10, 11–21. [Google Scholar] [CrossRef]
- Gill, M.H.; Gastwirth, J.L. A scale-free goodness-of-fit Test for the Exponential Distribution Based on the Gini Statistic. J. R. Stat. Soc. Ser. B Methodol. 1978, 40, 350–357. [Google Scholar] [CrossRef]
- Casella, G.; Berger, R.L. Statistical Inference, 2nd ed.; Duxbury Press: Pacific Grove, CA, USA, 2002. [Google Scholar]
- Wingo, D.R. Maximum likelihood methods for fitting the Burr type XII distribution to life test data. Biom. J. 1983, 25, 77–84. [Google Scholar] [CrossRef]


| n | 0.000 | 0.025 | 0.050 | 0.075 | 0.100 | 0.125 | ||
| 3 | 60 | 0.000 | 0.0100 | 0.0344 | 0.1114 | 0.3130 | 0.6696 | 0.9540 |
| 0.050 | 0.0100 | 0.0333 | 0.1054 | 0.2939 | 0.6382 | 0.9403 | ||
| 0.075 | 0.0100 | 0.0328 | 0.1025 | 0.2845 | 0.6223 | 0.9324 | ||
| 80 | 0.000 | 0.0100 | 0.0436 | 0.1643 | 0.4672 | 0.8540 | 0.9952 | |
| 0.050 | 0.0100 | 0.0421 | 0.1552 | 0.4418 | 0.8301 | 0.9927 | ||
| 0.075 | 0.0100 | 0.0414 | 0.1508 | 0.4293 | 0.8174 | 0.9910 | ||
| 100 | 0.000 | 0.0100 | 0.0534 | 0.2225 | 0.6082 | 0.9447 | 0.9996 | |
| 0.050 | 0.0100 | 0.0514 | 0.2101 | 0.5802 | 0.9311 | 0.9994 | ||
| 0.075 | 0.0100 | 0.0504 | 0.2041 | 0.5662 | 0.9234 | 0.9991 | ||
| 4 | 60 | 0.000 | 0.0100 | 0.0386 | 0.1365 | 0.3933 | 0.7839 | 0.9868 |
| 0.050 | 0.0100 | 0.0369 | 0.1263 | 0.3621 | 0.7443 | 0.9787 | ||
| 0.075 | 0.0100 | 0.0360 | 0.1215 | 0.3471 | 0.7238 | 0.9733 | ||
| 80 | 0.000 | 0.0100 | 0.0497 | 0.2027 | 0.5689 | 0.9282 | 0.9994 | |
| 0.050 | 0.0100 | 0.0473 | 0.1873 | 0.5309 | 0.9054 | 0.9986 | ||
| 0.075 | 0.0100 | 0.0461 | 0.1801 | 0.5122 | 0.8924 | 0.9980 | ||
| 100 | 0.000 | 0.0100 | 0.0616 | 0.2746 | 0.7140 | 0.9803 | 1.0000 | |
| 0.050 | 0.0100 | 0.0582 | 0.2541 | 0.6761 | 0.9707 | 0.9999 | ||
| 0.075 | 0.0100 | 0.0567 | 0.2443 | 0.6569 | 0.9647 | 0.9999 | ||
| 5 | 60 | 0.000 | 0.0100 | 0.0418 | 0.1562 | 0.4539 | 0.8502 | 0.9956 |
| 0.050 | 0.0100 | 0.0394 | 0.1418 | 0.4114 | 0.8071 | 0.9908 | ||
| 0.075 | 0.0100 | 0.0383 | 0.1352 | 0.3913 | 0.7839 | 0.9873 | ||
| 80 | 0.000 | 0.0100 | 0.0544 | 0.2329 | 0.6396 | 0.9609 | 0.9999 | |
| 0.050 | 0.0100 | 0.0509 | 0.2112 | 0.5914 | 0.9409 | 0.9996 | ||
| 0.075 | 0.0100 | 0.0493 | 0.2012 | 0.5676 | 0.9288 | 0.9994 | ||
| 100 | 0.000 | 0.0100 | 0.0678 | 0.3149 | 0.7806 | 0.9918 | 1.0000 | |
| 0.050 | 0.0100 | 0.0632 | 0.2863 | 0.7363 | 0.9852 | 1.0000 | ||
| 0.075 | 0.0100 | 0.0611 | 0.2730 | 0.7134 | 0.9807 | 1.0000 | ||
| = 0.01 | ||||||
|---|---|---|---|---|---|---|
| m | n | 0.000 | 0.025 | 0.050 | 0.100 | |
| 5 | 0.05 | 10 | 0.00016 | 0.00064 | 0.00205 | 0.02280 |
| 20 | 0.00094 | 0.00407 | 0.01661 | 0.19383 | ||
| 40 | 0.00202 | 0.01503 | 0.07845 | 0.65924 | ||
| 60 | 0.00340 | 0.02959 | 0.16399 | 0.89157 | ||
| 80 | 0.00352 | 0.04384 | 0.25984 | 0.97334 | ||
| 100 | 0.00416 | 0.06086 | 0.36242 | 0.99392 | ||
| 200 | 0.00571 | 0.15585 | 0.74854 | 1.00000 | ||
| 500 | 0.00667 | 0.47964 | 0.99508 | 1.00000 | ||
| = 0.05 | ||||||
| m | n | 0.000 | 0.025 | 0.050 | 0.100 | |
| 5 | 0.05 | 10 | 0.01448 | 0.03333 | 0.07094 | 0.28509 |
| 20 | 0.02244 | 0.06323 | 0.16004 | 0.61186 | ||
| 40 | 0.02930 | 0.11266 | 0.32399 | 0.91324 | ||
| 60 | 0.03189 | 0.15746 | 0.46820 | 0.98347 | ||
| 80 | 0.03411 | 0.20030 | 0.58476 | 0.99741 | ||
| 100 | 0.03565 | 0.23446 | 0.68200 | 0.99955 | ||
| 200 | 0.03987 | 0.41045 | 0.92596 | 1.00000 | ||
| 500 | 0.04267 | 0.75502 | 0.99968 | 1.00000 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, S.-F.; Chang, W.-T. The Evaluation on the Process Capability Index CL for Exponentiated Frech’et Lifetime Product under Progressive Type I Interval Censoring. Symmetry 2021, 13, 1032. https://doi.org/10.3390/sym13061032
Wu S-F, Chang W-T. The Evaluation on the Process Capability Index CL for Exponentiated Frech’et Lifetime Product under Progressive Type I Interval Censoring. Symmetry. 2021; 13(6):1032. https://doi.org/10.3390/sym13061032
Chicago/Turabian StyleWu, Shu-Fei, and Wei-Tsung Chang. 2021. "The Evaluation on the Process Capability Index CL for Exponentiated Frech’et Lifetime Product under Progressive Type I Interval Censoring" Symmetry 13, no. 6: 1032. https://doi.org/10.3390/sym13061032
APA StyleWu, S.-F., & Chang, W.-T. (2021). The Evaluation on the Process Capability Index CL for Exponentiated Frech’et Lifetime Product under Progressive Type I Interval Censoring. Symmetry, 13(6), 1032. https://doi.org/10.3390/sym13061032