
Computing Expectiles Using k-Nearest Neighbours Approach


 ,
, 
Abstract
1. Introduction
2. K-Nearest Neighbours Expectile Regression
| Procedure 1 Computing Expectiles |
|
2.1. Distance Measures
- •
- Euclidean Distance (ED) is also called norm or Ruler distance and defined by
- •
- Manhattan Distance (MD) is also known as distance, and defined as the sum of absolute difference of elements of and for , which is,
- •
- Chebychev Distance (CbD) is the maximum value distance and specified by
- •
- Canberra Distance (CD) is a weighted version of Manhattan distance measure and defined byNote that (8) is sensitive to small changes when both and are close to zero.
- •
- Soergel Distance (SoD) is widely used for calculating the evolutionary distance and obeying all four properties of a valid distance measure. It is listed by
- •
- Lorentzain Distance (LD) is defined as a natural log of absolute distance between vector and , that iswhere one is added to avoid the log of zero and to ensure non-negative property of a distance metric.
- •
- Cosine Distance is derived from a cosine similarity that measures the angle between two vectors. It is specified by
- •
- Jaccard Distance (JacD) measures dissimilarity between two vectors. It is defined by
- •
- Clark Distance is also called the coefficient of divergence. It is the square root of half of divergence distance. It is defined by
- •
- Squared Chi-Squared Distance belongs to the family of and it is defined by
- •
- Average Distance is the average of Manhattan distance and Chebyshev distance. It is defined by
- •
- Divergence Distance is defined by
- •
- Hassanat Distance (HasD) is defined bywhere forIt is important to note that (17) is invariant to different scale, noise, and outlier, and it is always bounded by . Contrary to other distances measures, shows high similarity between points and when it approaches zero where as it shows high dissimilarity when it approaches one. Moreover, it can only achieve limiting value one if or .
- •
- Whittaker’s Index of Association Distance
2.2. Selecting Best k
| Procedure 2 Computing Best k |
|
2.3. The ex- Algorithm
| Algorithm 1 Compute test error |
|
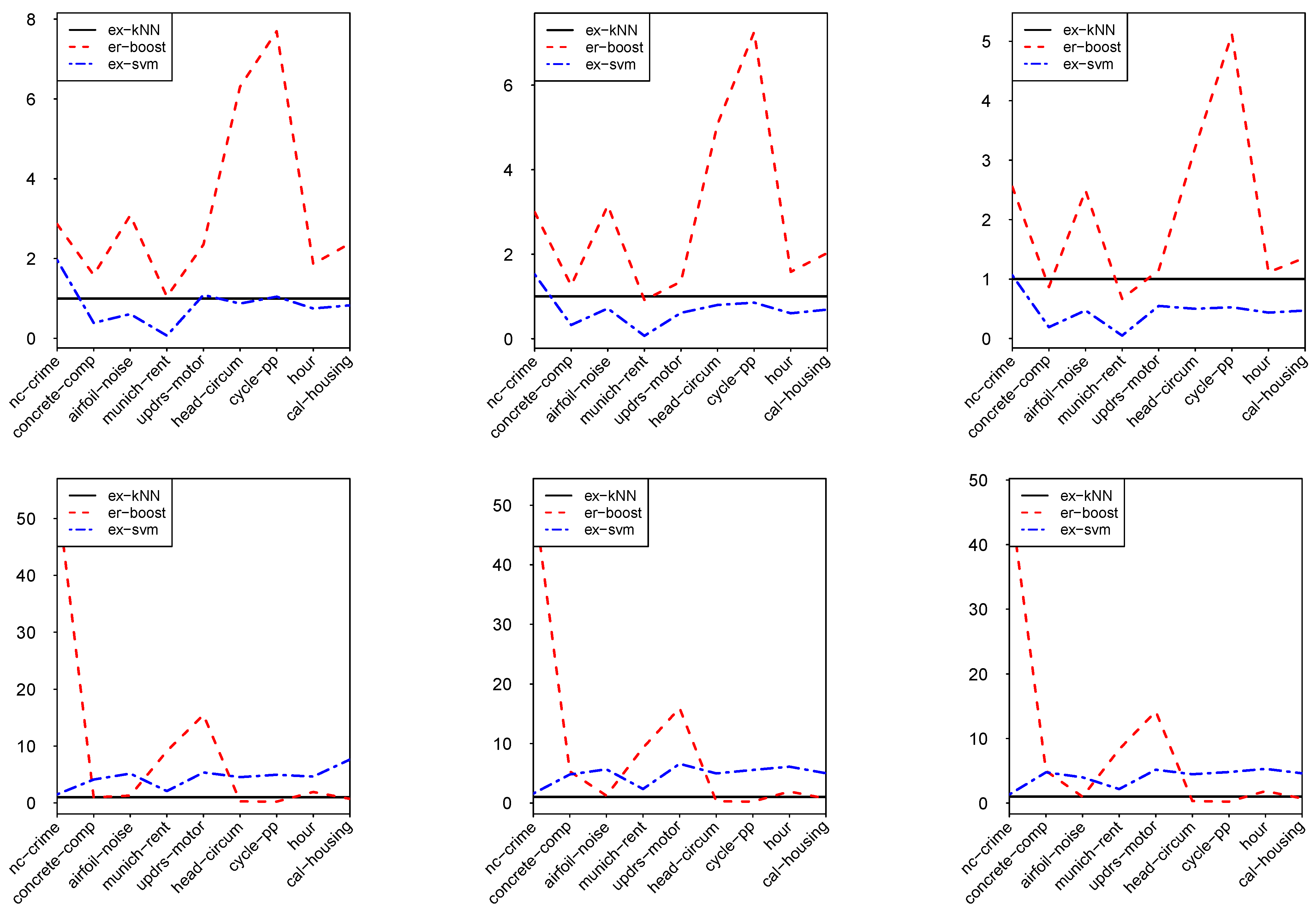
3. Experimental Results
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Impact of Different Distance Measures on Test Error and Computational Cost of ex-kNN

{kind=link}
| Distance Measure | Data Set | Average Rank | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| NC-CRIME | CONCRETE-COMP | AIRFOIL-NOISE | MUNICH-RENT | UPDRS-MOTOR | HEAD-CIRCUM | CYCLE-PP | HOUR | CAL-HOUSING | ||
| Euclidean | 0.0047 (4) | 0.0246 (3) | 0.0125 (2) | 0.0142 (8) | 0.0277 (6) | 0.0039 (2) | 0.0047 (3) | 0.0150 (1) | 0.0237 (5) | 3.78 |
| Manhattan | 0.0036 (3) | 0.0257 (6) | 0.0130 (5) | 0.0135 (6) | 0.0245 (4) | 0.0039 (2) | 0.0045 (1) | 0.0157 (6) | 0.0229 (1) | 3.78 |
| Chebychev | 0.0066 (7) | 0.0299 (8) | 0.0121 (1) | 0.0152 (9) | 0.0347 (10) | 0.0039 (2) | 0.0050 (5) | 0.0165 (7) | 0.0250 (8) | 6.33 |
| Canberra | 0.0034 (2) | 0.0250 (6) | 0.0130 (5) | 0.0131 (4) | 0.0229 (1) | 0.0039 (2) | 0.0046 (2) | 0.0155 (4) | 0.0231 (3) | 3.22 |
| Soergel | 0.0034 (2) | 0.0250 (6) | 0.0130 (5) | 0.0131 (4) | 0.0229 (2) | 0.0039 (2) | 0.0046 (2) | 0.0155 (4) | 0.0231 (3) | 3.33 |
| Lorentzian | 0.0029 (1) | 0.0270 (7) | 0.0129 (4) | 0.0132 (5) | 0.0236 (3) | 0.0038 (1) | 0.0045 (1) | 0.0155 (4) | 0.0230 (2) | 3.11 |
| Cosine | 0.0060 (6) | 0.0249 (5) | 0.0175 (6) | 0.0114 (1) | 0.0323 (8) | 0.0042 (3) | 0.0069 (6) | 0.0152 (3) | 0.0260 (9) | 5.22 |
| Contracted JT | 0.0059 (5) | 0.0248 (4) | 0.0121 (1) | 0.0140 (7) | 0.0287 (7) | 0.0039 (2) | 0.0048 (4) | 0.0150 (1) | 0.0237 (5) | 4 |
| Clark | 0.0746 (8) | 0.0396 (10) | 0.0223 (9) | 0.0352 (11) | 0.0981 (12) | 0.0038 (1) | 0.0048 (4) | 0.0540 (9) | 0.0248 (7) | 7.89 |
| Squared Chi-squared | 0.0692 (7) | 0.0366 (9) | 0.0215 (8) | 0.0352 (11) | 0.1037 (13) | 0.0038 (1) | 0.0047 (3) | 0.0477 (8) | 0.0241 (6) | 7.33 |
| Average () | 0.0036 (3) | 0.0233 (2) | 0.0128 (3) | 0.0129 (2) | 0.0257 (5) | 0.0039 (2) | 0.0047 (3) | 0.0151 (2) | 0.0235 (4) | 2.88 |
| Divergence | 0.0746 (8) | 0.0366 (9) | 0.0223 (9) | 0.0352 (11) | 0.0981 (12) | 0.0038 (1) | 0.0048 (4) | 0.0540 (9) | 0.0248 (7) | 7.78 |
| Hassanat | 0.0155 (9) | 0.0667 (11) | 0.0592 (10) | 0.0349 (10) | 0.0896 (11) | 0.0563 (4) | 0.0772 (8) | 0.0604 (10) | 0.0864 (11) | 9.33 |
| Whittaker’s Index association | 0.0036 (3) | 0.0210 (1) | 0.0178 (7) | 0.0130 (3) | 0.0333 (9) | 0.0042 (3) | 0.0070 (7) | 0.0156 (5) | 0.0263 (10) | 5.33 |
| Distance Measure | Data Set | Average Rank | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| NC-CRIME | CONCRETE-COMP | AIRFOIL-NOISE | MUNICH-RENT | UPDRS-MOTOR | HEAD-CIRCUM | CYCLE-PP | HOUR | CAL-HOUSING | ||
| Euclidean | 0.0063 (6) | 0.0350 (4) | 0.0145 (3) | 0.0177 (7) | 0.0535 (5) | 0.0050 (2) | 0.0064 (3) | 0.0236 (1) | 0.0385 (5) | 3.89 |
| Manhattan | 0.0041 (3) | 0.0405 (8) | 0.0145 (3) | 0.0174 (5) | 0.0470 (1) | 0.0050 (2) | 0.0062 (1) | 0.0254 (7) | 0.0378 (2) | 3.56 |
| Chebychev | 0.0085 (8) | 0.0398 (7) | 0.0142 (1) | 0.0192 (8) | 0.0624 (6) | 0.0051 (3) | 0.0067 (5) | 0.0256 (8) | 0.0402 (6) | 5.78 |
| Canberra | 0.0040 (2) | 0.0389 (6) | 0.0149 (5) | 0.0172 (4) | 0.0474 (2) | 0.0050 (2) | 0.0062 (1) | 0.0252 (6) | 0.0375 (1) | 3.22 |
| Soergel | 0.0040 (2) | 0.0389 (6) | 0.0149 (5) | 0.0172 (4) | 0.0474 (2) | 0.0050 (2) | 0.0062 (1) | 0.0252 (6) | 0.0375 (1) | 3.22 |
| Lorentzian | 0.0037 (1) | 0.0419 (9) | 0.0143 (3) | 0.0169 (3) | 0.0470 (1) | 0.0050 (2) | 0.0062 (1) | 0.0256 (8) | 0.0378 (2) | 3.33 |
| Cosine | 0.0067 (7) | 0.0343 (2) | 0.0219 (7) | 0.0156 (1) | 0.0663 (7) | 0.0054 (4) | 0.0100 (7) | 0.0246 (4) | 0.0429 (8) | 4.78 |
| Contracted JT | 0.0067 (7) | 0.0345 (3) | 0.0141 (2) | 0.0175 (6) | 0.0527 (3) | 0.0050 (2) | 0.0066 (4) | 0.0237 (2) | 0.0382 (4) | 3.67 |
| Clark | 0.0550 (11) | 0.0435 (10) | 0.0304 (9) | 0.0560 (10) | 0.1505 (10) | 0.0049 (1) | 0.0063 (2) | 0.0716 (11) | 0.0407 (7) | 7.89 |
| Squared Chi-squared | 0.0506 (10) | 0.0459 (11) | 0.0231 (8) | 0.0560 (10) | 0.1268 (11) | 0.0050 (2) | 0.0064 (3) | 0.0685 (9) | 0.0392 (5) | 7.67 |
| Average () | 0.0046 (5) | 0.0367 (5) | 0.0146 (4) | 0.0175 (6) | 0.0533 (4) | 0.0050 (2) | 0.0064 (3) | 0.0245 (3) | 0.0379 (3) | 3.88 |
| Divergence | 0.0550 (11) | 0.0435 (10) | 0.0304 (9) | 0.0560 (10) | 0.1505 (10) | 0.0049 (1) | 0.0063 (2) | 0.0716 (11) | 0.0407 (7) | 7.89 |
| Hassanat | 0.0266 (9) | 0.0963 (12) | 0.0679 (10) | 0.0558 (9) | 0.0982 (9) | 0.0582 (5) | 0.1019 (7) | 0.0701 (10) | 0.1173 (11) | 9.11 |
| Whittaker’s Index association | 0.0042 (4) | 0.0312 (1) | 0.0214 (6) | 0.0159 (2) | 0.0678 (8) | 0.0050 (2) | 0.0099 (6) | 0.0247 (5) | 0.0435 (9) | 4.78 |
| Distance Measure | Data Set | Average Rank | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| NC-CRIME | CONCRETE-COMP | AIRFOIL-NOISE | MUNICH-RENT | UPDRS-MOTOR | HEAD-CIRCUM | CYCLE-PP | HOUR | CAL-HOUSING | ||
| Euclidean | 0.0073 (6) | 0.0458 (3) | 0.0165 (5) | 0.0213 (6) | 0.0535 (5) | 0.0062 (3) | 0.0078 (4) | 0.0323 (1) | 0.0521 (3) | 3.67 |
| Manhattan | 0.0050 (3) | 0.0547 (9) | 0.0160 (2) | 0.0211 (5) | 0.0470 (1) | 0.0061 (2) | 0.0076 (2) | 0.0349 (7) | 0.0502 (1) | 3.44 |
| Chebychev | 0.0103 (8) | 0.0498 (5) | 0.0164 (4) | 0.0245 (8) | 0.0624 (6) | 0.0062 (3) | 0.0081 (6) | 0.0344 (5) | 0.0552 (6) | 5.67 |
| Canberra | 0.0047 (2) | 0.0522 (7) | 0.0169 (6) | 0.0202 (3) | 0.0474 (2) | 0.0060 (1) | 0.0076 (2) | 0.0345 (6) | 0.0502 (1) | 3.33 |
| Soergel | 0.0047 (2) | 0.0522 (7) | 0.0169 (6) | 0.0202 (3) | 0.0474 (2) | 0.0060 (1) | 0.0076 (2) | 0.0345 (6) | 0.0502 (1) | 3.33 |
| Lorentzian | 0.0045 (1) | 0.0569 (11) | 0.0156 (1) | 0.0206 (4) | 0.0470 (1) | 0.0061 (2) | 0.0075 (1) | 0.0351 (8) | 0.0502 (1) | 3.33 |
| Cosine | 0.0072 (5) | 0.0449 (2) | 0.0263 (8) | 0.0185 (1) | 0.0633 (7) | 0.0067 (5) | 0.0129 (8) | 0.0326 (3) | 0.0591 (8) | 5 |
| Contracted JT | 0.0075 (7) | 0.0456 (10) | 0.0162 (3) | 0.0211 (5) | 0.0527 (3) | 0.0061 (2) | 0.0079 (5) | 0.0325 (2) | 0.0524 (4) | 4.56 |
| Clark | 0.0291 (9) | 0.0518 (6) | 0.0384 (10) | 0.0803 (10) | 0.1505 (9) | 0.0060 (1) | 0.0078 (4) | 0.0804 (10) | 0.0552 (6) | 7.22 |
| Squared Chi-squared | 0.0303 (10) | 0.0544 (8) | 0.0275 (9) | 0.0803 (10) | 0.1268 (10) | 0.0061 (2) | 0.0079 (5) | 0.0792 (9) | 0.0534 (5) | 7.56 |
| Average () | 0.0057 (4) | 0.0487 (4) | 0.0165 (5) | 0.0220 (7) | 0.0533 (4) | 0.0062 (3) | 0.0077 (3) | 0.0335 (4) | 0.0511 (2) | 4.0 |
| Divergence | 0.0291 (9) | 0.0518 (6) | 0.0384 (10) | 0.0803 (10) | 0.1505 (9) | 0.0060 (1) | 0.0078 (4) | 0.0804 (10) | 0.0552 (6) | 7.22 |
| Hassanat | 0.0376 (11) | 0.1271 (12) | 0.0630 (11) | 0.0801 (9) | 0.0982 (8) | 0.0548 (6) | 0.0127 (7) | 0.1330 (11) | 0.1554 (9) | 9.33 |
| Whittaker’s Index association | 0.0047 (2) | 0.0415 (1) | 0.0251 (7) | 0.0188 (2) | 0.0678 (7) | 0.0066 (4) | 0.0076 (2) | 0.0335 (4) | 0.0590 (7) | 4 |
| Distance Measure | Data Set | Average Rank | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| NC-CRIME | CONCRETE-COMP | AIRFOIL-NOISE | MUNICH-RENT | UPDRS-MOTOR | HEAD-CIRCUM | CYCLE-PP | HOUR | CAL-HOUSING | ||
| Euclidean | 0.5446 (2) | 0.5844 (1) | 0.1316 (1) | 1.6198 (4) | 10.524 (2) | 9.0639 (7) | 16.1634 (3) | 65.4357 (9) | 75.7579 (1) | 3.33 |
| Manhattan | 0.5498 (3) | 0.818 (12) | 0.1045 (12) | 1.8028 (6) | 10.364 (1) | 8.5893 (2) | 18.51 (10) | 63.3749 (4) | 77.5216 (2) | 5.78 |
| Chebychev | 0.6044 (9) | 0.5906 (2) | 0.9668 (7) | 3.0618 (13) | 13.593 (10) | 8.9278 (6) | 17.4414 (7) | 63.6503 (5) | 86.1188 (10) | 7.67 |
| Canberra | 0.5899 (8) | 0.5954 (3) | 0.9402 (4) | 1.8594 (8) | 10.826 (3) | 8.5108 (1) | 16.5988 (4) | 65.7512 (10) | 80.164 (5) | 5.11 |
| Soergel | 0.5227 (1) | 0.6073 (4) | 0.8939 (2) | 1.8247 (7) | 12.143 (8) | 9.6888 (10) | 17.7741 (8) | 65.3165 (8) | 83.2344 (8) | 6.22 |
| Lorentzian | 0.7613 (14) | 0.7697 (11) | 1.2644 (14) | 3.2461 (14) | 26.761 (13) | 13.4067 (14) | 24.3586 (14) | 149.57 (14) | 156.521 (14) | 13.56 |
| Cosine | 0.5604 (6) | 0.6299 (5) | 1.0400 (13) | 1.946 (10) | 11.805 (6) | 10.1804 (12) | 19.8549 (12) | 78.3711 (11) | 94.7818 (13) | 9.78 |
| Contracted JT | 0.5682 (7) | 0.6525 (9) | 0.9802 (9) | 1.8632 (9) | 11.362 (4) | 8.7091 (4) | 16.7185 (5) | 65.1808 (7) | 84.1575 (9) | 7.00 |
| Clark | 0.6907 (12) | 0.6334 (6) | 0.9655 (5) | 1.5661 (3) | 12.752 (9) | 9.4176 (9) | 17.2851 (6) | 56.4671 (3) | 80.421 (6) | 6.33 |
| Squared Chi-squared | 0.554 (4) | 0.6351 (7) | 0.9660 (6) | 1.4994 (1) | 11.9517 (7) | 8.7754 (5) | 15.9783 (2) | 47.3696 (2) | 78.1152 (3) | 4.67 |
| Average | 0.5543 (5) | 0.607 (4) | 0.9069 (3) | 1.7472 (5) | 11.6386 (5) | 9.1459 (8) | 15.9075 (1) | 64.6276 (6) | 82.6535 (7) | 4.89 |
| Divergence | 0.608 (10) | 0.6077 (4) | 0.9719 (8) | 1.5152 (2) | 12.14 (8) | 8.6737 (3) | 18.1009 (9) | 47.3471 (1) | 78.7135 (4) | 5.44 |
| Hassanat | 0.7566 (13) | 0.6872 (10) | 1.0079 (13) | 2.2696 (12) | 18.315 (12) | 10.7503 (13) | 21.5964 (13) | 93.594 (13) | 92.7772 (12) | 12.33 |
| Whittaker | 0.6154 (11) | 0.6385 (8) | 1.0025 (9) | 1.9555 (11) | 14.668 (11) | 10.1414 (11) | 19.4346 (11) | 81.7056 (12) | 91.5862 (11) | 10.56 |
| Distance Measure | Data Set | Average Rank | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| NC-CRIME | CONCRETE-COMP | AIRFOIL-NOISE | MUNICH-RENT | UPDRS-MOTOR | HEAD-CIRCUM | CYCLE-PP | HOUR | CAL-HOUSING | ||
| Euclidean | 0.5708 (2) | 0.5709 (1) | 0.8935 (2) | 1.6198 (4) | 10.495 (1) | 8.9081 (5) | 15.9607 (2) | 63.2521 (5) | 76.2212 (1) | 2.6 |
| Manhattan | 0.6034 (6) | 0.594 (2) | 0.9196 (4) | 1.8028 (6) | 10.517 (2) | 8.2911 (1) | 17.2263 (9) | 66.1123 (9) | 77.8895 (2) | 4.6 |
| Chebychev | 0.539 (1) | 0.6171 (5) | 1.1711 (10) | 2.0618 (11) | 14.732 (9) | 9.3347 (8) | 17.9897 (10) | 61.1169 (4) | 81.1524 (6) | 7.1 |
| Canberra | 0.5395 (1) | 0.5937 (2) | 0.9097 (3) | 1.8594 (8) | 10.806 (3) | 8.6402 (2) | 16.628 (4) | 65.9869 (8) | 82.4209 (8) | 4.3 |
| Soergel | 0.5878 (3) | 0.596 (3) | 0.9583 (5) | 1.8247 (7) | 11.584 (5) | 8.9926 (6) | 16.9919(8) | 65.3066 (6) | 81.9699 (7) | 5.6 |
| Lorentzian | 0.75 (9) | 0.7826 (10) | 2.0282 (11) | 3.2461 (13) | 25.827 (12) | 13.44 (14) | 23.1625 (14) | 148.494 (14) | 156.957 (13) | 12.2 |
| Cosine | 0.6181 (7) | 0.6827 (8) | 0.9902 (6) | 1.946 (9) | 11.799 (7) | 10.179 (11) | 19.1273 (12) | 78.2216 (11) | 97.3233 (12) | 9.2 |
| Contracted JT | 0.6053 (5) | 0.5958 (3) | 0.9215 (4) | 1.8632 (8) | 11.209 (4) | 8.7274 (4) | 16.9739 (7) | 65.8887 (7) | 190.639 (14) | 6.2 |
| Clark | 0.6513 (8) | 0.6448 (6) | 0.9245 (4) | 1.5661 (3) | 12.109 (8) | 9.343 (9) | 16.8576 (6) | 56.6508 (3) | 80.3316 (5) | 5.8 |
| Squared Chi-squared | 0.8069 (10) | 0.6165 (5) | 0.9978 (7) | 1.4994 (1) | 11.734 (6) | 9.5527 (10) | 15.9735 (3) | 51.4523 (2) | 78.0933 (3) | 5.2 |
| Average | 0.57 (2) | 0.6041 (3) | 0.8823 (1) | 1.7472 (5) | 11.5787 (5) | 9.0538 (7) | 15.846 (1) | 66.4976 (10) | 83.7506 (9) | 4.8 |
| Divergence | 0.5989 (4) | 0.6124 (4) | 1.0063 (8) | 1.5152 (2) | 12.115 (8) | 8.665 (3) | 16.7336 (5) | 47.2858 (1) | 78.5157 (4) | 4.3 |
| Hassanat | 0.6543 (8) | 0.7225 (9) | 1.0487 (9) | 2.2696 (12) | 18.6056 (11) | 11.2559 (13) | 19.8263 (13) | 95.3304 (13) | 92.7626 (11) | 11.0 |
| Whittaker | 0.5744 (2) | 0.6718 (7) | 0.9935 (6) | 1.9555 (10) | 15.3884 (10) | 10.4403 (12) | 18.2015 (11) | 87.7859 (12) | 91.691 (10) | 8.9 |
| Distance Measure | Data Set | Average Rank | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| NC-CRIME | CONCRETE-COMP | AIRFOIL-NOISE | MUNICH-RENT | UPDRS-MOTOR | HEAD-CIRCUM | CYCLE-PP | HOUR | CAL-HOUSING | ||
| Euclidean | 0.6173 (9) | 0.5747 (1) | 1.1302 (12) | 1.8723 (8) | 11.5164 (4) | 8.8205 (6) | 16.0187 (2) | 64.775 (6) | 74.3069 (1) | 5.4 |
| Manhattan | 0.5877 (7) | 0.627 (6) | 1.0535 (9) | 1.7588 (5) | 11.1217 (2) | 8.2967 (1) | 16.273 (6) | 61.1129 (4) | 77.543 (2) | 4.7 |
| Chebychev | 0.6173 (9) | 0.6042 (3) | 0.9624 (5) | 1.7797 (6) | 12.2382 (8) | 9.296 (9) | 17.5824 (9) | 67.123 (9) | 82.936 (6) | 7.1 |
| Canberra | 0.514 (1) | 0.608 (4) | 1.0633 (10) | 1.905 (9) | 10.8455 (1) | 8.4855 (2) | 16.9752 (8) | 65.7854 (8) | 79.529 (4) | 5.2 |
| Soergel | 0.6495 (10) | 0.605 (4) | 0.891 (2) | 2.1117 (12) | 11.6266 (6) | 8.7794 (5) | 17.6685 (10) | 65.14 (7) | 83.0972 (7) | 7.0 |
| Lorentzian | 0.7376 (11) | 0.8223 (11) | 1.2033 (13) | 3.1173 (14) | 25.8591 (14) | 13.592 (14) | 24.2913 (13) | 147.046 (14) | 158.0938 (14) | 13.1 |
| Cosine | 0.5593 (4) | 0.6235 (5) | 1.1075 (11) | 1.9934 (11) | 12.3925 (9) | 10.141 (12) | 18.8673 (14) | 76.3668 (11) | 98.0471 (12) | 9.9 |
| Contracted JT | 0.522 (2) | 0.5938 (2) | 0.9526 (4) | 1.7922 (7) | 11.2751 (3) | 8.6923 (4) | 17.2228 (4) | 69.6091 (10) | 127.1401 (13) | 5.4 |
| Clark | 0.5612 (4) | 0.6482 (7) | 1.0328 (8) | 1.562 (3) | 12.7084 (11) | 8.9228 (7) | 16.664 (7) | 60.9276 (3) | 80.3319 (5) | 6.1 |
| Squared Chi-squared | 0.5808 (6) | 0.6243 (5) | 1.0119 (7) | 1.5108 (2) | 11.7821 (7) | 9.6469 (10) | 16.0538 (3) | 50.4478 (1) | 88.5031 (9) | 5.6 |
| Average | 0.5702 (5) | 0.6105 (4) | 0.8769 (1) | 1.7392 (4) | 11.5745 (5) | 9.1333 (8) | 16.0031 (1) | 62.9529 (5) | 88 (8) | 4.6 |
| Divergence | 0.5354 (3) | 0.6829 (9) | 0.991 (6) | 1.4968 (1) | 12.6362 (10) | 8.6422 (3) | 16.2329 (5) | 50.6745 (2) | 78.5331 (3) | 4.7 |
| Hassanat | 0.6535 (9) | 0.7815 (10) | 1.0523 (9) | 2.2169 (13) | 18.0316 (13) | 11.0908 (13) | 18.2871 (12) | 89.8852 (13) | 92.8332 (11) | 11.4 |
| Whittaker | 0.5924 (8) | 0.6597 (8) | 0.9252 (3) | 1.926 (10) | 15.1091 (12) | 9.9105 (11) | 17.8684 (11) | 83.5628 (12) | 91.9307 (10) | 9.4 |
References
- Koenker, R.; Bassett, G., Jr. Regression quantiles. Econometrica 1978, 46, 33–50. [Google Scholar] [CrossRef]
- Newey, W.K.; Powell, J.L. Asymmetric least squares estimation and testing. Econometrica 1987, 55, 819–847. [Google Scholar] [CrossRef]
- Efron, B. Regression percentiles using asymmetric squared error loss. Statist. Sci. 1991, 1, 93–125. [Google Scholar]
- Abdous, B.; Remillard, B. Relating quantiles and expectiles under weighted-symmetry. Ann. Inst. Statist. Math. 1995, 47, 371–384. [Google Scholar] [CrossRef]
- Schnabel, S.; Eilers, P. An analysis of life expectancy and economic production using expectile frontier zones. Demogr. Res. 2009, 21, 109–134. [Google Scholar] [CrossRef]
- Sobotka, F.; Radice, R.; Marra, G.; Kneib, T. Estimating the relationship between women’s education and fertility in Botswana by using an instrumental variable approach to semiparametric expectile regression. J. R. Stat. Soc. C App. 2013, 62, 25–45. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, S.; Lai, K.K. Measuring financial risk with generalized asymmetric least squares regression. Appl. Soft Comput. 2011, 11, 5793–5800. [Google Scholar] [CrossRef]
- Kim, M.; Lee, S. Nonlinear expectile regression with application to value-at-risk and expected shortfall estimation. Comput. Stat. Data Anal. 2016, 94, 1–19. [Google Scholar] [CrossRef]
- Bellini, F.; Klar, B.; Müller, A.; Gianin, R.E. Generalized quantiles as risk measures. Insur. Math. Econ. 2014, 54, 41–48. [Google Scholar] [CrossRef]
- Keating, C.; Shadwick, W.F. A universal performance measure. J. Perform Meas. 2002, 6, 59–84. [Google Scholar]
- Schnabel, S.K.; Eilers, P.H. Optimal expectile smoothing. Comput. Statist. Data Anal. 2009, 53, 4168–4177. [Google Scholar] [CrossRef]
- Sobotka, F.; Kneib, T. Geoadditive expectile regression. Comput. Statist. Data Anal. 2012, 56, 755–767. [Google Scholar] [CrossRef]
- Yang, Y.; Zou, H. Nonparametric multiple expectile regression via ER-Boost. J. Stat. Comput. Simul. 2015, 85, 1442–1458. [Google Scholar] [CrossRef]
- Farooq, M.; Steinwart, I. An SVM-like approach for expectile regression. Comput. Stat. Data Anal. 2017, 109, 159–181. [Google Scholar] [CrossRef]
- Yao, Q.; Tong, H. Asymmetric least squares regression estimation: A nonparametric approach. J. Nonparametr. Statist. 1996, 6, 273–292. [Google Scholar] [CrossRef]
- Taunk, K.; De, S.; Verma, S.; Swetapadma, A. A brief review of nearest neighbor algorithm for learning and classification. In Proceedings of the 2019 International Conference on Intelligent Computing and Control Systems (ICCS), Madurai, India, 15–17 May 2019; pp. 1255–1260. [Google Scholar]
- Mulak, P.; Talhar, N. Analysis of distance measures using k-nearest neighbor algorithm on kdd dataset. Int. J. Sci. Res. 2015, 4, 2101–2104. [Google Scholar]
- Lopes, N.; Ribeiro, B. On the impact of distance metrics in instance-based learning algorithms. In Proceedings of the Iberian Conference on Pattern Recognition and Image Analysis, Santiago de Compostela, Spain, 17–19 June 2015; pp. 48–56. [Google Scholar]
- Chomboon, K.; Chujai, P.; Teerarassamee, P.; Kerdprasop, K.; Kerdprasop, N. An empirical study of distance metrics for k-nearest neighbor algorithm. In Proceedings of the 3rd International Conference on Industrial Application Engineering, Kitakyushu, Japan, 28–31 March 2015. [Google Scholar]
- Todeschini, R.; Ballabio, D.; Consonni, V.; Grisoni, F. A new concept of higher-order similarity and the role of distance/similarity measures in local classification methods. Chemom. Intell. Lab. Syst. 2016, 157, 50–57. [Google Scholar] [CrossRef]
- Prasath, V.B.; Alfeilat, H.A.A.; Lasassmeh, O.; Hassanat, A. Distance and similarity measures effect on the performance of k-nearest neighbor classifier-a review. arXiv 2017, arXiv:1708.04321. [Google Scholar]
- Lall, U.; Sharma, A. A nearest neighbor bootstrap for resampling hydrologic time series. Water Resour. Res. 1996, 32, 679–693. [Google Scholar] [CrossRef]
- Zhang, S.; Li, X.; Zong, M.; Zhu, X.; Wang, R. Efficient kNN classification with different numbers of nearest neighbors. IEEE Trans. Neural Networks Learn. Syst. 2017, 29, 1774–1785. [Google Scholar] [CrossRef]
- Zhang, S.; Cheng, D.; Deng, Z.; Zong, M.; Deng, X. A novel kNN algorithm with data-driven k parameter computation. Pattern Recognit. Lett. 2018, 109, 44–54. [Google Scholar] [CrossRef]
- Zhang, S.; Zong, M.; Sun, K.; Liu, Y.; Cheng, D. Efficient kNN algorithm based on graph sparse reconstruction. In Proceedings of the International Conference on Advanced Data Mining and Applications, Guilin, China, 19–21 December 2014; Springer: Cham, Switzerland, 2014; pp. 356–369. [Google Scholar]
- Eddelbuettel, D.; François, R. Rcpp: Seamless R and C++ integration. J. Stat. Softw. 2011, 40, 1–18. [Google Scholar] [CrossRef]
- Eddelbuettel, D.; Sanderson, C. RcppArmadillo: Accelerating R with high-performance C++ linear algebra. Comput. Stat. Data Anal. 2014, 71, 1054–1063. [Google Scholar] [CrossRef]
- Yang, Y. Erboost: Nonparametric Multiple Expectile Regression via ER-Boost. 2015. R Package Version 1.3. Available online: https://CRAN.R-project.org/package=erboost (accessed on 1 March 2021).
- Steinwart, I.; Thomann, P. LiquidSVM: A fast and versatile SVM package. arXiv 2017, arXiv:1702.06899. [Google Scholar]

| Data | Sample Sizes | Training Size | Test Size | Categorical | Features Continuous | Total |
|---|---|---|---|---|---|---|
| nc-crime | 630 | 441 | 189 | 3 | 16 | 19 |
| concrete-comp | 1030 | 721 | 309 | 0 | 8 | 8 |
| airfoil-noise | 1503 | 1052 | 451 | 1 | 4 | 5 |
| munich-rent | 2053 | 1437 | 616 | 8 | 4 | 12 |
| updrs-motor | 5875 | 4112 | 1763 | 1 | 18 | 19 |
| head-circum | 7020 | 4914 | 2106 | 0 | 4 | 5 |
| cycle-pp | 9568 | 6697 | 2871 | 0 | 5 | 5 |
| hour | 17,379 | 12,165 | 5214 | 7 | 5 | 12 |
| cal-housing | 20,639 | 14,447 | 6192 | 0 | 8 | 8 |
| Data Set | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| ex- | er-boost | ex-svm | ex- | er-boost | ex-svm | ex- | er-boost | ex-svm | |
| NC-CRIME | 0.0029 | 0.0083 | 0.0057 | 0.0040 | 0.0120 | 0.0061 | 0.0047 | 0.0120 | 0.0050 |
| CONCRETE-COMP | 0.0250 | 0.0397 | 0.0097 | 0.0389 | 0.0490 | 0.0127 | 0.0522 | 0.0452 | 0.0100 |
| AIRFOIL-NOISE | 0.0130 | 0.0401 | 0.0079 | 0.0149 | 0.047 | 0.0107 | 0.0169 | 0.0462 | 0.0080 |
| MUNICH-RENT | 0.0131 | 0.0137 | 0.0009 | 0.0172 | 0.0158 | 0.0012 | 0.0202 | 0.0135 | 0.0010 |
| UPDRS-MOTO | 0.0229 | 0.0538 | 0.0249 | 0.0474 | 0.0640 | 0.0291 | 0.0474 | 0.0545 | 0.026 |
| HEAD-CIRCUM | 0.0039 | 0.0246 | 0.0034 | 0.00500 | 0.0254 | 0.0040 | 0.0060 | 0.0193 | 0.0030 |
| CYCLE-PP | 0.0046 | 0.0354 | 0.0048 | 0.0062 | 0.0450 | 0.0053 | 0.0076 | 0.0389 | 0.0040 |
| HOUR | 0.0155 | 0.0289 | 0.0116 | 0.0252 | 0.0399 | 0.0152 | 0.0344 | 0.0383 | 0.0150 |
| CAL-HOUSING | 0.0231 | 0.0549 | 0.0191 | 0.0375 | 0.0761 | 0.0259 | 0.0552 | 0.0751 | 0.0260 |
| Data Set | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| ex- | er-boost | ex-svm | ex- | er-boost | ex-svm | ex- | er-boost | ex-svm | |
| NC-CRIME | 0.545 | 29.790 | 0.900 | 0.571 | 29.819 | 0.830 | 0.617 | 29.730 | 0.820 |
| CONCRETE-COMP | 0.584 | 2.924 | 2.740 | 0.572 | 3.032 | 2.740 | 0.575 | 2.867 | 2.410 |
| AIRFOIL-NOISE | 0.132 | 1.091 | 5.060 | 0.893 | 1.105 | 4.510 | 1.130 | 1.072 | 4.510 |
| MUNICH-RENT | 1.619 | 14.760 | 3.82 | 1.619 | 15.026 | 4.070 | 1.872 | 15.604 | 3.380 |
| UPDRS-MOTO | 10.524 | 163.30 | 6.91 | 10.495 | 167.24 | 59.52 | 11.516 | 163.63 | 56.49 |
| HEAD-CIRCUM | 9.064 | 2.512 | 44.320 | 8.908 | 2.664 | 39.43 | 8.821 | 2.819 | 41.20 |
| CYCLE-PP | 16.163 | 3.833 | 88.670 | 15.961 | 3.728 | 77.06 | 16.018 | 3.680 | 80.250 |
| HOUR | 65.435 | 126.30 | 386.160 | 63.252 | 121.820 | 343.23 | 64.775 | 120.270 | 303.550 |
| CAL-HOUSING | 75.757 | 54.780 | 381.12 | 76.221 | 57.433 | 342.99 | 74.301 | 53.620 | 340.69 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Farooq, M.; Sarfraz, S.; Chesneau, C.; Ul Hassan, M.; Raza, M.A.; Sherwani, R.A.K.; Jamal, F. Computing Expectiles Using k-Nearest Neighbours Approach. Symmetry 2021, 13, 645. https://doi.org/10.3390/sym13040645
Farooq M, Sarfraz S, Chesneau C, Ul Hassan M, Raza MA, Sherwani RAK, Jamal F. Computing Expectiles Using k-Nearest Neighbours Approach. Symmetry. 2021; 13(4):645. https://doi.org/10.3390/sym13040645
Chicago/Turabian StyleFarooq, Muhammad, Sehrish Sarfraz, Christophe Chesneau, Mahmood Ul Hassan, Muhammad Ali Raza, Rehan Ahmad Khan Sherwani, and Farrukh Jamal. 2021. "Computing Expectiles Using k-Nearest Neighbours Approach" Symmetry 13, no. 4: 645. https://doi.org/10.3390/sym13040645
APA StyleFarooq, M., Sarfraz, S., Chesneau, C., Ul Hassan, M., Raza, M. A., Sherwani, R. A. K., & Jamal, F. (2021). Computing Expectiles Using k-Nearest Neighbours Approach. Symmetry, 13(4), 645. https://doi.org/10.3390/sym13040645