
Technology Hotspot Tracking: Topic Discovery and Evolution of China’s Blockchain Patents Based on a Dynamic LDA Model


Abstract
1. Introduction
- (1)
- We propose a time-based dynamic latent Dirichlet allocation (TDLDA) modeling method based on a probabilistic graph model and knowledge representation learning for patent text mining.
- (2)
- We present a computational model, topic intensity (TI), that expresses the topic strength and evolution.
- (3)
- In order to evaluate the topic quality, we used the point-wise mutual information (PMI) [9] value which can measure the word association to test the effectiveness of our proposed TDLDA model.
- (4)
- TDLDA is an effective model to extract hot topics and evolution trends of blockchain patent texts, which can help researchers more accurately grasp the research direction of blockchain technology.
2. Related Works
3. Construction of Blockchain Patent Text Based on Dynamic LDA Model
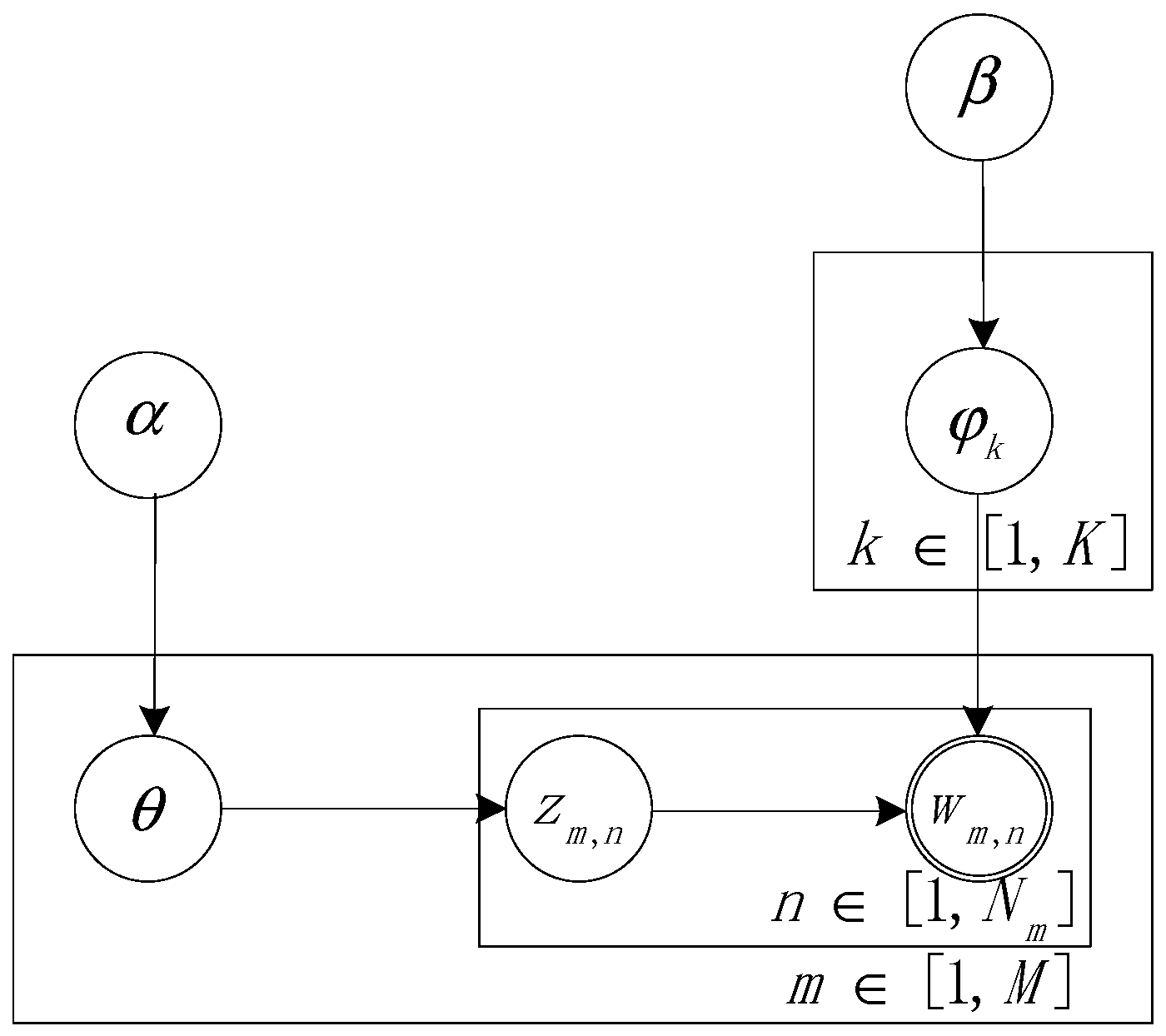
3.1. Foundation Theory for LDA
3.2. Time-Based Dynamic LDA Blockchain Patent Text Topic Construction Process
| Algorithm 1. Blockchain patent text subject mining process based on TDLDA model. |
| Input: Patent text data set , where D is a set of documents. Output: Topic set within each time period and the first n topic words according to probability. |
| 1 initialize D, , ; 2 initialize , ; 3 ; 4 repeat 5 for n = 1 to N 6 ; 7 for i = 1 to K 8 ; 9 ; 10 until convergence |
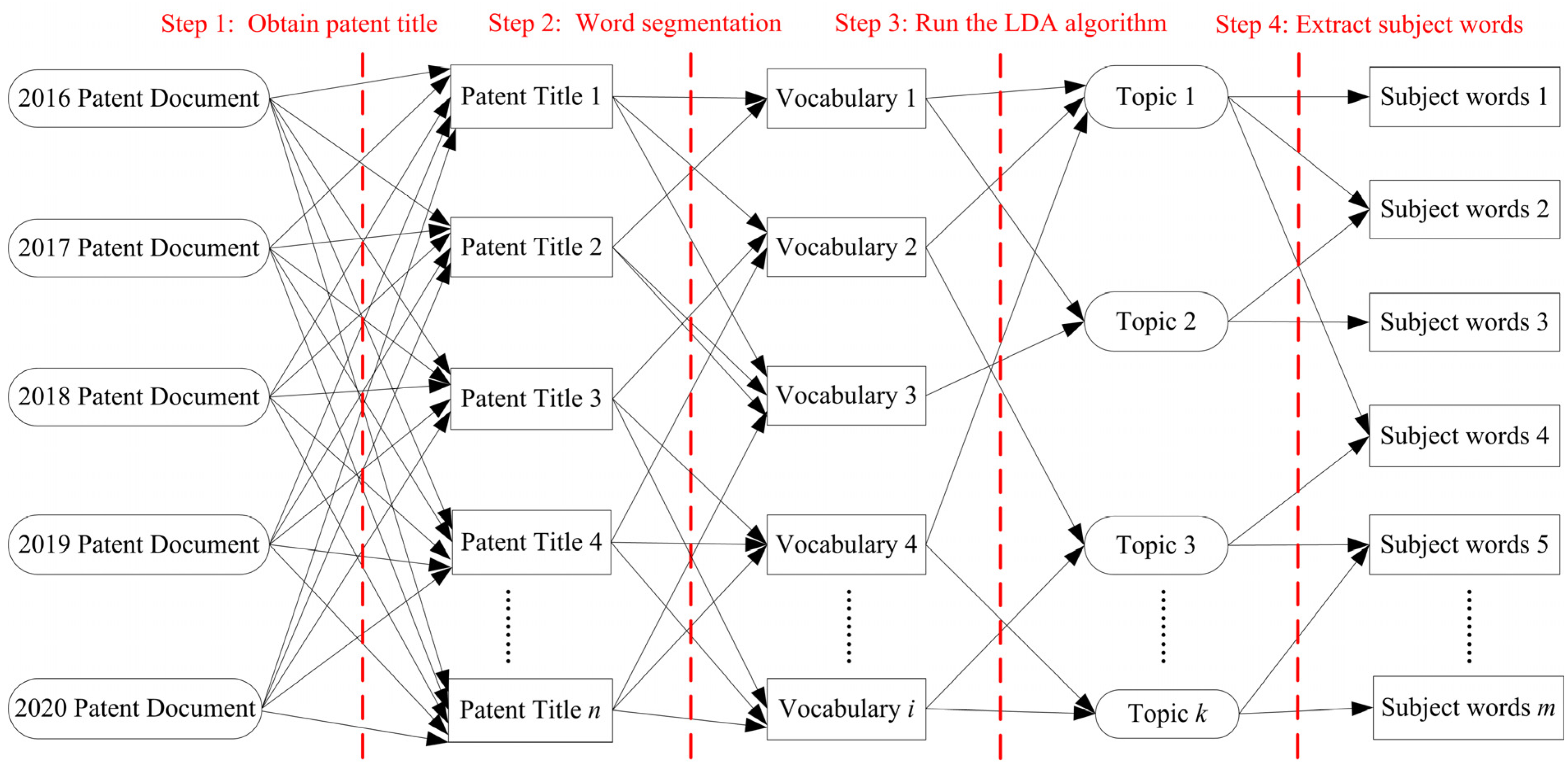
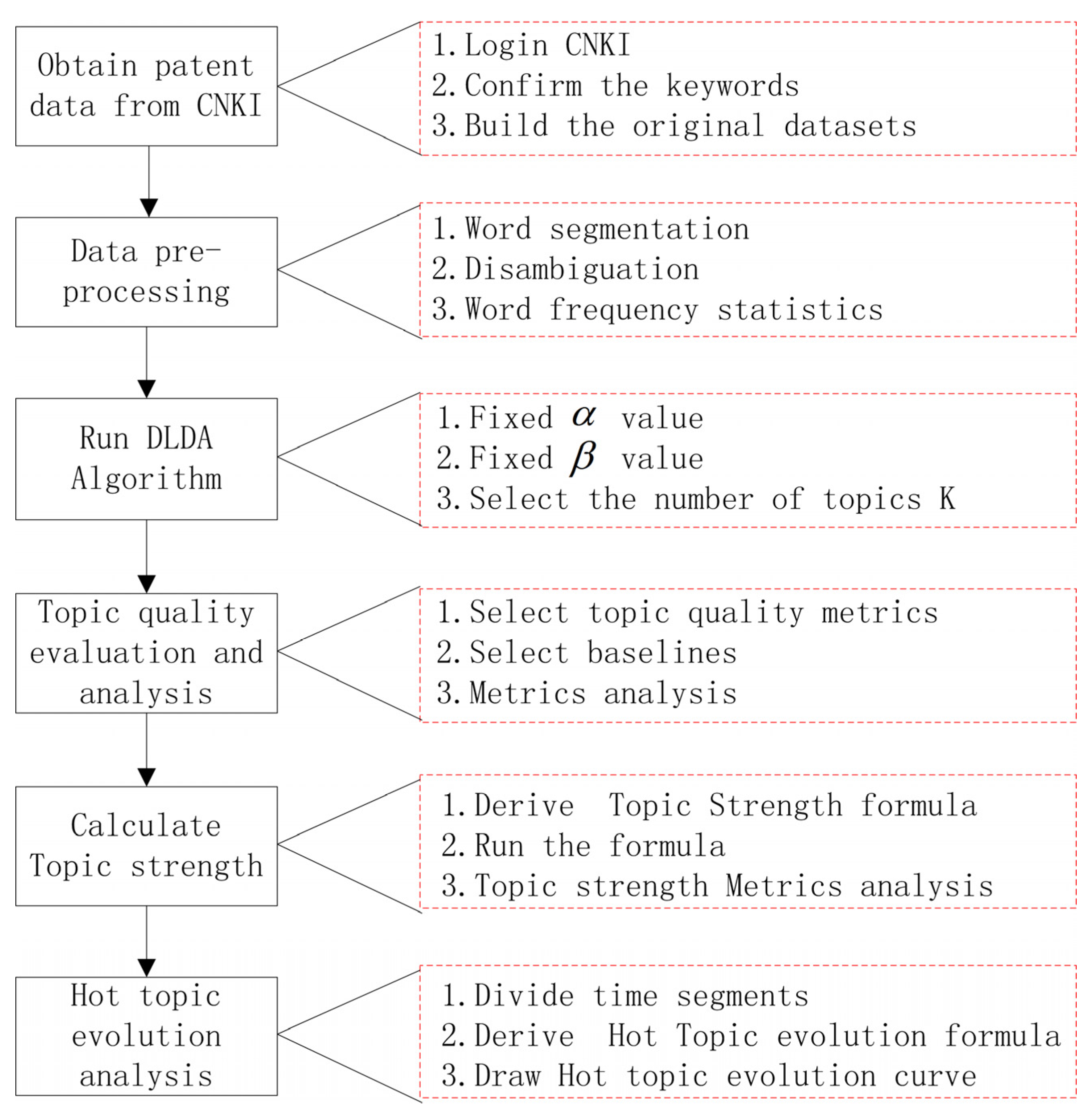
4. Data Source and Experimental Process
4.1. Data Source
4.2. TDLDA-Based Patent Text Topic Extraction Process
4.3. Topic Strength Calculation and Evolution Analysis Process
4.4. Experimental Environment and Related Parameter Settings
5. Experimental Results and Analysis
5.1. Hot Topic Discovery and Analysis of Topic Quality
5.1.1. Analysis of Hot Topics and Keywords
5.1.2. Topic Performance Metrics Evaluation
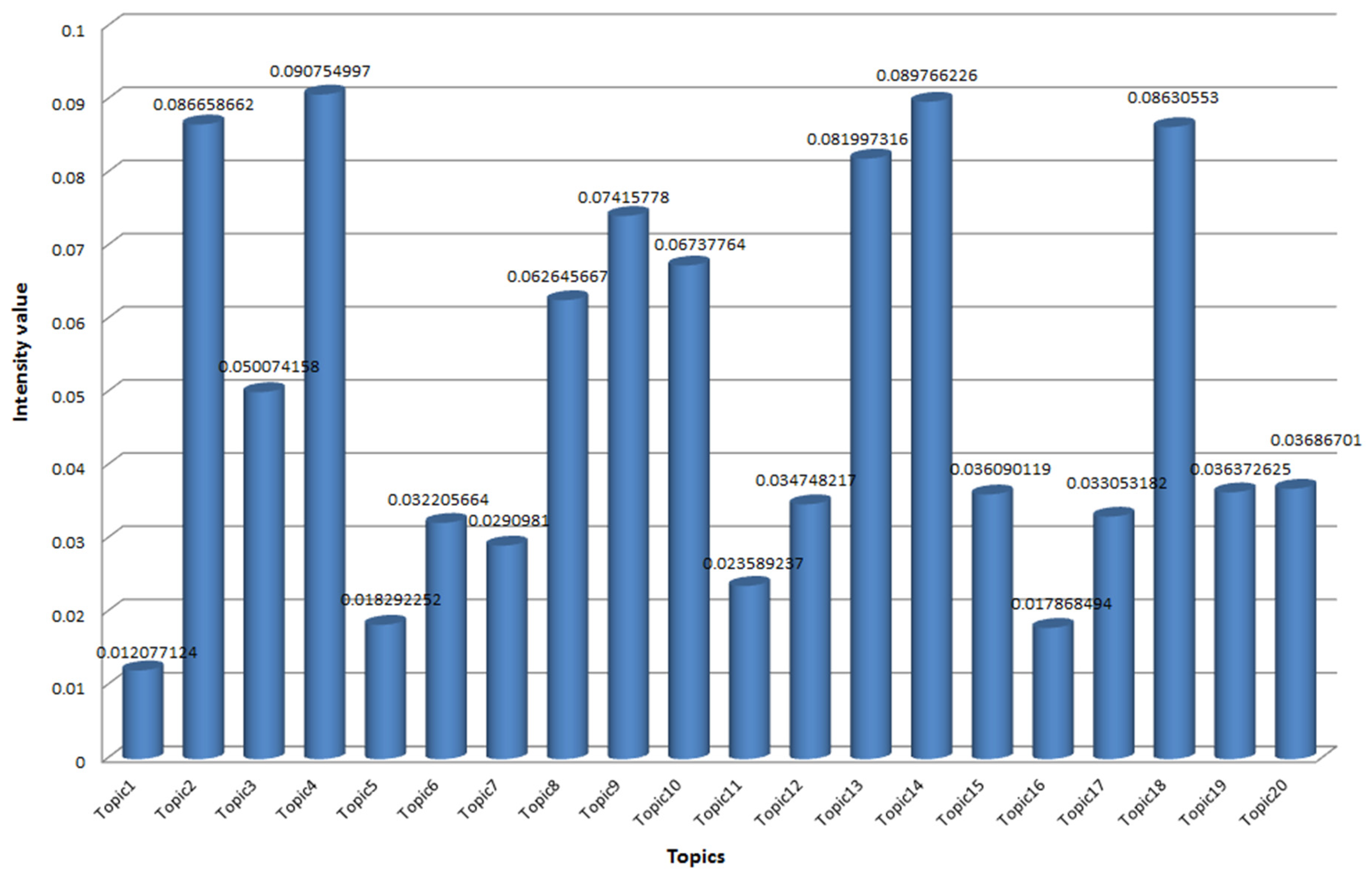
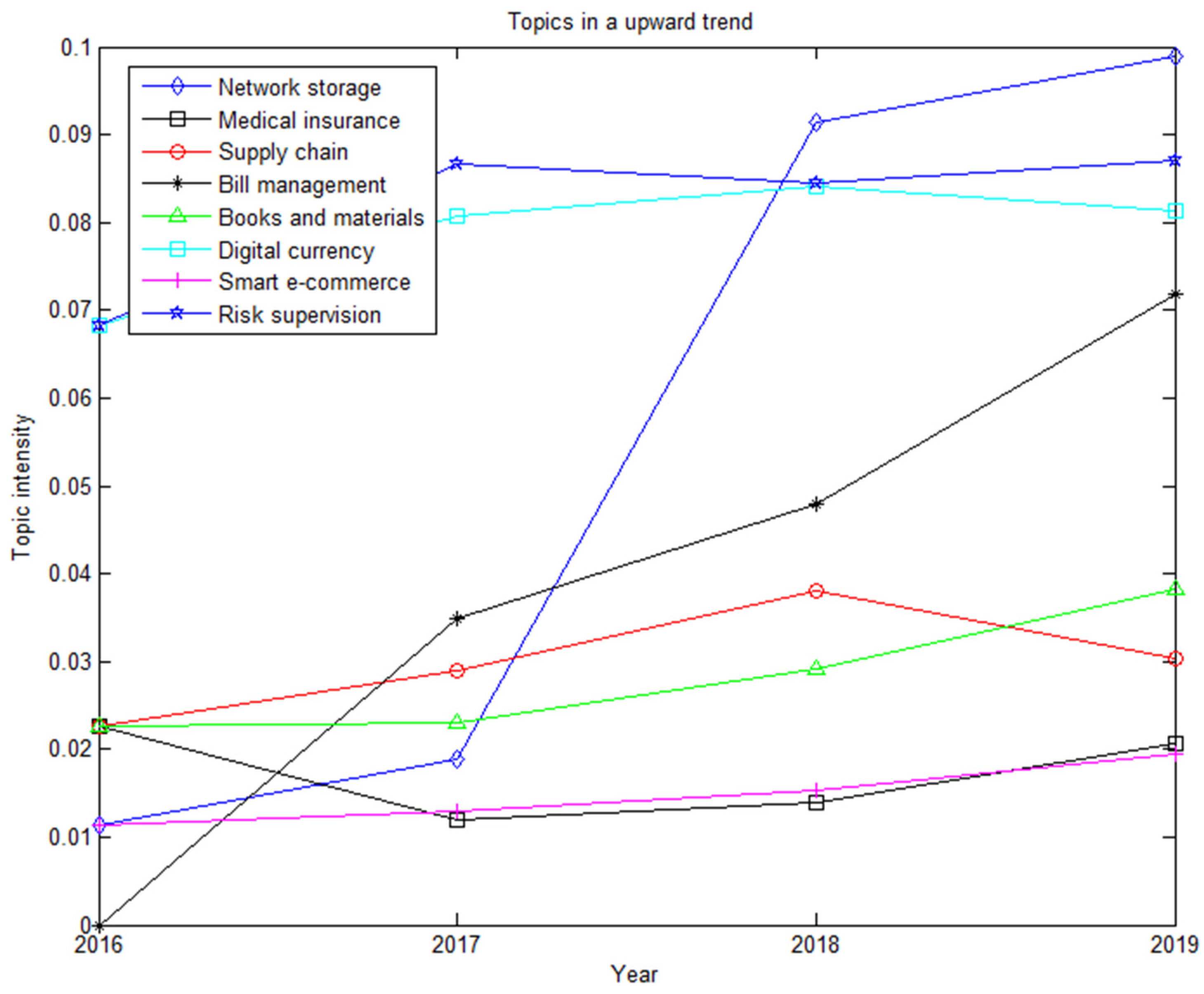
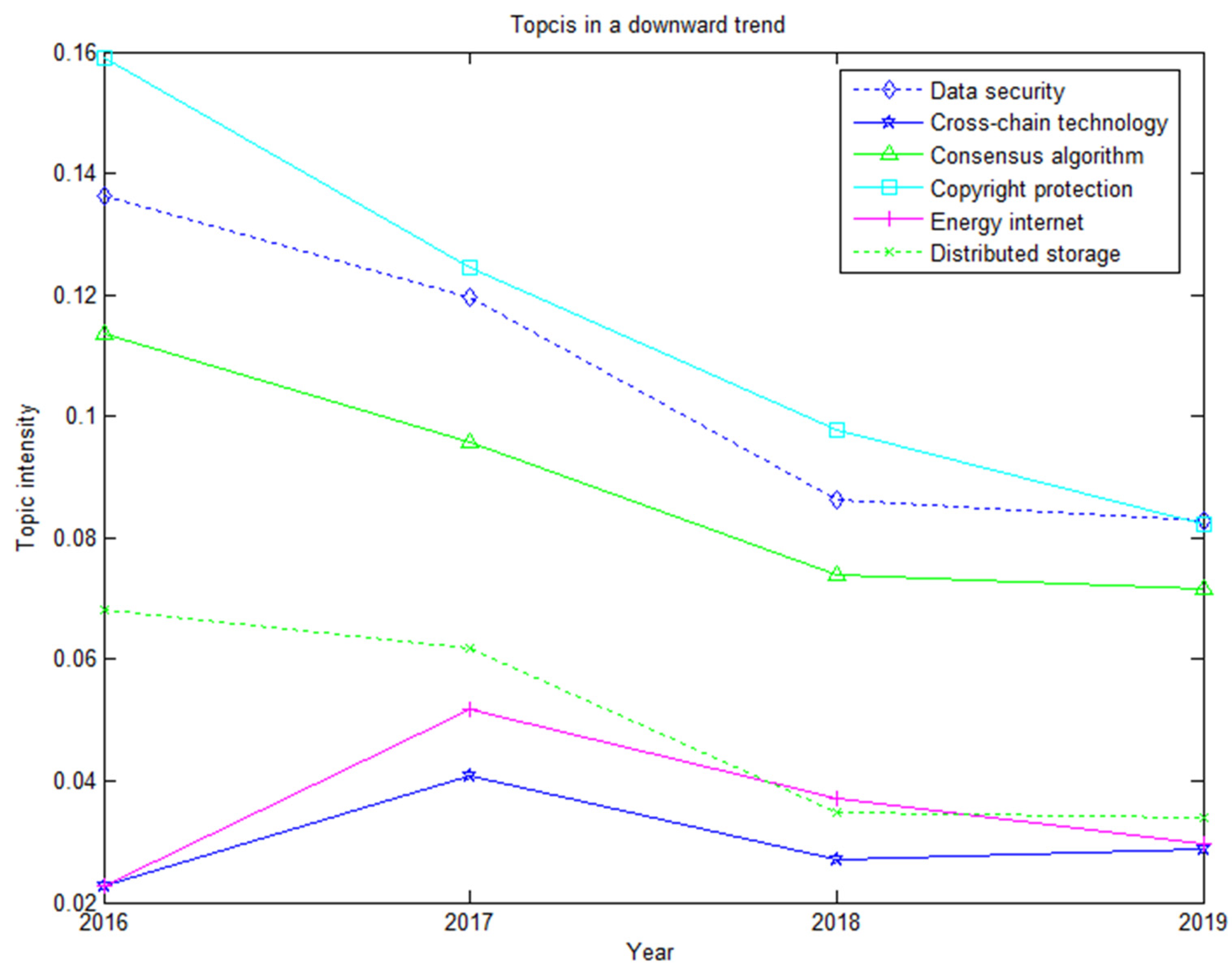
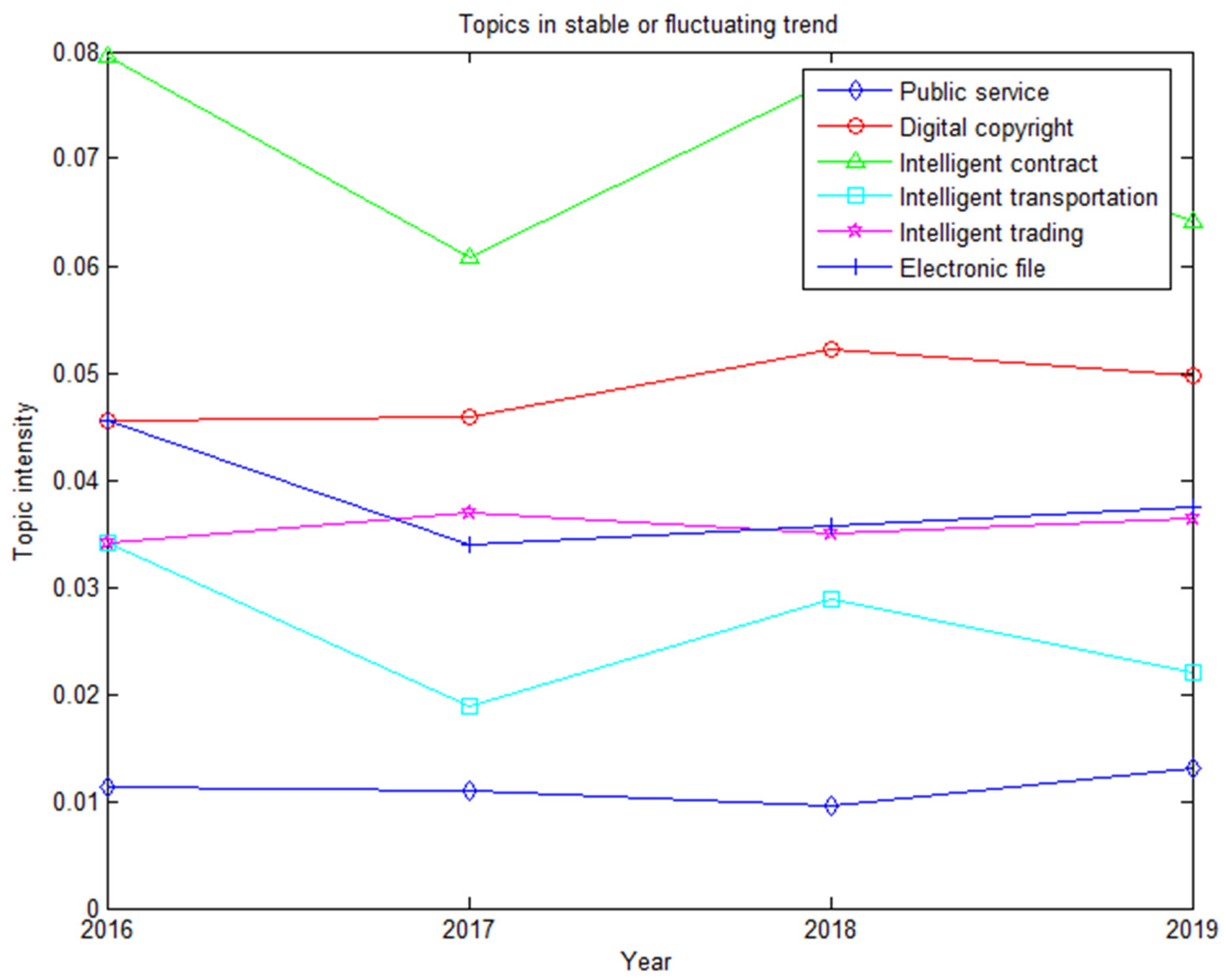
5.2. Blockchain Patent Hot Topic Evolution Analysis
5.2.1. Theoretical Basis of Topic Evolution
5.2.2. Topic Evolution Trend Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lee, H.J.; Oh, H. A Study on the Deduction and Diffusion of Promising Artificial Intelligence Technology for Sustainable Industrial Development. Sustainability 2020, 12, 5609. [Google Scholar] [CrossRef]
- Ampornphan, P.; Tongngam, S. Exploring Technology Influencers from Patent Data Using Association Rule Mining and Social Network Analysis. Information 2020, 11, 333. [Google Scholar] [CrossRef]
- Feng, L.; Zhang, H.; Chen, Y.; Lou, L. Scalable Dynamic Multi-Agent Practical Byzantine Fault-Tolerant Consensus in Permissioned Blockchain. Appl. Sci. 2018, 8, 1919. [Google Scholar] [CrossRef]
- Yang, H.; Liang, Y.; Yuan, J. Distributed Blockchain-Based Trusted Multidomain Collaboration for Mobile Edge Computing in 5G and Beyond. IEEE Trans. Ind. Inform. 2020, 16, 7094–7104. [Google Scholar] [CrossRef]
- Feng, L.; Zhang, H.; Tsai, W.; Sun, S. System architecturefor high-performance permissioned blockchains. Front. Comput. Sci. 2019, 13, 1151–1165. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Zuo, Y.; Zhao, J.; Xu, K. Word network topic model: A simple but general solution for short and imbalanced texts. Knowl. Inf. Syst. 2016, 48, 379–398. [Google Scholar] [CrossRef]
- Zuo, Y.; Wu, J.; Zhang, H. Topic Modeling of Short Texts: A Pseudo-Document View. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 2105–2114. [Google Scholar]
- Church, K.W.; Hanks, P. Word association norms, mutual information, and lexicography. Comput. Linguist. 1990, 16, 22–29. [Google Scholar]
- Li, S.; Hu, J.; Cui, Y.; Hu, J. DeepPatent: Patent classification with convolutional neural networks and word embedding. Scientometrics 2018, 117, 721–744. [Google Scholar] [CrossRef]
- Trappey, A.J.; Trappey, C.V.; Fan, C.Y.; Lee, I.J. Consumer driven product technology function deployment using social media and patent mining. Adv. Eng. Inform. 2018, 36, 120–129. [Google Scholar] [CrossRef]
- An, J.; Kim, K.; Mortara, L.; Lee, S. Deriving technology intelligence from patents: Preposition-based semantic analysis. J. Informetr. 2018, 12, 217–236. [Google Scholar] [CrossRef]
- Lei, L.; Qi, J.; Zheng, K. Patent Analytics Based on Feature Vector Space Model: A Case of IoT. IEEE Access 2019, 7, 45705–45715. [Google Scholar] [CrossRef]
- Kumari, R.; Jeong, J.Y.; Lee, B.H.; Choi, K.N.; Choi, K. Topic modelling and social network analysis of publications and patents in humanoid robot technology. J. Inf. Sci. 2019. [Google Scholar] [CrossRef]
- Park, S.; Jun, S. Patent Keyword Analysis of Disaster Artificial Intelligence Using Bayesian Network Modeling and Factor Analysis. Sustainability 2020, 12, 505. [Google Scholar] [CrossRef]
- Liu, Y.; Tang, A.; Sun, Z.; Tang, W. An integrated retrieval framework for similar questions: Word-semantic embedded label clustering—LDA with question life cycle. Inf. Sci. 2020, 537, 227–245. [Google Scholar] [CrossRef]
- Maier, D.; Waldherr, A.; Miltner, P.; Wiedemann, G.; Niekler, A.; Keinert, A.; Pfetsch, B.; Heyer, G.; Reber, U.; Häussler, T.; et al. Applying LDA Topic Modeling in Communication Research: Toward a Valid and Reliable Methodology. Commun. Methods Meas. 2018, 12, 93–118. [Google Scholar] [CrossRef]
- Wan, C.; Peng, Y.; Xiao, K.; Liu, X.; Jiang, T.; Liu, D. An association-constrained LDA model for joint extraction of product aspects and opinions. Inf. Sci. 2020, 519, 243–259. [Google Scholar] [CrossRef]
- Elkhadir, Z.; Mohammed, B. A cyber network attack detection based on GM Median Nearest Neighbors LDA. Comput. Secur. 2019, 86, 63–74. [Google Scholar] [CrossRef]
- Bastani, K.; Namavari, H.; Shaffer, J. Latent Dirichlet allocation (LDA) for topic modeling of the CFPB consumer complaints. Expert Syst. Appl. 2019, 127, 256–271. [Google Scholar] [CrossRef]
- Cao, Y.; Li, W.; Zheng, D. A hybrid recommendation approach using LDA and probabilistic matrix factorization. Clust. Comput. J. Netw. Softw. Tools Appl. 2019, 22, S8811–S8822. [Google Scholar] [CrossRef]
- Jeon, J.; Kim, M. Discovering Latent Topics with Saliency-Weighted LDA for Image Scene Understanding. IEEE Multimed. 2019, 26, 56–68. [Google Scholar] [CrossRef]
- Xu, Y.; Li, Y.; Liang, Y.; Cai, L. Topic-sentiment evolution over time: A manifold learning-based model for online news. J. Intell. Inf. Syst. 2019, 55, 27–49. [Google Scholar] [CrossRef]
- Hu, K.; Luo, Q.; Qi, K.; Yang, S.; Mao, J.; Fu, X.; Zheng, J.; Wu, H.; Guo, Y.; Zhu, Q. Understanding the topic evolution of scientific literatures like an evolving city: Using Google Word2Vec model and spatial autocorrelation analysis. Inf. Process. Manag. 2019, 56, 1185–1203. [Google Scholar] [CrossRef]
- Yang, M.; Qu, Q.; Chen, X.; Tu, W.; Shen, Y.; Zhu, J. Discovering author interest evolution in order-sensitive and Semantic-aware topic modeling. Inf. Sci. 2019, 486, 271–286. [Google Scholar] [CrossRef]
- Xu, Y.; Zhang, S.; Zhang, W.; Yang, S.; Shen, Y. Research Front Detection and Topic Evolution Based on Topological Structure and the PageRank Algorithm. Symmetry 2019, 11, 310. [Google Scholar] [CrossRef]
- Chae, B.K.; Park, E.O. Corporate Social Responsibility (CSR): A Survey of Topics and Trends Using Twitter Data and Topic Modeling. Sustainability 2018, 10, 2231. [Google Scholar] [CrossRef]
- Kim, J.M.; Kim, N.K.; Jung, Y.; Jun, S. Patent data analysis using functional count data model. Soft Comput. 2019, 23, 8815–8826. [Google Scholar] [CrossRef]
- Ren, Y.; Wang, Y.; Zhu, J. Spectral Learning for Supervised Topic Models. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 726–739. [Google Scholar] [CrossRef]
- Zhang, C.; Lu, S.; Zhang, C. A Novel Hot Topic Detection Framework with Integration of Image and Short Text Information from Twitter. IEEE Access 2019, 7, 9225–9231. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, H.; Liu, R. Experimental explorations on short text topic mining between LDA and NMF based Schemes. Knowl. Based Syst. 2019, 163, 1–13. [Google Scholar] [CrossRef]
- Martinez, A.M.; Kak, A.C. PCA versus LDA. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 228–233. [Google Scholar] [CrossRef]
- Blei, D.M. Probabilistic topic models. Commun. ACM 2012, 55, 77–84. [Google Scholar] [CrossRef]
- Shang, F.; Cheng, J.; Liu, Y. Bilinear Factor Matrix Norm Minimization for Robust PCA: Algorithms and Applications. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 2066–2080. [Google Scholar] [CrossRef]
- Jiang, Z.; Lin, Z.; Davis, L. Label Consistent K-SVD: Learning a Discriminative Dictionary for Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2651–2664. [Google Scholar] [CrossRef]
- Wang, J.; Fan, Y.; Feng, L. Research Hotspot Prediction and Regular Evolutionary Pattern Identification Based on NSFC Grants Using NMF and Semantic Retrieval. IEEE Access 2019, 7, 1–12. [Google Scholar] [CrossRef]
- Newman, D.; Karimi, S.; Cavedon, L. External evaluation of topic models. In Proceedings of the ADCS, Sydney, Australia, 4 December 2009; pp. 11–18. [Google Scholar]
- Rosario, J.; Mohamed, A.; Saverio, N. A Vocabulary for Growth: Topic Modeling of Content Popularity Evolution. IEEE Trans. Multimed. 2018, 20, 2683–2692. [Google Scholar]
- Cui, K. The Research and Implementation of Topic Evolution Based on LDA. Ph.D. Thesis, National University of Defense Technology, Changsha, China, 2010; pp. 18–26. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fields | Methods | Contexts |
|---|---|---|
| Patent text mining | [10] Convolutional neural networks | Patent information management and knowledge mining |
| [11] Consumer-driven product function | Identify customer needs in real time | |
| [12] Preposition-based semantic analysis | Overcomes the limitations of keyword-based network | |
| [13] Feature vector space model(FVSM) | Patents related to Internet of Things (IoT) technology | |
| [14] Social network analysis | Identify underlying topics inhumanoid robot technology | |
| [15] Bayesian network modeling | Analyze patent documents related to artificial intelligence | |
| Technical level | [16] WELQLC-QR | Improve the similar semanticsfor question retrieval |
| [17] Valid and reliable LDA | More accessible to communication researchers | |
| [18] AC-LDA | Capture the relationships hidden in local sentences | |
| [19] NN-LDA | Create anintrusion detection systems | |
| [20] Intelligent LDA | Explored their associated trends over time | |
| [21] NMF-LDA | Provide users with suggestions and selections | |
| [22] SwLDA | Mimics human perception behavior | |
| Topic evolution trend | [23] Manifold learning-based model | Explore topic-sentiment associate online news |
| [24] dDeep learning language model | How keyword semantics can invoketopic evolution | |
| [25] Semantic-aware dynamic model | Monitors the evolution of author interest | |
| [26] Graph-based theory | Research front detection and topic evolution | |
| [27] Computational content analysis | CSR-related conversations in the Twitter-sphere | |
| [28] Functional count data model | The patent data of Applecompany |
| Dataset | Alpha | Beta | Number of Topics | Numberof Documents | Dictionary Length | Number of Iterations |
|---|---|---|---|---|---|---|
| BC_patents_2016 | 0.2 | 0.1 | 10 | 67 | 11 | 999 |
| BC_patents_2017 | 0.2 | 0.1 | 20 | 573 | 64 | 999 |
| BC_patents_2018 | 0.2 | 0.1 | 20 | 2170 | 976 | 999 |
| BC_patents_2019 | 0.2 | 0.1 | 20 | 5355 | 1570 | 999 |
| BC_patents_16-19 | 0.2 | 0.1 | 20 | 8245 | 1985 | 999 |
| Serial Number | Topic | Topic Words |
|---|---|---|
| 1 | Public service | Scan code, logistics, mobile phone, computer room, rail traffic, public transport system, sell ticket, swiping card, access control system, face recognition |
| 2 | Data security | Encryption, transaction, account, secret key, data security, wallet, information, model, homomorphic, authority |
| 3 | Digital copyright | Terminal, identity, user, server, networking, information management, network systems, advertisement, trust, secret key |
| 4 | Network storage | Data processing, storage medium, server, relation, account number, network system, product, video |
| 5 | Medical insurance | Electronic, vote, Web page, case, authentication, evidence, identification photo, hospital, drug, medical treatment, prescription |
| 6 | Supply chain | Networking, framework, supply chain, finance, certificate, car, agricultural products, information security, cross-border, industry |
| 7 | Cross-chain technology | Cross-chain, business, domain name, partition, on chain, distributed, storage device, media, object, flow |
| 8 | Bill management | Electronic equipment, medium, data management, business, invoice, bill, verification, resource management, transaction, customer |
| 9 | Consensus algorithm | Consensus, mechanism, node, agreement, model, credibility, plan, Byzantium, vote, center, computing power |
| 10 | Intelligent contract | Intelligent, contract, resources, game, terminal, bracelet, communication, power grid, commodity trading, long range, insurance |
| 11 | Intelligent transportation | Recording, logistics, vehicle, coordination, drug, food, electric car, image, network, security, video, parking space |
| 12 | Books and materials | Data processing, electronic device, account book, authentication, digital certificate, resource allocation, book, work |
| 13 | Digital currency | Network, node, mining, fragmentation, account book, cluster, label, agreement, rule |
| 14 | Copyright protection | Assets, transaction, currency, copyright, content, platform, value, enterprise, bank, token, copyright protection |
| 15 | Intelligent trading | Keep accounts, agent, deploy, authority, account book, lottery, platform, product, client |
| 16 | Smart e-commerce | Evaluation, credit, private key, event, feature, e-commerce, community, user, signature |
| 17 | Energy internet | Distributed, trading System, energy, electricity, Internet, task, mode, dispatch, trading platform, power grid |
| 18 | Risk supervision | Electronic equipment, terminal equipment, transaction, public welfare, goods, digital certificate, client, insurance, risk, government affairs |
| 19 | Distributed storage | Storage system, file, distributed, business, structure, index, time, risk, client, certificate |
| 20 | Electronic file | Management system, query method, record, state, check, service platform, file, charging, positioning |
| Baseline | K = 20 | K = 40 | K = 60 | K = 80 | ||||
|---|---|---|---|---|---|---|---|---|
| Top10 | Top20 | Top10 | Top20 | Top10 | Top20 | Top10 | Top20 | |
| PCA | 0.1328 | 0.51765 | 0.39395 | 0.78558 | 0.77763 | 1.09517 | 1.11799 | 1.41249 |
| SVD | 0.4252 | 0.68815 | 0.43065 | 0.74698 | 0.78218 | 1.08732 | 1.09908 | 1.355 |
| TDLDA | 0.4634 | 1.36685 | 0.58643 | 1.35635 | 0.61522 | 1.43057 | 0.6032 | 1.3434 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Fan, Y.; Zhang, H.; Feng, L. Technology Hotspot Tracking: Topic Discovery and Evolution of China’s Blockchain Patents Based on a Dynamic LDA Model. Symmetry 2021, 13, 415. https://doi.org/10.3390/sym13030415
Wang J, Fan Y, Zhang H, Feng L. Technology Hotspot Tracking: Topic Discovery and Evolution of China’s Blockchain Patents Based on a Dynamic LDA Model. Symmetry. 2021; 13(3):415. https://doi.org/10.3390/sym13030415
Chicago/Turabian StyleWang, Jinli, Yong Fan, Hui Zhang, and Libo Feng. 2021. "Technology Hotspot Tracking: Topic Discovery and Evolution of China’s Blockchain Patents Based on a Dynamic LDA Model" Symmetry 13, no. 3: 415. https://doi.org/10.3390/sym13030415
APA StyleWang, J., Fan, Y., Zhang, H., & Feng, L. (2021). Technology Hotspot Tracking: Topic Discovery and Evolution of China’s Blockchain Patents Based on a Dynamic LDA Model. Symmetry, 13(3), 415. https://doi.org/10.3390/sym13030415