1. Introduction
Hearing-impaired people around the world use sign language as their medium for communication. However, sign language is not universal, with one hundred varieties used around the world [
1]. One of the most widely used types of sign language is American Sign Language (ASL), which is used in the United States, Canada, West Africa, and Southeast Asia and influences Thai Sign Language (TSL). Typically, global sign language is divided into two forms: gesture language and finger-spelling. Gesture language or sign language involves the use of hand gestures, facial expressions, and the use of mouths and noses to convey meanings and sentences. This type is used for communication between deaf people in everyday life, focusing on terms such as eating, ok, sleep, etc. Finger-spelling sign language is used for spelling letters related to the written language with one’s fingers and is used to spell people’ names, places, animals, and objects.
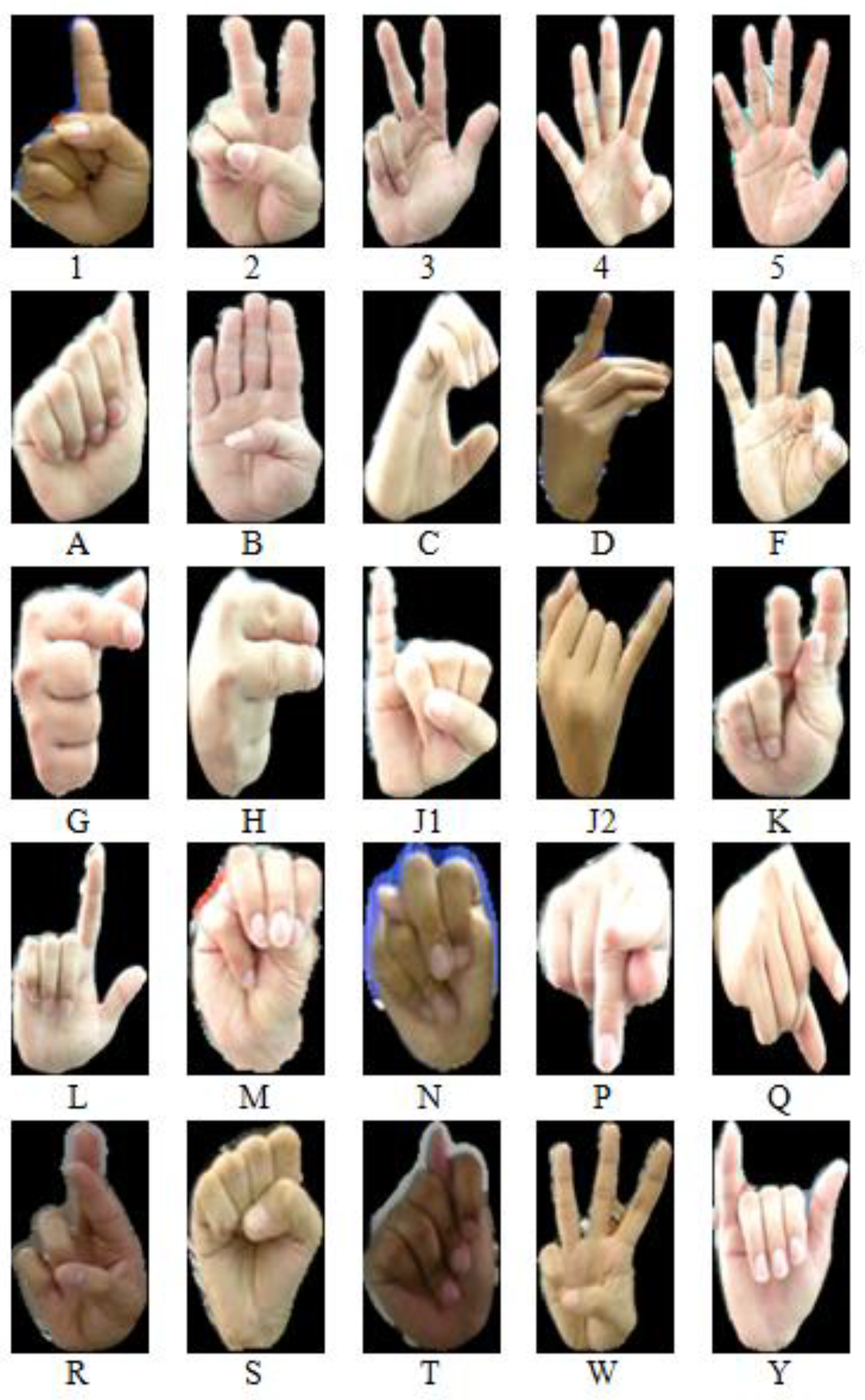
ASL is the foundation of Thai finger-spelling sign language (TFSL).The TFSL was invented in 1953 by Khunying Kamala Krairuek using American finger-spelling as a prototype to represent the 42 Thai consonants, 32 vowels, and 6 intonation marks [
2]. All forty-two Thai letters can be presented with a combination of twenty-five hand gestures. For this purpose, the number signs are combined with alphabet signs to create additional meanings. For example, the K sign combined with the 1 sign (K+1) meaning ‘ข’ (/k
h/). Consequently, TFSL strokes can be organized into three groups (one-stroke, two-stroke, and three-stroke groups) with 15 letters, 24 letters, and 3 letters, respectively. However, ‘ฃ’(/k
h/) and ‘ฅ’(/k
h/) have not been used since Thailand’s Royal Institute Dictionary announced their discontinuation [
3], and are no longer used in Thai finger-spelling sign language.
This study is part of a research series on TFSL recognition that focuses on one stroke performed by a signer standing in front of a blue background. Global and local features using support vector machine (SVM) on the radial basis function (RBF) kernel were applied and were able to achieve 91.20% accuracy [
4]; however, there were still problems with highly similar letters. Therefore, a new TFSL recognition system was developed by applying pyramid histogram of oriented gradient (PHOG) and local features with k-nearest neighbors (KNN), providing an accuracy up to 97.6% [
3]. However, past research has been conducted only using one-stroke, 15-character TFSL under a simple background, which does not cover all types of TFSL. There is also research on TFSL recognition systems that uses a variety of techniques, as shown in
Table 1.
The study of TFSL recognition systems for practical applications requires using a variety of techniques, since TFSL has multi-stroke gestures and combines hand gestures to convey letters as well as complex background handling and a wide range of light volumes.
Deep learning is a tool that is increasingly being used in sign language recognition [
2,
9,
10], face recognition [
11], object recognition [
12], and others. This technology is used for solving complex problems such as object detection [
13], image segmentation [
14], and image recognition [
12]. With this technique, the feature learning method is implemented instead of feature extraction. Convolution neural network (CNN) is a learning feature process that can be applied to recognition and can provide high performance. However, deep learning requires much data for training, and such data could use simple background or complex background images. In the case of a picture with a simple background, the object and background color are clearly different. Such an image can be used as training data without cutting out the background. On the other hand, a complex background image features objects and backgrounds that have similar colors. Cutting out the background image will obtain input images for training with deep learning, featuring only objects of interest without distraction. This can be done using the semantic segmentation method, which uses deep learning to apply image segmentation. This method requires labeling objects of interest to separate them from the background. Autonomous driving is one application of semantic segmentation used to identify objects on the road, and can also be used for a wide range of other applications.
This study is based on the challenges of the TFSL recognition system. There are up to 42 Thai letters that involve spelling with one’s fingers—i.e., spelling letters with a combination of multi-stroke sign language gestures. The gestures for spelling several letters, however, are similar, so a sign language recognition system under a complex background should instead be used. There are many studies about the TFSL recognition system. However, none of them study the TFSL multi-stroke recognition system using the vision-based technique with complex background. The main contributions of this research are the application of a new framework for a multi-stroke Thai finger-spelling sign language recognition system to videos under a complex background and a variety of light intensities by separating people’s hands from the complex background via semantic segmentation methods, detecting changes in the strokes of hand gestures with optical flow, and learning features with CNN under the structure of AlexNet. This system supports recognition that covers all 42 characters in TFSL.
The proposed method focuses on developing a multi-stroke TFSL recognition system with deep learning that can act as a communication medium between the hearing impaired and the general public. Semantic segmentation is then applied to hand segmentation for complex background images, and optical flow is used to separate the strokes of sign language. The processes of feature learning and classification use CNN.
2. Review of Related Literature
Research on sign language recognition systems has been developed in sequence with a variety of techniques to obtain a system that can be used in the real world. Deep learning is one of the most popular methods effectively applied to sign language recognition systems. Nakjai and Katanyukul [
2] used CNN to develop a recognition system for TFSL with a black background image and compared 3-layer CNN, 6-layer CNN, and HOG, finding that the 3-layer CNN with 128 filters on every layer had an average precision (mAP) of 91.26%. Another study that applied deep learning to a sign language recognition system was published by Lean Karlo S. et al. [
9], who developed an American sign language recognition system with CNN under a simple background. The dataset was divided into 3 groups: alphabet, number, and static word. The results show that alphabet recognition had an average accuracy of 90.04%, number recognition had an accuracy average of 93.44%, and static word recognition had an average accuracy of 97.52%. The total average of the system was 93.67%. Rahim et al. [
15] applied deep learning to a non-touch sign word recognition system using hybrid segmentation and CNN feature fusion. This system used SVM to recognize sign language. The research results under a real-time environment provided an average accuracy of 97.28%.
Various sign language studies aimed to develop a vision base by using, e.g., image and video processing, object detection, image segmentation, and recognition systems. Sign language recognition systems using vision can also be divided into two types of backgrounds: simple backgrounds [
3,
4,
9,
16] and complex backgrounds [
17,
18,
19]. A simple background entails the use of a single color such as green, blue, or white. This can help hand segmentation work more easily, and the system can recognize accuracy at a high level. Pariwat et al. [
4] used sign language images on a blue background while the signer wore a black jacket in a TFSL recognition system with SVM on RBF, including global and local features. The average accuracy was 91.20%. Pariwat et al. [
3] also used a simple background in a system that was developed by combining PHOG and local features with KNN. This combination enhanced the average accuracy to levels as high as 97.80%. Anh et al. [
10] presented a Vietnamese language recognition system using deep learning in a video sequence format. A simple background, like a white background, was used in training and testing, providing an accuracy of 95.83%. Using a simple background makes it easier to develop a sign language recognition system and provides high-accuracy results, but this method is not practical due to the complexity of the backgrounds in real-life situations.
Studying sign language recognition systems with complex backgrounds is challenging. Complex backgrounds consist of a variety of elements that are difficult to distinguish, which requires more complex methods. Chansri et al. [
7] developed a Thai sign language recognition system using Microsoft Kinect to help locate a person’s hand in a complex background. This study used the fusion of depth and color video, HOG features, and a neural network, resulting in accuracy of 84.05%. Ayman et al. [
17] proposed the use of Microsoft Kinect for Arabic sign language recognition systems with complex backgrounds with histogram of oriented gradients—principal component analysis (HOG-PCA) and SVM. The resulting accuracy value was 99.2%. In summary, research on sign language recognition systems using vision-based techniques remains a challenge for real-world applications.
5. Conclusions
The research focused on the development of a multi-stroke TFSL recognition system to support the use of complex background with deep learning. This study compared five CNN performance models. According to the results, the first and second structure formats are static CNN architecture, and the determined number of filters and size of the filters were the same for all layers, providing a minimal accuracy value. The third format uses an architectural style to determine the number of filters from ascending with the same size of the filter, which results in increased accuracy. The fourth format uses an ascending number of filters. The first layer uses large filters for learning the global feature, whereas the next layer uses smaller filters for learning the local feature. This results in higher accuracy. The fifth format is a mixed architectural style, designed based on AlexNet structure. Its first and second convolution layer increases the number of filters from ascending while the third and fourth layers show the number of a static filter rises from the second layer. However, the fifth and sixth layers use a fixed number of filters which drop from the two previous layers. For similar purpose, the large size of the filter is used in the first layer to learn global features, while the smaller filter is used in the next layer to learn the local feature. The results show that mixed architecture with global feature learning followed by local feature learning shows outperforming accuracy. By using the fifth format to train the system, the results of the overall study indicate that factors affecting the system’s accuracy average include (1) very similar sign language gestures that negatively affect classification, resulting in lower accuracy average results; (2) low-movement sign language spelling gestures that affect the detection of multiple spelling gestures, causing faulty stroke detection; and (3) the spelling of multiple-stroke sign language, which affects the average accuracy since too much movement can sometimes lead to movement being detected between gestural changes, resulting in system recognition errors. A solution could be to improve the motion detection system to make the strokes of the sign language more accurate or to apply a long short-term memory network (LSTM) to enhance the recognition system’s accuracy. In conclusion, the study results demonstrate that similarities in the gestures and strokes when finger-spelling Thai sign language caused decreases in accuracy. For future studies, further TFSL recognition system development is needed.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}