Abstract
Discovering densely-populated regions in a dataset of data points is an essential task for density-based clustering. To do so, it is often necessary to calculate each data point’s local density in the dataset. Various definitions for the local density have been proposed in the literature. These definitions can be divided into two categories: Radius-based and k Nearest Neighbors-based. In this study, we find the commonality between these two types of definitions and propose a canonical form for the local density. With the canonical form, the pros and cons of the existing definitions can be better explored, and new definitions for the local density can be derived and investigated.
1. Introduction
Density-based clustering is the task of detecting densely-populated regions (called clusters) separated by sparsely-populated or empty regions in a data set of data points. It is an unsupervised process that can discover clusters of arbitrary shapes [1]. Many density-based clustering algorithms have been proposed in the literature [2,3,4,5,6,7,8,9], but most of them adopt their definitions of local density. Since clusters are derived based on each data point’s local density, using an inappropriate definition for local density could yield bad clustering results. Thus, it is crucial to define local density properly for density-based clustering.
This study divides the definitions for local density in the literature into two categories: Radius-based and k Nearest Neighbors-based (or kNN-based for short). Radius-based local density uses a radius to specify the neighborhood of a data point, and the data points within a data point’s neighborhood mainly determine the local density of the data point. In contrast, kNN-based local density uses the k nearest neighbors or the reverse k nearest neighbors of a data point to derive its local density.
In this study, we propose a canonical form for local density. All previous definitions for local density can be viewed as a special case of the canonical form. The canonical form decomposes local density definition into three parts: The contribution set, contribution function, and integration operator. The contribution set of a data point specifies the set of data points that contribute to the data point’s local density. The contribution function calculates the contribution of a data point to the local density of another data point. The integration operator is used to combine the contributions of the data points in the contribution set to yield local density.
The advantage of using this canonical form is twofold. First, it allows us to interpret the implicit difference between different definitions for local density. For example, in Section 2.2, we show that the kNN-based local density defined in [6,7] implicitly uses a radius equal to one and , respectively. Second, this canonical form facilitates exploring the pros and cons of these existing definitions for local density. We can then combine these definitions’ merits to derive suitable definitions for local density for the problem at hand.
The rest of this paper is organized as follows. Section 2 reviews the existing definitions for local density. Section 3 proposes the canonical form for local density and shows how these definitions fit the canonical form. Section 4 describes how to derive new definitions for local density using this canonical form. Section 5 conducts an experiment to show how the three parts (i.e., contribution set, contribution function, and integration operator) of the canonical form affect local density distribution. Section 6 concludes this paper.
2. Review on Local Density
Most density-based clustering algorithms require calculating each data point’s local density to derive clusters in the dataset. However, there is no standard definition for a data point’s local density. Many definitions for local density have been proposed in the literature. Based on the parameters used in the definitions, we can divide the existing definitions into two categories. A radius-based definition uses a parameter for the radius of a data point’s neighborhood, and a kNN-based definition uses a parameter k to limit the scope of the data points involved to the k nearest neighbors. In this section, we review these two types of definitions. For ease of exposition, some notations are defined in Table 1.

Table 1.
Notations.
2.1. Radius-Based Local Density
As described earlier, a radius-based local density uses parameter to specify the radius of a data point’s neighborhood. Consider a dataset of n data points and the local density of a data point . A radius-based local density ensures that those data points within ’s neighborhood have a large contribution to and that the data points outside ’s neighborhood have little or no contribution to . In what follows, we describe two definitions for the radius-based local density in the literature.
In [4], the local density of a data point is defined as the number of data points within the data point’s neighborhood, which is given as follows:
where
and is the distance between data points and . Thus, each data point with contributes 1 to . In [2], the constraint is adopted instead of , i.e., each data point with contributes 1 to . However, this change should not make a significant difference on .
Instead of using the radius as a hard threshold in Equation (1), [4] proposed a local density definition that uses an exponential kernel, as shown in Equation (3).
With Equation (3), each data point contributes to . Notably, is an inverse S-shaped function of with an inflection point at . That is, the value of decreases at an increasing speed as approaches from 0, and then at a decreasing speed after is greater than . Thus, to be exact, Equation (3) uses a soft threshold at , instead of at . Figure 1 shows the curves of and its first and secondary derivatives with respect to . The three black dots indicate that the inflection point occurs when the first and secondary derivatives reach minimum and zero, respectively.
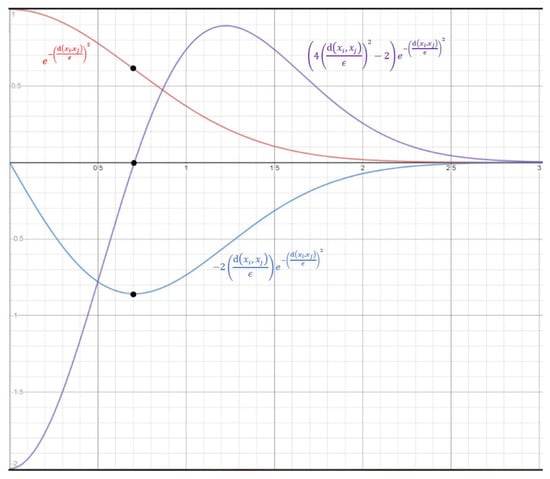
Figure 1.
The horizontal axis is and the vertical axis is the values of (in red) and its first (in blue) and secondary (in purple) derivatives with respect to .
The proper value for is dataset-dependent. Thus, instead of setting the value for directly, Ref. [4] used another parameter, p, to derive . Specifically, is set to the top p% distance of all pairs’ distances in , and 1 ≤ p ≤ 2 is recommended. Alternatively, Ref. [5] used parameter k to determine the value of .
2.2. kNN-Based Local Density
Although the radius-based local density is intuitive and straightforward, using the same radius for all data points may be inappropriate for some datasets. The kNN-based local density adopts a different approach by restricting only the k nearest neighbors contributing to the local density. In what follows, we describe four definitions of the kNN-based local density in the literature.
In [6], a data point’s local density is defined using an exponential kernel and the distances to k nearest neighbors, as shown in Equation (4).
where denotes the set of k nearest neighbors of . Notably, is a monotonically decreasing function of . Its derivative to is , which is a monotonically increasing function of . As increases from 0, the value of drops at an exponentially decreasing speed. Such a property may cause a significantly different effect for different datasets. For example, if the maximum distance between any and is small, then a fixed change to will cause a large change to . In contrast, if the minimum distance between any and is large, then a fixed change to will only cause a small change to . The cause of such an inconsistent behavior is because Equation (4) is not unit-less. Alternatively, the function can be interpreted as a unit-less function with a fixed radius for any dataset.
Reference [7] used the mean of ’s squared distance to its k nearest neighbors to derive , as shown in Equation (5):
Similar to Equation (4), in Equation (5) is a monotonically decreasing function of and is not unit-less. We can rewrite Equation (5) to remove the summation in the exponent as follows.
Similar to in Equation (3), in Equation (6) is an inverse S-shaped function of with an inflection point at . The function can also be interpreted as a unit-less function with a fixed radius for any dataset. That is, Equation (6) uses the parameter k to implicitly derive the radius , which controls the positions of the inflection point of the inverse S-shaped function .
Reference [5] proposed a kNN-based unit-less definition for , which is similar to Equation (3) but limits the data points contributing to only to , as shown in Equation (7).
Reference [5] also used the parameter k to determine the value of as follows:
where is the distance between and its kth nearest neighbor, and is the mean of of all data points in . Equation (8) derives as plus the standard deviation of , and thus a larger k yields a larger .
Reference [8] used the distance between and the mean of its k nearest neighbors to derive , as follows:
This definition could yield counterintuitive results because using the mean of k nearest neighbors sacrifices their distribution. For example, consider the case of two nearest neighbors and of located at opposite sides of , and . Then, remains unchanged independent of the values of and , which contradicts the intuition that larger and should result in smaller .
Reference [8] also proposed using the number of reverse nearest neighbors as the local density, as follows:
where is the set of reverse nearest neighbors of . This definition could render a data point having even though is in a densely-populated region. Thus, this definition should be used with caution.
To avoid the bias of nearest neighbors, [10] proposed the using mutual nearest neighbors to define local density, as follows:
where is the set of mutual nearest neighbors of and ; is the similarity between and ; and is the set of k data points chosen from with the largest .
3. Canonical Form for Local Density
In this section, we first propose the canonical form for local density. Then, we show how the existing definitions for local density fit the canonical form.
3.1. Canoncial Form
Based on the review in Section 2, this section proposes a canonical form for local density. Consider dataset and data point . The canonical form for the local density includes three parts: The contribution set , the contribution function , and the integration operator. The contribution set is the set of data points contributing to . Three possible values for are commonly used in the literature: , , and . The first value is the set of nearest neighbors of , where is the parameter [5,6,7]. The second value is the entire dataset [4]. The third value uses to specify the radius of a data point’s neighborhood, and only the data points within the neighborhood of contribute to [2,4].
The contribution function calculates the contribution of a data point to the density of . A general form for is proposed as follows:
where is the radius of a data point’s neighborhood. In the literature, the value of the exponent is 1, 2, or . In practice, we can use any m ≥ 1 to achieve a different effect, which is discussed further in Section 4.
The integration operator integrates the contributions of the data points in to yield . In the literature, either the summation or the product operator is used. Thus, the canonical form for local density can be defined using Equation (17) or Equation (18), as follows:
3.2. Fit the Existing Definitions to the Canoncial Form
Based on the canonical form defined in Section 3.1, we can derive most of the definitions for local density reviewed in Section 2, and Table 2 summarizes the results. We have excluded the definition in Equation (10) because it tends to conflict with the basic property of local density, as described in Section 2.
Table 2.
Equations (3), (4), (6), (7) and (19)–(21) fit the canonical forms defined in Equations (16)–(18).
Notably, we have transformed Equation (1) to Equation (19) below such that it can match the canonical form in Equation (17):
Here, = 1 if , and = 0 if . Thus, Equations (1) and (19) yield exactly the same results except at where Equation (1) has , but Equation (19) has .
Similarly, we have transformed Equation (12) to Equation (20) below such that it can match the canonical form in Equation (17).
Additionally, Equation (15) is rewritten as Equation (21) to avoid using .
Notably, by (14), only if , and by (13), contains at most k data points, and thus we replace in (15) by or simply to speed up the computation.
By fitting the existing definitions to the canonical form, we can see that most of them use a radius , explicitly or implicitly. With Table 2, we can better explore the pros and cons of these definitions. For example, Equation (4) uses a fixed radius of , and Equation (6) uses radius which only depends on the parameter k. Both of them do not consider the data points’ distribution in the dataset to determine . Consequently, the chosen value for may not be adaptable to different datasets. In contrast, Equations (3), (7) and (19) not only use a parameter (p or k) but also consider the distribution of the data points to decide a proper value for .
4. Derive New Definitions Using the Canonical Form
As described in Section 3.1, there are three parts in the canonical form for local density. We can combine possible values for the three parts from the existing definitions to form new definitions for local density. However, some combinations may generate undesirable results, e.g., replacing the contribution set in Equation (6) with . Thus, it is crucial to understand how the possible values for the three parts affect the results.
First, consider the integration operator in the canonical form. As shown in the second column of Table 2, most of the existing definitions for local density used the summation operator . We can replace the summation operator with the product operator (or vice versa) to yield new definitions for local density. The operators and affect the local density differently. For example, if the value of is fixed, then the more evenly distributed the value of for all , the larger the value of . On the contrary, if the value of is fixed, then the more unevenly distributed the value of for all , the larger the value of . Notably, the contribution grows as the distance decreases. If we intend to give higher local density to those data points with more evenly distributed distances to their respective neighbors in , then the product operator is adopted. Otherwise, the summation operator should be used in most cases.
Next, consider the contribution function . The general form of , defined in Equation (16), contains two parameters: The exponent m and the radius . First, focus on the impact of using different values for m. We can view in Equation (16) as a function of . Figure 2 shows that the value of m affects the shape of the function curve. For m > 1, is an inverse S-shaped function of with an inflection point at . As the value of m approaches infinity, the inflection point approaches , yielding , and the function approximates the step function in Equation (2). Notably, if m = 1, is not an inverse S-shaped function. The function curves for m = 1, 1.5, 2, 3, 4, and 50 are shown in Figure 2, where the positions of the inflection points are indicated with solid circles. To choose a suitable value for m, we can check whether the problem at hand prefers that a small increase in does not cause too much decrease in when . If this is the case, then a large value for m should be adopted to move the inflection point to the right, i.e., closer to .
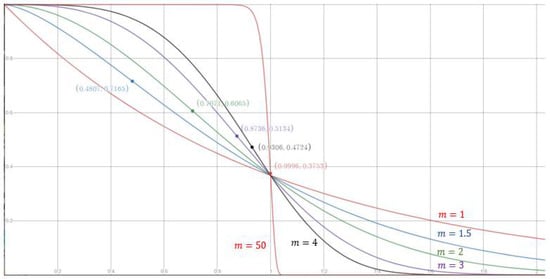
Figure 2.
The contribution for different values of m. The horizontal axis is , and the vertical axis is the contribution , as defined in Equation (16).
Next, consider the radius of a data point’s neighborhood. The value of should be dataset-dependent. For example, in [4], is set to the distance at the top p% of all pairs’ distances in , where p is a parameter. This method’s intuition is to have ⌊p(n − 1)/200⌋ data points within a data point’s neighborhood on average. However, this method tends to emphasize the dense regions and overlooks the sparse regions in the dataset. We denote the radius derived using this method by . In [5], is set to the mean plus one standard deviation of all data points’ distances to their respective k-th nearest neighbors (see Equation (8)). This method is sensitive to the outliers in the dataset and the value of k. We denote the radius derived using this method by .
To avoid the shortcomings of the above two methods, we integrate both methods and propose a new method, shown in Algorithm 1. The new method requires two parameters: k and P. First, it collects the distance of each data point to its k-th nearest neighbor. Then, it sorts these distances in ascending order and sets to the P-th percentile location, i.e., the -th distance, where n is the number of data points in the dataset. This new method considers each data point’s k-th nearest neighbor instead of the top p% of all pairs’ distances. Thus, it is less likely to overlook the sparse regions in the dataset. Furthermore, because the new method does not use mean and standard deviation, it is less sensitive to outliers than the second method. We denote the radius derived using this method by .
| Algorithm 1: The proposed method to derive ϵ. |
| Input: the set of data points Output: the radius 1. Set , where is the distance between and its k-th nearest neighbor. 2. Sort the elements in in ascending order. 3. Set 4. Set the s-th element in S. 5. Return |
Finally, consider the contribution set . As described in Section 3.1, , , and are three commonly used values for . Setting allows every data point contributing to It should only be used when the adopted is near zero for any data point far from (e.g., Equation (16) with a large m value). For a data point in a dense region, its k nearest neighbors are likely to locate within its neighborhood, i.e., . However, for in a sparse region, usually holds.
Using the product operator with (i.e., ) is a poor combination. Most of the data points in are far from thus, this combination involves multiplying many small rendering a small that fails to represent the local density of properly. In contrast, using the summation operator with does not cause such a problem.
Using the product operator with could also render strange results. For example, let be the current local density of , and be a data point where is less than the distance between and ’s nearest neighbor in . Intuitively, adding to should increase the local density of . However, according to Equation (16), is between 0 and 1 for any two data points and . Thus, with the addition of to , the local density of becomes , which is less than the original local density . Thus, the combination of using the product operator and is also a poor definition for local density.
5. Experiment
5.1. Experiment Design
For brevity, we use a tuple with four components to describe a definition for local density, where the first component indicates the integration operator, the second component indicates the contribution set, and the third and the fourth components indicate the exponent and the radius in the contribution function, respectively. For example, the row for Equation (7) in Table 2 can be represented as . This representation facilitates modifying an existing definition to create new definitions. For example, , and are three new definitions modified from .
This experiment is divided into four tests. In each test, we use the definition proposed in [5] as the benchmark and vary one component in the tuple to study how this component affects the results. In Test 1, we compare three different ways (i.e., , , and , described in Section 4) to derive radius . Here, and are derived by setting the parameters p = 2 and P = 75, respectively. Parameter k is also set to 5 to 50 in a step of 5 for both and . Test 2 compares the three definitions , , and to study the impact of using different values for the contribution set . Test 3 compares the three definitions ,, and to study the impact of using different values for the exponent . Test 4 compares the two definitions and to study the impact of using a different integration operator. In Tests 2 to 4, parameter k is set to 10 to derive and .
This experiment uses 16 well-known two-dimensional synthetic datasets. Table 3 shows the number of points and the number of clusters in these datasets.
Table 3.
Number of points and number of clusters in the 16 synthetic datasets.
5.2. Test 1: Comparing the Radiuses , , and
Test 1 compares radiuses , , and derived by the three methods described in Section 4. Obviously, increasing the values of p and P increases the values for and , respectively.
Figure 3 shows the experimental results of , , and by setting p = 2, P = 75, and k = 5 to 50 in a step of 5. The larger the value of k, the larger the values of and . In most cases, . For smaller datasets, tends to be smaller than and . It appears that the size of the dataset influences the behaviors of , , and differently. Let n denote the size of the dataset . The number of possible pairs of the data points in is . Since is set to the -th smallest value of all pairs’ distances in , the location of is linear with . In contrast, is set to the -th smallest value of the distances between all data points and their k-th nearest neighbors. That is, the location of is only linear with n. Thus, the dataset size appears to have a greater impact on than on .
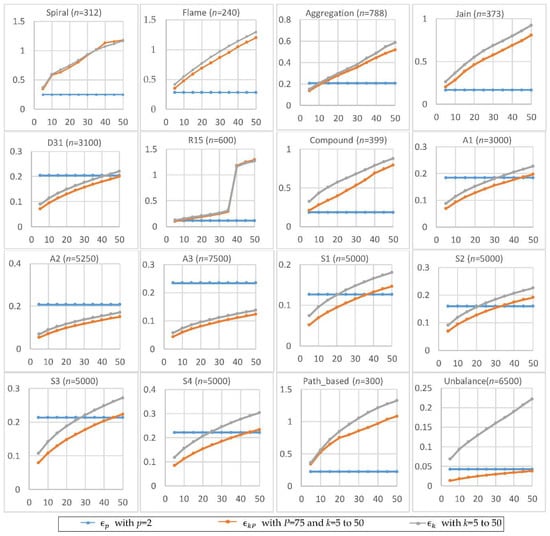
Figure 3.
The radiuses , , and for p = 2, P = 75, and k = 5 to 50. The horizontal axis is the value of k, and the vertical axis is the value of radius.
Two small datasets (Compound dataset and Path_based dataset) and two large datasets (D31 dataset and A2 dataset) are selected to show the impact of the database size on , , and . Three definitions, , , and , are used to calculate each data point’s local density, where the values of , , and (shown in Table 4) are derived by setting parameters p = 2, P = 75, and k =10. Notably, is the definition proposed in [5].
Table 4.
(p = 2), (k = 10), and (k = 10 and P = 75) for four datasets.
In Figure 4, the color scale legend on each subfigure’s right indicates the measure of local density. For the two small datasets (i.e., Compound and Path_based), we have , and thus using or results in more data points having high local density than using does, as shown in the upper two rows of Figure 4. In contrast, for the two large datasets (i.e., D31 and A2), , and thus using results in more data points having high local density than using or , as shown in the lower two rows of Figure 4.
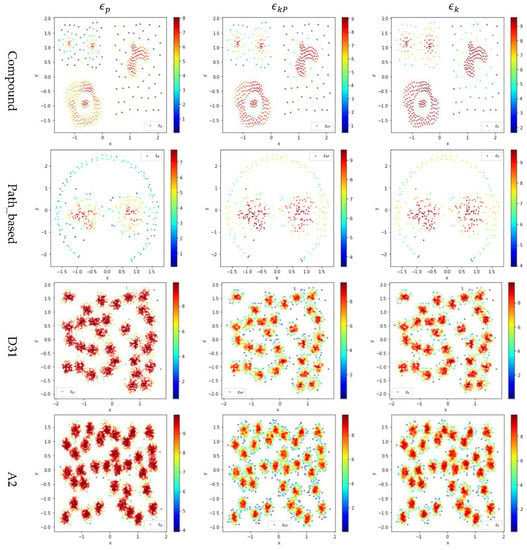
Figure 4.
The local densities calculated using , , or for the data points in four datasets (i.e., Path_based, Compound, D31, and A2). The horizontal and the vertical coordination show the position of data points, and the color indicates the value of local densities.
5.3. Test 2: Impact of the Contribution Set on Local Density
Test 2 adopts three definitions, , , and , to calculate local density and evaluates the impact of using different values for . Here, is set to 10 to derive and . The results are shown in Figure 5, where the subfigures in the same row are the results for a dataset and the subfigures in the same column are the results using the same method to determine .
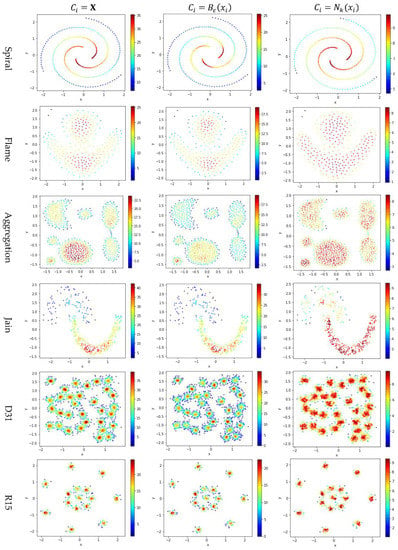
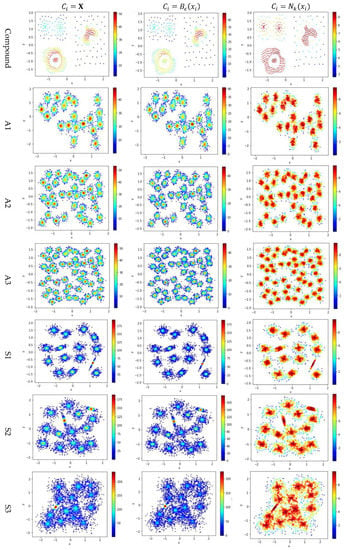
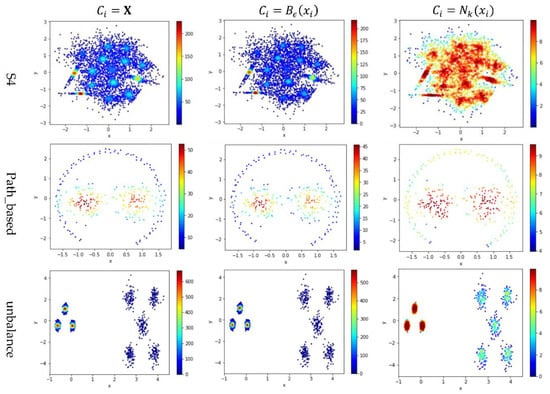
Figure 5.
The local densities calculated using , , or . The horizontal and the vertical coordination show the position of data points, and the color indicates the value of local densities.
In Figure 5, the color scale legend on each subfigure’s right indicates the measure of local density. A large local density range is usually preferred because it provides more discrepancy to compare the local density among data points. Using has the largest local density range than using or because using combines all data points’ contributions and Test 2 adopts the summation operator. Using results in a much smaller range of local density than using does, indicating that, for any data point in a densely-populated region, usually holds.
In the literature, all kNN-based methods (e.g., Equations (4), (6), and (7) in Table 2) adopted to calculate the local density. Figure 5 shows that replacing with or can enlarge the range of local density. Using tends to result in more data points within the high-density regions (see the subfigures in column 3 of Figure 5). For example, the subfigure of “Flame” database using shows that a majority of the data points have high local densities, making it difficult to partition the two densely-populated regions in the dataset. It is better to have each densely-populated region surrounded by low-density data points to facilitate clustering, e.g., the subfigure for “aggregation” dataset using . Therefore, overall, using is preferred.
However, for datasets containing both high-density clusters and low-density clusters (e.g., the Path_based dataset and the Unbalance dataset in the last two rows of Figure 5), using or tends to yield very low local density for the data points in the low-density clusters. A dense-based clustering algorithm must handle this situation carefully to avoid omitting the low-density clusters.
5.4. Test 3: Impact of the Exponent m on Local Density
Test 3 varies the value of in the contribution function to study the impact of on the local density. Specifically, we compare three definitions, ,, and , where is set to 10 to derive and . The results are shown in Figure 6, where the subfigures in the same row are the results for a dataset, and the subfigures in the same column are the results using the same value for .

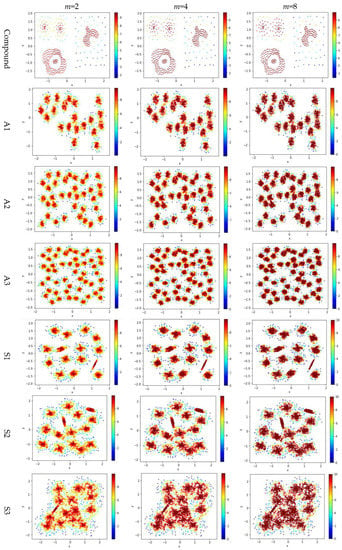
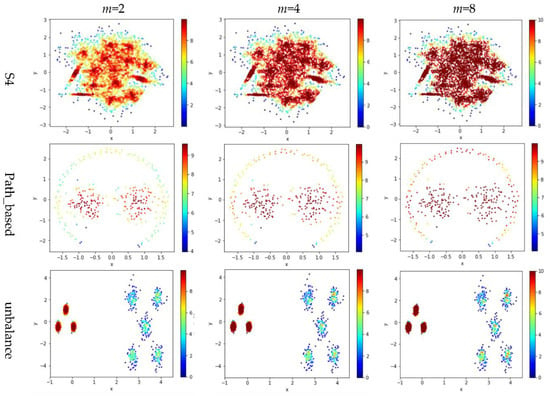
Figure 6.
The local densities calculated using m = 2, 4, or 10 in . The horizontal and the vertical coordination show the position of data points, and the color indicates the value of local densities.
Comparing the subfigures in the same row of Figure 6 reflects that a larger m incurs more data points to have a higher local density. For those datasets with nicely separated clusters (e.g., dataset R15), using a large m helps identify the cores of the clusters. However, for datasets with poorly separated clusters (e.g., dataset S4), using a large m makes it challenging to spot the boundary between two adjacent clusters. For datasets containing both high-density clusters and low-density clusters (e.g., the Unbalance dataset), the impact of the value of m on the local density is not significant.
5.5. Test 4: Impact of the Integration Operator ( or ) on Local Density
Test 4 studies the impact of using different integration operator ( or ) using two definitions and , to calculate local density. As in Tests 2 and 3, is set to 10 to derive and . The results are shown in Figure 7, where the subfigures in the same column are the results using the same integration operator.
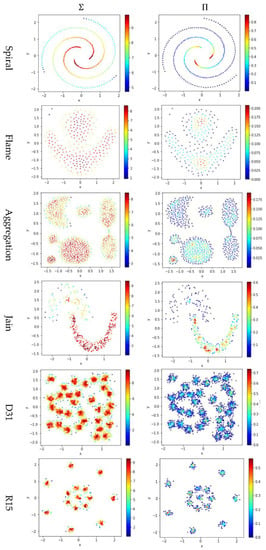
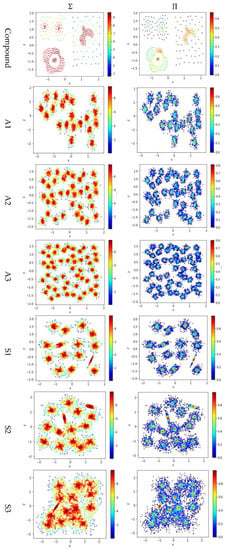
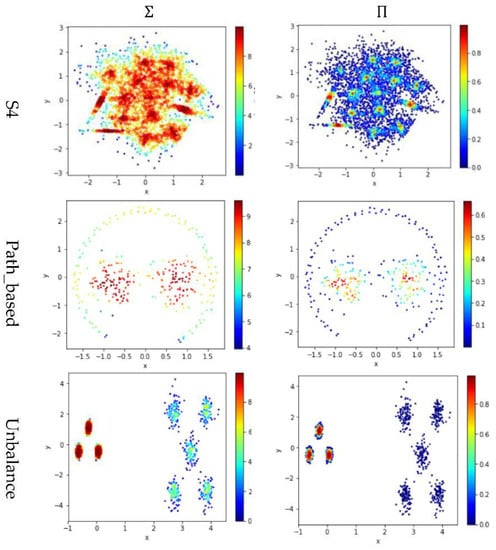
Figure 7.
The local densities calculated using different integration operator ( or ). The horizontal and the vertical coordination show the position of data points, and the color indicates the value of local densities.
The contribution function in Equation (16) yields a value between 0 and 1, so using the product operator to integrate the data points’ contributions results in a smaller local density than using the summation operator does. Using tends to keep only a small portion of data points having a higher local density, and thus it helps to identify the density peaks in the dataset. However, for datasets containing both high-density clusters and low-density clusters (e.g., the Path_based dataset and the Unbalance dataset), using cannot find the density peaks in the low-density clusters.
6. Conclusions
In this study, we first divided the existing definitions for local density into two categories, radius-based and kNN-based. It was shown that a kNN-based definition is implicitly radius-based. Then, we propose a canonical form to decompose the definition of local density into three parts: The integration operator ( or ), the contribution set , and the contribution function . Furthermore, the contribution function could be controlled with a radius and an exponent . Thus, a definition for local density could be represented as a tuple of four components ( or ,,,) to derive new definitions for local density. We conclude the following guidelines for developing new definitions for local density based on our analysis and experiment:
- ●
- (,,*,*) and (,,*,*) should be avoided because they could incur results contradicting the notion of local density. For example, they could yield a low density to a should-be high-density data point. Here, ‘*’ is used to represent a do not-care term;
- ●
- Product operator could be used only when the size of the contribution set is fixed for every data point, e.g., ;
- ●
- In most cases, the summation operator should be adopted. However, product operator helps to identify the density peaks in a dataset;
- ●
- The value for should be dataset-dependent, e.g., , , and . Notably, is sensitive to the dataset’s size, is sensitive to the parameter k and the outliers in the dataset, and provides a compromise between them;
- ●
- The value of m should be ≥2 so that the contribution function has an inflection point at . The greater the value of m, the closer the inflection point near .
Notably, using the above ( or ,,,) representation assumes that the contribution function is adopted. That is, given the parameters and, the value of depends only on the distance . However, in recent studies [8,10], may involve not only and but also their nearest neighbors. In such cases, a tuple of three components ( or ,,) should be adopted to represent a definition for local density, where may require additional parameters, e.g., for nearest neighbors. Furthermore, could incorporate the symmetric distance based on the mutual nearest neighbors of and , as did in [10]. Other symmetric distance matrices can also be adopted.
Using only one local density definition can be challenging to identify clusters in a dataset containing clusters with different densities. Future studies can address how to apply the proposed canonical form to handle this problem. For example, we can adopt a stepwise approach. Each step uses a different definition of local density to target the clusters of a specific feature. The proposed canonical form can facilitate changing the density definition at different stages of a clustering approach. The effective integration of the canonical form and a clustering approach is currently under-studied.
Funding
This research is supported by the Ministry of Science and Technology, Taiwan, under Grant MOST 108-2221-E-155-013.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data available in a publicly accessible repository. Please refer to the references in Table 3 for availability.
Acknowledgments
The author acknowledges the Innovation Center for Big Data and Digital Convergence at Yuan Ze University for supporting this study.
Conflicts of Interest
The author declares no conflict of interest.
References
- Han, J.; Kamber, M.; Pei, J. Data Mining: Concepts and Techniques, 3rd ed.; Morgan Kaufmann Publishers Inc.: Waltham, MA, USA, 2011. [Google Scholar]
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters a density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Ankerst, M.; Breunig, M.M.; Kriegel, H.-P.; Sander, J. OPTICS: Ordering points to identify the clustering structure. In Proceedings of the 1999 ACM SIGMOD International Conference on Management of Data, Philadelphia, PA, USA, 1–3 June 1999; pp. 49–60. [Google Scholar]
- Rodriguez, A.; Laio, A. Clustering by fast search and find of density peaks. Science 2014, 344, 1492–1496. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Ma, Z.; Fang, Y. Adaptive density peak clustering based on K-nearest neighbors with aggregating strategy. Knowl. Based Syst. 2017, 133, 208–220. [Google Scholar] [CrossRef]
- Xie, J.; Gao, H.; Xie, W.; Liu, X.; Grant, P.W. Robust clustering by detecting density peaks and assigning points based on fuzzy weighted K-nearest neighbors. Inf. Sci. 2016, 354, 19–40. [Google Scholar] [CrossRef]
- Du, M.; Ding, S.; Jia, H. Study on density peaks clustering based on k-nearest neighbors and principal component analysis. Knowl. Based Syst. 2016, 99, 135–145. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, D.; Yu, F.; Ma, Z. A Double-Density Clustering Method Based on “Nearest to First in” Strategy. Symmetry 2020, 12, 747. [Google Scholar] [CrossRef]
- Lin, J.-L.; Kuo, J.-C.; Chuang, H.-W. Improving Density Peak Clustering by Automatic Peak Selection and Single Linkage Clustering. Symmetry 2020, 12, 1168. [Google Scholar] [CrossRef]
- Lv, Y.; Liu, M.; Xiang, Y. Fast Searching Density Peak Clustering Algorithm Based on Shared Nearest Neighbor and Adaptive Clustering Center. Symmetry 2020, 12, 2014. [Google Scholar] [CrossRef]
- Chang, H.; Yeung, D.-Y. Robust path-based spectral clustering. Pattern Recognit. 2008, 41, 191–203. [Google Scholar] [CrossRef]
- Fu, L.; Medico, E. FLAME, a novel fuzzy clustering method for the analysis of DNA microarray data. BMC Bioinform. 2007, 8, 3. [Google Scholar] [CrossRef] [PubMed]
- Gionis, A.; Mannila, H.; Tsaparas, P. Clustering aggregation. ACM Trans. Knowl. Discov. Data 2007, 1, 4. [Google Scholar] [CrossRef]
- Jain, A.K.; Law, M.H. Data clustering: A user’s dilemma. In Proceedings of the 2005 International Conference on Pattern Recognition and Machine Intelligence, Kolkata, India, 20–22 December 2005; pp. 1–10. [Google Scholar]
- Veenman, C.J.; Reinders, M.J.T.; Backer, E. A maximum variance cluster algorithm. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 1273–1280. [Google Scholar] [CrossRef]
- Zahn, C.T. Graph-Theoretical Methods for Detecting and Describing Gestalt Clusters. IEEE Trans. Comput. 1971, 100, 68–86. [Google Scholar] [CrossRef]
- Kärkkäinen, I.; Fränti, P. Dynamic Local Search Algorithm for the Clustering Problem; A-2002-6; University of Joensuu: Joensuu, Finland, 2002. [Google Scholar]
- Fränti, P.; Virmajoki, O. Iterative shrinking method for clustering problems. Pattern Recognit. 2006, 39, 761–775. [Google Scholar] [CrossRef]
- Rezaei, M.; Fränti, P. Set Matching Measures for External Cluster Validity. IEEE Trans. Knowl. Data Eng. 2016, 28, 2173–2186. [Google Scholar] [CrossRef]













Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).