
Effective Intrusion Detection System to Secure Data in Cloud Using Machine Learning



Abstract
:1. Introduction
- Identify the set of optimal features in the new dataset CICIDS2017, which contains normal and most up-to-date common attacks. This was done to find a set of selected features that improved the performance of the detection mechanism.
- Examine the effect of newly developed fitness functions on identifying intrusions. The present study aimed to do this using a multifactor fitness function to measure the performance of IDS.
- Determine the best combination of parameter values for an SVM to produce the maximum detection rate of intrusions within the CICIDS2017 dataset.
- Conduct a comparative study between the CICIDS2017 dataset and the popular KDD CUP 99 dataset. The outcome was used to generalize the efficiency of the proposed system.
2. Background and Literature Review
2.1. Concepts of IDS and Related Work
- collecting data from the monitored systems;
- analyzing the collected data to classify it as normal or intrusion;
- alerting the admin about the possibility of intrusion to the concerned system so that they can take necessary action to prevent intrusion and protect the system.
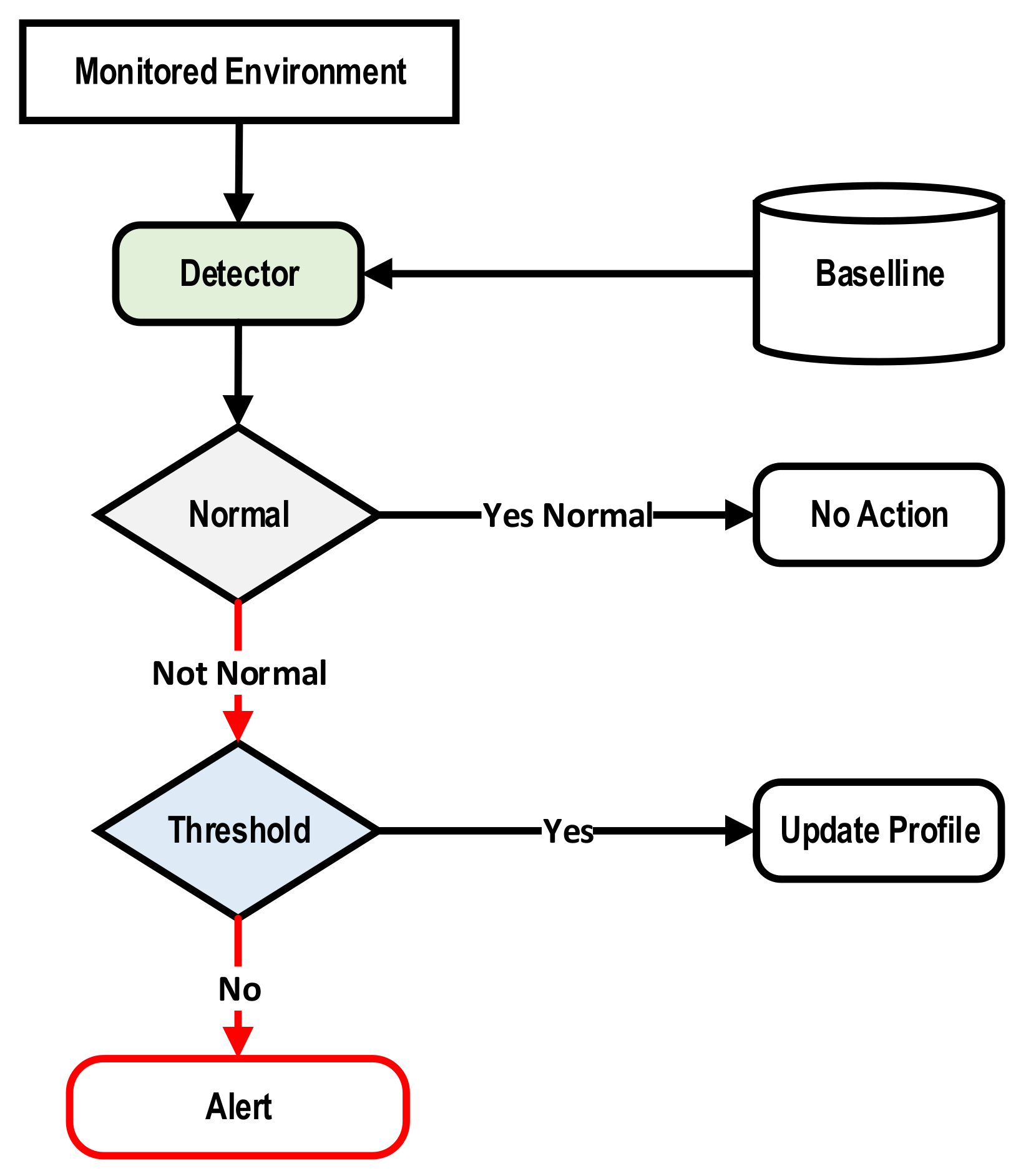
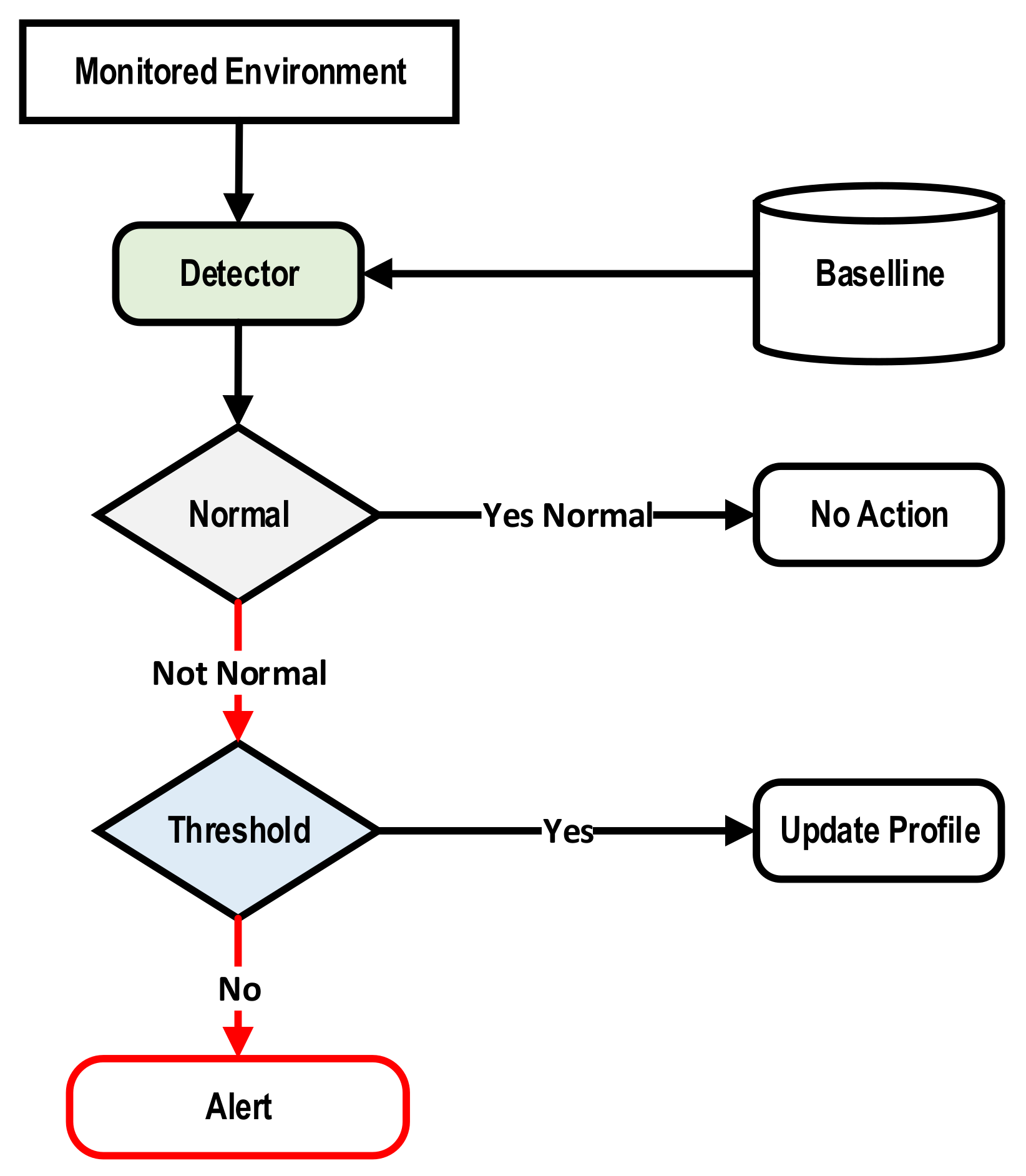
2.1.1. Anomaly-Based IDS
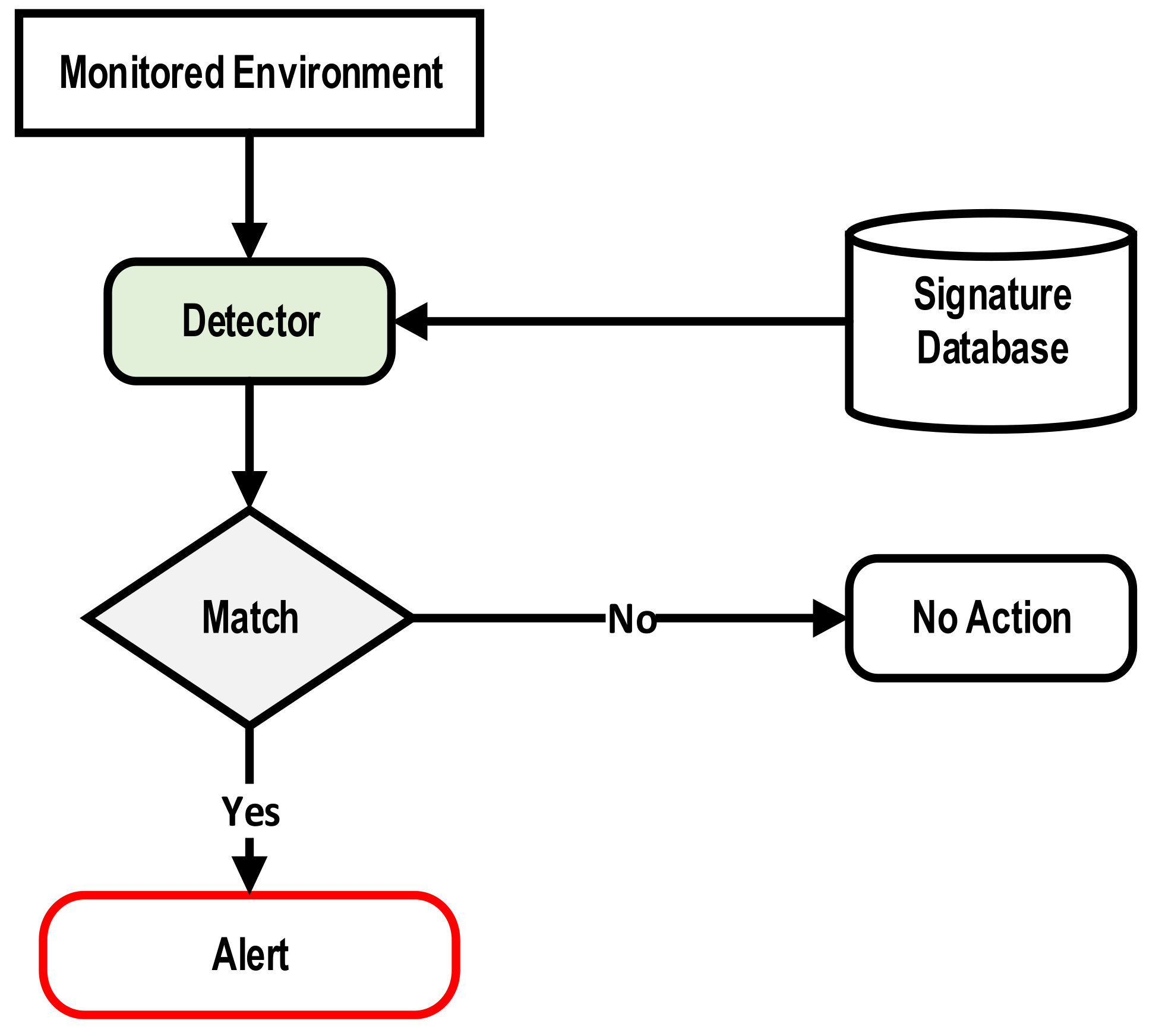
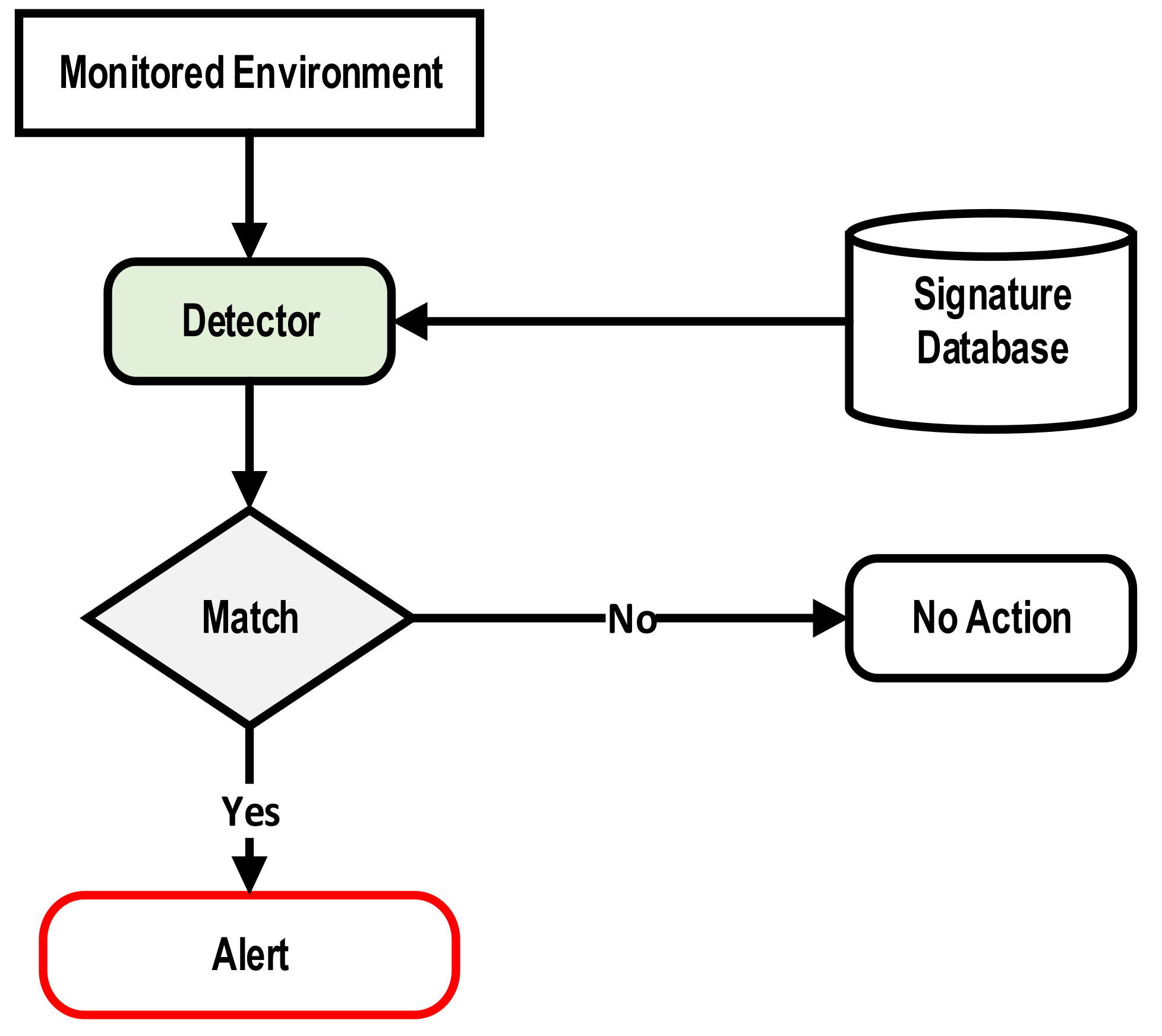
2.1.2. Signature-Based IDS
2.2. Feature Selection
2.3. Hybrid Intrusion Detection System Based on Machine Learning
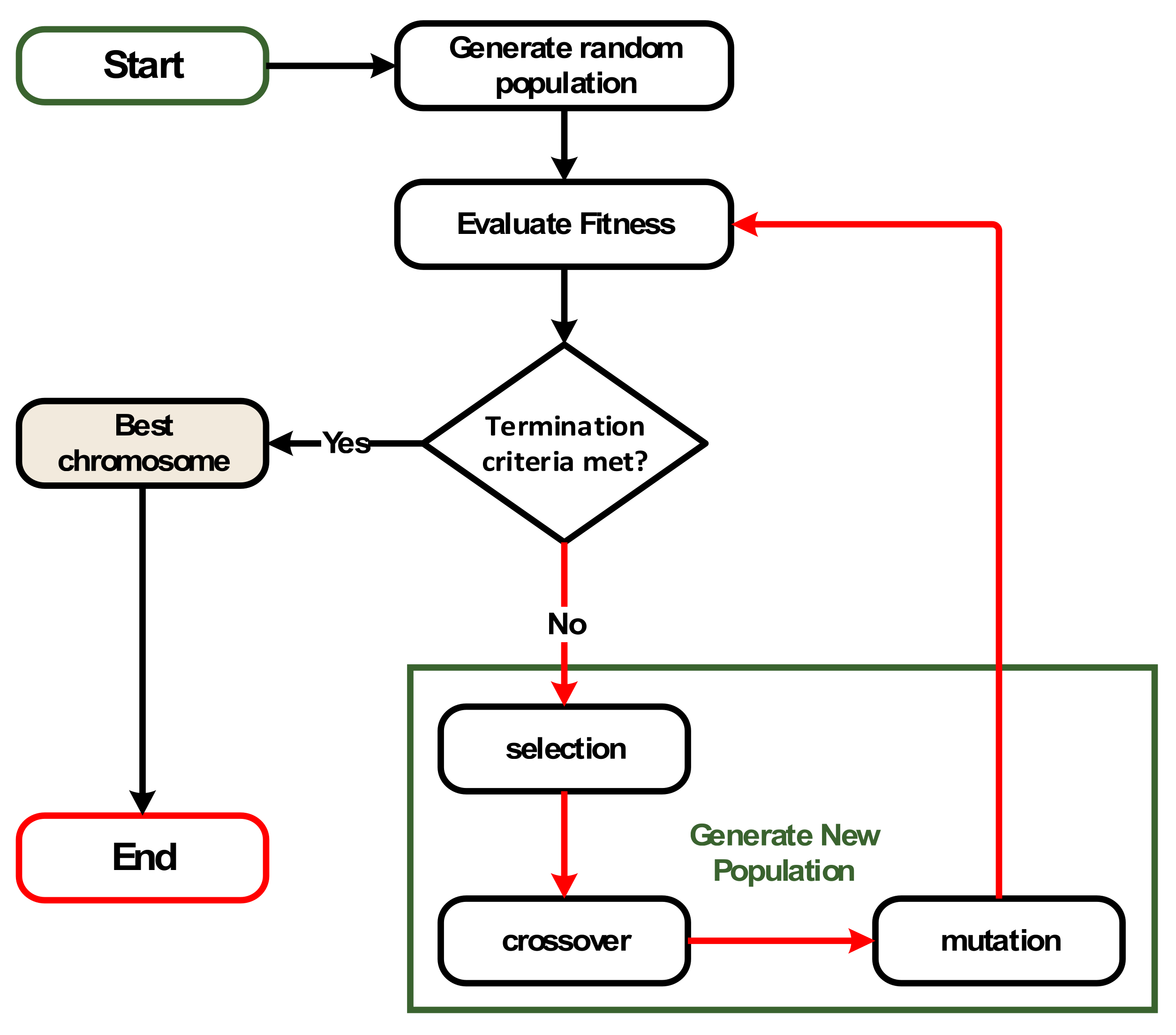
2.3.1. Genetic Algorithm Overview
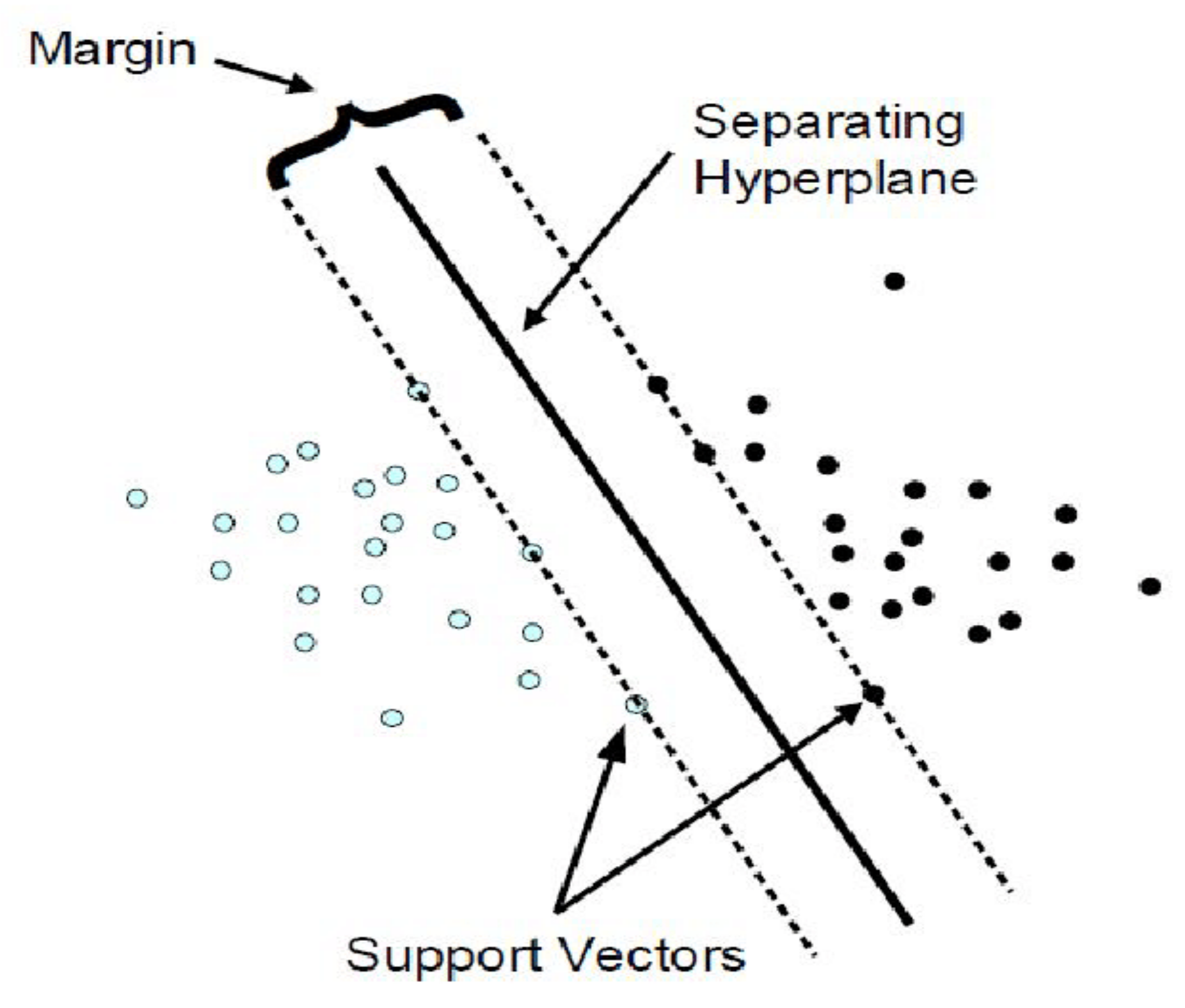
2.3.2. SVM-Based IDS and Related Work
- linear kernel: k (yi, yj) = . yj;
- polynomial kernel: k (yi, yj) = (γ . yj + r)d, γ > 0;
- radial basis function (RBF) kernel: k (yi, yj) = exp(−γ|| yi, yj2 ||), γ > 0;
- sigmoid kernel: yi, yj = tanh (γ . yj + r)
2.3.3. Related Work on Existing Hybrid IDS Using GA and SVM
3. The Proposed Hybrid IDS
3.1. Data Preparation
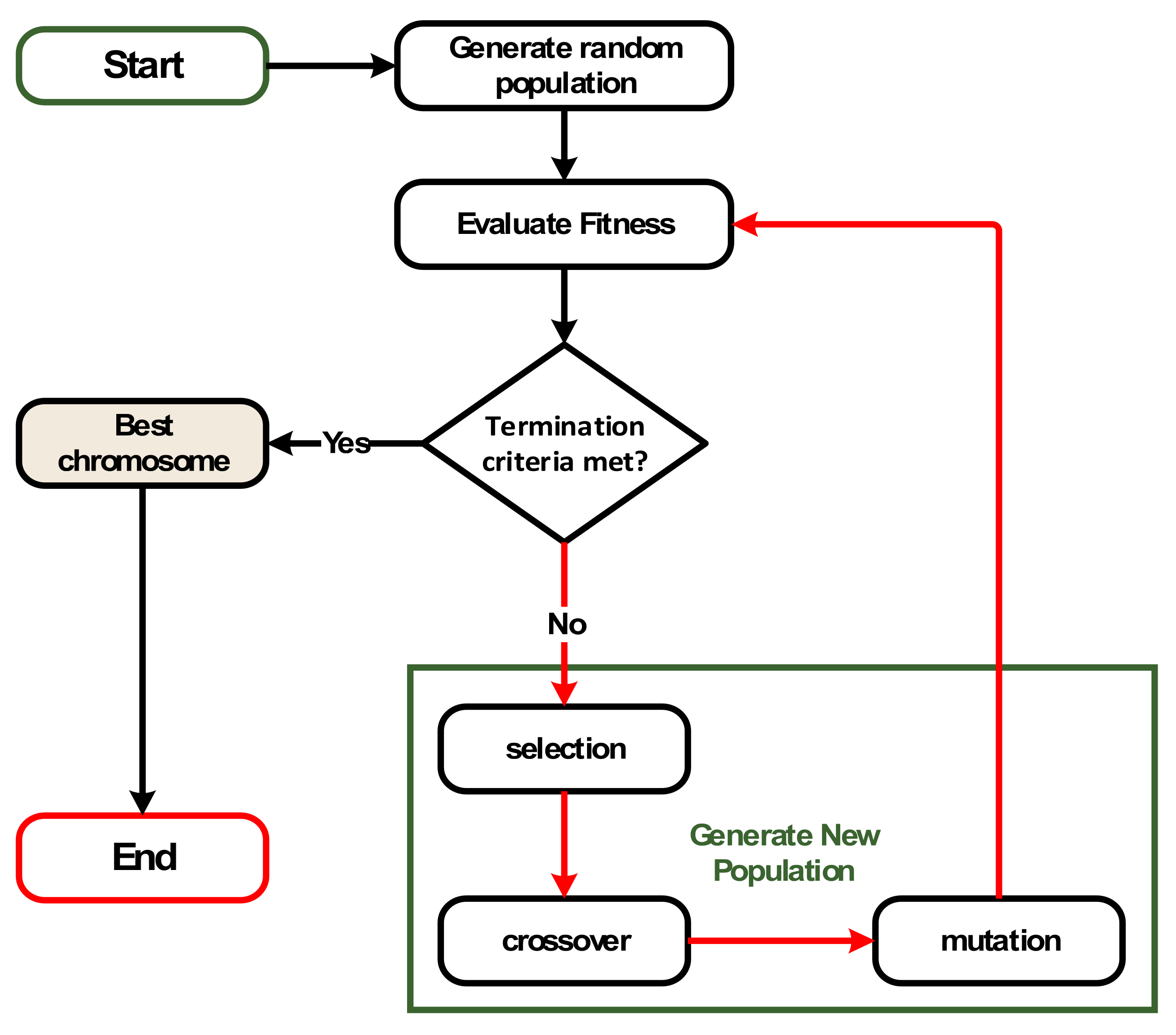
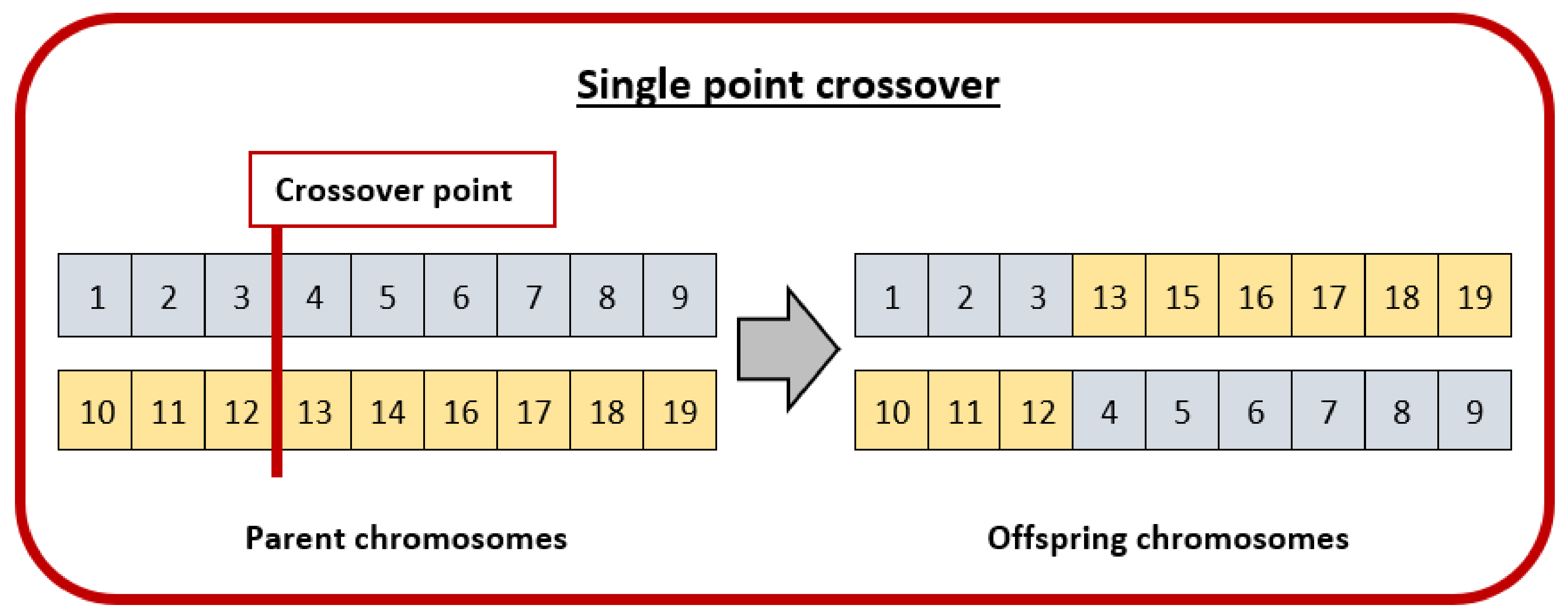
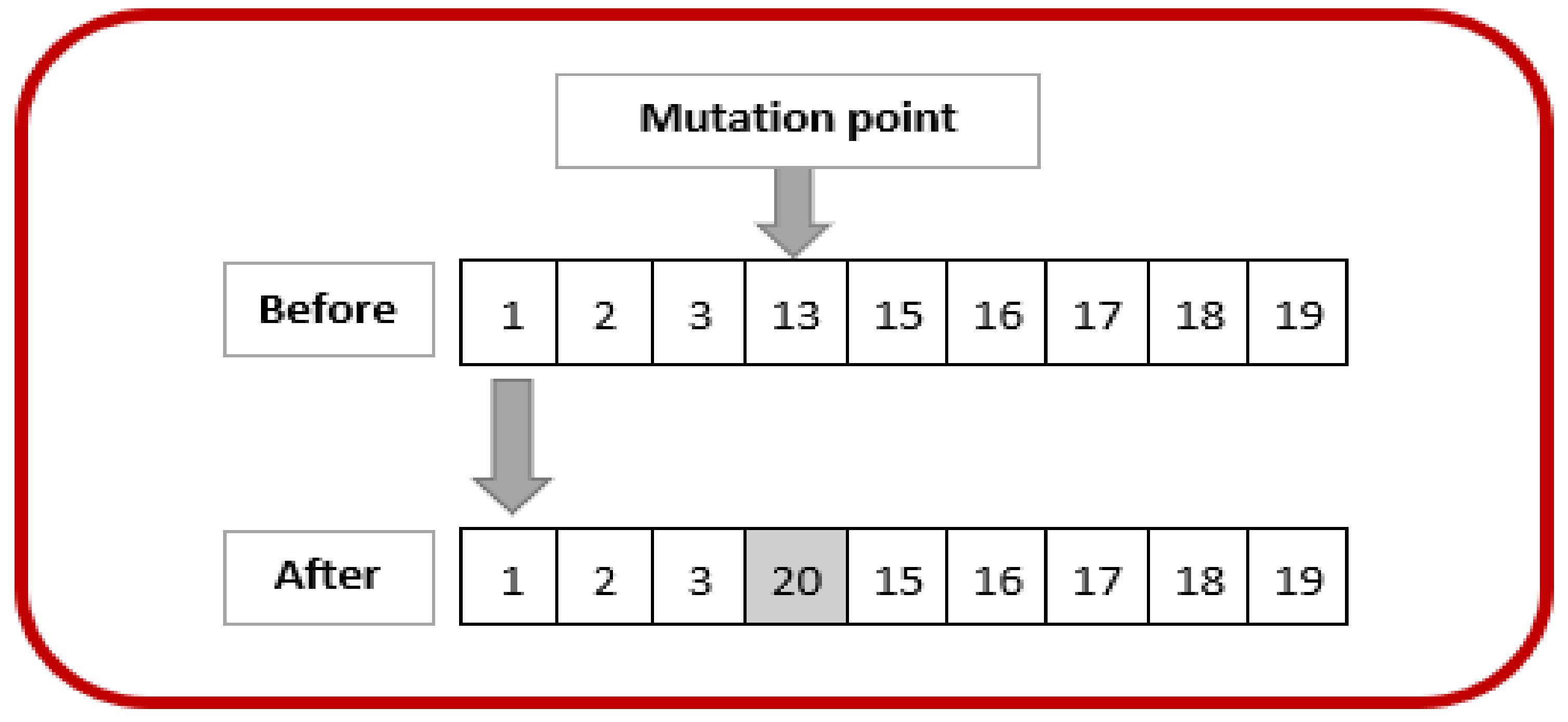
3.2. Genetic Algorithm (GA)
| Algorithm 1: GA process |
| 1: Create randomly first generation. 2: Evaluate fitness of each chromosome in the first generation. 3: Loop 4: Create next generation following these steps: 5: selection; 6: crossover; 7: mutation. 8: Until stop criteria is met. 9: The result is the best chromosome’s content of the last generation. |
3.2.1. Initial Population
3.2.2. Crossover
3.2.3. Mutation
3.2.4. Improved Fitness Function
3.2.5. Stopping Criteria
3.3. Support Vector Machine (SVM)
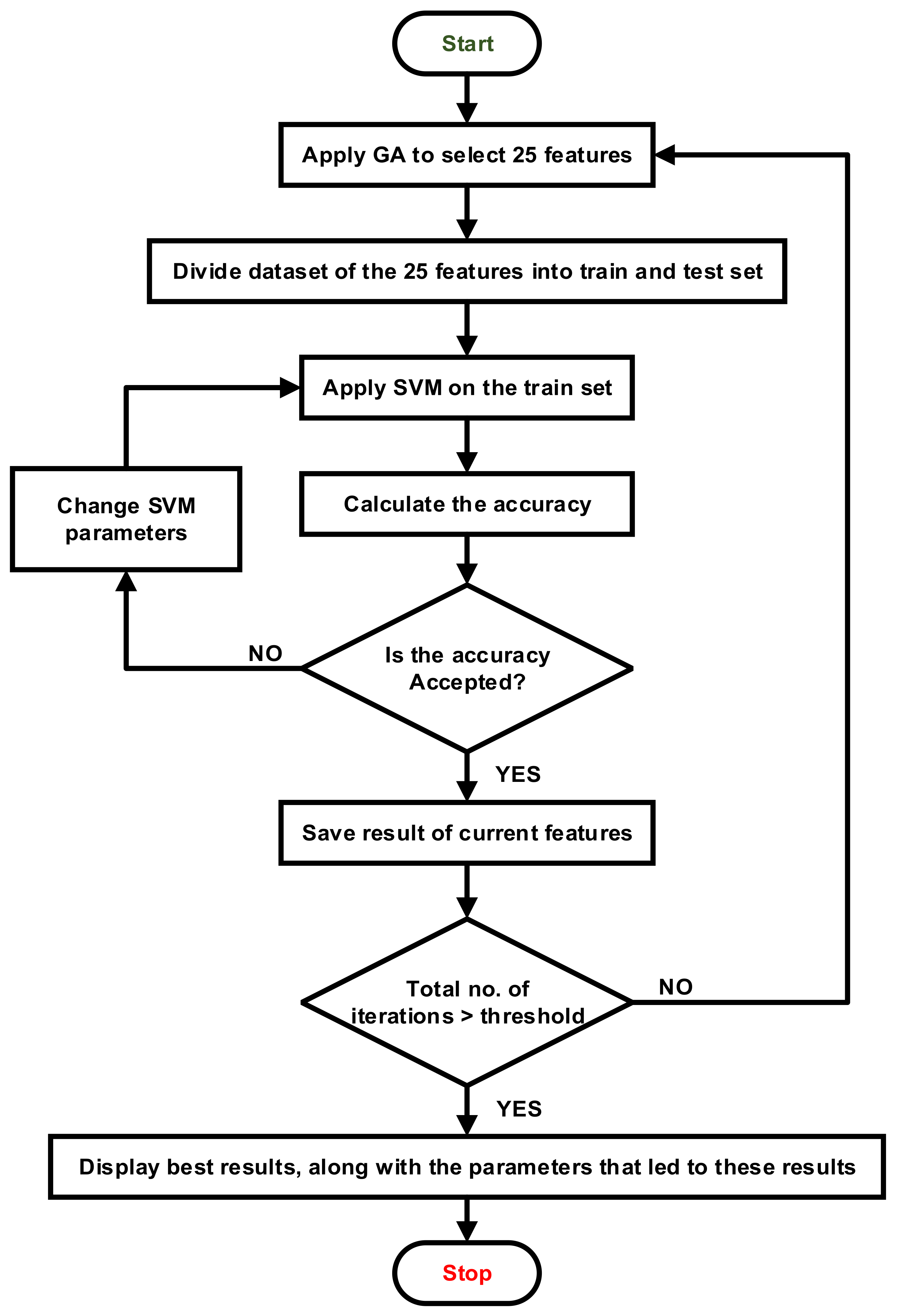
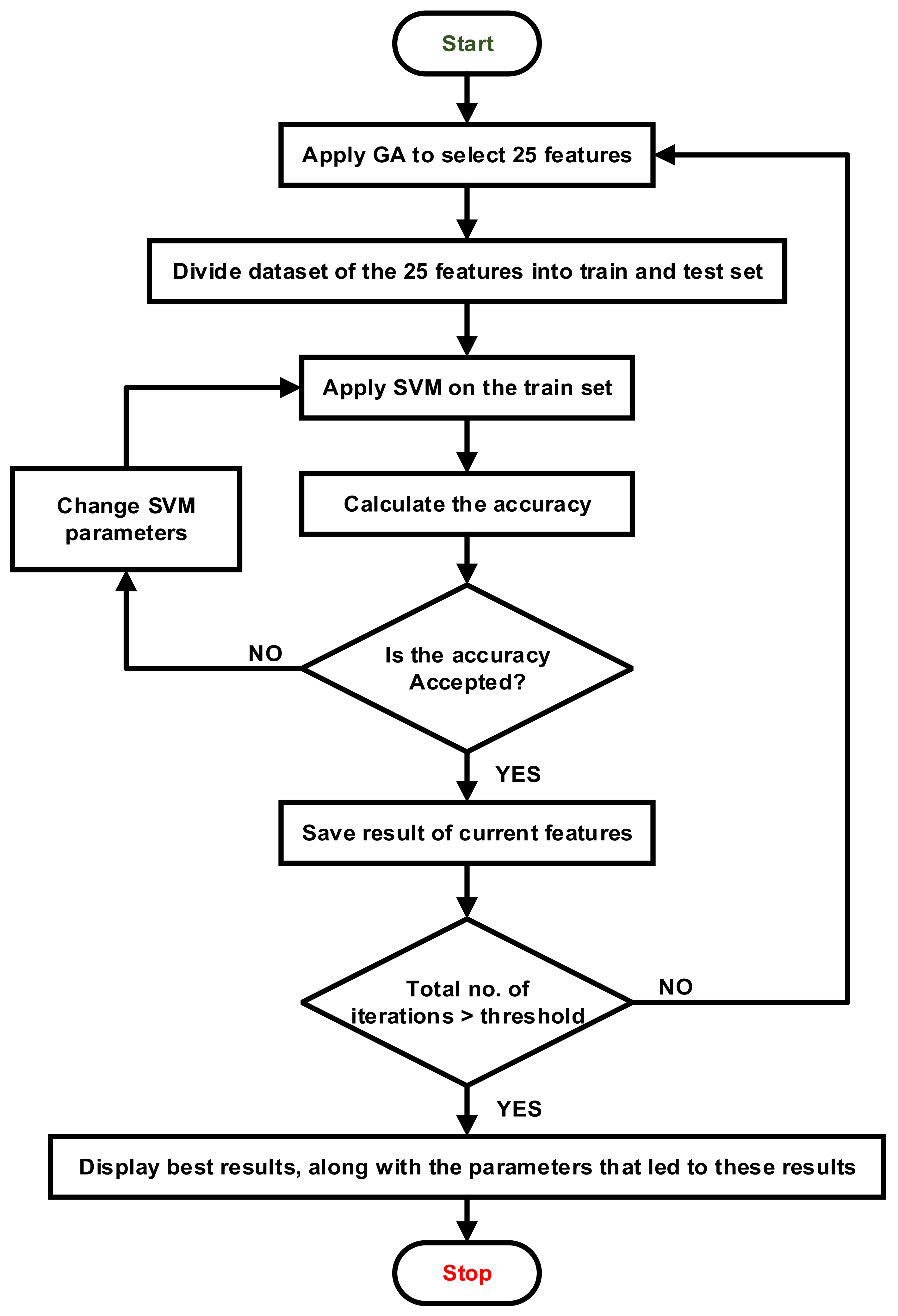
3.4. Integration between GA and SVM
| Algorithm 2: Hybrid IDS using GA and SVM. |
| 1: Apply Algorithm 1 to select features. 2: loop 3: Create initial generation. 4: for i=1 to n /*n is the number of folds*/ 5: Select 1/n of the population as a test set and (n−1)/n for training. 6: Apply SVM to the current training set with specific hyperparameters. 7: Evaluate the performance of the results using the fitness function. 8: end for 9: performance of the current generation= average score of the results of n folds 10: Save the results of step 6. 11: until the stop criteria are met. 12: Display the best result, along with the hyperparameters for the SVM that produced it. |
4. Implementation and Results
4.1. Experiments Procedure and Results
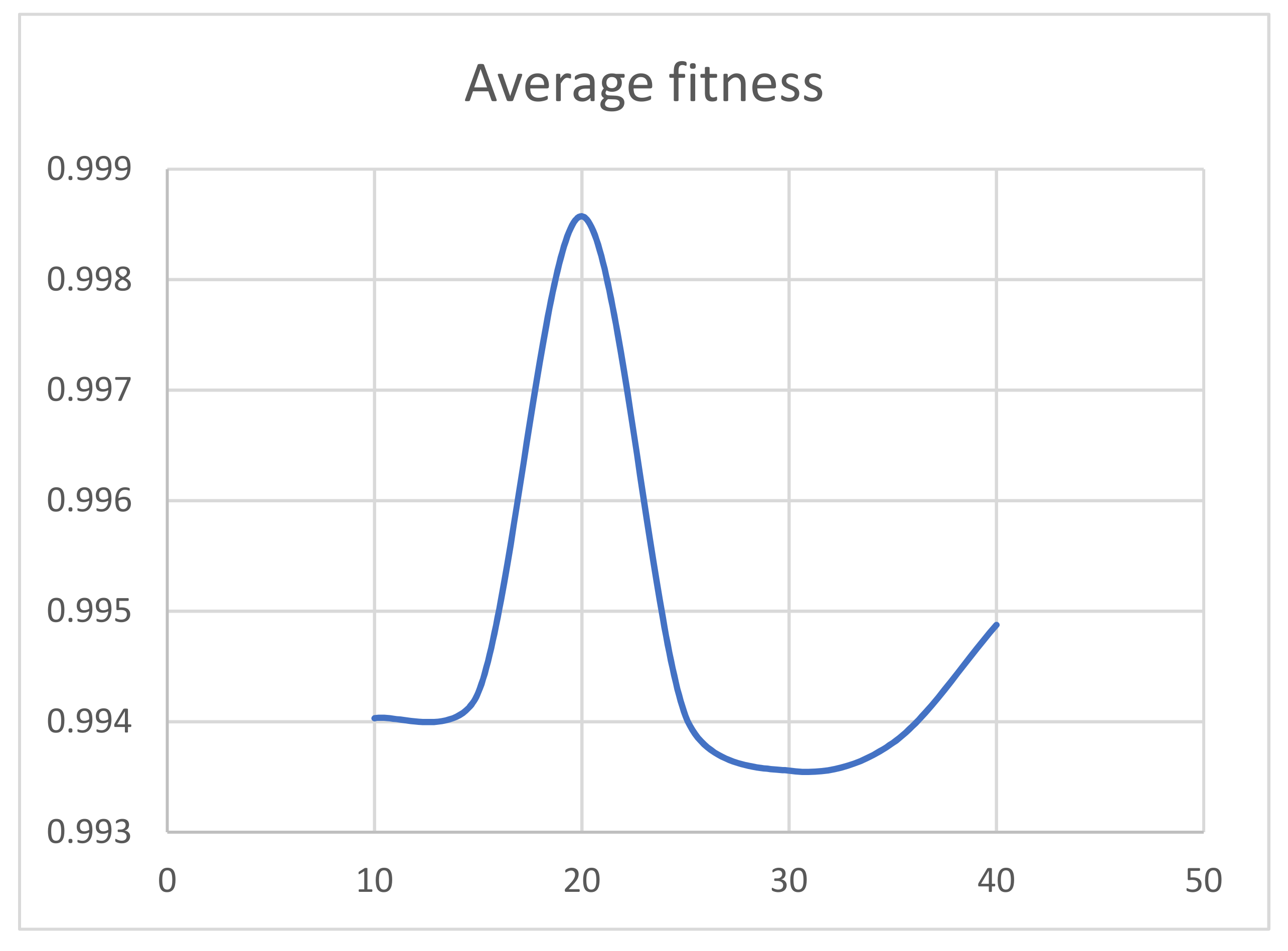
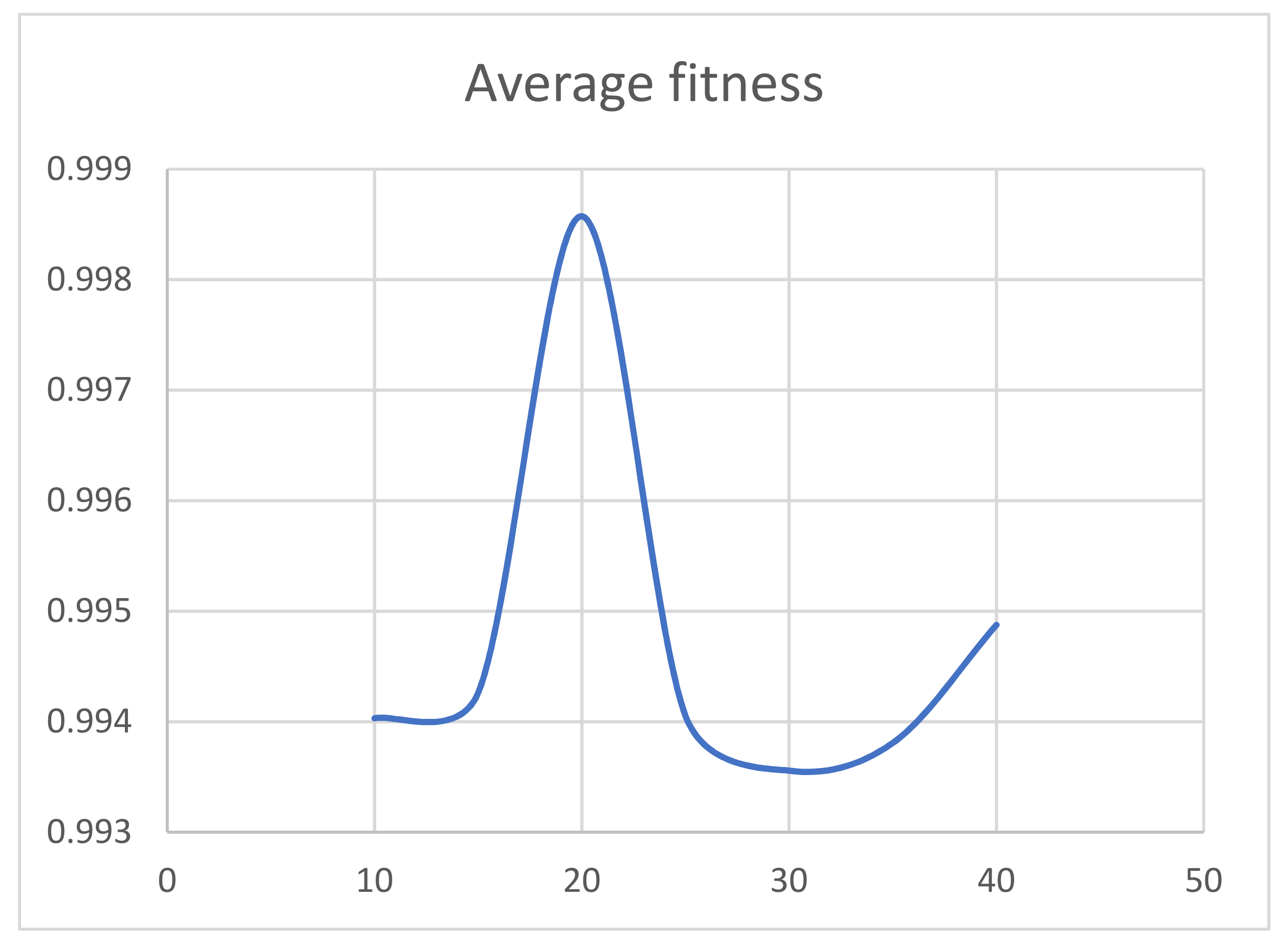
4.2. Analysis of Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Medical Data in the Crosshairs: Why Is Healthcare an Ideal Target? 14 August 2021. Available online: https://www.trendmicro.com/vinfo/us/security/news/cyber-attacks/medical-data-in-the-crosshairs-why-is-healthcare-an-ideal-target (accessed on 15 May 2020).
- Conaty-Buck, S. Cybersecurity and healthcare records. Am. Nurse Today 2017, 12, 62–64. [Google Scholar]
- eGOVERNMENT, Cloud Computing Initiatives. 22 April 2021. Available online: https://www.bahrain.bh/ (accessed on 15 July 2021).
- Moukhafi, M.; El Yassini, K.; Bri, S. A novel hybrid GA and SVM with PSO feature selection for intrusion detection system. Int. J. Adv. Sci. Res. Eng. 2018, 4, 129–134. [Google Scholar] [CrossRef]
- Kuang, F.; Xu, W.; Zhang, S. A novel hybrid KPCA and SVM with GA model for intrusion detection. Appl. Soft Comput. J. 2014, 18, 178–184. [Google Scholar] [CrossRef]
- Al-Yaseen, W.L.; Othman, Z.A.; Nazri, M.Z.A. Multi-level hybrid support vector machine and extreme learning machine based on modified K-means for intrusion detection system. Expert Syst. Appl. 2017, 67, 296–303. [Google Scholar] [CrossRef]
- Feng, W.; Zhang, Q.; Hu, G.; Huang, J.X. Mining network data for intrusion detection through combining SVMs with ant colony networks. Future Gener. Comput. Syst. 2014, 37, 127–140. [Google Scholar] [CrossRef]
- Ambusaidi, M.A.; He, X.; Nanda, P.; Tan, Z. Building an intrusion detection system using a filter-based feature selection algorithm. IEEE Trans. Comput. 2016, 65, 2986–2998. [Google Scholar] [CrossRef] [Green Version]
- Mustapha, B.; Salah, E.H.; Mohamed, I. A two-stage classifier approach using RepTree algorithm for network intrusion detection. Int. J. Adv. Comput. Sci. Appl. (IJACSA) 2017, 8, 389–394. [Google Scholar]
- Tuan, A.; McLernon, D.; Mhamdi, L.; Zaidi, S.A.R.; Ghogho, M. Intrusion Detection in SDN-Based Networks: Deep Recurrent Neural Network Approach. In Advanced Sciences and Technologies for Security Applications; Springer: Berlin/Heidelberg, Germany, 2019; pp. 175–195. [Google Scholar]
- Nguyen, K.K.; Hoang, D.T.; Niyato, D.; Wang, P.; Nguyen, D.; Dutkiewicz, E. Cyberattack detection in mobile cloud computing: A deep learning approach. In Proceedings of the IEEE Wireless Communications and Networking Conference, Barcelona, Spain, 15–18 April 2018. [Google Scholar]
- He, D.; Qiao, Q.; Gao, Y.; Zheng, J.; Chan, S.; Li, J.; Guizani, N. Intrusion detection based on stacked autoencoder for connected healthcare systems. IEEE Netw. 2019, 33, 64–69. [Google Scholar] [CrossRef]
- Mudzingwa, D.; Agrawal, R. A study of methodologies used in intrusion detection and prevention systems (IDPS). In Proceedings of the IEEE Southeastcon, Orlando, FL, USA, 15–18 March 2012. [Google Scholar]
- Aljawarneh, S.; Aldwairi, M.; Yassein, M.B. Anomaly-based intrusion detection system through feature selection analysis and building hybrid efficient model. J. Comput. Sci. 2018, 25, 152–160. [Google Scholar] [CrossRef]
- Ludinard, R.; Totel, É.; Tronel, F.; Nicomette, V.; Kaâniche, M.; Alata, É.; Bachy, Y. Detecting attacks against data in web applications. In Proceedings of the 7th International Conference on Risks and Security of Internet and Systems (CRiSIS), Cork, Ireland, 10–12 October 2012. [Google Scholar]
- Li, X.; Xue, Y.; Malin, B. Detecting anomalous user behaviors in workflow-driven web applications. In Proceedings of the IEEE Symposium on Reliable Distributed Systems, Irvine, CA, USA, 8–11 October 2012; pp. 1–10. [Google Scholar]
- Le, M.; Stavrou, A.; Kang, B.B. DoubleGuard: Detecting intrusions in multitier web applications. IEEE Trans. Dependable Secur. Comput. 2012, 9, 512–525. [Google Scholar] [CrossRef]
- Nascimento, G.; Correia, M. Anomaly-based intrusion detection in software as a service. In Proceedings of the 2011 IEEE/IFIP 41st International Conference on Dependable Systems and Networks Workshops (DSN-W), Hong Kong, China, 27–30 June 2011; pp. 19–24. [Google Scholar]
- Ariu, D. Host and Network Based Anomaly Detectors for HTTP Attacks. Ph.D. Thesis, University of Cagliari, Cagliari, Italy, 2010. [Google Scholar]
- Gimenez, C.; Villaegas, A.; Alvarez, G. An Anomaly-Based Approach for Intrusion Detection in Web Traffic. J. Inf. Assur. Secur. 2010, 5, 446–454. [Google Scholar]
- Saraniya, G. Securing the Network Using Signature Based IDS in Network IDS. Shodhshauryam Int. Sci. Refereed Res. J. 2019, 2, 99–101. [Google Scholar]
- Gao, W.; Morris, T. On Cyber Attacks and Signature Based Intrusion Detection for Modbus Based Industrial Control Systems. J. Digit. Forensics Secur. Law 2014, 9, 37–56. [Google Scholar] [CrossRef]
- Uddin, M.; Rehman, A.A.; Uddin, N.; Memon, J.; Alsaqour, R.; Kazi, S. Signature-based multi-layer distributed intrusion detection system using mobile agents. Int. J. Netw. Secur. 2013, 15, 97–105. [Google Scholar]
- Kumar, U.; Gohil, B.N. A Survey on Intrusion Detection Systems for Cloud Computing Environment. Int. J. Comput. Appl. 2015, 109, 6–15. [Google Scholar] [CrossRef]
- Lewis, P.M. The characteristic selection problem in recognition system. IEEE Trans. Inf. Theory 1962, 8, 171–178. [Google Scholar] [CrossRef]
- Shakya, V.; Makwana, R.R.S. Feature selection-based intrusion detection system using the combination of DBSCAN, K-Mean++ and SMO algorithms. In Proceedings of the 2017 International Conference on Trends in Electronics and Informatics (ICEI), Tirunelveli, India, 11–12 May 2017; pp. 928–932. [Google Scholar] [CrossRef]
- Almomani, O. A Feature Selection Model for Network Intrusion Detection System Based on PSO, GWO, FFA and GA Algorithms. Symmetry 2020, 12, 1046. [Google Scholar] [CrossRef]
- Gul, A.; Adali, E. A feature selection algorithm for IDS. In Proceedings of the 2017 International Conference on Computer Science and Engineering (UBMK), Antalya, Turkey, 5–8 October 2017; pp. 816–820. [Google Scholar] [CrossRef]
- Gharaee, H.; Hosseinvand, H. A new feature selection IDS based on genetic algorithm and SVM. In Proceedings of the 2016 8th International Symposium on Telecommunications (IST), Tehran, Iran, 27–28 September 2016; pp. 139–144. [Google Scholar] [CrossRef]
- Parimala, G.; Kayalvizhi, R. An Effective Intrusion Detection System for Securing IoT Using Feature Selection and Deep Learning. In Proceedings of the 2021 International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, 27–29 January 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Hakim, L.; Fatma, R. Influence Analysis of Feature Selection to Network Intrusion Detection System Performance Using NSL-KDD Dataset. In Proceedings of the 2019 International Conference on Computer Science, Information Technology, and Electrical Engineering (ICOMITEE), Jember, Indonesia, 16–17 October 2019; pp. 217–220. [Google Scholar] [CrossRef]
- Ahmadi, S.S.; Rashad, S.; Elgazzar, H. Efficient Feature Selection for Intrusion Detection Systems. In Proceedings of the 2019 IEEE 10th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 10–12 October 2019; pp. 1029–1034. [Google Scholar] [CrossRef]
- Wang, W.; Du, X.; Wang, N. Building a Cloud IDS Using an Efficient Feature Selection Method and SVM. IEEE Access 2019, 7, 1345–1354. [Google Scholar] [CrossRef]
- Tao, P.; Sun, Z.; Sun, Z. An Improved Intrusion Detection Algorithm Based on GA and SVM. IEEE Access 2018, 6, 13624–13631. [Google Scholar] [CrossRef]
- Hsu, C.-W.; Chang, C.-C.; Lin, C.-J. A Practical Guide to Support Vector Classification; Department of Computer Science, National Taiwan University: Taipei, Taiwan, 2003. [Google Scholar]
- Rai, N.; Rai, K. Genetic algorithm-based intrusion detection system. Int. J. Comput. Sci. Inf. Technol. 2014, 5, 4952–4957. [Google Scholar]
- Ojugo, A.A.; Eboka, A.O.; Okonta, O.E.; Yoro, R.E.; Aghware, F.O. Genetic Algorithm Rule-Based Intrusion Detection System (GAIDS). J. Emerg. Trends Comput. Inf. Syst. 2012, 3, 1182–1194. [Google Scholar]
- Bhattacharjee, P.S. Intrusion Detection System for NSL-KDD Data Set using Vectorised Fitness Function in Genetic Algorithm. Adv. Comput. Sci. Technol. 2017, 10, 235–246. [Google Scholar]
- Kalavadekar, M.P.N.; Sane, S.S. Building an Effective Intrusion Detection System using Genetic Algorithm based Feature Selection. Int. J. Comput. Sci. Inf. Secur. 2018, 16, 97–110. [Google Scholar]
- Gong, R.H.; Zulkernine, M.; Abolmaesumi, P. A software implementation of a genetic algorithm-based approach to network intrusion detection. In Proceedings of the Sixth International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing and First ACIS International Workshop on Self-Assembling Wireless Network, Towson, MD, USA, 23–25 May 2005; Volume 2005, pp. 246–253. [Google Scholar]
- Pawar, S.N.; Bichkar, R.S. Genetic algorithm with variable length chromosomes for network intrusion detection. Int. J. Autom. Comput. 2015, 12, 337–342. [Google Scholar] [CrossRef]
- Agarwal, B.; Mittal, N. Hybrid Approach for Detection of Anomaly Network Traffic using Data Mining Techniques. Procedia Technol. 2012, 6, 996–1003. [Google Scholar] [CrossRef]
- Serpen, G.; Aghaei, E. Host-based misuse intrusion detection using PCA feature extraction and kNN classification algorithms. Intell. Data Anal. 2018, 22, 1101–1114. [Google Scholar] [CrossRef]
- Praveen, K.; Rajendran, M.; Rajesh, R. Healthcare Systems Hybrid Intrusion Detection Algorithm for Private Cloud. Indian J. Sci. Technol. 2015, 48, 325–329. [Google Scholar]
- CICIDS2017, Intrusion Detection Evaluation Dataset, Last Update (2020). Available online: https://www.kaggle.com/cicdataset/cicids2017 (accessed on 25 February 2021).
- KDD Cup 1999 Data. Available online: http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html (accessed on 23 February 2021).
- Pozi, M.; Sulaiman, M.N.; Mustapha, N.; Perumal, T. Improving Anomalous Rare Attack Detection Rate. Neural Process. Lett. 2015, 44, 279–290. [Google Scholar] [CrossRef]
- Khan, M.A.; Ghazal, T.M.; Lee, S.W.; Rehman, A. Data Fusion-Based Machine Learning Architecture for Intrusion Detection. Comput. Mater. Contin. 2021, 70, 3399–3413. [Google Scholar] [CrossRef]
- Khan, A.; Abbas, S.; Rehman, A.; Saeed, Y.; Zeb, A.; Uddin, M.I.; Nasser, N.; Ali, A. A machine learning approach for blockchain-based smart home networks security. IEEE Netw. 2021, 35, 223–229. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Anomaly-Based IDS | |
|---|---|
| Characteristics | Limitations |
| This technique is time-consuming. It needs many features to detect attacks correctly. |
| Signature-Based IDS | |
| Characteristics | Limitations |
| Very high rate of false alarm for unknown attacks. Cannot detect a variant of a known attack or new attacks. |
| Hybrid Techniques for IDS | |
| Characteristic | Limitation |
| Computational cost is very high. |
| No. | Feature Name | No. | Feature Name | No. | Feature Name |
|---|---|---|---|---|---|
| 1 | Destination_Port | 27 | Bwd_IAT_Max | 53 | Avg_Bv/d_Segment_Size |
| 2 | Flow_Duration | 28 | Bwd_IAT_Min | 54 | Fwd_Header_Length |
| 3 | Total_Fwd_Packets | 29 | Fwd_PSH_Flags | 55 | Fwd_Avg_Bytes_Bulk |
| 4 | Total_Backward_Packets | 30 | Bwd_PSH_Flags | 56 | Fwd_Avg_Packets_Bulk |
| 5 | Total_Length_of_Fwd_Packets | 31 | Fv/d_URG_Flags | 57 | Fwd_Avg_Bulk_Rate |
| 6 | Total_Length_of_Bwd_Packets | 32 | Bwd_URG_Flags | 58 | Bwd_Avg_Bytes_Bulk |
| 7 | Fwd_Packet_Length_Max | 33 | Fwd_Header_Length | 59 | Bwd_Avg_Packets_Bulk |
| 8 | Fwd_Packet_Length_Min | 34 | Bwd_Header_Length | 60 | Bv/d_Avg_Bulk_Rate |
| 9 | Fwd_Packet_Length_Mean | 35 | Fv/d_Packets_s | 61 | Subflow_Fwd_Packets |
| 10 | Fwd_Packet_Length_Std | 36 | Bwd_Packets_s | 62 | Subflow_Fv/d_Bytes |
| 11 | Bwd_Packet_Length_Max | 37 | Min_Packet_Length | 63 | Subflow_Bv/d_Packets |
| 12 | Bwd_Packet_Length_Min | 38 | Max_Packet_Length | 64 | Subflow_Bv/d_Bytes |
| 13 | Bwd_Packet_Length_Mean | 39 | Packet_Length_Mean | 65 | Init_Win_bytes_forward |
| 14 | Bwd_Packet_Length_Std | 40 | Packet_Length_Std | 66 | Init_Win_bytes_backward |
| 15 | Flow_IAT_Mean | 41 | Packet_Length_Variance | 67 | act_data_pkt_fwd |
| 16 | Flow_IAT_Std | 42 | FIN_Flag_Count | 68 | min_seg_size_forward |
| 17 | Flow_IAT_Max | 43 | SYN_Flag_Count | 69 | Active_Mean |
| 18 | Flow_IAT_Min | 44 | RST_Flag_Count | 70 | Active_Std |
| 19 | Fwd_IAT_Total | 45 | PSH_Flag_Count | 71 | Active_Max |
| 20 | Fwd_IAT_Mean | 46 | ACK_Flag_Count | 72 | Active_Min |
| 21 | Fwd_lATStd | 47 | URG_Flag_Count | 73 | Idle_Mean |
| 22 | Fwd_IAT_Max | 48 | CWE_Flag_Count | 74 | Idle_Std |
| 23 | Fwd_IAT_Min | 49 | ECE_Flag_Count | 75 | Idle_Max |
| 24 | Bwd_1_AT_Total | 50 | Down_Up_Ratio | 76 | Idle_Min |
| 25 | Bwd_IAT_Mean | 51 | Average_Packet_Size | 77 | Label |
| 26 | Bwd_lATStd | 52 | Avg_Fv/d_Segment_Size |
| No. | Feature Name | No. | Feature Name |
|---|---|---|---|
| 1 | duration | 22 | is_guest_login |
| 2 | protocol_type | 23 | count |
| 3 | service | 24 | srv_count |
| 4 | flag | 25 | serror_rate |
| 5 | src_bytes | 26 | srv_serror_rate |
| 6 | dst_bytes | 27 | rerror_rate |
| 7 | land | 28 | srv_rerror_rate |
| 8 | wrong_fragment | 29 | same_srv_rate |
| 9 | urgent | 30 | diff_srv_rate |
| 10 | hot | 31 | srv_diff_host_rate |
| 11 | num_failed_logins | 32 | dst_host_count |
| 12 | logged_in | 33 | dst_host_srv_count |
| 13 | Inum_compromised | 34 | dst_host_same_srv_rate |
| 14 | Iroot_shell | 35 | dst_host_diff_srv_rate |
| 15 | Isu_attempted | 36 | dst_host_same_src_port_rate |
| 16 | Inum_root | 37 | dst_host_srv_diff_host_rate |
| 17 | Inum_file_creations | 38 | dst_host_serror_rate |
| 18 | Inum_shells | 39 | dst_host_srv_serror_rate |
| 19 | Inum_access_files | 40 | dst_host_rerror_rate |
| 20 | Inum_outbound_cmds | 41 | dst_host_srv_rerror_rate |
| 21 | is_host_login | 42 | label |
| Kernel | Gamma | Degree |
|---|---|---|
| Linear | Scale AUTO | 3 |
| Poly | Scale AUTO | 1, 2, 3 |
| RBF | Scale AUTO | 3 |
| Sigmoid | Scale AUTO | 3 |
| SVM Parameters | Fitness Value |
|---|---|
| svclassifier = SVC (kemel = ‘linear’, gamma = ‘scale’, degree = 3) | 0.994302 |
| svclassifier = SVC (kernel = ‘linear’, gamma = ‘auto’, degree = 3) | 0.994302 |
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘scale’, degree = l) | 0.994302 |
| svclassifier = SVC (kemel = ‘poly’, gamma = ‘scale’, degree = 2) | 0.994542 |
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘scale’, degree = 3) | 0.994542 |
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘auto’, degree = l) | 0.994302 |
| svclassifier = SVC (kemel = ‘poly’, gamma = ‘auto’, degree = 2) | 0.994583 |
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘auto’, degree = 3) | 0.994542 |
| svclassifier = SVC (kernel = ‘rbf’, gamma = ‘scale’, degree = 3) | 0.994624 |
| svclassifier = SVC (kernel = ‘rbf’, gamma = ‘auto’, degree = 3) | 0.994624 |
| svclassifier = SVC (kemel = ‘sigmoid’, gamma = ‘scale’, degree = 3) | 0.991761 |
| svclassifier = SVC (kemel = ‘sigmoid’, gamma = ‘auto’, degree = 3) | 0.991947 |
| Average | 0.994031 |
| 15 Features | |
|---|---|
| SVM Parameters | Fitness Value |
| svclassifier = SVC (kernel = ‘linear’, gamma = ‘scale’, degree = 3) | 0.994562 |
| svclassifier = SVQ (kernel = ‘linear’, gamma = ‘auto’, degree = 3) | 0.994562 |
| svdassifler = SVC (kernel = ‘poly’, gamma = ‘scale’, degree = l) | 0.994281 |
| svdasslfter = SVC (kernel = ‘poly’, gamma = ‘scale’, degree = 2) | 0.994583 |
| svclassifier = SVC (kernel = ’poly’, gamma = ‘scale’, degree = 3) | 0.994583 |
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘auto’, degree = l) | 0.994302 |
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘auto’, degree = 2) | 0.994583 |
| svdassifier = SVC (kernel = ‘poly’, gamma = ‘auto’, degree = 3) | 0.994583 |
| svdassifier = SVC (kernel = ’rbf’, gamma = ‘scale’, degree = 3) | 0.994604 |
| svdassifier = SVC (kernek = ‘rbf’, gamma = ‘auto’, degree = 3) | 0.994604 |
| svdassifier = SVC (kernel = ‘sigmoid’, gamma = ‘scale’, degree = 3) | 0.992954 |
| svdassifier = SVC (kernel = ‘sigmoid’, gamma = ‘auto’, degree = 3) | 0.992954 |
| Average | 0.994263 |
| 20 Features | Confusion Matrix | |
|---|---|---|
| SVM Parameters | Fitness Value | |
| svclassifier = SVC (kernel = ‘linear’, gamma = ‘scale’, degree = 3) | 1 | [[18758 551] |
| [ 411 79084]] | ||
| svdassifier = SVC (kernel = ‘linear’, gamma = ‘auto’, degree = 3) | 1 | [[18758 551] |
| [ 411 79084]] | ||
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘scale’, degree = l) | 1 | [[18762 547] |
| [ 850 78645]] | ||
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘scale’, degree = 2) | 1 | [[19215 94] |
| [ 106 79389]] | ||
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘scale’, degree = 3) | 0.997437 | [[33494 193] |
| [ 47 340]] | ||
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘auto’, degree = l) | 1 | [[33429 258] |
| [ 48 339]] | ||
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘auto’, degree = 2) | 1 | [[33487 200] |
| [ 47 340]] | ||
| svclassifier = SVC (kernel-‘poly’, gamma = ‘auto’, degree = 3) | 0.999979 | [[33686 1] |
| [ 368 19]] | ||
| svclassifier = SVC (kernel = ‘rbf’, gamma = ‘scale’, degree = 3) | 0.994901 | [[19228 81] |
| [ 61 79434]] | ||
| svclassifier = SVC (kernel = ‘rbf’, gamma = ‘auto’, degree = 3) | 0.998482 | [[33521 166] |
| [ 49 338]] | ||
| svclassifier = SVC (kernel = ‘sigmoid’, gamma = ‘scale’, degree = 3) | 0.998649 | [[33399 288] |
| svclassifier = SVC (‘kernel-sigmoid’, gamma = ‘auto’, degree = 3) | 0.99344 | [ 233 154]] |
| Average | 0.998574 | [[33436 251] |
| 25 Features | |
|---|---|
| SVM Parameters | Fitness Value |
| svclassifier = SVC (kernel = ‘linear’, gamma = ‘scale’, degree = 3) | 0.994427 |
| svclassifier = SVC (kemel = ‘linear’, gamma = ‘auto’, degree = 3) | 0.994427 |
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘scale’, degree = l) | 0.99426 |
| svclassifier = SVC (kemel = ‘poly’, gamma = ‘scale’, degree = 2) | 0.995953 |
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘scale’, degree = 3) | 0.996404 |
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘auto’, degree = l) | 0.99426 |
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘auto’, degree = 2) | 0.995953 |
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘auto’, degree = 3) | 0.996341 |
| svclassifier = SVC (kemel = ‘rbf’, gamma = ‘scale’, degree = 3) | 0.996762 |
| svclassifier = SVC (kernel = ‘rbf’, gamma = ‘auto’, degree = 3) | 0.996762 |
| svclassifier = SVC (kernel = ‘sigmoid’, gamma = ‘scale’, degree = 3) | 0.986537 |
| svclassifier = SVC (kemel = ‘sigmoid’, gamma = ‘auto’, degree = 3) | 0.986537 |
| Average | 0.994052 |
| 30 Features | |
|---|---|
| SVM Parameters | Fitness Value |
| svclassifier = SVC (kemel = ‘linear’, gamma = ‘scale’, degree = 3) | 0.994583 |
| svclassifier = SVC (kernel = ‘linear’, gamma = ‘auto’, degree = 3) | 0.994583 |
| svclassifier = SVC (kemel = ‘poly’, gamma = ‘scale’, degree = l) | 0.994583 |
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘scale’, degree = 2) | 0.994624 |
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘scale’, degree = 3) | 0.994539 |
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘auto’, degree = l) | 0.994583 |
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘auto’, degree = 2) | 0.994624 |
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘auto’, degree = 3) | 0.996804 |
| svclassifier = SVC (kernel = ‘rbf’, gamma = ‘scale’, degree = 3) | 0.99458 |
| svclassifier = SVC (kernel = ‘rbf’, gamma = ‘auto’, degree = 3) | 0.99458 |
| svclassifier = SVC (kernel = ‘sigmoid’, gamma = ‘scale’, degree = 3) | 0.987238 |
| svclassifier = SVC (kernel = ‘sigmoid’, gamma = ‘auto’, degree = 3) | 0.987363 |
| Average | 0.993557 |
| 35 Features | |
|---|---|
| SVM Parameters | Fitness Value |
| svclassifier = SVC (kernel = ‘linear’, gamma = ‘scale’, degree = 3) | 0.992532 |
| svclassifier = SVC (kemel = ‘linear’, gamma = ‘auto’, degree = 3) | 0.992532 |
| svclassifier = SVC (kemeI = ‘poly’, gamma = ‘scale’, degree = l) | 0.996033 |
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘scale’, degree = 2) | 0.996951 |
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘scale’, degree = 3) | 0.996951 |
| svclassifier = SVC (kemel = ‘poly’, gamma = ‘auto’, degree = l) | 0.995778 |
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘auto’, degree = 2) | 0.992633 |
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘auto’, degree = 3) | 0.992574 |
| svclassifier = SVC (kernel = ‘rbf’, gamma = ‘scale’, degree = 3) | 0.993822 |
| svclassifier = SVC (kernel = ‘rbf’, gamma = ‘auto’, degree = 3) | 0.993808 |
| svclassifier = SVC (kernel = ‘sigmoid’, gamma = ‘scale’, degree = 3) | 0.986881 |
| svclassifier = SVC (kernel = ‘sigmoid’, gamma = ‘auto’, degree = 3) | 0.992652 |
| Average | 0.993808 |
| 40 Features | |
|---|---|
| SVM Parameters | Fitness Value |
| svclassifier = SVC (kernel = ‘linear’, gamma = ‘scale’, degree = 3) | 0.995964 |
| svclassifier = SVC (kemel = ‘linear’, gamma = ‘auto’, degree = 3) | 0.995964 |
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘scale’, degree = l) | 0.989691 |
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘scale’, degree = 2) | 0.991477 |
| svclassifier = SVC (kemel = ‘poly’, gamma = ‘scale’, degree = 3) | 0.995303 |
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘auto’, degree = l) | 0.99463 |
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘auto’, degree = 2) | 0.995839 |
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘auto’, degree = 3) | 0.999979 |
| svclassifier = SVC (kernel = ‘rbf’, gamma = ‘scale’, degree = 3) | 0.996609 |
| svclassifier = SVC (kernel = ‘rbf’, gamma = ‘auto’, degree = 3) | 0.996547 |
| svclassifier = SVC (kemel = ‘sigmoid’, gamma = ‘scale’, degree = 3) | 0.991734 |
| svclassifier = SVC (kernel = ‘sigmoid’, gamma = ‘auto’, degree = 3) | 0.994776 |
| Average | 0.994876 |
| 15 Features | |
|---|---|
| SVM Parameters | Fitness Value |
| svclassifier = SVC (kernel= ‘linear’, gamma = ‘scale’, degree = 3) | 0.980213 |
| svclassifier = SVC (kernel = ‘linear’, gamma = ‘auto’, degree = 3) | 0.980213 |
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘scale’, degree = l) | 0.972088 |
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘scale’, degree = 2) | 0.985217 |
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘scale’, degree = 3) | 0.992792 |
| svclassifier = SVC (kemel = ‘poly’, gamma = ‘auto’, degree = l) | 0.972032 |
| svclassifier = SVC (kernel = ‘poly’, gamma = ‘auto’, degree = 2) | 0.985074 |
| svclassifier = SVC (kemel = ‘poly’, gamma = ‘auto’, degree = 3) | 0.991780 |
| svclassifier = SVC (kernel = ‘rbf’, gamma = scale’, degree = 3) | 0.992975 |
| svclassifier = SVC (kemel = ‘rbf’, gamma = ‘auto’, degree = 3) | 0.992650 |
| svclassifier = SVC (kernel = ‘sigmoid’, gamma = ‘scale’, degree = 3) | 0.893446 |
| svclassifier = SVC (kernel = ‘sigmoid’, gamma = ‘auto’, degree = 3) | 0.886727 |
| Average | 0.968767 |
| Authors | Detection Rate (DR) | Proposed Method (DR) | Achieved Improvement (%) |
|---|---|---|---|
| M. Moukhafi et al., 2018 [4] | 96.38% | 100% | 3.32 |
| F. Kuang et al., 2018 [5] | 95.26% | 4.74 | |
| Al-yaseen et al., 2018 [6] | 95.17% | 4.83 | |
| W. Feng et al., 2014 [7] | 94.86% | 5.14 |
| Authors | Accuracy Rate (%) | Dataset | Achieved Improvement (%) |
|---|---|---|---|
| Proposed Hybrid IDS (this work) | 99.3 | KDD CUP 99 | — |
| M. Moukhafi et al., 2018 [4] | 96.38 | 3.03 | |
| F. Kuang et al., 2018 [5] | 95.26 | 4.24 | |
| Al-yaseen et al., 2018 [6] | 95.17 | 4.34 | |
| W. Feng et al., 2014 [7] | 94.86 | 4.68 | |
| Khan et al., 2021 [49] | 94.6 | 4.97 | |
| Bhattacharjee et al., 2017 (f1) [39] | 99.18 | NSL-KDD | 0.12 |
| Bhattacharjee et al., 2017 (f2) [39] | 99.02 | 0.28 | |
| Pozi et al., 2016 [47] | 97.59 | 1.75 | |
| Khan et al., 2021 [49] | 93.91 | 5.74 | |
| Khan et al., 2021 [48] | 93.58 | KDD CUP 99 and NSL-KDD | 6.11 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aldallal, A.; Alisa, F. Effective Intrusion Detection System to Secure Data in Cloud Using Machine Learning. Symmetry 2021, 13, 2306. https://doi.org/10.3390/sym13122306
Aldallal A, Alisa F. Effective Intrusion Detection System to Secure Data in Cloud Using Machine Learning. Symmetry. 2021; 13(12):2306. https://doi.org/10.3390/sym13122306
Chicago/Turabian StyleAldallal, Ammar, and Faisal Alisa. 2021. "Effective Intrusion Detection System to Secure Data in Cloud Using Machine Learning" Symmetry 13, no. 12: 2306. https://doi.org/10.3390/sym13122306
APA StyleAldallal, A., & Alisa, F. (2021). Effective Intrusion Detection System to Secure Data in Cloud Using Machine Learning. Symmetry, 13(12), 2306. https://doi.org/10.3390/sym13122306