
A New Linear Regression Kalman Filter with Symmetric Samples



Abstract
:1. Introduction
2. Preliminaries
- In the prediction step, employing the system model (1) and the Chapman–Kolomogorov equation, we can obtainwhere
- In the updating step, when the latest measurement arrives, using Bayes’ rule, we havewhere the likelihood function is obtained according towith
2.1. Nonlinear Kalman Filtering Based on Statistical Linearization
- 1.
- Initialization: The initial density of is approximated by Gaussian:with the initial meanand initial covariance
- 2.
- Prediction: The apriori density function is approximated bywith predicted state meanand predicted state covariance matrixrespectively.
- 3.
- Updating: The Bayesian filter step (5) can be reformulated in form of the joint density according toHere, this joint density is approximated by Gaussianthen according to Theorem A2 in Appendix A, posterior state meanand posterior state covariance matrixwhere the measurement meanthe measurement covariance matrixas well as the cross-covariance matrix of predicted state and measurement
2.2. The Linear Regression Kalman Filter
2.3. The Smart Sampling Kalman Filter
3. The New Linear Regression Kalman Filter
3.1. Kullback–Leibler Divergence and Stein Variational Gradient Descent
| Algorithm 1:Off-Line Computation |
|
3.2. On-Line Filtering Algorithm
- when , and are the initial mean and covariance of initial density , respectively. The initial particles are generated according to
- For , given , and , letthen we have
- when the measurement arrives, letand computewithThe particles are updated according to
| Algorithm 2: On-Line Computation |
|
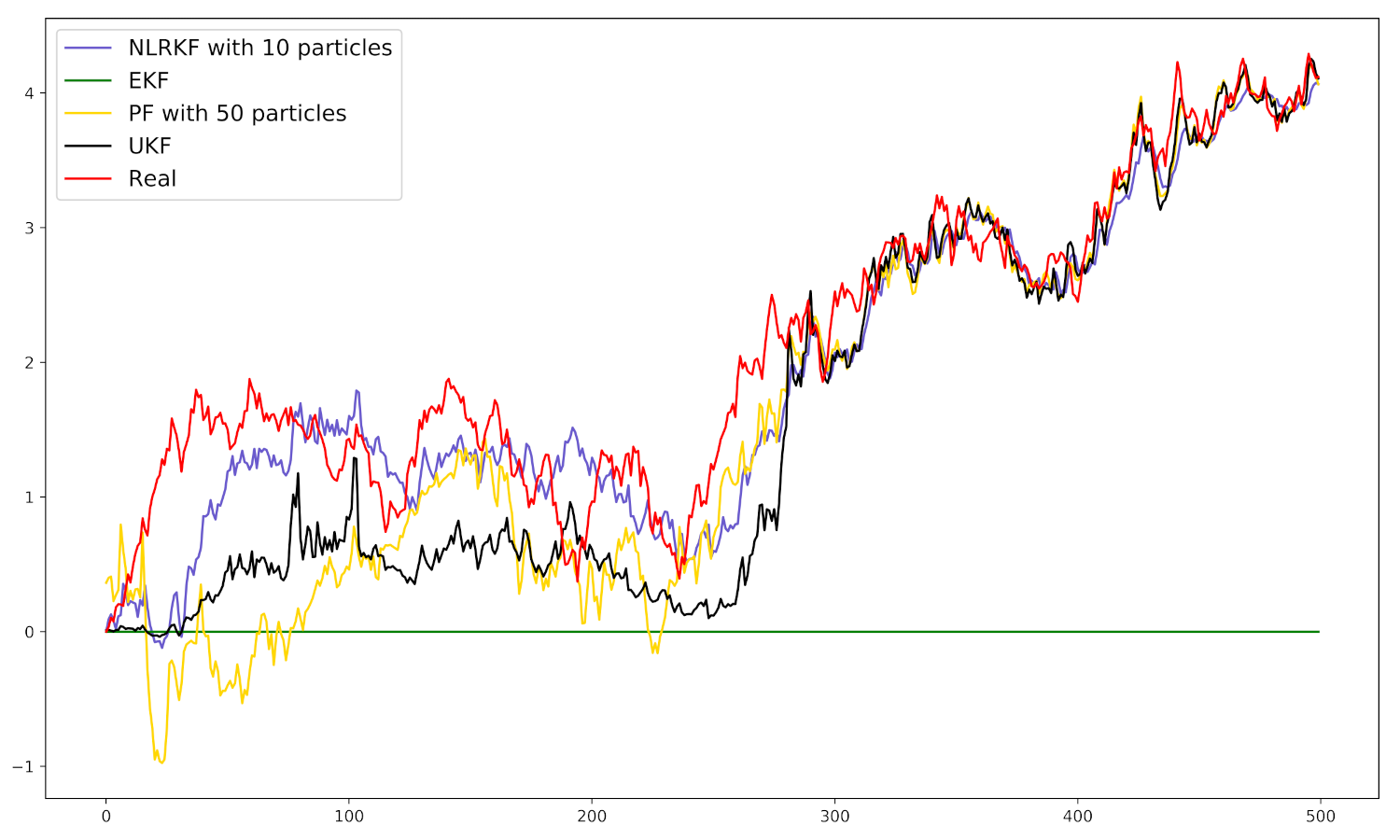
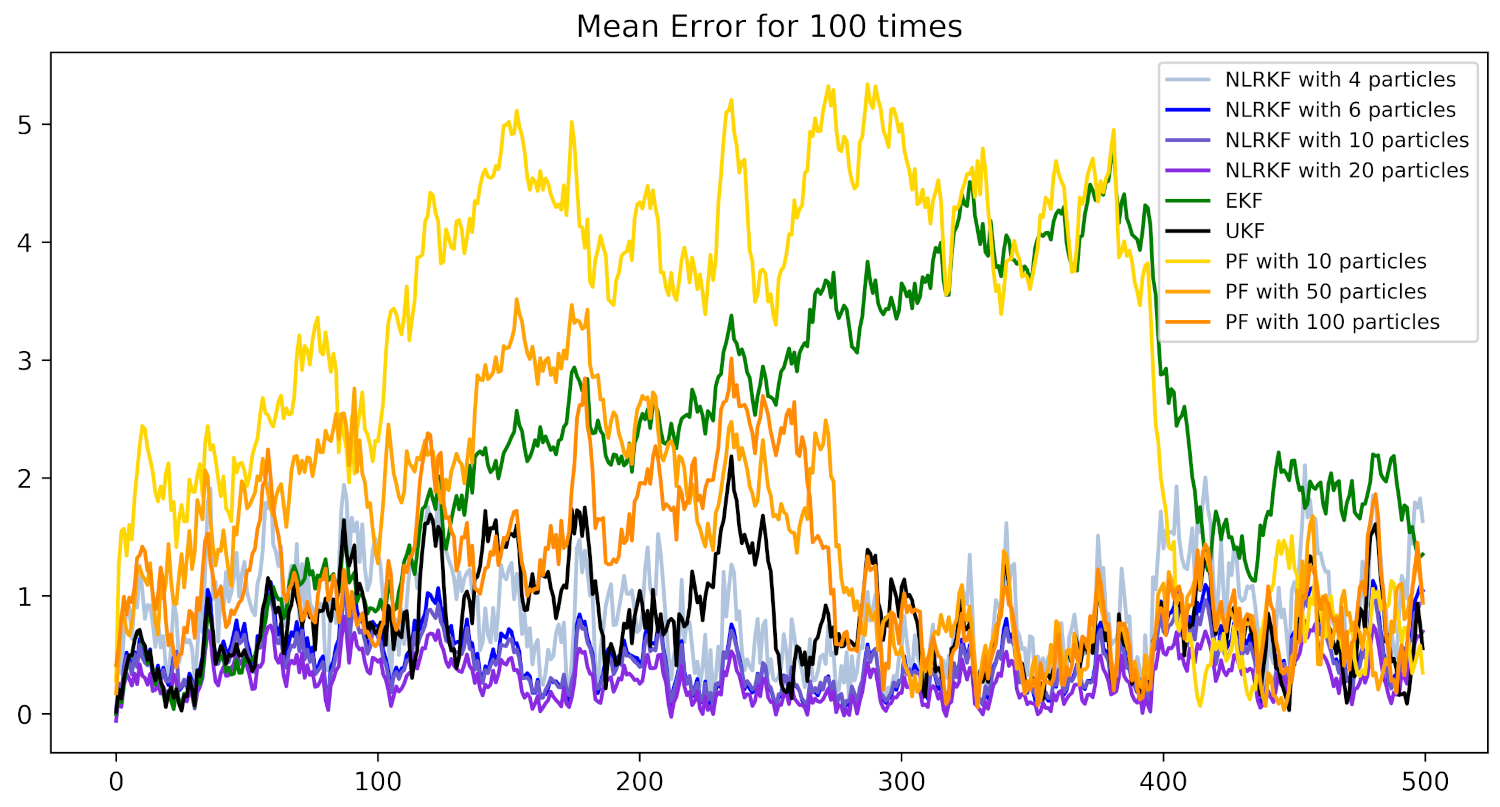
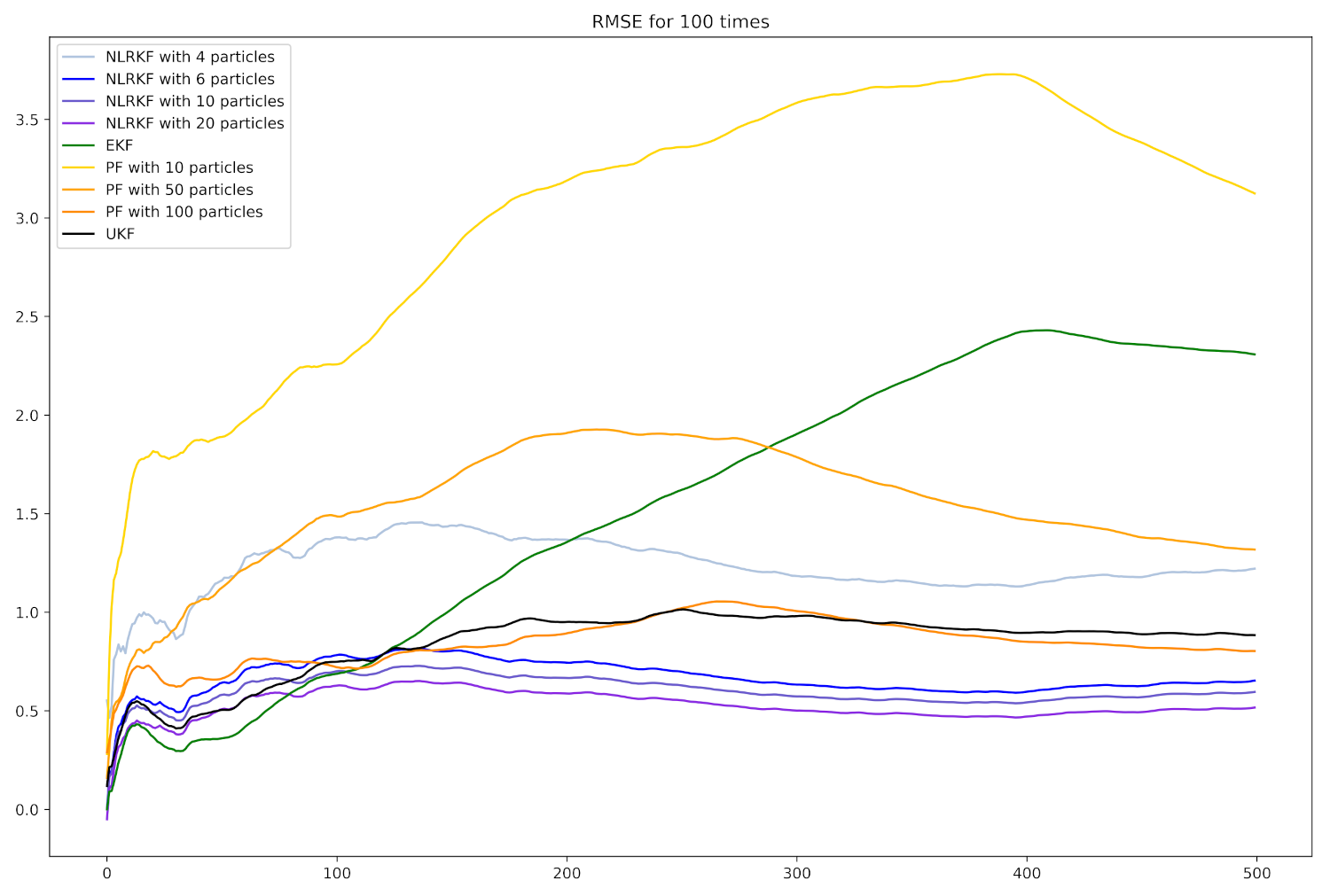
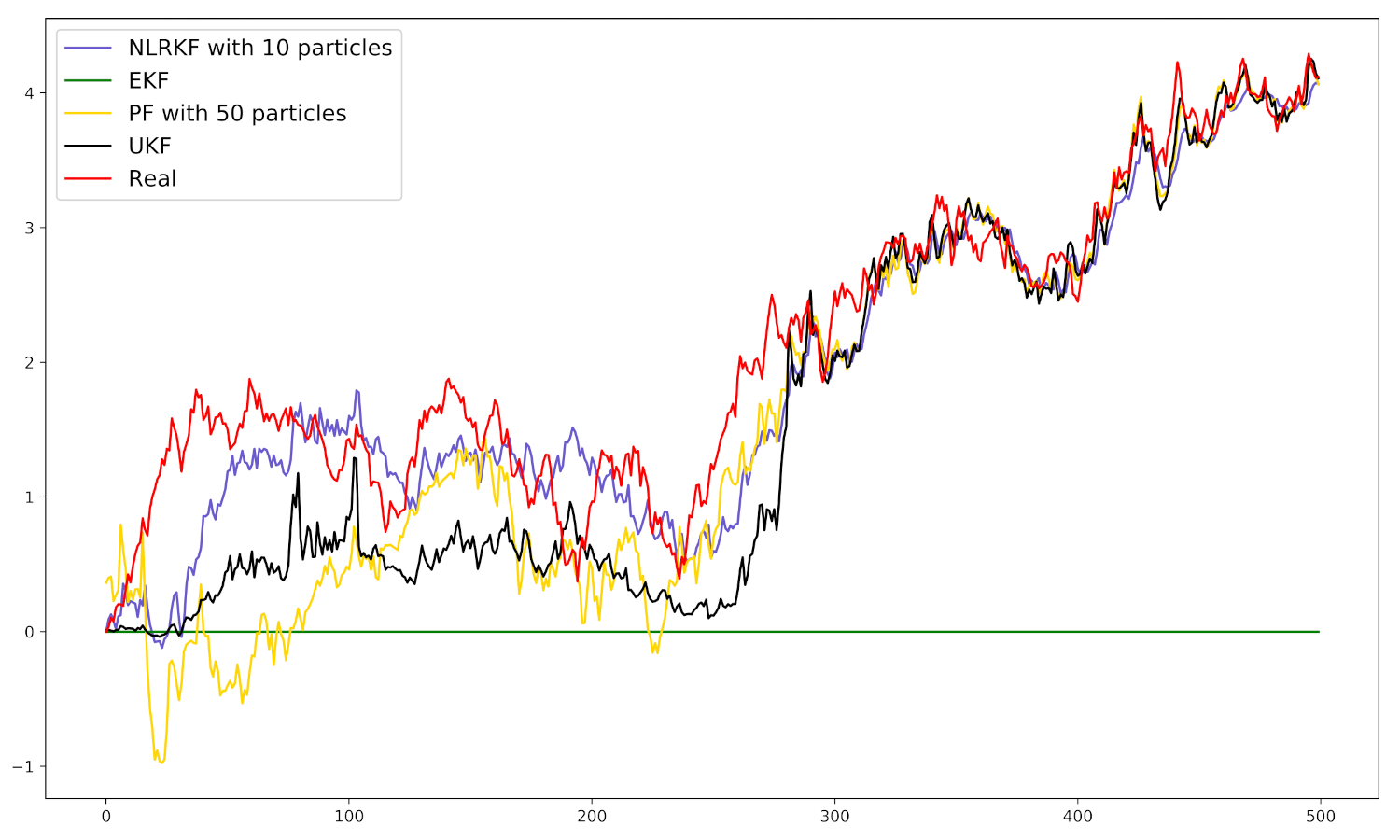
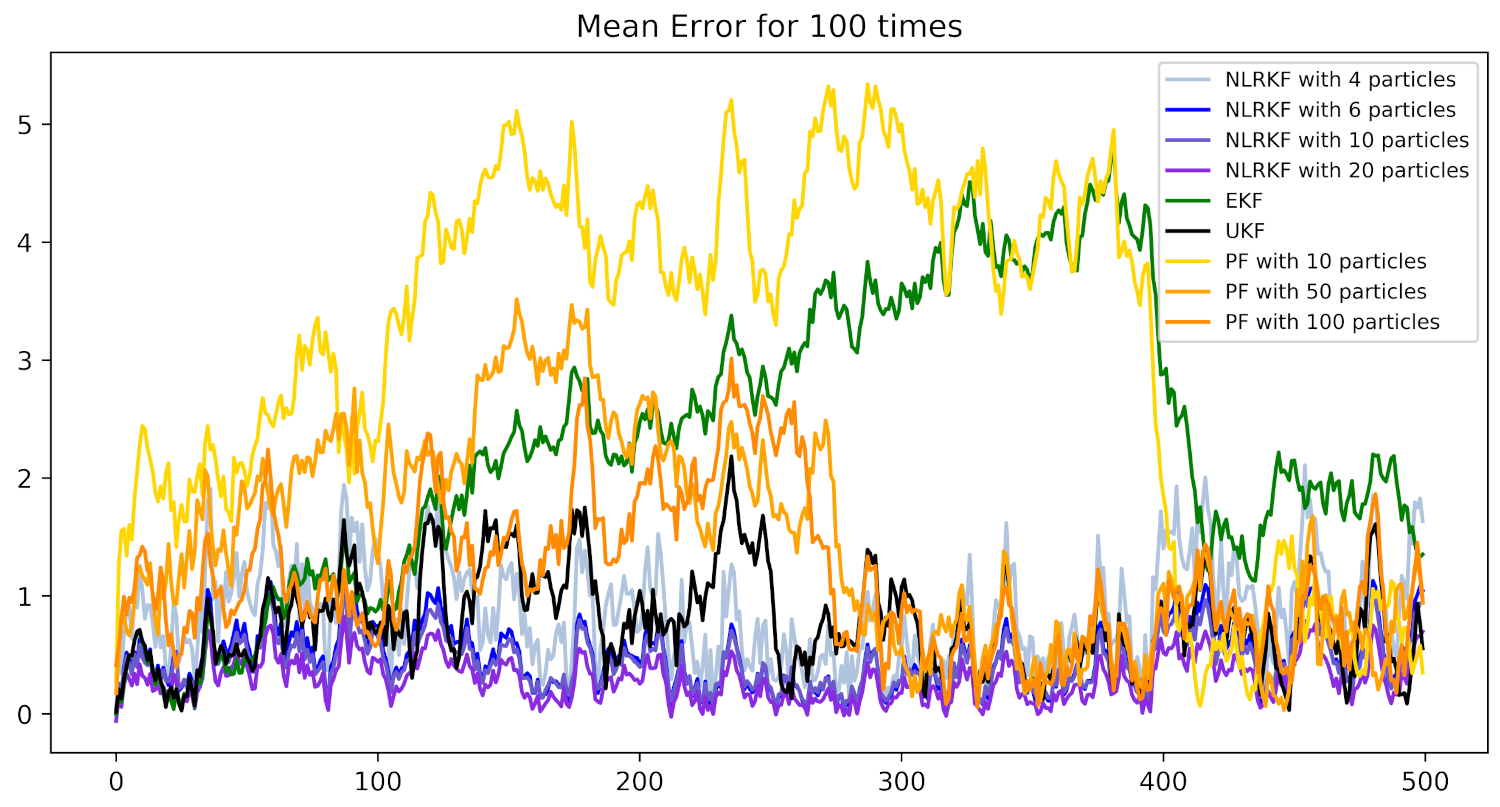
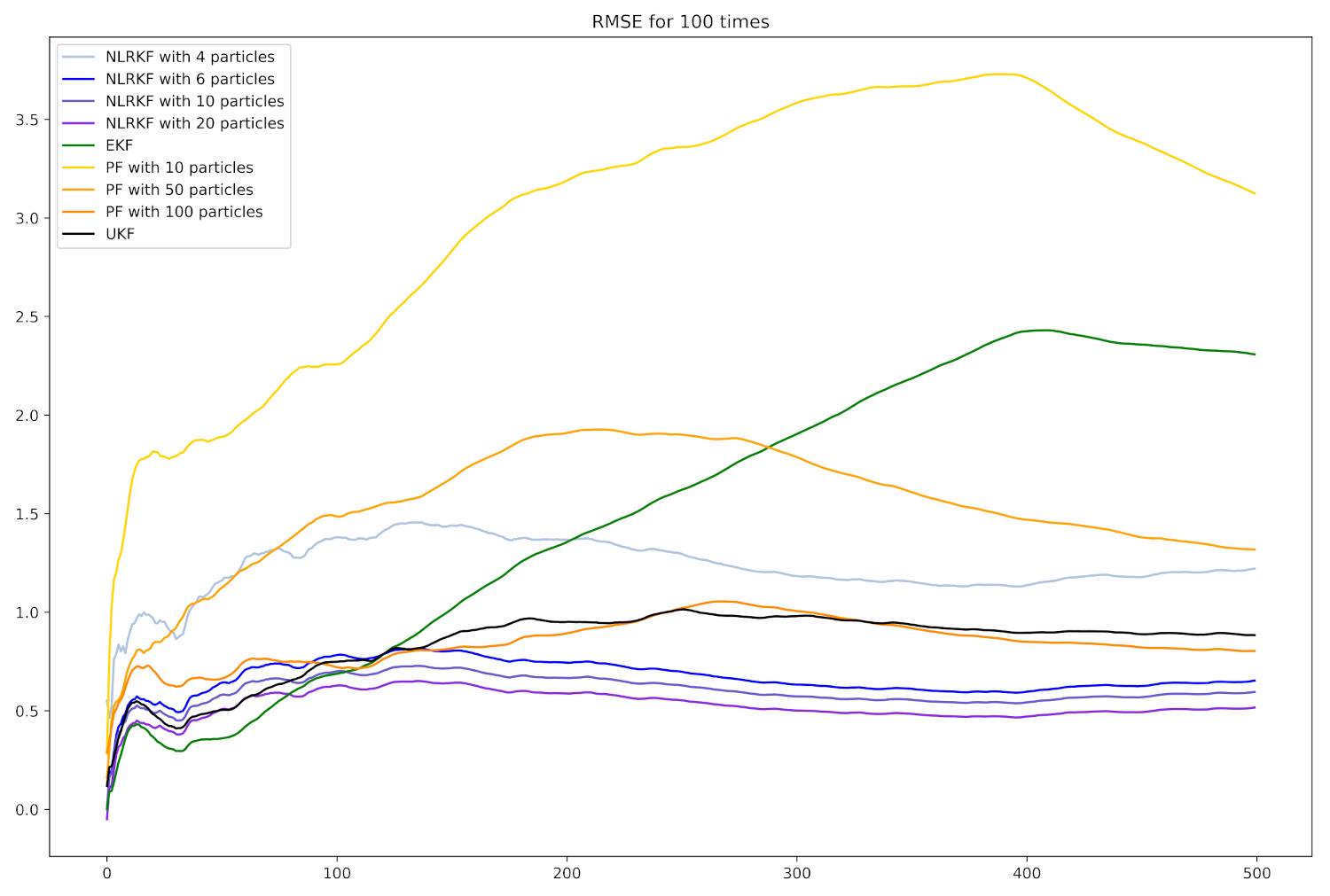
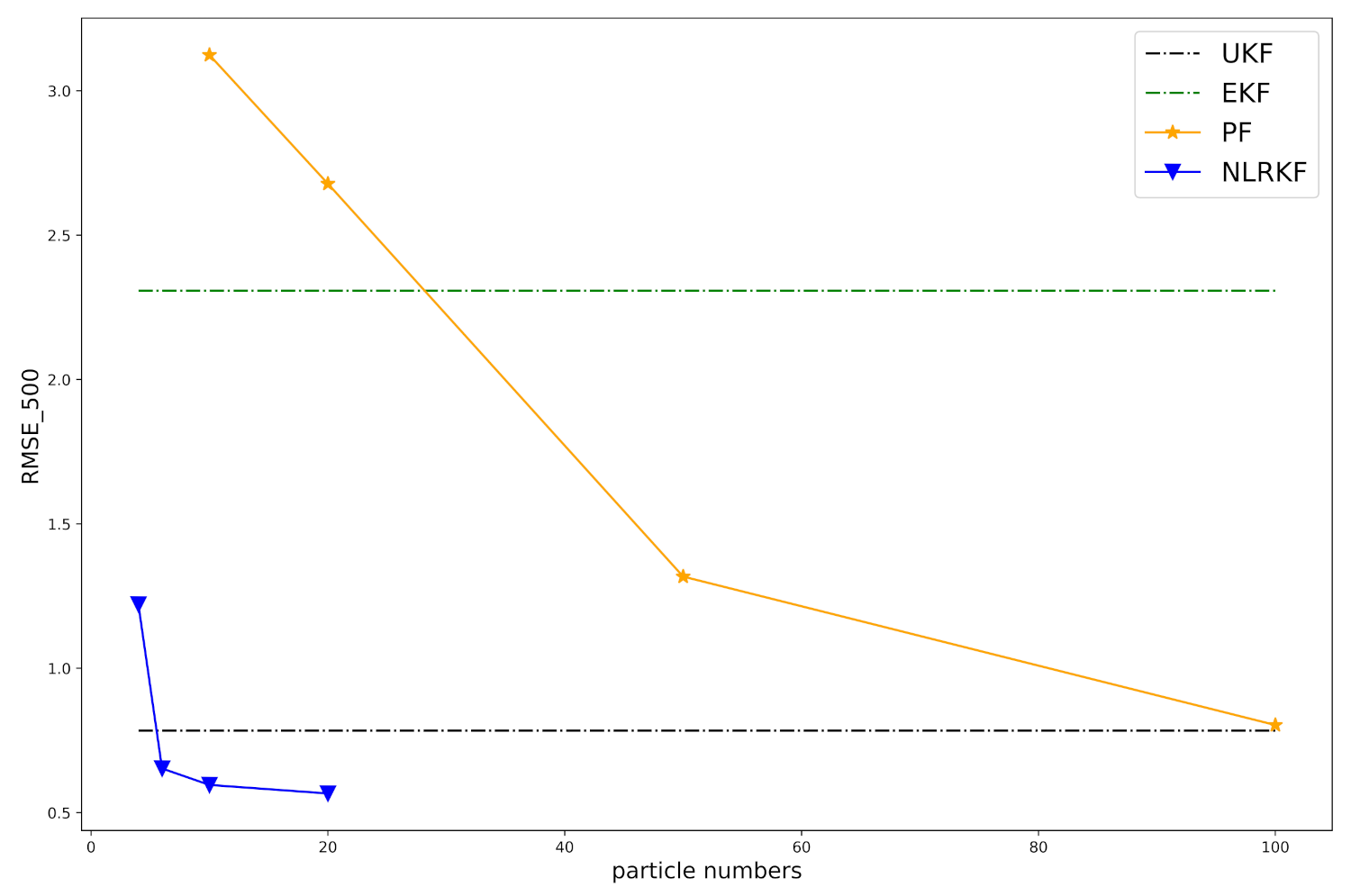
4. Experiments
4.1. Settings
4.2. Numerical Example
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Properties of Gaussian Random Variables
References
- Kalman, R.E. A new approach to linear filtering and prediction problem. ASME Trans. J. Basic Eng. Ser. D 1960, 82, 35–45. [Google Scholar] [CrossRef] [Green Version]
- Kalman, R.E.; Bucy, R.S. New results in linear filtering and prediction theory. ASME Trans. J. Basic Eng. Ser. D 1961, 83, 95–108. [Google Scholar] [CrossRef]
- Jazwinski, A.H. Stochastic Processes and Filtering Theory; Academic Press: New York, NY, USA; London, UK, 1970. [Google Scholar]
- Simon, D. Optimal State Estimation: Kalman, H Infinity, and Nonlinear Approaches; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Luo, X.; Chen, X.; Yau, S.S.T. Suboptimal linear estimation for continuous–discrete bilinear systems. Syst. Control Lett. 2018, 119, 92–100. [Google Scholar] [CrossRef]
- Gordon, N.J.; Salmond, D.J.; Smith, A.F.M. Novel Approach to Nonlinear/Non-Gaussian Bayesian State Estimation. Radar Signal Process. IEE Proc. F 1993, 140, 107–113. [Google Scholar] [CrossRef] [Green Version]
- Duncan, T.E. Probability Densities for Diffusion Processes with Applications to Nonlinear Filtering Theory and Detection Theory; Technical Report; Stanford University: Stanford, CA, USA, 1967. [Google Scholar]
- Mortensen, R.E. Optimal Control of Continuous Time Stochastic Systems. Ph.D. Thesis, University of California, Berkley, CA, USA, 1966. [Google Scholar]
- Zakai, M. On the optimal filtering of diffusion process. Z. Wahrsch. Verw. Geb. 1969, 11, 230–243. [Google Scholar] [CrossRef]
- Chen, X.; Shi, J.; Yau, S.S.T. Real-time solution of time-varying yau filtering problems via direct method and gaussian approximation. IEEE Trans. Autom. Control 2019, 64, 1648–1654. [Google Scholar] [CrossRef]
- Luo, X.; Yau, S.S.T. Hermite spectral method to 1-D forward Kolmogorov equation and its application to nonlinear filtering problems. IEEE Trans. Autom. Control 2013, 58, 2495–2507. [Google Scholar] [CrossRef]
- Shi, J.; Chen, X.; Yau, S.S.T. A Novel Real-Time Filtering Method to General Nonlinear Filtering Problem Without Memory. IEEE Access 2021, 9, 119343–119352. [Google Scholar] [CrossRef]
- Yau, S.T.; Yau, S.S.T. Real time solution of the nonlinear filtering problem without memory II. SIAM J. Control Optim. 2008, 47, 163–195. [Google Scholar] [CrossRef]
- Lefebvre, T.; Bruyninckx, H.; De Schutter, J. Kalman filters for non-linear systems: A comparison of performance. Int. J. Control 2004, 77, 639–653. [Google Scholar] [CrossRef]
- Steinbring, J.; Hanebeck, U.D. LRKF revisited: The smart sampling Kalman filter (S2KF). J. Adv. Inf. Fusion 2014, 9, 106–123. [Google Scholar]
- Julier, S.J.; Uhlmann, J.K. Unscented filtering and nonlinear estimation. Proc. IEEE 2004, 92, 401–422. [Google Scholar] [CrossRef] [Green Version]
- Majumdar, J.; Dhakal, P.; Rijal, N.S.; Aryal, A.M.; Mishra, N.K. Article: Implementation of Hybrid Model of Particle Filter and Kalman Filter based Real-Time Tracking for handling Occlusion on Beagleboard-xM. Int. J. Comput. Appl. 2014, 95, 31–37. [Google Scholar]
- Morelande, M.R.; Kreucher, C.M.; Kastella, K. A Bayesian Approach to Multiple Target Detection and Tracking. IEEE Trans. Signal Process. 2007, 55, 1589–1604. [Google Scholar] [CrossRef] [Green Version]
- Steinbring, J.; Pander, M.; Hanebeck, U.D. The smart sampling Kalman filter with symmetric samples. arXiv 2015, arXiv:1506.03254. [Google Scholar]
- Liu, Q.; Wang, D. Stein variational gradient descent: A general purpose bayesian inference algorithm. arXiv 2016, arXiv:1608.04471. [Google Scholar]
- Liu, Q. Stein variational gradient descent as gradient flow. arXiv 2017, arXiv:1704.07520. [Google Scholar]
- Härdle, W.K.; Simar, L. Applied Multivariate Statistical Analysis; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Hazewinkel, M.; Marcus, S.; Sussmann, H.J. Nonexistence of finite-dimensional filters for conditional statistics of the cubic sensor problem. Syst. Control Lett. 1983, 3, 331–340. [Google Scholar] [CrossRef] [Green Version]



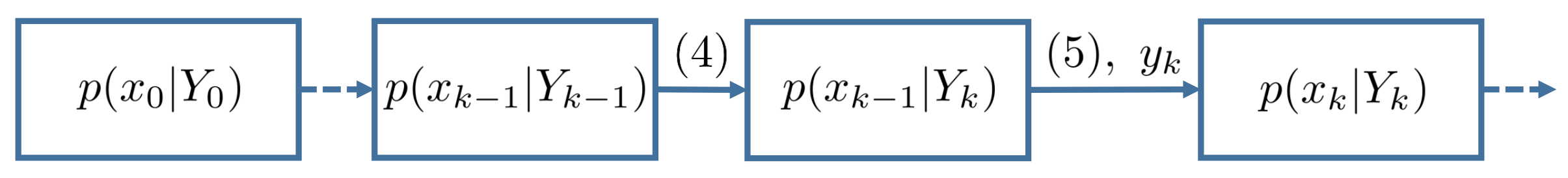{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Costing Time (s) | |
|---|---|---|
| EKF | 2.3076 | 0.0206 |
| UKF | 0.7840 | 0.1390 |
| NLRKF () | 1.2212 | 0.0406 |
| NLRKF () | 0.6529 | 0.0729 |
| NLRKF () | 0.5959 | 0.0879 |
| NLRKF () | 0.5663 | 0.1218 |
| PF () | 3.1242 | 0.1163 |
| PF () | 1.3175 | 0.1892 |
| PF () | 0.8034 | 0.2672 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Kang, J.; Teicher, M.; Yau, S.S.-T. A New Linear Regression Kalman Filter with Symmetric Samples. Symmetry 2021, 13, 2139. https://doi.org/10.3390/sym13112139
Chen X, Kang J, Teicher M, Yau SS-T. A New Linear Regression Kalman Filter with Symmetric Samples. Symmetry. 2021; 13(11):2139. https://doi.org/10.3390/sym13112139
Chicago/Turabian StyleChen, Xiuqiong, Jiayi Kang, Mina Teicher, and Stephen S.-T. Yau. 2021. "A New Linear Regression Kalman Filter with Symmetric Samples" Symmetry 13, no. 11: 2139. https://doi.org/10.3390/sym13112139
APA StyleChen, X., Kang, J., Teicher, M., & Yau, S. S.-T. (2021). A New Linear Regression Kalman Filter with Symmetric Samples. Symmetry, 13(11), 2139. https://doi.org/10.3390/sym13112139