1. Introduction
The recent rapid development of information and communication technology systems that offers limitless access to data has been changing internet behavior. As huge amounts of data are accessed by internet users in a relatively short time, the risk of malicious violations, such as unauthorized access to the network, increases. A network intrusion detection system (NIDS) is used to prevent unauthorized access. It is able to aid abnormal traffic diagnosis and predict the type of attack in the network. In addition, NIDS is robust to the rapid changes of attack classes. The robustness of NIDS largely affects the effectiveness of intrusion detection. NIDS works by analyzing and classifying the passing traffic data. Once the attack is identified, NIDS classifies the type of attack. Traditional approaches have been employed to identify and classify the type of attack using shallow machine learning methods, such as support vector machine, decision tree, and naïve Bayes [
1,
2,
3]. The effectiveness of the approaches has been evaluated using several benchmark datasets, such as KDD99 and Tokyo2016+, and they have obtained an intrusion detection accuracy of up to 97.41%. In addition, due to its increasing popularity in recent years, the neural network model has gained attention as an alternative to NIDS [
4,
5,
6,
7,
8]. Neural network models, such as convolution neural network (CNN), recurrent neural network, and deep neural network (DNN), have been evaluated and applied to benchmark datasets. The deep model can obtain an intrusion detection accuracy of up to 99%, which is higher than that of shallow machine learning.
Despite the high accuracy obtained by shallow machine learning and deep neural network, NIDS models suffer high false-positive alarm rates and lower intrusion detection rates due to imbalanced datasets [
9]. The data imbalance problem in datasets refers to the condition in which the distribution of classes is underrepresented. This condition occurs when one majority class is significantly outnumbered compared to the minority class, and the ratios can reach 1:100, 1:1000, or higher [
10,
11]. For instance, we have previously evaluated three benchmark NIDS real-world datasets: NSL-KDD [
12], UNSW-NB15 [
13], and Bot-IoT [
14].
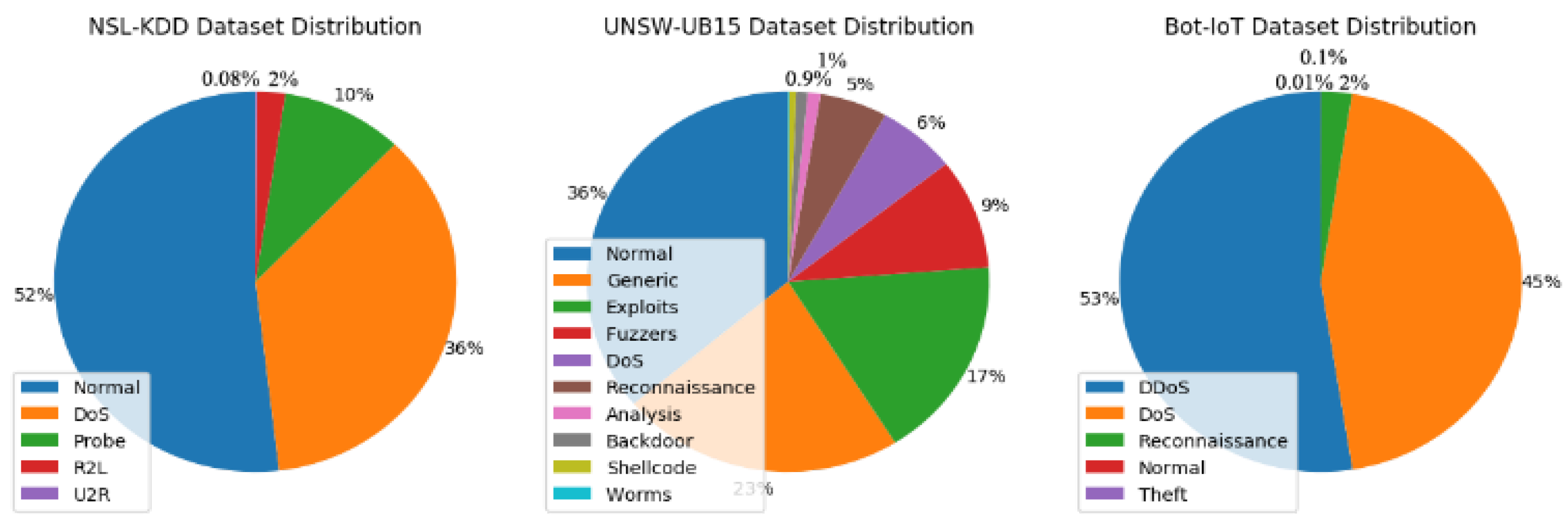
Figure 1 visualizes the distribution of each dataset. As can be seen, all suffer from high-class imbalance. The imbalance ratio reaches 1:534 between the majority and minority classes in the UNSW-NB15 dataset, while the highest imbalance ratio suffered by Bot-IoT is 1:26,750.
Table 1 shows a complete description of the three benchmark datasets. This significant ratio of classes may mislead and bias the NIDS model during intrusion detection. Therefore, the minority class is not adequately learned, even in binary-class problems or multiclass classification [
15,
16,
17].
Typically, there are two commons techniques when dealing with the imbalanced data problem: the data level technique and the algorithm level technique [
18]. The data level technique focuses on manipulating an imbalanced dataset to balance the distribution of the classes. The dataset is modified by adding repetitive data (oversampling) for the minority class and removing data (undersampling) for the majority class [
19,
20]. The most popular algorithm that uses the data level technique to cope with imbalanced data is the synthetic minority oversampling technique (SMOTE) [
21]. SMOTE works by generating synthetic data via oversampling of the minority class in its feature space interpolation. The minority class is oversampled in the region of the line segment between the samples by utilizing
k-nearest neighbors. The number of generated samples depends highly on the imbalanced dataset, and the samples are used to balance the dataset. On the other hand, an algorithm level technique modifies cost matrices using cost-sensitive learning to misclassify the data sample [
10,
22]. Cost-sensitive learning mainly focuses on the misclassified minority by directly modifying the reweighting value in the learning procedures. The learning costs are represented as a cost matrix to evaluate the ability of a trained network so that misclassification is reduced [
23]. Moreover, in cost-sensitive learning, more attention is given to the existing algorithm by weighting the minority class [
24]. In the evaluation of imbalanced datasets, the neural network tends to misclassify the majority samples with high average classification accuracy [
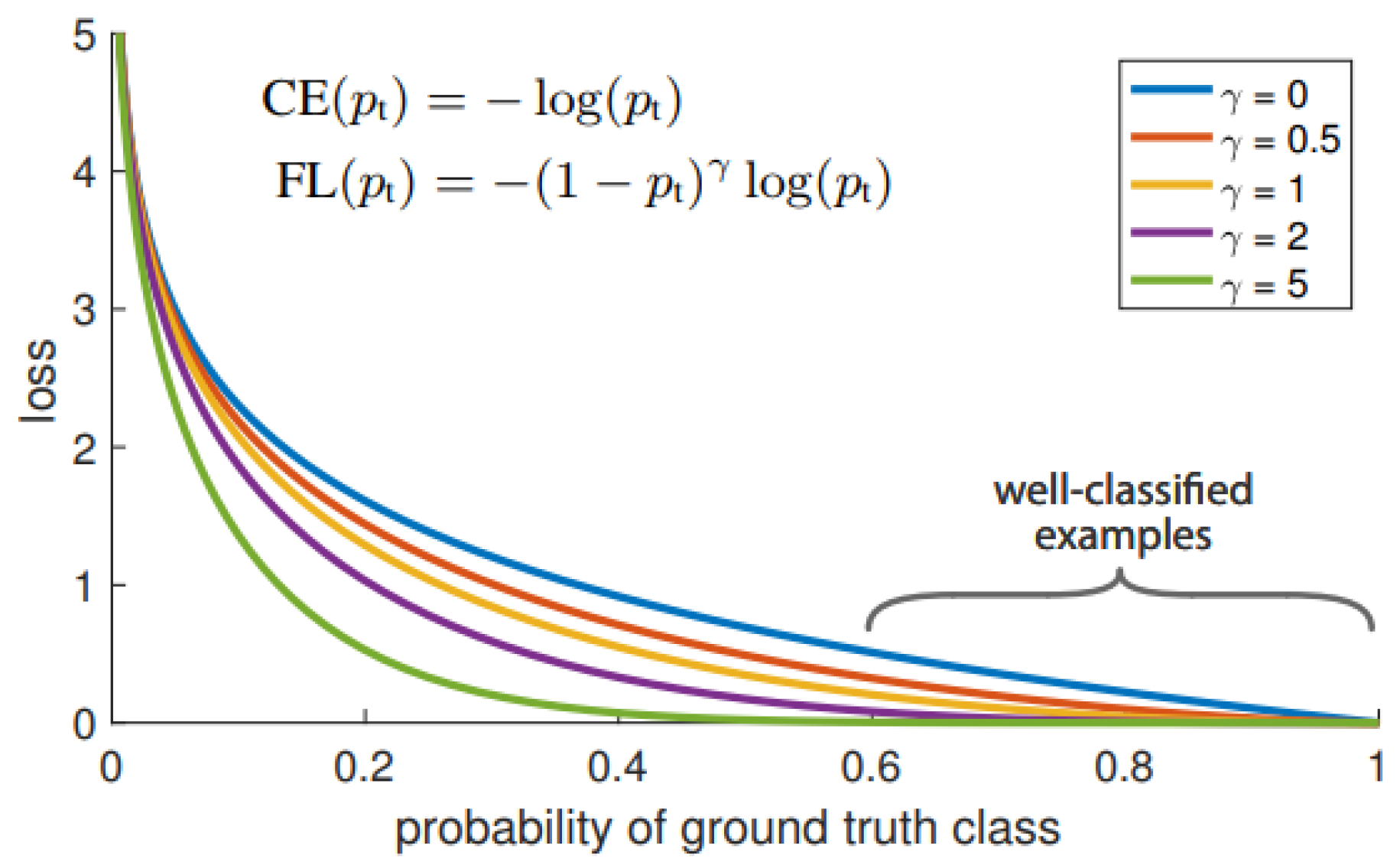
25]. To overcome this issue, cost-sensitive learning based on cross-entropy (CE) is preferable for training the neural network. Recently, a method that enhances cross-entropy, termed focal loss, has been emerging as an alternative candidate to improve performance [
26,
27,
28,
29,
30]. Specifically, the authors of [
30] performed a methodology to improve the performance of the deep learning technique using a focal loss neural network. The idea was proven feasible in machine vision and performed better than conventional cross-entropy. In summary, learning using an imbalanced dataset requires different handling techniques. Empirical study shows that some conventional handling techniques that are feasible for applying to a balanced dataset might obtain high misclassification costs when imbalanced datasets are used. As we know, in the real environment, data handled by machine learning is always in an imperfect form, i.e., they are examples of imbalanced data. Therefore, it is necessary to investigate a scheme to address this phenomenon.
The realm of intrusion detection has been studied extensively by many researchers. Vinayakumar et al. [
4,
6] proposed DNN using cross-entropy (DNN CE) and CNN using cross-entropy (CNN CE) to address the imbalance problem. Our preliminary results using the algorithms showed that both DNN CE and CNN CE could be successfully implemented in the datasets. However, even though both algorithms achieved good accuracy, they continued to suffer from the imbalance problem, as shown by the F1 score. In our preliminary results, we also utilized SMOTE to cope with the imbalance problem [
21]. SMOTE is used for balancing the majority and minority classes and intended to address the class imbalance. By combining DNN and CNN, SMOTE (DNN SMOTE and CNN SMOTE, respectively) was successfully implemented and achieved good accuracy. However, the F1 score was lacking. This means that addition of the data preprocessing step resulted in imbalance. In the end, we used an improved classification model for the intrusion detection system, termed the focal loss network intrusion detection system (FL-NIDS), to address the class imbalance in NIDS. Deep neural network and convolutional neural network layers were utilized to compare the performance of the system with previous research results. The effectiveness of FL-NIDS was analyzed using three benchmark datasets: NSL-KDD, UNSW-NB15, and Bot-IoT. In conclusion, the paper’s contributions are as follows: (i) proposing a loss function modification based on focal loss to solve the imbalanced data problem; (ii) comparing the performance of the proposed method with common methods using imbalanced datasets; and (iii) empirically testing the system with real-world datasets to validate the proposed model. The rest of the paper is organized as follows.
Section 2 presents detailed research related to the development of the proposed method.
Section 3 defines the methodology and the proposed model.
Section 4 explores some observations on the proposed model and discusses the accuracy of the proposed method compared to existing neural network models, such as vanilla deep neural network, vanilla convolutional neural network, and SMOTE, on three different datasets.
Section 5 concludes the paper.
2. Related Work
Shallow machine learning algorithms, which include support vector machine, decision tree, and naïve Bayes, have been evaluated in NIDS and proven to be feasible solutions to the intrusion detection problem [
1,
2,
3]. Due to the emergence of deep neural network algorithms in recent years, attention has automatically shifted to new algorithms that offer limitless exploration abilities but are complex. Vinayakumar et al. [
6] evaluated the effectiveness of shallow machine learning algorithms and deep neural networks. The authors concluded that deep neural network performed well in most experimental scenarios because the information in the network was learned by the distinguished pattern of several layers. Another discussion that compared shallow machine learning and deep neural networks was presented by Hodo et al. [
9]. The authors showed that deep neural network outperformed shallow machine learning in attack detection. Various CNN and long short-term memory (LTSM) deep neural network architectures were evaluated by Roopak et al. [
31]. The authors concluded that the deep neural network combination of CNN + LTSM performed well and obtained the highest accuracy of 97.16%. These previous studies have shown that, in general, deep neural network performs better than shallow machine learning. However, the imbalanced data case that is encountered in real-world datasets is neglected.
The imbalanced data case refers to the problem where the distribution of the dataset is significantly underrepresented. Some attempts to improve imbalanced datasets have been made. Sun et al. reviewed some methods that were able to overcome an imbalanced dataset [
11]. The methods included data level and algorithm level solutions. Furthermore, evaluation of the matrix was used to measure the effect on imbalanced datasets. Heibo compared some approaches to solve the imbalanced data problem and recommended several approaches from both the data level and algorithm level [
10]. Chawla et al. conducted an experiment using an oversampling approach for an imbalanced dataset [
21]. They utilized SMOTE, and the results showed that the method improved accuracy. However, despite SMOTE obtaining higher accuracy, the algorithm required huge computation time. Works applying algorithms to imbalanced datasets have also been conducted. The typical approach is to utilize cost-sensitive learning. Elkan presented a concept to optimize a neural network [
32]. The concept utilized the neural network to prevent and minimize the mistakes of different misclassification errors caused by different losses. The paper proposed and formulated cost-sensitive learning to optimize the proportion of negative and positive training. Wang et al. examined the ability of a neural network to overcome an imbalanced dataset [
33]. Despite obtaining high accuracy, the deep neural network did not achieve high precision. The research proved that an improvement of the cost learning rate in a neural network contributed to higher precision. Another research conducted by Cui et al. assessed the combination of cost-sensitive learning cross-entropy with focal loss [
26].
Focal loss is able to counter extreme foreground–background class imbalances [
27]. This study reshaped the typical cross-entropy loss so that the loss assigned to the classified sample was reduced. Focal loss is interested in a sparse set of hard samples during training and prevents the majority class from inundating the detector. In the area of machine vision, focal loss is utilized to detect characters in random images [
28]. This research was conducted on text recognition from images. The evaluation of the benchmark dataset showed that the focal loss detector performed better, with the accuracy increasing by 2.5% compared to the focal lossless algorithm. Nemoto et al. observed rare building changes by employing a CNN based on focal loss. Building changes is categorized as a rare positive case as building construction in rural areas is limited. The experiment showed that the application of focal loss was effective for detecting rare problems, and the model avoided overfitting.
4. Experiment and Performance Evaluation
4.1. Description of Network Intrusion Detection System Datasets
The benchmark datasets for NIDS are currently limited. Most of them are internal network simulations based on traffic and attack data simulations. This research utilized three benchmark datasets for NIDS: NSL-KDD, UNSW-NB15, and Bot-IoT. They were consistently utilized to evaluate the effectiveness of machine learning algorithms.
NSL-KDD: This dataset is the updated version of KDDCup99 that removes the redundant data and invalid records. This clean version prevents the machine learning algorithm from being biased during the training data phase. The dataset typically includes the connection information with 41 features and its associated labels, and there are five categories of labels: normal, DoS (denial of service), R2L (unauthorized access from a remote machine), U2R (unauthorized access to local root privileges), and probing (surveillance and other probing).
UNSW-NB15: This dataset is formed from a network simulation. The simulation is established by creating a network that consists of a server and router. The server generates simulated traffic data, including normal data traffic and malicious data. The router captures the simulated traffic data. The dataset consists of 10 classes and 42 features.
Bot-IoT: This new NIDS dataset covers all 11 typical updated attacks, such as DoS, distributed denial of service (DDoS), reconnaissance, and theft. Bot-IoT2019 contains a large number of traffic packets and attack types that has occurred over five consecutive days. The whole dataset encompasses 3,119,345 instances and 15 features containing five class labels (one normal and four attack labels).
4.2. Environment
The experiment was run on Ubuntu 18.04 LTS. Deep neural network was implemented using GPU TensorFlow and Keras as a higher-level framework. A Nvidia GeForce RTX2080 11 GB was installed on a computer containing an Intel® Xeon® CPU E5-2630 v4 @2.20 GHz CPU and 128 GB of DDR4 RAM.
4.3. Discussion
Imbalanced dataset has a huge influence on the ability of neural networks during training. The influence, which is affected by the majority class, is reflected by the late convergence of the loss function during the training process as the model sums the losses of all the large classes and rarely focuses on the minority class. By adding focal loss to cross-entropy loss, it reduces the large class contribution and extends the range to access the minority class. In this experiment, we compared and examined the cross-entropy of DNN using cross-entropy (DNN CE) from reference [
6], CNN using cross-entropy (CNN CE) from reference [
4], DNN using SMOTE (DNN SMOTE) from reference [
21], and CNN using SMOTE (CNN SMOTE) from reference [
21]; for DNN and CNN, focal loss with ɣ = 2.0 and α = 0.25 was used following reference [
27].
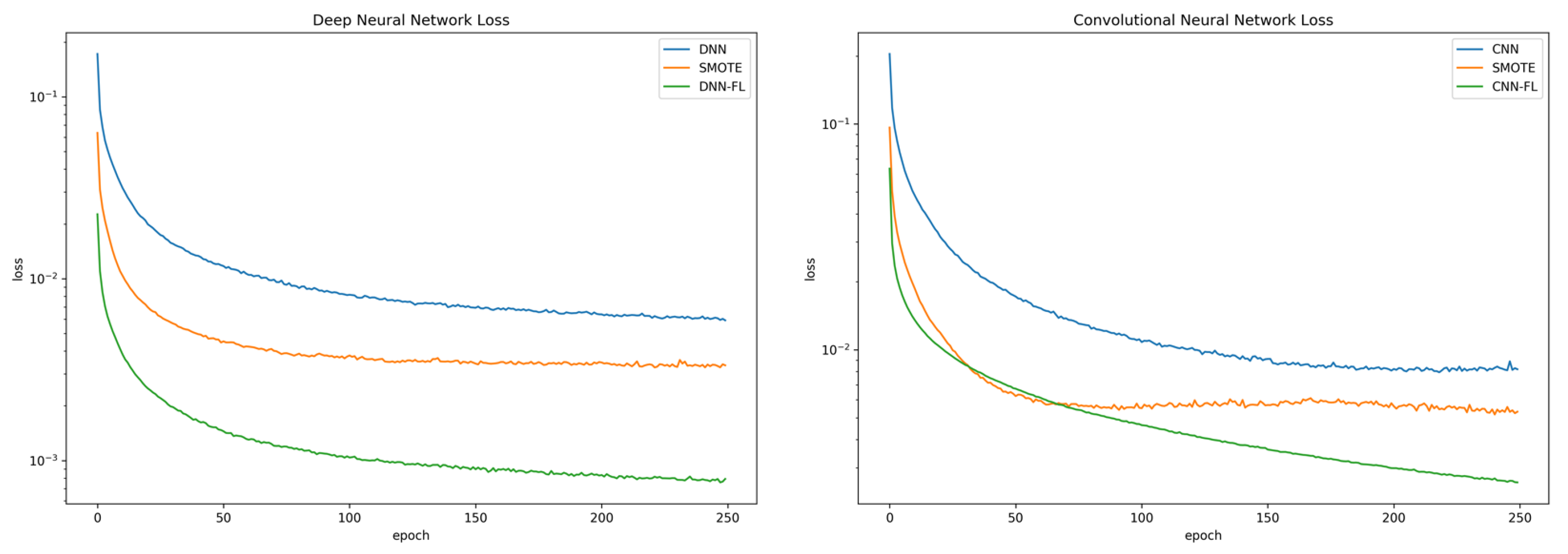
Figure 4a,b shows the loss function compared to DNN and the loss function compared to CNN using the respective techniques. Both models that utilized focal loss converged faster compared to DNN CE, CNN CE, DNN SMOTE, and CNN SMOTE. In addition, the proposed model obtained minimum loss errors that were 7 times better for the DNN architecture and 3.7 times better for the CNN architecture than CNN SMOTE. It also had better generalizability, as shown by the validation losses. The detailed loss error and loss validation are shown in
Table 5.
In terms of accuracy, the performance of FL-NIDS applying the DNN and CNN architecture was comparable to DNN CE, DNN SMOTE, CNN CE, and CNN SMOTE. Detailed accuracy results for the binary and multiclass classification using FL-NIDS are given in
Table 6 and
Table 7, respectively. The results showed that the accuracy was equally distributed, implying that the techniques are comparable to each other. The accuracy distribution of the NSL-KDD and UNSW-NB15 datasets were located approximately 77–89% in the binary classification and located slightly lower at approximately 66–78% in the multiclass classification. The opposite occurred in the Bot-IoT dataset. The accuracy distribution was located approximately 75–89% in the binary classification and located slightly higher at approximately 98–99% for the multiclass classification. In more detail, in the binary classification and multiclass classification using the DNN architecture, FL-NIDS outperformed DNN CE by a maximum of 5% in three layers using the Bot-IoT dataset. However, in some cases, FL-NIDS also surpassed the accuracy of DNN CE and DNN SMOTE. In the CNN-based architecture, FL-NIDS obtained even better accuracy by outperforming CNN CE and CNN SMOTE by a maximum of 2%. However, in some cases, FL-NISD also surpassed the accuracy of both of them. This result indicates that FL-NIDS has effective binary and multiclass classification performance and is able to classify potential future threats.
We have shown that accuracy for FL-NIDS is equal to the CE model and SMOTE model. However, accuracy alone cannot represent detection of the minority class. According to Equation (1), the accuracy only compares the positive detection of every class with respect to the total dataset. Therefore, when there is a change in the detection of the minority class, the detection does not affect the whole accuracy and tends to be ignored. We used precision, recall, and F1 score to assess the detection for imbalanced datasets. As shown in Equation (2), precision quantifies the exactness of the correctly labeled class. Precision focuses on the ratio of positive detections to the detection of each class, and it will be affected when there is a change in the minority class. Recall measures the sensitivity or correctly labeled positive classes. Recall is affected by the sensitivity of the model to negative detection errors. The F1 score is the average of precision and recall and measures the balance of precision and recall.
Detailed results of the DNN and CNN experiments using precision, recall, and F1 score are shown in
Table 8 and
Table 9, respectively. In the shallow layer (layer 1), the precision of FL-NIDS was poor compared to the other algorithms. However, as the number of layers increased, the precision of FL-NIDS was superior to the other models. It is obvious that FL-NIDS works best at a deep layer [
27]. In the deep model (layer 3), FL-NIDS outperformed the other models by 3% with the DNN architecture and 12% with the CNN architecture.
In the multiclass experiment, FL-NIDS outperformed the other models. Detailed results of multiclass classification using the DNN and CNN architectures are shown in
Table 10 and
Table 11, respectively. The precision was superior for the deep model (layer 3) compared to the other models. This finding was expected as FL-NIDS was developed to handle multiclass and imbalanced data. However, there was an anomaly during the detection of NSL-KDD using the DNN model, which might have been caused by the selection of the focal loss parameter because the performance of focal loss is heavily dependent on the dataset. In spite of the anomaly, FL-NIDS is suitable and superior to other algorithms.
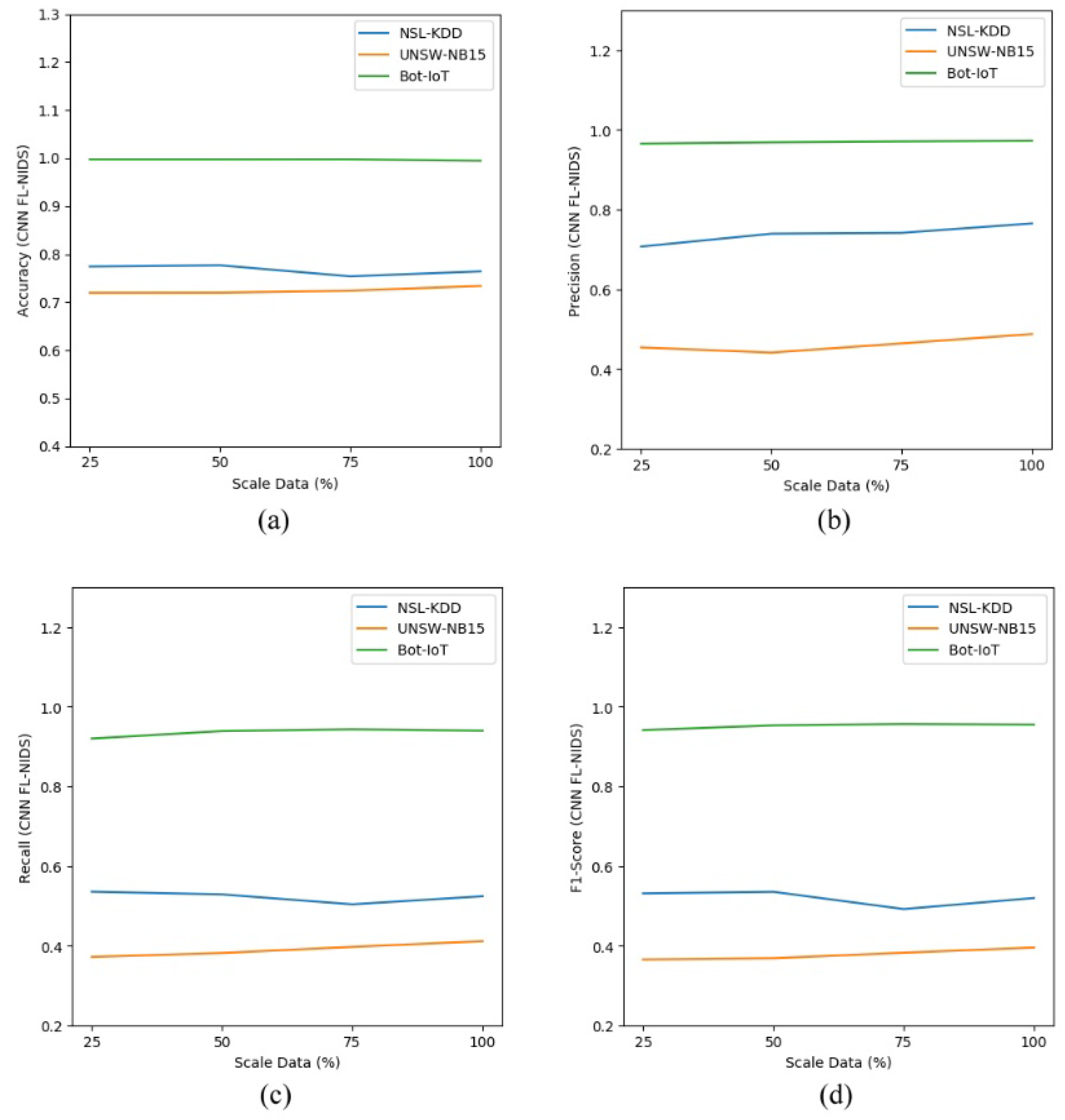
To get an insight on the scalability of the proposed approach, we measured the effectiveness of FL-NIDS by simulating a condition where few data are available. To mimic those circumstances, we trained the model using 25, 50, and 75% of the training dataset. Furthermore, the models were evaluated on the whole available testing data.
As depicted in
Table 12 and
Table 13, the scalability assessment of the proposed approach was conducted by comparing the performance of the DNN and CNN models using different data sizes. The performance comparison consisted of accuracy, precision, recall, and F1 score in multiclass classification. The results, shown in
Table 12 and
Table 13, indicate that our proposed approach is stable enough as the outcome achieved was almost the same, even for the model trained with few data.
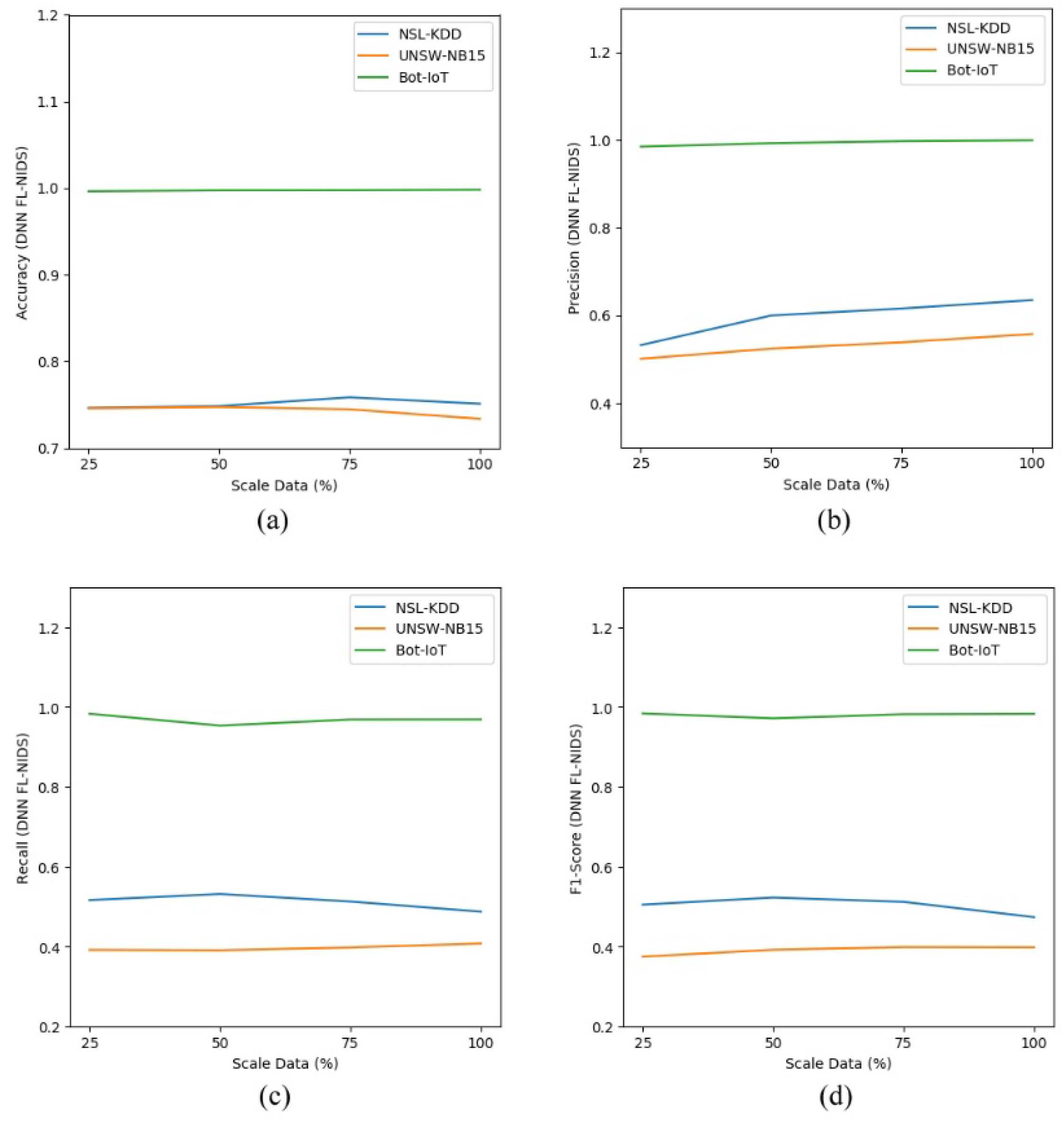
Figure 5a–d and
Figure 6a–d show the performance comparison for FL-NIDS in the DNN and CNN models, respectively. From the presented results, it can be seen that the performance of the proposed scheme is scalable enough as the accuracy of FL-NIDS could be maintained at 74% for DNN and 77% for CNN, even with the availability of only 25% of the data size for training.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}