Learning Multimodal Representations by Symmetrically Transferring Local Structures


Abstract
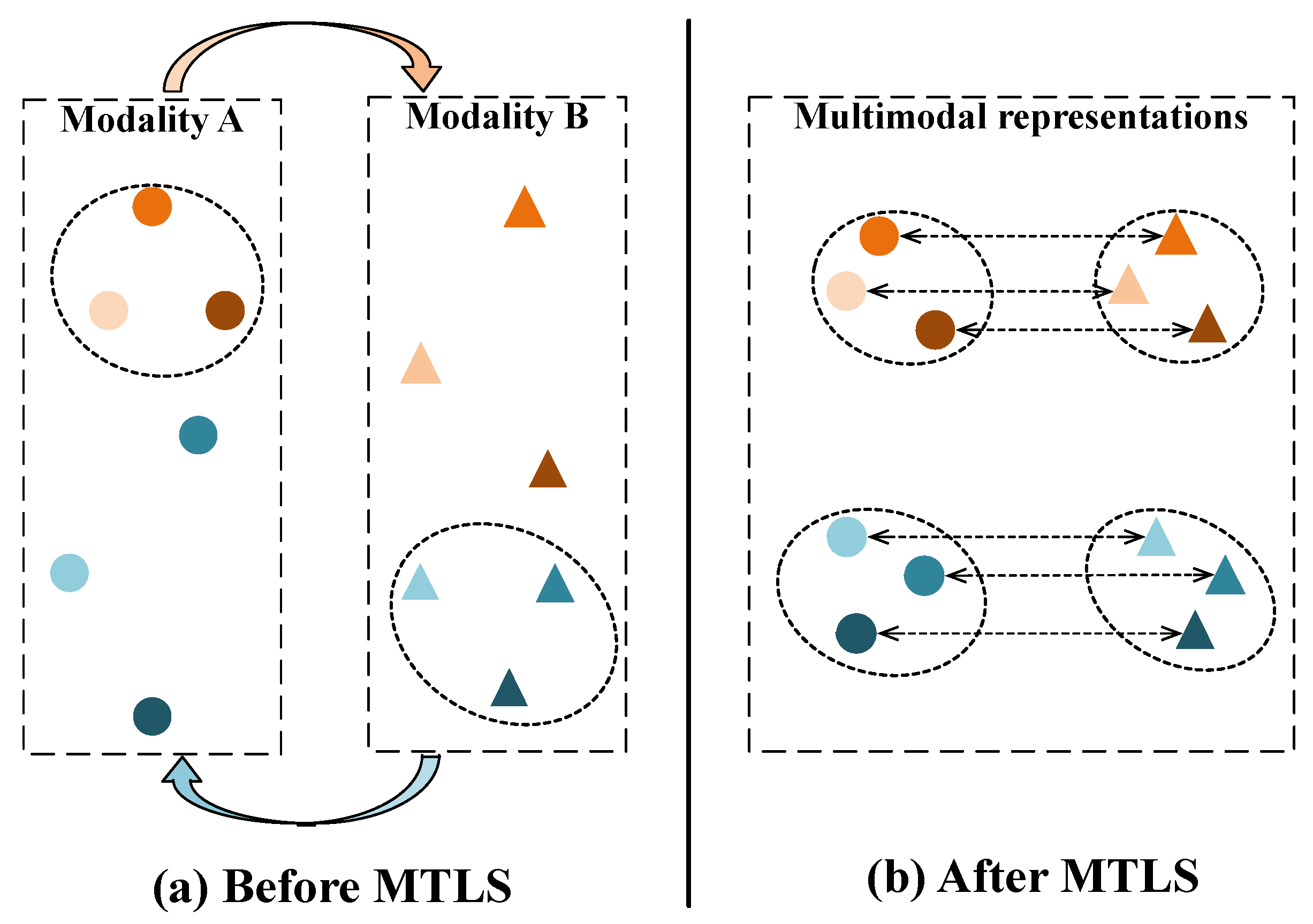
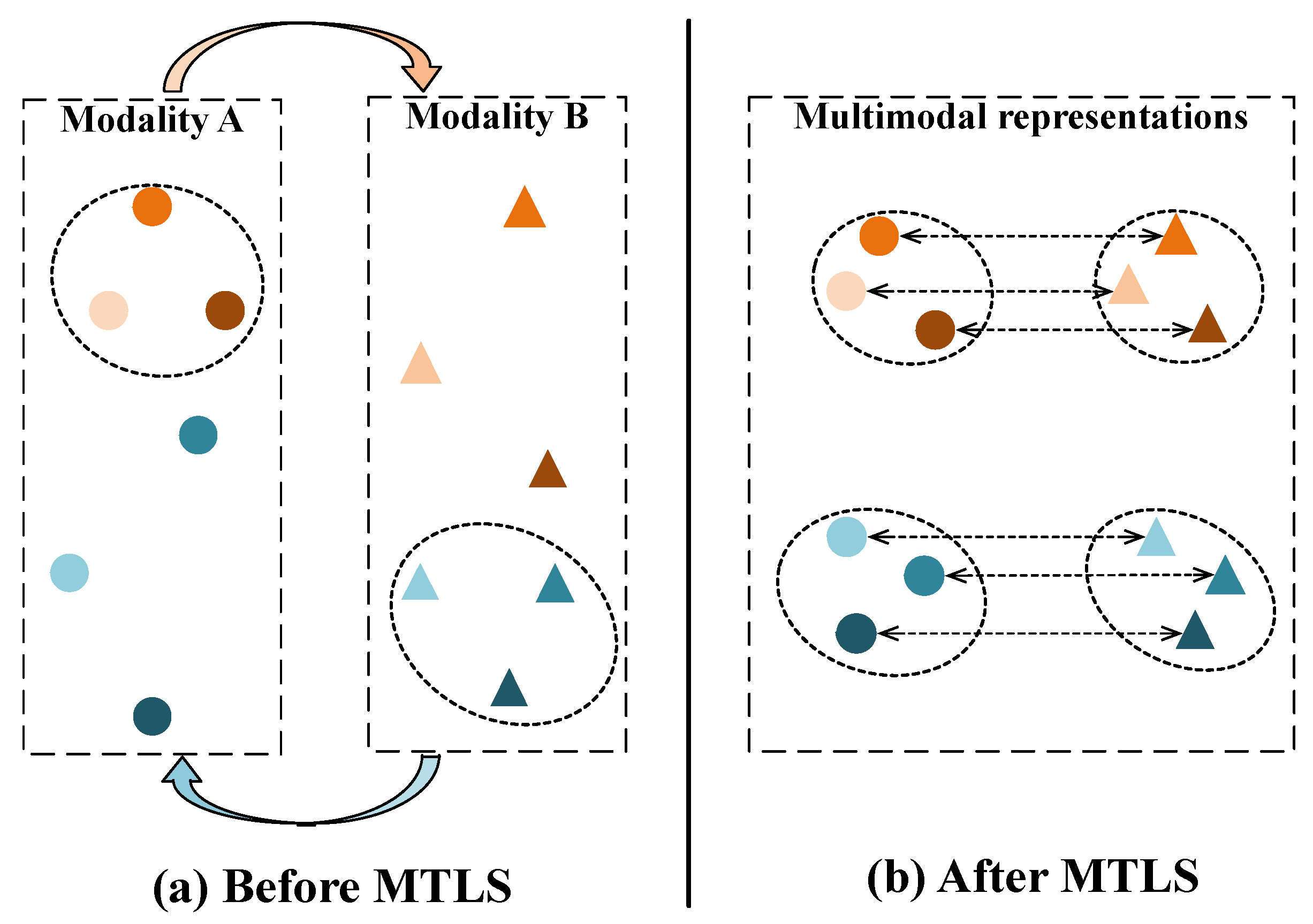
:1. Introduction
- A novel symmetric multimodal representation learning framework MTLS is proposed to learn complementary information from the other modality and has the potential to be instantiated into various modalities.
- MTLS builds a soft metric learning strategy to transfer local structures across modalities and enhances the intra-modal cluster structure through infinite-margin loss.
- MTLS is constrained by bidirectional retrieval loss to achieve modality aligning and trained by a customized iterative parameter updating process.
2. Related Work
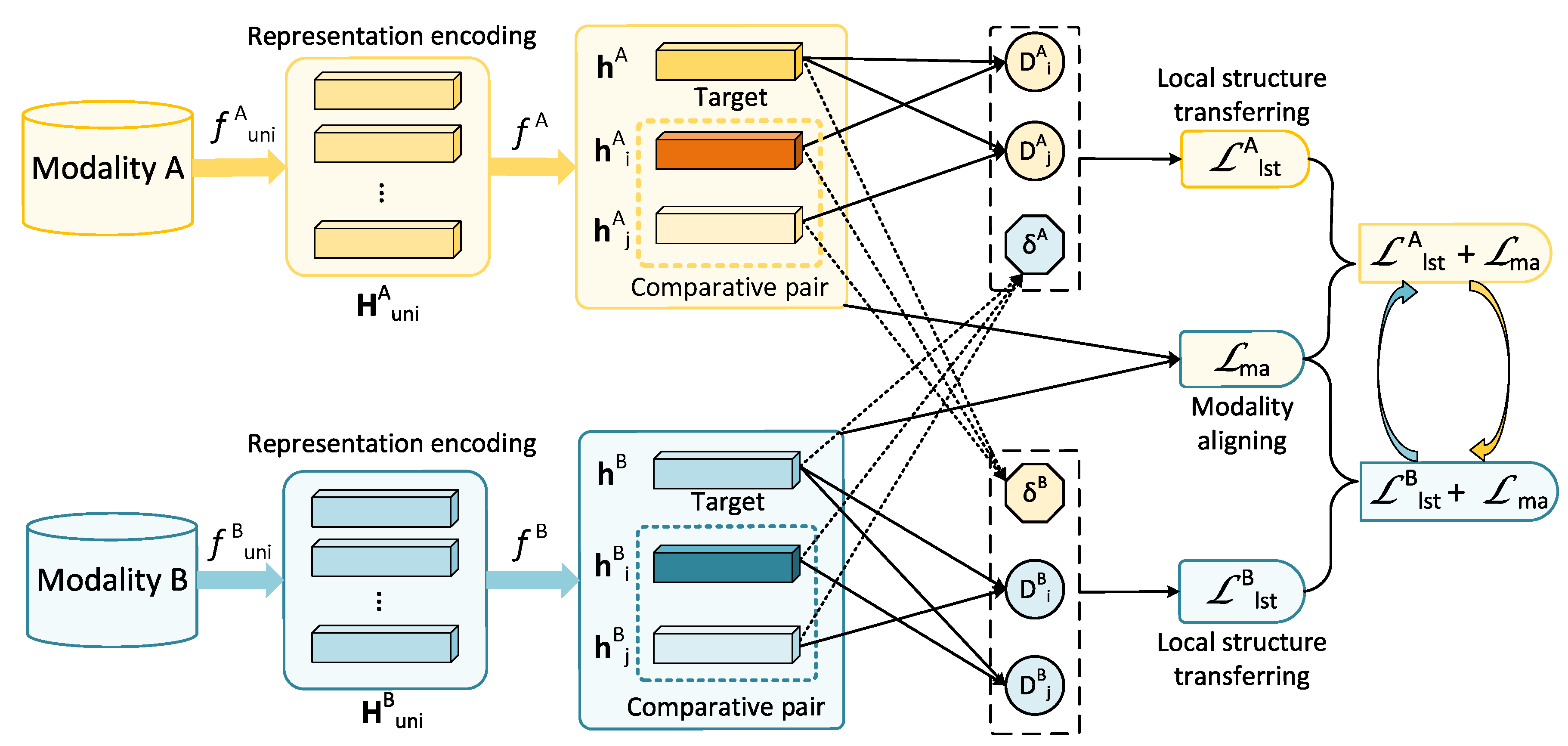
3. Multimodal Representations with Local Structure Transferring
3.1. Representation Encoding
3.2. Local Structure Transferring
3.3. Modality Aligning
3.4. Learning Algorithm
| Algorithm 1 The learning process of MTLS |
|
4. Experiments
4.1. Implementation Details
4.2. Experimental Setup
- Mean Vector (MV) [27]: it adopts the mean vector of word2vec embeddings as the caption embeddings.
- CCA (CCA) [27]: it adopts the fisher vectors with the fusion of Gaussian Mixture Model (GMM) and HGLMM.
- VSE [12]: it uses inner product and ranking loss to align image and text.
- VSE++ [44]: it updates VSE with hard negative sampling.
- Order-embeddings (Order) [24]: it optimizes the partial order of image-text pair.
- Embedding network in two-branch neural networks (TBNN) [13]: it emphasis intra-modal structure in the aligning process.
- Stacked cross attention networks (SCAN) [29]: it learns attention weights of image regions or text words for inferring image-text similarity.
- Bidirectional Focal Attention Network (BFAN) [30]: it reassigns attention to relevant image regions instead of all the regions based on inter-modality relation and intra-modality relation.
- Multimodal Tensor Fusion Network (MTFN) [19]: it explicitly learns the image-text similarity function with rank-based tensor fusion.
4.3. Cross-Modal Retrieval
- All the similarity-based neural network models, i.e., VSE, VSE++, Order, TBNN, SCAN, MTFN, BFAN, and our proposed MTLS perform better than the baseline models on both datasets, i.e., MV, CCA, and CCA, which indicates the representation ability of neural networks and the advantages of ranking loss.
- On Flickr30k dataset, our proposed MTLS achieves competitive results with state-of-the-art BFAN, which is more complex than our method since it considers the image regions and corresponding text words. Moreover, the BFAN is specially designed for image-text matching while our MTLS learns general multimodal representations for several tasks.
- On MSCOCO dataset, our method MTLS significantly outperforms other state-of-the-art methods. Especially for text-to-image retrieval task, MTLS achieves 81.7%, 52.7%, 100%, 83.0%, 35%, 32%, 33% improvements over the comparison methods VSE, VSE++, Order, TBNN, SCAN, MTFN and BFAN respectively in terms of R@1. This is because text-to-image retrieval is more challenging than image-to-text retrieval since one image is corresponding to five captions and MTLS captures complementary information in both text and image representations.
- According to the examples in Figure 3 and Figure 4, among the top five captions retrieved by our method MTLS four captions are the ground-truth ones and MTLS can find the most matching images from a bunch of ambiguous images according to the query text. Because in MTLS the local structures are not only enhanced within modality but also transferred between modalities, it is easier to retrieve the most relevant images or captions.
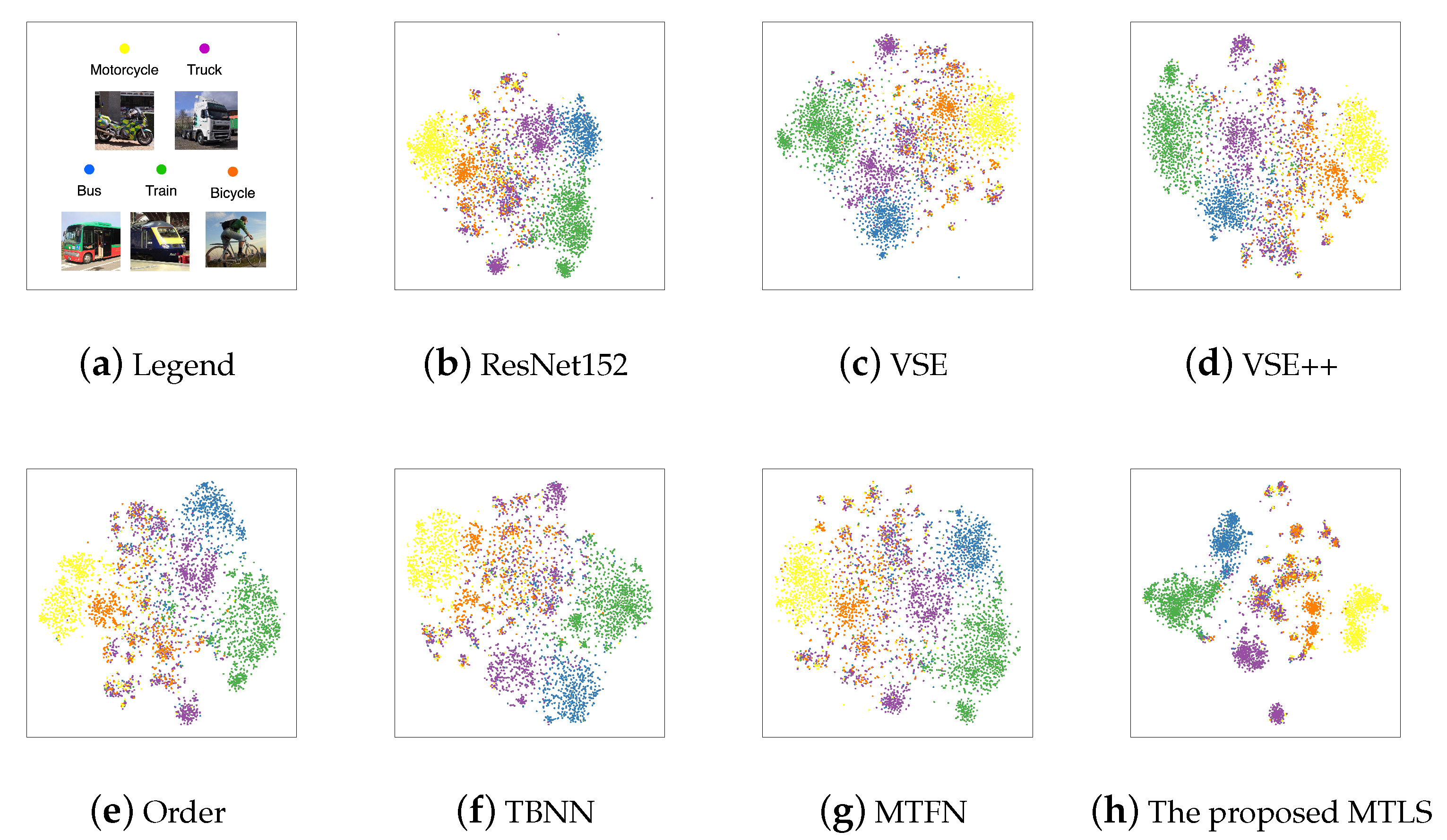
4.4. Image Clustering
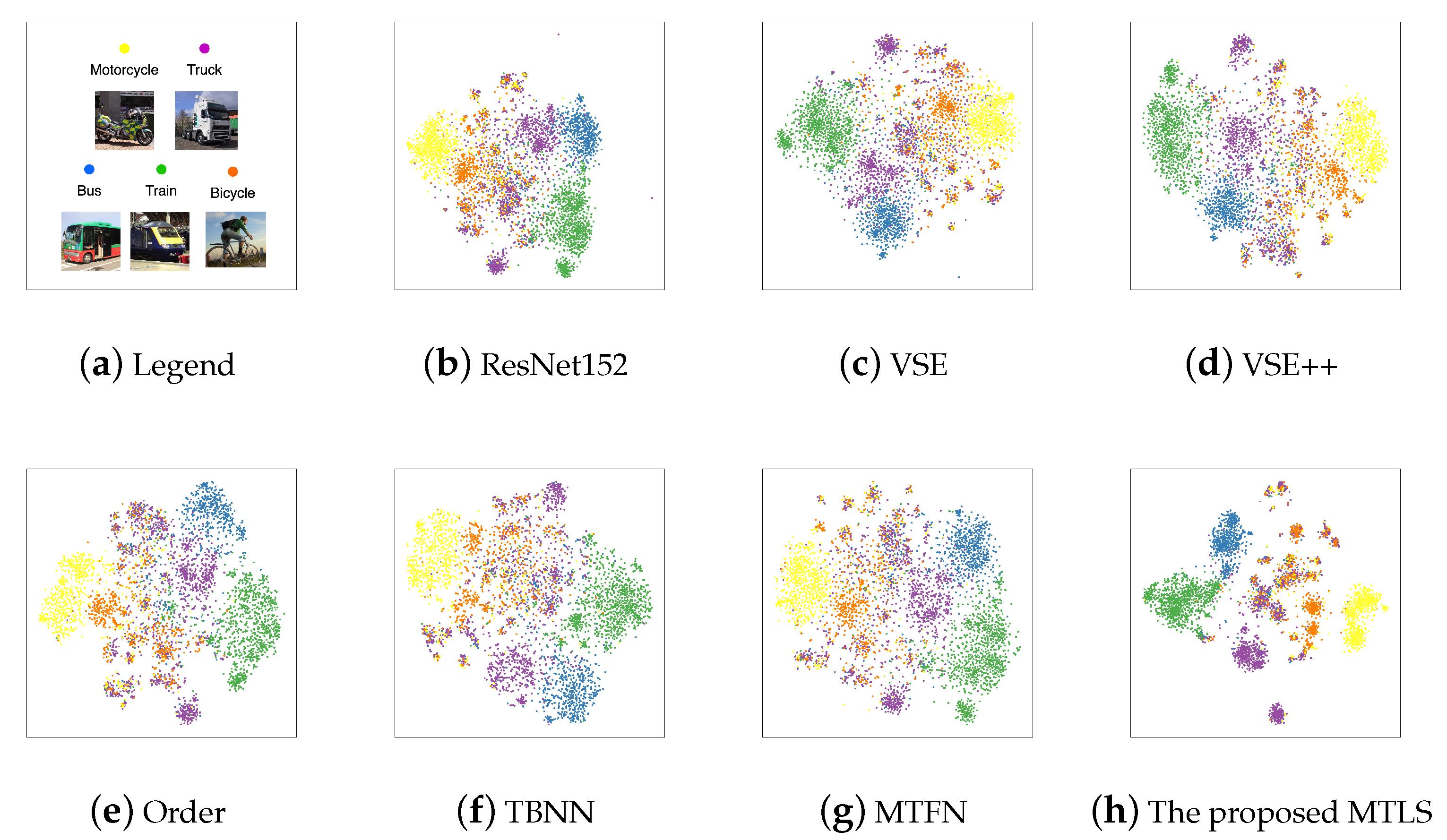
- Vehicle Dataset: it contains five subcategories images, i.e., bus, train, truck, bicycle, and motorcycle, which contains 4983 images in total. The representative image in each category is shown in Figure 5a.
- Animal Dataset: it contains seven subcategories images, i.e., horse, sheep, cow, elephant, bear, zebra, and giraffe, which contains 4737 images in total.
4.5. Visualization
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Johnson, J.; Karpathy, A.; Li, F.F. Densecap: Fully convolutional localization networks for dense captioning. In Proceedings of the CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 4565–4574. [Google Scholar]
- Antol, S.; Agrawal, A.; Lu, J.; Mitchell, M.; Batra, D.; Lawrence, Z.; Parikh, D. Vqa: Visual question answering. In Proceedings of the ICCV, Santiago, Chile, 7–13 December 2015; pp. 2425–2433.
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.J.; Shamma, D.A.; et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. Int. J. Comput. Vis. 2017, 123, 32–73. [Google Scholar] [CrossRef] [Green Version]
- Ngiam, J.; Khosla, A.; Kim, M.; Nam, J.; Lee, H.; Ng, A.Y. Multimodal deep learning. In Proceedings of the ICML-11, New Brunswick, NJ, USA, 2 July 2011; pp. 689–696. [Google Scholar]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- Baltrušaitis, T.; Ahuja, C.; Morency, L.P. Multimodal machine learning: A survey and taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 423–443. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jian, S.; Hu, L.; Cao, L.; Lu, K. Representation Learning with Multiple Lipschitz-Constrained Alignments on Partially-Labeled Cross-Domain Data. In Proceedings of the AAAI, Hilton New York Midtown, New York, NY, USA, 7–12 February 2020; pp. 4320–4327. [Google Scholar]
- Jian, S.; Hu, L.; Cao, L.; Gao, H.; Lu, K. Evolutionarily learning multi-aspect interactions and influences from network structure and node content. In Proceedings of the AAAI Conference on Artificial Intelligence. Hilton Hawaiian Village, Honolulu, HI, USA, 27 January–1 February 1 2019; Volume 33, pp. 598–605. [Google Scholar]
- Silberer, C.; Lapata, M. Learning grounded meaning representations with autoencoders. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Baltimore, MD, USA, 23–25 June 2014; pp. 721–732. [Google Scholar]
- Frome, A.; Corrado, G.S.; Shlens, J.; Bengio, S.; Dean, J.; Ranzato, M.A.; Mikolov, T. Devise: A deep visual-semantic embedding model. In Proceedings of the NIPS, Harrahs and Harveys, Lake Tahoe, CA, USA, 5–8 December 2013; pp. 2121–2129. [Google Scholar]
- Kiros, R.; Salakhutdinov, R.; Zemel, R. Unifying visual-semantic embeddings with multimodal neural language models. arXiv 2014, arXiv:1411.2539. [Google Scholar]
- Wang, L.; Li, Y.; Huang, J.; Lazebnik, S. Learning two-branch neural networks for image-text matching tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 394–407. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ouyang, W.; Chu, X.; Wang, X. Multi-source deep learning for human pose estimation. In Proceedings of the CVPR, Columbus, OH, USA, 23–28 June 2014; pp. 2329–2336. [Google Scholar]
- Zhang, H.; Hu, Z.; Deng, Y.; Sachan, M.; Yan, Z.; Xing, E. Learning Concept Taxonomies from Multi-modal Data. In Proceedings of the ACL, Berlin, Germany, 7–12 August 2016; Volume 1, pp. 1791–1801. [Google Scholar]
- Zhang, J.; Peng, Y.; Yuan, M. Unsupervised Generative Adversarial Cross-modal Hashing. In Proceedings of the AAAI, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Zhang, Y.; Lu, H. Deep cross-modal projection learning for image-text matching. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 686–701. [Google Scholar]
- Weston, J.; Bengio, S.; Usunier, N. Wsabie: Scaling up to large vocabulary image annotation. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Catalonia, Spain, 16–22 July 2011. [Google Scholar]
- Wang, T.; Xu, X.; Yang, Y.; Hanjalic, A.; Shen, H.T.; Song, J. Matching Images and Text with Multi-modal Tensor Fusion and Re-ranking. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 12–20. [Google Scholar]
- Huang, Y.; Wang, W.; Wang, L. Instance-aware image and sentence matching with selective multimodal lstm. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2310–2318. [Google Scholar]
- Li, S.; Xiao, T.; Li, H.; Yang, W.; Wang, X. Identity-aware textual-visual matching with latent co-attention. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1890–1899. [Google Scholar]
- Fukui, A.; Park, D.H.; Yang, D.; Rohrbach, A.; Darrell, T.; Rohrbach, M. Multimodal compact bilinear pooling for visual question answering and visual grounding. arXiv 2016, arXiv:1606.01847. [Google Scholar]
- Jabri, A.; Joulin, A.; Van Der Maaten, L. Revisiting visual question answering baselines. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 727–739. [Google Scholar]
- Vendrov, I.; Kiros, R.; Fidler, S.; Urtasun, R. Order-embeddings of images and language. arXiv 2015, arXiv:1511.06361. [Google Scholar]
- Lai, P.L.; Fyfe, C. Kernel and nonlinear canonical correlation analysis. Int. J. Neural Syst. 2000, 10, 365–377. [Google Scholar] [CrossRef] [PubMed]
- Andrew, G.; Arora, R.; Bilmes, J.; Livescu, K. Deep canonical correlation analysis. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1247–1255. [Google Scholar]
- Klein, B.; Lev, G.; Sadeh, G.; Wolf, L. Fisher vectors derived from hybrid gaussian-laplacian mixture models for image annotation. arXiv 2014, arXiv:1411.7399. [Google Scholar]
- Rasiwasia, N.; Costa Pereira, J.; Coviello, E.; Doyle, G.; Lanckriet, G.R.; Levy, R.; Vasconcelos, N. A new approach to cross-modal multimedia retrieval. In Proceedings of the 18th ACM international Conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 251–260. [Google Scholar]
- Lee, K.H.; Chen, X.; Hua, G.; Hu, H.; He, X. Stacked cross attention for image-text matching. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 201–216. [Google Scholar]
- Liu, C.; Mao, Z.; Liu, A.A.; Zhang, T.; Wang, B.; Zhang, Y. Focus Your Attention: A Bidirectional Focal Attention Network for Image-Text Matching. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 3–11. [Google Scholar]
- Xu, R.; Li, C.; Yan, J.; Deng, C.; Liu, X. Graph Convolutional Network Hashing for Cross-Modal Retrieval. In Proceedings of the IJCAI, Macao, China, 10–16 August 2019; pp. 982–988. [Google Scholar]
- Shi, Y.; You, X.; Zheng, F.; Wang, S.; Peng, Q. Equally-Guided Discriminative Hashing for Cross-modal Retrieval. In Proceedings of the IJCAI, Macao, China, 10–16 August 2019; pp. 4767–4773. [Google Scholar]
- Shang, F.; Zhang, H.; Zhu, L.; Sun, J. Adversarial cross-modal retrieval based on dictionary learning. Neurocomputing 2019, 355, 93–104. [Google Scholar] [CrossRef]
- Yan, C.; Li, L.; Zhang, C.; Liu, B.; Zhang, Y.; Dai, Q. Cross-modality bridging and knowledge transferring for image understanding. IEEE Trans. Multimed. 2019, 21, 2675–2685. [Google Scholar] [CrossRef]
- Wang, T.; Zhu, L.; Cheng, Z.; Li, J.; Gao, Z. Unsupervised deep cross-modal hashing with virtual label regression. Neurocomputing 2020, 386, 84–96. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Frome, A.; Singer, Y.; Sha, F.; Malik, J. Learning globally-consistent local distance functions for shape-based image retrieval and classification. In Proceedings of the ICCV, Rio de Janeiro, Brazil, 20 October 2007; pp. 1–8. [Google Scholar]
- Jian, S.; Hu, L.; Cao, L.; Lu, K. Metric-based auto-instructor for learning mixed data representation. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, Hilton New Orleans Riverside, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- LeCun, Y.; Chopra, S.; Hadsell, R.; Ranzato, M.; Huang, F. A Tutorial on Energy-Based Learning; MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yu, C.N.J.; Joachims, T. Learning structural SVMs with latent variables. In Proceedings of the ICML, Montreal, QC, Canada, 14–18 June 2009; Volume 2, p. 5. [Google Scholar]
- Faghri, F.; Fleet, D.J.; Kiros, J.R.; Fidler, S. Vse++: Improving visual-semantic embeddings with hard negatives. arXiv 2017, arXiv:1707.05612. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Young, P.; Lai, A.; Hodosh, M.; Hockenmaier, J. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Trans. Assoc. Comput. Linguist. 2014, 2, 67–78. [Google Scholar] [CrossRef]
- Lin, T.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C. Microsoft coco: Common objects in context. In Proceedings of the ECCV, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Karpathy, A.; Li, F. Deep visual-semantic alignments for generating image descriptions. In Proceedings of the CVPR, Boston, MA, USA, 7–12 June 2015; pp. 3128–3137. [Google Scholar]
- Hodosh, M.; Young, P.; Hockenmaier, J. Framing image description as a ranking task: Data, models and evaluation metrics. J. Artif. Intell. Res. 2013, 47, 853–899. [Google Scholar] [CrossRef] [Green Version]
- Zhong, Z.; Zheng, L.; Cao, D.; Li, S. Re-ranking person re-identification with k-reciprocal encoding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1318–1327. [Google Scholar]
- Ramirez, E.H.; Brena, R.; Magatti, D.; Stella, F. Probabilistic metrics for soft-clustering and topic model validation. In Proceedings of the 2010 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology, Toronto, ON, Canada, 31 August–3 September 2010; Volume 1, pp. 406–412. [Google Scholar]
- Romano, S.; Bailey, J.; Nguyen, V.; Verspoor, K. Standardized mutual information for clustering comparisons: One step further in adjustment for chance. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1143–1151. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Flickr30k Dataset | MSCOCO Dataset | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | Image-To-Text | Text-To-Image | Image-To-Text | Text-To-Image | ||||||||||||
| R@1 | R@5 | R@10 | mR | R@1 | R@5 | R@10 | mR | R@1 | R@5 | R@10 | mR | R@1 | R@5 | R@10 | mR | |
| MV [27] | 24.8 | 52.5 | 64.3 | 47.2 | 20.5 | 46.3 | 59.3 | 42.0 | 33.2 | 61.8 | 75.1 | 56.7 | 24.2 | 56.4 | 72.4 | 51.0 |
| CCA [27] | 34.4 | 61.0 | 72.3 | 55.9 | 24.4 | 52.1 | 65.6 | 47.3 | 37.7 | 66.6 | 79.1 | 61.1 | 24.9 | 58.8 | 76.5 | 53.4 |
| CCA [27] | 35.0 | 62.0 | 73.3 | 56.7 | 25.0 | 52.7 | 66.0 | 47.9 | 39.4 | 67.9 | 80.9 | 62.7 | 25.1 | 59.8 | 76.6 | 53.8 |
| VSE [12] | 42.1 | 73.2 | 84.0 | 66.4 | 31.8 | 62.6 | 74.1 | 56.1 | 56.0 | 85.8 | 93.5 | 78.4 | 43.7 | 79.4 | 89.7 | 70.9 |
| VSE++ [44] | 52.9 | 80.5 | 87.2 | 73.5 | 39.6 | 70.1 | 79.5 | 63.1 | 64.6 | 90.0 | 95.7 | 83.4 | 52.0 | 84.3 | 92.0 | 76.1 |
| Order [24] | 52.0 | 80.5 | 89.5 | 74.0 | 37.8 | 67.6 | 77.7 | 61.0 | 48.5 | 80.9 | 90.3 | 73.2 | 39.6 | 75.3 | 86.7 | 67.2 |
| TBNN [13] | 43.2 | 71.6 | 79.8 | 64.8 | 31.7 | 61.3 | 72.4 | 55.1 | 54.9 | 84.0 | 92.2 | 77.0 | 43.3 | 76.4 | 87.5 | 59.8 |
| SCAN [29] | 67.9 | 89.0 | 94.4 | 83.7 | 43.9 | 74.2 | 82.8 | 66.9 | 72.7 | 94.8 | 98.4 | 88.6 | 58.8 | 88.4 | 94.8 | 80.6 |
| BFAN [30] | 68.1 | 91.4 | - | 79.7 | 59.4 | 88.4 | - | 73.9 | 74.9 | 95.2 | - | 85.0 | 59.4 | 88.4 | - | 73.9 |
| MTFN [19] | 65.3 | 88.3 | 93.3 | 82.3 | 52.0 | 80.1 | 86.1 | 72.7 | 74.3 | 94.9 | 97.9 | 89.0 | 60.1 | 89.1 | 95.0 | 81.4 |
| MTLS | 67.5 | 89.7 | 94.6 | 84.0 | 68.8 | 87.7 | 89.6 | 82.1 | 76.4 | 96.5 | 98.5 | 90.5 | 79.4 | 97.0 | 98.1 | 91.5 |
| Vehicle Dataset | Animal Dataset | |||||
|---|---|---|---|---|---|---|
| Method | FMS | AMI | INC | FMS | AMI | INC |
| Resnet152 [37] | 52.5 | 45.5 | 31.3 | 63.4 | 58.4 | 10.7 |
| VSE [12] | 50.3 | 42.7 | 40.1 | 60.6 | 55.2 | 16.4 |
| VSE++ [44] | 52.8 | 45.5 | 31.5 | 61.9 | 56.1 | 14.3 |
| Order [24] | 58.7 | 53.5 | 11.6 | 59.3 | 52.7 | 23.1 |
| TBNN [13] | 52.8 | 48.0 | 24.7 | 55.2 | 51.0 | 28.0 |
| MTFN [19] | 55.1 | 51.4 | 16.4 | 63.3 | 56.5 | 14.3 |
| MTLS | 64.0 | 59.8 | - | 68.0 | 64.6 | - |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, B.; Jian, S.; Lu, K. Learning Multimodal Representations by Symmetrically Transferring Local Structures. Symmetry 2020, 12, 1504. https://doi.org/10.3390/sym12091504
Dong B, Jian S, Lu K. Learning Multimodal Representations by Symmetrically Transferring Local Structures. Symmetry. 2020; 12(9):1504. https://doi.org/10.3390/sym12091504
Chicago/Turabian StyleDong, Bin, Songlei Jian, and Kai Lu. 2020. "Learning Multimodal Representations by Symmetrically Transferring Local Structures" Symmetry 12, no. 9: 1504. https://doi.org/10.3390/sym12091504
APA StyleDong, B., Jian, S., & Lu, K. (2020). Learning Multimodal Representations by Symmetrically Transferring Local Structures. Symmetry, 12(9), 1504. https://doi.org/10.3390/sym12091504