3.2. Opcode
Opcode refers to the portion of instructions or fields specified in a computer program to perform an operation, and the opcode generated by PHP refers to the sequence of bytecodes that can be recognized by the Zend engine virtual machine. This is similar to a bytecode file in Java, or a bytecode object in Python, pycodeObject. Essentially, the opcode bytecode tells the machine what to do and what it is doing. Therefore, we can determine whether this file belongs to a malicious WebShell file through the opcode generated during the execution of the malicious WebShell file uploaded by the user.
In the Zend engine, the opcode bytecode file can be obtained through the Vulcan Logic Dump (VLD) tool. An example listed below is a typical malicious WebShell file parsed by the Zend engine:
| <?php @eval($_POST[’password’]);?> |
We use the VLD tool to run the above malicious WebShell file, and the opcode is shown in
Table 1.
3.4. Feature Vectorization
Word2vec is a feature vectorization tool that Google opened open in 2013, which is a deep learning model [
8,
9]. By training word vectors, Word2Vec can use low-latitude features to represent complex words, which can well reduce the feature dimension disaster caused by the traditional way to represent word vectors, thus reducing the time and space complexity of later algorithms. There are two implementations, CBOW and Skip-Gramm. CBOW predicts the target words by the context, and its model structure is shown on the left of in
Figure 2. Skip-gramm predicts context through the target words, and its model structure is shown on the right of
Figure 2. For a Word2vec implementation of words, in a good word vector, the relationship between the similarity of words can be expressed as a function of the distance between the words.
Word2Vec is one of the most popular fields in NLP [
10,
11,
12]. In
Research on the Construction of Sentiment Dictionary Based on Word2vec [
13], SO-PMI algorithm was used to judge the emotional state of the words not recorded in the dictionary, and word2Vec algorithm was used to correct them. Finally, the corrected words were added to the dictionary to complete the reconstruction of the dictionary. In
Using Word2Vec to Process Big Text Data [
14], the Word2Vec algorithm is first used to train the data model and obtain the word similarity, similar words are clustered together, and the generated cluster is used to adapt to the new data dimension to reduce the data dimension.
A Study on Sentiment Computing and Classification of Sina Weibo with Word2vec [
15] proposed a semantic orientation pointwise similarity distance (SO-SD) model, built an emotional dictionary using the Word2Vec tool, and then used the emotion dictionary to determine the emotional tendency of the microblog information.
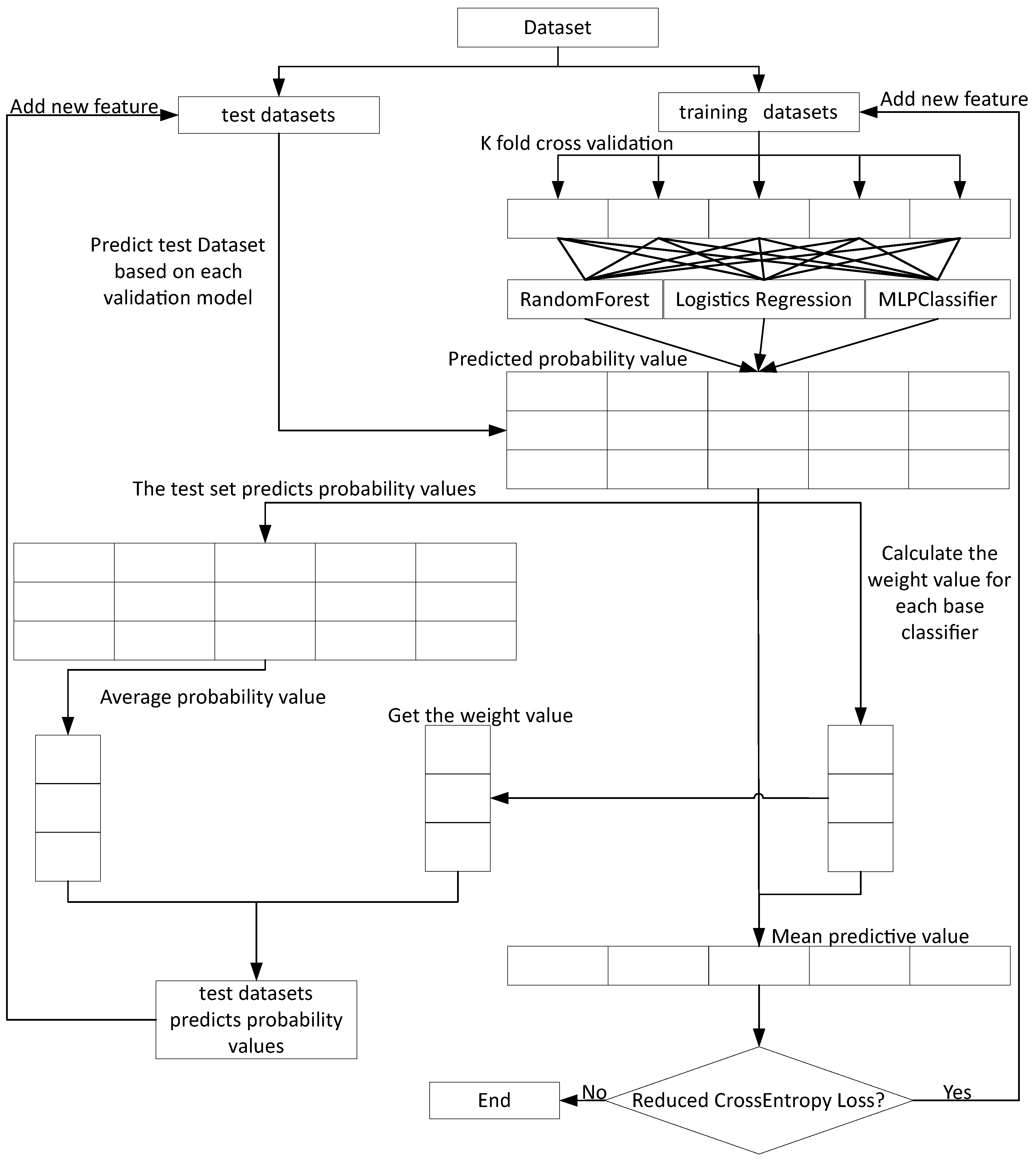
3.7. Deep Super Learner
Through the Data preprocessing operations of opcode dynamic feature extraction, static feature extraction, feature vectorization, feature selection and data sampling, the best feature set can be obtained to ensure that the deep integrated learning algorithm can give full play to the best detection effect.
Traditional machine learning algorithms are relatively simple and have strong interpretable, but their accuracy is often not as high as that of deep neural networks (DNN). The DNN output accuracy is often relatively high, and has a good application scenario in many aspects [
22,
23,
24]. However, DNN is poor in interpretation and the algorithm implementation is complex. Therefore,
Deep Super Learner: A Deep Ensemble for Classification Problems [
25] proposed a deep super learner to enable the advantages of fusion between the two, and this algorithm was applied to detect WebShell files in this study. Among them, LogisticRegression, MLPClassifier and RandomForestClassifier are used as the base classifier in the deep super learner. They can compensate for each other’s disadvantages. The advantages and disadvantages between the base classifier are shown in
Table 2. The specific implementation of model training for deep super learner is shown in Algorithm 1, the specific implementation of model test is shown in Algorithm 2, and the overall flowchart is shown in
Figure 4.
| Algorithm 1 Model training. |
| Input: Training datasets: ; List of base classifiers: ; K-fold cross-validation: K; Maximum iteration number: . |
| Output: K-fold cross-validated base classifiers model: , base classifiers temporary weight value: . |
- 1:
= [] - 2:
= [] - 3:
fordo - 4:
K-fold cross-validation in , to obtain training datasets and validation datasets; - 5:
for do - 6:
for classifier is extracted from base classifier list in turn do - 7:
The K-fold model is trained in ; - 8:
add to ; - 9:
under the model , obtain the predicted probability value of the verification data at this time; - 10:
end for - 11:
end for - 12:
the weight value of is calculated using predicted probability value of the verification data and ; - 13:
add the weight value of to ; - 14:
predicted probability value and weight value of are used to calculate the average predicted probability value of each sample; - 15:
loss minimization is calculated using average predicted probability value and ; - 16:
if the loss is smaller now than it was last time then - 17:
Add the average predicted probability value to as a new feature; - 18:
else - 19:
break - 20:
end if - 21:
end for - 22:
return.
|
| Algorithm 2 Model test. |
| Input: Test datasets: , ; base classifiers model:; K-fold cross-validation: K; base classifiers weight parameter: . |
| Output: The average predicted probability value of the test sets sample. |
- 1:
for weights value w is extracted from in turn do - 2:
K-fold cross-validation in , to obtain training datasets and validation datasets; - 3:
for model m is extracted from in turn do - 4:
for do - 5:
model m training and prediction based on k-fold cross validation; - 6:
end for - 7:
In the base classifier model m on the testsets to calculate the average predicted probability value; - 8:
end for - 9:
average predicted probability value and weights value w are used to calculate the average prediction probability value avg_probs of each sample in the test sets; - 10:
Take avg_probs as a new feature of X_data; - 11:
end for - 12:
return avg_probs
|
The SLSQP Algorithm was used to calculate the algorithm weight value in the 12th line of Algorithm 1 model training. SLSQP (Sequential Least Squares Programming), which was proposed and written by Kraft in 1988 [
35], can be used to solve nonlinear programming problems that minimize scalar functions:
when constrained by equality and inequality:
The upper and lower limits of the variable are
where m represents the number of equality and inequality constraints,
m represents the number of equality constraints,
l is the lower limit of variable
x,
u is the upper limit of variable x
, and
n is the sample size.
The SLSQP algorithm is integrated in PyOpt and SciPy. Pyopt is a python-based nonlinear constraint optimization package used to solve the optimal solution under nonlinear constraints. SciPy, a Python-based optimization package, also integrates the algorithm. In this study, however, we will use only SLSQP in SciPy.
Since this study focuses on the dichotomy of WebShell samples,
y can only be 0 or 1. The model predicts that the probability of a sample labeled 1 is:
The probability that the sample label is 0 is:
Using maximum likelihood estimation is:
The above equation is the probability that the model predicts that it belongs to the sample label
y. Since
y is the correct result given in the data set, the larger the above equation is, the better. In the formula above, we use the log transformation to get the following result:
Generally, the smaller the loss function is, the better. Therefore, by adding a negative sign to the above formula, the following formula can be obtained, namely the crossentropy loss in line 15 of Algorithm 1 model training.
where
y is the true category of the input instance
x and
is the probability that the input instance
x belongs to the malicious WebShell category.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}