1. Introduction
Researchers have often faced models involving latent variables and analyzed the relationships between two or more of those latent variables simultaneously. Latent variables are unobserved or unmeasured variables [
1] and measured by connecting to the observed variables because they cannot be directly measured [
2]. The statistical methodology that is able to accommodate these two objectives is structural equation modeling (SEM). SEM is a statistical method used to test the relationships between latent variables (path models) and between its observed variables (confirmatory factor models) [
2]. In general, SEM has two submodels, namely the measurement model and the structural model. The structural model describes the relationship between latent variables, while the measurement model is the relationship between indicators and the latent variables that construct it.
In social research, analyses involving latent variables and at the same time having a spatial effect have often been found. Spatial dependence may be caused by different kinds of spatial spillover effects. There are two frameworks that involve spatial data in the SEM model, namely at the level of the measurement model or the structural model. The involvement of spatial data at the level of the measurement model is commonly used to analyze multivariate spatial data [
3], i.e., when several variables are measured at the same locations over a spatial area, and they are often correlated with each other. Each of them might also be correlated across the locations because of geographic similarities of the different locations.
Christensen and Amemiya [
4] suggested a model with a latent variable that is distribution-free to analyze multivariate spatial data. However, it was limited by the assumption of a linear relationship between observed and latent variables that might not apply to Poisson and binomial data. The parameters of the model were estimated by means of a moment method. Wang and Wall [
3] proposed the generalized common spatial factor, which was an extension of the traditional factor analysis model. In this model, it was assumed that the common factors were spatially correlated and extended to handle more types of observed data from exponential families, especially Poisson and binomial data.
Hogan and Tchernis [
5] proposed the method of a Bayesian hierarchical model for analysis factors of spatially correlated multivariate data. At the first level, the distribution of a vector of manifest variables was conditional on an underlying latent factor in each location, whereas at the second level, the area-specific latent factors had a joint distribution that combined spatial correlation.
In contrast to previous researchers that only analyzed multivariate spatial data in measurement models in the SEM model, Liu et al. [
6] developed a generalized spatial structural equation model (GSSEM). They joined the generalized common spatial factor model proposed by Wang and Wall in [
3] and SEM that calculated spatial correlations. The GSSEM can also be extended to spatial correlations that can be added to the measurement model. Congdon [
7] used the factor analysis on the measurement model. In this model, the construct was observed through indicators. Indicators allowed both spatial correlation and correlation with one another. The relation among constructs that are nonlinear was approached using a spline regression.
Oud and Folmer [
8] proposed a SEM approach to the spatial dependence model. They combined the standard spatial model in [
9] with the multiple indicators multiple causes (MIMIC) model in [
10]. In this approach, the spatial weight that described the spatial spillover effects was located in the structural model. This approach was more flexible and informative compared to modeling that gave the spatial weight to the measurement model. The parameters of this model were estimated using Full Information Maximum Likelihood (FIML) and resulted in an estimator to control the bias of endogeneity due to the interaction between the dependent variable and its lag.
Anekawati et al. [
11] conducted modeling of education quality in the senior high school level using the spatial SEM approach. Although they allocated the spatial weight on the structural model, their work had a different perspective on the model in [
8]. They developed the spatial SEM model from the standard spatial model by Anselin in [
9] but replaced the dependent variables by endogenous latent variables, as well as independent variables. The latent variables were estimated as the factor scores using the partial least squares (PLS) method through iterative estimation developed by Trujillo in [
12]. The factor scores were modeled by involving the spatial effects, and the spatial dependence of this model was tested using the Lagrange multiplier (LM) test. The results of the spatial dependence test led to the spatial autoregressive (SAR) model. Furthermore, this model was called the spatial autoregressive model with latent variables (SAR-LVs). The parameters of the SAR-LVs model were estimated using maximum likelihood estimation (MLE).
Anekawati et al. [
13] estimated the parameters of the SAR-LVs model from Anekawati et al. in [
11] using the generalized method of moment (GMM), which was developed by Kelejian and Prucha in [
14,
15]. The SAR-LVs model in [
13] indicated a better fit for the model than the MLE method since it produced a higher R-square. Additionally, the GMM was computationally easier than MLE.
This idea can be used as alternative modeling involving latent variables and spatial data simultaneously, as the research limitation in [
16]. The research purposes in [
16] were to identify the relationship between vulnerability factors related to social, economic, and environmental aspects, and economic losses from natural disasters in 230 local communities in South Korea. The social, economic, and environmental aspects were latent variables measured by connecting to the observed variables. The social aspect was constructed by two indicators, namely the percentage of the population over age 15 without elementary school completion and a minority percentage of foreigners. Additionally, the economic and environmental aspects were latent variables. However, the relationship was modeled based on indicators, which were not latent variables. It was less precise to identify the research purpose. That study revealed the limitations of the study, which was an indicator-based approach for the identification of vulnerability factors. Therefore, the method in this study provides an alternative solution for the spatial model that involves latent variables, especially focusing on the spatial dependency test using the LM test.
Oud and Folmer [
8] did not perform a diagnostic test of spatial dependence, so there was no direction in determining whether the model led to the spatial autoregressive model or the spatial error model. Anekawati’s research works in [
11,
13] tested the spatial dependence using the Lagrange multiplier (LM) to diagnose spatial dependence.
One of the constructions of the test of parametric hypotheses based on asymptotic theory is the LM test [
17]. Anselin [
18] developed the diagnostics for spatial dependence using the LM test. The LM approach seems reasonable and relatively easy based on estimation under the null hypotheses [
17], namely, in its most simple form. Yang [
19] introduced a residual-based bootstrap method for asymptotically refined approximations to the finite sample critical values of the LM statistics.
The LM test of spatial dependence [
18,
19] did not involve latent variables for the standard SAR model. Anekawati‘s work [
11,
13] used the LM test of spatial dependence for the SAR-LVs model, but an error distribution of the model was assumed the same as the standard SAR model in [
9,
18]. The LM test for the standard SAR model in [
9,
18] had an assumption that error was normally distributed
. Meanwhile, the SAR-LVs model was modeled based on the standard SAR model, where factor scores replaced the independent and dependent variables. The factor scores were the estimation result of the latent variables in the submodel in SEM, namely, the measurement model. The measurement model had the assumption that the error was normally distributed, namely,
for exogenous and
for endogenous, while the error distribution in the standard SAR model was
. As a result, the error distribution of the SAR-LVs model should have a different distribution from the error of the standard SAR model. In this paper, an attempt is made to fill this gap. The focus of this study is to develop a Lagrange multiplier test of spatial dependence for the spatial autoregressive model (SAR) with latent variables (LVs).
To complete this paper, the estimation of latent variables into factor scores uses the weighted least squares (WLS) method, so that the error distribution of the SAR-LVs model is constructed from the result of this estimation. The estimation of parameters of the SAR-LVs model uses the two-stage least squares (2SLS) method. In the last section, the SAR-LVs model is applied for cases of the positive and negative spatial autoregressive coefficient to provide an interpretation of the spatial autoregressive coefficient.
2. Materials and Methods
2.1. Spatial Autoregressive Model with Latent Variable (SAR-LVs Model)
SEM consists of two basic components—the structural model and measurement model in [
2]. The measurement model represents the relationship between the manifest variable and exogenous latent variables (1) or endogenous latent variables (2), while the structural model describes the relationship among the latent variables (3). Bollen in [
1] wrote the measurement and structural model as Equations (1)–(3).
where
is the
endogenous random vector,
is the number of the endogenous variables,
is the
exogenous random vector,
is the number of the exogenous variables,
is the
coefficient matrix that shows the effect of the relationship of an endogenous latent variable to another endogenous variable,
is the
coefficient matrix which shows the effect of
relationship to
,
is the
random error vector,
is the
observed vector of the endogenous variables,
is a total number of indicators of the endogenous variables,
is the
observed vector of the exogenous,
is a total number of indicators of the exogenous variables,
is the
coefficient matrix which shows the relationship of
to
,
is the
coefficient matrix which shows the relationship of
to
,
is the
measurement error vector of
, and
is the
measurement error vector of
.
Assumptions that must be fulfilled are
is nonsingular, and the element of error vectors of measurements, namely
and
are homoscedastic and nonautocorrelated across observations (see [
1]).
Anselin wrote the standard SAR model in [
9]:
where
is the
spatially lagged dependent vector,
is the number of the observed units,
is the
exogenous matrix,
is coefficient of
,
is the
parameters vector of exogenous,
is the
spatial weight matrix with the main diagonal elements being zero,
is the
disturbance vector, where it is the classic homoscedastic situation. The queen contiguity method was used for spatial weighting. In queen contiguity,
Wij is defined as 1 for the entity where the common side or the common vertex meets the region of concern, and
Wij is defined as 0 for other regions [
20].
Oud and Folmer in [
8] wrote the SAR-LVs model in the form of the MIMIC. The proposed model was
, where
was the spatial lag coefficient of the endogenous variable,
was the contiguity matrix, and
was the observation matrix of the explanatory variable.
The SAR-LVs model is a model that involves latent variables, and the unit of observation is location. The SAR-LVs model is a standard SAR model in which the independent and dependent variables are latent variables. In the SEM model, there are latent variables that cannot be measured directly as a sample unit. Therefore, in this work, to represent the latent variable in the standard SAR in Equation (4) is changed by the factor score. The latent variable is replaced by the factor score from the measurement model in Equations (2) and (3) as a measured and random unit sample. As seen in Equation (4), the spatially lagged dependent variable is changed by the endogenous latent variable (), and the exogenous variable () is changed by the exogenous latent variable (), which is previously estimated using the WLS method. The result of estimation of the latent variable is denoted by and . This SAR-LVs model does not use the MIMIC model, since there are no exogenous or endogenous variables that are observed variables, and the endogenous variable is limited to only one.
Thus, the SAR-LVs model in Equation (4) changes to:
where
is the the
endogenous factor score vector,
is the
exogenous factor score matrix, and
is the
regression coefficient vector.
2.2. Estimation of Score of Latent Variable
The factor score is the estimation result of the latent variables, both the endogenous and exogenous variables in the measurement model. The method used is the WLS, which is by minimizing the sum squared errors that are weighted by the error variant matrix. In the estimation process, to obtain a factor score, it is assumed that the value of the loading factor and the error variant matrix are constant.
In the equation of the measurement model of the exogenous latent variable (1), where
is the number of the exogenous latent variable,
is the number of indicators of the
ith exogenous latent variable, and
is an error, where
with
is the covariant–variant matrix of measurement error of observed variable
, namely
The distribution of
is obtained through the properties of the expected value and variance of a random variable. It is assumed that the value of
and
are constant.
and
. Therefore, if
and
then the distribution of
is
. Suppose that a random sample T is given from a random variable
with
t = 1, 2, …, T so
. The probability function of
is
The likelihood function is
The latent variable
is estimated using the WLS method with optimization
). Maximum
by adding the weight of an error variant matrix
is obtained as
or can be written in matrix form and contain each element as
By assuming matrix
and
, so
in Equation (6) is a random observation matrix. Based on Definition A.1 in [
21] (
Appendix A),
has normal distribution
, where
.
The definition of the characteristic function of the random matrix is , where . If part of Equation (6) is assumed then Equation (6) can be simplified into . The characteristic function of is . Based on Theorem B.1, the characteristic function of can be changed into . If then the characteristic function of can be changed into .
The distribution of X is
and
. Based on Theorem A.2, the characteristic function of
is
. If
is changed by
then the characteristic function of
is
Furthermore,
is changed by
, so the characteristic function of
is
Based on Theorem A.2 and Equation (7),
is the matrix variate normal distribution with mean
and covariate matrix
and is notated by
. Based on Theorem A.1,
is the matrix variate normal distribution that is notated by:
In this paper, the number of the endogenous variables is limited only to one. The covariance matrix of the measurement error of the observed variable for
is
, namely
, where
is the number of indicators of the endogenous latent variable. In the same way as the previous estimation with the exogenous latent variable and by assuming that vector
and
, it is obtained
and its distribution is
Theorem A.1, A.2, and B.1 are provided in
Appendix A.
2.3. The Error Distribution of The SAR-LVs Model
The equation of the SAR-LVs model from the estimated factor score can be arranged as Equation (6) and adding
it can be written as
or can be written in the matrix form
where
is Equation (6) and
is Equation (10).
The SAR-LVs model (11) is a spatial regression model by considering as a response variable and as a predictor variable, both of which are random. Thus, the function of is , so that the variable is no longer random but fixed. As a result, the error in Equation (11) is where is a random variable, is fixed and is assumed not to correlate with , and .
The expectation value of
is
, and the variance of
is
, so the error distribution of
is
where
The error distribution of the standard SAR model is , while the error distribution of the SAR-LVs model is as Equation (12). This error distribution is used to construct the LM test.
2.4. Test of Dependency Spatial
The Lagrange multiplier (LM) test of the SAR-LVs model, as shown in Equation (11), is a test based on estimation under the null hypothesis. The likelihood function in the SAR-LVs model is obtained by replacing and multiplying by the Jacobian in the Gaussian function so that the likelihood function for the SAR-LVs model is obtained: , where .
The log-likelihood function for the SAR-LVs model is , where the value of is as in Equation (13), and .
Breusch and Pagan in [
17] defined LM test statistics as follows:
, where
is an element of an information matrix measuring
whose elements are the second derivative of each parameter estimated as
. The test was under the null hypothesis, so
is the first derivative of the log-likelihood function of
where
.
The value of
and
were decomposed in
Appendix A, which obtained
so
where
is an error of the OLS regression model,
, so
. The LM statistic test is
where
and
, so the value of test statistic LM becomes
The LM statistics follows the asymptotic distribution of .
2.5. Estimation of Parameter of SAR-LVs Model
If the parameter of the SAR-LVs model in Equation (11) and its error distribution as Equation (12) are estimated by the OLS, then the estimator is biased and inconsistent, since there is a case where the regression variable correlates with the error ε or . If the model is estimated by the moment method, the overidentified condition is obtained. The following explains the overidentified condition.
The Equation (11) can be simplified as follows:
where
is
and has the
-sized,
is
and has the the
-sized.
In this work, δ as Equation (15) was estimated by the 2SLS method as performed by [
14,
15], namely two steps of the ordinary least squares (OLS) method as follows: (i). The 2SLS method requires an
instrument variable, which is a joint of the
matrix and the
matrix or written as
. The instrument variable
is valid because it does not correlate with
and correlates with regressor
; (ii). Regress
on instrument variable
to obtain
; (iii). Regress
on
to obtain
where
and
which contains
and
.
3. Results and Discussion
In the discussion, this study examined two cases or models developed with the results of positive and negative spatial autoregressive coefficient to provide an interpretation of the spatial autoregressive coefficient. The first case was the education quality model developed by [
13], with updated data in 2018 and showing a negative spatial autoregressive coefficient. Meanwhile, the second case related to a poverty model conducted by [
22] producing a positive spatial autoregressive coefficient.
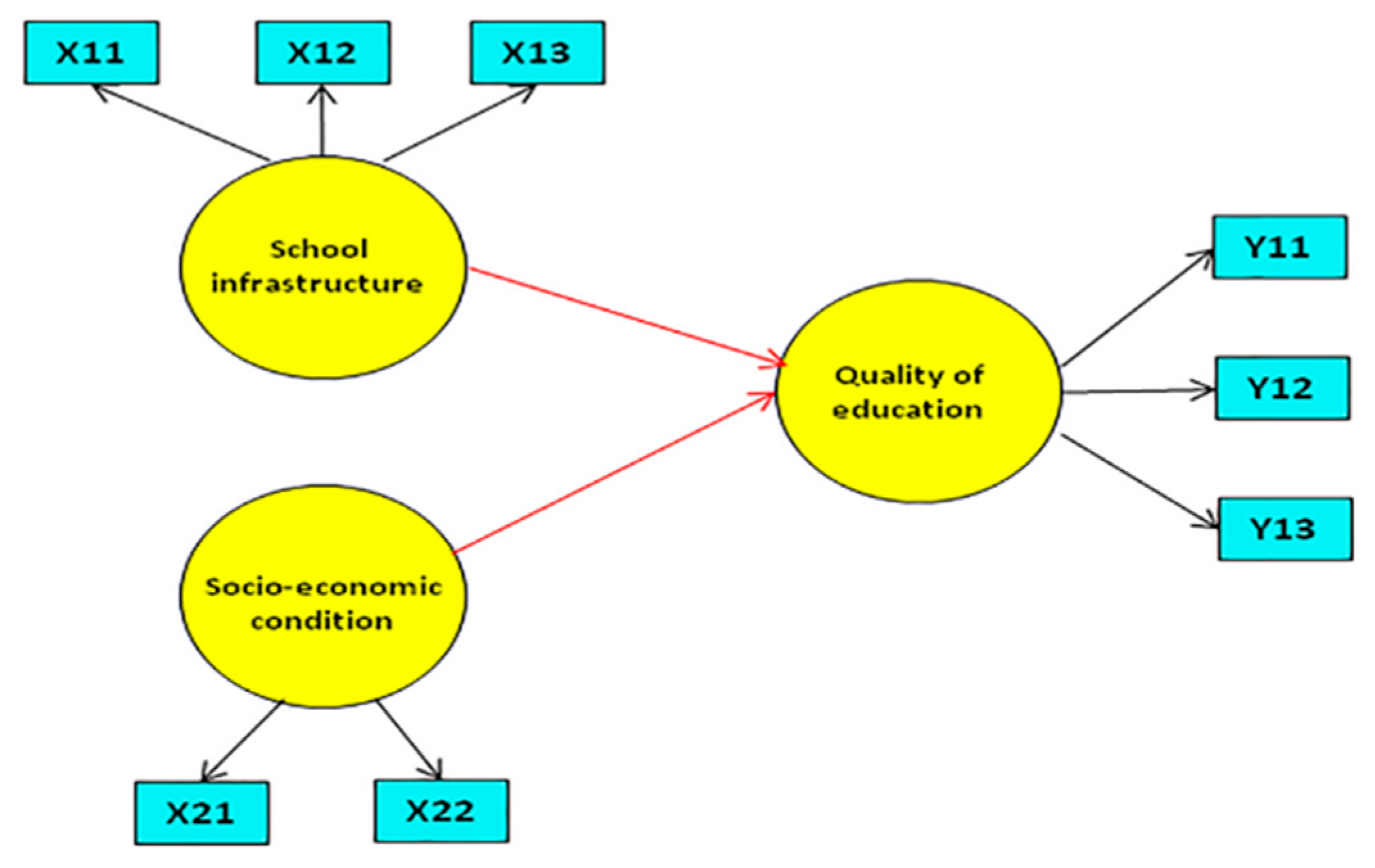
The education quality model for senior high schools in Sumenep Regency involved 27 observation units, one endogenous latent variable, and two exogenous latent variables. The endogenous latent variable was the education quality with three indicators. Indicators of education quality were the ratio of the gross enrolled number of senior high school students to the number of children aged between 15 and 18 years in each district (Y11)—the ratio of the number of accredited senior high schools with at least B levels to the total number of senior high schools in each district (Y12) and the average of national exam scores of senior high school students in each district (Y13).
Exogenous latent variables were school infrastructure and socioeconomic conditions. Indicators of school infrastructure were the proportion of the number of schools with a minimum classroom space according to the regulations of the national education ministry (X11), the proportion of the numbers of schools with laboratories according to the regulations of the national education ministry (X12), and the proportion of the number of schools with libraries according to the regulations of the national education ministry (X13).
Indicators of socioeconomic conditions were the ratio of the number of households running a home industry or with a shop at home to the total number of households in each district (X21) and the ratio of the number of households using clean water to the total number of households in each district (X22). The model is shown in
Figure 1.
Latent variables were estimated as in the Equations (6) and (9), then were modeled as in the Equation (11). The estimation of the model parameters as the Equation (16) used the Matlab software, and the results are shown in
Table 1. The LM test based on the Equation (14) used Matlab software, and the obtained value
was −2.3272. The value of
was compared to
with degrees of freedom of one and
. Then, the result was significant towards the SAR-LVs model. Additionally, the spatial autoregressive coefficient was negative.
In general, the SAR-LVs model for the education quality of the senior high school is: , where is the education quality in the i-th district, is the infrastructure, and is socioeconomic condition.
The spatial dependence test result was significant. This means there was a correlation between the education quality of the senior high schools in one district and the one in other contiguous districts. The negative spatial autoregressive coefficient interpreted the opposite of the common spillover effect, i.e., a district was supported by or gained a spillover effect of the neighboring districts’ education quality.
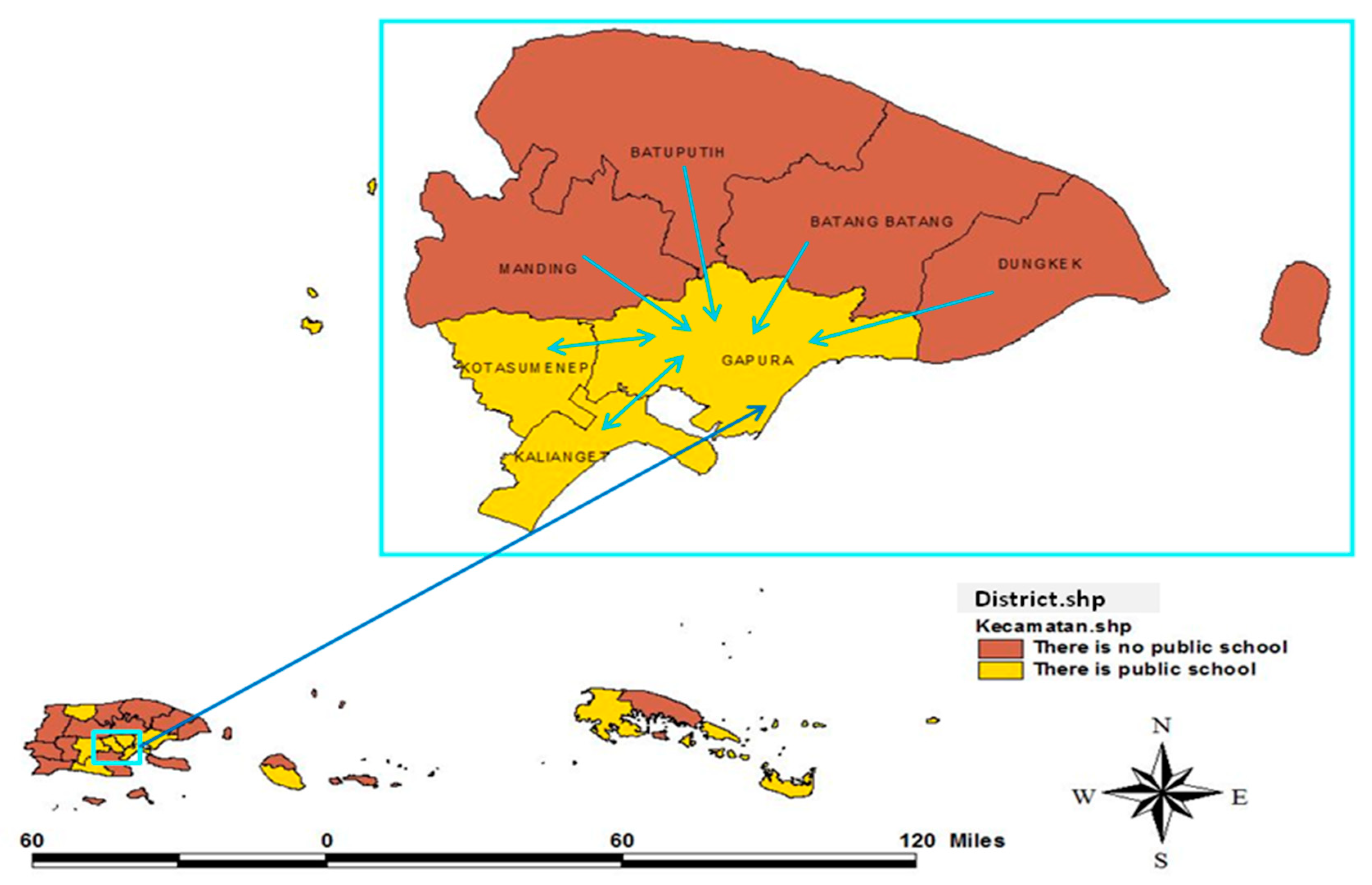
The spillover effect of the neighboring districts’ education quality was generally due to the migration of students to find high-quality schools in the neighboring districts. As a result, the districts that had high-quality schools, gained the spillover effect of quality education through high-achieving students from the neighboring districts. In general, high-quality schools in Sumenep Regency are public schools.
Figure 2 draws the distribution of districts with and without public schools. To illustrate the student migration, an example is provided in the Gapura district (see
Figure 2).
Table 2 shows the number of junior high school graduates and new senior high school students for seven districts in the same year, 2018, based on [
23]. This table provides an overview of the migration data of students entering senior high school among districts. The Gapura District was used as an example to illustrate student migration (see
Figure 2 and
Table 2). The Gapura District has one public school and six neighboring neighbors (queen contiguity). Based on
Table 2, the Gapura District has 485 junior high school graduates and 622 new high school students. This means that there was a migration of students to the Gapura District.
The Gapura District received the spillover effect of quality education from neighboring districts, especially those with no public schools. The quality spillover was due to schools in the Gapura district having the opportunity to select the best students from the district itself or the neighboring districts.
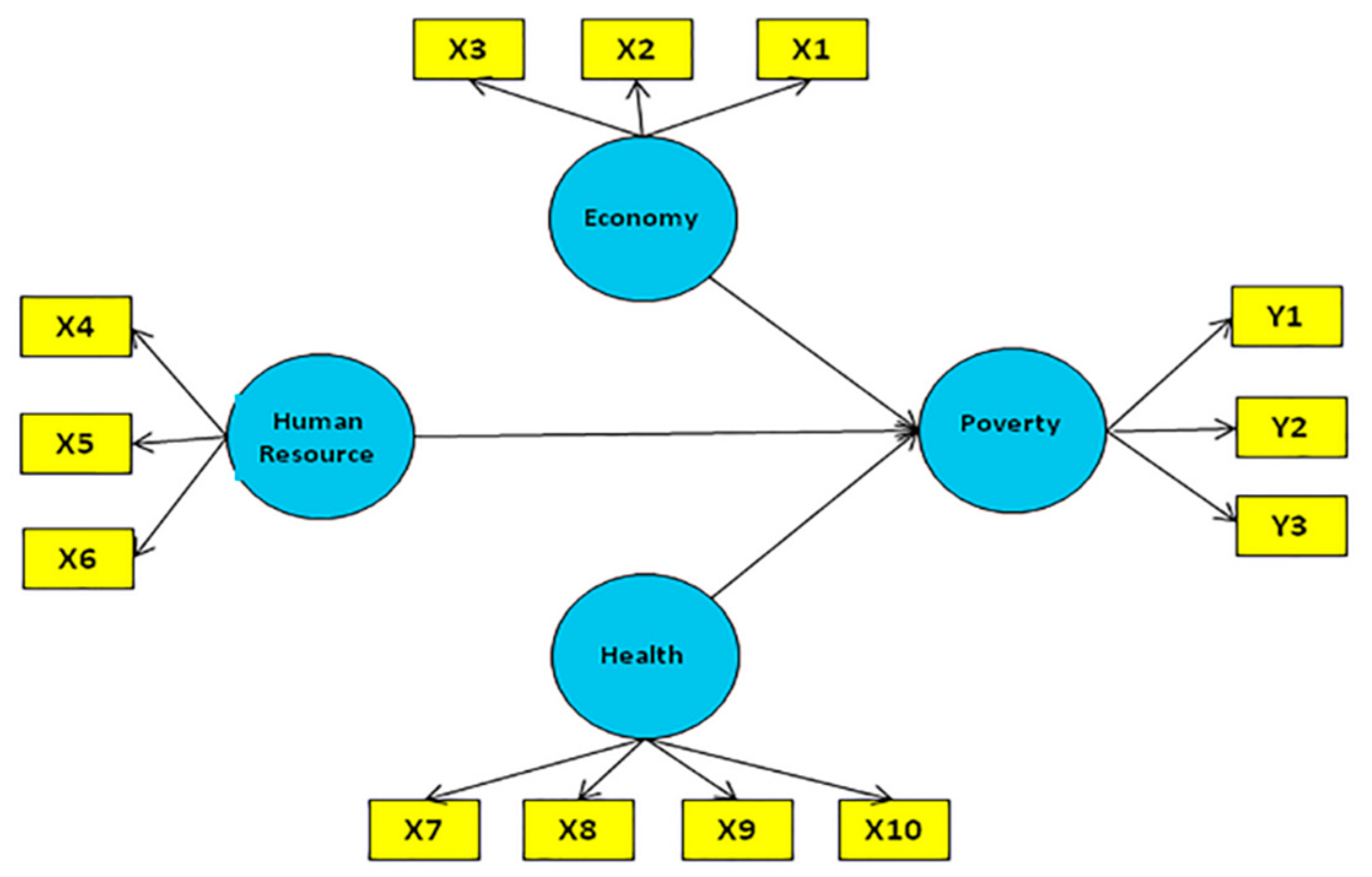
The second case was the poverty model in East Java province, with an observation unit of 38 regencies. This model had one endogenous latent variable, namely poverty, and three exogenous latent variables, namely Economy, Human Resource, and Health. Poverty indicators were the percentage of the poor population (Y1), the index of poverty depth (Y2), and the index of poverty severity (Y3). Indicators of economics were the percentage of poor people around 15 years old or more who were unemployed (X1), the percentage of poor people aged 15 years old or more who were working in agriculture (X2), and the percentage of households gaining Raskin (X3). Raskin is an Indonesian subsidy program to provide rice for people who live under the poverty line. Indicators of Human Resources were the percentage of poor people aged 15 years old and over who did not complete elementary education (X4), the literacy rate of the poor aged from 15 to 55 years (X5), and the participation rates in schools for the poor aged from 13 to 15 years (X6). Health indicators were the percentage of women using KB (Family planning program) devices in poor households (X7), the percentage of children under five in poorly immunized households (X8), the percentage of poor households using drinking water (X9), and the percentage of poor households using private/together latrines (X10). The model is shown in
Figure 3.
Latent variables were estimated as in the Equations (6) and (9), then were modeled as in the Equation (11). The estimation of the model parameters as in the Equation (16) used the Matlab software, and the results are shown in
Table 3. The LM test based on Equation (14) used the Matlab software, and the obtained value
was −4965. The value of
was compared to
with degrees of freedom of one and
. Then, the result was significant towards the SAR-LVs model. Meanwhile, the spatial autoregressive coefficient was positive.
In general, the SAR-LVs model for the poverty is , where is poverty in the i-th regency, is Economy, is Human Resource, and is Health.
The spatial dependence test result was significant. This means there was a correlation between poverty in one regency and the one in other contiguous regencies. The positive spatial autoregressive coefficient interpreted the common spillover effect, i.e., a regency gives a poverty spillover effect to the neighboring regencies.
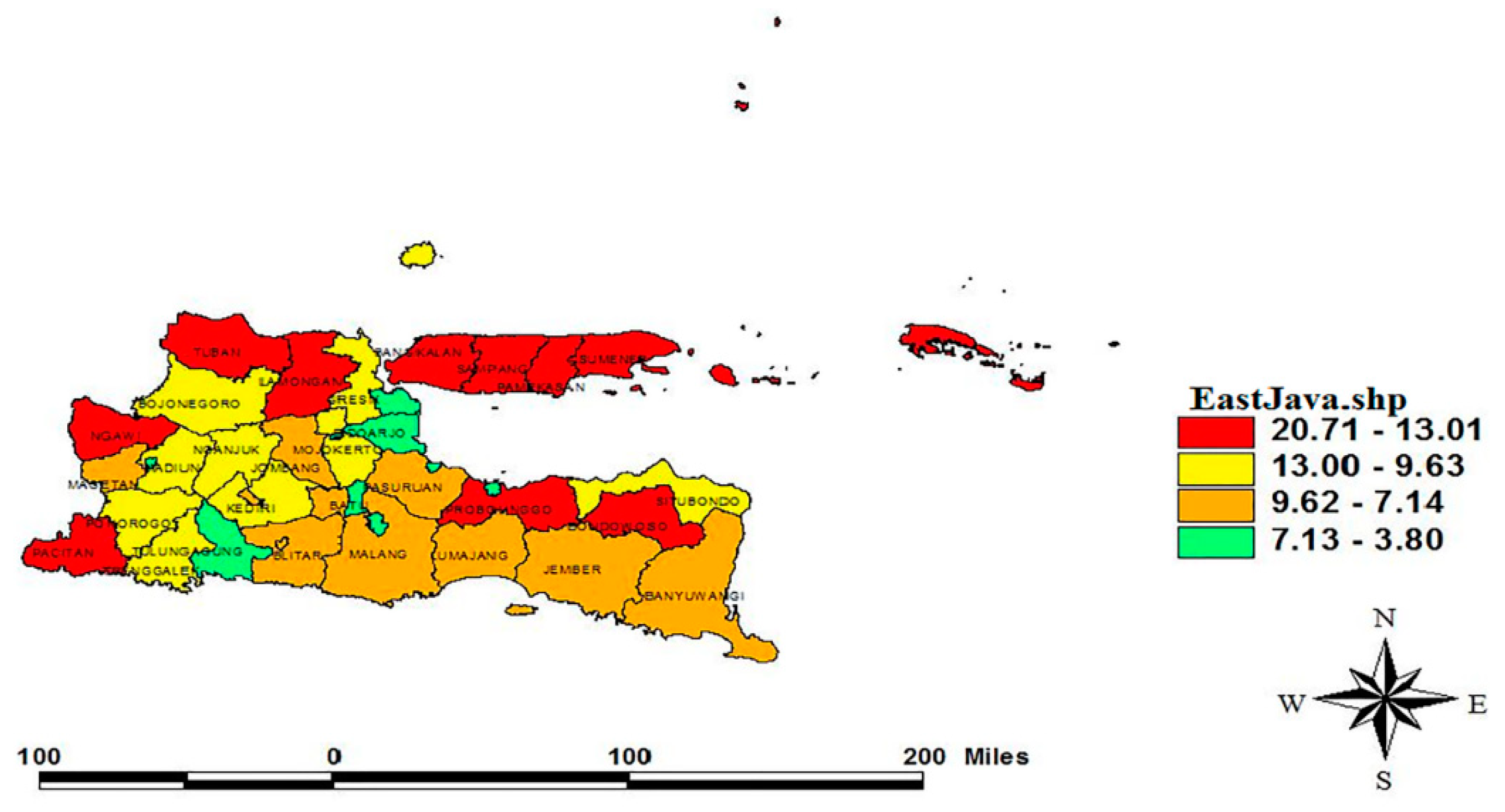
Figure 4 describes the poor people distribution in the East Java province measured in percent. The percentage of poor people was based on the poverty data in [
24] and was clustered into four quartiles. The regency with the high percentage of poor people was categorized as the first quartile (red zone), with 20.71–13.01%. On the other hand, the fourth quartile (green zone) includes the regency with 7.13–3.80% of the poor group. The first quartile was the regency group with the highest percentage of poor people, and so on until the fourth quartile was the regency group with the lowest percentage of poor people. According to
Figure 4, the location of regencies in the first quartile was always close to the regencies in the first and the second quartile. This visualization reinforces the results of the multiplier Lagrange test that there is a spatial effect where one regency gives the influence of poverty on its neighboring regencies.
The finding of this method provides value for policymakers relating to existing problems. The first case was the negative spatial autoregressive coefficient for the education quality model. It interpreted that a district was supported by or gained a spillover effect of the neighboring districts’ education quality through students’ migration. This case needs the policy to strive for quality standardization for all schools. The second case was the positive spatial autoregressive coefficient for the poverty model. It interpreted that a regency gives a poverty spillover effect to the neighboring regencies. Policymakers need this information to assist at the locus of poverty appropriately.
4. Conclusions
The SAR-LVs model is a standard SAR model in which the independent and dependent variables are latent variables. The standard SAR model is . The variable of is changed by the endogenous factor score (), and is changed by the exogenous factor score (). The estimation of the latent variables uses the WLS method and assumes that the value of and are constant. Therefore, the SAR-LVs model can be modeled as , where and . The distribution of and are and . The variables of and are random. Thus, the function of is , so that the variable is no longer random but fixed. The error distribution is obtained through the properties of the expected value and the variance of the error in the SAR-LVs model, namely where . Based on its error distribution model, so under the null hypothesis, the LM statistic is and follows the asymptotic distribution of .
Some significant limitations of this study need to be considered. Firstly, the number of endogenous latent variables is one. Future studies can be developed for the higher number of endogenous latent variables. Secondly, the LM test developed was merely for SAR-LVs. Future studies can be developed for a spatial error model with latent variables (SEM-LVs).







{kind=link}
{kind=link}
{kind=link}
{kind=link}