Abstract
A binary grammar is a relational grammar with two nonterminal alphabets, two terminal alphabets, a set of pairs of productions and the pair of the initial nonterminals that generates the binary relation, i.e., the set of pairs of strings over the terminal alphabets. This paper investigates the binary context-free grammars as mutually controlled grammars: two context-free grammars generate strings imposing restrictions on selecting production rules to be applied in derivations. The paper shows that binary context-free grammars can generate matrix languages whereas binary regular and linear grammars have the same power as Chomskyan regular and linear grammars.
1. Introduction
A “traditional” phrase-structure grammar (also known as a Chomskyan grammar) is a generative computational mechanism that produces strings (words) over some alphabet starting from the initial symbol and sequentially applying production rules that rewrite sequences of symbols [1,2,3]. According to the forms of production rules, phrase-structure grammars and their languages are divided into four families: regular, context-free, context-sensitive, and recursively enumerable [4,5].
Regular and context-free grammars, which have good computational and algorithmic properties, are widely used in modeling and studying of phenomena appearing in linguistics, computer science, artificial intelligence, biology, etc. [6,7]. However, many complex structures such as duplication (), multiple agreements () and crossed agreements () found in natural languages, programming languages, molecular biology, and many other areas cannot be represented by context-free grammars [6]. Context-sensitive grammars that can model these and other “non-context-free" structures are too powerful in order to be used in applications [5,8]. In addition many computational problems related to context-sensitive grammars are undecidable, and known algorithms for decidable problems concerning to these grammars have exponential complexities [4,5,6,9].
An approach to overcome this problem is to define “in-between’’ grammars that are powerful than context-free grammars but have similar computational properties. Regulated grammars are such types of grammars that are defined by adding control mechanisms to underlying context-free grammars in order to select specific strings for their languages [5]. Several variants of regulated grammars, such as matrix, programmed, ordered, context-conditional, random-context, tree-controlled grammars, have been defined according to control mechanisms used with the grammars [5,6,8]. Regulated grammars are classified into two main categories: rule-based regulated grammars that generate their languages under various production-related restrictions, and context-based regulated grammars that produce their languages under different context-related restrictions [10].
Though this type of the classification of regulated grammars allows us to understand the nature of restrictions imposed on the grammars, it does not clarify the role of control mechanisms from the aspect of the computational power. If we observe the control mechanisms used in both categories of regulated grammars, we can see that they consist of two parts [6]: (1) a “regular part", which is represented by a regular language of the labels of production rules (in rule-based case) or a regular language over the nonterminal and/or terminal alphabets (in context-based case) and (2) an “irregular part", which is represented by appearance checking (in rule-based case) and forbidding context (in context-based case), provides an additional power to the regular part.
If a regular part is solely used, the regulated grammars can generate small subsets of context-sensitive languages. On the other hand, if the both of regulations are used, then most regulated grammars generate all context-sensitive languages [6,10]. At this point, we again return to the same computational problems related to context-sensitive grammars, which we discussed early. Thus, we need to consider such regulation mechanisms that can grant to extend the family of context-free languages only to required ranges that cover necessary aspects of modeled phenomena. One of the possibilities to realize this idea can be the combination of several regular control mechanisms. One can consider a matrix of matrices or a matrix conditional context as combined regulation mechanisms. For instance, paper [11] studied simple-semi-conditional versions of matrix grammars with this approach. The problem in this case is that the combinations of such control mechanisms are, firstly, not natural and, secondly, they are too complex.
We propose, as a solution, an idea of imposing multiple regulations on a context-free grammar without combining them. We realize this idea by using relational grammars. A relational grammar is an n-ary grammar, i.e., a system of n terminal alphabets, n nonterminal alphabets, a set of n-tuples of productions and the initial n-tuple of nonterminals that generates the language of relations, i.e., tuples of strings over the terminal alphabets. On the other hand, a relational grammar can be considered of a system of n grammars in which each grammar generates own language using the corresponding productions enclosed in n-tuples. Thus, we can redefine a relational grammar as a system of mutually controlled n grammars where the grammars in relation generate their languages imposing restrictions on the applications of productions of other grammars. If we specify one grammar as the main, the other grammars in the system can be considered to be the regulation mechanisms controlling the generative processes of the main grammar.
This work is a preliminary work in studying mutually controlled grammars. In this paper, we define binary context-free grammars and study their generative power. We show that even mutually controlled two grammars can be as powerful as matrix grammars or other regulated grammars without appearance checking or forbidding context.
The paper is organized as follows. Section 2 surveys on regulated, parallel and relational grammars that are related to the introduced grammars. Section 3 contains necessary notions and notations used throughout the paper. Section 4 defines binary strings, languages and grammars Section 5 introduces synchronized normal forms for binary grammars and shows that for any binary context-free (regular, linear) grammar there exists an equivalent binary grammar in synchronized form. Section 6 investigate the generative powers of binary regular, linear and context-free grammars. Section 7 discusses the results of the paper and the power of mutually controlled grammars, and indicates to possible topics for future research.
2. Regulated, Parallel and Relational Grammars
In this section, we briefly survey some variants of regulated grammars with respect to the control mechanisms associated with them, parallel grammars as well as relational grammars, which are related to the introduced mutually controlled grammars.
The purpose of regulation is to restrict the use of the productions in a context-free grammar to select only specific terminal derivations successful hence to obtain a subset of the context-free language generated in usual way. Various regulation mechanisms used in regulated grammars can be classified into general types by their common features.
Control by prescribed sequences of production rules where the sequence of productions applied in a derivation belong to a regular language associated with the grammar:
- matrix grammars [12]—the set of production rules is divided into matrices and if the application of a matrix is started, a second matrix can be started after finishing the application of the first one, as well as the rules have to been applied in the order given a matrix;
- vector grammars [13]—in which a new matrix can be started before finishing those which have been started earlier;
- regularly controlled grammars [14]—the sequence of production rules applied in a derivation belong to a given regular language associated with the grammar.
Control by computed sequences of production rules where a derivation is accompanied by a computation, which selects the allowed derivations:
- programmed grammars [15]—after applying a production rule, the next production rule has to be chosen from its success field, and if the left hand side of the rule does not occur in the sentential form, a rule from its failure field has to be chosen;
- valence grammars [16]—where with each sentential form an element of a monoid is associated, which is computed during the derivation and derivations where the element associated with the terminal word is the neutral element of the monoid are accepted.
Control by context conditions where the applicability of a rule depends on the current sentential form and with any rule some restrictions are associated for sentential forms which have to be satisfied in order to apply the rule:
- random context grammars [17]—the restriction is the belonging to a regular language associated with the rule;
- conditional grammars [18]—the restriction to special regular sets;
- semi-conditional grammars [19]—the restriction to words of length one in the permitting and forbidden contexts;
- ordered grammars [18]—a production rule can be applied if there is no greater applicable production rule.
Control by memory where with any nonterminal in a sentential form, its derivation is associated:
- indexed grammars [20]—the application of production rules gives sentential forms where the nonterminal symbols are followed by sequences of indexes (stack of special symbols), and indexes can be erased only by rules contained in these indexes but erasing of the indexes is done in reverse order of their appearance.
Control by external mechanism where a mechanism used to select derivations does not belong to the grammar:
- graph-controlled grammars [21,22]—the sequence of productions applied in a derivation to obtain a string corresponds to a path, whose nodes represent the production rules, in an associated bicolored digraph;
- Petri net controlled grammars [23,24]—the sequence of productions used to obtain a string of the language of a grammar corresponds to a firing sequence of transitions, which are labeled by the productions, from the initial marking to a final marking.
Parallelism is another nontraditional approach used with grammars where, instead of rewriting a single symbol in each derivation step, several symbols can be rewritten simultaneously. There are two main variants of parallel mechanisms associated with grammars. The first is total parallelism, which is used in the broad varieties of (Deterministic Extended Tabled Zero-Sided) Lindenmayer systems [5,25] where all symbols of strings including terminals are in each step rewritten by productions. The second is partial parallelism where all or some nonterminal symbols (not terminal symbols) are written in each step of the derivations:
- absolutely parallel grammars [26]—all nonterminals of the sentential form are rewritten in one derivation step;
- Indian parallel grammars [27]—all occurrences of one letter are replaced (according to one rule);
- Russian parallel grammars [28]—which combines the context-free and Indian parallel feature;
- scattered context grammars [29]—in which only a fixed number of symbols can be replaced in a step but the symbols can be different;
- concurrently controlled grammars [30]—the control over a parallel application of the productions is realized by a Petri net with different parallel firing strategies.
Another perspective in using the notion of parallelism with grammars is a grammar system, which is a system of several phrase-structure grammars with own axioms, symbols and rewriting productions that can work simultaneously and generate own strings. One of such grammar systems is a parallel communicating grammar system [31,32], where the grammars start from separate axioms, work parallelly rewriting their own sentential forms, and also communicate with each other by request. The language of one distinguished grammar in the system is considered the language of the system.
A relational grammar (an n-ary grammar) can be considered to be another type of grammar systems consisting of several grammars that work by applying productions synchronously or asynchronously [33,34]. More precisely, an n-ary grammar (where n is a positive integer) is a system of n terminal alphabets, n nonterminal alphabets, a set of productions and an initial n-tuple of nonterminals. Each production is an n-tuple of common productions or empty places. An n-ary grammar generates the language of relations, i.e., n-tuples of strings over the terminal alphabets. Work [33] showed that classes of languages generated by relational grammars forms a hierarchy between the family of context-free languages and the family of context-sensitive languages. Paper [34] studied closure, projective and other properties of relational grammars, and generalized the Chomsky’s classification for n-ary grammars. Several other papers [35,36,37,38,39,40] also investigated the properties of relational grammars and applied in solving problems appeared in natural and visual language processing.
3. Notions and Notations
Throughout the paper, we assume that the reader is familiar with the basic concepts and results of the theory of formal languages, Petri nets and relations; for details we refer to [4,9,41] (formal languages, automata, computation), [6,10] (regulated rewriting systems), [42,43] (Petri nets), [23,24,44] (Petri net controlled grammars), and [33,34,45,46,47,48] (finitary relations). Though, in this section, we recall all necessary notions and notations that are important for understanding this paper.
Basic conventions: the inclusion is denoted by ⊆ and the strict (proper) inclusion is denoted by ⊂. The symbol ∅ denotes the empty set. The powerset of a set X is denoted by , while its cardinality is denoted by . An ordered sequence of elements is called a pair and denoted by . Two pairs and are equal iff and . Let be sets. The set of all pairs , where and , is called the Cartesian product of X and Y, and denoted by . Then, . A binary relation on sets is a subset of the Cartesian product .
Strings, Languages and Grammars
We first recall the fundamental concepts of the formal language theory such as an alphabet, a string and a language from [41]:
Definition 1.
An alphabet is a nonempty set of abstract symbols.
Definition 2.
A string (or a word) over an alphabet Σ is a finite sequence of symbols from Σ. The sequence of zero symbols is called the empty string, and denoted by λ. The set of all strings over Σ is denoted by . The set is denoted by .
Definition 3.
A subset of is called a language.
Definition 4.
The number of the occurrences of symbols in is called its length and denoted by . The number of occurrences of a symbol x in a string w is denoted by .
Example 1.
Let be an alphabet. Then, is a string over Σ where and , . We can notice that w belongs to , which is a language over Σ.
Next, we cite the definitions of context-free, matrix grammars and related notations which are more detailly given in [4,6].
Definition 5.
A context-free grammar is a quadruple where V and Σ are disjoint alphabets of nonterminal and terminal symbols, respectively, is the start symbol and is a finite set of (production) rules. Usually, a rule is written as . A rule of the form is called an erasing rule, and a rule of the form , where , is called terminal.
Definition 6.
Let be a context-free grammar. If , then G is called regular, and if , then it is called linear.
The families of regular, linear and context-free languages are denoted by , and , respectively.
Definition 7.
Let be a context-free grammar.
- The string directly derives , written as , if and only if there is a rule such that and .
- The reflexive and transitive closure of the relation ⇒ is denoted by .
- A derivation using the sequence of rules is denoted by or .
- The language generated by a grammar G is defined by .
Example 2.
where R contains the productions:
is a context-free grammar, and it generates the language L in Example 1.
Definition 8.
A matrix grammar is a quadruple , Σ, S, where are defined as for a context-free grammar, M is a finite set of matrices which are finite strings over a set of context-free rules (or finite sequences of context-free rules). The language generated by a matrix grammar G is defined by .
Example 3.
where M contains the matrices:
is a matrix grammar, and it generates the language .
The family of languages generated by matrix grammars is denoted by .
Lastly, we retrieve the notions of a Petri net, a context-free Petri net and a Petri net controlled grammar from [23,24,44].
Definition 9.
A Petri net is a construct where P and T are disjoint finite sets of places and transitions, respectively, is a set of directed arcs, is a weight function, where for all .
A Petri net can be represented by a bipartite directed graph with the node set where places are drawn as circles, transitions as boxes and arcs as arrows with labels or . If or , the label is omitted. A mapping is called a marking. For each place , gives the number of tokens in p.
Definition 10.
A context-free Petri net (in short, a cf Petri net) with respect to a context-free grammar is a tuple where
- (1)
- is a Petri net;
- (2)
- labeling functions and are bijections;
- (3)
- there is an arc from place p to transition t if and only if and . The weight of the arc is 1;
- (4)
- there is an arc from transition t to place p if and only if and where and . The weight of the arc is ;
- (5)
- the initial marking ι is defined by and for all .
The following example ([23]) explains the construction of a cf Petri net.
Example 4.
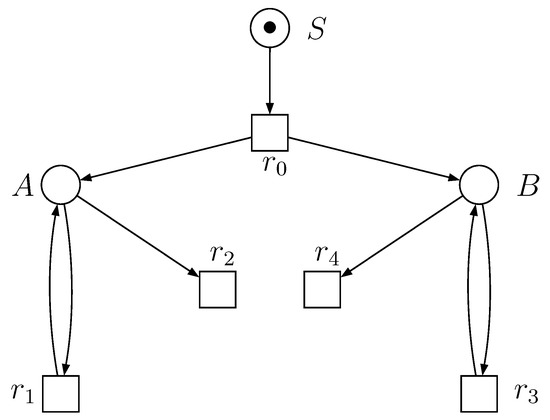
Let be a context-free grammar defined in Example 2. Figure 1 illustrates a cf Petri net N with respect to the grammar .
Figure 1.
A cf Petri net N associated with the grammar , where the places are labeled with the nonterminals and the transitions are labeled with the productions in one-to-one manner. Moreover, the input place of each transition corresponds to the left-hand side of the associated production and its output places correspond to the nonterminals in the right-hand side of the production. If a transition does not have output places, then the associated production is terminal.
Definition 11.
A Petri net controlled grammar is a tuple where V, Σ, S, R are defined as for a context-free grammar and the construct is a Petri net, is a labeling function and M is a set of final markings. The language generated by a Petri net controlled grammar G, denoted by , consists of all strings such that there is a derivation and an occurrence sequence which is successful for M such that .
The family of languages generated by Petri net controlled grammars is denoted by .
The hierarchical relationships of the language families defined above are summarized as follows.
Theorem 1.
The correctness of inclusions was first shown in [1,3]. The proof of the strict inclusion can be found in [41]. The equality was established in [23].
4. Binary Strings, Languages and Grammars
In this section, we define binary strings, languages and grammars by modifying the n-ary counterparts initially studied in [33,34].
Definition 12.
A pair of strings , is called an binary string over V and denoted by . The binary empty string is denoted by .
Definition 13.
A subset L of is called a binary language.
Definition 14.
The concatenation of binary strings and is defined as .
Definition 15.
For two binary languages , their
- union is defined as
- concatenation is defined as
Definition 16.
For , its Kleene star is defined as
where and , .
Definition 17.
A binary context-free grammar is a quadruple
where
- (1)
- , , are sets of nonterminal symbols,
- (2)
- , with , , are sets of terminal symbols,
- (3)
- is the start (initial) pair, and
- (4)
- R is a finite set nonempty set of binary productions (rules).A binary production is a pair where , , is either empty or it is a context-free production, i.e., .
Remark 1.
A binary production can be written as where , and if , , if . For production , to indicate its left-hand side and right-hand side, we also use notations and , i.e., and .
Remark 2.
In Definition 17, if each nonempty is regular production, then the grammar G is called regular and if each nonempty is linear production, then it is called linear.
Remark 3.
We say and are left and right grammars with respect to the binary grammar G, respectively, where
Definition 18.
Let G be a binary context-free grammar. Let be pairs in . We say that u directly derives v, written as , if there exist pairs and a production such that and . The reflexive and transitive closure of → is denoted by .
Definition 19.
The binary language generated by a binary context-free grammar G is defined as
Definition 20.
The left and right languages are defined as
i.e., the sets of left and right strings in all binary strings of , respectively.
Example 5.
Consider the binary grammar
where R consists of the following productions
It is not difficult to see that, after n steps, the first production produces the pair . Then in order to eliminate all s, we apply the second production n times, and terminate derivation with applying the third production, which generates the pair string . Thus, , and .
Example 6.
The grammar
where R consists of the productions
generates the language where the right language .
Example 6 illustrates that binary context-free grammars can generate non-context-free languages, which implies that binary context-free grammars are more powerful than the Chomskyan context-free grammars. Thus, binary context-free grammars can be used in studying non-context-free structures such as cross-serial dependencies appearing in natural and programming languages using “context-free” tools such as parsing (derivation) trees.
We denote the families of binary languages generated by binary grammars with left and right grammars of type by . We also denote the the families of the left and right languages generated by binary grammars by , .
5. Synchronized Forms for Binary Grammars
In a binary grammar, the derivation of a string in the left or right grammar can pause or stop while the other still continues because of the rules of the forms and . However, we show that the both first and second derivations by binary context-free grammars can be synchronized, i.e., in each derivation step, some pair of nonempty productions is applied and both derivations stop at the same time.
Definition 21.
A binary context-free (regular, linear) grammar G is called synchronized if it does not have any production of the form or .
Lemma 1.
For every binary context-free grammar, there exist an equivalent synchronized binary context-free grammar.
Proof.
Let be a binary context-free grammar. Let
We define the binary cf grammar where , , where X, and are new nonterminals, and
Then, the equality is obvious. □
The proof of Lemma 1 cannot be used for showing that there is also a synchronized form for a binary regular or linear grammar. The next lemma illustrates the existence of an equivalent synchronized form for any binary regular grammar too.
Lemma 2.
For every binary regular grammar, there exist an equivalent synchronized binary regular grammar.
Proof.
Let be a binary regular grammar. Let and
The proof of the lemma consists of two parts. First, we replace all binary productions of the form and with the productions and where E is a new nonterminal, and , . By this change, the early stop of one of derivations by the left and right grammars is prevented. Let
We set , and
and .
Second, in order to eliminate empty productions, we replace all binary production rules of the form and with the pairs of production rules , and , , respectively, where s are new nonterminals. Thus, we define the following sets of new productions:
where s are new nonterminal symbols introduced for each production or in . Let
and
We define the binary regular grammar as follows:
First, we show that . Consider a derivation
in G where
For a derivation step , , the following cases are possible:
Case 1: the right-hand side is obtained by applying a production from . Then, the same rule is also applied in the corresponding step in the simulating derivation of .
Case 2: the right-hand side is obtained by applying a production of the form or . Then, the production sequence or the production sequence is applied in the corresponding step in the simulating derivation of .
Case 3: the right-hand side is obtained by applying a rule of the form , or , . Then, the rule or is applied in the corresponding step in the simulating derivation in , and the derivation terminates with applying .
The inclusion is obvious:
(1) the application of a rule of the form , , or , , can be immediately replaced with the pair or , respectively;
(2) if a rule of the form or is applied at some derivation step, the only applicable pair of productions then is or , respectively, since is the unique for each pair of productions. Thus, the sequence of pairs of productions and or and are replaced with or , respectively. □
Using the same arguments of the proof of Lemma 2, one can show that the similar fact also holds for binary linear grammars.
Lemma 3.
For every binary linear grammar, there exist an equivalent synchronized binary linear grammar.
6. Generative Capacities of Binary Grammars
In this section, we discuss the generative capacities of binary regular, linear and context free grammars.
The following two lemmas immediately follows from the definitions of binary languages.
Lemma 4.
, .
Lemma 5.
Lemma 6.
Proof.
Let be a context-free (regular, linear) grammar. Then, we define the binary context-free (regular, linear) grammar by setting, for each production , the production in . Then, it is not difficult to see that . In the same way, we can also show that . □
Now we show that binary regular and linear grammars generate regular and linear languages, respectively.
Lemma 7.
Proof.
Let be a binary linear grammar. Without loss of generality, we can assume that the grammar G is synchronized. We set where , , are new nonterminals, and we define
Then, is a linear grammar, and is obvious. Hence, is linear, i.e., . □
Corollary 1.
Next, we show that binary context-free grammars are more powerful than Chomskyan context-free grammars.
Lemma 8.
.
Proof.
By Lemma 6, . Let us consider a binary context-free grammar where R consists of the following productions:
Any successful derivation starts with production . For each production sequence , , if the first production is applied, then, the only applicable production in the derivation is the second one. If after , production sequence is applied, then the derivation generates the binary string . Else, after some steps, the derivation results in , , by applying production sequences or/and , and then, it terminates by applying production sequence . Thus,
Since , we have the strict inclusion . □
Next, we show that binary context-free grammars are at least as powerful as matrix grammars.
Lemma 9.
Proof.
Let be a matrix grammar where M consists of matrices with , . We set the following sets of new nonterminals
We construct the following binary productions
- (1)
- the start production:
- (2)
- the matrix entry productions:
- (3)
- the matrix processing productions:where ,
- (4)
- the matrix exit productions:
- (5)
- the terminating production:
We define the binary context-free grammar where R consists of all productions (1)–(5) constructed above.
Claim 1: . Let
be a derivation in G. We construct the derivation in that simulates D. The derivation starts with the step:
Since, is the first matrix applied in derivation D, the next step in is
Furthermore,
By applying ,
we return X to the derivation, and then, we can continue the simulation of the application of the matrix in the same manner. Thus, simulates D, and .
Claim 2: . Any successfully terminating derivation in starts by applying production , followed by applying for some . Then only possible productions to be applied are matrix processing productions of the form (3). When the application of the productions in the currently active sequence starts, the productions of another sequence of the form (3) cannot be applied. In order to switch to another sequence of productions of the form (3), the corresponding production of the form (4) must be applied after finishing the application of all productions in the current sequence in the given order. To successfully terminate the derivation, the productions of the forms (4) and (5) must be applied. By construction, each sequence of productions of the form (3) simulates some matrix from G, any successful derivation in can be simulated by a successful derivation in G. Thus, . □
The lemma above shows that any matrix language can be generated by a binary grammar where one of its grammars is regular and the other is context-free. Here, the natural question arises whether there is a binary grammar with both grammars are context-free that generates a non-matrix language or not. Next lemma shows that binary context-free grammars can only generate matrix languages even if their both grammars are context-free.
Lemma 10.
Proof.
Let be a binary context-free grammar. Without loss of generality, we assume that G is in a synchronized form. Let . The proof idea is as follows: First, we will construct a context-free Petri net N with respect to G. Second, we define a Petri net controlled grammar where the underlying right grammar is controlled by the Petri net N. Then we show that , i.e., .
Part 1: We construct the cf Petri net with respect to the nonterminals of the left grammar and productions of the grammar G by setting its components in the following way:
- is a Petri net;
- the labeling functions and are bijections;
- there is an arc from place p to transition t if and only if and . The weight of the arc is 1;
- there is an arc from transition t to place p if and only if and where and . The weight of the arc is ;
- the initial marking is defined by and for all .
Part 2: Using the right grammar , we define the PN controlled grammar where is the cf Petri net defined above, is a labeling function and M is a set of final markings. We set and if and only if .
Part 3: Now we show that . Let
be a derivation in G where . We show that the derivation D can be simulated by the derivation in the grammar constructed as follows. starts with , and by definition of N, , thus, transition is enabled. In the first step, we obtain
When transition occurs the place in N corresponding to each nonterminal in receive the tokens whose number is equal to the number of the occurrence of the nonterminal in .
Suppose that for some , we constructed the first i steps of the derivation :
with where , which corresponds to the first i steps of D. By definition, and . When transition fires, a token moves from the input place of , that is labeled by the left-hand side of , to its output places, that are labeled by the nonterminals occurring in the right-hand side of . Thus, these nonterminals are also occur in . The next step in D occurs by applying the pair :
Since production is applicable in the current step, its left-hand side occurs in . It follows that the transition , , can fire. Consequently, we choose the production with , in , and obtain
The last step in D results in that is obtained by applying the pair . Then, we choose with in . Since , i.e., it does not contain nonterminals, all places of N have no tokens. Thus, . It shows that .
Let
with . By definition, we immediately obtain for some , . Then, we can construct the derivation D in the grammar G
which shows that . Thus, . By Theorem 1, □.
We summarize the results obtained above in the following theorem.
Theorem 2.
7. Conclusions
In this paper, we redefined binary grammars as mutually controlled grammars where either grammar in a relation generates own language imposing restriction to the other.
Though binary grammars are asynchronous systems by their definitions, we showed that they can also work in synchronized mode (Lemmas 1–3), i.e., the both grammars in a binary relation generate strings with derivations where the grammars apply some productions in each step, and stop at the same time. This feature of binary grammars allows using one grammar in a relation as a regulation mechanism for the other.
We have studied the generative capacity of binary context-free grammars, and showed that binary regular and linear grammars have the same power as their Chomskyan alternatives, i.e., traditional regular and linear grammars, respectively (Lemmas 6 and 7 and Corollary 1). On the other hand, we have proved that binary context-free grammars are much more powerful than traditional context-free grammars (Lemma 8), that is, they generate all matrix languages even if binary grammars consist of regular and context-free pairs (Lemma 9). Moreover, we established that using context-free grammars as the components of relations does not increase the computational power of binary context-free grammars, i.e., they remain equivalent to matrix grammars (Lemma 10). Using the inclusion hierarchies in Theorem 1 and the results of the paper, we obtained the comparative hierarchy for binary regular, linear and context-free grammars (Theorem 2). We have also illustrated that binary grammars have practical significance: Example 6, and Lemma 8 show that cross-serial dependencies such as duplication and multiple agreements—non-context-free syntactical structures appearing in natural and programming languages—can be expressed with binary grammars.
Here, we emphasize that ternary or higher degree relational context-free grammars are more powerful than binary ones, and can be used in modeling “nested” cross-serial dependencies. Let us assume that a ternary context-free grammar is defined similarly to binary grammars. Then, the reader can convince himself that the following language
the language of nested mutual agreements, can be generated by a ternary context-free grammar
where R consists of the following tuples of productions:
The detailed study of higher degree relational grammars as mutually controlled grammars will be the topic of our next investigation.
Author Contributions
Conceptualization, S.T. and A.A.A. (Ali Amer Alwan); methodology, S.T. and R.A.; validation, A.A.A. (Ali Abd Almisreb) and Y.G.; formal analysis, A.A.A. (Ali Abd Almisreb) and Y.G.; investigation, S.T. and R.A.; writing—original draft preparation, S.T. and R.A.; writing—review and editing, S.T. and A.A.A. (Ali Amer Alwan); supervision, S.T. All authors have read and agreed to the published version of the manuscript.
Funding
This work has been supported by the United Arab Emirates University Start-Up Grant 31T137.
Acknowledgments
We would like to thank the anonymous reviewers for their valuable comments and useful remarks about this paper.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study and in the writing of the manuscript, or in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| CF | context-free |
| REG | regular |
| LIN | linear |
| MAT | matrix |
References
- Chomsky, N. Three models for the description of languages. IRE Trans. Inf. Theory 1956, 2, 113–124. [Google Scholar] [CrossRef]
- Chomsky, N. Syntactic Structure; Mouton: Gravenhage, The Netherland, 1957. [Google Scholar]
- Chomsky, N. On certain formal properties of grammars. Inf. Control 1959, 2, 137–167. [Google Scholar] [CrossRef]
- Hopcroft, J.; Motwani, R.; Ullman, J. Introduction to Automata Theory, Languages, and Computation; Pearson: London, UK, 2007. [Google Scholar]
- Rozenberg, G.; Salomaa, A. (Eds.) Handbook of Formal Languages; Springer: Berlin/Heidelberg, Germany, 1997; Volume 1–3. [Google Scholar]
- Dassow, J.; Păun, G. Regulated Rewriting in Formal Language Theory; Springer: Berlin/Heidelberg, Germany, 1989. [Google Scholar]
- Pǎun, G.; Rozenberg, G.; Salomaa, A. DNA Computing. New Computing Paradigms; Springer: Berlin/Heidelberg, Germany, 1998. [Google Scholar]
- Meduna, A.; Soukup, O. Modern Language Models and Computation. Theory with Applications; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Sipser, M. Introduction to the Theory of Computation; Cengage Learning: Boston, MA, USA, 2013. [Google Scholar]
- Meduna, A.; Zemek, P. Regulated Grammars and Automata; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Meduna, A.; Kopeček, T. Simple-Semi-Conditional Versions of Matrix Grammars with a Reduced Regulated Mechanism. Comput. Inform. 2004, 23, 287–302. [Google Scholar]
- Abraham, A. Some questions of phrase-structure grammars. Comput. Linguist. 1965, 4, 61–70. [Google Scholar] [CrossRef]
- Cremers, A.; Mayer, O. On vector languages. J. Comp. Syst. Sci. 1974, 8, 158–166. [Google Scholar] [CrossRef][Green Version]
- Ginsburg, S.; Spanier, E. Control sets on grammars. Math. Syst. Theory 1968, 2, 159–177. [Google Scholar] [CrossRef]
- Rozenkrantz, D. Programmed grammars and classes of formal languages. J. ACM 1969, 16, 107–131. [Google Scholar] [CrossRef]
- Pǎun, G. A new generative device: Valence grammars. Rev. Roum. Math. Pures Appl. 1980, 25, 911–924. [Google Scholar]
- Cremers, A.; Maurer, H.; Mayer, O. A note on leftmost restricted random context grammars. Inform. Proc. Lett. 1973, 2, 31–33. [Google Scholar] [CrossRef]
- Fris, I. Grammars with partial ordering of the rules. Inform. Control 1968, 12, 415–425. [Google Scholar] [CrossRef][Green Version]
- Kelemen, J. Conditional grammars: Motivations, definitions and some properties. In Proc. Conf. Automata, Languages and Mathematical Sciences; Peak, I., Szep, J., Eds.; Salgótarján, Hungary, 1984; pp. 110–123. [Google Scholar]
- Aho, A. Indexed grammars. An extension of context-free grammars. J. ACM 1968, 15, 647–671. [Google Scholar] [CrossRef]
- Wood, D. Bicolored Digraph Grammar Systems. RAIRO Inform. Thérique et Appl./Theor. Inform. Appl. 1973, 1, 145–150. [Google Scholar] [CrossRef]
- Wood, D. A Note on Bicolored Digraph Grammar Systems. IJCM 1973, 3, 301–308. [Google Scholar]
- Dassow, J.; Turaev, S. Petri net controlled grammars: The power of labeling and final markings. Rom. J. Inf. Sci. Technol. 2009, 12, 191–207. [Google Scholar]
- Dassow, J.; Turaev, S. Petri net controlled grammars: The case of special Petri nets. J. Univers. Comput. Sci. 2009, 15, 2808–2835. [Google Scholar]
- Prusinkiewicz, P.; Hanan, J. Lindenmayer Systems, Fractals, and Plants; Lecture Notes in Biomathematics; Springer: Berlin, Germany, 1980; Volume 79. [Google Scholar]
- Rajlich, V. Absolutely parallel grammars and two-way deterministic finite state transducers. J. Comput. Syst. Sci. 1972, 6, 324–342. [Google Scholar] [CrossRef]
- Siromoney, R.; Krithivasan, K. Parallel context-free languages. Inform. Control 1974, 24, 155–162. [Google Scholar] [CrossRef]
- Levitina, M. On some grammars with global productions. NTI Ser. 1972, 2, 32–36. [Google Scholar]
- Greibach, S.; Hopcroft, J. Scattered context grammars. J. Comput. Syst. Sci. 1969, 3, 232–247. [Google Scholar] [CrossRef]
- Mavlankulov, G.; Othman, M.; Turaev, S.; Selamat, M.; Zhumabayeva, L.; Zhukabayeva, T. Concurrently Controlled Grammars. Kybernetika 2018, 54, 748–764. [Google Scholar] [CrossRef]
- Păun, G.; Santean, L. Parallel communicating grammar systems: The regular case. Ann. Univ. Buc. Ser. Mat.-Inform. 1989, 37, 55–63. [Google Scholar]
- Csuhaj-Varjú, E.; Dassow, J.; Kelemen, J.; Păun, G. Grammar Systems: A Grammatical Approach to Distribution and Cooperation; Gordon and Beach Science Publishers: New York, NY, USA, 1994. [Google Scholar]
- Král, J. On Multiple Grammars. Kybernetika 1969, 5, 60–85. [Google Scholar]
- Čulík II, K. n-ary Grammars and the Description of Mapping of Languages. Kybernetika 1970, 6, 99–117. [Google Scholar]
- Bellert, I. Relational Phrase Structure Grammar and Its Tentative Applications. Inf. Control 1965, 8, 503–530. [Google Scholar] [CrossRef]
- Bellert, I. Relational Phrase Structure Grammar Applied to Mohawk Constructions. Kybernetika 1966, 3, 264–273. [Google Scholar]
- Crimi, C.; Guercio, A.; Nota, G.; Pacini, G.; Tortora, G.; Tucci, M. Relation Grammars and their Application to Multidimensional Languages. J. Vis. Lang. Comput. 1991, 4, 333–346. [Google Scholar] [CrossRef]
- Wittenburg, K. Earley-Style Parsing for Relational Grammars. In Proceedings of the IEEE Workshop on Visual Languages, Seattle, WA, USA, 15–18 September 1992; pp. 192–199. [Google Scholar]
- Wittenburg, K.; Weitzman, L. Relational Grammars: Theory and Practice in a Visual Language Interface for Process Modeling. In Visual Language Theory; Marriott, K., Meyer, B., Eds.; Springer Science & Business Media: New York, NY, USA, 1998; pp. 193–217. [Google Scholar]
- Johnson, D. On Relational Constraints on Grammars. In Grammatical Relations; Cole, P., Sadock, J., Eds.; BRILL: Leiden, The Netherlands, 2020; pp. 151–178. [Google Scholar]
- Martín-Vide, C.; Mitrana, V.; Păun, G. (Eds.) Formal Languages and Applications; Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Baumgarten, B. Petri-Netze. Grundlagen und Anwendungen; Wissensschaftverlag: Mannheim, Germany, 1990. [Google Scholar]
- Reisig, W.; Rozenberg, G. (Eds.) Lectures on Petri Nets I: Basic Models; Springer: Berlin, Germany, 1997; Volume 1441. [Google Scholar]
- Dassow, J.; Turaev, S. Petri net controlled grammars with a bounded number of additional places. Acta Cybernetica 2009, 19, 609–634. [Google Scholar]
- Novák, V.; Novotný, M. Binary and Ternary Relations. Math. Bohem. 1992, 117, 283–292. [Google Scholar]
- Novák, V.; Novotný, M. Pseudodimension of Relational Structures. Czechoslov. Math. J. 1999, 49, 541–560. [Google Scholar]
- Cristea, I.; Ştefănescu, M. Hypergroups and n-ary Relations. Eur. J. Comb. 2010, 31, 780–789. [Google Scholar] [CrossRef]
- Chaisansuk, N.; Leeratanavalee, S. Some Properties on the Powers of n-ary Relational Systems. Novi Sad J. Math. 2013, 43, 191–199. [Google Scholar]
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).