Image-Level Structure Recognition Using Image Features, Templates, and Ensemble of Classifiers

Abstract
1. Introduction
- Utilizing five different features for the study of the image-level structure recognition.
- Performing feature-level fusion for each sub-region (e.g., sky or ground) of an image and concatenating these features into a single set for a whole image.
- Using individual classifiers for each template outcome and, later on, fusing output classifiers at the decision level to predict a class label.
- Results exhibiting that the feature-level fusion and decision-level fusion approaches improve the recognition accuracy significantly.
2. Related Work
3. Background
3.1. Image Features
3.1.1. Parameters of Weibull Distribution
3.1.2. Color Features
3.1.3. Histogram of Oriented Gradients (HOG)
3.1.4. Local Binary Pattern and Entropy Value (LBP-E)
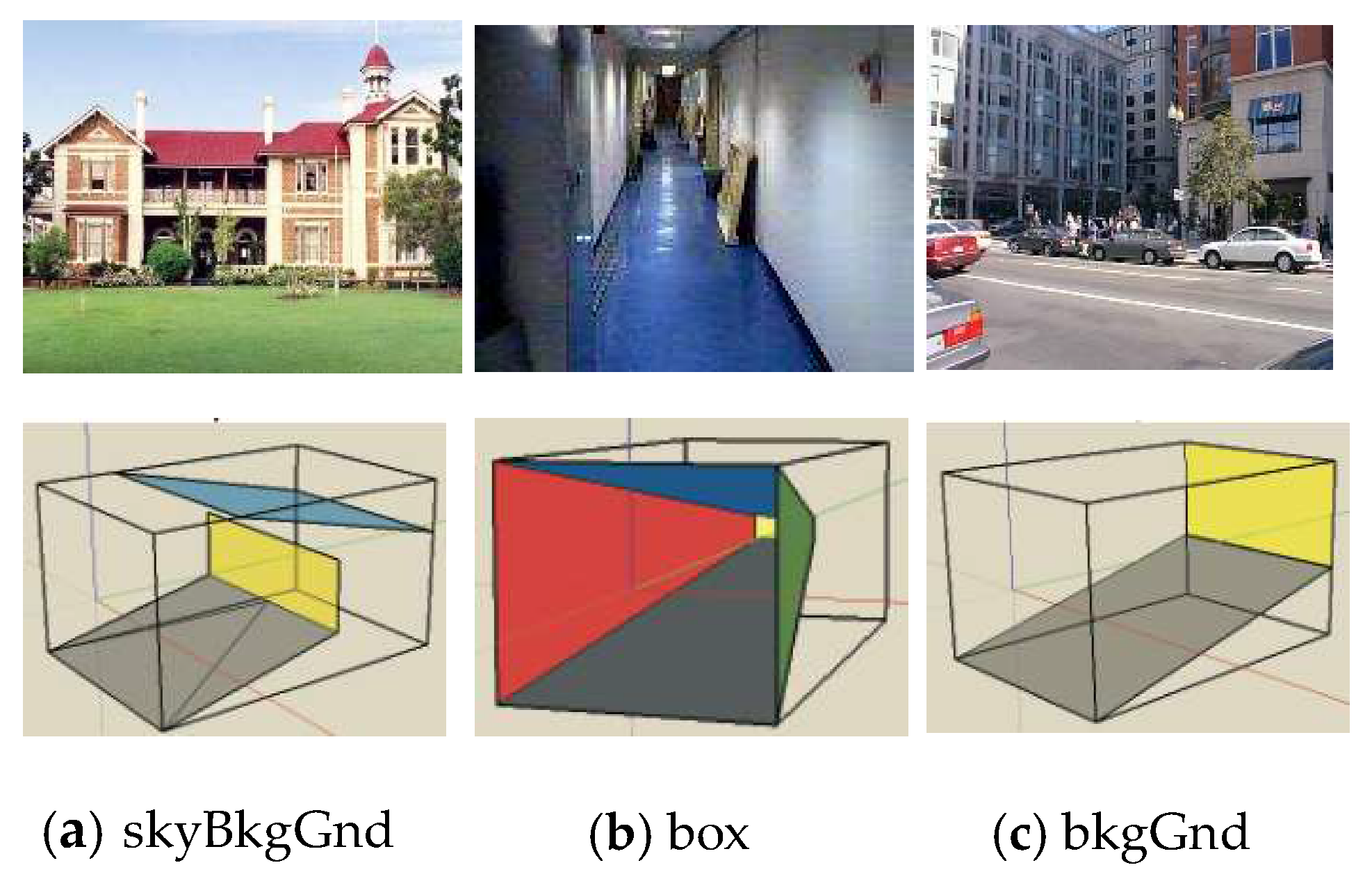
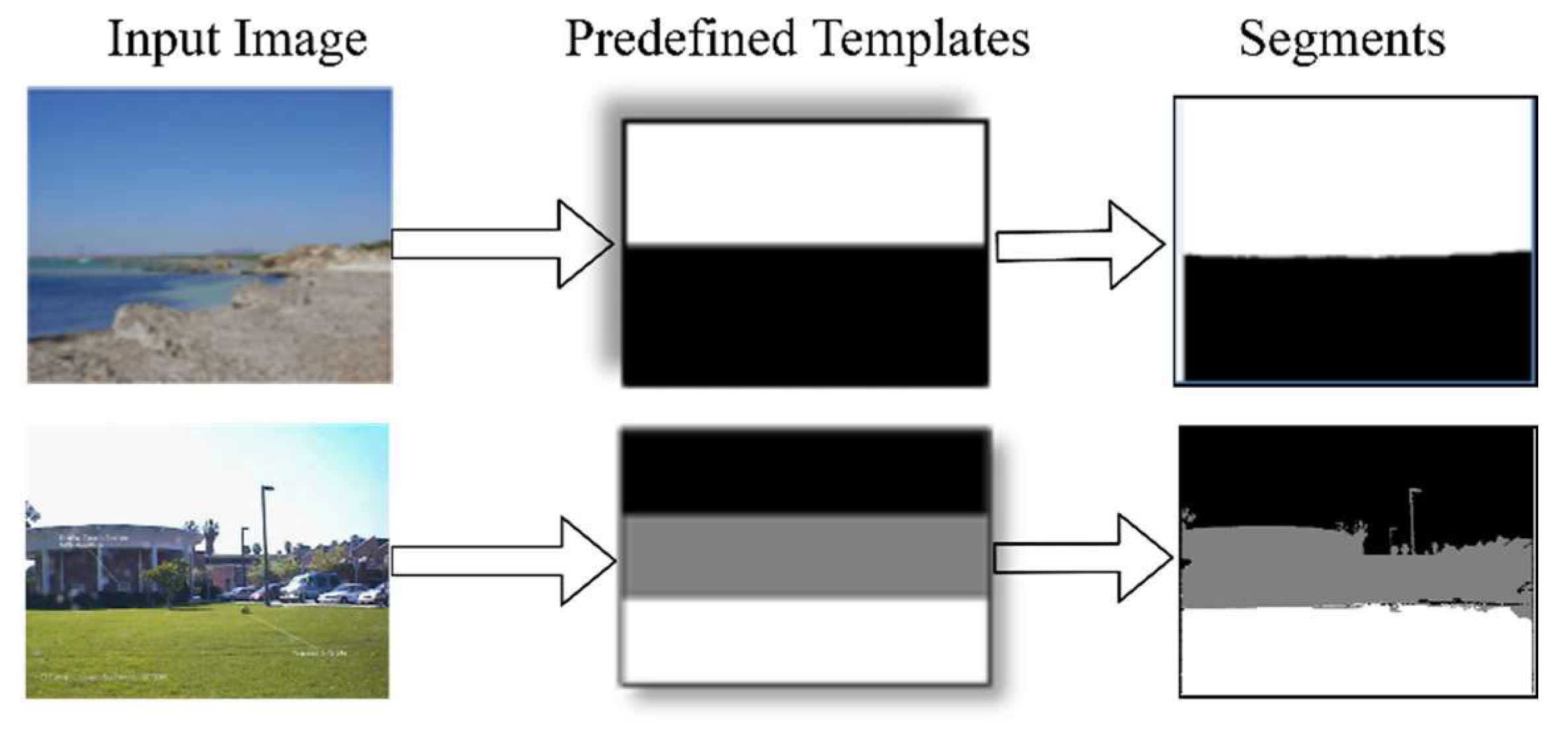
3.2. Template-Based Segmentation
3.3. Classifier, Ensemble of Classifiers, and Their Performance Measures
4. Proposed Method of Image-Level Structure Recognition
| Algorithm 1. Proposed method of stage recognition. |
| Input: T Templates, N training images, Ɲ total number of images, S classes, YN training labels, YM testing labels Output: Acc, Pr, Re, F-score |
| // Template-based segmentation and feature extraction 1. for j=1:Ɲ do // for each image 2. for t=1:T do 3. // according to Algorithm 2 4. = // feature vector for image , t is a certain template 5. end for 6. end for // Training & testing 7. for t=1:T do 8. // according to Equation (15), N is a number of training samples. 9. end for 10. for t=1:T do 11. //where is used to train t-th classifier. 12. end for // Testing (prediction) 13. for j=N+1: Ɲ do // loop on test images 14. for t=1:T do //loop on classifiers 15. is S-dimensional score vector for an image j. 16. end for //t 17. end for//j // Classifiers combination 18. for j=N+1: Ɲ do // M test images 19. = Sum_rule (), fusion of T scores 20. end for//j //Performance measures 21. [Acc, Pr, Re, F-score]=Calculate_Measures (l′, YM). // YM is a true label end algorithm |
4.1. Template-Based Segmentation and Feature Extraction Procedures
4.1.1. Template-Based Segmentation Procedure Description
4.1.2. Feature Extraction Procedure Description
| Algorithm 2. Template-based segmentation. |
| Input: TS(H,W) template, I(H,W) image |
| Output: Sg(H,W) segmented image Initialization: Sg(H,W) = 0, M’(H,W) = 0, δ(H, W) = 0 is temporary matrix |
| 1. s = obtain number_of_components(TS); 2. for sk = 1 to s do, 3. //initialize by zero 4. for i=1 to H do //loop on rows 5. for j=1 to W do //loop on columns 6. then //check that 7. //if yes, store it in 8. end if 9. end for//j 10. end for//i //find the x and y coordinate of the center point of the sk-th component of TS 11. 12. 13. 14. for i=1 to H do //loop on rows 15. for j=1 to W do //loop on columns 16. then //M’(i, j) indicates part of the segment, 0 otherwise. 17. 18. end if 19. end for//j 20. end for//i 21. end for//sk 22. for i=1 to H do, 23. for j=1 to W do, 24. if ( then //if pixel is not a part of any segment //find the nearest segment c, using Euclidean distance for s components, . 25. 26. ; 27. end if 28. end for//end i 29. end for//end j 30. Return Sg//return the template-based segmentation |
4.2. Training and Testing of Ensemble of Classifiers
4.3. Fusion of the Ensemble of Classifiers
5. Implementation and Experiments
5.1. Implementation Details
5.2. Dataset 1: Stage Dataset
5.2.1. Experiments and Results for Stage Dataset
5.2.2. Comparison with State-of-the-Art Methods
5.3. Dataset 2: 15-Scene Image Dataset
5.3.1. Experiments and Results for 15-Scene Image Dataset
5.3.2. Comparison with State-of-the-Art Methods for 15-Scene Image Dataset
6. Discussion and Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Biederman, I. Perceiving real-world scenes. Science 1972, 177, 77–80. [Google Scholar] [CrossRef] [PubMed]
- Thorpe, S.; Fize, D.; Marlot, C. Speed of processing in the human visual system. Nature 1996, 6582, 520–522. [Google Scholar] [CrossRef] [PubMed]
- Richards, W.; Jepson, A.; Feldman, J. Priors. Preferences and categorical percepts. In Perception as Bayesian Inference; David, C.K., Whitman, R., Eds.; Cambridge University Press: Cambridge, England, 1996; pp. 93–122. [Google Scholar]
- Nedovic, V.; Smeulders, A.W.; Redert, A.; Geusebroek, J.M. Stages as models of scene geometry. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 9, 1673–1687. [Google Scholar] [CrossRef]
- Lou, Z.; Gevers, T.; Hu, N. Extracting 3d layout from a single image using global image structures. IEEE Trans. Image Proc. 2015, 24, 3098–3108. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Geusebroek, J.-M.; Smeulders, A.W.M. A six-stimulus theory for stochastic texture. Int. J. Comput. Vis. 2005, 62, 7–16. [Google Scholar] [CrossRef]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 2169–2178. [Google Scholar]
- Sanchez, J.; Perronnin, F.; Mensink, T.; Verbeek, J. Image classification with the fisher vector: Theory and practice. Int. J. Comput. Vision. 2013, 105, 222–245. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Kai, L.; Li, F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 million image database for scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1452–1464. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.E.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Liu, S.; Deng, W. Very deep convolutional neural network based image classification using small training sample size. In Proceedings of the 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 730–734. [Google Scholar]
- Ojala, T.; Pietik, M.; Inen, M.T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Pietikäinen, M.; Zhao, G. Two Decades of Local Binary Patterns: A Survey. In Advances in Independent Component Analysis and Learning Machines; Academic Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Chan, T.F.; Vese, L.A. Active contours without edges. IEEE Trans. Image Proc. 2001, 10, 266–277. [Google Scholar] [CrossRef] [PubMed]
- Kittler, J.; Hatef, M.; Duin, R.P.W.; Matas, J. On combining classifiers. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 226–239. [Google Scholar] [CrossRef]
- Mohandes, M.; Deriche, M.; Aliyu, S.O. Classifiers Combination Techniques: A comprehensive review. IEEE Access. 2018, 6, 19626–19639. [Google Scholar] [CrossRef]
- Tulyakov, S.; Jaeger, S.; Govindaraju, V.; Doermann, D. Review of classifier combination methods. In Machine Learning in Document Analysis and Recognition; Springer: Berlin/Heidelberg, Germany, 2008; pp. 361–386. [Google Scholar]
- Snelick, R.; Uludag, U.; Mink, A.; Indovina, M.; Jain, A. Large-scale evaluation of multimodal biometric authentication using state-of-the-art systems. IEEE Trans. Pattern Anal. Mach. Intel. 2005, 27, 450–455. [Google Scholar] [CrossRef]
- Zafar, B.; Ashraf, R.; Ali, N.; Ahmed, M.; Jabbar, S.; Chatzichristofis, S.A. Image classification by addition of spatial information based on histograms of orthogonal vectors. PLoS ONE 2018, 13, e0198175. [Google Scholar] [CrossRef] [PubMed]
- Oliva, A.; Torralba, A. Modeling the shape of the scene: A holistic representation of the spatial envelope. Int. J. Comput. Vis. 2001, 42, 145–175. [Google Scholar] [CrossRef]
- Li, F.-F.; Perona, P. A bayesian hierarchical model for learning natural scene categories. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 524–531. [Google Scholar]
- Hoiem, D.; Efros, A.A.; Hebert, M. Recovering surface layout from an image. Int. J. Comput. Vis. 2007, 75, 151–172. [Google Scholar] [CrossRef]
- Xiao, J.; Hays, J.; Ehinger, K.A.; Oliva, A.; Torralba, A. SUN database: Large-scale scene recognition from abbey to zoo. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3485–3492. [Google Scholar]
- Ali, N.; Zafar, B.; Riaz, F.; Dar, S.H.; Ratyal, N.I.; Bajwa, K.B.; Iqbal, M.K.; Sajid, M. A hybrid geometric spatial image representation for scene classification. PLoS ONE 2018, 13, e0203339. [Google Scholar] [CrossRef]
- Zafar, B.; Ashraf, R.; Ali, N.; Ahmed, M.; Jabbar, S.; Naseer, K.; Ahmad, A.; Jeon, G. Intelligent image classification-based on spatial weighted histograms of concentric circles. Comput. Sci. Inf. Syst. 2018, 15, 615–633. [Google Scholar] [CrossRef]
- Zhang, W.; Tang, P.; Zhao, L. Remote sensing image scene classification using CNN-CapsNet. Remote Sens. 2019, 11, 494. [Google Scholar] [CrossRef]
- Tomasi, C. Histograms of Oriented Gradients. (Computer Vision Sampler). 2012, pp. 1–6. Available online: https://www2.cs.duke.edu/courses/spring19/compsci527/notes/hog.pdf (accessed on 11 May 2020).
- Carreira, J.; Sminchisescu, C. CPMC: Automatic object segmentation using constrained parametric min-cuts. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1312–1328. [Google Scholar] [CrossRef]
- Masi, I.; Wu, Y.; Hassner, T.; Natarajan, P. Deep face recognition: A survey. In Proceedings of the 2018 31st SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Parana, Brazil, 29 October–1 November 2018; pp. 471–478. [Google Scholar]
- Patalas, M.; Halikowski, D. A model for generating workplace procedures using a CNN-SVM architecture. Symmetry 2019, 11, 1151. [Google Scholar] [CrossRef]
- Kim, S.; Kavuri, S.; Lee, M. Deep network with support vector machines. In International Conference on Neural Information Processing; Springer: Berlin/Heidelberg, Germany, 2013; pp. 458–465. [Google Scholar]
- LeCun, Y.; Cortes, C.; Burges, C.J. MNIST Handwritten Digit Database. 2010. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 11 May 2020).
- Weijer, J.V.D.; Gevers, T.; Gijsenij, A. Edge-based color constancy. IEEE Trans. Image Process. 2007, 16, 2207–2214. [Google Scholar] [CrossRef] [PubMed]
- Gonzalez, R.C.; Woods, R.E.; Eddins, S.L. Digital Image Processing Using MATLAB, 2nd ed.; Prentice-Hall, Inc.: Chennai, Tamil Nadu, India, 2003. [Google Scholar]
- Ortes, F.; Karabulut, D.; Arslan, Y.Z. General perspectives on electromyography signal features and classifiers used for control of human arm prosthetics. In Advanced Methodologies and Technologies in Engineering and Environmental Science; IGI Global: Hershey, PA, USA, 2019; pp. 1–17. [Google Scholar]
- Urbanowicz, R.J.; Moore, J.H. Learning classifier systems: A complete introduction, review, and roadmap. J. Artif. Evol. Appl. 2009. [Google Scholar] [CrossRef]
- Ballabio, D.; Grisoni, F.; Todeschini, R. Multivariate comparison of classification performance measures. Chemom. Intell. Lab. Syst. 2018, 174, 33–44. [Google Scholar] [CrossRef]
- Aghdam, H.H.; Heravi, E.J. Guide to Convolutional Neural Networks: A Practical Application to Traffic-Sign Detection and Classification; Springer: Berlin/Heidelberg, Germany, 2018; pp. 1–303. [Google Scholar]
- Lee, C.; Badrinarayanan, V.; Malisiewicz, T.; Rabinovich, A. Roomnet: End-to-end room layout estimation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4875–4884. [Google Scholar]
- Hoiem, D.; Efros, A.A.; Hebert, M. Geometric context from a single image. In Proceedings of the 10th IEEE International Conference on Computer Vision (ICCV’05), Beijing, China, 17–21 October 2005; pp. 654–661. [Google Scholar]
- Hoiem, D.; Efros, A.A.; Hebert, M. Putting objects in perspective. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; pp. 2137–2144. [Google Scholar]
- Hedau, V.; Hoiem, D.; Forsyth, D. Recovering the spatial layout of cluttered rooms. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 1849–1856. [Google Scholar]
- Winn, J.; Criminisi, A.; Minka, T. Object categorization by learned universal visual dictionary. In Proceedings of the 10th IEEE International Conference on Computer Vision (ICCV’05), Beijing, China, 17–21 October 2005; Volume 1, pp. 1800–1807. [Google Scholar]
- Gettyimages. Available online: https://www.Gettyimages.Com/Photos/ (accessed on 4 March 2019).
- Weijer, J.V.D.; Gevers, T.; Gijsenij, A. Available online: https://Staff.Fnwi.Uva.Nl/Th.Gevers/Software.Html (accessed on 10 March 2019).
- Mark Geusebroek, J.; Smeulders, A.W.M.; Weijer, J.V.D. Available online: https://Ivi.Fnwi.Uva.Nl/Isis/Publications/Bibtexbrowser.Php?Key=Geusebroektip2003&Bib=All.Bib (accessed on 12 March 2019).
- Mensink, T. Available online: https://Github.Com/Tmensink/Fvkit (accessed on 11 May 2019).
- Wang, P.; Zhang, X.; Hao, Y. A method combining CNN and ELM for feature extraction and classification of sar image. J. Sens. 2019. [Google Scholar] [CrossRef]
- Huang, G.B.; Bai, Z.; Kasun, L.L.C.; Vong, C.M. Local receptive fields based extreme learning machine. IEEE Comp. Intell. Mag. May 2015, 10, 18–29. [Google Scholar] [CrossRef]
- Lin, G.; Fan, C.; Zhu, H.; Miu, Y.; Kang, X. Visual feature coding based on heterogeneous structure fusion for image classification. Inf. Fusion 2017, 36, 275–283. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. of Features/Image | Feature Descriptors | Average Accuracy of Stage Recognition (%) | ||
|---|---|---|---|---|
| SVM Linear | SVM Quad. | SVM Gaussian | ||
| 64 | Weibull Dist. (W) | 49.70 | 53.71 | 51.24 |
| 80 | Atm. Scattering (A) | 48.61 | 50.88 | 50.60 |
| 128 | Pres. Line (P) | 43.39 | 46.82 | 46.13 |
| 144 | HOG | 58.88 | 62.28 | 59.60 |
| 48 | HSV | 48.61 | 54.31 | 52.87 |
| 96 | LBP-E | 56.52 | 58.63 | 57.61 |
| 512 | Gist [24] | 61.61 | 63.71 | 61.01 |
| 144 | W + A | 55.89 | 60.19 | 58.20 |
| 209 | P + A | 54.30 | 57.22 | 54.52 |
| 208 | W + HOG | 60.14 | 65.10 | 61.54 |
| 304 | HOG + RGB + HSV + W | 62.73 | 66.72 | 64.43 |
| 336 | HOG + HSV + RGB + LBP-E | 64.42 | 68.51 | 65.82 |
| 400 | HOG + HSV + RGB + W + LBP-E | 65.01 | 69.50 | 66.43 |
| 912 | HOG + HSV + RGB + W + LBP-E + Gist | 65.60 | 69.80 | 65.34 |
| No. of Features | Methods | Template Number | Accuracy of Stages (%) |
|---|---|---|---|
| 400 | HOG + HSV + RGB + W + LBP-E | (a) | 68.59 |
| (b) | 68.17 | ||
| (c) | 66.25 | ||
| (d) | 67.17 | ||
| (e) | 66.58 | ||
| (f) | 69.50 | ||
| (g) | 68.59 | ||
| (h) | 69.01 | ||
| 304 | HOG + HSV + RGB + W | (a)–(f) | 77.49 |
| 304 | HOG + HSV + RGB + W | (a)–(h) | 79.48 |
| 400 | HOG + HSV + RGB + W + LBP-E | (a)–(f) | 80.40 |
| 400 | HOG + HSV + RGB + W + LBP-E | (a)–(h) | 82.50 |
| Row # | No. of Features | Method [Reference] | SVM (Kernel) | Acc % | Pr % | Re % | F-Score % | Training + Testing Time (s) |
|---|---|---|---|---|---|---|---|---|
| 1 | 512 | Gist [24] | Quad. | 63.71 | 69.41 | 52.02 | 55.09 | 16.03 |
| 2 | 992 | Hoiem et al. [26] | Quad. | 64.70 | 66.81 | 51.63 | 55.74 | 76.75 |
| 3 | 208 | Nedovic et al. [4] (P + A) | Gauss. | 60.29 | 58.70 | 46.78 | 50.17 | 13.89 |
| 4 | 144 | Nedovic et al. [4] (W + A) | Gauss. | 59.80 | 59.11 | 45.85 | 49.47 | 13.44 |
| 5 | 3072 | Sánchez et al. [9] | Quad. | 72.40 | 73.4 | 59.90 | 63.61 | 68.45 |
| 6 | 400 | Proposed method | Quad. | 82.50 | 85.95 | 68.24 | 71.60 | 320.29 |
| Row# | Method | Acc % | Pr % | Re % | F-Score % | Training Time (s) | Testing Time (s) | Fusion Time (s) | Total Time (s) |
|---|---|---|---|---|---|---|---|---|---|
| 1 | GoogLeNet [12] | 78.93 | 81.39 | 72.75 | 74.88 | 11,518 | 46.31 | - | 11,564.31 |
| 2 | GoogLeNet365 [12] | 82.02 | 79.36 | 75.24 | 75.66 | 13,324 | 47.32 | - | 13,371.32 |
| 3 | ResNet-50 [13] | 82.23 | 79.49 | 77.22 | 76.14 | 30,099 | 37.07 | - | 30,136.07 |
| 4 | AlexNet [14] | 78.93 | 80.10 | 69.97 | 73.34 | 5760 | 38.70 | - | 5798.70 |
| 5 | VGG-16 [15] | 79.75 | 77.52 | 75.78 | 75.55 | 12,934 | 42.54 | - | 12,976.54 |
| 6 | CNN + SVM [34,35] | 80.58 | 83.48 | 75.24 | 76.24 | 22.72 | 10.16 | - | 32.88 |
| 7 | CNN + ELM [52] | 76.86 | 70.32 | 81.43 | 73.45 | 22.41 | 0.51 | - | 22.92 |
| 8 | Proposed method | 86.25 | 86.91 | 75.32 | 77.00 | 314.60 | 2.22 | 0.028 | 316.85 |
| Pred. Templates | No. of Features/Image | Acc. % | Pr % | Re % | F-Score % | Avg. Time of Training (s) | Avg. Time of Testing + Fusion (s) |
|---|---|---|---|---|---|---|---|
| (a) | 400 | 80.85 | 79.96 | 79.61 | 79.69 | 486.61 | |
| (b) | 79.40 | 79.10 | 77.94 | 78.36 | |||
| (c) | 78.80 | 78.41 | 77.33 | 77.72 | |||
| (d) | 79.55 | 78.33 | 78.33 | 78.53 | 13.71 | ||
| (e) | 79.30 | 77.90 | 77.99 | 77.84 | |||
| (f) | 82.94 | 82.62 | 82.07 | 82.28 | |||
| (g) | 80.07 | 79.28 | 79.01 | 79.05 | |||
| (h) | 78.77 | 77.36 | 77.16 | 77.20 | |||
| Majority vote((a)–(h)) | 86.46 | 86.19 | 85.84 | 85.96 | - | 109.88 | |
| Max rule((a)–(h)) | 89.36 | 89.32 | 95.41 | 90.74 | - | 110.40 | |
| Sum rule((a)–(h)) | 92.58 | 92.59 | 95.96 | 93.19 | - | 110.48 |
| Row# | Methods | Accuracy% |
|---|---|---|
| 1 | Zafar et al. [23] (OVH) | 87.07 |
| 2 | Lin et al. [54] (LVFC-HSF) | 87.23 |
| 3 | Zafar et al. [29] (CWCH) | 88.04 |
| 4 | Ali et al. [28] (HGSIR) | 90.41 |
| 5 | VGG-16 [15] | 88.65 |
| 6 | Proposed method | 92.58 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, A.; Chefranov, A.; Demirel, H. Image-Level Structure Recognition Using Image Features, Templates, and Ensemble of Classifiers. Symmetry 2020, 12, 1072. https://doi.org/10.3390/sym12071072
Khan A, Chefranov A, Demirel H. Image-Level Structure Recognition Using Image Features, Templates, and Ensemble of Classifiers. Symmetry. 2020; 12(7):1072. https://doi.org/10.3390/sym12071072
Chicago/Turabian StyleKhan, Altaf, Alexander Chefranov, and Hasan Demirel. 2020. "Image-Level Structure Recognition Using Image Features, Templates, and Ensemble of Classifiers" Symmetry 12, no. 7: 1072. https://doi.org/10.3390/sym12071072
APA StyleKhan, A., Chefranov, A., & Demirel, H. (2020). Image-Level Structure Recognition Using Image Features, Templates, and Ensemble of Classifiers. Symmetry, 12(7), 1072. https://doi.org/10.3390/sym12071072