A Lightweight Android Malware Classifier Using Novel Feature Selection Methods



Abstract
1. Introduction
- We utilize several methods of feature selection to reduce the feature space size of any Android application dataset. These methods significantly reduced the size of the utilized dataset feature vector space. Then, we compare these methods in terms of accuracy, model memory size, and training time.
- We conduct a set of experiments using five different ML classifiers (a support vector machine (SVM), logistic regression, AdaBoost, stochastic gradient descent (SGD), and latent Drichlet allocation (LDA)) based on the Drebin dataset.
- To the best of the authors’ knowledge, this is the first work to utilize the feature frequency as a feature selection factor in the field of Android malware detection. The proposed feature selection method results in a model with the highest reported accuracy to date for the full Drebin dataset at 99%. In addition, we propose the first ML model for Android malware detection using a single feature, the URL_score feature, with an accuracy rate of 80%.
2. Background and Related Work
2.1. Types of Android Malware Detection Analysis
2.2. Android Malware Detection Based on Static Feature Categories
2.3. Feature Selection Methods of Android Static Features
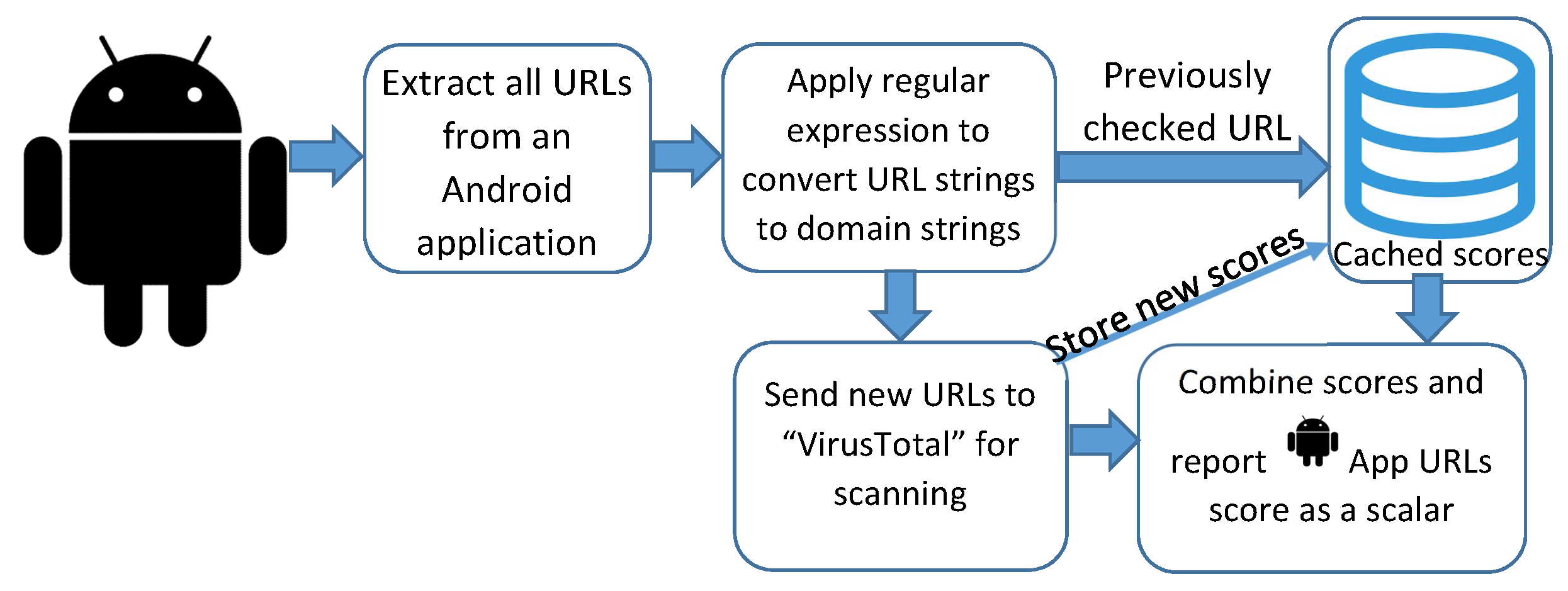
2.4. URLs as Features in Android Malware Detection Methods
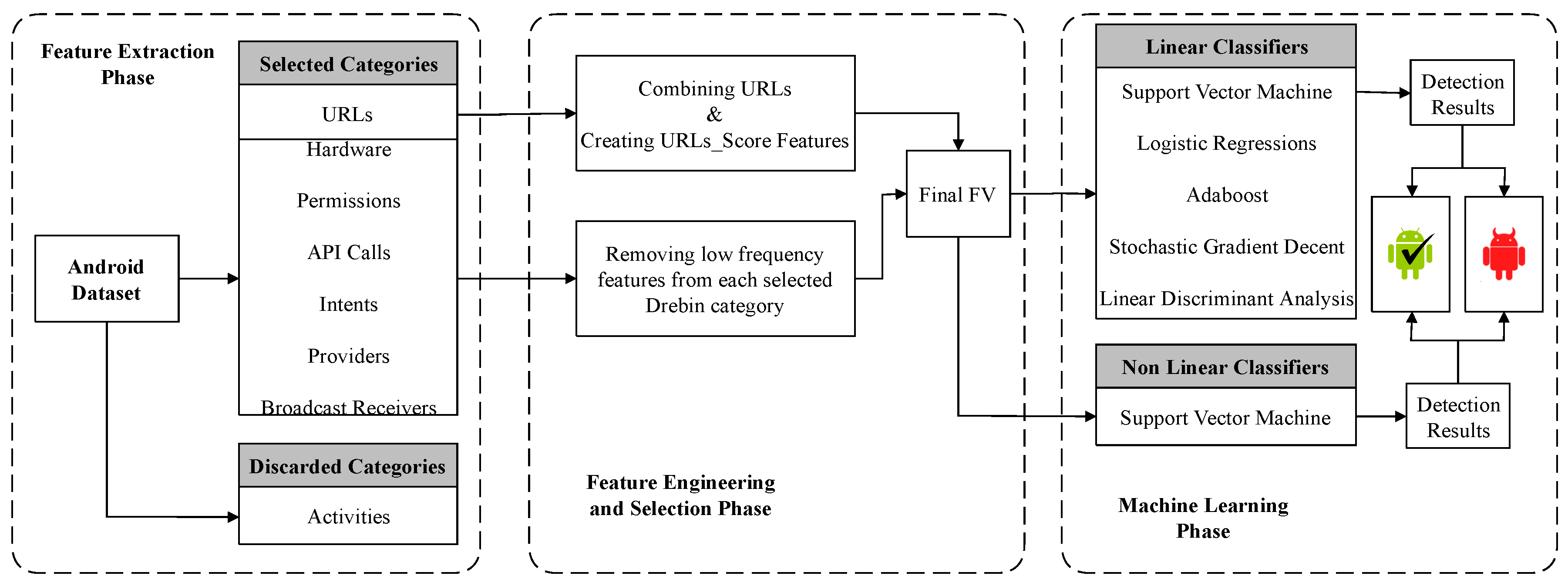
3. Methodology
3.1. Feature Extraction
3.2. Feature Engineering
URL Feature Merging
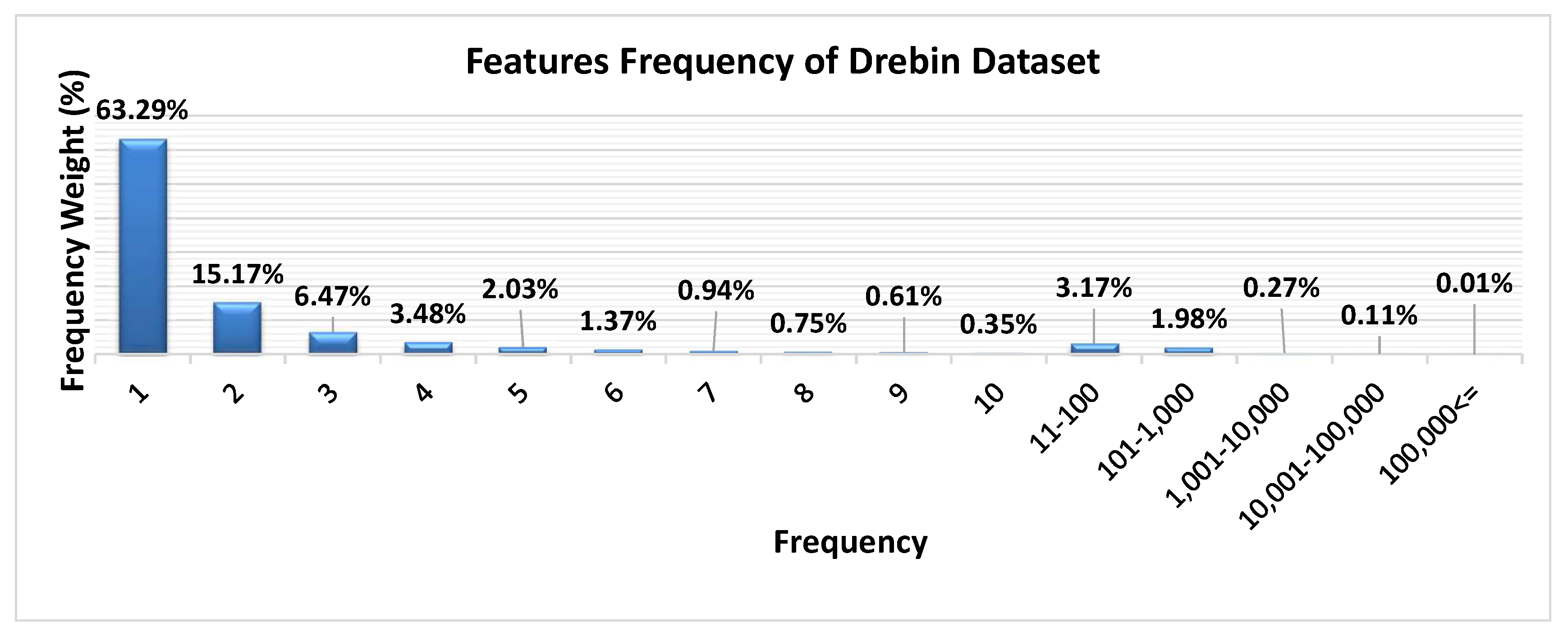
3.3. Feature Selection Based on the Feature Frequency
4. Experimental Results
4.1. Experimental Setup
4.2. Experimental Data
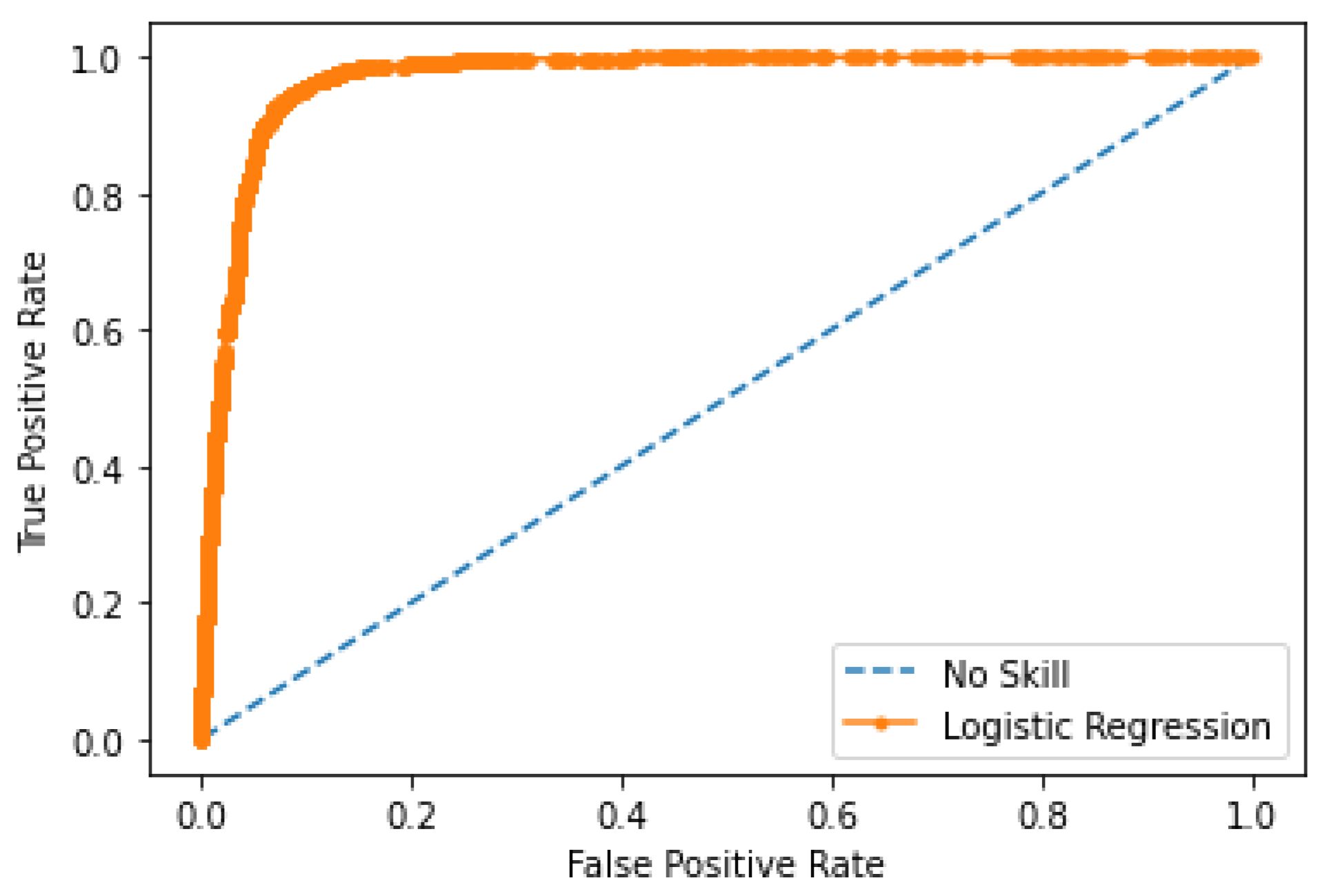
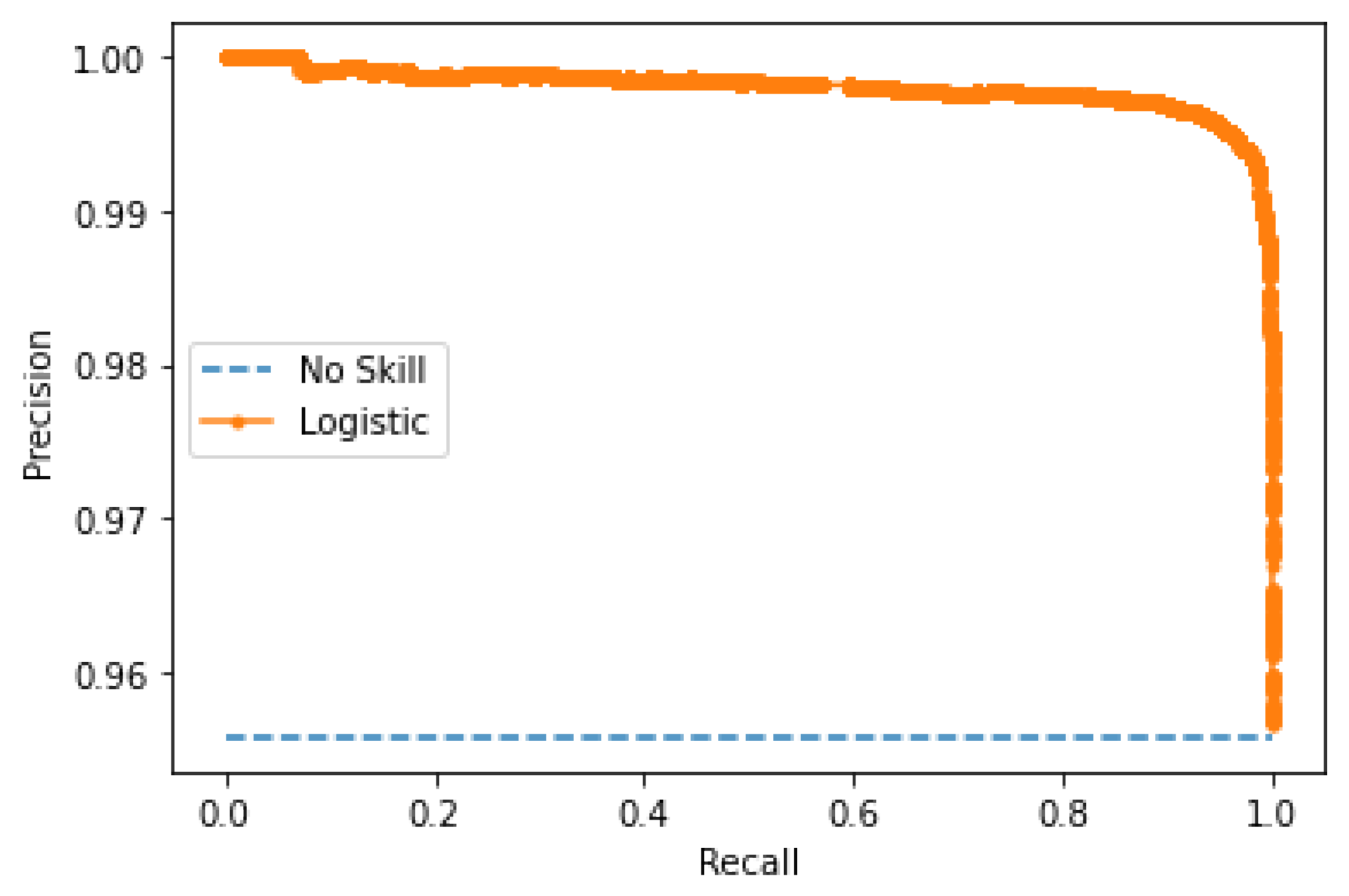
4.3. Results
4.3.1. Comparison against the Existing Malware Detection Methods
4.3.2. Accuracy Evaluation
4.3.3. Model’S Disk Size and Running Times
4.3.4. Comparison against the Existing Feature Selection Methods
4.3.5. Evaluation of Feature Space Reduction
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Android OS Market Share of Smartphone Sales to End Users. 2018. Available online: https://www.statista.com/statistics/216420/global-market-share-forecast-of-smartphone-operating-systems/ (accessed on 3 December 2018).
- Ribeiro, J.; Saghezchi, F.B.; Mantas, G.; Rodriguez, J.; Shepherd, S.J.; Abd-Alhameed, R.A. An Autonomous Host-Based Intrusion Detection System for Android Mobile Devices. Mob. Netw. Appl. 2020, 25, 164–172. [Google Scholar] [CrossRef]
- Kim, D.; Shin, D.; Shin, D.; Kim, Y.H. Attack detection application with attack tree for mobile system using log analysis. Mob. Netw. Appl. 2019, 24, 184–192. [Google Scholar] [CrossRef]
- Qiao, M.; Sung, A.H.; Liu, Q. Merging permission and api features for android malware detection. In Proceedings of the 2016 5th IIAI International Congress on Advanced Applied Informatics (IIAI-AAI), Kumamoto, Japan, 10–14 July 2016; pp. 566–571. [Google Scholar]
- Kunda, D.; Chishimba, M. A survey of android mobile phone authentication schemes. Mob. Netw. Appl. 2018, 1–9. [Google Scholar] [CrossRef]
- Arp, D.; Spreitzenbarth, M.; Hubner, M.; Gascon, H.; Rieck, K.; Siemens, C. DREBIN: Effective and Explainable Detection of Android Malware in Your Pocket. NDSS 2014, 14, 23–26. [Google Scholar]
- Leeds, M.; Atkison, T. Preliminary Results of Applying Machine Learning Algorithms to Android Malware Detection. In Proceedings of the 2016 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 15–17 December 2016; pp. 1070–1073. [Google Scholar]
- Yuan, Z.; Lu, Y.; Xue, Y. Droiddetector: Android malware characterization and detection using deep learning. Tsinghua Sci. Technol. 2016, 21, 114–123. [Google Scholar] [CrossRef]
- Ahmadi, M.; Sotgiu, A.; Giacinto, G. IntelliAV: Building an Effective On-Device Android Malware Detector. arXiv 2018, arXiv:1802.01185. [Google Scholar]
- Wang, X.; Yang, Y.; Zeng, Y.; Tang, C.; Shi, J.; Xu, K. A novel hybrid mobile malware detection system integrating anomaly detection with misuse detection. In Proceedings of the 6th International Workshop on Mobile Cloud Computing and Services, Paris, France, 11 September 2015; pp. 15–22. [Google Scholar]
- Moonsamy, V.; Rong, J.; Liu, S. Mining permission patterns for contrasting clean and malicious android applications. Future Gener. Comput. Syst. 2014, 36, 122–132. [Google Scholar] [CrossRef]
- Dash, S.K.; Suarez-Tangil, G.; Khan, S.; Tam, K.; Ahmadi, M.; Kinder, J.; Cavallaro, L. Droidscribe: Classifying android malware based on runtime behavior. In Proceedings of the 2016 IEEE Security and Privacy Workshops (SPW), San Jose, CA, USA, 22–26 May 2016; pp. 252–261. [Google Scholar]
- Somarriba, O.; Perez Ramos, L.C.; Zurutuza, U.; Uribeetxeberria, R. Dynamic DNS Request Monitoring of Android Applications via Networking. In Proceedings of the 2018 IEEE 38th Central America and Panama Convention (CONCAPAN XXXVIII), San Salvador, El Salvador, 7–9 November 2018; pp. 1–6. [Google Scholar]
- Mao, K.; Capra, L.; Harman, M.; Jia, Y. A survey of the use of crowdsourcing in software engineering. J. Syst. Softw. 2017, 126, 57–84. [Google Scholar] [CrossRef]
- Wang, W.; Zhao, M.; Wang, J. Effective android malware detection with a hybrid model based on deep autoencoder and convolutional neural network. J. Ambient. Intell. Humaniz. Comput. 2019, 10, 3035–3043. [Google Scholar] [CrossRef]
- Tong, F.; Yan, Z. A hybrid approach of mobile malware detection in Android. J. Parallel Distrib. Comput. 2017, 103, 22–31. [Google Scholar] [CrossRef]
- Xue, Y.; Zeng, D.; Chen, F.; Wang, Y.; Zhang, Z. A New Dataset and Deep Residual Spectral Spatial Network for Hyperspectral Image Classification. Symmetry 2020, 12, 561. [Google Scholar] [CrossRef]
- Kabakus, A.T. What Static Analysis Can Utmost Offer for Android Malware Detection. Inf. Technol. Control. 2019, 48, 235–249. [Google Scholar] [CrossRef]
- Amin, M.; Tanveer, T.A.; Tehseen, M.; Khan, M.; Khan, F.A.; Anwar, S. Static malware detection and attribution in android byte-code through an end-to-end deep system. Future Gener. Comput. Syst. 2020, 102, 112–126. [Google Scholar] [CrossRef]
- Wang, K.; Song, T.; Liang, A. Mmda: Metadata Based Malware Detection on Android. In Proceedings of the 2016 12th IEEE International Conference on Computational Intelligence and Security (CIS), Wuxi, China, 16–19 December 2016; pp. 598–602. [Google Scholar]
- Singh, B.; Evtyushkin, D.; Elwell, J.; Riley, R.; Cervesato, I. On the detection of kernel-level rootkits using hardware performance counters. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security, Abu Dhabi, UAE, 2–6 April 2017; pp. 483–493. [Google Scholar]
- Idrees, F.; Rajarajan, M.; Conti, M.; Chen, T.M.; Rahulamathavan, Y. PIndroid: A novel Android malware detection system using ensemble learning methods. Comput. Secur. 2017, 68, 36–46. [Google Scholar] [CrossRef]
- Feizollah, A.; Anuar, N.B.; Salleh, R.; Suarez-Tangil, G.; Furnell, S. Androdialysis: Analysis of android intent effectiveness in malware detection. Comput. Secur. 2017, 65, 121–134. [Google Scholar] [CrossRef]
- Yerima, S.Y.; Sezer, S.; Muttik, I. Android malware detection: An eigenspace analysis approach. In Proceedings of the IEEE 2015 Science and Information Conference (SAI), London, UK, 28–30 July 2015; pp. 1236–1242. [Google Scholar]
- Aafer, Y.; Du, W.; Yin, H. Droidapiminer: Mining api-level features for robust malware detection in android. In Proceedings of the International Conference on Security and Privacy in Communication Systems, Sydney, Australia, 25–28 September 2013; pp. 86–103. [Google Scholar]
- Hou, S.; Ye, Y.; Song, Y.; Abdulhayoglu, M. Hindroid: An intelligent android malware detection system based on structured heterogeneous information network. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 1507–1515. [Google Scholar]
- Garcia, J.; Hammad, M.; Malek, S. Lightweight, obfuscation-resilient detection and family identification of Android malware. ACM Trans. Softw. Eng. Methodol. (TOSEM) 2018, 26, 11. [Google Scholar] [CrossRef]
- Wei, F.; Li, Y.; Roy, S.; Ou, X.; Zhou, W. Deep ground truth analysis of current android malware. In Proceedings of the International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment, Bonn, Germany, 6–7 July 2017; pp. 252–276. [Google Scholar]
- Zhou, Y.; Jiang, X. Dissecting android malware: Characterization and evolution. In Proceedings of the 2012 IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 24–25 May 2012; pp. 95–109. [Google Scholar]
- Andrototal Official Blog. Available online: http://blog.andrototal.org/ (accessed on 20 April 2020).
- Liao, L.; Li, K.; Li, K.; Yang, C.; Tian, Q. UHCL-Darknet: An OpenCL-based Deep Neural Network Framework for Heterogeneous Multi-/Many-core Clusters. In Proceedings of the 47th International Conference on Parallel Processing (ICPP 2018), Eugene, OR, USA, 13–16 August 2018; p. 44. [Google Scholar]
- Duan, M.; Li, K.; Li, K. An ensemble cnn2elm for age estimation. IEEE Trans. Inf. Forensics Secur. 2018, 13, 758–772. [Google Scholar] [CrossRef]
- Ahmadi, M.; Sotgiu, A.; Giacinto, G. Intelliav: Toward the feasibility of building intelligent anti-malware on android devices. In Proceedings of the International Cross-Domain Conference for Machine Learning and Knowledge Extraction, Reggio, Italy, 29 August–1 September 2017; pp. 137–154. [Google Scholar]
- Wang, X.; Zhang, J.; Zhang, A. Machine-Learning-Based Malware Detection for Virtual Machine by Analyzing Opcode Sequence. In Proceedings of the International Conference on Brain Inspired Cognitive Systems, Xi’an, China, 7–8 July 2018; pp. 717–726. [Google Scholar]
- Li, C.; Zhu, R.; Niu, D.; Mills, K.; Zhang, H.; Kinawi, H. Android Malware Detection based on Factorization Machine. arXiv 2018, arXiv:1805.11843. [Google Scholar] [CrossRef]
- Wang, S.; Chen, Z.; Yan, Q.; Ji, K.; Wang, L.; Yang, B.; Conti, M. Deep and Broad Learning based Detection of Android Malware via Network Traffic. In Proceedings of the 2018 IEEE/ACM 26th International Symposium on Quality of Service (IWQoS), Banff, AB, Canada, 4–6 June 2018; pp. 1–6. [Google Scholar]
- Taheri, R.; Ghahramani, M.; Javidan, R.; Shojafar, M.; Pooranian, Z.; Conti, M. Similarity-based Android malware detection using Hamming distance of static binary features. Future Gener. Comput. Syst. 2020, 105, 230–247. [Google Scholar] [CrossRef]
- VirusTotal. 2018. Available online: https://www.virustotal.com/ (accessed on 3 December 2018).
- Robertson, S. Understanding inverse document frequency: On theoretical arguments for IDF. J. Doc. 2004, 60, 503–520. [Google Scholar] [CrossRef]
- Grosse, K.; Papernot, N.; Manoharan, P.; Backes, M.; McDaniel, P. Adversarial perturbations against deep neural networks for malware classification. arXiv 2016, arXiv:1606.04435. [Google Scholar]
- Shahpasand, M.; Hamey, L.; Vatsalan, D.; Xue, M. Adversarial Attacks on Mobile Malware Detection. In Proceedings of the 2019 IEEE 1st International Workshop on Artificial Intelligence for Mobile (AI4Mobile), Hangzhou, China, 24 February 2019; pp. 17–20. [Google Scholar]
- Fushiki, T. Estimation of prediction error by using K-fold cross-validation. Stat. Comput. 2011, 21, 137–146. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | The Proposed Method | Ours (URL_Score) | Drebin [6] | CNN [40] | SVM [41] |
|---|---|---|---|---|---|
| Accuracy | 99% | 80% | 94% | 98% | 98% |
| Num of features | 349 | 1 | 545,356 | 545,356 | 545,356 |
| Feature Space | Linear SVM | Log. Reg. | AdaBoost | SGD | LDA |
|---|---|---|---|---|---|
| FS(1,1 × 105) | 95.61% | 95.68% | 95.41% | 95.71% | 95.72% |
| FS(3,1 × 105) | 95.71% | 95.78% | 95.81% | 95.70% | 95.75% |
| FS(5,1 × 105) | 95.77% | 95.70% | 95.73% | 95.75% | 95.73% |
| FS(7,1 × 105) | 98.94% | 98.93% | 97.95% | 97.73% | 98.83% |
| FS(9,1 × 105) | 99.03% | 98.82% | 97.88% | 97.77% | 98.78% |
| FS(11,1 × 105) | 98.89% | 98.89% | 97.90% | 97.90% | 98.73% |
| FS(13,1 × 105) | 98.80% | 98.78% | 97.97% | 97.80% | 98.64% |
| FS(15,1 × 105) | 98.77% | 98.81% | 97.98% | 97.76% | 98.54% |
| FS(25,1 × 105) | 98.68% | 98.62% | 97.88% | 97.87% | 98.26% |
| FS(50,1 × 105) | 98.44% | 98.51% | 97.86% | 97.68% | 98.18% |
| FS(75,1 × 105) | 98.37% | 98.45% | 97.75% | 97.62% | 98.10% |
| FS(100,1 × 105) | 98.47% | 98.49% | 97.85% | 97.58% | 98.18% |
| FS(125,1 × 105) | 98.44% | 98.50% | 97.95% | 97.50% | 98.09% |
| FS(150,1 × 105) | 98.04% | 97.95% | 97.73% | 97.18% | 97.78% |
| FS(250,1 × 105) | 98.16% | 98.40% | 97.85% | 97.54% | 97.78% |
| FSURLs_score | 80.15% | 79.92% | 79.89% | 80.11% | 79.67% |
| Feature Space | Linear SVM | Log Reg. | AdaBoost | SGD | LDA |
|---|---|---|---|---|---|
| FS(3,1 × 105) | 94% | 94% | 94% | 94% | 94% |
| FS(5,1 × 105) | 94% | 94% | 94% | 94% | 94% |
| FS(7,1 × 105) | 99% | 99% | 98% | 98% | 99% |
| FS(9,1 × 105) | 99% | 99% | 98% | 98% | 99% |
| FSURLs_score | 85% | 85% | 84% | 85% | 85% |
| Model Name | Linear SVM (URL) * | Linear SVM | Log_Reg | AdaBoost | SGD | LDA | Non Linear SVM |
|---|---|---|---|---|---|---|---|
| Model size | 1 | 19,854 | 19,853 | 19,277 | 20,130 | 19,700 | 196,225,074 |
| Feature Space | Drebin Original Feature Space | Drebin Modified Feature Space | |
|---|---|---|---|
| No. of Features | No. of Features | FRP | |
| FS(1,1.3 × 105) | 545,356 | 49,117 | – |
| FS(3,1.3 × 105) | 95,621 | 9838 | 20.0% |
| FS(5,1.3 × 105) | 44,613 | 4890 | 9.9% |
| FS(7,1.3 × 105) | 26,862 | 3253 | 6.6% |
| FS(9,1.3 × 105) | 19,724 | 2411 | 4.9% |
| FS(11,1.3 × 105) | 15,775 | 1888 | 3.8% |
| FS(13,1.3 × 105) | 12,920 | 1544 | 3.1% |
| FS(15,1.3 × 105) | 10,997 | 1380 | 2.8% |
| FS(25,1.3 × 105) | 7223 | 865 | 1.8% |
| FS(50,1.3 × 105) | 4269 | 517 | 1.1% |
| FS(75,1.3 × 105) | 3112 | 352 | 0.7% |
| FS(100,1.3 × 105) | 2422 | 349 | 0.7% |
| FS(200,1.3 × 105) | 1313 | 172 | 0.4% |
| Category | URLs | Activity | Service Receiver | Intent | Provider | Permis. | Call | API Call | HW | Real Permis. |
|---|---|---|---|---|---|---|---|---|---|---|
| No. of features | 310,511 | 185,729 | 33,222 | 6379 | 4513 | 3812 | 733 | 315 | 72 | 70 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salah, A.; Shalabi, E.; Khedr, W. A Lightweight Android Malware Classifier Using Novel Feature Selection Methods. Symmetry 2020, 12, 858. https://doi.org/10.3390/sym12050858
Salah A, Shalabi E, Khedr W. A Lightweight Android Malware Classifier Using Novel Feature Selection Methods. Symmetry. 2020; 12(5):858. https://doi.org/10.3390/sym12050858
Chicago/Turabian StyleSalah, Ahmad, Eman Shalabi, and Walid Khedr. 2020. "A Lightweight Android Malware Classifier Using Novel Feature Selection Methods" Symmetry 12, no. 5: 858. https://doi.org/10.3390/sym12050858
APA StyleSalah, A., Shalabi, E., & Khedr, W. (2020). A Lightweight Android Malware Classifier Using Novel Feature Selection Methods. Symmetry, 12(5), 858. https://doi.org/10.3390/sym12050858