IntruDTree: A Machine Learning Based Cyber Security Intrusion Detection Model




Abstract
1. Introduction
- We first highlight the importance of security features for high dimensions in a machine learning-based intrusion detection model.
- We then present an intrusion detection tree “IntruDTree” machine-learning-based security model that first takes into account the ranking of security features according to their importance and then build a tree-based generalized model based on the selected important features.
- Finally, we conduct experiments to evaluate the effectiveness of our intrusion detection model IntruDTree. The experimental results show that our IntruDTree model significantly outperforms previous ones for detecting cyber intrusions in various unseen test cases.
2. Background and Related Work
3. Materials and Methods
3.1. Exploring Security Dataset
3.2. Preparing Raw Security Data
- Feature encoding: As mentioned earlier, the dataset contains both the numeric and nominal values of the given security features. Although most of the features are numerically valued, several are nominally valued, such as , , , shown in Table 1, and the class value [anomaly, normal] as well. Thus, it is needed to convert all the nominal valued features into vectors in order to fit these data to the target machine learning-based intrusion detection model. Although, “One Hot Encoding” is a popular approach, we used “Label Encoding” in this work. The reason is that, in one hot encoding technique, a significant number of feature dimensions increase. On the other hand, the label-encoding approach directly converts the feature values into particular numeric values. Let us consider an example in terms of the feature . Label encoding can turn the values [tcp, udp, icmp, udp, icmp] into vectors [0, 1, 2, 1, 2].
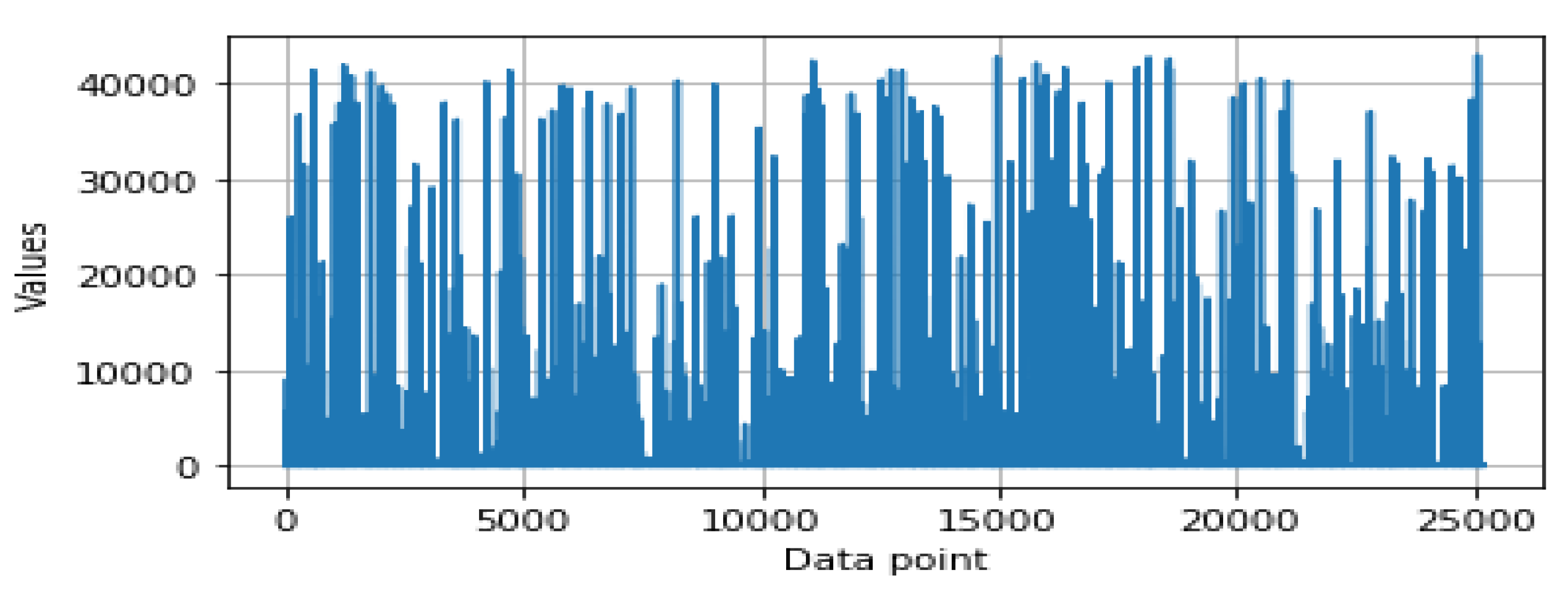
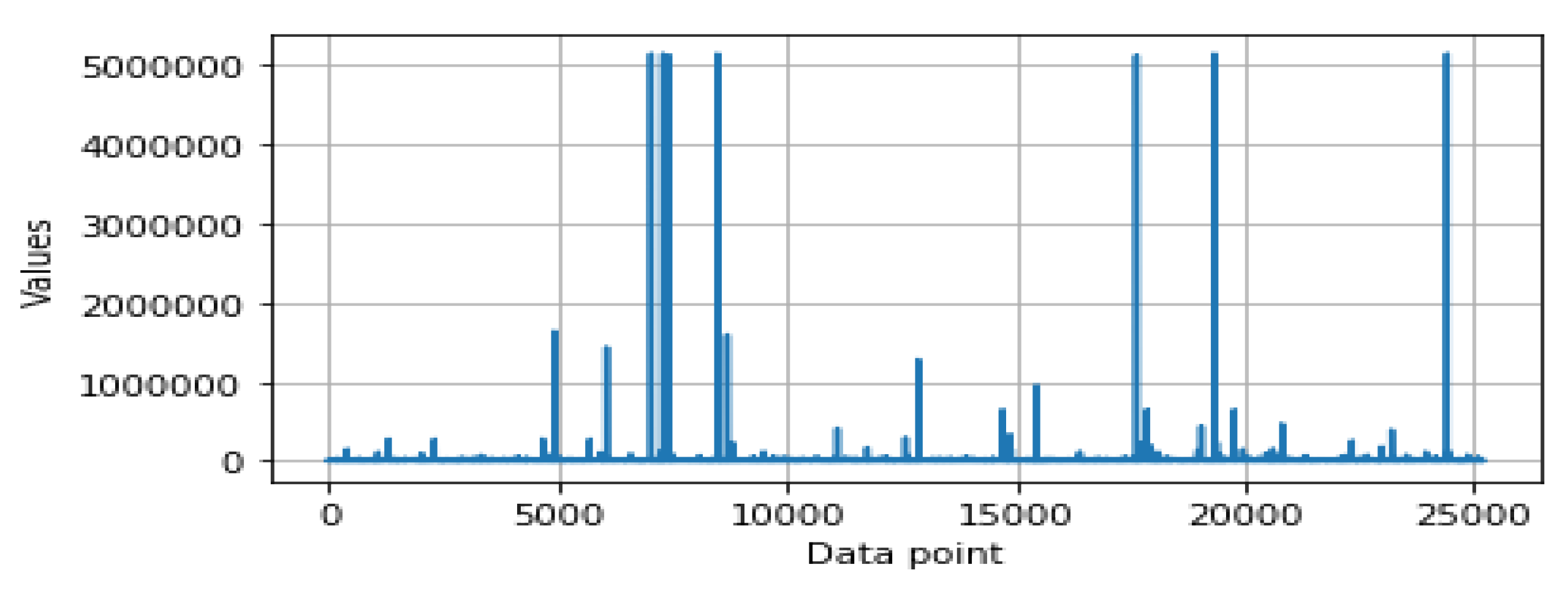
- Feature scaling: In data pre-processing, feature scaling is also known as data normalization. The values of the security features are in different ranges that vary from feature to feature. For instance, Figure 1 and Figure 2 show the data distributions of two different features, and , respectively. For some data points, the value is very low while for some data points, it is much higher, as shown in Figure 1 and Figure 2. Thus, data scaling method is used to normalize the range of the feature values, known as the independent variables as well. In order to do this, we used a Standard Scaler that normalizes the security features with the mean value = 0 and standard deviation = 1. The normalized values are then ready for further analysis in order to build the security model.
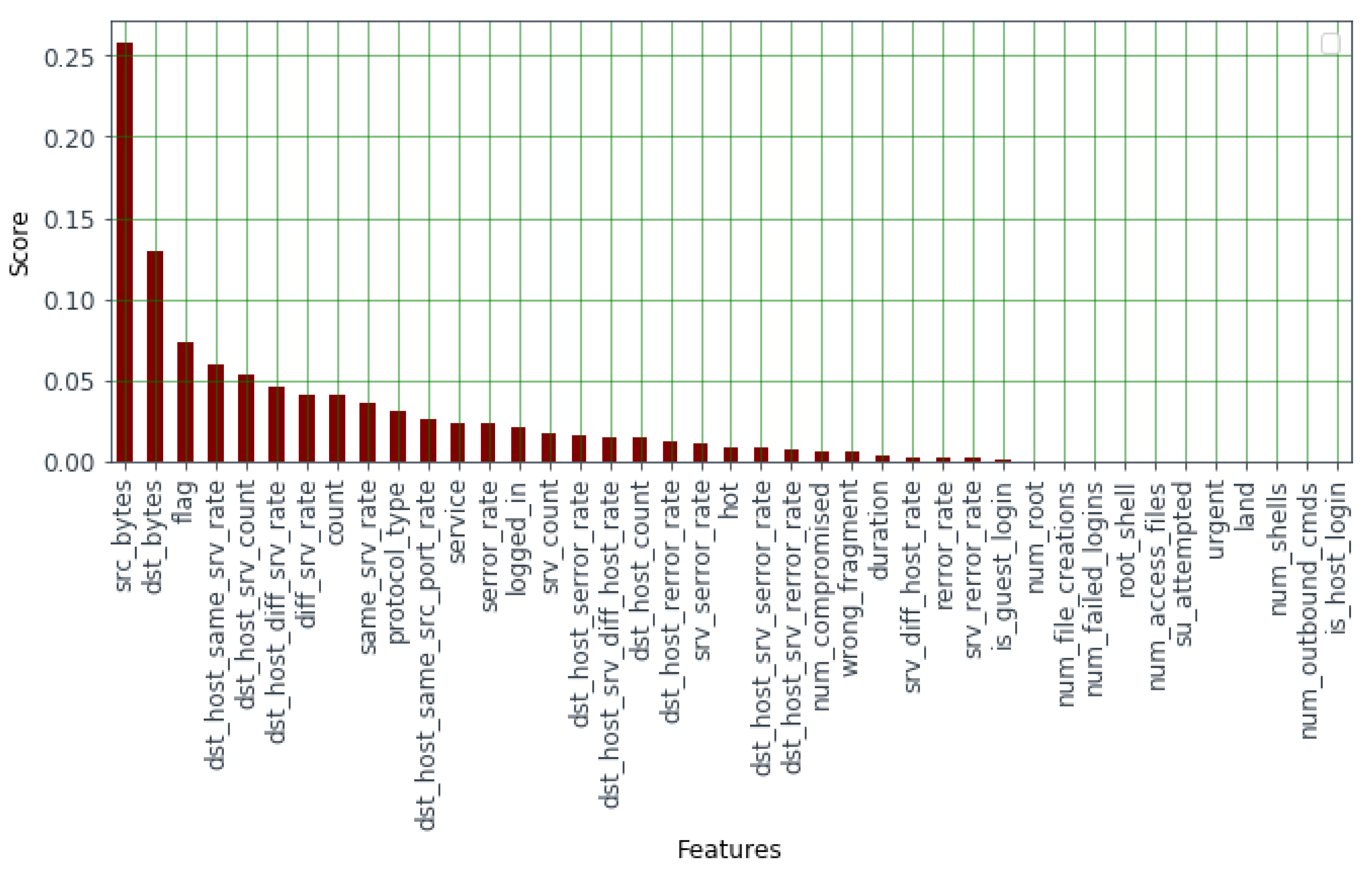
3.3. Determining Feature Importance and Ranking
3.4. Designing Intrusion Detection Tree
| Algorithm 1: IntruDTree Induction |
 |
4. Experimental Results and Discussion
4.1. Experimental Setup
- Question 1: Does the feature importance score and corresponding ranking strategy in IntruDTree model simplify the security dataset by reducing the negligible features, and help to build a generalized data-driven security model?
- Question 2: Is the IntruDTree machine-learning-based security model able to effectively detect cyber intrusions and to provide significant outcome results for unseen test cases?
- Question 3: How effective is our IntruDTree model compared to traditional machine learning classification-based methods?
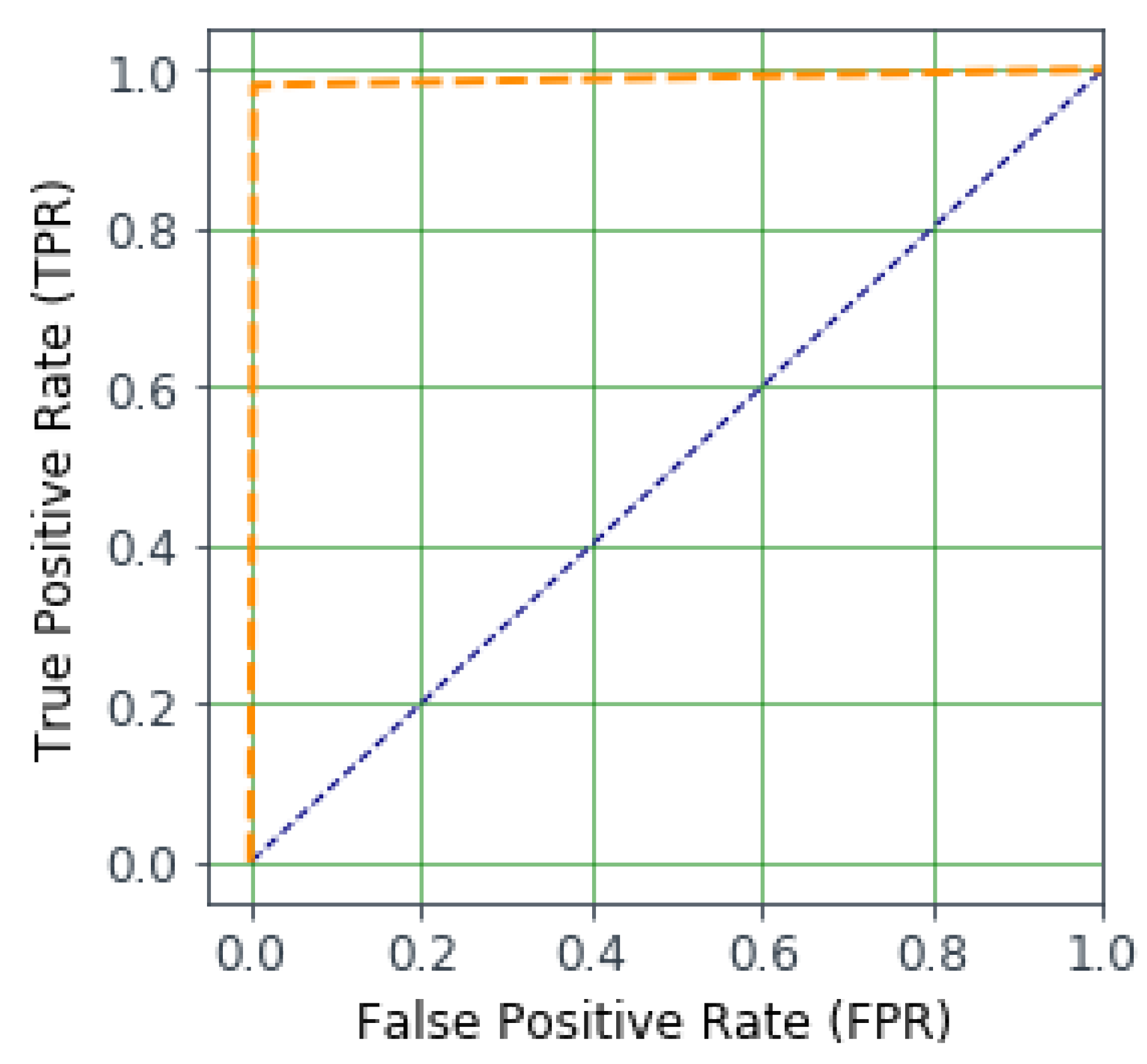
4.2. Evaluation Metric
4.3. Effect of Feature Importance Score and Ranking
4.4. Outcome Results of IntruDTree Model
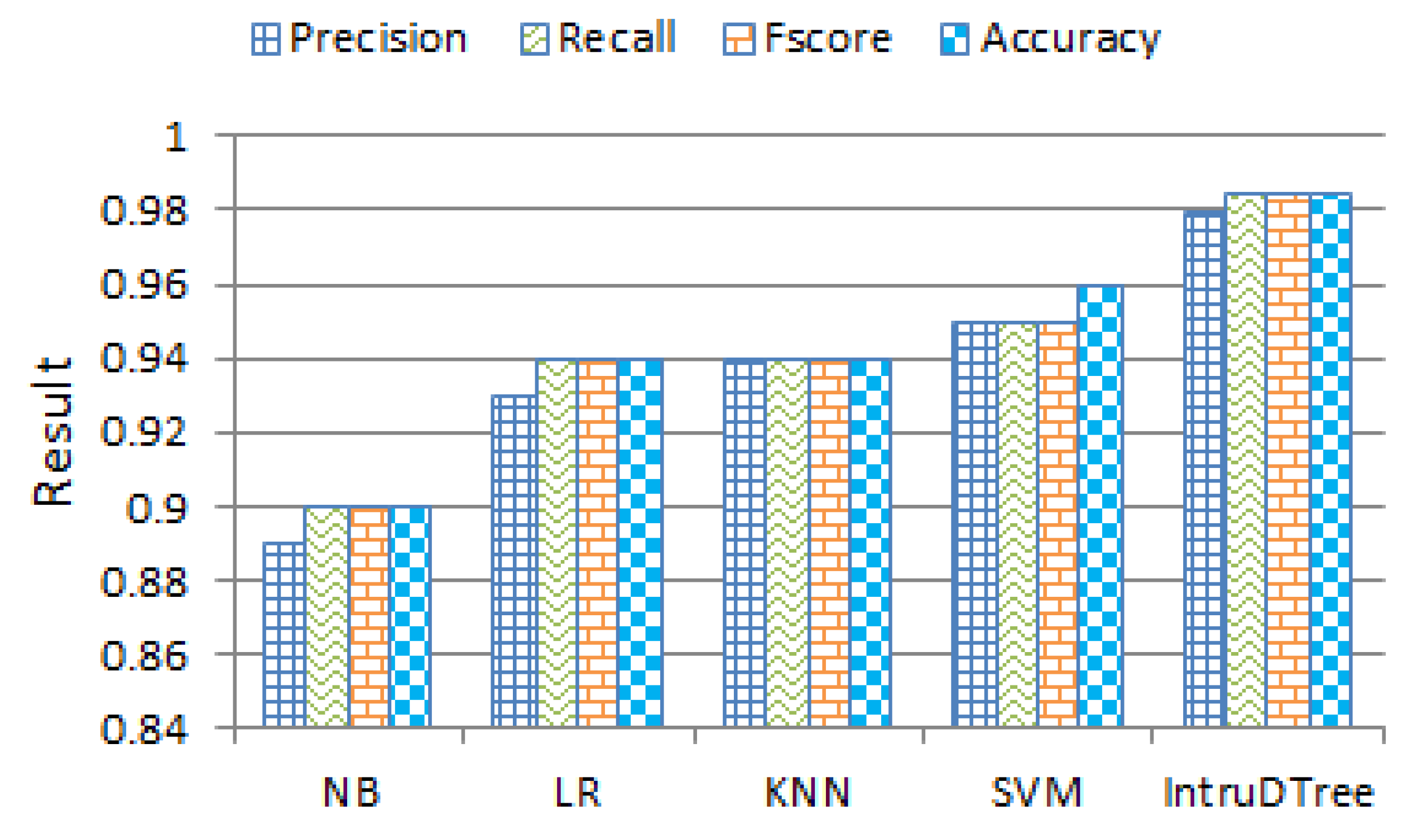
4.5. Effectiveness Comparison
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Sun, N.; Zhang, J.; Rimba, P.; Gao, S.; Zhang, L.Y.; Xiang, Y. Data-driven cybersecurity incident prediction: A survey. IEEE Commun. Surv. Tutor. 2018, 21, 1744–1772. [Google Scholar] [CrossRef]
- Dainotti, A.; Pescapé, A.; Ventre, G. Worm traffic analysis and characterization. In Proceedings of the 2007 IEEE International Conference on Communications, Glasgow, UK, 24–28 June 2007; pp. 1435–1442. [Google Scholar]
- Qu, X.; Yang, L.; Guo, K.; Ma, L.; Sun, M.; Ke, M.; Li, M. A Survey on the Development of Self-Organizing Maps for Unsupervised Intrusion Detection. Mob. Netw. Appl. 2019. [Google Scholar] [CrossRef]
- IBM Security Report. Available online: https://www.ibm.com/security/data-breach (accessed on 20 October 2019).
- Tsai, C.F.; Hsu, Y.F.; Lin, C.Y.; Lin, W.Y. Intrusion detection by machine learning: A review. Expert Syst. Appl. 2009, 36, 11994–12000. [Google Scholar] [CrossRef]
- Mohammadi, S.; Mirvaziri, H.; Ghazizadeh-Ahsaee, M.; Karimipour, H. Cyber intrusion detection by combined feature selection algorithm. J. Inf. Secur. Appl. 2019, 44, 80–88. [Google Scholar] [CrossRef]
- Tapiador, J.E.; Orfila, A.; Ribagorda, A.; Ramos, B. Key-recovery attacks on KIDS, a keyed anomaly detection system. IEEE Trans. Dependable Secur. Comput. 2013, 12, 312–325. [Google Scholar] [CrossRef]
- Tavallaee, M.; Stakhanova, N.; Ghorbani, A.A. Toward credible evaluation of anomaly-based intrusion-detection methods. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2010, 40, 516–524. [Google Scholar] [CrossRef]
- Milenkoski, A.; Vieira, M.; Kounev, S.; Avritzer, A.; Payne, B.D. Evaluating computer intrusion detection systems: A survey of common practices. ACM Comput. Surv. (CSUR) 2015, 48, 1–41. [Google Scholar] [CrossRef]
- Buczak, A.L.; Guven, E. A survey of data mining and machine learning methods for cyber security intrusion detection. IEEE Commun. Surv. Tutor. 2015, 18, 1153–1176. [Google Scholar] [CrossRef]
- Xin, Y.; Kong, L.; Liu, Z.; Chen, Y.; Li, Y.; Zhu, H.; Gao, M.; Hou, H.; Wang, C. Machine learning and deep learning methods for cybersecurity. IEEE Access 2018, 6, 35365–35381. [Google Scholar] [CrossRef]
- Moskovitch, R.; Elovici, Y.; Rokach, L. Detection of unknown computer worms based on behavioral classification of the host. Comput. Stat. Data Anal. 2008, 52, 4544–4566. [Google Scholar] [CrossRef]
- Sommer, R.; Paxson, V. Outside the closed world: On using machine learning for network intrusion detection. In Proceedings of the 2010 IEEE Symposium on Security and Privacy, Berkeley/Oakland, CA, USA, 16–19 May 2010; pp. 305–316. [Google Scholar]
- Seufert, S.; O’Brien, D. Machine learning for automatic defence against distributed denial of service attacks. In Proceedings of the 2007 IEEE International Conference on Communications, Glasgow, UK, 24–28 June 2007; pp. 1217–1222. [Google Scholar]
- Sarker, I.H.; et al. Cybersecurity Data Science: An Overview from Machine Learning Perspective. 2020; in press. [Google Scholar]
- Sarker, I.H.; Kayes, A.; Watters, P. Effectiveness Analysis of Machine Learning Classification Models for Predicting Personalized Context-Aware Smartphone Usage. J. Big Data 2019, 6, 57. [Google Scholar] [CrossRef]
- Sinclair, C.; Pierce, L.; Matzner, S. An application of machine learning to network intrusion detection. In Proceedings of the 15th Annual Computer Security Applications Conference (ACSAC’99), Phoenix, AZ, USA, 6–10 December 1999; pp. 371–377. [Google Scholar]
- Alazab, A.; Hobbs, M.; Abawajy, J.; Alazab, M. Using feature selection for intrusion detection system. In Proceedings of the 2012 International Symposium on Communications and Information Technologies (ISCIT), Gold Coast, Australia, 2–5 October 2012; pp. 296–301. [Google Scholar]
- Han, J.; Pei, J.; Kamber, M. Data Mining: Concepts and Techniques; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Witten, I.H.; Frank, E. Data Mining: Practical Machine Learning Tools and Techniques; Morgan Kaufmann: Burlington, MA, USA, 2005. [Google Scholar]
- Agrawal, R.; Srikant, R. Fast algorithms for mining association rules. In Proceedings of the 20th International Conference on Very Large Data Bases, Santiago, Chile, 12–15 September 1994; Volume 1215, pp. 487–499. [Google Scholar]
- Sarker, I.H.; Salim, F.D. Mining User Behavioral Rules from Smartphone Data through Association Analysis. In Proceedings of the 22nd Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD), Melbourne, Australia, 3–6 June 2018; pp. 450–461. [Google Scholar]
- Sarker, I.H. Context-aware rule learning from smartphone data: Survey, challenges and future directions. J. Big Data 2019, 6, 95. [Google Scholar] [CrossRef]
- Sarker, I.H. A machine learning based robust prediction model for real-life mobile phone data. Internet Things 2019, 5, 180–193. [Google Scholar] [CrossRef]
- Li, Y.; Xia, J.; Zhang, S.; Yan, J.; Ai, X.; Dai, K. An efficient intrusion detection system based on support vector machines and gradually feature removal method. Expert Syst. Appl. 2012, 39, 424–430. [Google Scholar] [CrossRef]
- Amiri, F.; Yousefi, M.R.; Lucas, C.; Shakery, A.; Yazdani, N. Mutual information-based feature selection for intrusion detection systems. J. Netw. Comput. Appl. 2011, 34, 1184–1199. [Google Scholar] [CrossRef]
- Hu, W.; Liao, Y.; Vemuri, V.R. Robust Support Vector Machines for Anomaly Detection in Computer Security. In Proceedings of the International Conference on Machine Learning and Applications—ICMLA 2003, Los Angeles, CA, USA, 23–24 June 2003; pp. 168–174. [Google Scholar]
- Wagner, C.; François, J.; Engel, T. Machine learning approach for ip-flow record anomaly detection. In Proceedings of the International Conference on Research in Networking, Valencia, Spain, 9–13 May 2011; pp. 28–39. [Google Scholar]
- Moskovitch, R.; Nissim, N.; Stopel, D.; Feher, C.; Englert, R.; Elovici, Y. Improving the detection of unknown computer worms activity using active learning. In Proceedings of the Annual Conference on Artificial Intelligence, Osnabrück, Germany, 10–13 September 2007; pp. 489–493. [Google Scholar]
- Kotpalliwar, M.V.; Wajgi, R. Classification of Attacks Using Support Vector Machine (SVM) on KDDCUP’99 IDS Database. In Proceedings of the 2015 Fifth International Conference on Communication Systems and Network Technologies, Gwalior, India, 4–6 April 2015; pp. 987–990. [Google Scholar]
- Saxena, H.; Richariya, V. Intrusion detection in KDD99 dataset using SVM-PSO and feature reduction with information gain. Int. J. Comput. Appl. 2014, 98, 25–29. [Google Scholar] [CrossRef]
- Pervez, M.S.; Farid, D.M. Feature selection and intrusion classification in NSL-KDD cup 99 dataset employing SVMs. In Proceedings of the 8th International Conference on Software, Knowledge, Information Management and Applications (SKIMA 2014), Dhaka, Bangladesh, 18–20 December 2014; pp. 1–6. [Google Scholar]
- Shon, T.; Kim, Y.; Lee, C.; Moon, J. A machine learning framework for network anomaly detection using SVM and GA. In Proceedings of the Sixth Annual IEEE SMC Information Assurance Workshop, West Point, NY, USA, 15–17 June 2005; pp. 176–183. [Google Scholar]
- Kokila, R.; Selvi, S.T.; Govindarajan, K. DDoS detection and analysis in SDN-based environment using support vector machine classifier. In Proceedings of the 2014 Sixth International Conference on Advanced Computing (ICoAC), Chennai, India, 17–19 December 2014; pp. 205–210. [Google Scholar]
- Kruegel, C.; Mutz, D.; Robertson, W.; Valeur, F. Bayesian event classification for intrusion detection. In Proceedings of the 19th Annual Computer Security Applications Conference, Las Vegas, NV, USA, 8–12 December 2003; pp. 14–23. [Google Scholar]
- Benferhat, S.; Kenaza, T.; Mokhtari, A. A naive bayes approach for detecting coordinated attacks. In Proceedings of the 2008 32nd Annual IEEE International Computer Software and Applications Conference, Turku, Finland, 28 July–1 August 2008; pp. 704–709. [Google Scholar]
- Panda, M.; Patra, M.R. Network intrusion detection using naive bayes. Int. J. Comput. Sci. Netw. Secur. 2007, 7, 258–263. [Google Scholar]
- Koc, L.; Mazzuchi, T.A.; Sarkani, S. A network intrusion detection system based on a Hidden Naïve Bayes multiclass classifier. Expert Syst. Appl. 2012, 39, 13492–13500. [Google Scholar] [CrossRef]
- Shapoorifard, H.; Shamsinejad, P. Intrusion detection using a novel hybrid method incorporating an improved KNN. Int. J. Comput. Appl. 2017, 173, 5–9. [Google Scholar] [CrossRef]
- Vishwakarma, S.; Sharma, V.; Tiwari, A. An intrusion detection system using KNN-ACO algorithm. Int. J. Comput. Appl. 2017, 171, 18–23. [Google Scholar] [CrossRef]
- Sharifi, A.M.; Amirgholipour, S.K.; Pourebrahimi, A. Intrusion detection based on joint of K-means and KNN. J. Converg. Inf. Technol. 2015, 10, 42. [Google Scholar]
- Bapat, R.; Mandya, A.; Liu, X.; Abraham, B.; Brown, D.E.; Kang, H.; Veeraraghavan, M. Identifying malicious botnet traffic using logistic regression. In Proceedings of the 2018 Systems and Information Engineering Design Symposium (SIEDS), Charlottesville, VA, USA, 27 April 2018; pp. 266–271. [Google Scholar]
- Besharati, E.; Naderan, M.; Namjoo, E. LR-HIDS: Logistic regression host-based intrusion detection system for cloud environments. J. Ambient Intell. Humaniz. Comput. 2019, 10, 3669–3692. [Google Scholar] [CrossRef]
- Kumar, P.A.R.; Selvakumar, S. Distributed denial of service attack detection using an ensemble of neural classifier. Comput. Commun. 2011, 34, 1328–1341. [Google Scholar] [CrossRef]
- Dainotti, A.; Pescapé, A.; Ventre, G. A cascade architecture for DoS attacks detection based on the wavelet transform. J. Comput. Secur. 2009, 17, 945–968. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Morgan Kaufmann Publishers, Inc.: Burlington, MA, USA, 1993. [Google Scholar]
- Sarker, I.H.; Colman, A.; Han, J.; Khan, A.I.; Abushark, Y.B.; Salah, K. BehavDT: A Behavioral Decision Tree Learning to Build User-Centric Context-Aware Predictive Model. Mob. Netw. Appl. 2019. [Google Scholar] [CrossRef]
- Ingre, B.; Yadav, A.; Soni, A.K. Decision tree based intrusion detection system for NSL-KDD dataset. In Proceedings of the International Conference on Information and Communication Technology for Intelligent Systems, Ahmedabad, India, 25–26 March 2017; pp. 207–218. [Google Scholar]
- Malik, A.J.; Khan, F.A. A hybrid technique using binary particle swarm optimization and decision tree pruning for network intrusion detection. Clust. Comput. 2018, 21, 667–680. [Google Scholar] [CrossRef]
- Relan, N.G.; Patil, D.R. Implementation of network intrusion detection system using variant of decision tree algorithm. In Proceedings of the 2015 International Conference on Nascent Technologies in the Engineering Field (ICNTE), Navi Mumbai, India, 9–10 January 2015; pp. 1–5. [Google Scholar]
- Rai, K.; Devi, M.S.; Guleria, A. Decision tree based algorithm for intrusion detection. Int. J. Adv. Netw. Appl. 2016, 7, 2828. [Google Scholar]
- Puthran, S.; Shah, K. Intrusion detection using improved decision tree algorithm with binary and quad split. In Proceedings of the International Symposium on Security in Computing and Communication, Jaipur, India, 21–24 September 2016; pp. 427–438. [Google Scholar]
- Moon, D.; Im, H.; Kim, I.; Park, J.H. DTB-IDS: An intrusion detection system based on decision tree using behavior analysis for preventing APT attacks. J. Supercomput. 2017, 73, 2881–2895. [Google Scholar] [CrossRef]
- Balogun, A.O.; Jimoh, R.G. Anomaly intrusion detection using an hybrid of decision tree and K-nearest neighbor. J. Adv. Sci. Res. Appl. 2015. [Google Scholar]
- Sangkatsanee, P.; Wattanapongsakorn, N.; Charnsripinyo, C. Practical real-time intrusion detection using machine learning approaches. Comput. Commun. 2011, 34, 2227–2235. [Google Scholar] [CrossRef]
- Network Intrusion Detection. Available online: https://www.kaggle.com/ (accessed on 12 March 2020).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Name | Value Type | Feature Name | Value Type |
|---|---|---|---|
| Integer | Float | ||
| Nominal | Float | ||
| Float | Float | ||
| Float | Integer | ||
| Nominal | Integer | ||
| Float | Float | ||
| Float | Integer | ||
| Float | Nominal | ||
| Float | Float | ||
| Integer | Float | ||
| Integer | Integer | ||
| Float | Integer | ||
| Float | Integer | ||
| Integer | Float | ||
| Integer | Integer | ||
| Integer | Integer | ||
| Integer | Integer | ||
| Integer | Integer | ||
| Integer | Integer | ||
| Integer | Integer | ||
| Integer | - | - |
| Ranking | Security Feature Name | Importance Score |
|---|---|---|
| 01 | 0.258093 | |
| 02 | 0.129825 | |
| 03 | 0.073396 | |
| 04 | 0.059504 | |
| 05 | 0.053630 | |
| 06 | 0.046281 | |
| 07 | 0.041144 | |
| 08 | 0.040548 | |
| 09 | 0.036620 | |
| 10 | 0.031650 | |
| 11 | 0.025566 | |
| 12 | 0.023904 | |
| 13 | 0.023188 | |
| 14 | 0.020901 |
| Class | Precision | Recall | FScore | Accuracy |
|---|---|---|---|---|
| Normal | 0.98 | 0.98 | 0.98 | 0.98 |
| Anomaly | 0.98 | 0.98 | 0.98 | 0.98 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sarker, I.H.; Abushark, Y.B.; Alsolami, F.; Khan, A.I. IntruDTree: A Machine Learning Based Cyber Security Intrusion Detection Model. Symmetry 2020, 12, 754. https://doi.org/10.3390/sym12050754
Sarker IH, Abushark YB, Alsolami F, Khan AI. IntruDTree: A Machine Learning Based Cyber Security Intrusion Detection Model. Symmetry. 2020; 12(5):754. https://doi.org/10.3390/sym12050754
Chicago/Turabian StyleSarker, Iqbal H., Yoosef B. Abushark, Fawaz Alsolami, and Asif Irshad Khan. 2020. "IntruDTree: A Machine Learning Based Cyber Security Intrusion Detection Model" Symmetry 12, no. 5: 754. https://doi.org/10.3390/sym12050754
APA StyleSarker, I. H., Abushark, Y. B., Alsolami, F., & Khan, A. I. (2020). IntruDTree: A Machine Learning Based Cyber Security Intrusion Detection Model. Symmetry, 12(5), 754. https://doi.org/10.3390/sym12050754