Facial Expression Recognition by Regional Weighting with Approximated Q-Learning


Abstract
1. Introduction
2. Classifiers and Reinforcement Learning for Facial Expression Recognition
2.1. k-Nearest Neighbor (kNN)
- Euclidean distance
- Manhattan distance
- Mahalanobis distance
2.2. Error-Correcting Output Codes (ECOC) for Multi-Class SVM
2.3. Reinforcement Learning
2.3.1. Markov Decision Process (MDP)
2.3.2. Reinforcement Learning for MDP Optimization
2.3.3. Q-Learning
- Value iteration
- Policy iteration
- Q-learning [16]
3. Facial Expression Recognition by Regional Weighting
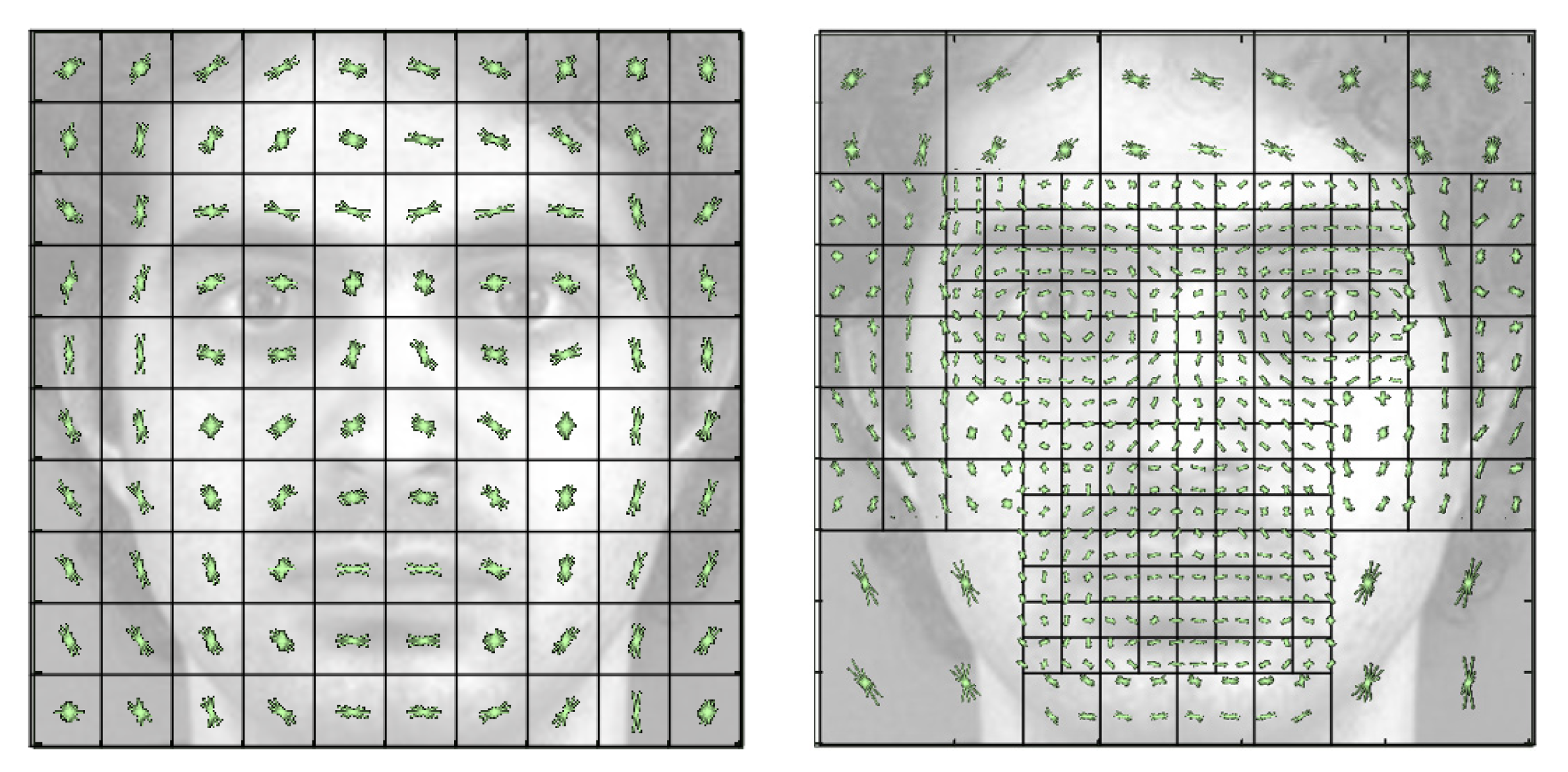
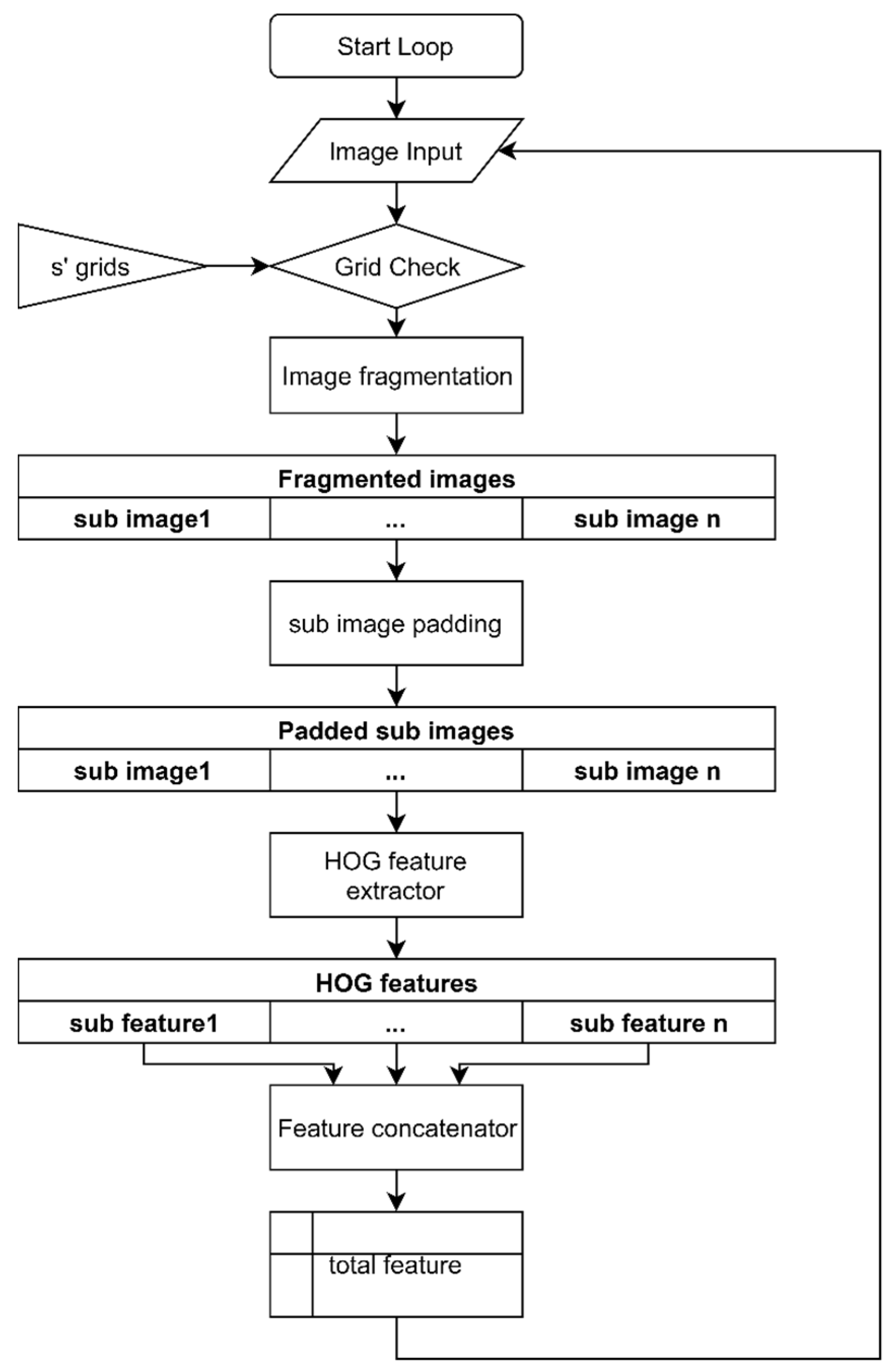
3.1. Feature Extraction by Regional Weighting
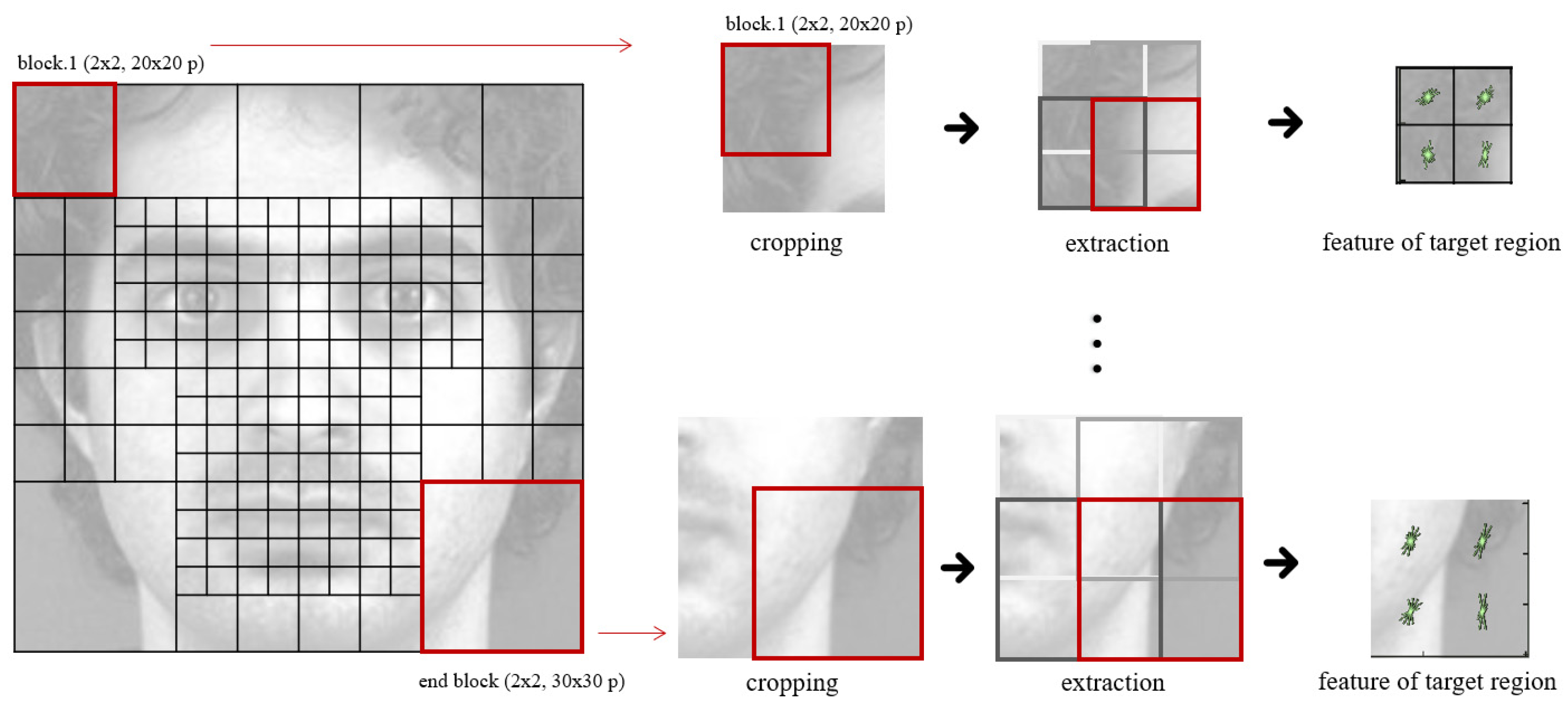
3.2. Vector Feature Extraction Method Using Grid Map
3.3. Weighted Feature Extraction with Grid Map
3.4. Combining with Reinforcement Learning
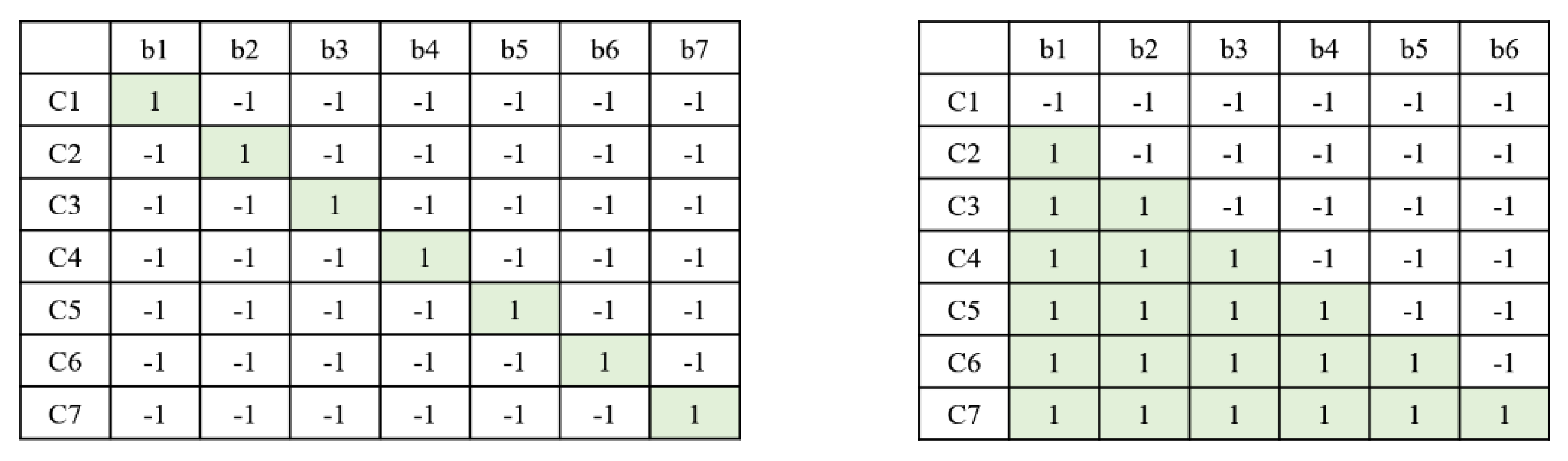
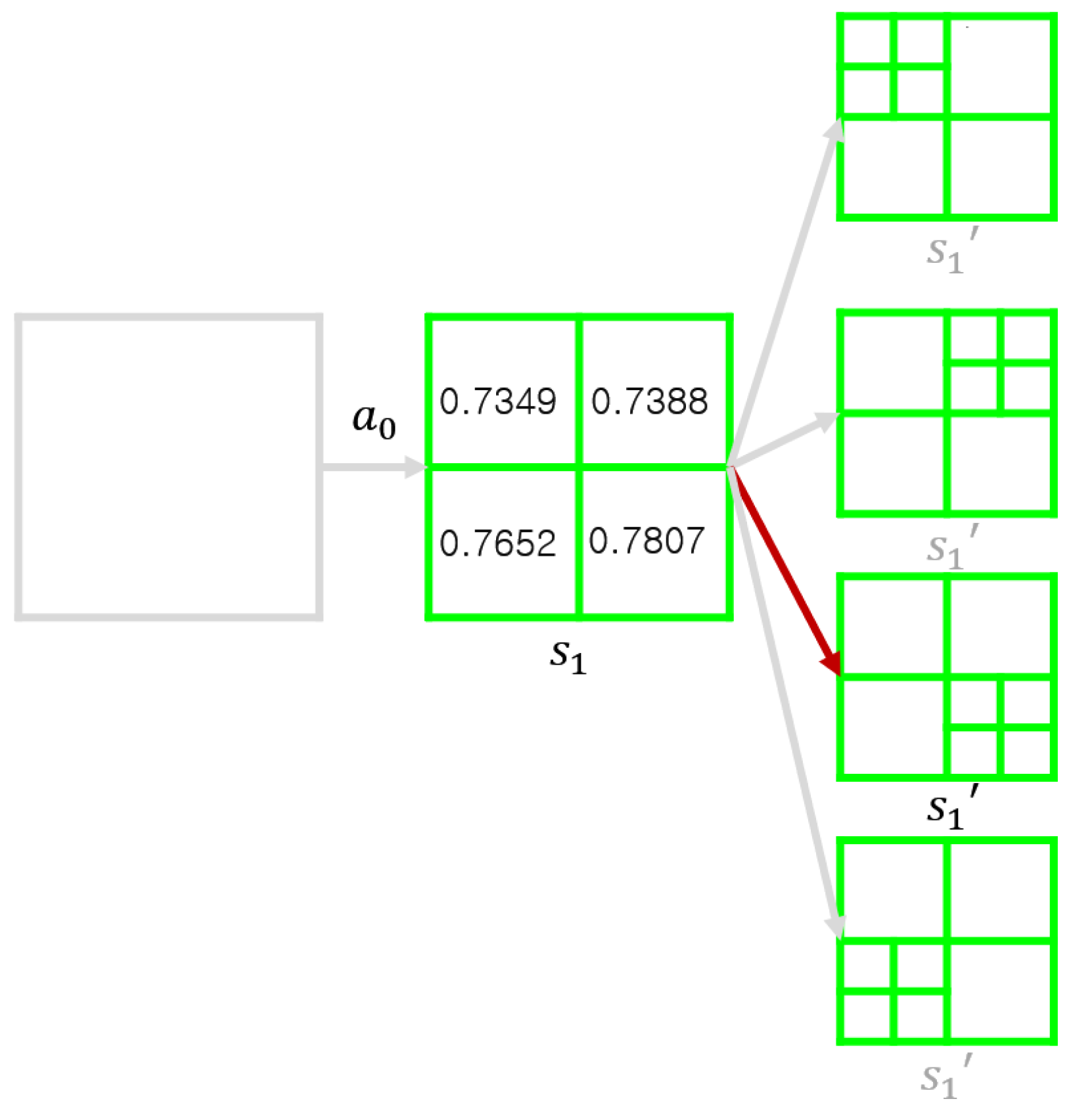
3.4.1. One-Way Decision Process
3.4.2. Multi-Way Decision Process
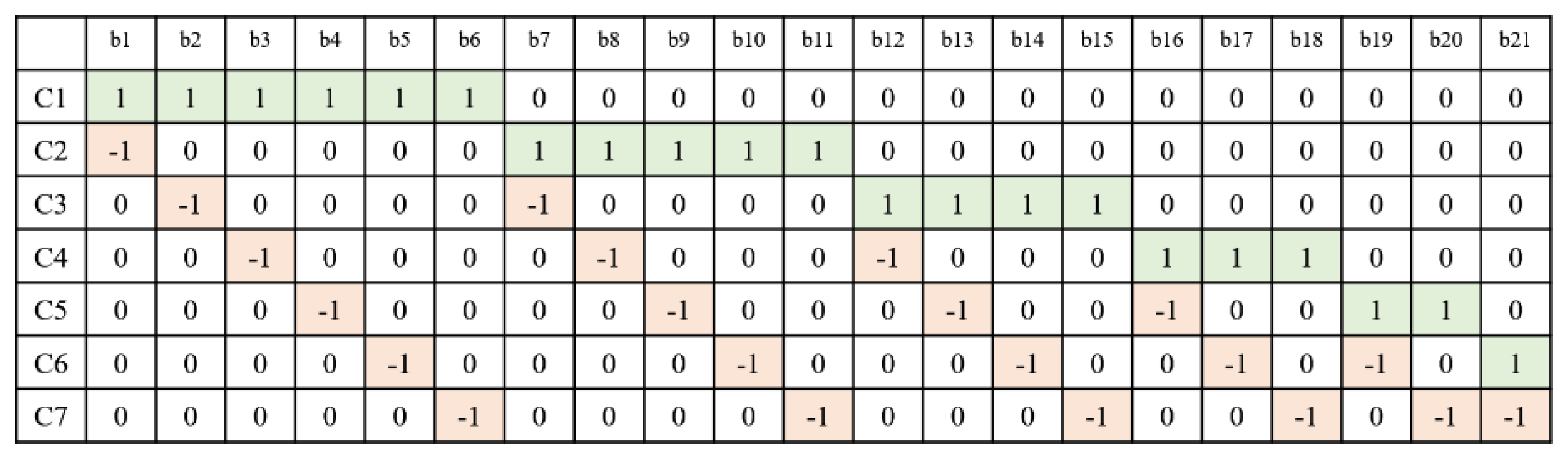
3.5. Q-Function Definition for Optimizing
4. Experiments
4.1. Validation of Classifiers
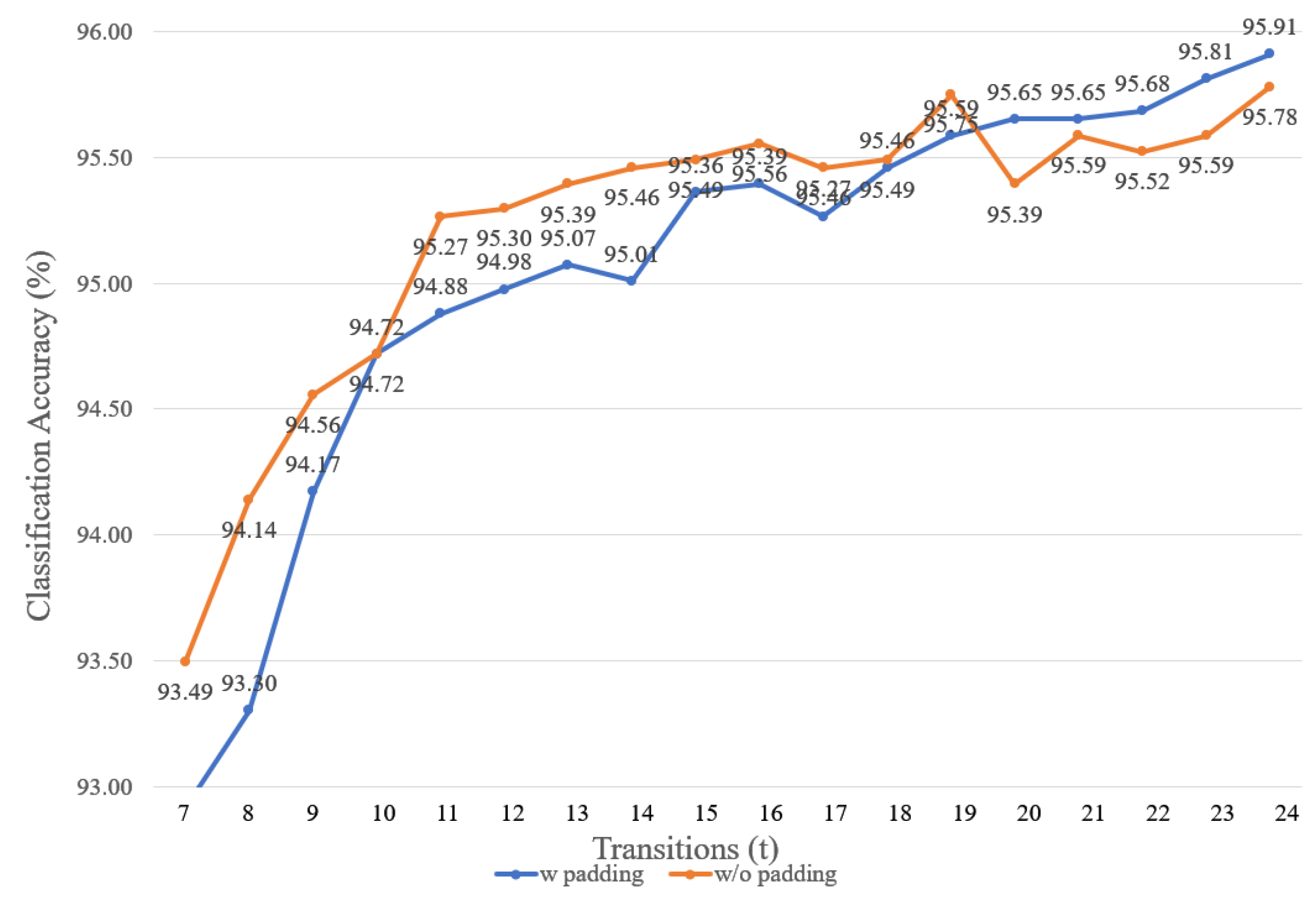
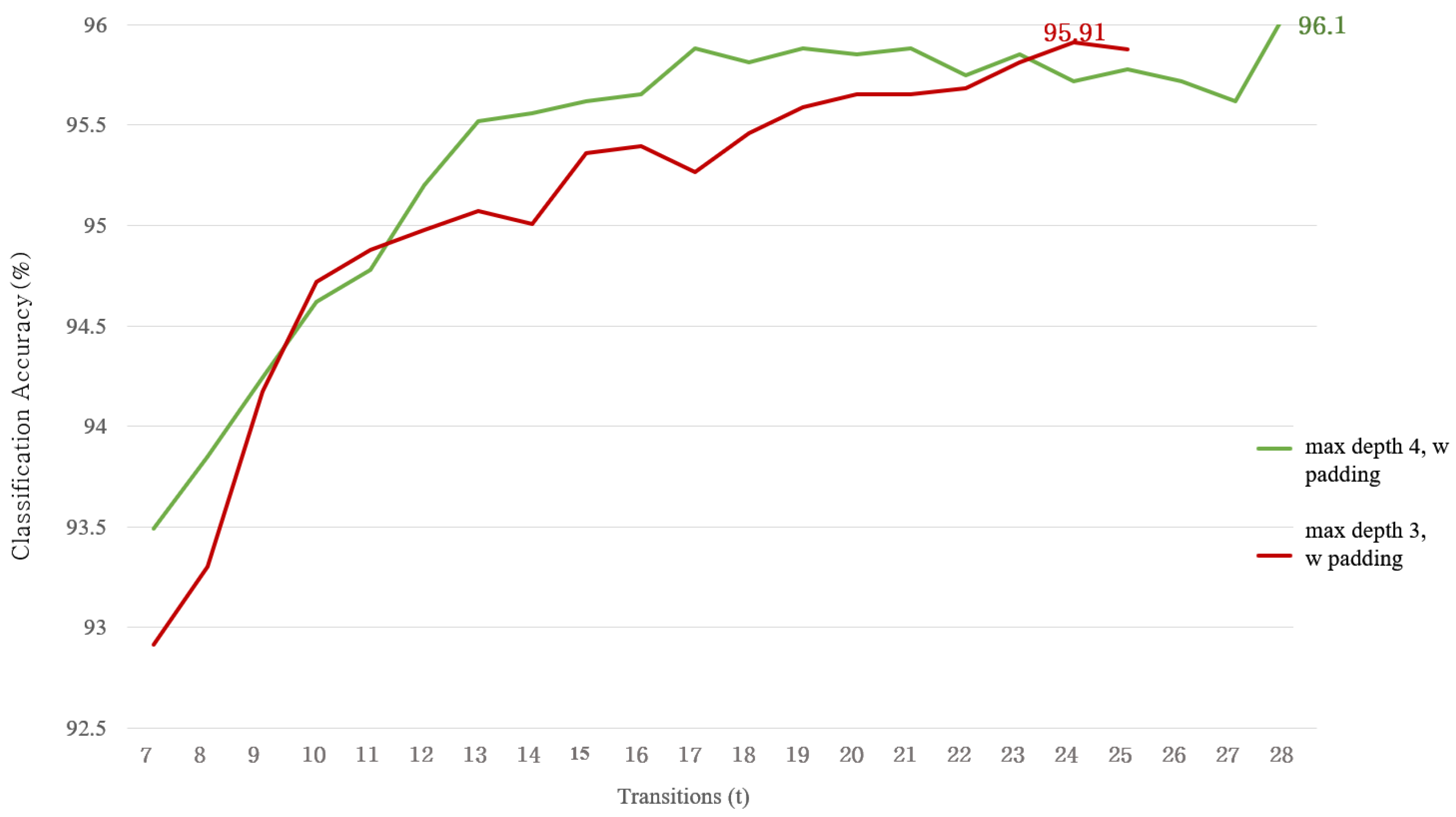
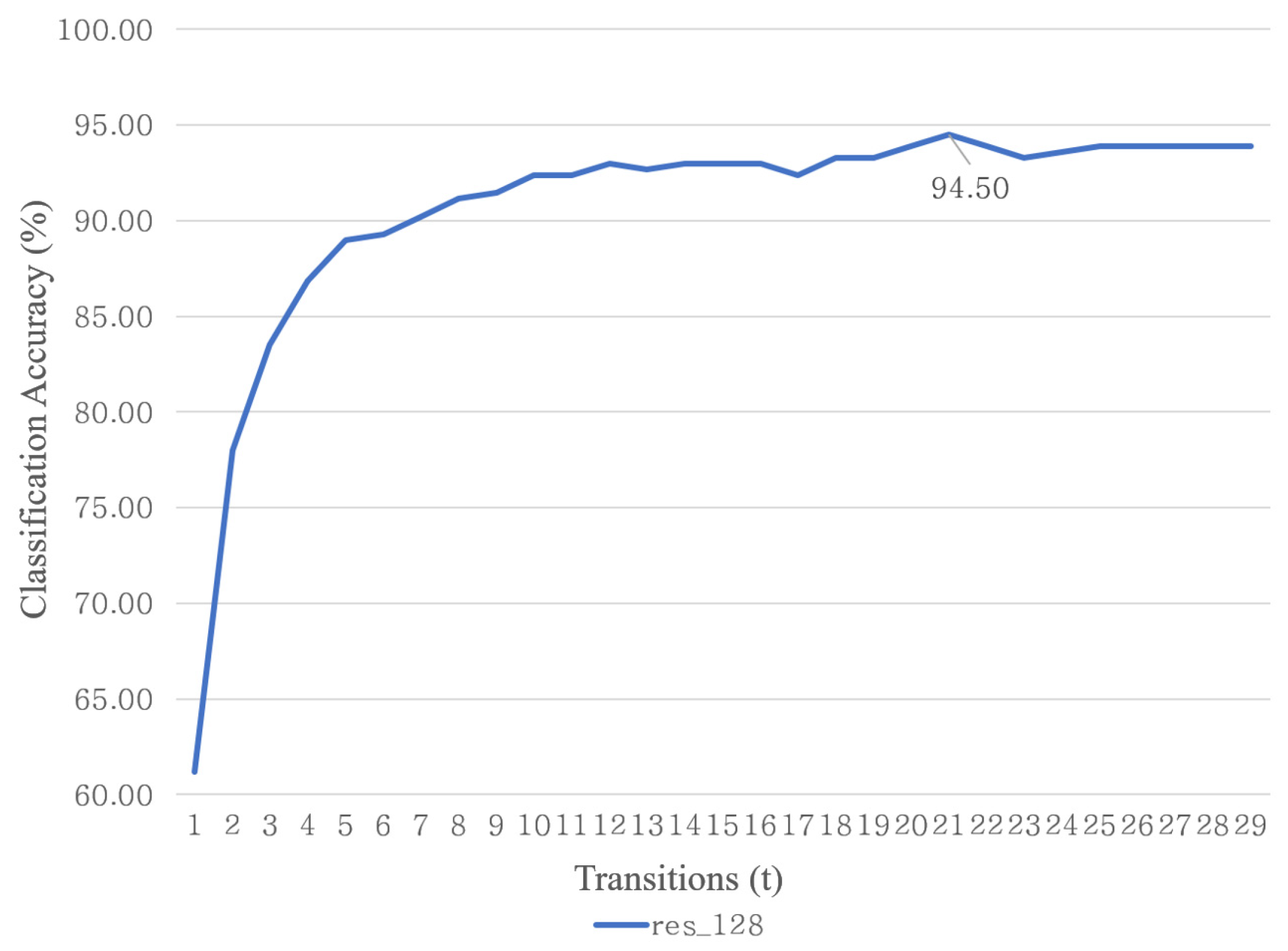
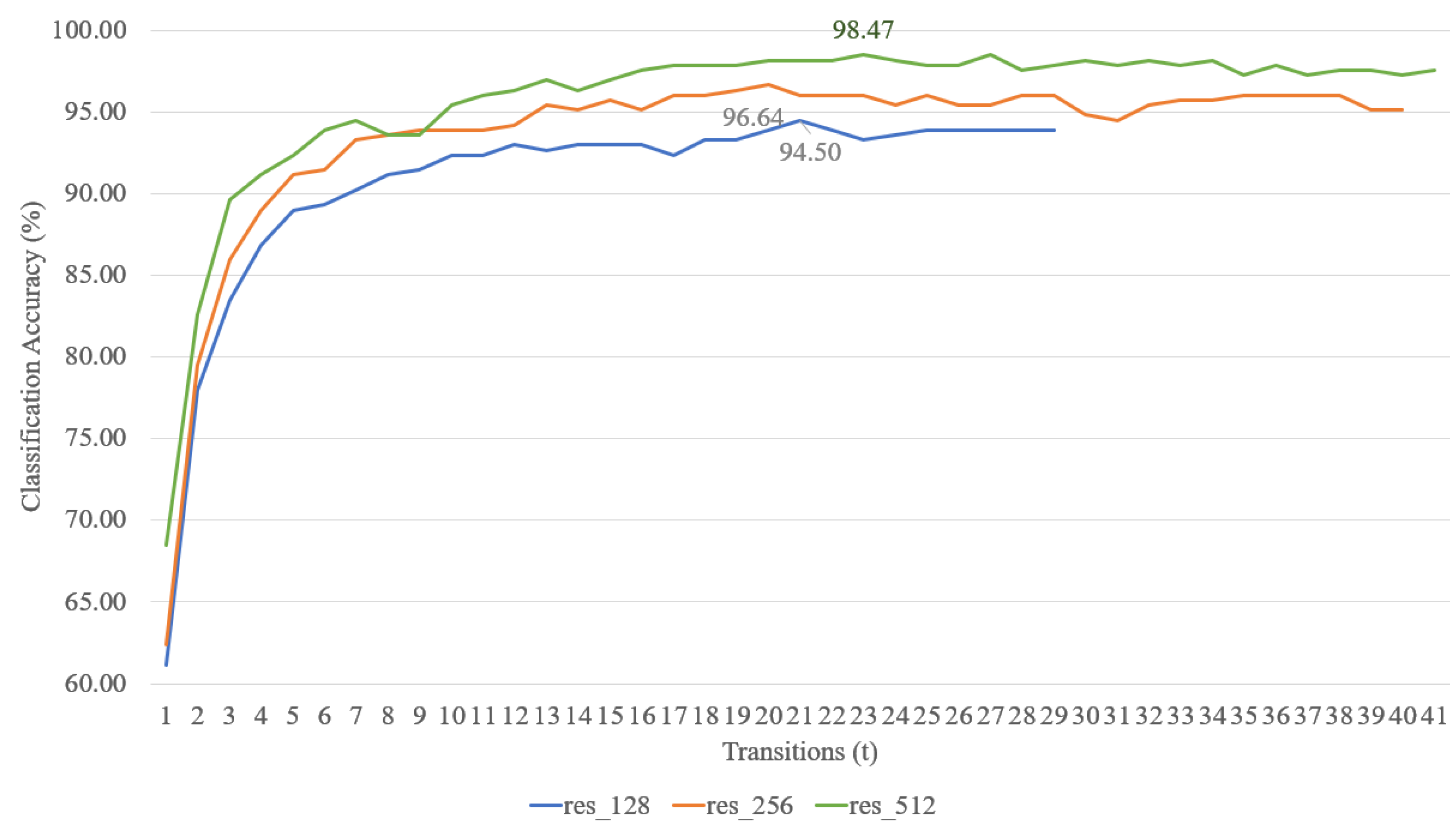
4.2. Classification Accuracy
4.3. Result of Feature Reduction
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Michel, P.; El Kaliouby, R. Real time facial expression recognition in video using support vector machines. In Proceedings of the 5th International Conference on Multimodal interfaces, Vancouver, BC, Canada, 5–7 November 2003. [Google Scholar]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef]
- Huang, Y.; Chen, F.; Lv, S.; Wang, X. Facial Expression Recognition: A Survey. Symmetry 2019, 11, 1189. [Google Scholar] [CrossRef]
- Liu, M.; Li, S.; Shan, S.; Chen, X. Au-inspired deep networks for facial expression feature learning. Neurocomputing 2015, 159, 126–136. [Google Scholar] [CrossRef]
- Lopes, A.T.; de Aguiar, E.; De Souza, A.F.; Oliveira-Santos, T. Facial expression recognition with convolutional neural networks: Coping with few data and the training sample order. Pattern Recognit. 2015, 61, 610–628. [Google Scholar] [CrossRef]
- Yang, H.; Zhang, Z.; Yin, L. Identity-adaptive facial expression recognition through expression regeneration using conditional generative adversarial networks. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition, Xi’an, China, 15–19 May 2018; pp. 294–301. [Google Scholar]
- Zhang, Z.; Luo, P.; Loy, C.C.; Tang, X. Facial landmark detection by deep multi-task learning. In European Conference on Computer Vision, Proceedings of the ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Tian, Y.-I.; Kanade, T.; Cohn, J.F. Recognizing action units for facial expression analysis. IEEE Trans. Panalysis Mach. Intell. 2001, 23, 97–115. [Google Scholar] [CrossRef] [PubMed]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the International Conference on Computer Vision & Pattern Recognition (CVPR ’05), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Dietterich, T.G.; Bakiri, G. Solving multiclass learning problems via error-correcting output codes. J. Artif. Intell. Res. 1994, 2, 263–286. [Google Scholar] [CrossRef]
- Fei, B.; Liu, J. Binary tree of SVM: A new fast multiclass training and classification algorithm. IEEE Trans. Neural Netw. 2006, 17, 696–704. [Google Scholar] [CrossRef] [PubMed]
- Übeyli, E.D. ECG beats classification using multiclass support vector machines with error correcting output codes. Digit. Signal Process. 2007, 17, 675–684. [Google Scholar] [CrossRef]
- Bellman, R. A Markovian decision process. J. Math. Mech. 1957, 6, 679–684. [Google Scholar] [CrossRef]
- Howard, R.A. Dynamic Programming and Markov Processe; John Wiley: New York, NY, USA, 1960. [Google Scholar]
- Shapley, L.S. Stochastic games. Proc. Natl. Acad. Sci. 1953, 39, 1095–1100. [Google Scholar] [CrossRef] [PubMed]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Lyons, M.J.; Akamatsu, S.; Kamachi, M.; Gyoba, J.; Budynek, J. The Japanese female facial expression (JAFFE) database. In Proceedings of the third International Conference on Automatic Face and Gesture Recognition, Nara, Japan, 14–16 April 1998. [Google Scholar]
- Lundqvist, D.; Flykt, A.; Öhman, A. The Karolinska directed emotional faces (KDEF). CD ROM Dep. Clin. Neurosci. Psychol. Sect. Karolinska Inst. 1998, 91, 2. [Google Scholar]
- Aifanti, N.; Papachristou, C.; Delopoulos, A. The MUG facial expression database. In Proceedings of the 11th International Workshop on Image Analysis for Multimedia Interactive Services WIAMIS 10, Desenzano del Garda, Italy, 12–14 April 2010. [Google Scholar]
- Olszanowski, M.; Pochwatko, G.; Kuklinski, K.; Scibor-Rylski, M.; Lewinski, P.; Ohme, R.K. Warsaw set of emotional facial expression pictures: A validation study of facial display photographs. Front. Psychol. 2015, 5, 1516. [Google Scholar] [CrossRef] [PubMed]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The extended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2001), Kauai, HI, USA, 8–14 December 2001; pp. 511–518. [Google Scholar]
- Mayya, V.; Pai, R.M.; Pai, M.M. Automatic facial expression recognition using DCNN. Procedia Comput. Sci. 2016, 93, 453–461. [Google Scholar] [CrossRef]
- Matthews, I.; Baker, S. Active appearance models revisited. Int. J. Comput. Vis. 2004, 60, 135–164. [Google Scholar] [CrossRef]
- Liu, P.; Han, S.; Meng, Z.; Tong, Y. Facial expression recognition via a boosted deep belief network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, GA, USA, 20–23 June 2014. [Google Scholar]
- Shan, C.; Gong, S.; McOwan, P.W. Facial expression recognition based on local binary patterns: A comprehensive study. Image Vis. Comput. 2009, 27, 803–816. [Google Scholar] [CrossRef]
- Li, K.; Jin, Y.; Akram, M.W.; Han, R.; Chen, J. Facial expression recognition with convolutional neural networks via a new face cropping and rotation strategy. Vis. Comput. 2019, 36, 391–404. [Google Scholar] [CrossRef]
- Pu, X.; Fan, K.; Chen, X.; Ji, L.; Zhou, Z. Facial expression recognition from image sequences using twofold random forest classifier. Neurocomputing 2015, 168, 1173–1180. [Google Scholar] [CrossRef]
- Zeng, N.; Zhang, H.; Song, B.; Liu, W.; Li, Y.; Dobaie, A.M. Facial expression recognition via learning deep sparse autoencoders. Neurocomputing 2018, 273, 643–649. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Classifier | Max Accuracy (%) | Optimal Cell Size | Feature Extraction (ms) | Total Time (ms) | Detection/s |
|---|---|---|---|---|---|---|
| HOG | kNN | 78.21 | 14 × 14 | 3.014 | 23.748 | 42.109 |
| HOG | ECOC | 97.44 | 10 × 10 | 3.366 | 16.565 | 60.368 |
| LBP | kNN | 73.08 | 12 × 12 | 3.290 | 48.101 | 20.790 |
| LBP | ECOC | 92.31 | 12 × 12 | 3.290 | 16.893 | 59.196 |
| Binary Tree | Classification Accuracy (%) | Total Time (s) |
|---|---|---|
| one vs. all (OVA) | 95.1047 | 122.90 |
| ordinal | 89.7907 | 166.31 |
| one vs. one (OVO) | 95.4911 | 62.35 |
| Depth | res_128 | res_256 | res_512 |
|---|---|---|---|
| 1 | 0 | 1 | 1 |
| 2 | 10 | 4 | 5 |
| 3 | 18 | 25 | 21 |
| 4 | 20 | 27 | 23 |
| 5 | 16 | 4 | 20 |
| Method | Bins | Total Time (s) | Classifying an Image (ms) |
|---|---|---|---|
| Basic | 4232 | 196.770 | 0.0602 |
| Proposed | 2912 | 130.520 | 0.0399 |
| Ratio to basic (%) | 68.81 | 66.33 | 66.28 |
| Basic Method | Proposed | |||
|---|---|---|---|---|
| Cell Size | Bins | Accuracy (%) | Bins | Accuracy (%) |
| 32 | 145 | 78.20 | 128 | 57.91 |
| 30 | 174 | 79.36 | 128 | 57.91 |
| 28 | 212 | 81.26 | 224 | 76.04 |
| 26 | 259 | 80.23 | 224 | 77.04 |
| 24 | 321 | 88.05 | 320 | 82.87 |
| 22 | 402 | 86.38 | 416 | 87.09 |
| 20 | 512 | 91.95 | 512 | 91.34 |
| 18 | 664 | 93.27 | 704 | 93.11 |
| 16 | 882 | 94.81 | 896 | 94.33 |
| 14 | 1208 | 95.14 | 1184 | 95.10 |
| 12 | 1721 | 95.33 | 1760 | 95.72 |
| 10 | 2592 | 95.39 | 2624 | 96.14 |
| 8 | 4232 | 95.97 | 2816 | 96.04 |
| 6 | 7854 | 95.75 | 2912 | 96.36 |
| 4 | 18432 | 95.62 | ... | … |
| 2 | 76832 | 94.98 | 3392 | 96.10 |
| Method | Validation | Accuracy (%) | ||
|---|---|---|---|---|
| Binary | Six Classes | Seven Classes | ||
| DCNN + SVM [23] | LOSO | 97.08 | 96.02 | |
| HOG + SVM [24] | LOSO | 96.40 | ||
| BDBN [25] | 8-fold | 96.70 | ||
| AUDN [4] | 10-fold | 95.78 | ||
| Lopes et al. [5] | 10-fold | 98.92 | 96.76 | 95.75 |
| LBP + SVM [26] | 10-fold | 95.10 | 91.40 | |
| Li et al. [27] | 10-fold | 98.18 | 97.38 | |
| Pu et al. [28] | 10-fold | 96.38 | ||
| Zeng et al. [29] | 10-fold | 95.79 | ||
| Proposed | 10-fold | 98.47 | ||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oh, S.-G.; Kim, T. Facial Expression Recognition by Regional Weighting with Approximated Q-Learning. Symmetry 2020, 12, 319. https://doi.org/10.3390/sym12020319
Oh S-G, Kim T. Facial Expression Recognition by Regional Weighting with Approximated Q-Learning. Symmetry. 2020; 12(2):319. https://doi.org/10.3390/sym12020319
Chicago/Turabian StyleOh, Seong-Gi, and TaeYong Kim. 2020. "Facial Expression Recognition by Regional Weighting with Approximated Q-Learning" Symmetry 12, no. 2: 319. https://doi.org/10.3390/sym12020319
APA StyleOh, S.-G., & Kim, T. (2020). Facial Expression Recognition by Regional Weighting with Approximated Q-Learning. Symmetry, 12(2), 319. https://doi.org/10.3390/sym12020319