Multi-Level P2P Traffic Classification Using Heuristic and Statistical-Based Techniques: A Hybrid Approach




Abstract
1. Introduction
- ability to classify P2P traffic with high accuracy.
- ability to work with both TCP and UDP protocols (since various P2P applications use either TCP or UDP or both protocols for communication).
- involves less computation in classifying P2P traffic (by not relying on the DPI approach for classification) in comparison to various existing hybrid techniques.
- ability to classify P2P traffic even if it is encrypted.
2. Related Work
3. Analysis of Existing P2P Traffic Classification Techniques
3.1. Port-Based Traffic Classification
3.2. Payload-Based Traffic Classification
- it involves a great amount of processing load and complexity.
- it is not feasible in high-speed networks as it needs a large amount of computational resources for inspecting the traffic.
- it is almost impossible to classify the network traffic if it contains a proprietary protocol or if the traffic is encrypted.
- it may violate privacy policies of some organizations which do not allow a direct inspection of packets.
3.3. Classification in the Dark
4. Multi-Level P2P Traffic Classification Technique
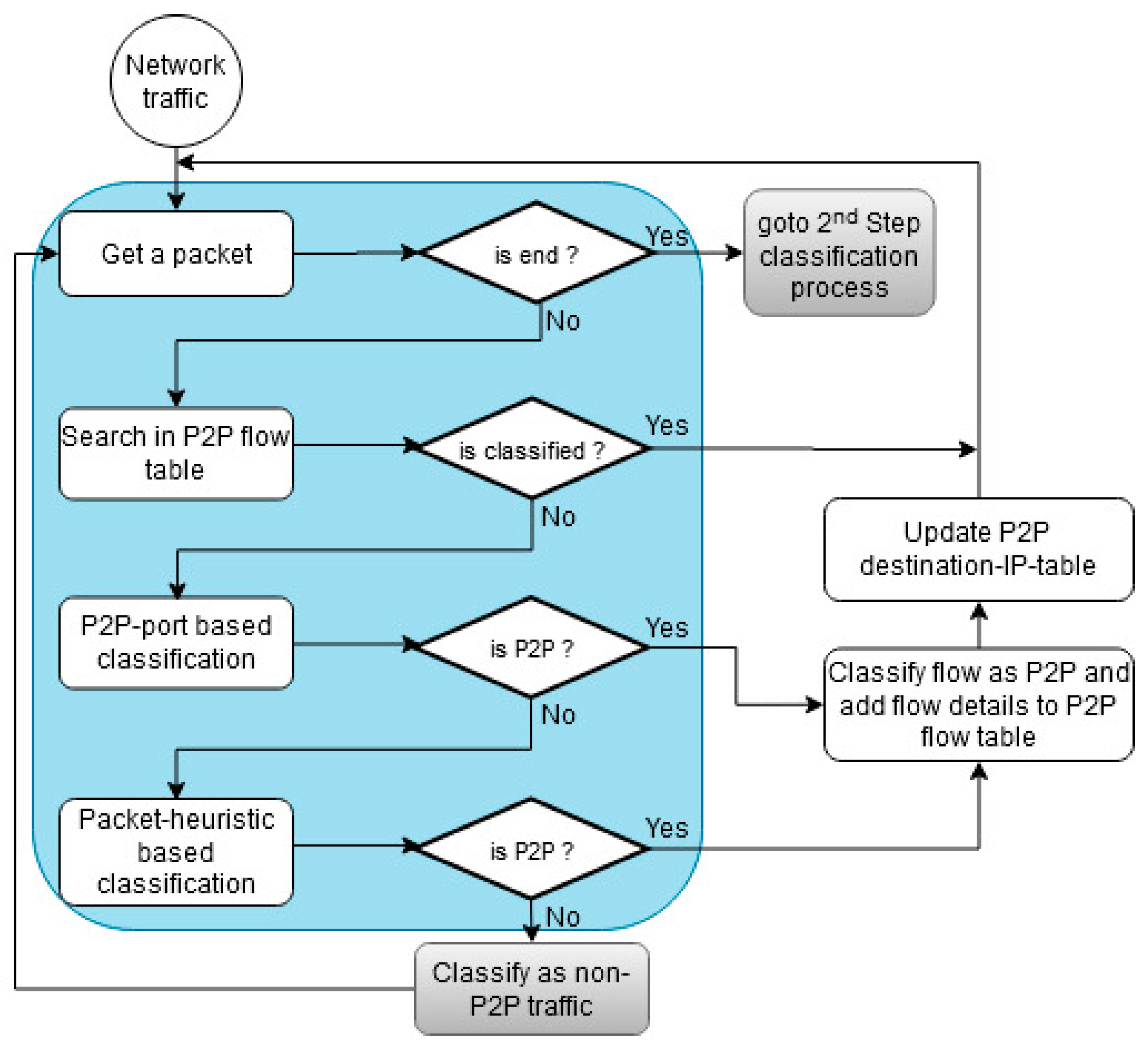
4.1. System Model for Classifying P2P Traffic
4.2. Packet-Level Classification Process (First Step)
4.2.1. P2P-Port Based Classification
4.2.2. Packet-Heuristic Based Classification
- (1)
- Usage of ephemeral port numbers: In order to communicate over a network, an application makes use of the transport-layer port number. The port numbers below 1024 are called well-known privileged port numbers, whereas port numbers above 1024 are called ephemeral port numbers. It is observed that many P2P applications (e.g., BitTorrent, VoIP, etc.) use ephemeral port numbers, whereas non-P2P applications (e.g., web, email, etc.) use well-known privileged port numbers for communication over the network. In client-server-based communication, the client uses an ephemeral port number (randomly chosen by the operating system) to communicate with the server and the server responds back with the requested data using a well-known port number. Therefore, if the source port and destination port of a packet are found to be ephemeral, then its flow is classified as P2P. However, this heuristic fails if a peer masquerades using the well-known port number (e.g., port 443 used by HTTPS) for communication.
- (2)
- Usage of TCP and UDP protocols simultaneously: It has been observed that most of the P2P applications such as Skype, Gnutella, etc. employ TCP and UDP protocols simultaneously for communication. Depending on the type of P2P application, TCP may be used for transferring the data, whereas UDP may be used for signaling messages and vice-versa [12,58]. For example, a Skype peer communicates with the super-peer using both TCP and UDP protocols. Therefore, if a source-IP uses TCP and UDP protocols simultaneously for communication with the destination-IP, then its flow is classified as P2P. However, some false positives may exist with this heuristic as there are some non-P2P applications such as streaming, IRC, gaming, etc. which exhibit a similar behavior [5].
- (3)
- Communication with destination-IP which is already classified as P2P: Prior to the communication between peers, a peer waits for the incoming connections from the other peers with the help of a listening port [59]. Figure 5 shows a scenario where peer-A (already classified as P2P) waits for incoming connections from the other peers. Its < IP, port > pair will act as the destination for all the other peers (i.e., peer-B, peer-C, peer-D, etc.) who want to communicate with it. Hence, the flows of all such peers are classified as P2P which communicate with the already classified P2P peer. For this purpose, we make use of the P2P destination-IP-table for storing < IP, port > pair information of those peers, which are already classified as P2P. While processing the packets, we analyze if either their source or destination < IP, port > pair maps with one of the records stored in the destination-IP-table, then the flows of such packets are also classified as P2P.
- (4)
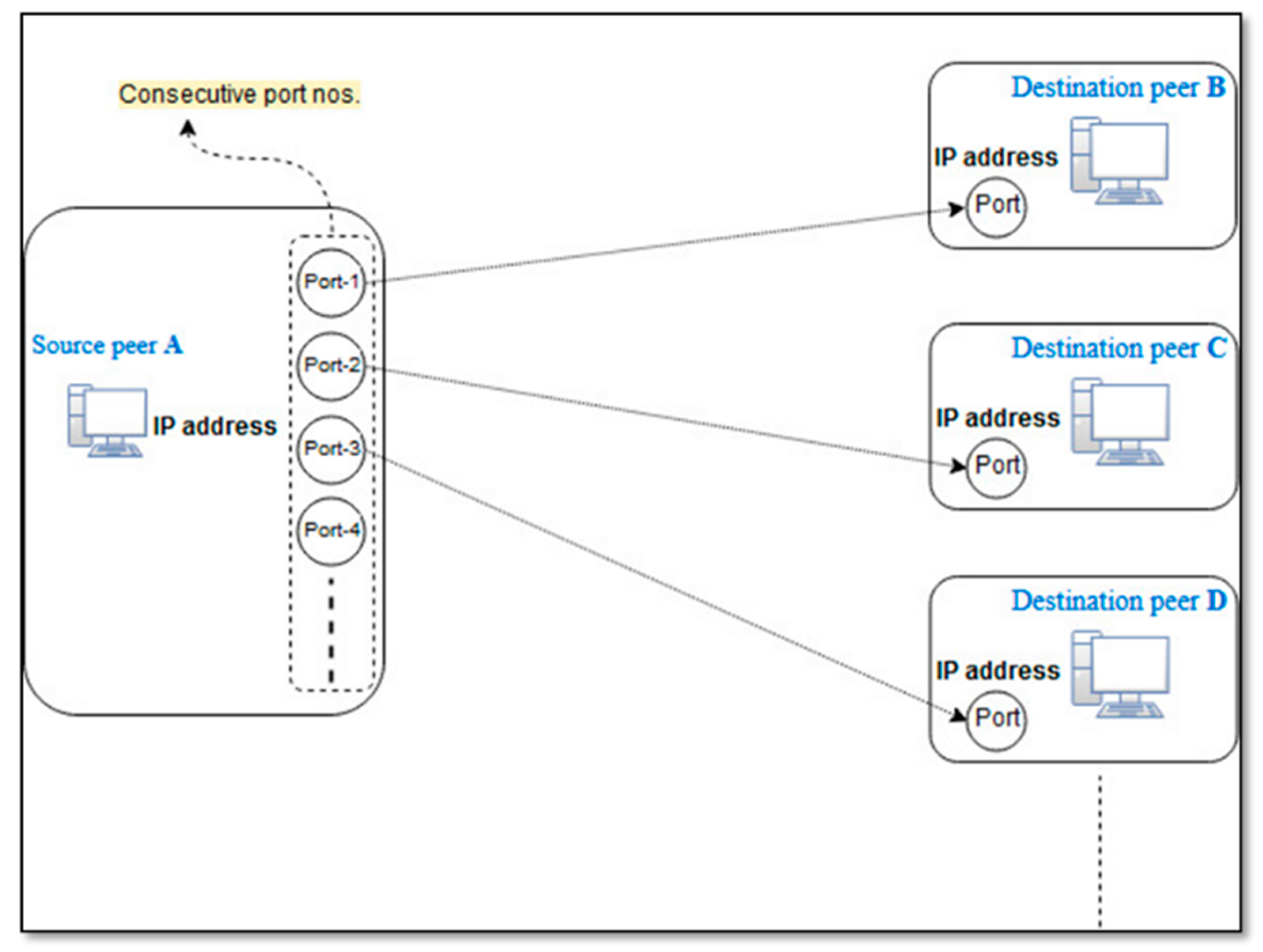
- Usage of consecutive port numbers: It has been observed that various P2P applications actively make a number of connections with the other peers for communication. In this case, the operating system of a peer allocates successive port numbers to the application (where the first port is randomly chosen and allocated) [60]. Figure 6 shows a scenario where the P2P source peer-A uses consecutive port numbers to communicate with the destination peers (i.e., peer-B, peer-C, peer-D, etc.). Therefore, we analyze that if a source-IP makes use of consecutive port numbers for communication, then its flows are classified as P2P.
| Algorithm 1: Packet-level classification process (first step). |
| Input: Network traffic packets |
| Output: Traffic-flows classified as P2P and non-P2P |
| pkt: Packet |
| ft: P2P_flow_table |
| fi: Flow_information |
| spn: Source_port_number |
| dpn: Destination_port_number |
| dit: Destination_IP_table |
| wkP: Well_known_P2P_ports |
| h1: Heuristic_1 |
| h2: Heuristic_2 |
| h3: Heuristic_3 |
| h4: Heuristic_4 |
| Begin |
| (1) pkt = fetch_packet() |
| (2) do |
| (3) { |
| (4) if (ft.contains (pkt.fi) |
| (5) goto step 15 |
| (6) else if (pkt.spn == wkP || pkt.dpn == wkP) |
| (7) { |
| (8) write: pkt.fi → P2P |
| (9) update: dit ← pkt.fi |
| (10) } |
| (11) else if ((pkt.h1 || pkt.h2 || pkt.h3 || pkt.h4) == true) |
| (12) write: pkt.fi → P2P |
| (13) else |
| (14) write: pkt.fi → non-P2P |
| (15) pkt = fetch_packet() |
| (16) } while (pkt ! = NULL) |
| (17) goto 2nd step classification process |
| End |
4.3. Flow-Level Classification Process (Second Step)
4.3.1. Flow-Heuristic Based Classification
4.3.2. Statistical Based Classification
- Packet inter-arrival time from source-to-destination
- Packet inter-arrival time from destination-to-source
- Duration of flow
- Total number of packets from source-to-destination
- Total number of packets from destination-to-source
- Total number of bytes of all packets
- Total packet bytes from source-to-destination
- Total packets bytes from destination-to-source
- Payload size of packets from source-to-destination
- Payload size of packets from destination-to-source
| Algorithm 2: Flow-level classification process (second step). |
| Input: Traffic-flows classified as non-P2P in the first step |
| Output: Traffic-flows classified as P2P and non-P2P |
| flw: Flow |
| ft: P2P_flow_table |
| fi: Flow_information |
| std: Data_transferred_from_source_to_destination |
| dts: Data_transferred_from_destination_to_source |
| thld: Data_threshold (3MB) |
| fh: Flow_heuristic = ((std + dts) > thld) |
| ff: Flow_features |
| MLA: Machine_learning_algorithm |
| rst: Result |
| Begin |
| (1) flw = fetch_flow() |
| (2) do |
| (3) { |
| (4) if (ft.contains (flw.fi)) |
| (5) goto step 17 |
| (6) else if (flw.fh == true) |
| (7) write: flw → P2P |
| (8) else |
| (9) { |
| (10) fset = flw.ff |
| (11) rst = flw.MLA (fset) |
| (12) if (rst == “P2P”) |
| (13) write: flw → P2P |
| (14) else |
| (15) write: flw → non-P2P |
| (16) } |
| (17) flw = fetch_flow() |
| (18) }while (flw ! = NULL) |
| End |
5. Verification
5.1. Evaluation Metrics
- (1)
- TP: Percentage of instances correctly categorized as belonging to a particular class.
- (2)
- TN: Percentage of instances correctly categorized as not belonging to a particular class.
- (3)
- False positive (FP): Percentage of instances incorrectly categorized as belonging to a particular class.
- (4)
- FN: Percentage of instances incorrectly categorized as not belonging to a particular class.
5.2. Datasets, Validation, and Experimental Results
6. Conclusions
- (1)
- It may produce some false positives (during the P2P-port based classification process) if the network traffic includes malicious applications using well-known P2P default ports that can be utilized by various P2P applications.
- (2)
- It does not perform a fine-grained classification to classify P2P traffic into specific applications.
- (3)
- It is made to work on offline datasets which consist of a limited number of P2P and non-P2P applications and hence, may produce some false positives (due to one of the proposed heuristics discussed in Section 3) when traffic datasets involve all kinds of P2P and non-P2P application protocols.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mohammadi, M.; Raahemi, B.; Akbari, A.; Moeinzadeh, H.; Nasersharif, B. Genetic-based minimum classification error mapping for accurate identifying Peer-to-Peer applications in the internet traffic. Expert Syst. Appl. 2011, 38, 6417–6423. [Google Scholar] [CrossRef]
- Sen, S.; Wang, J. Analyzing peer-to-peer traffic across large networks. ACM J. 2002, 12, 137–150. [Google Scholar]
- Dai, L.; Yang, J.; Lin, L. A comprehensive system for P2P classification. In Proceedings of the 2010 2nd IEEE International Conference on Network Infrastructure and Digital Content, Beijing, China, 24–26 September 2010. [Google Scholar]
- Chu, H.; Yi, H.; Zhang, X. A new P2P traffic identification methodology based on flow statistics. In Proceedings of the 2011 IEEE 3rd International Conference on Communication Software and Networks, Xi’an, China, 27–29 May 2011. [Google Scholar]
- Keralapura, R.; Nucci, A.; Chuah, C.-N. A novel self-learning architecture for p2p traffic classification in high speed networks. Comput. Netw. 2010, 54, 1055–1068. [Google Scholar] [CrossRef]
- Gomes, J.V.; Inácio, P.R.M.; Pereira, M.; Freire, M. Detection and classification of peer-to-peer traffic: A survey. ACM Comput. Surv. 2013, 45. [Google Scholar] [CrossRef]
- Bhatia, M.; Kumar, R.M. Identifying P2P traffic: A survey. Peer-to-Peer Netw. Appl. 2016, 10, 1182–1203. [Google Scholar] [CrossRef]
- Karagiannis, T.; Papagiannaki, K.; Faloutsos, M. BLINC: Multilevel traffic classification in the dark. ACM SIGCOMM Comput. Commun. Rev. 2005, 35, 229–240. [Google Scholar] [CrossRef]
- Turkett, W.H., Jr.; Karode, A.V.; Fulp, E.W. In-the-dark network traffic classification using support vector machines. AAAI 2008, 3, 1745–1750. [Google Scholar]
- Global Internet Phenomena, Sandvine. 2019. Available online: https://www.sandvine.com/phenomena (accessed on 10 February 2020).
- Controlling P2P Traffic. 2003. Available online: https://www.lightreading.com/controlling-p2p-traffic/d/d-id/598203&page_number=2 (accessed on 21 September 2020).
- Reddy, J.M.; Hota, C. Heuristic-Based Real-Time P2P Traffic Identification. In Proceedings of the 2015 International Conference on Emerging Information Technology and Engineering Solutions, Pune, India, 20–21 February 2015. [Google Scholar]
- Bozdogan, C.; Gokcen, Y.; Zincir, I. A Preliminary Investigation on the Identification of Peer to Peer Network Applications. In Proceedings of the Companion Publication of the 2015 on Genetic and Evolutionary Computation Conference—GECCO Companion ’15, Madrid, Spain, 11–15 July 2015. [Google Scholar]
- Tseng, C.-M.; Huang, G.-T.; Liu, T.-J. P2P traffic classification using clustering technology. In Proceedings of the 2016 IEEE/SICE International Symposium on System Integration (SII), Sapporo, Japan, 13–15 December 2016. [Google Scholar]
- Chuan, L.; Wang, C.; Jixiong, H.; Ye, Z. Peer to peer traffic identification using support vector machine and bat-inspired optimization algorithm. In Proceedings of the 2017 12th International Conference on Computer Science and Education (ICCSE), Houston, TX, USA, 22–25 August 2017. [Google Scholar]
- Ali, B.M.; Jamil, H.A.; Hamdan, M.; Bassi, J.S.; Ismail, I.; Marsono, M.N. Multi-stage feature selection for on-line flow peer-to-peer traffic identification. In Proceedings of the Asian Simulation Conference, Melaka, Malaysia, 27–29 August 2017. [Google Scholar]
- Jamil, H.A.; Ali, B.M.; Hamdan, M.; Osman, A.E. Online P2P Internet Traffic Classification and Mitigation Based on Snort and ML. Eur. J. Eng. Res. Sci. 2019, 4, 131–137. [Google Scholar] [CrossRef]
- Nazari, Z.; Noferesti, M.; Jalili, R. DSCA: An inline and adaptive application identification approach in encrypted network traffic. In Proceedings of the 3rd International Conference on Cryptography, Security and Privacy, Kuala Lumpur, Malaysia, 19–21 January 2019. [Google Scholar]
- Ye, W.; Cho, K. Two-Step P2P Traffic Classification with Connection Heuristics. In Proceedings of the 2013 Seventh International Conference on Innovative Mobile and Internet Services in Ubiquitous Computing, Taichung, Taiwan, 3–5 July 2013. [Google Scholar]
- Ye, W.; Cho, K. Hybrid P2P traffic classification with heuristic rules and machine learning. Soft Comput. 2014, 18, 1815–1827. [Google Scholar] [CrossRef]
- Ye, W.; Cho, K. P2P and P2P botnet traffic classification in two stages. Soft Comput. 2015, 21, 1315–1326. [Google Scholar] [CrossRef]
- Khan, R.U.; Kumar, R.; Alazab, M.; Zhang, X. A Hybrid Technique To Detect Botnets, Based on P2P Traffic Similarity. In Proceedings of the 2019 Cybersecurity and Cyberforensics Conference (CCC), Melbourne, Australia, 8–9 May 2019. [Google Scholar]
- Service Name and Transport Protocol Port Number Registry. Available online: https://www.iana.org/assignments/service-names-port-numbers/service-names-port-numbers.xhtml (accessed on 11 July 2020).
- Roughan, M.; Sen, S.; Spatscheck, O.; Duffield, N. Class of service mapping for QoS: A statistical signature-based approach to IP traffic classification. In Proceedings of the 4th ACM SIGCOMM Conference on Internet Measurement, Taormina Sicily, Italy, 25–27 October 2004. [Google Scholar]
- Zuev, D.; Moore, A.W. Traffic classification using a statistical approach. In International Workshop on Passive and Active Network Measurement; Springer: Berlin/Heidelberg, Germany, 2005; pp. 321–324. [Google Scholar]
- Moore, A.W.; Papagiannaki, K. Toward the accurate identification of network applications. In International Workshop on Passive and Active Network Measurement; Springer: Berlin/Heidelberg, Germany, 2005; pp. 41–54. [Google Scholar]
- Karagiannis, T.; Broido, A.; Brownlee, N.; Claffy, K.C.; Faloutsos, M. Is p2p dying or just hiding? [p2p traffic measurement]. In Proceedings of the IEEE Global Telecommunications Conference, Dallas, TX, USA, 29 November–3 December 2004. [Google Scholar]
- Madhukar, A.; Williamson, C. A longitudinal study of P2P traffic classification. In Proceedings of the 14th IEEE International Symposium on Modeling, Analysis, and Simulation, Monterey, CA, USA, 11–14 September 2006. [Google Scholar]
- Karagiannis, T.; Broido, A.; Brownlee, N.; Claffy, K.; Faloutsos, M. File-Sharing in the Internet: A Characterization of P2P Traffic in the Backbone; University of California: Riverside, CA, USA, 2003. [Google Scholar]
- Liu, S.-M.; Sun, Z. Active learning for P2P traffic identification. Peer-to-Peer Netw. Appl. 2015, 8, 733–740. [Google Scholar] [CrossRef]
- Gomes, J.V.P.; Inácio, P.R.M.; Freire, M.M.; Pereira, M.; Monteiro, P.P. Analysis of Peer-to-Peer Traffic Using a Behavioural Method Based on Entropy. In Proceedings of the 2008 IEEE International Performance, Computing and Communications Conference, Austin, TX, USA, 7–9 December 2008. [Google Scholar]
- Perényi, M.; Dang, T.D.; Gefferth, A.; Molnár, S. Identification and Analysis of Peer-to-Peer Traffic. J. Commun. 2006, 1, 36–46. [Google Scholar] [CrossRef]
- Yan, J.; Wu, Z.; Luo, H.; Zhang, S. P2P Traffic Identification Based on Host and Flow Behaviour Characteristics. Cybern. Inf. Technol. 2013, 13, 64–76. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, L.; Yuan, Z.; Xue, Y.; Dong, Y. Characterizing Application Behaviors for classifying P2P traffic. In Proceedings of the 2014 International Conference on Computing, Networking and Communications (ICNC), Honolulu, HI, USA, 3–6 February 2014. [Google Scholar]
- Zhang, Q.; Ma, Y.; Zhang, P.; Wang, J.; Li, X. Netflow based P2P detection in UDP traffic. In Proceedings of the Fifth International Conference on Intelligent Control and Information Processing, Dalian, China, 18–20 August 2014. [Google Scholar]
- Sun, M.-F.; Chen, J.-T. Research of the traffic characteristics for the real time online traffic classification. J. China Univ. Posts Telecommun. 2011, 18, 92–98. [Google Scholar] [CrossRef]
- Gong, J.; Wang, W.; Wang, P.; Sun, Z. P2P traffic identification method based on an improvement incremental SVM learning algorithm. In Proceedings of the 2014 International Symposium on Wireless Personal Multimedia Communications (WPMC), Sydney, NSW, Australia, 7–10 September 2014. [Google Scholar]
- Deng, S.; Luo, J.; Liu, Y.; Wang, X.; Yang, J. Ensemble learning model for P2P traffic identification. In Proceedings of the 2014 11th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD), Xiamen, China, 19–21 August 2014. [Google Scholar]
- Qin, T.; Wang, L.; Zhao, D.; Zhu, M. CUFTI: Methods for core users finding and traffic identification in P2P systems. Peer-to-Peer Netw. Appl. 2015, 9, 424–435. [Google Scholar] [CrossRef]
- He, J.; Yang, Y.; Qiao, Y.; Deng, W.-P. Fine-grained P2P traffic classification by simply counting flows. Front. Inf. Technol. Electron. Eng. 2015, 16, 391–403. [Google Scholar] [CrossRef]
- Ertam, F.; Avcı, E. A new approach for internet traffic classification: GA-WK-ELM. Measurement 2017, 95, 135–142. [Google Scholar] [CrossRef]
- Sun, G.; Liang, L.; Chen, T.; Xiao, F.; Lang, F. Network traffic classification based on transfer learning. Comput. Electr. Eng. 2018, 69, 920–927. [Google Scholar] [CrossRef]
- Lim, H.-K.; Kim, J.-B.; Heo, J.-S.; Kim, K.; Hong, Y.-G.; Han, Y.-H. Packet-based network traffic classification using deep learning. In Proceedings of the 2019 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Okinawa, Japan, 11–13 February 2019. [Google Scholar]
- Park, S.; Chung, H.; Lee, C.; Lee, S.; Lee, K. Methodology and implementation for tracking the file sharers using BitTorrent. Multimedia Tools Appl. 2013, 74, 271–286. [Google Scholar] [CrossRef]
- Cruz, M.; Ocampo, R.; Montes, I.; Atienza, R. Fingerprinting BitTorrent Traffic in Encrypted Tunnels Using Recurrent Deep Learning. In Proceedings of the 2017 Fifth International Symposium on Computing and Networking (CANDAR), Aomori, Japan, 19–22 November 2017. [Google Scholar]
- Jiang, Q.; Hu, H.; Hu, G. Real-Time Identification of Users under the New Structure of Skype. In Proceedings of the 2016 IEEE International Conference on Sensing, Communication and Networking (SECON Workshops), London, UK, 27–27 June 2016. [Google Scholar]
- Munir, S.; Majeed, N.; Babu, S.; Bari, I.; Harry, J.; Masood, Z.A. A joint port and statistical analysis based technique to detect encrypted VoIP traffic. Int. J. Comput. Sci. Inf. Secur. 2016, 14, 117. [Google Scholar]
- Lee, S.-H.; Goo, Y.-H.; Park, J.-T.; Ji, S.-H.; Kim, M.-S. Sky-Scope: Skype application traffic identification system. In Proceedings of the 2017 19th Asia-Pacific Network Operations and Management Symposium (APNOMS), Seoul, Korea, 27–29 September 2017. [Google Scholar]
- Di Mauro, M.; Di Sarno, C. Improving SIEM capabilities through an enhanced probe for encrypted Skype traffic detection. J. Inf. Secur. Appl. 2018, 38, 85–95. [Google Scholar] [CrossRef]
- Saqib, N.A.; Shakeel, Y.; Khan, M.A.; Mahmood, H.; Zia, M. An effective empirical approach to VoIP traffic classification. Turk. J. Electr. Eng. Comput. Sci. 2017, 25, 888–900. [Google Scholar] [CrossRef]
- Wang, R.; Zhang, J.; Zhang, Y.; Yin, M.; Xu, J. A Real-Time Identification System for VoIP Traffic in Large-Scale Networks. In Proceedings of the 2019 IEEE 21st International Conference on High Performance Computing and Communications; IEEE 17th International Conference on Smart City; IEEE 5th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Zhangjiajie, China, 10–12 August 2019. [Google Scholar]
- Li, J.; Zhang, S.; Lu, Y.; Yan, J. Hybrid internet traffic classification technique. J. Electron. 2009, 26, 101–112. [Google Scholar] [CrossRef]
- Chen, Z.; Yang, B.; Chen, Y.; Abraham, A.; Groşan, C.; Peng, L. Online hybrid traffic classifier for Peer-to-Peer systems based on network processors. Appl. Soft Comput. 2009, 9, 685–694. [Google Scholar] [CrossRef][Green Version]
- Nair, L.M.; Sajeev, G.P. Internet Traffic Classification by Aggregating Correlated Decision Tree Classifier. In Proceedings of the 2015 Seventh International Conference on Computational Intelligence, Modelling and Simulation (CIMSim), Kuantan, Malaysia, 27–29 July 2015. [Google Scholar]
- Sajeev, G.P.; Nair, L.M. LASER: A novel hybrid peer to peer network traffic classification technique. In Proceedings of the 2016 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Jaipur, India, 21–24 September 2016. [Google Scholar]
- jNetPcap. Available online: https://sourceforge.net/projects/jnetpcap/ (accessed on 10 August 2020).
- Weka. Available online: https://www.cs.waikato.ac.nz/ml/weka (accessed on 10 August 2020).
- Velan, P.; Čermák, M.; Čeleda, P.; Drašar, M. A survey of methods for encrypted traffic classification and analysis. Int. J. Netw. Manag. 2015, 25, 355–374. [Google Scholar] [CrossRef]
- Karagiannis, T.; Broido, A.; Faloutsos, M.; Claffy, K. Transport layer identification of P2P traffic. In Proceedings of the 4th ACM SIGCOMM Conference on Internet Measurement, Taormina Sicily, Italy, 25–27 October 2004. [Google Scholar]
- Lu, C.-N.; Huang, C.-Y.; Lin, Y.-D.; Lai, Y.-C. Session level flow classification by packet size distribution and session grouping. Comput. Netw. 2012, 56, 260–272. [Google Scholar] [CrossRef]
- Nguyen, T.T.T.; Armitage, G. A survey of techniques for internet traffic classification using machine learning. IEEE Commun. Surv. Tutor. 2008, 10, 56–76. [Google Scholar] [CrossRef]
- Gringoli, F.; Salgarelli, L.; Dusi, M.; Cascarano, N.; Risso, F. Gt: Picking up the truth from the ground for internet traffic. ACM SIGCOMM Comput. Commun. Rev. 2009, 39, 12–18. [Google Scholar] [CrossRef]
- Dusi, M.; Gringoli, F.; Salgarelli, L. Quantifying the accuracy of the ground truth associated with Internet traffic traces. Comput. Netw. 2011, 55, 1158–1167. [Google Scholar] [CrossRef]
- Wireshark. Available online: https://www.wireshark.org (accessed on 10 August 2020).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Protocols | TCP/UDP Port Numbers |
|---|---|
| BitTorrent | 6881–6999 |
| Direct Connect | 411, 412, 1025–32,000 |
| eDonkey | 2323, 3306, 4242, 4500, 4501, 4661–4674, 4677, 4678, 4711, 4712, 7778 |
| FastTrack | 1214, 1215, 1331, 1337, 1683, 4329 |
| Yahoo (messages/video/voice) | 5000–5010, 5050, 5100 |
| Napster | 5555, 6257, 6666, 6677, 6688, 6699–6701 |
| MSN (voice/file-transfer) | 1863, 6891–6901 |
| MP2P | 10,240–20,480, 22,321, 41,170 |
| Kazaa | 1214 |
| Gnutella | 6346–6347 |
| ARES Galaxy | 32285 |
| AIM (messages/video) | 1024–5000, 5190 |
| Dataset | P2P (No. of Flows) | Non-P2P (No. of Flows) | Total |
|---|---|---|---|
| Dataset-1 | 20,617 | 48,179 | 68,796 |
| Dataset-2 | 3881 | 2892 | 6773 |
| Protocol | Packets | Bytes |
|---|---|---|
| POP3 | 13,647 | 918,878 |
| IMAP | 3191 | 213,554 |
| HTTP | 1,399,230 | 92,060,704 |
| BitTorrent | 379,836 | 329,477,265 |
| SSH | 2,586,027 | 141,334,606 |
| RTMP | 11,712 | 779,616 |
| Dropbox | 6498 | 429,308 |
| StarCraft | 7 | 394 |
| FTP_CONTROL | 19 | 1274 |
| Telnet | 90 | 6132 |
| SOCKS | 2487 | 139,650 |
| Skype | 30 | 3657 |
| Others | 402,357 | 26,674,298 |
| Classification Process | Accuracy (%) |
|---|---|
| P | 11.90 |
| P + PH | 90.50 |
| P + PH + FH | 95.10 |
| P + PH + FH + S | 98.30 |
| Ref | Studies | First Step Classification | Second Step Classification | Accuracy (%) |
|---|---|---|---|---|
| [53] | Chen et al. (2009) | Static feature-based (port, signature, pattern) | Flexible neural tree-based | 95.65 |
| [52] | Li et al. (2009) | Coarse-grained (C4.5 decision tree) | Fine-grained (signature, port) | 96.03 |
| [5] | Keralapura et al. (2010) | TCM pattern | signature | 95.00 |
| [19] | Ye and Cho (2013) | Signature, connection heuristics | C4.5 decision tree | 97.46 |
| [20] | Ye and Cho (2014) | Signature, connection heuristics | REPTree, pattern heuristics | 98.19 |
| [55] | Sajeev and Nair (2016) | Signature | C4.5 decision tree | 96.00 |
| [21] | Ye and Cho (2017) | At packet-level: Signature, connection heuristics At flow-level: REPTree, pattern heuristics | REPTree | 97.70 |
| [22] | Khan et al. (2019) | Port filtering, DNS query filtering, flow counting | Decision tree | 94.40 |
| Proposed hybrid technique | port, packet-level heuristics | Flow-level heuristics, C4.5 decision tree | 98.30 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bhatia, M.; Sharma, V.; Singh, P.; Masud, M. Multi-Level P2P Traffic Classification Using Heuristic and Statistical-Based Techniques: A Hybrid Approach. Symmetry 2020, 12, 2117. https://doi.org/10.3390/sym12122117
Bhatia M, Sharma V, Singh P, Masud M. Multi-Level P2P Traffic Classification Using Heuristic and Statistical-Based Techniques: A Hybrid Approach. Symmetry. 2020; 12(12):2117. https://doi.org/10.3390/sym12122117
Chicago/Turabian StyleBhatia, Max, Vikrant Sharma, Parminder Singh, and Mehedi Masud. 2020. "Multi-Level P2P Traffic Classification Using Heuristic and Statistical-Based Techniques: A Hybrid Approach" Symmetry 12, no. 12: 2117. https://doi.org/10.3390/sym12122117
APA StyleBhatia, M., Sharma, V., Singh, P., & Masud, M. (2020). Multi-Level P2P Traffic Classification Using Heuristic and Statistical-Based Techniques: A Hybrid Approach. Symmetry, 12(12), 2117. https://doi.org/10.3390/sym12122117