Lifelong Machine Learning for Regional-Based Image Classification in Open Datasets



Abstract
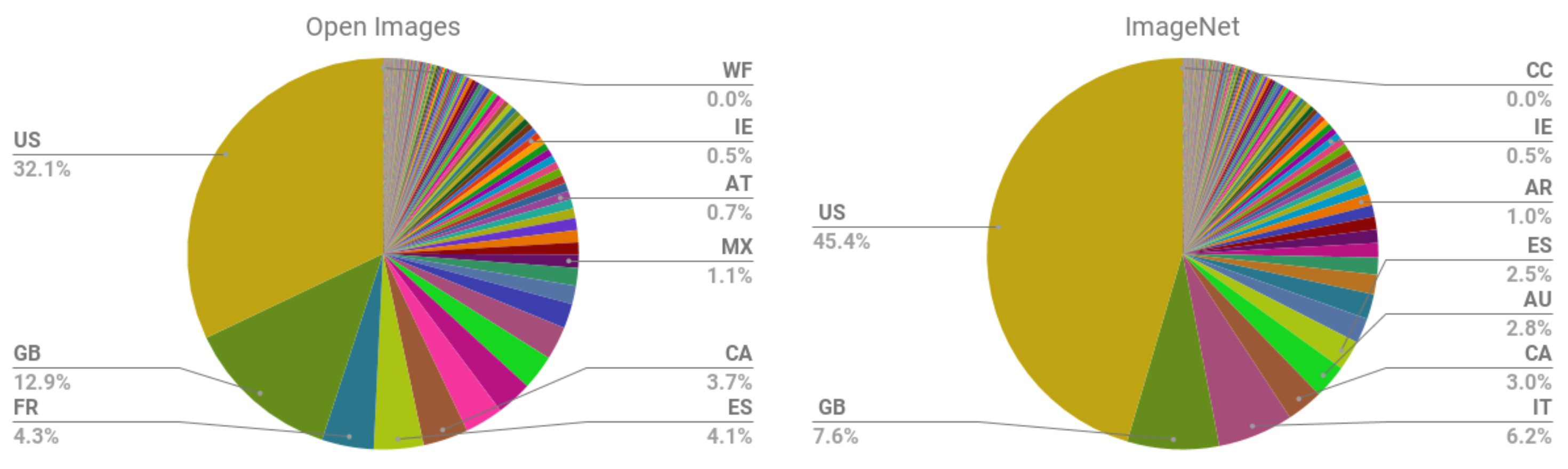
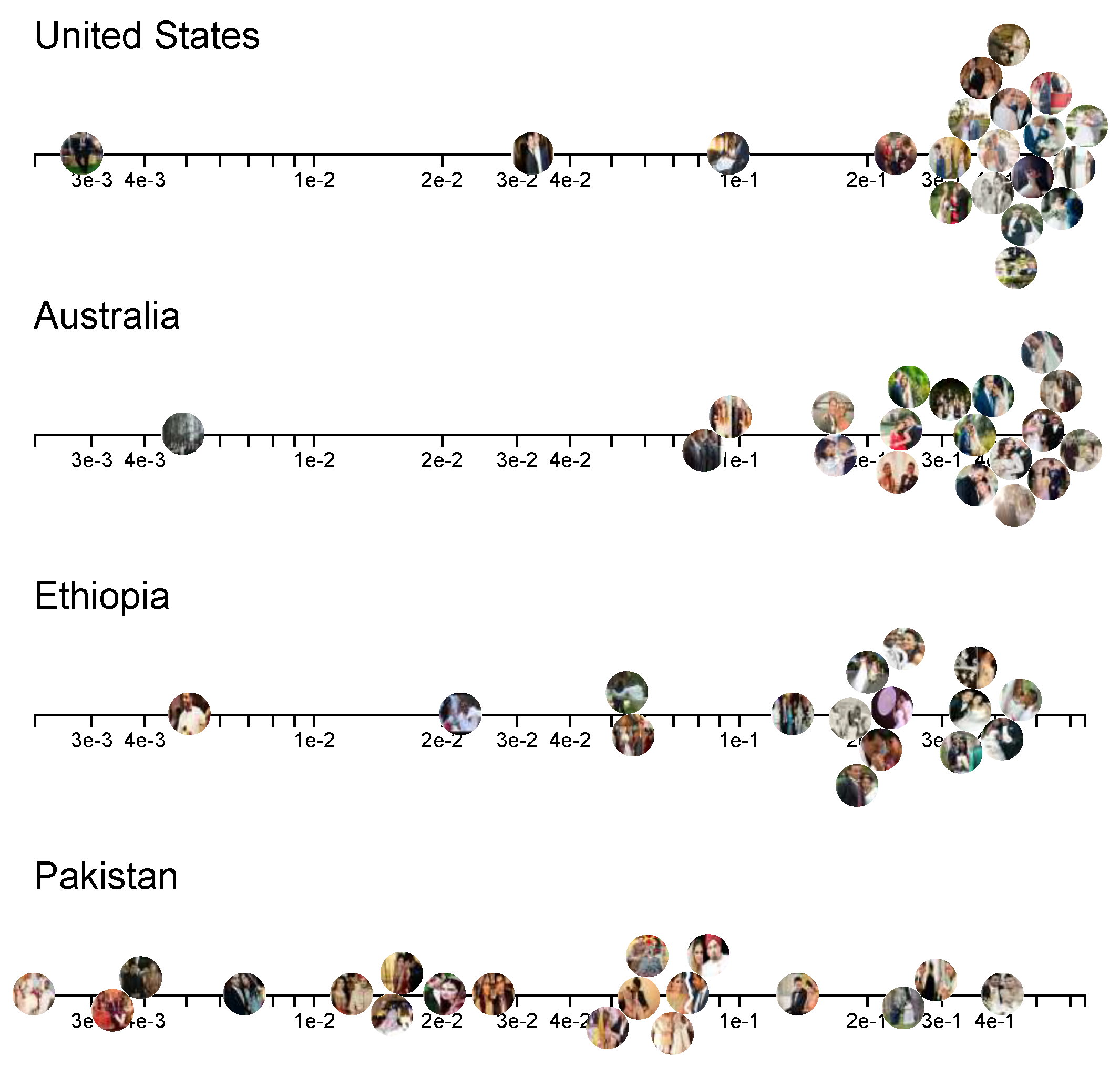
:1. Introduction
2. Literature Study
3. Proposed Methodology
3.1. Preprocessing Analysis
3.2. Normalization
3.3. Image Classification Models
3.3.1. LeNet, ResNet and Inception
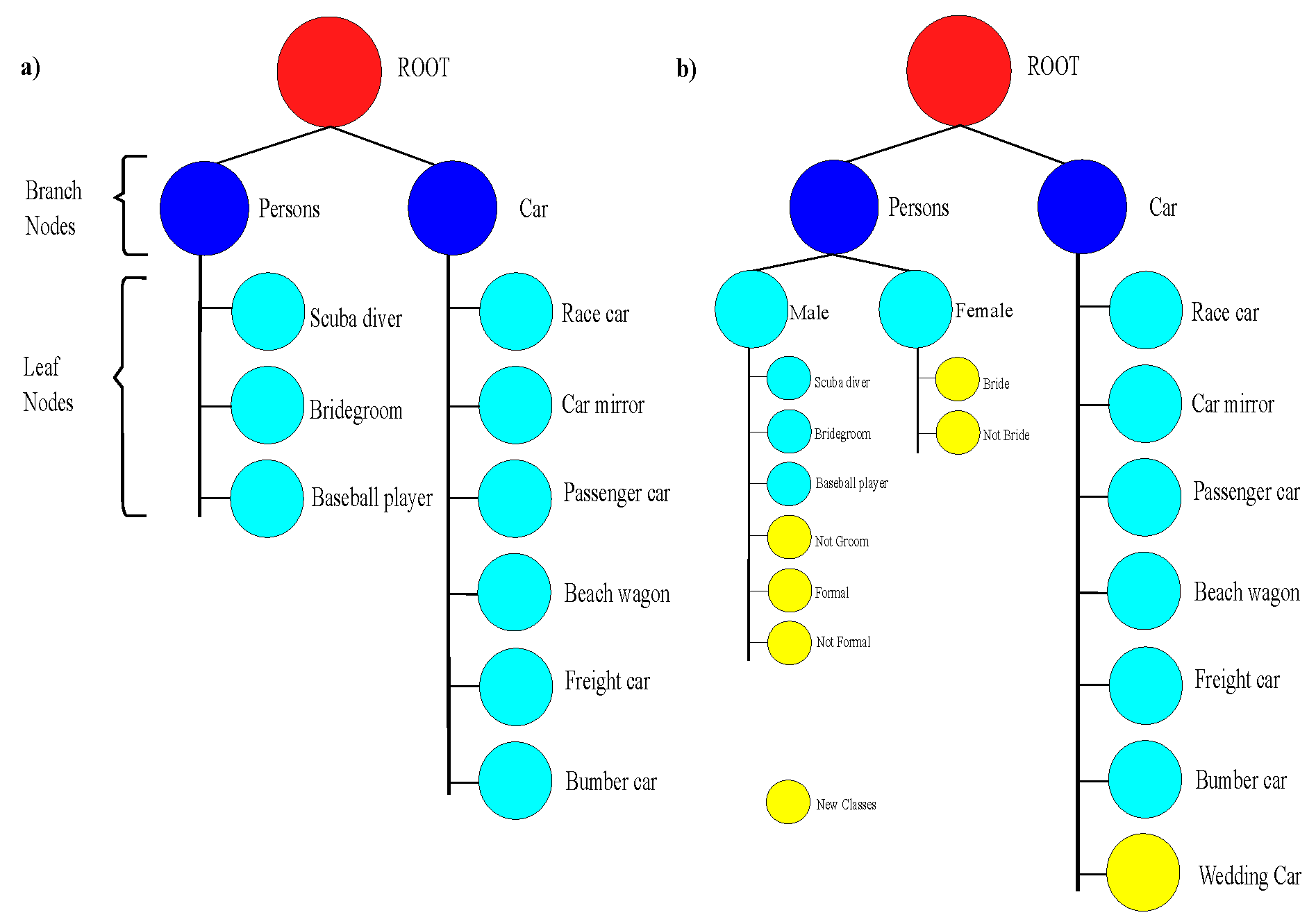
3.3.2. Tree-CNN
- The list consists of M objects and corresponds to M new classes.
- Every object S[i] has the following features:
- -
- The label of new class is stored in S[i].label
- -
- The top 3 average softmax () output values are stored in S[i].values as a vector [v1, v2, v3] where
- -
- The nodes corresponding to the softmax values are stored in S[i].nodes.
- S is ordered in the descending order of S[i].value[1]
- Addition of newly created class to already present node: If is larger than by the threshold , it shows a high correlation with that child node. Therefore, the newly created class is combined with the child node .
- Merging children nodes to create a new node and added the newly created class to the node: In case of larger than one children nodes where the newly created class have high probability for, we can combine them to form a new node. This is possible when and , where and are threshold values provided by user.
- Add newly created class as a new node: In case the newly created class does not have a probability that is larger than the other values by a threshold ) or all children nodes are full, Tree-CNN grows horizontally when new classes are added as a new child node. The node becomes a leaf node to make classification of class.
| Algorithm 1: Algorithm of Tree-CNN |
 |
4. Simulation
4.1. Configuration of Machine
4.2. CNN Architectures Trained on Wedding Dataset
4.3. Accuracy of CNN Models in Train and Test Dataset
4.4. Performance in Terms of Accuracy, Precision, Recall and F1-Score
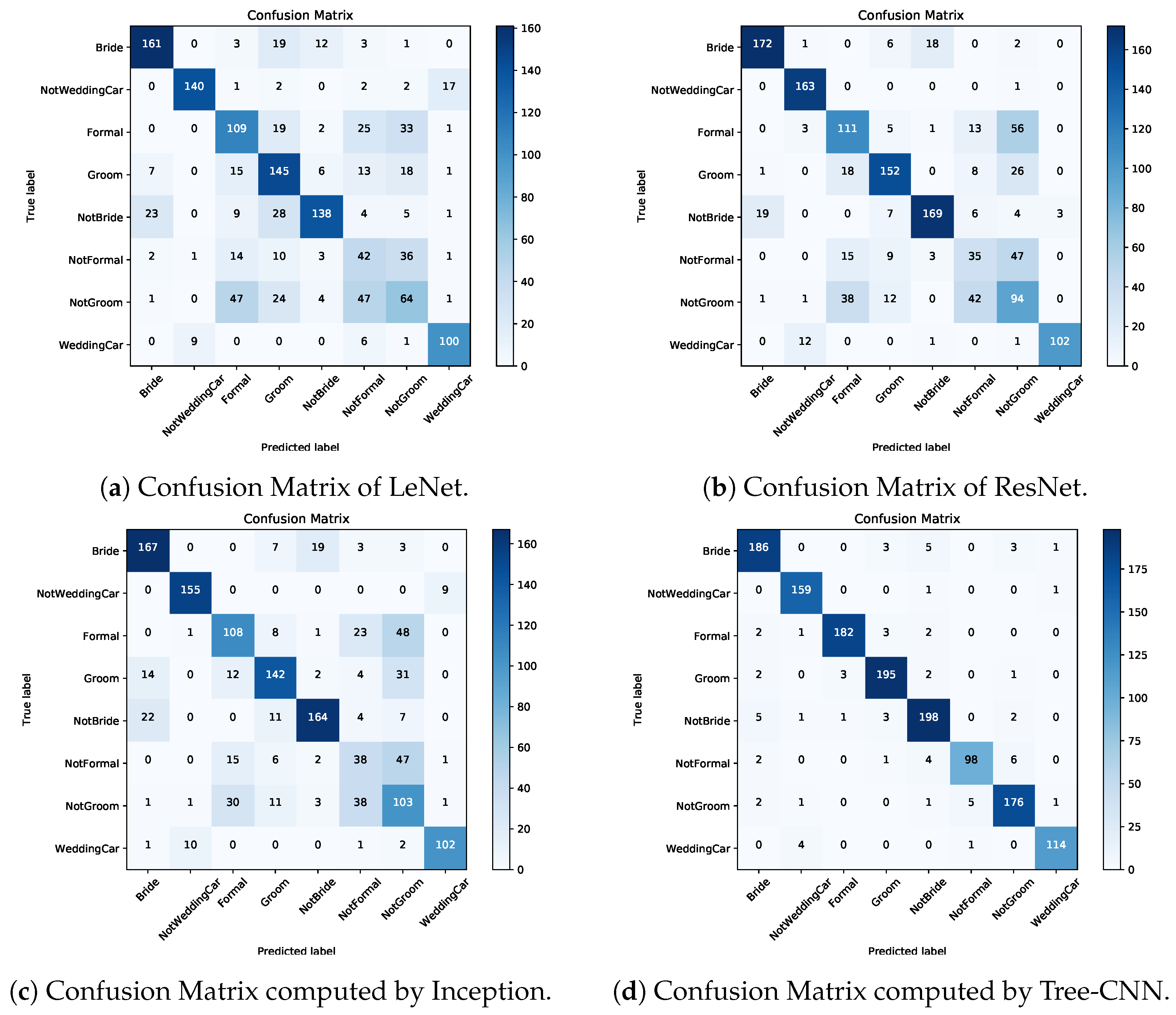
4.5. Confusion Matrix
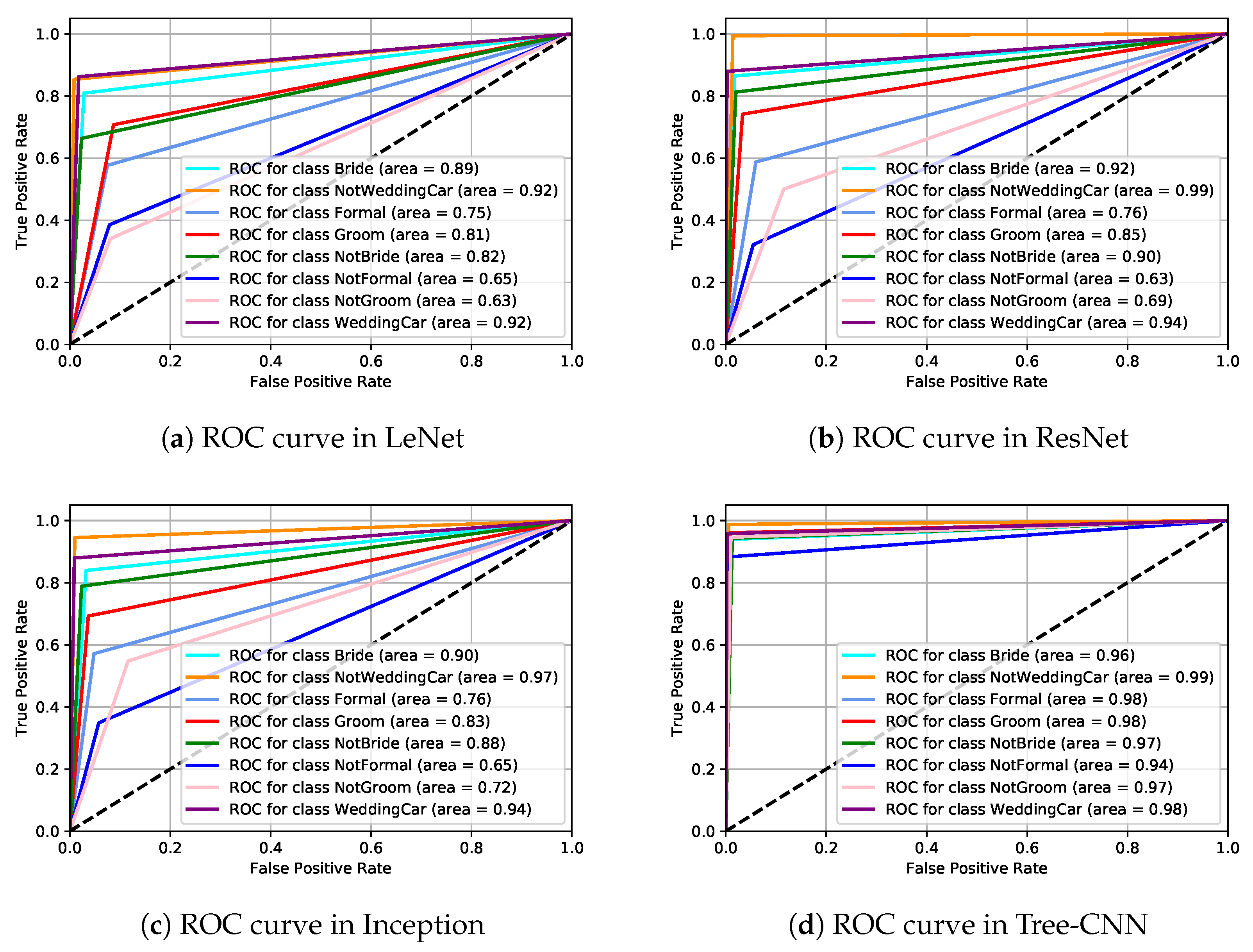
4.6. Evaluation with ROC Curve
4.7. Prediction of Labels by Different Models
4.8. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Shankar, S.; Halpern, Y.; Breck, E.; Atwood, J.; Wilson, J.; Sculley, D. No Classification without Representation: Assessing Geodiversity Issues in Open Data Sets for the Developing World. arXiv 2017, arXiv:1711.08536. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef] [Green Version]
- Lawrence, S.; Giles, C.; Tsoi, A.; Back, A. Face recognition: A convolutional neural-network approach. IEEE Trans. Neural Netw. Learn. Syst. 1997, 8, 98–113. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bobić, V.N.; Tadić, P.R.; Kvascev, G. Hand gesture recognition using neural network based techniques. In Proceedings of the 2016 13th Symposium on Neural Networks and Applications (NEUREL), Belgrade, Serbia, 22–24 November 2016; pp. 1–4. [Google Scholar]
- Gu, J.; Wang, G.; Cai, J.; Chen, T. An Empirical Study of Language CNN for Image Captioning. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1231–1240. [Google Scholar] [CrossRef] [Green Version]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Awasthi, A.; Sarawagi, S. Continual Learning with Neural Networks: A Review. In Proceedings of the ACM India Joint International Conference on Data Science and Management of Data, Kolkata, India, 3–5 January 2019; pp. 362–365. [Google Scholar] [CrossRef]
- Silver, D.L.; Yang, Q.; Li, L. Lifelong Machine Learning Systems: Beyond Learning Algorithms; 2013 AAAI Spring Symposium Series; AAAI: Stanford, CA, USA, 2013; Volume SS-13-05. [Google Scholar]
- Sultana, F.; Sufian, A.; Dutta, P. Advancements in Image Classification using Convolutional Neural Network. In Proceedings of the 2018 Fourth International Conference on Research in Computational Intelligence and Communication Networks (ICRCICN), Copenhagen, Denmark, 19 August 2018; pp. 122–129. [Google Scholar]
- Boulent, J.; Foucher, S.; Théau, J.; St-Charles, P.L. Convolutional Neural Networks for the Automatic Identification of Plant Diseases. Front. Plant Sci. 2019, 10, 941. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jmour, N.; Zayen, S.; Abdelkrim, A. Convolutional neural networks for image classification. In Proceedings of the 2018 International Conference on Advanced Systems and Electric Technologies, Hammamet, Tunisia, 22–25 March 2018; pp. 397–402. [Google Scholar] [CrossRef]
- Sharma, N.; Jain, V.; Mishra, A. An Analysis Of Convolutional Neural Networks For Image Classification. Procedia Comput. Sci. 2018, 132, 377–384. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- He, T.; Zhang, Z.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of Tricks for Image Classification with Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Lee, S.; Stokes, J.; Eaton, E. Learning Shared Knowledge for Deep Lifelong Learning using Deconvolutional Networks. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI-19, Macao, China, 10–16 August 2019; pp. 2837–2844. [Google Scholar] [CrossRef] [Green Version]
- Yang, K.; Qinami, K.; Li, F.-F.; Deng, J.; Russakovsky, O. Towards Fairer Datasets: Filtering and Balancing the Distribution of the People Subtree in the ImageNet Hierarchy. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency (FAT*’20), Barcelona, Spain, 27–30 January 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 547–558. [Google Scholar]
- Jia, Y.; Batra, N.; Wang, H.; Whitehouse, K. A Tree-Structured Neural Network Model for Household Energy Breakdown. In Proceedings of the World Wide Web Conference, New York, NY, USA, 17 May 2019; pp. 2872–2878. [Google Scholar] [CrossRef]
- Jiang, S.; Xu, T.; Guo, J.; Zhang, J. Tree-CNN: From generalization to specialization. EURASIP J. Wirel. Commun. Netw. 2018, 2018, 216. [Google Scholar] [CrossRef]
- Ni, J.; Gong, T.; Gu, Y.; Zhu, J.; Fan, X. An Improved Deep Residual Network-Based Semantic Simultaneous Localization and Mapping Method for Monocular Vision Robot. Comput. Intell. Neurosci. 2020, 2020, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Daliri, S. Using Harmony Search Algorithm in Neural Networks to Improve Fraud Detection in Banking System. Comput. Intell. Neurosci. 2020, 2020, 1–5. [Google Scholar] [CrossRef] [PubMed]
- Chen, G.; Lu, G.; Xie, Z.; Shang, W. Anomaly Detection in EEG Signals: A Case Study on Similarity Measure. Comput. Intell. Neurosci. 2020, 2020, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Zhang, Y.; Yu, X. An Overview of Image Caption Generation Methods. Comput. Intell. Neurosci. 2020, 2020, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning Long-term Dependencies with Gradient Descent is Difficult. Trans. Neur. Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Roy, D.; Panda, P.; Roy, K. Tree-CNN: A hierarchical Deep Convolutional Neural Network for incremental learning. Neural Netw. 2020, 121, 148–160. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization, 2014. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS’10), Sardinia, Italy, 13–15 May 2010. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-scale Machine Learning. In Proceedings of the 12th USENIX Conference on Operating Systems Design and Implementation, Berkeley, CA, USA, 4 November 2016; pp. 265–283. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label | Category | Train | Test |
|---|---|---|---|
| 0 | Bride | 787 | 199 |
| 1 | NotWeddingCar | 760 | 164 |
| 2 | Formal | 720 | 189 |
| 3 | Groom | 797 | 205 |
| 4 | NotBride | 791 | 208 |
| 5 | NotFormal | 431 | 109 |
| 6 | NotGroom | 735 | 188 |
| 7 | WeddingCar | 489 | 116 |
| Image | ResNet50-Pre-Trained | Inception-V3-Pre-Trained | LeNet-Scratch | ResNet-Scratch | Inception-Scratch | Tree-CNN |
|---|---|---|---|---|---|---|
 | abaya: 30.1%, vestment: 23.2%, cloak: 5.0%, theater_curtain: 5.0% | abaya: 31.6% harp: 18.9% vestment: 8.4% wig: 3.1% | Bride: 100.00% Groom: 0.0% | Bride: 100.00% Groom: 0.00% | Bride: 87.04% NotBride: 12.94% | Bride: 90.2%, wig: 7.4%, NotBride: 2.2%, bridegroom: 0.1% |
 | beach_wagon: 41.7%, pickup:10.9%, car_wheel: 8.7%, cab: 6.8% | jeep: 54.4%, beach_wagon: 25.9%, pickup: 5.3%, car_wheel: 1.7% | NotWeddingCar: 72.89% NotFormal: 26.23% | NotWeddingCar: 99.99% WeddingCar: 0.01% | NotGroom: 99.89% NotWeddingCar: 0.08% | minivan: 96.8%, beach_wagon: 1.8%, moving_van: 1.3%, parking_meter: 0.1% |
 | buletproof_vest: 43.6%, windsor_tie: 6.9%, gar: 2.7%, barracouto: 2.6% | bulletproof_vest: 33.1%, Windsor_tie: 5.2%, paddle: 2.1%, barracouta: 2.0% | Formal: 63.56% NotFormal: 22.51% | Formal: 94.94% NotGroom: 5.04% | NotGroom: 93.88% Formal: 6.02% | Formal: 98.1%, Groom: 1.6%, cardigan: 0.2%, suit: 0.0% |
 | fur_coat: 21.0%, breastplate: 8.8%, bow_tie: 7.5%, cardigan: 6.9% | military_uniform: 7.9%, pickelhoube: 7.2%, fur_coat: 6.6%, bow_tie: 4.7% | Groom: 100.00% NotGroom: 0.0% | Groom: 100.00% NotGroom: 0.00% | Groom: 100.00% NotGroom: 0.00% | bridegroom: 99.2%, NotGroom: 0.4%, NotFormal: 0.3%, mask: 0.1% |
 | groom: 16.0%, feather_boa: 14.8%, fountain: 4.4%, stole: 4.1% | sarang: 36.1%, maillat: 6.1%, gown: 4.7%, maillot: 4.3% | NotBride: 100.00% Bride: 0.0% | NotBride: 100.00% Bride: 0.00% | NotBride: 99.94% Bride: 0.06% | NotBride: 96.1%, Bride: 0.2%, cloak: 2.7%, Sarang: 1.0% |
 | file: 18.3%, refrigerator: 8.6%, photocopier: 3.5%, desk: 3.3% | suit: 67.1%, Loafer: 5.8%, Windsor_tie: 1.7%, sweatshirt: 1.2% | NotFormal: 99.16% NotGroom: 0.40% | NotFormal: 92.08% Formal: 6.60% | NotGroom: 100.00% Groom: 0.00% | NotFormal: 90.8%, Loafer: 4.3%, Formal: 1.5%, jean: 3.4% |
 | bow_tie: 30.1%, Windsor_tie: 5.4%, microphone: 4.5%, mask: 4.5% | drumstick: 6.5%, jersey: 4.2%, sweatshirt: 3.3%, mask: 2.8% | NotGroom: 99.18% NotFormal: 0.82% | NotGroom: 100.00% Groom: 0.00% | NotGroom: 100.00% NotFormal: 0.00% | NotGroom: 98.2%, jean: 1.7%, NotFormal: 0.0%, suit: 0.0% |
 | gondola: 21.8%, clog: 19.9%, minivan: 10.7%, milk_can: 6.5% | pickelhaube: 6.9%, waffle_iron: 5.9%, minivan: 5.5%, space_bar: 4.2% | WeddingCar: 100.00% NotWeddingCar: 0.0% | WeddingCar: 100.00% Groom: 0.00% | WeddingCar: 99.98% NotGroom: 0.01% | WeddingCar: 94.2%, altar: 4.2%, limousine: 1.6%, pot: 0.0% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alyami, H.; Alharbi, A.; Uddin, I. Lifelong Machine Learning for Regional-Based Image Classification in Open Datasets. Symmetry 2020, 12, 2094. https://doi.org/10.3390/sym12122094
Alyami H, Alharbi A, Uddin I. Lifelong Machine Learning for Regional-Based Image Classification in Open Datasets. Symmetry. 2020; 12(12):2094. https://doi.org/10.3390/sym12122094
Chicago/Turabian StyleAlyami, Hashem, Abdullah Alharbi, and Irfan Uddin. 2020. "Lifelong Machine Learning for Regional-Based Image Classification in Open Datasets" Symmetry 12, no. 12: 2094. https://doi.org/10.3390/sym12122094
APA StyleAlyami, H., Alharbi, A., & Uddin, I. (2020). Lifelong Machine Learning for Regional-Based Image Classification in Open Datasets. Symmetry, 12(12), 2094. https://doi.org/10.3390/sym12122094